Partitioning of Tables/indexes
HelloOracle Version 10.2.0
O/s Version: SUSE Linux
Currently, all tables and indexes are stored in the ponit of NFS mounting. I would like to know if I can partition the tables/indexes on local storage temporarily.
Thank you
Hello
Yes you can do it. But if you have a few scores on NAS and others on the local drive, then depending on the nature of the query/DML you will see some performance issues.
MSK
Tags: Database
Similar Questions
-
What happens to the existing after the partition of table index and created with local index
Hi guys,.
/ / DESC part id name number, varchar2 (100), number of wage
In an existing table PART I add 1 column DATASEQ MORE. I wonder the part of table based on dataseq.now, the table is created with this logic of partition
create the part table partition (identification number, name varchar2 (100), number of salary, number DATASEQ) in list (dataseq) (values partition PART_INITIAL (1));
Suggestionn necessary. given that the table is partitioned based on DATASEQ I wonder to add local indexes on dataseq. to dataseq, I have added a local index create index idx on share (dataseq) LOCAL; Now my question is, already, there are the existing index is the column ID and salary.
(1) IDX for dataseq is created locally so that it will be partition on each partition on the main table. Please tell me what is happening to the index on the column ID and salary... it will create again in local?
Please suggest
S
Hello
first of all, in reality 'a partition table' means create a new table a migration of existing data it (although, theoretically, you can use dbms_redefinition to partition an existing table - however, it's just doing the same thing behind the scenes). This means that you also get to decide what to do with the index - index will be local, who will be global (you can also reassess some of existing indexes and decide that they are not really necessary).
Second of all, the choice of the partitioning key seems weird. Partitioning is a data management technique more that anything else, in order to be eligible, you must find a good partitioning key. A column recently added, named "data_seq" is not a good candidate. Can you give us more details about this column and why it was chosen as a partitioning key?
I suspect that the person who proposed this partitioning scheme made a huge mistake. A non-partitioned table is much better in all aspects (including the ease of management and performance) that divided one wrongly.
Best regards
Nikolai
-
Partitioning or an index organized table. Suggestion required.
Hi gurus,
We decided to perfomance increase in customer table that has more than 100 million records
{code}
customer_id number,
cust_name varchar,
Date of Applied_date,
City varchar (100)
{code}
This is the structure of the customer table.
We decided to composite partition the table based on date (range) applied and customer_id (hash).
I am confused to go with table index (where tables and indexes are stored together) for better performance.
Please suggest what we I'm going? for best performance.
Please answer
Supersen
If the query predicate (WHERE clause) include the Partition key column, Oracle can make the size of Partition - that is to say identify the target Partition. Otherwise, he would have to do a full Table Scan because he doesn't know what Partition the target Row (s) is in.
For example, if you are partitioning by APPLIED_DATE but your request is on the table by CITY, Oracle cannot identify the target Partition and do a Scan of Table full - even if you subpartition by CUSTOMER_ID and integrate CUSTOMER_ID in your query, Oracle cannot identify the Subpartition because it cannot identify the Partition.
Hemant K Collette
-
partition in maintained growth index, partition of table didn't need to add space.
Version Oracle 11 g 1 material, OS is aix.
We have a 100 to dataware house, are partitioned with the index.
Each table move data 6 months previously and even with the index. However our table tablespace has not seen more, but index tablespace kept more and more, I have to keep adding spaces.
How to address this issue? where to find the problem is?
Thanks in advance.>
I joined dba_segments with dba_objects to get nom_segment, owner, created, bytes/1024/1024 as this tablespace.
. . .
EVENT_TYPE_HGRAM_DEV STATS INDEX SUBPARTITION 28-SEP-05 DECEMBER 10 05
1
>
Does not the validation of the application and the columns you listed do not match the data that you have posted.EVENT_TYPE_HGRAM_DEV - the name says a statistical histogram on the EVENT_TYPE table in the DEV environment. This object name means something to you?
Enter you two dates but only "created" as a column. And what is the '1' represent?
You also do not show an OWNER but mention a column 'owner '.
Which table is, or has been, this index belong to? The table still exists? Have you purged the recyclebins?
-
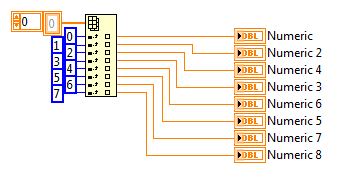
Hello world
I know that I can use a table to reshape to convert a 2D 1 d.
But I'm curious of know how is it when I wire a 2D in an array of index table, and there is no constant for the index entries, the result comes out as a 1 d array?
How it works in this case? could someone please explain that to me?
Index functions Array always returns the element or subarray n-dimension table to index. By default, if you do not connect the index , the first input terminals line sub-table index 0, the second subarray index 1st row and so on.
-
I have a table 1 d with 20 items... I now want to put all the 20 by 20 (variable) indicators different elements for further processing each indivually... Function table index is too tiny miny and ugly while creating this... any easier way?
So is it too much work? I do not understand the question.
-
Slow table indexing when you use a subroutine
I wrote a labview code that extracts a range of data to an analog waveform. (3 options - last value only, all values or a specific range)
I'm buying what I consider of large amounts of data (analog samples at 1 MHz for 20 seconds).
I'm proceessing in a loop of consumer data and found that the functions of indexation has slowed to a crawl (~ by seek 100mSec).
The slowdown is a linear relationship to the size of the array.
My debug analysis concluded that, if I change one of my subroutines of code inline, the speed problem disappeared.
Why is - this?
My best guess is that Labview takes a copy of the table to send by the Subvi.
I'm not editing data in the subroutine, is it possible to say LABVIEW not to do?
Attached are 2 versions of my VI, prompt a Subvi online (sorry for the mess) others (slow) use the code as a Subvi.
Criterion VI to create a picture of increasing size and measure search for table indexing time and the computer graphic.
I'm using Labview 8.5.1
iTm
Long time user first time poster...
Tim,
You are quite correct. What you might look into is recessing workmanship of your VI. It depends on what you want to do with the final result. Reentrant will solve this problem, but don't update the data on the front panel.
See the following KB: differences between screws neres (Preallocate), incoming screws (part of Clones), VI models and Dyn...
-
How to find on fragmented tables/index.
Hi I am using oracle 10g. is there a way to know more fragmented tables/indexes, so that the reorganization or reconstruction of to improve sql performajnce?930254 wrote:
Hi I am using oracle 10g. is there a way to know more fragmented tables/indexes, so that the reorganization or reconstruction of to improve sql performajnce?Its a great time you read all messages written by Jonathan Lewis on the fragmentation and first understand what it is in true before thinking about to remove it.
http://jonathanlewis.WordPress.com/category/Oracle/infrastructure/fragmentation/Aman...
-
How to import tables, index, tablespace, etc. of a DMP.
Hello
I would like to know how to import tables, index, tablespace, etc. of an export an Oracle 10.2.0.1 to apply on an Oracle 11.2.0 DMP. When I import the DMP file a unique Tablespace, for example, will users tablespace data.
On the basis of origin, we have different tablespace each separated with different content (tables, index) and I would like to know if it is posible to import the same schema, tables, index, tablespace quite with a DMP alone, Export. I can't use DBUA because the database on the 10.2 software is missing, I have only one file (24 GB) DMP DMP!.
Thanks for the reply,
Sorry for my English :).
Kind regards.The standard solution is
-Make sure that the target user doesn't have the UNLIMITED TABLESPACE privilege, using REVOKE
-Make sure that the target user has no QUOTA on the default tablespace using ALTER USER... QUOTA
-Make sure that there is quota on the tablespace (s) of the target, using ALTER USER... QUOTA
-import indexes = n
-empty the index orders in a separate file
IMP indexfile =...
-run this file--------------
Sybrand Bakker
Senior Oracle DBA -
Table partitioning on table MTL_SYSTEM_ITEMS_B?
Hello
We have an obligation to apply the partitioning on table MTL_SYSTEM_ITEMS_B. main reason is to improve the performance of queries.
We planned to do with ORGANIZATION_ID column as the partition key.
If anyone can share with your thoughts, what method of partition is good at this table to improve performance.
Thank youHello
Please see these links/docs.
Using partitioning of database with the E-Business Suite
http://blogs.Oracle.com/stevenChan/2006/09/using_database_partitioning_wi.htmlUpdated whitepaper: database, partitioning for E-Business Suite
http://blogs.Oracle.com/stevenChan/2009/04/whitepaper_update_database_partitioning_for_ebusin.htmlNote: 554539.1 - database using partitioning with Oracle E-Business Suite
Thank you
Hussein -
ORA-01502: index 'pk_tab1' or partition of this index is unusable;
After ruining congratulate him:
ALTER index rebuild tablespace to developers pk_tab1. »
I check the State of objects and getting no results
Select * From User_Objects o
Where o.status! = 'VALID';
But my process to get the error
ORA-01502: index 'pk_tab1' or partition of this index is unusable;
Way?
And how to avoid problem, like these in the future?
How to check the index is to rebuild correctly?Please show us
Select index_name, status, user_indexes tablespace_name I where i.index_name = 'PK_TAB1'
If it stills status INDIVIDUAL... rebuild
change the PK_TAB1 index rebuild online;
and check... so again; Drop it and recreate ;)
Edited by: Surachart (HunterX) on June 16, 2009 13:03
-
Delay in a partitioned table index population
Hello
We have a 3 TB database, which earns about 5 GB per day. Fat is partitioned by date (a partition for each day), as well as their local indexes. The population of data is made by IBM DataStage and assume that it uses a bulk loading. I have 2 questions:
1. is the index updated immediately for cargo in bulk, or Oracle wait until the load has finished updating indexes on table?
2. is there a way to tell Oracle to have an index for a table, but not for a partition of this table? What I want to do is fill partition today the table with data today, but be able to build the index for this partition at a later date. Deletion and re-creation of the index for the entire table are not an option.
Thank you.What you would normally do here is to load the data into a separate intermediate table, build indexes on this staging of the table, and then create a swap partition to load the data into the partitioned table. Exchange partition is a way to exchange very quickly a partition of a partitioned with a separate table and unpartitioned table. This happens almost instantly.
Justin
-
Hi all
I use oracle 10g R2 64 bits on 64-bit windows server 2008.
I am facing problem with a table, which seems to be supposed to be a table partitioned, because it expects the 80000 lines per year.
This is the normal table for the table script
create table Leave_Request (Leave_request_id number primary key, emp_id number references emp(emp_id) not null, leave_type_id number references leave_types(leave_type_id) not null, leave_apply_date date not null, leave_from_date date not null, leave_to_date date not null, remarks varchar2(3000));
What is known, is that an index would be created to Leave_request_id automatically.
now, my question is how to partition? How to create its index score?
I read a few pages on the partitions and the notion of partitioning, but always confused with my situation.
an example would be much appreciated.
Thank you.
First of all you must decide the column on which you want to partition in function. As you expect 80000 lines per year, you can partition it on the date column for example leave_apply_date with the partition of the RANGE.
What is known, is that an index would be created to Leave_request_id automatically.
No you need write explicitly create index statement to create indexes.
now, my question is how to partition?
Here is an example:
CREATE TABLE sales_range
(salesman_id NUMBER (5),)
salesman_name VARCHAR2 (30),
Sales_Amount NUMBER (10),
Sales_Date DATE)
PARTITION OF RANGE (sales_date)
(
PARTITION sales_jan2000 VALUES LESS THAN (TO_DATE('02/01/2000','MM/DD/YYYY')),
PARTITION sales_feb2000 VALUES LESS THAN (TO_DATE('03/01/2000','MM/DD/YYYY')),
PARTITION sales_mar2000 VALUES LESS THAN (TO_DATE('04/01/2000','MM/DD/YYYY')),
PARTITION sales_apr2000 VALUES LESS THAN (TO_DATE('05/01/2000','MM/DD/YYYY'))
);
How to create its index score?
Just add keyword LOCAL at the end of the create index example statement
CREATE INDEX abc_ix_01 ON test (last_update_time) LOCAL app_index TABLESPACE;
For more information, read Tables and partitioned indexes .
-
Partition of table reorganization
Hello
I have a pretty large table with the partition of the range. The person who ran a database before me, left huge amount of data in the default partition as existing partitioned filled and he did not create the new partition. Now, I'm putting together this table. The default partition has about 70 million lines. I want to know what will be the most effective way to carry out this exercise? the table has a primary key, foreign key, and also some other indexes on that.
In the test environment, I created new partitions. Data copied from the default partition in 6 temporary tables. Copy takes about 8 hours. Now, I'm debating if I should truncate data from default partition and move the lines of time tables created back into the new partitions by writing insert query? I know it's easier way out, but not the most effective way.
Another option I'm considering is, use datapump to export the data from the partition and then import, but I have not tried this? Can you show me or direct me to an example where the datapump is used to export and import a partition.
Oracle version: 11.2.0.3
Operating system: SUN Solaris 10
In the test environment, I created new partitions. Data copied from the default partition in 6 temporary tables. Copy takes about 8 hours. Now, I'm debating if I should truncate data from default partition and move the lines of time tables created back into the new partitions by writing insert query? I know it's easier way out, but not the most effective way.
We cannot help you if you SHOW us what you have done rather than simply say.
What is the table the original table DDL?
What is the DDL of the new test table?
What data is in each of 6 temporary tables?
If each of 6 temporary tables has data belonging to a single NEW partition then just use EXCHANGE PARTITION.
1. create 6 new partitions in the table
2 make a swap partition between each of the 6 new partitions and the corresponding temporary table is not partitioned.
Trade is expected to take less than a second because they are updates only data dictionary.
See my response and code example in this thread
-
Join wise Partition 3 tables is possible?
Hello
I have two tables. One is an array of key-value (EAV model).
The key-value table has a partitioning of reference through the reference to the main table, which is partionned by the time.
I want to choose to select all entries in the main table with two specific value in the table "key-value. Because each value is a line, I need to join (or do a subquery) table of the value of key as many times as I have values to search.
In my case, the query is:
This query can also be written like this:SELECT p.pdu_id FROM pdu p INNER JOIN field_value fv ON (fv.pdu_id = p.pdu_id AND fv.field_id = 4) INNER JOIN field_value fv2 ON (fv2.pdu_id = p.pdu_id AND fv2.field_id= 3) WHERE P.TIME > to_date('11/21/2006 00:00:00','MM/DD/YYYY HH24:MI:SS') AND P.TIME < to_date('11/28/2006 00:00:00','MM/DD/YYYY HH24:MI:SS') AND fv.value = '0xFFFFFF' AND fv2.value = 'aircraft'
The two motions have comparable performance and explain the plan.SELECT p.pdu_id FROM ( SELECT p.pdu_id FROM pdu p INNER JOIN field_value fv ON (fv.pdu_id = p.pdu_id AND fv.field_id = 4) WHERE P.TIME > to_date('11/21/2006 00:00:00','MM/DD/YYYY HH24:MI:SS') AND P.TIME < to_date('11/28/2006 00:00:00','MM/DD/YYYY HH24:MI:SS') AND fv.value = '0xFFFFFF' ) p INNER JOIN field_value fv2 ON (fv2.pdu_id = p.pdu_id AND fv2.field_id = 3) WHERE fv2.value = 'aircraft'
This query takes time looooonnng... When I look at the plan to explain it and I can see that only a partition of Oracle 'p' access, only a score of "fv", but all the fv2 partition!
An idea to make fv2 use only the right partition?
Thanks in advance
Published by: Thibault January 31, 2011 03:16Hello
Try this and use an index on the column used for Assembly.
SELECT / * + (p.pdu_id_idx) * / p.pdu_id of
(select pdu_id from pdu, including TIME > to_date (November 21, 2006 00:00:00 "," MM/DD/YYYY HH24:MI:SS'))
AND THE TIME< to_date('11/28/2006="" 00:00:00','mm/dd/yyyy="">
(select pdu_id field_value where value = "0xFFFFFF" and field_id = 4) fv,.
(select pdu_id field_value where value = "airplane" and field_id = 3) fv2
where p.pdu_id = fv.pdu_id
and p.pdu_id = fv2.pdu_id;
Maybe you are looking for
-
How can I scroll through email in the list?
Before the last update, I was able to click on the arrow down in an email, and it would be then just move to the next on the list email. Now he asks me to confirm if I want to just open and read the next unread mail. Blah! not what I want. Having an
-
A unit of material that I can't get my mini sd port to work. I have to download something first?
I'm sorry it is an acer aspire netbook D255E
-
When I right click of my mouse I do not get the properties option. I need to increase the resolution to fit a bigger screen.
-
Cannot install itune in vista.
I use Windows Vista. When I try to install the latest itune. I got a message error "there is a problem with this Windows Installation Package. A program required for this istall complete could not be run. "what program should I?
-
HP a4316f-b not fully implemented on the road
My HP Pavilion A4316F-B does not start. The fans, I think, the discs turn up. The power button is not lighting and the monitor stay asleep. I can open the CD/DVD disc trays, too. I pulled the CMOS battery to reset. I've also removed power and on butt