ODI a table as a table size of loading
HelloI have a table with two columns.
Name of the table - PROGRAMS.
Columns - Pgm_ID, Pgm_Type.
What I'm trying to accomplish when I add a new line, I want to update this table. But if the same Pgm_Type already exists, to ignore it.
In my model, I loaded this table as type SCD OLAP. Pgm_ID as a substitute key column and Pgm_Type as add a line about the changes. In my procedure insert statement, I added 3 additional lines, but I'm a primary key violation. Is it possible to do this without adding additional columns for the current record flag and start and end time stamp etc, is there an alternative way to deal with it.
Thanks for your time and your help.
You can use an incremental update KM. For example, incremental update of IKM Oracle (FUSION).
-Put your UK (unique key) on Pgm_ID.
-Select the Insert for the Pgm_ID and the Pgm_Type.
-Select the update for Pgm_Type box.
So, when you load data from the source:
-If the Pgm_ID is not in the target, the line is copied.
-If the Pgm_ID is not in the target, the Pgm_Type is updated.
It will be useful.
Kind regards
JeromeFr
Tags: Business Intelligence
Similar Questions
-
Hello
In file attached an example of my problem. I remove a 2-dimension table and the size of the screen. I can see in "size 2" (see the example) that the size is not 0. Is this a normal behavior?
Thanks in advance, Daniel.
Hi Daniel,.
Since the delete array help page:
"Delete From table details
This function reduces the table in only one dimension... »
Even if your table 'seem empty,' he is so really. I'm guessing that the memory for lines is still allocated.
You can see by connecting the array to a loop and check how many times she iterates (i.e. twice).
To really empty table, you can add a further dismantling of the Array function and delete lines (length = 2, index = 0). Now connect this to a for loop and you will see it does not iterate. Table sizes will now be 0,0.
A little weird at first, but ultimately this is the expected behavior.
Steve
-
How to compare the original value of table size and the changed value
juice I took a table and then took the function of the size of the array so that it shows me the number of the elements present in it. so it'll be the original table size value. If the items in the table even changes another value, then I want to compare the original table size value and the value of table size has changed. How to compare... Please help me. you are looking for a possible solution. Thank you

Hi stara,
the attached picture shows the ony solution.
It will be useful.
Mike
-
WARNING: table size limit exceeded
Noticed this error on a sensor event. I had the same as those of the 5378-0,5488-0,5528-0,5476-0.5557-0,5687-0,5524-0 sigs.
What it means?
evError: eventId = 1130169990404666072 = severity = WARNING Cisco vendor
Author:
hostId: 02-evlan-c7
appName: sensorApp
appInstanceId: 355
time: December 1, 2005 19:10:08 UTC offset-360 = timeZone = GMT-06:00
errorMessage: warning Table size limit exceeded by GIS 5378.0. Additional table will be created. name = errUnclassified
These warnings are initially simply information and do not constitute an error that the user needs to worry.
When signatures are added to the sensor, the sensor will compile all signatures in a large regular expression cache table. This considerably speeds up the analysis. The cache table, however, has a limited size. When you add a signature to the cache table would develop the table beyond the allowed size, then you will see the warning that you posted above.
That caveat lets you know, it's that he couldn't add that signature to the existing table, and so it must create a new table for the signature and the signatures follow.
This information before debugging for developers of signature just so they can track what is happening because signatures are added.
The sensor works correctly and work very well. The addition of the new table only adds a very small performance reduction as an extra table must be analyzed during the analysis of the packets.
Users running with the signature by default settings would never need to worry about this message and can consider only a few logging information (it should really have been a status message instead of an error message)
Users who are unretiring signatures or creating their own custom signatures can see this message as they set up their sensors. So then he os to let them know that tables additional cache is taken to be created to manage the additional signatures. Once more just information and not a real error.
-
Get NPES trying to create a line of the iterator of table on the loading of the page.
Hi allI'm new to ADF and try to learn from its concepts. I've created a workflow with the train and using 7 jspx pages as the train stops. When I move from one stop to the next stop, the data are made to the database.
My use case is, I want to fill an iterator of table on the loading of the page based on the data provided on the previous stop.
I tried to use the code to find the iterator and create the line the view object in support Builder bean as well as file impl application module(call the executable action method) but every time I got the same null pointer exception.
The code used for creating line iterator:
BindingContext bindingContext = BindingContext.getCurrent ();
BindingContainer DCBindingContainer = (DCBindingContainer) bindingContext.getCurrentBindingsEntry ();
IdIterator DCIteratorBinding = bindingContainer.findIteratorBinding("iteratorName");ViewObject vo = idIterator.getViewObject ();
Line rw = vo.createRow (); It is the line where I'm getting null pointer exception.
Trace of the exception:
at oracle.adf.model.bean.DCDataVO.initFKs(DCDataVO.java:621)
at oracle.adf.model.bean.DCDataVO.createInstance(DCDataVO.java:592)
at oracle.jbo.server.QueryCollection.createRowWithEntities(QueryCollection.java:1993)
at oracle.jbo.server.ViewRowSetImpl.createRowWithEntities(ViewRowSetImpl.java:2492)
at oracle.jbo.server.ViewRowSetImpl.doCreateAndInitRow(ViewRowSetImpl.java:2533)
at oracle.jbo.server.ViewRowSetImpl.createRow(ViewRowSetImpl.java:2514)
at oracle.jbo.server.ViewObjectImpl.createRow(ViewObjectImpl.java:11079)
Please correct me if I'm wrong, but that's what I think I understand that, iterator links are not initialized correctly on appeal by Builder or application module impl of the file that I use.
I will need to create a listener of phase of page for the task flow and and use the method afterPhase to call my method for line creation and insertion in the table iterator. ?
But this approach causes the phase listner class to call for each workflow page I don't want I need to fill out the table only for a single page and not to other pages of six.
Please help me in this problem by providing suggestions and pointers.
My version of JDev is 11.1.1.6.
Thanks in advance.
~ Abhishek
Hi Ben,
Thanks for your reply. But it did not solve my problem.
To solve my problem, what I did is mentioned below:
In my support for this page two, I create a listner beforePhase method and named her beforePhase displaying page jspx tag property.
when the phaseId is RENDER_RESPONSE, so I call my method to set the extracted database of the values in the table iterator. and it updated the iterator with new values.
Thank you all for your answers.
-
Difference between external tables and sql * loader
Hello
Could you please tell me the difference between
tables external and sql * loader
I have serached on the net but did ' get correct idea
Please help me1 SQL LOADER can be run on the network (from any client computer), external tables can't
2. return to the Oracle 9, external Tables could not load CLOB/BLOB (Oracle10 changed it)
3 oracle 11 external tables have preprocessor, which is pretty dam characteristic cool - running essentially any OS command e.g. decompress before external table run. What's even better is the fact that the result of the operating system command is the source of the outer table, which means that there are no required temporary file (unzip the tracks and the output is the source of the external table). There are several ways to great use this - look at my blog for samples rare http://jiri.wordpress.com/2010/01/19/no-more-unix-scripts-in-11-2/
4. as long as the 009 stressed, filed external load anything, they show just. Think of it more as load on request - it's great if you have old files archived and one or two users what to see content once a while
5. external tables require no user access to the operating system, it is oracle environment pure - this may seem minor but for me it's huge. The fact that the ETL needs no special unix, no control file command and uses the simple SQL and DDL is nice and important
6. external tables can load more text files, Oracle export dump files can be loaded, perhaps in the future more formats will be supported (hopefully all right excel format?)
now the same thing to kill the myth - the TWO are EXACTLY the same when it comes to speed, I would actually drive of the external tables before will be faster because sql loader is old technology oracle doesn't really develops more
-
How to write a loop repeat 2 in 2D array values to readable size 10 1 table size
Hello everyone, I need help about to write for loop or may be a different approach, as you know for
I have a table 1 [1 2 3 4 5 67 8 9 10] d... now I want use for loop that reads 2 values as ([1 2]) and together these 2 values of first line of 2D array and repeat in a loop again read another 2 values ([3 4]) and set the 2 row table 2D like this line [5 6] 3 table 2D... .as she write 5 lines of table (2 * 5) 2D to 1 d (1 * 10) table... you can tell otherwise easy as not exatcly to be for loop... Thanks a lot for your help and suggestions... waiting for your answers
The short answer is that you must use the function Array reshape.
The longer answer involves more questions. You still have the same table 1 d of size? If this isn't the case, it will always be an even number of elements? If this is not the case, what you do with the last element? If you keep, what do you use to "pad" of the additional element of the matrix of results?
-
Data in table size limit @ 129491 float64s
I don't have a studio of measure, but I'm trying to s-series OR-DAQ interface modules using the NIDAQmx.h interface.
My problem boils down to the following in a c ++ application project console (visual studio 2005):
#include
int main() {}
float64 data [128 * 128 * 6]; 98304 64 - bit numbersor 786432 bytes (not a megabyte)
}
This command compiles and runs very well.
If I increase the allocated size of the table given more 129491 (float64s), the program compiles well but when I run the console program, I get an exception of windows does not support. Now that the number is just shy of 20-bit addressing for bytes, but it is not like he is exactly on the number or anything.
I will continue to look around for a solution, but if anyone can help, that would be great.
Thank you!
Hello Gus,
The stack size by default for applications compiled with Visual C++ is 1 MB. Note that the operating system and C runtime uses some stack space before that never call your main() function, so you have slightly less than a megabyte to work with. You can increase the size of the stack using the Visual C++/f option, but a better approach is to allocate the array on the heap instead (using malloc () free () or new/delete [] []).
Brad
-
Different font on label multiline table size
I feel that the answer is going to be it is not possible, but is it possible to have the text of different sizes in the same row/column label? I want to do is to have up to three lines of text, where the first line is larger than the other two... Maybe some sequence in the string of exhaust... something like:
SetTableRowAttribute (handle, control, 1, ATTR_LABEL_TEXT, "<\big>Line1\n<\little><\little>Line3 Line2\n");
Hi gtoph,
Unfortunately, there is no way to have the different fonts in a single table cell.
Suggestion of JR is a good thing. I'll add my own, in case that you have to scroll the table, but you don't need to edit the text:
You can create and configure a control out of the screen that has the look you want (see attachment), then empty control in an image using GetCtrlDisplayBitmap, set the type of cell in your table to VAL_CELL_PICTURE and then put your bitmap image in the cell.
But of course, this will not work unless you want to only display the text and not modify it.
Luis
-
Composed of different arithmetic table size
Hi all
I have two table with a different size,
Table 1 table 2
1 0
1 0
1 0
1
If compound arithmetic GOLD was performed on them, I went out
1
1
1
Is it possible that I can get
1
1
1
1
Thank you.
The filling is more easily done using "reshape the table." Here is a minimal code that fills the shorter array to the size of the longer of the two.

-
Partioned table - size Tablespace
Hi all
I need to find the size of a tablespace (free and used) for a partitioned table, can help some action on that by sharing the script. Google to get it, but could not able to find
Thank you
Clara wrote:
Hi all
I need to find the size of a tablespace (free and used) for a partitioned table, can help some action on that by sharing the script. Google to get it, but could not able to find
Thank you
start by querying ALL_TAB_PARTITIONS
I offer you my condolences; Since you rarely get your questions answered here.
-
design of table size question of data modeling
Hi Experts,
Sorry if I put my question in a wrong forum please suggest an appropriate forum.
need your opinion on the current design of our data warehouse of 10 years.
There is a dimension table with the structure as follows
Dimension table
--------------------
Number of dimension key (THIS IS NOT a PRIMARY KEY)
Natural key (from source) number
the source name character
current record indicator e Char (1)
date of form_date
TO_DATE date
several other columns, which, if change a new current record is created and the previous one is marked as H-historical
Data are stored in the table of size like this
Dimension_key natural key Source name current record ind from_date to to_date
1 10001 Source1: 1 January 2005 May 31, 2005
1 10001 Source1: 1 - jun - 20005 12-dec-2011
1 10001 Source1 C 13-dec-2011 NULL
2 20002 Source1: 1 - jun - 20001 12-dec-2011
2 20002 Source1 C 13-dec-2011 NULL
The problem I see in this design is that if any attribute is changed there is no surrogate key, the new record is inserted first taking the key dimension based on the (natural_key, source_name, current_record_ind).
Shouldn't it be kept as follows based on the principles of data warehousing.
Dimension_key natural key Source name current record ind from_date to to_date
1 10001 Source1: 1 January 2005 May 31, 2005
2 10001 Source1: 1 - jun - 20005 12-dec-2011
3 10001 Source1 C 13-dec-2011 NULL
4-20002 Source1: 1 - jun - 20001 12-dec-2011
5 20002 Source1 C 13-dec-2011 NULL
Please let me know the advantages and disadvantages of the current design.
Published by: Rous Sharma on December 15, 2011 20:28Correct, your second example for example by using a surrogate key is design to go with.
Flaws with the original design:
-There is a relationship one between Dimension_Key and Natural_Key, no need to keep both.
-Si Dimension_Key is the FK with a fact table, there will be a number of many relationships between fact and Dimension.
-Additional processing to search for Dimension_Key rather than simply for example use a sequence. -
Column not found error while Mrna an oracle with ODI user table
Hello
I'm trying to fill a column in an oracle table with the USER name of the ODI by using the function getUser ("USER_NAME") in the column mapping of the Interface, but the interface throwhing an error * column not found: supervisor in training [Select...] *. but it works very well with getUser("I_USER') column is of the filling of the user ID.
can someone help me why the user is not filling.
Thank youJoin the call to the api getUser inside single quotes
'<%=getUser("USER_NAME")%>'ID is a number can be used directly but USER_NAME returns a string which should be enclosed in quotes
-
Anyway is to check a file size of tables? I'm banging my head against a brick wall with Oracle APPS database at the minute. I have a db oracle limited account to query the db oracle behind the suite oracle e-business. There is a standard table that customer details are stored, lets call it "mysterytable". When I query this table, it returns 0 results. When our DBA it runs under the account of apps it returns 0 results.
When our DBA runs select * from dba_tab_privs where TABLE_NAME = 'mysterytable '... It returns
APPS schema1 mysterytable schema1 REFERENCES YES NO
APPS schema1 mysterytable schema1 DAY YES NO
APPS schema1 mysterytable schema1 SELECT YES NO
APPS schema1 mysterytable schema1 INSERT YES NO
APPS schema1 mysterytable schema1 INDEX YES NO
APPS schema1 mysterytable schema1 REMOVE YES NO
APPS schema1 mysterytable schema1 ALTER YES NO
I'm still convinced uterrely that data must be in this table, so I was wondering if theres no way to determine a size of the file at all tables, just to prove he's data in it? If this is not any other pointers?
If I execute select * from schema1.mysterytable it returns 0 results, he says not table are not etc. I had this problem before and data are here it's just because of my permissions it won't let me run the query. Mind you, I imagine that the APPS should be able to query this table depending on whether the "BENEFICIARY"?user599292 wrote:
Point taken, Ed but I'm an analyst not a DBA.I tried runinng the query with my personal account (low-privilege), as well as the APPS account. Returns no data, but I know for a fact that there is data in this table?
What can I do else?
Work with your dba.
oracle> sqlplus / a sysdba sql> select count(*) from myschema.mymystrytable;If that returns zero, then there is no lines in the table. period.
If it returns a count > 0, then I guess there's a TEUS in game, or you are have been not qualified "mymystrytable" with the schema name appropriate and were against another 'mymystrytable '. -
Hello
How to find the size of the table limit.
in fact, you could hit a limit of loop until you hit a limit table. but you'll see with this code.
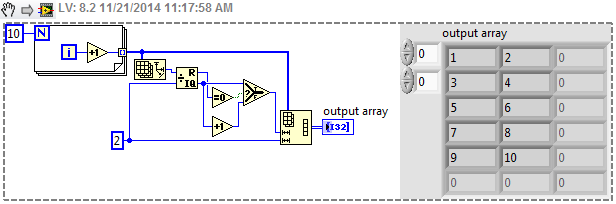
Maybe you are looking for
-
can you gave me my model number? giving my serial number
can you gave me my model number giving my serial nuber
-
My niece has a HP mini 110 that does not have a day. Do a check of the hard drive in the bios, it failed (7 on playback). I though I should get a new one so I ordered another. While waiting for that to happen, I had access to a usb SATA bridge and th
-
In Windows Movie Maker HELP "FOR THE DURATION of the CHANGE" 2. ' "says to" select title you want to change the duration. How to "choose" the title? The title as a RECOVERY when the arrow is hovering a square bubble appears showing the title and 6.7
-
Vista home prem 32 has 4 GB Mem.,
My Vista home prem 32 a 4 GB Mem, but windows uses only 1.27 GB forcing excessive paging & slowdown system way down... How can I fix it?
-
Norton tells me search\gather\windows\system index is invalid or missing
WHENEVER I LANCE NORTON UTILITIES START SCAN IT ME SAYS THAT H.KEY-LOCAL-MACHINE\SOFTWARE\MICROSOFT\WINDOWS SEARCH\GATHER\WINDOWS\SYSTEM INDEX IS NOT VALID OR MISSING. THEN IT REPAIRS BUT THE NEXT DAY I RAN THE ANALYSIS, HE COMES UP WITH THE SAME MES