Problem adding values to a table with the state machine architecture
Hello
I currently have a problem that I have to build a program using state machine architecture and now I want to add a value in a table whenever you press a button, but I would like the table to add the new value, rather than deleting the last value. I can't seem to figure out how to make this work without using while loops and similar. It doesn't seem to work properly.
It is in the case of measurement.
The idea is I draw several lines then it records the length of the lines in a table and then I'll take one average this so I can convert pixels into real life SO units. But right now I can't seem to add the information in the table.
There is a little screw Sub, but I think that they should not be important for this question please!
What's the problem with just the table help build?
Tags: NI Software
Similar Questions
-
Adding values to a table in a State Machine
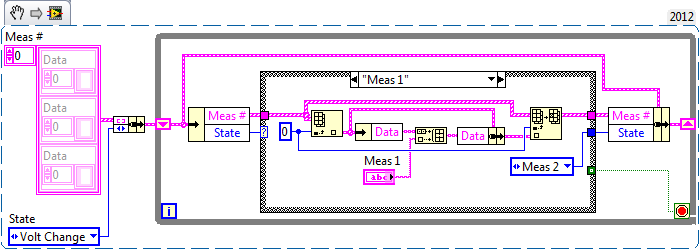
I'm building a VI that control several instruments and then takes data from these measures and applies them to the calculations appropriate to the materials science, such as the resistivity and Seebeck effect. I created a state machine that establishes a level of tension and takes three sets of three different measuring points, using a scanner Keithley 7001 and nanovoltmeter Keithley 2182. I'm now trying to find a way to take action and put them in three separate tables so that I can use them for analysis later. I prefer the tables because there are several screws that can help me to do what I have to do easily (for example, the VI means), but if something works better, I am open for entry.
My simple question: what is the best way to take measurements of the case 1 SOUL, SOUL 2 and 3 soul and store them in three separate tables?
I enclose my VI.
Edit: Just after the announcement, I decided that I will take the structures of sequence holding the sections measure and instead turn them into business within the state machine. I'll post a new VI of the present when I finished.
In this example, I used a structure called soul #. This structure allows each soul to have its own unique array.
The structure is an array of clusters. The cluster contains a string array named Data.
I hope this helps.
-
kindly tell how to use the unique value of a table with the index 0
kindly tell how to use the unique value of a table with the index 0
Hi
Yep, use Index Array as Gerd says. Also, using the context help (+ h) and looking through the array palette will help you get an understanding of what each VI does.
This is fundamental LabVIEW stuff, perhaps you'd be better spending some time going through the basics.
-CC
-
problem with the state machine
Hello! I have a VI to monitor a storage tank. I tried to do by creating a simple state machine that changes the value(on/off) of some faucets based on 2 conditions:
-When a certain temperature reaches a predetermined value AND its derivative is<0, the="" state="" must="" change="" from="" on="" to="">
-When some time passes, the State should change from off to on.
Unfortunately I can't get this working as it never changes state (by example, if I start with him always stay on 'on' and vice versa).
Could you please tell me what I'm doing wrong? I enclose the screenshots of the 2 States.
Thank you!
Sounds like your shift which could not not be wired properly.
-
update to column values (false) in a copy of the same table with the correct values
Database is 10gr 2 - had a situation last night where someone changed inadvertently values of column on a couple of hundred thousand records with an incorrect value first thing in the morning and never let me know later in the day. My undo retention was not large enough to create a copy of the table as it was 7 hours comes back with a "insert in table_2 select * from table_1 to timestamp...» "query, so I restored the backup previous nights to another machine and it picked up at 07:00 (just before the hour, he made the change), created a dblink since the production database and created a copy of the table of the restored database.
My first thought was to simply update the table of production with the correct values of the correct copy, using something like this:
Update mnt.workorders
Set approvalstat = (select b.approvalstat
mnt.workorders a, mnt.workorders_copy b
where a.workordersoi = b.workordersoi)
where exists (select *)
mnt.workorders a, mnt.workorders_copy b
where a.workordersoi = b.workordersoi)
It wasn't the exact syntax, but you get the idea, I wanted to put the incorrect values in x columns in the tables of production with the correct values of the copy of the table of the restored backup. Anyway, it was (or seem to) works, but I look at the process through OEM it was estimated 100 + hours with full table scans, so I killed him. I found myself just inserting (copy) the lines added to the production since the table copy by doing a select statement of the production table where < col_with_datestamp > is > = 07:00, truncate the table of production, then re insert the rows from now to correct the copy.
Do a post-mortem today, I replay the scenario on the copy that I restored, trying to figure out a cleaner, a quicker way to do it, if the need arise again. I went and randomly changed some values in a column number (called "comappstat") in a copy of the table of production, and then thought that I would try the following resets the values of the correct table:
Update (select a.comappstat, b.comappstat
mnt.workorders a, mnt.workorders_copy b
where a.workordersoi = b.workordersoi - this is a PK column
and a.comappstat! = b.comappstat)
Set b.comappstat = a.comappstat
Although I thought that the syntax is correct, I get an "ORA-00904: 'A'. '. ' COMAPPSTAT': invalid identifier ' to run this, I was trying to guess where the syntax was wrong here, then thought that perhaps having the subquery returns a single line would be cleaner and faster anyway, so I gave up on that and instead tried this:
Update mnt.workorders_copy
Set comappstat = (select distinct)
a.comappstat
mnt.workorders a, mnt.workorders_copy b
where a.workordersoi = b.workordersoi
and a.comappstat! = b.comappstat)
where a.comappstat! = b.comappstat
and a.workordersoi = b.workordersoi
The subquery executed on its own returns a single value 9, which is the correct value of the column in the table of the prod, and I want to replace the incorrect a '12' (I've updated the copy to change the value of the column comappstat to 12 everywhere where it was 9) However when I run the query again I get this error :
ERROR on line 8:
ORA-00904: "B". "" WORKORDERSOI ": invalid identifier
First of all, I don't see why the update statement does not work (it's probably obvious, but I'm not)
Secondly, it is the best approach for updating a column (or columns) that are incorrect, with the columns in the same table which are correct, or is there a better way?
I would sooner update the table rather than delete or truncate then re insert, as it was a trigger for insert/update I had to disable it on the notice re and truncate the table unusable a demand so I was re insert.
Thank youHello
First of all, after post 79, you need to know how to format your code.
Your last request reads as follows:
UPDATE mnt.workorders_copy SET comappstat = ( SELECT DISTINCT a.comappstat FROM mnt.workorders a , mnt.workorders_copy b WHERE a.workordersoi = b.workordersoi AND a.comappstat != b.comappstat ) WHERE a.comappstat != b.comappstat AND a.workordersoi = b.workordersoiThis will not work for several reasons:
The sub query allows you to define a and b and outside the breakets you can't refer to a or b.
There is no link between the mnt.workorders_copy and the the update and the request of void.If you do this you should have something like this:
UPDATE mnt.workorders A -- THIS IS THE TABLE YOU WANT TO UPDATE SET A.comappstat = ( SELECT B.comappstat FROM mnt.workorders_copy B -- THIS IS THE TABLE WITH THE CORRECT (OLD) VALUES WHERE a.workordersoi = b.workordersoi -- THIS MUST BE THE KEY AND a.comappstat != b.comappstat ) WHERE EXISTS ( SELECT B.comappstat FROM mnt.workorders_copy B WHERE a.workordersoi = b.workordersoi -- THIS MUST BE THE KEY AND a.comappstat != b.comappstat )Speed is not so good that you run the query to sub for each row in mnt.workorders
Note it is condition in where. You need other wise, you will update the unchanged to null values.I wouold do it like this:
UPDATE ( SELECT A.workordersoi ,A.comappstat ,B.comappstat comappstat_OLD FROM mnt.workorders A -- THIS IS THE TABLE YOU WANT TO UPDATE ,mnt.workorders_copy B -- THIS IS THE TABLE WITH THE CORRECT (OLD) VALUES WHERE a.workordersoi = b.workordersoi -- THIS MUST BE THE KEY AND a.comappstat != b.comappstat ) C SET C.comappstat = comappstat_OLD ;This way you can test the subquery first and know exectly what will be updated.
This was not a sub query that is executed for each line preformance should be better.Kind regards
Peter
-
How the values to insert into the table with the command insertion
Dear all
can someone tell me how the values to insert into the table with the command insert, I want to say I always use command insert behind my forms on what shutter release button press the button of my save, but today I had a form of 6i, where controls (textbox, combo, etc.) are delineated with directly the table with I guess than the Properties Windows , I created 3 columns in tand 3 text on forms fields, now kindly tell me how to do this fields to fill and do not insert command, I mean directly defined with table column
Please help me its urgentHello
If the block is based on your database table, just committed the shape, then changes will be applied to the database.
François
-
Table with the Kindle and generated content in e - pubs design problems
I encountered a strange problem with e-pub files exported from 5.5 design. It's only a problem with the Kindle, but that in itself is a pretty big problem. This has to do with the way In Design creates tables of contents. As you know, the "Table of contents" function in In Design is what generates the NCX or navigation device in your e-pub. Our books, we also create a linked table of contents in the text of the book. Below is a string of code generated by In Design that shows a typical chapter opening header that is included in the NCX and also back to the table of contents links in the text. The first (toc_marker-10) id is automatically generated by the 'Table of contents' function and corresponds to the id used by the NCX. The second id (Morella) has been created by me using an anchor point and assigning a "destination of the hyperlink" which can bind an element in my table in the text of the content. Then this piece of text is a hypertext link (via as HREF) return to the table of contents page. As you can see, In Design puts the second id towards the end of the code and after the HREF that links to my table of contents page. This works very well on all the reading devices except the Kindle, which seems to become confused by the order of the elements in the code. Amazon said that because this second id comes after the HREF, the hyperlink does not appear on this text (Morella) and the connection breaks. The way around this is simple: just move the second id < an id = "Morella" / > while it comes immediately before the href tag and everything works. But that means getting into the e-pub afterwards and put away all instances of the problem. In addition, there is no consistency in order that design attributes to the elements in the present code. In some cases where the links have been created in exactly the same way, the second id appears before the HREF and the link works fine. It's just a bug or did someone knows if In Design actually uses logic to decide the order of the items below?
< h4 id = "toc_marker-10" class = "chapternumber" > < a href = "Poe_Short_Stories - 2.html #CONTENTS" > < an id = "Morella" / > Morella < /a > < / h4 >
It really doesn't seem like a problem of Kindle. InDesign creates an EPUB file, not a Mobi file. It is designed to create an EPUB that will pass validation.
Creating the EPUB MOBI file is a separate issue and not something that InDesign must concern itself with.
At this stage of development of eBook (early on), it is quite well provided you will need script or manually change some CSS and XHTML to adjust the vagaries of different devices.
-
Good afternoon
I have a problem when I create an asynceventlistener with the terms GENERATED ALWAYS AS IDENTITY and GENERATED BY DEFAULT AS IDENTITY by creating asynceventlistener table does not respect the creation parameters. I have the following example:-asynceventlistenercreate asynceventlistener referrallistener(listenerclass "com.vmware.sqlfire.callbacks.DBSynchronizer".InitParams"' com.mysql.jdbc.Driver, jdbc:mysql://localhost:3306 / sqlfdb, user, password"True ENABLEBATCHCONFLATIONBATCHSIZE 100000BATCHTIMEINTERVAL 60000True ENABLEPERSISTENCE)groups of servers (dbsync);-Start asynceventlistenercall sys.start_async_event_listener ('REFERRALLISTENER');-create table in sqlfirecreate the table sqlftest(id int not null not ALWAYS AS IDENTITY GENERATED,name varchar (10),PRIMARY KEY (id))asynceventlistener (referrallistener);-create table in mysqlcreate the table sqlftest(id int not null AUTO_INCREMENT, name varchar (10),)PRIMARY KEY ('id')) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;When I insert in sqlfire this replica on Mysql database but is then immediately, without worrying about the BATCHSIZE or BATCHTIMEINTERVAL which is 60 seconds.Thanks for the support.GuillermoHi Guillermo,.
This is the version that fixes your issue. We added a system property - Dsqlfire.enable - bulk-dml-batch
It is disabled by default. If enabled(-Dsqlfire.enable-bulk-dml-batching=true) it will be lot in bulk (not pk) LMD and send commands to DBSynchronizer.Name: SQLFire103_39386.zip
Size: 27,61 MB
Expires: January 12, 2013
Download: https://ftpsite.vmware.com:443 / download? domain = FTPSite & id = 12f220841bb632e22f669d5835265b46Yogesh-
-
Gears - error when you try to insert values into a table with multiple columns
Hello
I started playing with the gears and SQlLite today and I get an error when I try to insert values into a table with multiple columns.
I have:
var db = google.gears.factory.create('beta.database'); db.open('developerSet'); db.execute('create table if not exists Developers (DeveloperName text, DeveloperAge int)'); var devName = "Davy" var devAge = 32; try { db.execute('insert into Developers values (?, ?)', [devName, devAge]); alert('success'); } catch (e) { alert(e); }I get the error:
net.rim.device.api.database.DatabaseException; insert into developers values (?,?): SQL logic error or missing database.
I use this reference: http://code.google.com/apis/gears/api_database.html
Everything works if I have only one field as:
var db = google.gears.factory.create('beta.database'); db.open('developerSet'); db.execute('create table if not exists Developers (DeveloperName text)'); var devName = "Davy" var devAge = 32; try { db.execute('insert into Developers values (?)', [devName]); alert('success'); } catch (e) { alert(e); }I use the plug-in Visual Studio 2.0 for 2008 that are running Windows XP SP and Simulator 2.13.0.56
Thank you
Davy
Yes, a SQLite database will persist between battery pulls. The database is registered either to internal MEM or removable media (not the device memory), depending on which is available on your device.
In general, its not considered a best practice to remove your table as soon as it is empty and re - create it again when you want to add data. This adds extra overhead fresh for the final, delete and insert first for a given table. Instead, define and finalize your drawing before you create your table. Once created, review the static schema.
That being said, for development purposes, it may be easier to provide an easy way to drop your tables while you develop your schema.
See you soon,.
Adam
-
Hi Please help me how to use cascade, if I don't have only one table with the customer name and the name of the product in the ADF... I use Jdeveloper 11.1.
For the client, I used customer VO with client list to fill but to populate the product that I use bind variable PrODUCT_NAME select distinct from TABLE where client_name =: bindCustomer
so first of all, I need to set the variable of liaison on behalf of the selected customer.
Can you please tell me how to set this variable binding in this case.
After you set the LOV to your product attribute, correspondting VO in the LOV will appear under view accessors.
Change the accessor of the view, you will see the variable binding. Set its value to the customer field of the parent object.
Visit this link: https://www.youtube.com/watch?v=nXwL2_RP7AQ
Kind regards
Elias.
-
How to export data to excel that has 2 tables with the same number of columns and the column names?
Hi everyone, yet once landed upward with a problem.
After trying many things to myself, finally decided to post here...
I created a form in form builder 6i in which clicking on a button, the data gets exported to the excel sheet.
It works very well with a single table. The problem now is that I cannot do the same with 2 tables.
Because the tables have the same number of columns and the columns names.
Here are the 2 tables with column names:
Table-1 (MONTHLY_PART_1) Table-2 (MONTHLY_PART_2) SL_NO SL_NO MODEL MODEL END_DATE END_DATE U-1 U-1 U-2 U-2 U-4 U-4 .......... ........ .......... ........ U-20 U-20 U-25 U-25 Given that the tables have the same column names, I get the following error :
402 error at line 103, column 4
required aliases in the SELECT list of the slider to avoid duplicate column names.
So how to export data to excel that has 2 tables with the same number of columns and the column names?
Should I paste the code? Should I publish this query in 'SQL and PL/SQL ' Forum?
Help me with this please.
Thank you.
Wait a second... is this a kind of House of partitioning? Shouldn't it is a union of two tables instead a join?
see you soon
-
How to compare the length of the data to a staging table with the definition of the base table
Hello
I have two tables: staging of the table and the base table.
I get flatfiles data in the staging of the table, depending on the structure of the requirement of staging of the table and the base table (length of each column in the staging table is 25% more data dump without errors) are different for ex: If we have the city long varchar 40 column in table staging there 25 in the base table. Once data are discharged into the intermediate table that I want to compare the actual length of the data for each column in the staging table with the database table definition (data_length for each column of all_tab_columns) and if no column is different length that I need to update the corresponding line in the intermediate table which also has an indicator called err_length.
so for that I use the cursor c1 is select length (a.id), length (b.SID) of staging_table;
c2 (name varchar2) cursor is select data_length all_tab_columns where table_name = 'BASE_TABLE' and column_name = name;
But we get atonce data in the first query while the second slider, I need to get for each column and then compare with the first?
Can someone tell me how to get the desired results?
Thank you
Manoi.Hey, Marco.
Of course, you can set src.err_length in the USING clause (where you can reference all_tab_columns) and use this value in the SET clause.
It is:MERGE INTO staging_table dst USING ( WITH got_lengths AS ( SELECT MAX (CASE WHEN column_name = 'ENAME' THEN data_length END) AS ename_len , MAX (CASE WHEN column_name = 'JOB' THEN data_length END) AS job_len FROM all_tab_columns WHERE owner = 'SCOTT' AND table_name = 'EMP' ) SELECT s.ename , s.job , CASE WHEN LENGTH (s.ename) > l.ename_len THEN 'ENAME ' END || CASE WHEN LENGTH (s.job) > l.job_len THEN 'JOB ' END AS err_length FROM staging_table s JOIN got_lengths l ON LENGTH (s.ename) > l.ename_len OR LENGTH (s.job) > l.job_len ) src ON (src.ename = dst.ename) WHEN MATCHED THEN UPDATE SET dst.err_length = src.err_length ;As you can see, you have to hardcode the names of the columns common to several places. I swam () to simplify that, but I found an interesting (at least for me) alternative grouping function involving the STRAGG user_defined.
As you can see, only the subquery USING is changed.MERGE INTO staging_table dst USING ( SELECT s.ename , s.job , STRAGG (l.column_name) AS err_length FROM staging_table s JOIN all_tab_columns l ON l.data_length < LENGTH ( CASE l.column_name WHEN 'ENAME' THEN ename WHEN 'JOB' THEN job END ) WHERE l.owner = 'SCOTT' AND l.table_name = 'EMP' AND l.data_type = 'VARCHAR2' GROUP BY s.ename , s.job ) src ON (src.ename = dst.ename) WHEN MATCHED THEN UPDATE SET dst.err_length = src.err_length ;Instead of the user-defined STRAGG (that you can copy from AskTom), you can also use the undocumented, or from Oracle 11.2, WM_CONCAT LISTAGG built-in function.
-
It is possible to have two tables with the same name in Oracle!
Oracle Version: 10 gr 2
MS Access 2007, I had to use the 'Export' by which I copy a table (and its data) to an Oracle schema via an ODBC connection. Later, I realized that, during the copy of tables with a mix of lower and upper case names, the table does not copied (exported). But MS Access will give you the message that table obtained export successfully.
MS-Access mess around Oracle data dictionary.
When you issue
You will see the names of the tables. But when you try to DESCRIBE or SELECT this table, you willSQL>select * from tab; TNAME TABTYPE CLUSTERID ------------------------------ ------- ---------- AMStates TABLE Version TABLE
You can even create another table with the same name in the schemaSQL>desc Version ERROR: ORA-04043: object Version does not exist
Why this is happening and how can I bring these items 'non-existent '?SQL>create table VERSION (X NUMBER); Table created.Hello
Use
SQL > desc 'Version '.
Or
SQL > select * from 'Version '.
Or
SQL > drop table 'Version '.
To overcome the problems of mixed-case.
-
Windows Vista can not launch problem of checkers: try to re-launch your game. If the problem persists, it may be network with the server problems or a problem with the configuration of your firewall. Please check your firewall settings by visiting the Open Ports FAQ.
Original title: launch of the problems of checkers:
Hello
If you have not yet tried to disable the antivirus/firewall software, then try the following steps to disable them.
Disable the anti-virus software: http://windows.microsoft.com/en-US/windows-vista/Disable-antivirus-software
Enable or disable Windows Firewall: http://windows.microsoft.com/en-US/windows-vista/Turn-Windows-Firewall-on-or-off
IMPORTANT: Antivirus software can help protect your computer against viruses and other security threats. In most cases, you should not disable your antivirus software. If you do not disable temporarily to install other software, you must reactivate as soon as you are finished. If you are connected to the Internet or a network during the time that your antivirus software is disabled, your computer is vulnerable to attacks
-
Original title: cannot backup Windows 7 system.
When I try to back up the system or create the image of the system I get the following message, the error was detected in the Volumn Service VSS (Shadow Copy) the problem occurred while trying to connect with the VSS writers. Verify that the event system Service and the VSS service are running and look for errors related to event logs. (0 x 80042318).
Hi bernardolahoustino,
Please keep us informed. Please let us know the State of the question, so that we can help you further.
Maybe you are looking for
-
Can I use iTunes gift cards to buy an app?
Can I use iTunes gift cards to buy an app?
-
Equium L20 does support a USB 2.0?
I am about to buy an external hard drive and the seller States works with all laptops but that you need USB V2.0 when I check the specifications of my laptop it says USB 2.0. is it the same thing? Post edited by: mariedann
-
All-in-One Photosmart 3210 error messages
When it works the 3210 did a wonderful job. I am running Vista Home Premium on an HP Pavilion a6234x Desktop PC, automatic updates from Microsoft. Starting and restarting, I consistenly get an error as follows: "worker HPProduct - the component you a
-
How do you make thermocouples to read below-200 c? LabVIEW doesn't let me.
I use the SCXI1102 thermocouple with the K type thermocouples. This is an M series data acquisition card in a PXI chassis. My problem is that I want to measure temperatures up to 35 K and LabVIEW won't let me. When I try to set the value min minus
-
Media Player 11 payne repeatedly list lists the name of the file instead of file name
Hello: I am using media player 11 to play .wav files. The payne list shows only the name of the folder repeatedly (album name) instead of the list the file names (song). How can I configure this to display file names?