PCTFREE and PCTUSED for index.
Simple doubt confuse many.1 why PCTFREE is required as update is performed internally as a deletion followed by insert in the index? Also this PCTFREE can waste space also in block.
2. why PCTUSED is required as a complete block must be free (no key entry) to be re-used anywhere in the structure of the index by listing in free-list index?
-Yasser
YasserRACDBA wrote:
Simple doubt confuse many.1 why PCTFREE is required as update is performed internally as a deletion followed by insert in the index? Also this PCTFREE can waste space also in block.
PCTFREE is essentially used for updates of these Null enteries in marketing and now have updated.
2. why PCTUSED is required as a complete block must be free (no key entry) to be re-used anywhere in the structure of the index by listing in free-list index?
PCTUSED is NOT used for the index. You can't control how index blocks would be used as as setting limits used again lower in data blocks. Here's a good explanation for the same question asked by yours truly :)
HTH
Aman...
Tags: Database
Similar Questions
-
can I put PCTFREE and PCTUSED in LMT
Hello
can I put PCTFREE and PCTUSED in LMT (locally tablesapce)?
and how I can decrease the probability of migration of line and chaning in LMT
Thank youHello
It depends on the MANAGEMENT option space you choose.
If you create the LMT with SPACE MANAGEMENT MANUAL then you will always have to tune
PCTFREE and PCTUSED as formelly (with DMT).
It is recommended to use the AUTOMATIC SPACE MANAGEMENT then these settings are tuned
by algorithms.Also, by setting the AUTOMATIC SPACE MANAGEMENT, you can use the SHRINK command which is very
useful to rearrange your Tables and indexes (starting with 10g).Best regards
Jean Valentine -
Hai!
I want to improve the performance of insertion and retriving from a table! "
* Could I achieve this by changing the PCTFREE and PCTUSED values?
* If so, what are the values that I put?
-my table contains lakhs of records.
-is continuous insertion of records.
-Update of the is a rare disease.
-iam using Oracle 10 g, data_block_size = 8kb, OS: windows-7
* What to change in the block size?
-Do I need to increase it? or decrease it?936113 wrote:
u could tell me, how would I know if Segment space management is AUTOMATIC or NOT...!select segment_space_management from user_tablespaces where tablespace_name = (select tablespace_name from user_tables where table_name = 'XXX'); -
Why my drive hard Boot keep reading and writing for 20 minutes after the start?
As the title says my HDD Boot continues to read and write for about 20 minutes after the start. Read and write up to 10 GB in the process. I would say a good way to destroy a disc. I have not seen this behavior in any other OS.
10.10.5 OS version
Model: Mac Pro
ID: MacPro3, 1
Processor: Intel Quad-Core Xeon
Number of processors: 2
Total number of cores: 8
(Vivid RAM) memory: 8 GB
Any help will be greatly appreciated.
Thank you.
Check Console.app and see what happens. Could be something of a time Machine for Spotlight indexing to a process of runaway of an OS X or a bug in the application.
-
Hello and thanks for reading.
I have a problem that requires me to do a lot of manipulations with the berries, and I am doing this in a series of nested for loops. I'll cut straight to my question.
I initialize an array 0 in several user-defined columns. I run a loop for the number of times user, generating a random value to each iteration defined. If I activate the automatic indexing, I use the subset of table replace outside the loop and it works very well.
Here's my problem. If I turn off the automatic indexing, and son of the [i] block to the index on the subset of table replace, now all of a sudden all I get is a random value, and it is always in the last slot in the table.
I was pulling my hair out on this problem. I looked at the forums, I looked at the example problems, I don't know WHY it does this, but I have TO be able to use the loop counter to replace the elements in the array. I'll lay 3 loops, and I'm not quite (familiar) uncomfortable with the way the auto-indexation feature chooses value auto-index to be able to think through the problem.
I wrote the program in C in my head in about 10 minutes, but this automatic indexing thing is KILLING me and I have no idea how import C in LabView without writing a dll, which I don't know how do either.
Please let me know how I can get the loop For to browse a table without using automatic indexing. Yet once again, I have no idea why he is just posting a value in the last slot of the table.
Thanks a lot for all the replies.
I know what it is. I have no LV 2010 here at installed work, so I have to rely on my memory and see the code.
You use replace table subset. With lit autoindexing, you create a table 1 d of random numbers which is be the same length as your table due to the terminal N being associated with the length of the array. If you end up replacing the dimension table 1 d in its entirety in a single shot with the new data starting with element 0. (For smile, associate a smaller number to Terminal N and you will see that some of your table 1 d is replaced).
The way I showed you replace 1 data at a time, and the first iteration is item 0, the element following 1...
-
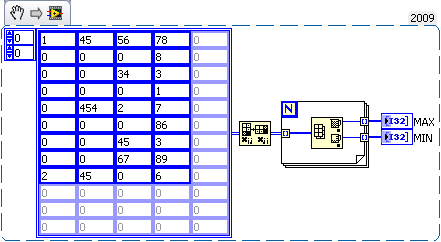
How to find the Maxima and Minima for each column of a 2D array?
Hello
I have a 2D chart and I would find the maxima and minima of each column of the 2-D table. Even though I know how to get maxima and minima for the whole picture but don't know how columnwise? Any ideas please?
Thank you
Rohit
Hello
@Smercurio-What you said is true, I should have shown using automatic indexing enabled which is really excellent choice. I just tried to show in a very simple way.

Anyway, here's the best way
-
Where to find drivers for Win Vista LAN, BT and Wifi for Aspire V3 - 571G?
Where to find drivers for Win Vista LAN, BT and Wifi for Aspire V3 - 571G?
Try this, 100% reliable Web site:
http://www.station-drivers.com/index.php/downloads/func-startdown/633/
-
latest drivers and codecs for my hardware and software on my computer
Question No. 1, how can I know if I have the latest and greatest drivers and codecs for all my software and hardware? Question #2 so I have later where can I find them?
Start > run > type MSinfo32 > hit enter and wait.
Take note drivers and their index numbers
(1) for audio: go to the computer manufacturer's website and check the drivers for your machine. Video: do the same thing, unless you have a PC with a separate card. In this case, go to the nVidia or ATI Web site and get the latest drivers from there. Codecs: Download and install the pack K-lite codec free or similar.
(2) Google is your best friend. Search: Support... PC/laptop do... »
See you soon,.
Jerry
-
Win 7 to wait for indexing status never ends
Win 7 to wait for indexing status never ends
Cannot use outlook 2010 mail filters all inactive when displayed Ribbon except + (More) search icon
Hi Bill,
Thanks for posting your question in the Microsoft Community forum. I understand that indexing status never ends. I would like to help solve you the problem.
Before troubleshooting, provide us with information.
1. What is the brand and model of the computer?
2. what security software is installed?
3. is the question confined to the indexing status?
4. don't you make changes to the computer before the show?
This problem can be caused by some incompatible system files associated with indexing. Follow these methods:
Method 1.
Open the search and indexing Troubleshooter: http://windows.microsoft.com/en-US/windows7/Open-the-Search-and-Indexing-troubleshooter
Method 2.
1. go to control panel and look for 'Features' in programs and features.
2. click on "Turn Windows features on or off".
3. uncheck the search of Windows and restart as required.
4. go to c:\ProgramData\Microsoft\Search\Data\Applications and rename the folder Windows at Windows_ORIG.
5. return to the search function of Windows to make it back on (see steps 1 and 2).
6. restart as required.
Method 2.
I suggest that you can exercise SFC scan and check if that helps. The SFC/SCANNOW command analyzes all protected system files and replaces incorrect versions with appropriate Microsoft versions.
For more information how to make SFC / scan, please follow this link: http://support.microsoft.com/kb/929833
Method 3.
Run a full scan of the computer with the Microsoft Safety Scanner to make sure that the computer is virus-free.
Microsoft Safety Scanner: http://www.microsoft.com/security/scanner/en-us/default.aspx
Security Scanner warning: there will be data loss through an analysis using the Microsoft safety scanner to eliminate viruses as appropriate.
You can ask your question related to Outlook 2010 here: http://answers.microsoft.com/en-us/office/forum/office_2010-outlook?tab=all&tm=1363676957004
Let us know if you need help with this question, we will be happy to offer you our help.
-
Does anyone know why these garbage Adobe CC is not open on weekends? We all sit and wait for these people to return to work to help us to fix their JUNK?
If you go to the forum to your specific program and ask a question, with all the relevant details, someone may be able to help
Forum of https://forums.adobe.com/thread/1929760 to find a forum for your program list
-or directly to the https://forums.adobe.com/welcome Forum Index
-
Difference of path between primary key and a Unique Index
Hi all
Is there a specific way the oracle optimizer to treat differently the Primary key and Unique index?
Oracle Version
Sample data test for Index NormalSQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production PL/SQL Release 11.2.0.3.0 - Production CORE 11.2.0.3.0 Production TNS for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production NLSRTL Version 11.2.0.3.0 - Production SQL>
Examples of test when using primary key dataSQL> create table t_test_tab(col1 number, col2 number, col3 varchar2(12)); Table created. SQL> create sequence seq_t_test_tab start with 1 increment by 1 ; Sequence created. SQL> insert into t_test_tab select seq_t_test_tab.nextval, round(dbms_random.value(1,999)) , 'B'||round(dbms_random.value(1,50))||'A' from dual connect by level < 100000; 99999 rows created. SQL> commit; Commit complete. SQL> exec dbms_stats.gather_table_stats(USER_OWNER','T_TEST_TAB',cascade => true); PL/SQL procedure successfully completed. SQL> select col1 from t_test_tab; 99999 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 1565504962 -------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 99999 | 488K| 74 (3)| 00:00:01 | | 1 | TABLE ACCESS FULL| T_TEST_TAB | 99999 | 488K| 74 (3)| 00:00:01 | -------------------------------------------------------------------------------- Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 6915 consistent gets 259 physical reads 0 redo size 1829388 bytes sent via SQL*Net to client 73850 bytes received via SQL*Net from client 6668 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 99999 rows processed SQL> create index idx_t_test_tab on t_test_tab(col1); Index created. SQL> exec dbms_stats.gather_table_stats('USER_OWNER','T_TEST_TAB',cascade => true); PL/SQL procedure successfully completed. SQL> select col1 from t_test_tab; 99999 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 1565504962 -------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 99999 | 488K| 74 (3)| 00:00:01 | | 1 | TABLE ACCESS FULL| T_TEST_TAB | 99999 | 488K| 74 (3)| 00:00:01 | -------------------------------------------------------------------------------- Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 6915 consistent gets 0 physical reads 0 redo size 1829388 bytes sent via SQL*Net to client 73850 bytes received via SQL*Net from client 6668 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 99999 rows processed SQL>
If you see here the same even as the statistics were gathered,SQL> create table t_test_tab1(col1 number, col2 number, col3 varchar2(12)); Table created. SQL> create sequence seq_t_test_tab1 start with 1 increment by 1 ; Sequence created. SQL> insert into t_test_tab1 select seq_t_test_tab1.nextval, round(dbms_random.value(1,999)) , 'B'||round(dbms_random.value(1,50))||'A' from dual connect by level < 100000; 99999 rows created. SQL> commit; Commit complete. SQL> exec dbms_stats.gather_table_stats('USER_OWNER','T_TEST_TAB1',cascade => true); PL/SQL procedure successfully completed. SQL> select col1 from t_test_tab1; 99999 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 1727568366 --------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 99999 | 488K| 74 (3)| 00:00:01 | | 1 | TABLE ACCESS FULL| T_TEST_TAB1 | 99999 | 488K| 74 (3)| 00:00:01 | --------------------------------------------------------------------------------- Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 6915 consistent gets 0 physical reads 0 redo size 1829388 bytes sent via SQL*Net to client 73850 bytes received via SQL*Net from client 6668 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 99999 rows processed SQL> alter table t_test_tab1 add constraint pk_t_test_tab1 primary key (col1); Table altered. SQL> exec dbms_stats.gather_table_stats('USER_OWNER','T_TEST_TAB1',cascade => true); PL/SQL procedure successfully completed. SQL> select col1 from t_test_tab1; 99999 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 2995826579 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 99999 | 488K| 59 (2)| 00:00:01 | | 1 | INDEX FAST FULL SCAN| PK_T_TEST_TAB1 | 99999 | 488K| 59 (2)| 00:00:01 | --------------------------------------------------------------------------------------- Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 6867 consistent gets 0 physical reads 0 redo size 1829388 bytes sent via SQL*Net to client 73850 bytes received via SQL*Net from client 6668 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 99999 rows processed SQL>
* In the 1st table T_TEST_TAB, table always use FULL table access after creating indexes.
* And in the 2nd table T_TEST_TAB1, table uses PRIMARY KEY as expected.
Any comments?
Kind regards
BPat>
* In the 1st table T_TEST_TAB, table always use FULL table access after creating indexes.
* And in the 2nd table T_TEST_TAB1, table uses PRIMARY KEY as expected.
>
Yes - for the first table a full table scan will be used as the currently selected column is nullable and indexes do not include null values.The index can be used for the second query, since all the data (first column) is available between the index and there may be no NULL values because of the primary key. If you check constraints, you find that the there is now a CHECK constraint to ensure that the first column cannot be null.
For a full and interesting discussion see the explanation of this and a related issue on the question I ask in this thread
What SYS tables (not seen) contain the value NULL spec /not/ column definition? and my response he posted: 23 April 2012 09:02I ask the question is based on a question here which is similar to yours
Columns becoming nullable after a fall of primary key? -
alternative to delete and re-create indexes
Hi all
We use Oracle 11.2.0.2. We have a script where we fall before the full update of a table, the indexes and re-create indexes to improve performance.
Rather than a drop and recreate indexes, I wanted to know if there's another approach better to achieve performance gains.
I thought make unusable index and rebuild later. Would it not be better to drop and re-create the index.
Thanks for your time.>
I thought make unusable index and rebuild later. Would it not be better to drop and re-create the index.
>
This is exactly the right strategy to use. He does need to get the benefit of the performance, and there is no danger of inadvertently re-create the index with the wrong settings or in the wrong table space.See understanding when to use unusable index or Invisible in the DBA Guide
http://docs.Oracle.com/CD/E11882_01/server.112/e25494/indexes002.htm#CIHJIDJG
>
Unusable indexAn unusable index is ignored by the optimizer, and is not maintained by DML. One of the reasons to make an unusable index are to improve the performance of loading in bulk. (Loads in bulk, go faster if the database is not required to manage the index when inserting rows.) Instead of letting fall the index and later re-creation, requiring you to remember the exact parameters of the CREATE INDEX statement, you can make the index unusable and then rebuild.
-
CGI. REMOTE_USER nec / but not for index.cfm
This is a ColdFusion 10 installation under Windows 2008 R2 with IIS 7.5. We have an additional authentication module, co-signer, installed for the SSO.
If I send a request to https:// [Servername] /test/ and empty the CGI variables, cgi.auth_type is set to co-signer and cgi.auth_user and cgi.remote_user are both set to my username.
If I send a request to https:// [servername]/test/index.cfm and discharge the CGI, cgi.auth_type, cgi.auth_user, and cgi.remote_user variables are all set to [empty string]. ]
Some of the things that we tried (largely based on positions and cgi.auth_user do not stay together):
- Move the co-signer module to the top of the list of modules in IIS
- Activating Windows auth at the level of the server in IIS (index.cfm then additional authorization required beyond co-signer)
- Activating Windows auth at the level of the directory in IIS (no change - remote_user not filled in)
- Disable anonymous authentication at the server level in IIS (index.cfm then returns a message 401 Unauthorized)
It's strange because cgi.script_name value is set to /test/index.cfm in both cases, but the credentials are passed to /test/ and not/test/index.cfm.It's a longshot that anyone here use co-signer, but I was wondering if anyone has any other ideas for what could be the cause.
Thank you! We consulted an expert co-signer, and we had a configuration problem. The fact that he was working in the ASP was shaking me.
In our case, co-signer protection was not enabled in the web.config file of the file to the root of the document, but only active for the directory in question (/ test) by the Web.config in this folder.
When we activated the protection at the document root (and deleted the file to the directory level web.config), server for auth_type, auth_user and remote_user environment variables being passed the ColdFusion.
-
RoboHelp can produce a decent online help 508 compliant? When I try, TOC, IX and search for bad air.
I have Windows 7 and RoboHelp 9. I take a long Word document and convert it to help online. The OCD, IX and search for bad air. I contacted Adobe Support and up to now, they say it's just what assistance 508 compliant is supposed to look like, even if I keep coming back to try to get different opinions. Specifically, the table of contents entries are not expandable and collapsible, it shows just the whole thing. They show no legs. The index produces numbers like 2_1_1_Add_a_New_Outcome.htm entries. Research shows the symbols and numbers, starting by! 1 2 3 4 5 6 7 8 9 10 11, and has no search box to enter a Word to search for. Anyone know if it's really only 508 compliant I can get of RoboHelp, please help?
Hi Tom
Sorry, I've had an incredibly taxing a few days and I forgot your last question, ask questions about WebWorks.
Unfortunately, I have no idea how WebWorks. In addition, I'm not any kind of expert on Section 508 compliance. I heard "collegial" of it but none to support than real life. And because the way I didn't stay in a Holiday Inn Express last night, I can't pretend to be an expert.
Maybe someone else here knows about WebWorks and maybe speak to that. Or, you could ask another meeting place. Maybe WebWorks has their own forums? Or you could try asking on TECHWR-L or HATT.
http://www.techwr-l.com/archives/
http://groups.Yahoo.com/group/Hatt/
See you soon... Rick

Useful and practical links
Wish to RoboHelp form/Bug report form
Begin to learn RoboHelp HTML 7, 8 or 9 in the day!
-
STUCK - indexing a list and with the index as a variable
Hello world. I imagine that this is not a difficult task, but I can't find any information on exactly what I need to accomplish.Let's say I have a table with fruits. The name of the fruitid and fruitname fields.I have query select * from fruit by fruitname. Then I take this data and create a list (or a table?) with the fruitnames.What I want to do is list the results with their place in the list or a table. Not their fruitid. For example:1 Apple
2 Orange
3 pearsWhere the 1,2,3 is the order of the list and not any recovered data form the query. I need to use the 1,2,3 as variables separately form the Apple, Orange, pear.I've been search in the online help, CFWACK and search for information about indexed lists is cheating on me. I was looking at listgetat but the results will be different each time and it just didn't seem like the solution ListGetAt returns the variable... for example:Apple AppleOrange OrangePEAR PEARAny thoughts? Any help in a new direction is welcome. I use CF7.01 on WinServer2003 and SQLServer2008.
Google "
". Find the cfml reference manual page and read it. Pay special attention to the variables are produced by cfquery.

Maybe you are looking for
-
change the order so "" is first followed by topic?
When you open the e-mail I want to see who of in the first column. Can't find how to do this.
-
Norton 360-all-in-one-security version 4
Hello I recently installed Norton 360 all in one security from a usb key, and he slowed down-my starting from 37 seconds to 50 seconds. All of my settings for this program are defined by default. Norton 360 v4 claims, it won't slow down your boot tim
-
brand new toshiba netbook keyboard does not work. just Commission online.
keyboard of net-book brand new Toshiba does not. just online diagnosis explain ok.
-
I can't unlock my account hotmail even after changing the password
E-mail address is removed from the privacy *. This account is the most I have He is blocked for some reason any and I can't unlock again I did some steps to change my password, but I get the error message, and I repeat the same steps for ever. but st
-
try to download the update of windows... error number: 0x8024400a...
try to download the update of windows... all I get is "the website has encountered a problem and cannot display the page you are trying to view" error number: 0x8024400a the... no idea on how to solve this problem?