place memory safe table
Hello.
I work with an array of "big", and I would like to know if I'm just doing.
I am given concatenation (SGL) on my program and with him, build a larger painting each iteration of the loop. I calculated that I need a table with about 200000 points. If I'm right, this isn't good at worked with a shift register, because if the table is larger each iteration Labview urechi new table every time. So, what I do is initialize an array with 200000 points NaN and after he fill it with a constant =. Its this right?
Thank you
Hey Navarro,
initialization of a table prior to the size correct (or necessary) is recommended.
Case 'period': delete this table later by replacing it with a blank matrix constant is nonsense.
Case 'save': adding new items to your table is a nonsense - why you initialize it before?
Use InitArray with ReplaceArrayElements!
Tags: NI Software
Similar Questions
-
How to load a pointer data memory in table
I'm trying to interface to a DLL used to manage a piece of hardware. The DLL is written in c. uses _stdcall and the Import Wizard has hooked up with success of most screws in a library; many of them work everything just as it is. I have also played with the knot of library function call and think that most of the time, I got the hang of it. I ran successfully for the odd Windows API call (e.g., MessageBox). However, I am a newcomer in Labview. My problem is related to a DLL function that requires a pointer to a block of memory, in which he then dealt with the material (in the form of table of UINTs) data. I want to display these data in Labview, through a table I guess. I think I found everything I need to do in terms of creating a table and hanging until the node of library function call with an input pointer.
I hope this would work IF the block of memory has been fully completed until the function has returned. HOWEVER, this is not how the DLL function. It creates a thread that exert to put data in the memory block after the function in the DLL. Extra features are available for face to discover if the data transfer is complete. I guess this is enough to refute the marshaling of data in Labview, unless there is some special commands for this purpose.
I thought maybe I should allocate the memory using the Windows API (LocalAlloc LPTR flagged so I get a pointer) and I wrote a little VI that allocates and releases the memory that seems to work. This way I can release memory when the transfer is complete. MY PROBLEM is, given the pointer to the block of memory, as returned by LocallAlloc, how can I get Labview to read the memory in an array of integers.
I am now a little stuck and would like to receive advice on one, how to convert the block of memory, or on a way to approach things btter.
TIA
SteveJM wrote:
So I have a working solution, which is basically the same idea as your suggestion, but uses the Windows API. I took the trouble to mention it, but when I looked more closely at 'MoveBlock', 'DSNewPtrt' etc, I realized that they are a static C library. This means that using them requires that you have a C development system and knowledge how to build DLLs on that. As it happens that causes me a problem, but it seemed like a hammer in this case because the routines you need are already in the kernel32.dll module. [Yes that makes specific Windows, but then you would need rebuild your dll for each operating system in any case].
This paragraph is completely inaccurate. These functions are integrated into the runtime LabVIEW, without which your LabVIEW code will not work. You have the guarantee that if you can run your LabVIEW code, or in the development environment or as a compiled application, these functions are available. No need for a C development system (if that were the case, don't you think someone would have mentioned in one of the many messages on this forum on the use of MoveBlock?).
SteveJM wrote:
It is true that you need to find a way to pass the pointer to the destination of reference. In other words, using a "handful" I guess. One of the difficulties is that the documentation for Labview is rather imprecise on what happening coming in and out of the function call. Unfortunately, the meaning of "Handle" is very dependent on context, so documentation should be much more detailed. If you select 'Manage' rather than "Pointer table" minimum size box disappears implying that Labview will take a pointer to a pointer to a format of Labview. It would then allow the size information in the allocation of the table and set the offset pointer approprately when passing a pointer to the function that would fill the memory. If the size of the table was large enough, it might be useful to tweak with this to avoid the copy useless (and allocation), but I don't have time now, unless I find the best literature which explicitly explains this gathering takes place for each option in the dialog box.
All the help you need is available. Set up a call library function node to pass by handle, close the configuration dialog box, right-click on the function call library node and choose Create .c file... You will get a draft of C with all structs defined for you, and you will see that the handful of LabVIEW table includes size information. There is no "triage." He is just passing pointers autour (and a few and Word-permutation of bytes due to problems of "endianness"). When you pass an array of pointer to array value, you get what you expect - LabVIEW dereferences the handle once and passes the pointer of table. It's exactly like a C function call. Nothing unusual occurs when the call is returned (with the exception, even once, "endianness" switch if necessary). That said, it's a bad idea to do what you want to do with a handle, because LabVIEW is allowed to move the table when he likes and has no way to know that some other functions still has this memory block to stay where he is.
-
Table of contents - how to not 'place' in the table of contents
whenever I click to open my document of OCD
-l' black needle text attached to it
-I click the ESC key and all other buttons control to try to eliminate it because I don't want to insert this text into my running already - for the most part of OCD.
n ' matter what - it ends by placing the text in the text in blue box.
-then I have to select it and delete it.
- but I am not convinced that I have
-because when I click on layers, I see 4 layers under the main layer.
Why this is happening please?
-How to I solve it?
-It should have been the first concern I've ever posted in discussing toc for a few days.
Thanks again.
Regina
dopfel wrote:
whenever I click to open my document of OCD
-l' black needle text attached to it
-I click the ESC key and all other buttons control to try to eliminate it because I don't want to insert this text into my running already - for the most part of OCD.
n ' matter what - it ends by placing the text in the text in blue box.
-then I have to select it and delete it.
- but I am not convinced that I have
-because when I click on layers, I see 4 layers under the main layer.
Why this is happening please?
-How to I solve it?
-It should have been the first concern I've ever posted in discussing toc for a few days.
Thanks again.
Regina
TOC instructions are confusing, I agree.
To avoid having a table of contents to fill your cursor when you already have a table of contents, place the text in text tool in the existing table of contents, and then choose layout > Update Table of contents.
HTH
Kind regards
Peter
_______________________
Peter gold
Know-how ProServices
-
Topics in several places in the table of contents
Hi all
I was wondering if it is possible to insert a topic more than once in the Table of contents? This is probably a strange request, but the problem occurred because I imported a manual written in Word, but the part of it contains information already in the RoboHelp project. I was wondering if I could erase the information duplicated in favor of a link to what was already there?
Thanks in advance for your suggestions.
See you soon,.
darkagnStone of right: the table of contents will be get synchronized with the trial (up and down) that he meets. However, you can use redirect pages to work around this problem.
1 create a new topic (and name it target_topic_name_redirect.htm as a visual cue for yourself). The title is the same in the topic title target (which is the name that will appear in the table of contents).
2 remove all text in the topic in WYSIWYG mode (leaving a blank page).
3 al ' TrueCode, add this line to the other META tags (in any place).
4 drag and drop the redirection page to where you want the TOC.
Note: A value of 0 (zero) is the duration time (none) and this topic will be displayed before the redirection to the topic target. If you prefer to make this available to the viewer redirection, you can increase it to, say, 8 or 10 and provide a text like "pick up this section of the"Configuration"section. Please wait a moment. »
Good luck
Leon -
Place the dimension table of DLL handle size
Hello
What is the correct way to handle the transition matrix dimensions, I found this document, outlining only the memory and situation examples that indicate the following two possibilities:
typedef struct {}
dimSizes [measures]
ArrDatatype data [1];
} Array * ArrayHdl;or this one:
typedef struct {}
dimSize1 of Int32;
.
.
.
.
dimSizeX of Int32;
ArrDatatype data [1];
} Array * ArrayHdl;Bublina wrote:
Hello
What is the correct way to handle the transition matrix dimensions, I found this document, outlining only the memory and situation examples that indicate the following two possibilities:
typedef struct {}
dimSizes [measures]
ArrDatatype data [1];
} Array * ArrayHdl;or this one:
typedef struct {}
dimSize1 of Int32;
.
.
.
.
dimSizeX of Int32;
ArrDatatype data [1];
} Array * ArrayHdl;They are equivalent, except that the int32 has been forgotten in the first!
And a comma in the declaration of type for both!
Personally, I tend to use the other, but never did more 2D pictures. For multi-D arrays, the first can be interesting if you get to make a loop on the dimensions of the matrix somehow.
-
Looking for a Script add lines in several places in a Table
Hi all!
I'm new to InDesign Scripting and I was hunting around trying to find something that would possibly work, and I can't quite find it. I hope someone can help!
I have a book that has tons of tables in it. They are all from the same table. 2 columns on 10 lines. Here's my dilemma:
My client wants to add new lines to these tables, specifically:
- A new line at the beginning of the table
- A line after the already established 3rd row
- 3Rows after the already established 9 line
Is it still possible with a script?
(I talk about "established" line, because I do not know if once the script adds the first rank at the top of the screen if this then that the numbers from the rest of the lines - and so on, as others are added.)
Any help would be appreciated.
Hello
What is a book for you? A single document or a real Indesign-book-file with multiple documents?
A single document:
var curDoc = app.activeDocument;
var allTables = curDoc.stories.everyItem ().tables.everyItem () .getElements ();
for (var t = 0; t)< alltables.length;="" t++="" )="">
var curTable = allTables [t];
var allRows = curTable.rows;
curTable.rows.add (LocationOptions.AFTER, allRows [8]);
curTable.rows.add (LocationOptions.AFTER, allRows [8]);
curTable.rows.add (LocationOptions.AFTER, allRows [8]);
curTable.rows.add (LocationOptions.AFTER, allRows [2]);
curTable.rows.add (LocationOptions.AT_BEGINNING);
}
Several documents in a book file:
This assumes that the file only one book is open!
app.scriptPreferences.userInteractionLevel = UserInteractionLevels.neverInteract;
var curBook = app.books [0];
var allDocuments = curBook.bookContents;
for (var n = 0; n)< alldocuments.length;="" n++="" )="">
var curDoc = app.open (file (.fullName allDocuments [n]));
var allTables = curDoc.stories.everyItem ().tables.everyItem () .getElements ();
for (var t = 0; t)< alltables.length;="" t++="" )="">
var curTable = allTables [t];
var allRows = curTable.rows;
curTable.rows.add (LocationOptions.AFTER, allRows [8]);
curTable.rows.add (LocationOptions.AFTER, allRows [8]);
curTable.rows.add (LocationOptions.AFTER, allRows [8]);
curTable.rows.add (LocationOptions.AFTER, allRows [2]);
curTable.rows.add (LocationOptions.AT_BEGINNING);
}
Optional
curDoc.save ();
curDoc.close ();
}
app.scriptPreferences.userInteractionLevel = UserInteractionLevels.interactWithAll;
-
Automatic text of lines-placement of the table from one line to the other
Hello
can someone help me with a problem of formatting with tables;
I would like to set up a table with multiple lines and the text automatically flow to the next line when you type once we're full... any help would be greatly appreciated
Hey there,
I just do the 1st rank.
During the ENTIRE event, I changed the Javascript and insert the following code:
xfa.host.setFocus(xfa.resolveNode("form1.#subform.Table1.Row3[1].Cell1"));Now it's working. You can do the rest.Tip: when coding, if you hold down Ctrl + Shift and click on any field, you get the name of the field instantly.Here is the file: https://acrobat.com/#d=P * lo * Yg113HNVP6pbXKo-ADiego -
I made a spreadsheet program AppleWorks 6 (Yes, I know... why not just use the chisel and stone tablet...), and I would like to move the text in an InDesign table. I can copy of AW6 and paste into IDCS3 and transfer content in a format delimited by tabs, what would be nice if I was sticking in a block of text and set the tabs.
I know that you can navigate between cells in a table with the tab key, but paste text with the existing tabs will not be circulated in the following cells the way I hope. If I paste or insert into the first cell of a table, it sets all the text in the first cell and oversets that does not fit. I checked the help files and found this:
Work with overset cells
You cannot flow overset text in another cell. Instead, change or resize the content or expand the cell or block of text in which the table appears.
Is there a trick I am missing, or is - not possible in ID? I tried to save the file AW6 as the spreadsheet Excel Mac 5 and Excel Mac 98, 2001 spreadsheet (the only two Excel Mac formats), and placing in ID, but the only thing that comes through is numbers (without other keys).
Thanks in advance.
If you get the text delimited by tabs, just highlight the building whole tab (less the last statement) and use the table > convert text to table.
Other that that, I don't know Appleworks, but if you can get your table in RTF, ID will import a RTF table like a real table.
Ken
-
Can I place tables in an anchored frame?
I want to place two adjacent tables in one of my framemaker documents. Should I use a framework anchored to this? If so, how is it possible to place two tables in an anchored frame? Is there another way to do this? Help, please!
Thank you!
A table can be placed in a block of text.
An anchored frame can contain blocks of text.
A graphic frame can also contain text blocks.
If you need tables to be able to move, i.e. If your steam content exchange, then placing two blocks of text in an anchored frame would be the way to go.
If you need the paintings on a specific page and never move, you can then use a graphic image that contains two blocks of text.
-
buffer allocation and minimizing memory allocation
Hello
I am tryint to minimize the buffer allocation and memory in general activity. The code will run 'headless' on a cRIO and our experience and that of the industry as a whole is to ellliminate or minimize any action of distribution and the dynamic memory deallocation.
In our case we treat unfortunately many string manipulations, thus eliminating all the alloc/dealloc memmory is significant (impossible?).
Which leaves me with the strategy of "minimize".
I did some investigation and VI of profiling and play with the structure "on the spot" to see if I can help things.
For example, I have a few places where I me transpoe a few 2D charts. . If I use the tool 'See the buffer allocations' attaced screenshot would indicate that I am not not to use the structure of the preliminary examination International, both for the operation of transposition of the table for the item index operations? As seems counter intuitive to me, I have a few basic missunderstanding either with the "show stamp" tool of the preliminary examination International, or both... The tool shows what a buffer is allocated in the IPE and will once again out of the International preliminary examination, and the 2D table converts has an allowance in and out, even within the IPE causing twice as many allowances as do not use REI.
As for indexing, using REI seems to result in 1.5 times more allowances (not to mention the fact that I have to wire the index numbers individually vs let LabVIEW auto-index of 0 on the no - IPE version).
The example illustrates string conversions (not good from the point of view mem alloc/dealloc because LabVIEW does not determine easily the length of the 'picture' of the chain), but I have other articles of the code who do a lot of the same type of stuff, but keeping digital throughout.
I would be grateful if someone could help me understand why REI seems to increase rather than decrease memory activity.
(PS > the 2D array is used in the 'incoming' orientation by the rest of the code, so build in data table to avoid the conversion does not seem useful either.)
QFang wrote:
-My reasoning (even if it was wrong) was to indicate to the compiler that "I do not have an extra copy of these tables, I'll just subscribe to certain values..." Because a fork in a thread is a fairly simple way to increase the chances of duplications of data, I thought that the function index REI, by nature to eliminate the need to split or fork, the wire of the array (there an in and an exit), I would avoid duplication of work or have a better chance to avoid duplication of work.
It is important to realize that buffer allocations do occur at the level of the nodes, not on the wires. Although it may seem to turn a thread makes a copy of the data, this is not the case. As the fork will result in incrementing a reference count. LabVIEW is copy-on-write - no copy made memory until the data is changed in fact, and even in this case, the copy is performed only if we need to keep the original. If you fork a table to several functions of Board index, there is always only one copy of the table. In addition, the LabVIEW compiler tries to plan operations to avoid copies, so if several branches read from a wire, but only it changes, the compiler tries to schedule the change operation to run after all the readings are made.
QFang wrote:
After looking at several more cases (as I write this post), I can't find any operation using a table that I do in my code that reduces blackheads by including a preliminary International examination... As such, I must STILL understand IPE properly, because my conclusion at the present time, is that haver you 'never' in them for use. Replace a subset of a table? no need to use them (in my code). The indexing of the elements? No problem. .
A preliminary International examination is useful to replace a subset of the table when you're operating on a subset of the original array. You remove the items that you want, make some calculations and then put back them in the same place in the table. If the new table subset comes from somewhere other than the original array, then the POI does not help. If the sides of entry and exit of International preliminary examination log between them, so there no advantage in PEI.
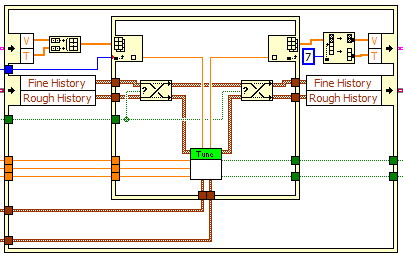
I am attaching a picture of code I wrote recently that uses the IPEs with buffer allocations indicated. You can see that there is only one game of allowances of buffer after the Split 1 table D. I could have worked around this but the way I wrote it seemed easier and the berries are small and is not time-critical code so there is no need of any optimization. These tables is always the same size, it should be able to reuse the same allowance with each iteration of the VI, rather than allocate new arrays.
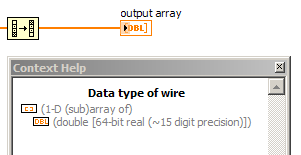
Another important point: pads can be reused. You might see a dot of distribution on a shift register, but that the shift register must be assigned only once, during the first call to the VI. Every following call to the VI reuses this very spot. Sometimes you do not see an allocation of buffer even if it happens effectively. Resizing a table might require copying the whole table to a new larger location, and even if LabVIEW must allocate more memory for it, you won't always a point of buffer allocation. I think it's because it is technically reassign an existing table instead of allocating a new, but it's always puzzled me a bit. On the subject of the paintings, there are also moments where you see a point to buffer allocation, but all that is allocated is a 'subfield' - a pointer to a specific part of an existing table, not a new copy of the data. For example 1 reverse D table can create a sub-table that points towards the end of the original with a 'stride' array-1, which means that it allows to browse the transom. Same thing with the subset of the table. You can see these subtables turning on context-sensitive help and by placing the cursor on a wire wearing one, as shown in this image.
Unfortunately, it isn't that you can do on the string allocations. Fortunately, I never saw that as a problem, and I've had systems to operate continuously for months who used ropes on limited hardware (Compact FieldPoint controllers) for two recordings on the disk and TCP communication. I recommend you move the string outside critical areas and separate loop operations. For example, I put my TCP communication in a separate loop that also analyses the incoming strings in specific data, which are then sent by the queue (or RT-FIFO) to urgent loops so that these loops only address data of fixed size. Same idea with logging - make all string conversions and way of handling in a separate loop.
-
Rename tables and columns in sql running that accessing these columns in the table.
Hello
Using oracle 11.2.0.3
We want to rename columns, tables and work just a sql scripts for this.
If sqls who have access to those running long tables/columns for example reports what is happening
Existing sql running, will work perfectly in that picked up sql before table/colum rename or will they crash if tables/columns renamed during them.
scripts wil take a few seconds to run maximum
Thank you
The only other activity that would go on select is against these tables/columns. No etl isnert/update/delete etc wil, which happened during the name change.
Only possible activities are report instructions srunning select.
Tried to run a long selection and rename that select while that was going on and got no error on the test system.
This is because certain statements does not place locks on tables or lines, so even if a session is reading data, another session can make some ddl (or dml) manipulation.
In this situation (with only selects, no other dml queries), renaming can be done, but the question remains, what the application code?
If it refers to old column names after name change operation, is no good.
-
Hello guys
I need to advise the guys
example: I have a table called "FS_DPK_Rank"
Here's the table looks like:

and the report will be like this:

where the amount of the balance will be SUM by product and TOP 2 is like TopN by CIF No. (overall TopN)
but there is condition: when the user choose Office then function TopN will adjust according to the offices.
I'm really confused how to solve this situation.really need suggestions, advises and solutions.with respectfully
Hello
I tried your script on my local machine and was able to realize your condition in a different way. Below is the set of data that I tried. I'll post here if I find another solution.

Final result

Monthly activity - SUM ('made activity'. "" activities "by"Time ". ("" Month ")
(Top 2) sum - SUM ((CASE WHEN RANG (« activité faits"." nombre d'activités» par «Time».))) ("" Month ")<3 then="" "activity="" facts"."#="" of="" activities"="" else="" 0="" end)="" by="">


In your case, replace "Time". "" Months "of the grouping column. Also in the example above I gave the rank directly. Replace it with a CASE statement according to your requirement. Also place the CIF No. in the analysis and then exclude this column in the tabular presentation.
Suppose you have model RPD in place for this table.
-
ADF Parent-child tables of rules
Hello
I use JDeveloper and ADF 12.1.3. Now, I have a set of related tables, and each of them have only a child table.
I have a jsf page master / detail for each child table. Inside it, I can insert a row in the parent table and several rows in the child table. Commit the button is clicked validate monkey for the booth tables. Link between the master (parent table) and retail (child table) is done via the partnership link and view for the user interface.
Now, here's the rule I would apply: I can't commit newly created at the table parent without at least a new inserted row in child table.
Because I have several parent-child tables in this case of use, I wanted to replace the EntityImpl class and add newly created to each parent table class, so I bussines logic in one place for this tables.
We will look and taste to the table of one of the parents (not overloaded class EntityImpl):
The Interior has generated parent EO class
@Override
{} public void beforeCommit (TransactionEvent transactionEvent)
TODO implement this method
If (! validateParentChildNumber()) {}
throw new local ("not allowed.");
}
super.beforeCommit (transactionEvent);
}
public boolean validateParentChildNumber() {}
If (getParentChild (). GetRowCount() > 0)
Returns true;
on the other
Returns false;
}
This works well. If I inserts a row in the parent table and one or more rows in the child table passes validation. But if I get a line inside the parent table and no line of children tables I'm not allowed message in my browser.
So here's where problem read. Once I'm getting now authorized message, no matter if I insert the new line of Herald, I cannot commit until what I restar my app. Why? Because now, I constantly have this message:
It's like I can't hire the existing parent row I inserted before the child missing line. Why is this happening? I should replace postChanges method and what to put in it?
Thx a lot
Yes, you should do it in all cases, but point of my post is - put this code in the method of beforeCommit() of the primary entity. Only you need to do in beforeCommit(), is to count the child related entities.
In your java master entity impl class, you will have the method which returns a RowIterator with associated children, entities, something like that
public getChildsEO() {} RowIterator
return (RowIterator)...;
}
then, just call this method in beforeCommit() and see if there is at least a child entity...
You have a point?
-
Tree of the University campus solutions 9.0 organization and Lookup Table question
People,
Hello. I'm creating 9.0 Solution Campus of a college. I confront the issue as below:
Implement AWAR > Foundation Table > academic Structure > academic organization
I implemented the academic organization of these data Table: in addition to academic departments, I also type in academic institutions and academic groups.
Then I create academic organization tree using the tree Manager. The tree is verified and valid a date of entry into force.
Then I put in place the 2 tables below:
Implemented AWAR > Foundation Table > academic Structure > program academic table
Implemented AWAR > Foundation Table > academic Structure > Table of different disciplines
Table of research of the academic organization developed in the 2 above table successfully. But when I put in place the other 2 tables below, search for academic organisation table does:
Implement > AWAR > Security > secure Administration of the student > user ID > Security academic organization
Curriculum management > Catalogue > Catalogue courses > tab offer
I understand that the 2 tables above are based on the tree of academic organizations and not on the academic organization Table. I see no error in the tree.
Because the search for academic organisation table can't happen in the tab 'Offers' course catalogue, the course cannot be saved.
My question is:
Any folk can help resolve the issue of the "academic organization lookup table cannot mount security academic organization and in the tab catalog of courses'? Or any suggestion on the tree of the academic organizations?
Thanks in advance.
Perform the following procedure:
Home > ACSS configuration > Security > secure Administration student > process > security update - Acad Orgs
After the execution of the process, check the lookup tables.
-
Add a line to the table programmatically
Hello
How do I add lines to the af: table of the java class? for that to editable object view exist on the JSPX page
Thank you
Chaya
You can see the following code to add a line at the end of the table programmatically:
public String cb1_action() {}
Add the code in the event here...
BindingContainer bc is BindingContext.getCurrent () .getCurrentBindingsEntry ();.
JUCtrlHierBinding hierBinding = (JUCtrlHierBinding) bc.get ("EmployeesView3");
DCIteratorBinding dciter = hierBinding.getDCIteratorBinding ();
NavigatableRowIterator nav = dciter.getNavigatableRowIterator ();
NewRow row = nav.createRow ();
newRow.setNewRowState (Row.STATUS_INITIALIZED);
Line lastRow = nav.last ();
int lastRowIndex = nav.getRangeIndexOf (lastRow);
nav.insertRowAtRangeIndex (lastRowIndex + 1, newRow);
dciter.setCurrentRowWithKey (newRow.getKey () .toStringFormat (true));
Returns a null value.
}
For the case where you must add a line in different places of the table, see the link below:
http://adfsonal.blogspot.in/2013/02/create-row-at-end-of-ADF-table.html






Maybe you are looking for
-
I went through the steps on 'cannot uninstall an add-on. " Uninstall in safe mode doesn't seem to work and when I try to uninstall it manually, I'm either wrong, or that the information does not apply to 4.1 because I don't see anything in the folder
-
I get the CO1033 error code in Outlook Express.
I got the CO133 error code in Outlook Express. I can receive emails, but I can't send them. I also about 25 000 emails I receive is no longer, so I can't delete them even more. What is the cure? original title: CO133 error code
-
Printing with larger font results
Hello My 3 year old has played with the printer and now the PrintOut prints incredibly large, almost as if it prints a quarter of a page at a time. It is a waste of paper (taking 14 pages to print a document from pages 3-4) and I can't read it becau
-
I lost my manual of my OfficeJet 6500 a more printer. How do I: (1) get a new manual (2) where is the location of the internal cartridge of the device (3) how to change the cartridge. ?
-
Cisco Voice Gateway with FXO of Telco, operation support for IP phone
Hi all A very quick question. Incoming calls via telephone in a voice gateway company ending on a Cisco 7941 G. Is it possible for a Cisco 7941 IP handsets or others to instagate actuation when the call is active, then causes the RTC line provide the