Question of indexation UCM
Hello
I'm relatively new to the AAU so please excuse my question if it's very basic.
I want to rebuild the full index on the content. The problem is that I have 10% (approximately) 20 GB free out available 200 GB) of free space on the disk where content is stored and I fear that runs the full it will cause disk space be fully occupied until it completes successfully. I know that the index is stored in the tables in the DB (DB has enough space), but I wonder if she will write all the files in the folder content and reduce the free space by a drawing of lots, or even completely occupy?
Also, can you please tell me how long would take indexing after as I start running it (approximately)? (I have about 40 GB of content)
Thanks in advance for your answer.
I'd be a little concerned about the amount of available disk space, depending on your current configuration.
- If you are currently storing content in folders on the file system, it can not also be an issue from a perspective of indexing.
- If you store content in the database however, content server will need to out the content on the file system in order to perform content indexing. Having to write content on the disc is where you might have problems.
How long will it take? There is no formula regarding how long x amount of content will not. It only depends on the types of files themselves and the complexity of the content in the documents being indexed. 40 GB of JPEG files will end very quickly, because these files have no text to index. 40 GB of several sheets workbooks Excel with thousands of lines and columns of numeric data may take some time. The system must extract the textual components of each file, write the text that it finds in a txt by each content element file, and then the content of this txt file is passed to the search index.
Tags: Fusion Middleware
Similar Questions
-
question about indexing settings
Hello
I was looking through the release of Essbase and here's my question about the index file I deleted a populous cube and I see everthing reset to 0 except index Cache current value that remained the same when the cube is populated.
Any help or a response in this regard is greately appericiated.
Thank youNo, it should not change to zero. As I said, the key cache takes the memory when the application starts and keeps it until the application is stopped even if there are no data in the cube. HE maintains that the memory for when there no are data. I've seen of many inplementations where the client has set the cache to be really fat git thought would only use what it takes, but instead, the amout set gets consumed. So, I'm called asking how they can possibly be out of memory on their server. Moral of the story, do no bigger that it must really be or you will expect a lot of the key cache memory
-
Technical question of indexation of Spotlight search
I wonder about how the spotlight indexing process occurs and if maybe it's the cause of the problems of start and stop and the kernel panics.
When live, I got used to print some articles in PDF format for later reading offline - or when I get the chance. In November I started going through many articles and deleting or filing - and in the case of their deposit - I was deleting pages that were released just junk, so I did that article.
If the PDF files have been indexed for content when I moved to different folders - or altered and saved - and if all goes well index deleted when I deleted them - would it have caused a problem when I stop this process.
I got a stop where the system remained in market (light on mac pro 2008) but not asleep - then force a shutdown. I had a tension where the projector showed that indexing - for about 10 seconds - without report.
The console logs showed messages that a process completed- and kernel panic with no ID is.
So is indexing made by MDS and MDS worker - and how will I know when indexing is complete prior to the stoppage.
I changed the spotlight preferences to search only files - removed all the rest - but will they even indexed.
And why - if the work must be done before the power off - Apple is not only to display a message on the screen!
As the first users think seem to complain after an update - how to slow their macs (really busy busy) are - if it's just a bad thing worse.
I'm on Snow Leopard - on Mac Pro 2008
Additional information - I always stop after use as no point in leaving a system on when only used a few hours a day.
My DirectoryService.error.log shows that inadequate completely new closures in 2008.
Standard use - after - as the power outlet Strip which is controlled by a wall switch - I cut that.
Something was still running and stop feeding ended this work - only that he might be the index - which I really do not use for detail on a PDF unless I want to scan something while it is open.
I am now waiting the minute 1 stop & look at the light of itty bitty on the front of the tower to use it is over.
My drive is less than 50% of the full - last cleaning was to make sure that it stays like that.
-
Hello world
I know that I can use a table to reshape to convert a 2D 1 d.
But I'm curious of know how is it when I wire a 2D in an array of index table, and there is no constant for the index entries, the result comes out as a 1 d array?
How it works in this case? could someone please explain that to me?
Index functions Array always returns the element or subarray n-dimension table to index. By default, if you do not connect the index , the first input terminals line sub-table index 0, the second subarray index 1st row and so on.
-
I created an index, but after reviewing, I noticed that some entries appear under other entries. For example, I have an entry called new account prior... watch well with page numbers except that there are two numbers to additional pages should are associated with a Non-US citizen index tag. For the life of me I can't get no U.S. citizen is present on the subject of own line with the associated page numbers. I located with ALT + CTRL and remove the tag... started... even tried no US Cititzen without the hyphen. I had it on a couple of entries. Markers look good in the doc, but then they show without their category of marker and just applied to a completely separate topic pages. So, any advice would be appreciated at this stage!
You can download it from the Adobe site or you can do help > updates from in FM personally I always liked doing downloads separately that archives the and if necessary I can reapply them later.
Also be sure to check the updates in your configuration of Acrobat too, there have been significant updates in the last month, for security issues.
-
UCM is able to handle more documents of 700TB?
Hi all
We have more than 700 documents of TB who want to gather in one place. We are looking for a solution. One of them is Oracle UCM. The question is can UCM process this amount of documents or not? If Yes, is good enough for 30000 simultaneous users of performance?
Thank you
They may need to see only one by one, but unless you have a direct link to the document at hand, there will be a certain type of research. With 8 billion documents, you must consider a few factors.
- You "got to do a deep analysis of how such research is usually performed by the users. For example, a document is always checked on three meta elements (say 'title', 'Department' and 'country'). Listen to common queries.
- You will need the indexes on these fields and unlikely combination on these areas.
- You will not be able to fields of substring search (if you really want a performance system), and all documents must have values in all fields search keys (i.e. not null values). Cannot empty searches (like 'show me everything I see' research). You may need to hire certain types of results max and certainly clear the function which returns the number that is placed on the top of the search page - I forgot the setting. This is important because the search is actually performed twice: once to get the number, the second actually return results. The first query might be enough to stop everything and if the meter is slow to come back, guess what is your username? They click on the button search again, run this query once again dear! I've seen this too many times... it happens.
- According to the number of new elements being inserted, the index database may be rebuilt frequently, even daily.
-
Hi Experts,
My client 2 issues that I am not clear about the answer, could you give me a tip?
This client uses ECM11.1.1.1.5 with text oracle as full text index engine, the questions are:
1. is it possible to build indexes full text at a later rather than building when the consignment of a doc? for example, the user checkin a doc in ecm, at that time, ecm does not full text index, in the night, we use the api / script to build the full text for new documents created.
2. it takes 15 s consignment to a word file of 50 m in ecm, with or without construction of full text index, we use MaxIndexableFileSize in config.cfg to the control's text index full is built for the 50 M word file, the client wonder with a bandwidth of 200 K between the server of the University Complutense of Madrid and ucm db why there is no latency performance for the construction of the full text, by a common index, ucm will send the text in doc ucm DB file to generate full text indexes, in this file of Word of 50 m, we appear 9 of 10 text pages, admittedly, most of the content is repeatable.
Best regards
LANA story behind this request is the customer has a slow network between the server of the University Complutense of Madrid and db of the Complutense University of Madrid, it is 200Kbit/s, customer wants to improve the speed of creation of doc, so asked me to do a test of performance for the delayed construction of fulltext index.
If you know what the problem is, it would be more logical to put the efforts to solve the cause, rather than a clumsy workaround solution.
Your other questions, read the Metalink Note 865713.1 as he explains how database. FULL-text indexing jobs. "Offshoring" indexing to ITS could solve the problem, but I just don't believe it is - also note that even if you find a workaround for "creation of doc" solution, you will have to deal with the problem, every time that you press on the database, so sooner or later it will appear somewhere else.
-
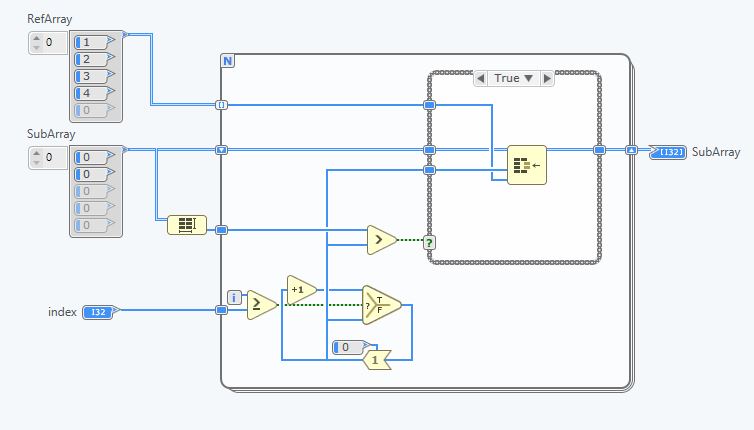
changing/variable index of an array on FPGA
Hi all
I have a question about indexing an array on FPGA. Concretely, I have a constant size 1 M table and want pieces of index of size N of it. Unfortunately, when you try to compile I get the error message: the tables with variable sizes running are not supported. Is there a work-around nice for who?
See you soon
Hello
Well, I don't have first play dynamicaly with the Index of the Array of subset function entry.
This is not supported in a SCTL, so that the planned behavior.
There are several workaround solutions to do this, depending on how you design your design.
1 point by Point approach (as usually made it in FPGAs), using a function table of Index on the RefArray and with the use of counters to keep track of the Index, and evantualy count each sample collected.
This means that every cycle, you have an example that needs to be addressed, you don't work with a tableau more out.
2. same as 1, but using a BRAM I32 element as an interface in the screenshot gave you, I understand that your table with a value of several KBs, which can be a problem in the long term for your design.
3. using a FPGA IP, you could build something like this:
You can use a loop in the context IP FPGA that auto-index the RefArray, to pick up the samples you want, in your sub-table.
This means that you can always work with a table in the output, but the cost will be that you can not leave the subarray in each clock cycle. (use the estimate feature to see the actual flow rate)
4. you can explicitly implement a big MUX, using a box structure. In each case, you provide the desired sub-table.
This is indeed what LV FPGA would do if you where using a standard while loop. Yes, ugly, but no way around it if you want a sub-table, at every clock cycle.
5. the BRAM/DRAM can work with an interface of up to 1024 bits, 32x32bits elements for ex, then you might have used up to 32 items in you case (using the loose I32)
So! In your case, I recommend that you use option 5 if possible:
-Think of BRAMs, your table is starting to get impatient on slices
-Use up to an interface of 1 024 bits on BRAM for a sub-table, do you really need more of 1024 bits a sub-table?
If you don't see how to go from there, I would need more information on what you try to do + all necessary and upstream of the stored data and their data type
Good bye
-
How to rebuild a spatial index partition that is marked 'INPROGRS '.
I'm on 12.1.0.1 Enterprise Edition.
I have a very large table of sdo_geometry objects that I divided it into several partitions. I have create a spatial index on this table as UNUSABLE and then rebuild the partitions across a few different sessions.
In total, the construction of index takes a few days. Last week during the construction of the index, the database crashed completely. This left me with most of the scores with a USER_IND_PARTITIONS. USABLE STATUS, some with UNUSABLE and a couple with INPROGRS.
I can rebuild the UNUSABLE partitions as usual, but when I try to build a INPROGRS partition I get:
ERROR at line 1: ORA-29952: cannot issue DDL on a domain index partition marked as LOADING
The mistake is understandable, given that the index partition was INPROGRS when the database crashed. The question is how to recover from it. The doco says:
Expect that the index partition operation complete question GOLD FORCE INDEX DROP to remove question OR index an ALTER TABLE DROP PARTITION to delete the partition.
None of these options are good for me. I don't want to let down the entire index as most of it is built. It doesn't seem to be an option to recover a partition of index construction which is blocked at INPROGRS.
Support Doc ID 557600.1 addresses this issue says in the context of the Oracle text index. Sa dit :
Sometimes, if CREATE INDEX or ALTER INDEX fails, an index can be left with the status of LOADING or INPROGRS and let the context index in an unusable state.
Any attempt to retrieve using SUMMARY INDEX is blocked. The only recourse is to drop and re-create the index.
In this case, use CTX_ADM. MARK_FAILED to force LOADING failure index status so that you can retrieve the index with the INDEX of CURRICULUM VITAE.
If the suggestion is to use CTX_ADM. MARK_FAILED ( http://docs.oracle.com/database/121/CCREF/cadmpkg.htm#CCREF0500 ).
There is a similar option for spatial indexes?
Thank you
John
Hi John,.
Have you tried mdsys.reset_inprog_index (owner IN varchar2, varchar2 IN index_name)?
This procedure will erase INPROGRS and to FAIL if index or index partition is INPROGRS.
Thank you
Ying
-
Hi all
I create a procedure for my goal of learning and uses the HR schema. Now the problem is that when I run my procedure, then I get the error mentioned topic. I know there is a problem with the code "l_salary (l_salary.count + 1): = l_employee_id (indx) .salary;' but unable to solve." Help you in this regard will be appreciated. Thank you
My procedure
create or replace
PROCEDURE increase_salary
(dept_id_in IN VARCHAR2)
AS
TYPE emp_id_t IS TABLE OF employees % rowtype;
TYPE emp_sal_t IS TABLE OF THE employees.salary%TYPE;
l_employee_id emp_id_t: = emp_id_t ();
l_salary emp_sal_t: = emp_sal_t ();
BEGIN
SELECT *.
LOOSE COLLECTION l_employee_id-, l_salary
Employees
WHERE department_id = dept_id_in;
FOR indx IN 1.l_employee_id.count
loop
dbms_output.put_line ('EMPLOYEE_ID =' | l_employee_id (indx) .employee_id |) "salary =' | l_employee_id (indx) .salary);
IF l_employee_id (indx) .salary > 6000 THEN
l_salary (l_salary.count + 1): = l_employee_id (indx) .salary; - problem is here, I think
dbms_output.put_line (' salary ='| l_salary (indx));
END IF;
END loop;
END;
Concerning
Shu
979596 wrote:
l_salary (l_salary.count + 1): = l_employee_id (indx) .salary; - problem is here, I think
dbms_output.put_line (' salary ='| l_salary (indx));
First issue: you need extend the collection first. Change:
l_salary (l_salary.count + 1): = l_employee_id (indx) .salary;
TO
l_salary.extend;
l_salary (l_salary.count): = l_employee_id (indx) .salary;
Second question: bad index. Change:
dbms_output.put_line (' salary ='| l_salary (indx));
TO:
dbms_output.put_line (' salary ='| l_salary (l_salary.) Count));
SY.
-
Simple index (the display of the data (all columns) in an index of Toad)
Hi all
I am training on sql tuning and over the years I've seen ppl creating many clues, today I'm trying to learn the different types of index and just curious to see physical data in an index, but I'm not able to do a toad, I know if I have a few def index as :
create index employees_employee_id on employees (employee_id)
My clue would have two columns of information: first rowid and employee_ids in a sorted order right? <-if my understanding is not correct could any1 please correct me here.
PS: The major problem is to see the physical in Toad index data, please help me with this.
Thank you very much
Rahul
There is no SELECT query that could be written on the index. But a select on a TABLE can be a way such that Oracle only scans the index and give you the information
Here is an example.
SQL > create table t
() 2
3 no integer
4 );Table created.
SQL > create index t_idx on t (no);
The index is created.
SQL > insert into t
2. Select level
3 from dual connect by level<=>10 rows created.
SQL > commit;
Validation complete.
SQL > alter table t modify is not null;
Modified table.
SQL > exec dbms_stats.gather_table_stats (user, 't', cascade-online true)
PL/SQL procedure successfully completed.
SQL > select rowid, not according to t;
ROWID NO.
------------------ ----------
AAFrZaABMAAAiKKAAA 1
AAFrZaABMAAAiKKAAB 2
AAFrZaABMAAAiKKAAC 3
AAFrZaABMAAAiKKAAD 4
AAFrZaABMAAAiKKAAE 5
AAFrZaABMAAAiKKAAF 6
AAFrZaABMAAAiKKAAG 7
AAFrZaABMAAAiKKAAH 8
AAFrZaABMAAAiKKAAI 9
AAFrZaABMAAAiKKAAJ 1010 selected lines.
SQL > select * from table (dbms_xplan.display_cursor);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------
SQL_ID, 35mwb1b3fpfrh, number of children 0
-------------------------------------
Select the rowid, not of tHash value of plan: 3354442786
--------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 1 (100) | |
| 1. INDEX SCAN FULL | T_IDX | 10. 30. 1 (0) | 00:00:01 |
--------------------------------------------------------------------------13 selected lines.
Actually in this case, I questioned the INDEX
-
Oracle UCM how to ignore the Login page.
Hi all
I have the following questions regarding the UCM login without SSO solution screen to jump.
1. is it possible to switch the connection of the Complutense University of Madrid passing the username and password in the url? If yes how.
2-stellent 7.5.1 we can add plugin for IdcAuthPlugin Web server, it will give the ability to customize authentication.
Is it possible in UCM11g as well?
3 do we need to create our own authentication provider in weblogic to skip the login screen?
Thank you and best regards,
Karai
Published by: karais on January 14, 2013 12:49 AMYou can add credentials on the URL in following this:
http://www.redstonecontentsolutions.com/5/post/2011/07/one-click-login-into-the-Oracle-content-server11g.html
-
Oracle 10.2.0.3.0 - impdp - unusable index exists on unique/primary...
Hi all
Oracle 10.2.0.3.0 - during impdp the following error appears:
Object type SCHEMA_EXPORT/TABLE/CONSTRAINT/treatment
ORA-39083: THAT CONSTRAINT Type could not create object error:
ORA-14063: unusable Index exists on constraint unique/primary key
Because sql is:
ALTER TABLE 'MY_SCHEMA '. "' MY_TABLE ' ADD CONSTRAINT PRIMARY KEY 'MY_TABLE_PK' ('ID')
USING INDEX PCTFREE, INITRANS 10 2 MAXTRANS 255
STORAGE (INITIAL 1048576 THEN 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 DEFAULT USER_TABLES)
TABLESPACE "MY_TBS".
Question:
Tree index does not contain the dump file, and impdp should simply create index as it appears in the metadata information.
So, what's the point to clear this error?921817 wrote:
So, what's the point impdp tells his State? It can be hundreds of unusable indexes, why it is not only rebuild?
Because Impdb cannot create an object that is already there and can't make it valid.
Aman...
-
Spatial index on a Partition from the list?
Hello
Environment:
10g, SUSE Linux.
Question:
Spatial indexing can do on list go?
(We can do on the beach of Partitions).
Thank you
SeanNo, this is not yet supported.
Siva
-
Vista file extended properties
Is there a list somewhere of the Vista file extended properties and the index numbers associated with them? For example, Index 0 can be the name, 1 index can be sized and 2 Index can be file type and so on. In my view, there are more than 200 Vista file extended properties and they cover all types of files such as image files to the music files to regular documents.
Can someone point me in the right direction or give them here?
Thank you!
Hi Bdsii,
Thanks for posting on Microsoft answers Community Forums.
The Indexing Service is based on the file systems, you currently have on your computer. Since you have Vista is the NTFS file system. It works on both Windows XP and Vista.
You can take a look at the link below which gives you information about indexing option both on the FAT and NTFS file system. That should answer most of your question with indexing.
http://TechNet.Microsoft.com/en-us/library/bb457112.aspx
It will be useful.
Kind regards
Srinivas
Microsoft Answers Support Engineer
Visit our Microsoft answers feedback Forum and let us know what you think
Maybe you are looking for
-
There is on El Capitan iBooks 1.5... Where do we get iBooks 4.0 or later?
In the article below, they say does sync ePub etc files in iBooks 4.x and later versions. I'm on 10.11.4 and I have iBooks 1.5. Where can I get iBooks 4.0 or later? Because the synchronization of files ePub on devices does not work for me. I tried an
-
Cannot ping local interface after last criticism of microsoft update
I just bought a Satellite Pro A200.When I upgraded to the latest critical updates from Microsoft Update, I found that I could ping is no longer my local IP address. This has happened to the card NETWORK LAN RJ45 and the wireless network card.I reinst
-
Since i ' v decides to keep what I was looking for programs to stop or remove that increases the battery life. 41/2 hours is quite ridiculous. No matter what success there in the extension of the battery?
-
Windows Mail keeps denying access to e-mail attachments that are .jpg picture files.
Messaging Windows keeps denying access to e-mail attachments that are .jpg picture files. How can he blocked so I can see the .jpg pictures? original title: Windows Mail has blocked access.
-
Hard to find the upgrade to Adobe Flash player for Vista 64-bit
I got my PC for a little over 2 years now and I would like to watch videos and movies on my pc via internet. When I try to view a video or a movie, a bar appears at the top of the window tells me to download the correct version of adobe flash, but i