Refresh a specific partition of the table, materialized
DB version 11.2.0.3 Linux
We have several views partitioned materlialized. Partitioning key is the principal. We want to update partition independently, for example to update all partitions of materialized view for principal GB (e.g. the principal refresh GB only although there are also other partitions belonging to other mndators which are obsolete).
Is it possible to refresh only the partitions? I am aware of the track changes of partition but I think / know that it is possible to update a specific partition.
We have several views partitioned materlialized. Partitioning key is the principal. We want to update partition independently, for example to update all partitions of materialized view for principal GB (e.g. the principal refresh GB only although there are also other partitions belonging to other mndators which are obsolete).
Is it possible to refresh only the partitions? I am aware of the track changes of partition but I think / know that it is possible to update a specific partition.
Non - Oracle update process not to refresh a specific partition.
But there is a work around if you manage refreshes him yourself.
WARNING - This is NOT for the faint of heart. I do not recommend the use of the approach unless it is absolutely necessary. Make sure you understand all of the issues involved before using this technique of production.
Basically, you:
1. create a partitioned table pre-built to found the MV on
2. create a MV using the pre-built table
3. create a regular work/temp table with the same structure as the MV
4. fill the temp/work table with new data of the partition (updated)
5. run an EXCHANGE PARTITION of work/temp with the 'specific' partition table you want to update
Arup Nanda has a text with a very simple example of how the process works. You will need to modify it for your use case.
http://Arup.blogspot.com/2010/04/online-MATERIALIZED-view-complete.html
Tags: Database
Similar Questions
-
Is Acrobat Pro just for us. We have an employee handbook that needs editing. A part is current pdf, some of an earlier version. You want to get all in a manual, the table of contents automatically adjust and links to specific pages of the table of contents.
Acrobat Pro is certainly not the right tool for editing. You want to change the manual using the source - MS Word files for example. Once you have the full changes including OCD work as you want, Acrobat Pro is the tool to convert the source document to PDF format, and ensure the accessibility requirements of 508 - and preferably ISO 14289 (PDF/UA) - are met.
-
Column of type BLOB in own tablespace in partition in the table, tablespace to move
Hi all
First off I use Oracle Database 11.2.0.2 on AIX 5.3.
We have a table is partitioned on a monthly basis.
In this table, there is a partition (BOTTOM), this lower score is 1.5 TB in size thanks to a BLOB column called (ATTACHMENT).
The rest of the table is not large, about 30 GB, it's the BLOB column that uses all the space.
The lower part is in its own default tablespace (DefaultTablespace), the BLOB column in the lower score is also in its own tablespace (TABLESPACE_LOB) - 1.5 to
I was invited in order to free up space by moving the TABELSPACE_LOB (from the low partition) to a data archive, confirming the data is there and then remove the lower score of the production.
I do not have enough free space (or time) make an expdp, I think not only its doable with data so much.
CREATE TABLE tablename ( xx VARCHAR2(14 BYTE), xx NUMBER(8), xx NUMBER, ATTACHMENT BLOB, xx DATE, xx VARCHAR2(100 BYTE), xx INTEGER, ) LOB (ATTACHMENT) STORE AS ( TABLESPACE DefaultTablespace ENABLE STORAGE IN ROW NOCOMPRESS TABLESPACE DefaultTablespace RESULT_CACHE (MODE DEFAULT) PARTITION BY RANGE (xx) ( PARTITION LOWER VALUES LESS THAN ('xx') LOGGING COMPRESS BASIC TABLESPACE DefaultTablespace LOB (ATTACHMENT) STORE AS ( TABLESPACE TABLESPACE_LOB ENABLE STORAGE IN ROW ) ...>>My idea was to take a table, excluding the attachment column datapump, export using external tables.
Then to create the table on the database archive 'with' the attachment column.
Import data only, as I understand that if you use a dump file that has too many columns Oracle he will manage, I hope it will work the other way around.
Then on the production, make the TABLESPACE_LOB read-only and move it to the new file system.
It's a little more complicated that a normal gesture of tablespace because of how the table is split.
Any advice would be much appreciated.
I was thinking about an approach as:
SWAP PARTITION allows to separate the partition of the table
- Create a non-partitioned table which is otherwise identical in structure to tablename (nonpart_tablename)
- ALTER TABLE TableName LOWER WITH nonpart_tablename SWAP PARTITION
Move the segment of the table at TABLESPACE_LOB, or to a different tablespace on its own. It is, as you say, only 30 GB and I think (but not strongly enough to go forward without testing/validation on a smaller scale) that the displacement of the segment of the table in this way does not disrupt the LOB segment, as long as you don't say MOVE LOB.
- ALTER TABLE nonpart_tablename MOVE TABLESPACE TABLESPACE_LOB
Now the TABLESPACE_LOB tablespace is self-contained and you can make it transportable.
-
Adding new partition in the table are
Hello
Oracle 9i
Windows 2003 operating system
The main entry/exit table is one of the base tables that has a large number of records and a very high success rate, and to avoid poor performance that may occur in such cases, Oracle Table partitioning technique has been examined in the early stages of the implementation of the system.
Unfortunately, the technique used to divide data based on the year of the transaction considered the year 2010 as the last specific partition, so all records created after this year is gathered in a single partition and this may cause poor performance in the years to come.
Are required to add another 10 partitions; up to the year 2020 taking into account that the downtime should be close to zero.
Ground:
According to my knowledge
for this, so we can create a new table with the same columns and add required 10 more partitions, and if we take 2 scenarios like
export/imp
insertion in the new table select * from < table > old
What is the best, and if we take exp/imp, if her take a few hours of time to complete a task... what will happen for the updates as insert, update, and delete in this time what will be the impact on the import... I mean if all committed tarnscations... These tarnscations automatically add to the table are not.
Please tell me what is the best and the tarnscations should not effect... pls tell me how excatly we can complete the task.
Concerning
873393In my script, I have a DROP TABLE because I'll put up a reproducible demonstration. I can run the script repeatedly and regenerate the same demo data!
In your environment you would not fall off the table!
To simplify the demo for you: IGNORE the DROP TABLE command. Pretend it does not exist.Hemant K Collette
-
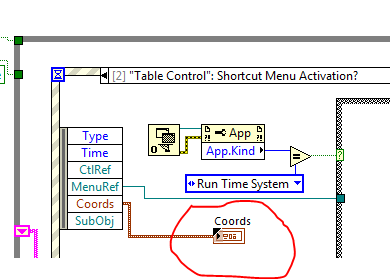
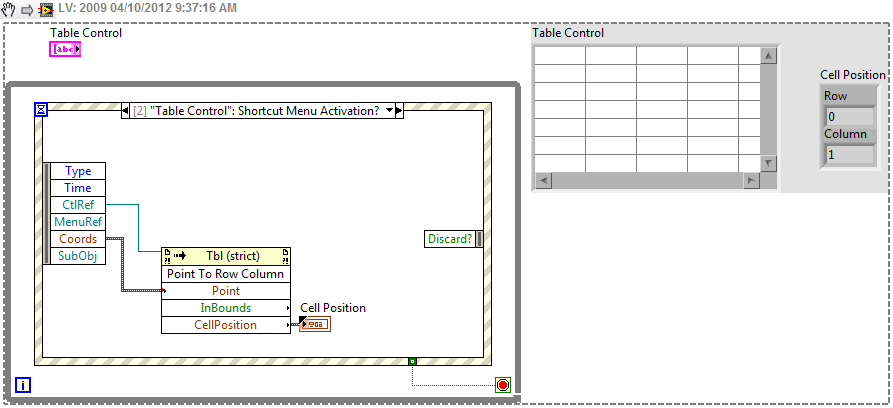
How to determine a specific line in the table clicked on
Hello-
I need to determine the specific line of a table control that is right-mouse-clicking. I think that this is possible by using the context Menu Activation? event for the control of the table and get the vertical coordinate in the Coords filter options.
He is performing experiments to determine the vertical amplitude of each row in the table, or maybe in determining the width of a line and using a linear relationship to determine the possible range of the following lines. Do you feel it is the best strategy or is it maybe an another easier way to get this information?
Thank you
Don
You can use the CtlRef with the Point in the array to the method line for the information.
Ben64
I was too slow to respond...
-
HowTo archive several Partitions of the Table to a new table?
We have a very big_table partitioned on the TRAN_DATE column per month.
PARTITION 'P200310' VALUES LESS THAN (TO_DATE (' 2003-11-01 00:00:00 ',' SYYYY-MM-DD HH24:MI:SS ',' NLS_CALENDAR = GREGORIAN '))
+.. +
+.. +
+.. +
PARTITION "P201008" VALUES LOWER THAN (TO_DATE (' 2010-09-01 00:00:00 ', 'SYYYY-MM-DD HH24:MI:SS', ' NLS_CALENDAR = GREGORIAN ' "))
We wanted sheet music archive (consolidated) "P200812" "P200811" "P200810"... and below in a new_table.
I tested the "swap partition" method but the docs I found offers with one partition is going to a single table, such as:
P200812-> table1
P200811-> table2
etc...
etc...
so, I end up with multiple partitions at several tables... not what we wanted.
I think a merger of all the partitions P200812 and below in a single partition and make the Exchange. What is the quickest way?
Any help or pointers will be greatly appreciated.
Thank you.
Edited by: joey_p May 14, 2010 12:45 AMcreate new_table as select * from big_table where 1=2; -- create an empty, non-partitioned table alter new_table nologging; alter session enable parallel dml; insert /*+ APPEND PARALLEL (n 2) */ into new_table n select /*+ PARALLEL (b 2) */ * from big_table partition (first_partition_name); commit; insert /*+ APPEND PARALLEL (n 2) */ into new_table n select /*+ PARALLEL (b 2) */ * from big_table partition (second_partition_name); commit; alter table big_table truncate partition (first_partition_name); alter table big_table truncate partition (second_partition_name); alter table big_table merge partition ....TRUNCATE and MERGE orders that you would do once you have verified that all the data has been copied to the new table. (and, preferably, after a BACKUP was taken, because integration into new_table was made without redoing loggging.
Hemant K Collette
http://hemantoracledba.blogspot.com -
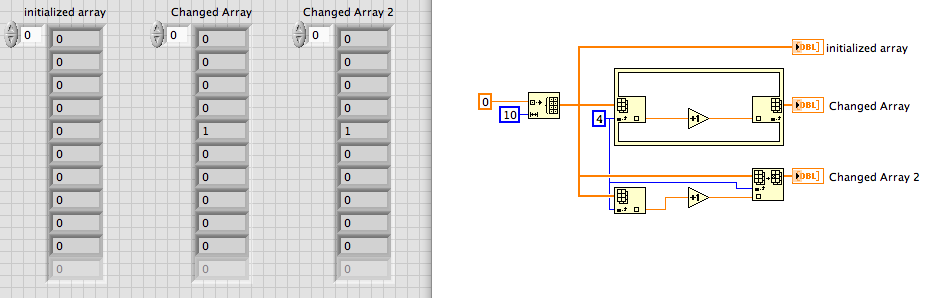
How to change a specific element in the table
Hello
I have a chart intialized 1 d
I want to take the table exist and for example to add + 1 to the 5th element
How can it be done?
Thank you
If you have a newer version of LV, the Structure of elements in Place can simplify this.
Lynn
-
Move the partition of the table and get ORA-14006: invalid partition name
I'm using oracle 11.2.0.4 and I am trying to move a partitioned table to one tablespace to another. I checked may times and I have the correct table name and the name of the partition. However, I get the error ora-14006.
Can see everything what could be the problem?
SQL > ALTER TABLE GWPROD. QRY_TES_ROLLINGCUREDITS MOVE PARTITION 201112 TABLESPACE GW_PROD_T2 PARALLEL (DEGREE 4) NOLOGGING;
ALTER TABLE GWPROD. QRY_TES_ROLLINGCUREDITS MOVE PARTITION TABLESPACE GW_PROD_T2 PARALLEL (DEGREE 4) NOLOGGING 201112
*
ERROR on line 1:
ORA-14006: invalid partition name
Thanks in advance.
Names that begin with numbers are not legal partition names. A fool created by placing them between double quotes. You will need to do the same.
-
Cannot highlight specific things in the tables with the new Dreamweaver CC
I am an interactive designer, so I code and design for my business emails. DIVS not being able to be used in emails (too many browser incompatibility), our emails are coded with tables (unfortunately).
That being said, in CS6, whenever I chose something in the view design, Dreamweaver would immediately highlight what I chose. Thus, for example, the image of 'Hero' in the email - I would click on it and the URL of the image would be highlighted. Even for text, links, whatever it is. Works great, saved a lot of time.
My colleagues and I, after having had a top of shit same installation of CC in the first place, the questions can now no longer for it. When I select this image of heroes in Design view, Dreamweaver highlights the entire table it is in, or something other completely irrelevant, rather than the link of the image. We must now seek in our code to find the URL, or whatever it is we seek to change, which is extremely time consuming and opens up a whole bunch of questions QA. We notice with DIVs, highlighted this function works fine, but as we mainly work with tables it is very frustrating.
Is there a setting, a work around? No matter what? Help D:
Nothing has changed in DW with regard to selecting something in Design view and have it select in Code view, but your explanation of what is happening gave me a thought...
Are you sure that you are actually in design mode?
CBWMS 20141 has done some strange Design/Code/Split/Live preferences. It is possible that you change actually in Live View (you will see light blue contours around the selected items), who does not like the Design view and highlight the bad code in a very similar way to way to what you describe.
Make sure that the drawing is selected in the drop-down menu next to Split in your toolbar of the Document.
-
Create index partition in the partition table tablespace
Hello
I am running a work custom that
* Creates a tablespace by day
* Creates the daily table partition in the created tablespace
* Removes the days tablepartition X
* Removes the storage space for this partition of X + 1 day.
The work above works perfectly, but it has problems with the management of the index for these partitioned tables. In the old database (10g - single node), all indexes and partitions exist in a BIG tablespace and when I imported the table creation script in the new database, I changed all the partitions table & index to go in their respective space.
For example:
Table_name... Nom_partition... Index_Part_name... Tablespace_name
============...================............====================...........=================
TABL1... TABL1_2012_07_16... TABL1_IDX_2012_07_16... TBS_2012_07_16
TABL1... TABL1_2012_07_15... TABL1_IDX_2012_07_15... TBS_2012_07_15
But now, when the job is run, it creates the index in the tablespace TBS_DATA default.
Table_name... Nom_partition... Index_Part_name... Tablespace_name
============...================.............====================...........=================
TABL1... TABL1_2012_08_16... TABL1_IDX_2012_08_16... TBS_DATA
TABL1... TABL1_2012_08_15... TABL1_IDX_2012_08_15... TBS_DATA
I can issue alter index rebuild to move the index to its tablespace default, but how can I make sure that the index is created in the designated tablespace?
NOTE: the partition/tablespace management work that I run only creates the partition of the table and not the index.
The new env is a cluster of CARS of 2 nodes 11 GR 2 on Linux x86_64.
Thanks in advance,
aBBy.try something like this
ALTER table tab_owner.tab_name add the partition v_new_part_nm
values less (to_date('''|| v_new_part_dt_formatted ||'') ((', "DD-MON-YYYY)) tablespace ' | part_tbs
update the index (ind1_name (partition ind_partition_name tablespace ind_part_tbs)
ind2_name (partition tablespace ind_part_tbs ind_partition_name))
; -
Table partitioned using the hash partition
I need to create the table using hash partition and need to specify the number of partitions (for example, 32)
1. How/where to specify the number of partitions? I checked under "partitioning" tab of the properties of the table, but "system partition" is disabled.
2. What is the difference between the hash by quantity vs Hash of the list of partitions and which should I use?Hello
To do this, you must set the Partition Type to HASH BY QUANTITY. Then, tab Tablespaces part of hash, you can set the quantity field on HashP to the number of partitions.
Ownership of the system partition is only enabled if the type of partitioning SYSTEM.
Hash partition list allows you to add entries in hash Partitions of the Table nsud Partition to set each individual partition.David
-
Limit the number of partitions of a table can have
Hello
It has been a while I think about a simple method and the best solution to a performance problem in my application. Benefiting from the table partitioning seems a simpler approach. It involves tiny my application code changes and more, it keeps the logic of global application 100% intact. However, sometimes the number of required partitions can grow to more than 500 thousand. I know another application implementation of partitions that 50 thousand for one of his paintings. I wonder if Oracle recommends or puts a limit to a number of partitions of the table can have. How does that limit, if it exists, varies so each of my partition table contains only a small amount of data. say, no more than 2 thousand records each of size 1 KB. What are the important considerations to keep in mind while creating the huge number of partitions of a table?
All entries on this would be a great help.
Thank you
EXISTING
PS: versions of Oracle 10 g from to consider.
Published by: Olivia on December 30, 2009 09:46
Published by: Olivia on December 30, 2009 09:50Hello
Please visit the following link.
Concerning
-
Partition wise joined possible with partitions of the interval?
Hello
I want to know the score wise join (NTC) is possible with interval partitioning - I can't find an explicit statement that he isn't, but I can't make it work - I did a simple test case to illustrate the issue.
below, I have 2 create table scripts - 1 for the case of interval and 1 for the case of hash - I then a simple query on these 2 objects which should produce a NTC.
In the case of hash, it works very well (see screenshot 2nd with a set of slaves), the first screenshot shows the case of the interval where I find myself with 2 sets of slaves and no NTC.
No idea if this is possible and I just missed something?
(for the test case choose the names of schema/storage appropriate for your system)
Oh and version (I almost forgot... :-))-East 11.2.0.4.1 SLES 11)
See you soon,.
Rich
-case interval
CREATE TABLE 'SB_DWH_IN '. "' TEST1 '.
TABLESPACE "SB_DWH_INTEGRATION".
PARTITION BY RANGE ("OBJECT_ID") INTERVAL (10000)
(PARTITION 'LESS_THAN_ZERO' VALUES LESS THAN (0) TABLESPACE "SB_DWH_INTEGRATION")
in select * from DBA_OBJECTS where object_id is not null;
CREATE TABLE 'SB_DWH_IN '. "" TEST2 ".
TABLESPACE "SB_DWH_INTEGRATION".
PARTITION BY RANGE ("OBJECT_ID") INTERVAL (10000)
(PARTITION 'LESS_THAN_ZERO' VALUES LESS THAN (0) TABLESPACE "SB_DWH_INTEGRATION")
in select * from DBA_OBJECTS where object_id is not null;
-case of hash
CREATE TABLE 'SB_DWH_IN '. "' TEST1 '.
TABLESPACE "SB_DWH_INTEGRATION".
8 partitions PARTITION OF HASH ("OBJECT_ID")
store in ("SB_DWH_INTEGRATION")
in select * from DBA_OBJECTS where object_id is not null;
CREATE TABLE 'SB_DWH_IN '. "" TEST2 ".
TABLESPACE "SB_DWH_INTEGRATION".
8 partitions PARTITION OF HASH ("OBJECT_ID")
store in ("SB_DWH_INTEGRATION")
in select * from DBA_OBJECTS where object_id is not null;
-query to run
Select / * + PARALLEL(TEST2,8) PARALLEL(TEST1,8) * / *.
of 'SB_DWH_IN '. "" TEST2 ","SB_DWH_IN ". "' TEST1 '.
where TEST1.object_id = test2.object_id


It is planned and a consequence of the estimate of the number of parallel slaves.
To the parallel 41 each slave made 3 passes (i.e. sleeves 3 partitions).
Add a partition (by table), and a set of slaves will have to manage a 4th pass: the cost of the query using NTC would increase from 33 percent even if the modification of the data is less than 0.8%.
I guess that in the production Oracle distributes your lines of 1 M for a hash join.
Because the decision is encrypted, it is possible that a very extreme tilt in partition in the table sizes billion line might overthrow the optimizer in a non - NTC join - but I have not tested that.
If you want to force the plan John Watson suggestion for a hint of pq_distribute is relevant. To cover all the bases and call your tables SMALL and LARGE
/*+
leading (FAT kid)
USE_HASH (large)
no_swap_join_inputs (large)
PQ_DISTRIBUTE (wide none none)
*/
If it's legal, that should do it.
Concerning
Jonathan Lewis
-
How to extract specific data from the user to view?
Hello
I have a requirement I need to display only the Session_user-specific data in the table. Scenario is that if the user belongs to a specific region should be able to see data for that specific region only.
I think passing the session_user view query name but don't know if it of possible or not. If possible how to do this.
What is the best way to achieve this?
Thank you
Angelica
Hello
If you use the ADF for authentication security, the user name is then accessible from the context of the ADF in British Colombia ADF. You can then
1. create a view of the criteria in British Colombia ADF to a specific view
2. set the display criteria to use a variable binding
3. use groovy to add the value of the bind variable
-set the type of value of 'Expression '.
-Add adf.context.securityContext.userName
4. go in the Module--> Application data model
5 Select the instance of the View object
6. press on "change."
7. Select the view test
If you download the example in this article: Oracle ADF: security for everyone so you see that users have a profile page containing data for the authenticated user. Sound by using the method described above
If you do not use ADF security you can always use this approach. Instead of providing the value of the variable bind using Groovy you can run the view object using executeWithParams operation in this case, you can read the value of the authenticated user to the side view ADF. The binding variable would not be set to the Expression in this case though.
Frank
-
Daily requirement Auto partitioning on space table
Hi gurus of the Oracle
How to configure the Oracle Table for partition of auto every day in space table every day.
There should be one to a mapping between the space in the partition and the table
table space must be created automatically
appreciate the help
Hello
Our agreement is intended to improve query response time
Although in fact the main reason to create separate daily to separate partition table space is to optimize the balance for easily maintainable against partition of large size that could help a lot to SOME queries and IO select


Maybe you are looking for
-
Is there a Contact component option?
How do I set the Contact list so that it is visible all the time and I can just click on the Contact and open an email to them? It seems that I had this option first.
-
How to escape (delete) the American dictionary
The default dictionary is American EnglishI want to use English EnglishI installed the English Dictionary of "GB" and "topic: config ' * claims * that it's now a Firefox uses, but whenever I type for example"organize"I get the sinuous red streak and
-
When I copy and paste a path from the Windows Explorer in teststand as a constant, I should add an extra "-" in front of all the "------" manually. Is there a faster way? Thank you!
-
Why my event structure reacts to an event of "change value"?
Hello I created a VI with 2 while loops and structure 1 integrated event. The first while loop creates a square wave and the value of the pass signal periodically - this event is registered by a property node and also shown on an indicator. I've link
-
How to use windows search to search the contents of a bunch of files with random names / extensions?
How to use windows search to search the contents of a bunch of files with random names / extensions? Plain txt files say 1,000 with random name of file extensions?