Regular expression - elimination of comments
Hello
I am trying to solve a problem, I remove the comment text of an individual raw text stored in an oracle table.
There is no special case. I mean several models of comment.
My Version of Oracle is: 11.2.0.4.
Could you help me?
Hello
You can solve this problem with the help of the regular expression REGEXP_REPLACE.
An example for this:
SELECT STRG
, REGEXP_REPLACE (strg, ' / \ * ([^(/\*) | ^(\*/)]) *------* /', ", 1, 0) AS STRG_NEW
(SELECT
"TextBlock: / * dog."
--
CAT
"* / normal / *" people * /.
text "STRG AS FROM DUAL)
;
Original text:
==============
TextBlock: / * dog
--
CAT
' * / normal / * ' people * /.
text
Result-text:
============
TextBlock: normal
text
With this selection, you can remove every comment blocks, but it doesn't work though if the comment template is not single quotes included!
It's a simple solution, that's maybe what you are looking for.
Kind regards
David Shepherd
Tags: Database
Similar Questions
-
I solved this by using the following regular expression in find DW and replace dialogue, it will be all the html on several lines between two specified comments:
<!-NameofStartingComment--(.| \s)*?--NameofEndingComment-->)
Hello
I have structured my site in dreamweaver with each page between the comments section:
<! - navBarStart - >
HTML here
<! - naveBarEnd - >
I used this method because I wanted to be able to easily use the find and replace dialogue with regular expressions to update pieces of code throughout my site. However, I have real problems finding the correct regular expression to use.
So in every page I have my <! - startHtmlSection - > <!-endHtmlSection-> between these two tags, I sometimes have different HTML. I want to find the regular expression I could use 'generic' of all the html to a find a replacement between two of my comments specified. Can anyone help? I googled and tried everything what is obvious (after you have selected the regular expressions in the find and Replace dialog) but DW never find the tags in the pages of sites.
I solved this by using the following regular expression in find DW and replace dialogue, it will be all the html on several lines between two specified comments:
Hello
I have structured my site in dreamweaver with each page between the comments section:
HTML here
I used this method because I wanted to be able to easily use the find and replace dialogue with regular expressions to update pieces of code throughout my site. However, I have real problems finding the correct regular expression to use.
So in every page I have my between these two tags, I sometimes have different HTML. I want to find the regular expression I could use 'generic' of all the html to a find a replacement between two of my comments specified. Can anyone help? I googled and tried everything what is obvious (after you have selected the regular expressions in the find and Replace dialog) but DW never find the tags in the pages of sites.
-
Regular expression breaks script
I have the following statement of regular expressions in my JSX file:
var regex = /[^/]*(?=\.[^.]+($|\?))/; // Doesn't work while this does: var regex = /[\u0400-\u04FF]+/;
.. .and it breaks execution of my script for unknown reasons. What's not here? I thought the syntax / theRegEx.
(comment to the statement of regex solves the problem and the script runs normally)I tested the regex here:
RegExr: Learn, build, & Test of RegEx.. .on this string: "c:/Users/martin.dahlin/Desktop/Test/lolFile.lol".
gives me "lolFile" without the quotes.xbytor is right, there is really no "regex-standard/compliance. Basic things work quite universally, but there are the specifics of the platform and conventions and you just test & work around them.
That said, get into your regular expression to Tester online regex and a debugger: JavaScript, Python, PHP, and PCRE gives and error "/ separator unescaped ', i.e. must be ' / [^\/] * (?)» = \. [ ^.] +($|\?)) /". Also the use of the explicit constructor is a tad safer, typos lead more reasonable errors.
-
Regular Expressions of Drivng me crazy!
Oracle Version 11 GR 2
Scripts of test data
CREATE TABLE REGEX_TEST
(ID NUMBER 4,
VARCHAR2 (50) COMMENTS
);
Insert into REGEX_TEST (ID, COMMENTS) values (1, "< Little Red Riding Hood > #title");
Insert into REGEX_TEST (ID, COMMENTS) values (2, "#title < Little Red Riding Hood > #publisher < Penguin >");
Insert into REGEX_TEST (ID, COMMENTS) values (3, ' #title < Little Red Riding Hood > #publisher < Penguin > #pages < 30 > ");
Congratulations to Frank Kulash to provide the following SQL to clean the field of comments only properly marked the text in the field
Properly tagged text is defined as
Start by #.
then nameOfHashTag
then < valueOfHashTag >
The number or name of hashtags is variable and is not known at design time
The Frank provided SQL is (with a slight mod)
Original, SELECT comments
REGEXP_REPLACE (comments
, '(^|>)[^#.*<]*'
"\1") that cleaned
of REGEX_TEST;
Source language CLEANED #title < little Red Riding Hood > #title < little Red Riding Hood > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > FIRST QUESTION: I understand the [^ #. * <] * component - search for zero or more occurrences of anything that is not a # tracking of zero or more characters, then a < and I understand the () sets a capturing group, but I don't understand how it works - 1 is probably a reference to the Group?
Now, I add a few more - lines to see how he treats badly marked text that is
void <>
text that is not marked
text is not enclosed by sharp hooks
Insert into REGEX_TEST (ID, COMMENTS) values ('4, #title <>");
Insert into REGEX_TEST (ID, COMMENTS) values (5, "#title <>#publisher < Penguin >");
Insert into REGEX_TEST (ID, COMMENTS) values (6, "#title < Little Red Riding Hood > text that isn't marked < Penguin > #publisher");
Insert into REGEX_TEST (ID, COMMENTS) values (7, "#title oops I forgot #publisher < Penguin > rafters").
Original, SELECT comments
REGEXP_REPLACE (comments
, '(^|>)[^#.*<]*'
"\1") that cleaned
of REGEX_TEST;
Source language CLEANED #title < little Red Riding Hood > #title < little Red Riding Hood > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > #title <> #title <> #title <>#publisher < penguin > #title <>#publisher < penguin > #title < little Red Riding Hood > text that is not signposted #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #title oops I forgot the #publisher < Penguin > rafters #title oops I forgot the #publisher < Penguin > rafters SECOND QUESTION: Is there any way I can specify that the <>cannot be empty - I played a bit with the +? but impossible to get what I want. Similarly, the latter (without text no sharp hooks)-I guess this would be impossible because you don't know if it was wong, until you have met the # next date you would be somehow to follow back and ignore the whole group.
I learned two things in this
1. regular expressions are extremely powerful
2. but they will drive you crazy?
Once again thanks a lot for the help
BTW - I managed to do what I had to do it using a lot of PL/SQL code, but not very fast!
Hello
So, you want only the substrings that are well-formed attribute/value pairs (attribute or value may be missing). You want to ignore anything in the comments that is not part of a well-formed pair.
It is not very difficult to get a single well-formed pair. The problem is that there is no good way to say 'everything that is not part of a well-formed pair '. One solution is to extract from each pair trained well on a separate line and then re - combine them into a single string by id, like this:
WITH split_data AS
(
SELECT id
comments
REGEXP_SUBSTR (comments,
, '#' || -sign #.
'[^<]+' || ="" --="" 1="" or="" more="" of="" any="" characters="" except="">
'<' || ="" --=""><>
'[^>]+' || -1 or several characters any except >
'>' -- > sign
1
LEVEL
) AS well_formed_pair
LEVEL AS pair_num
OF regex_test
([LEVEL CONNECTION <= regexp_count="" (comments,=""> <> <[^>] + > ')
AND PRIOR id = id
AND PRIOR SYS_GUID () IS NOT NULL
)
SELECT id
commented THAT the original
LISTAGG (well_formed_pair) WITHIN GROUP (ORDER BY pair_num)
THAT cleaned
OF split_data
GROUP BY id, comments
ORDER BY id
;
The 2nd argument of REGEXP_SUBSTR above is actually the same as the 2nd argument of REGEXP_COUNT. I wrote one of them in a more detailed form, hoping to make it clear what happens if has been done. You can write an expression so be it.
The result is just what you asked:
ID CLEANED ORIGINAL
--- ---------------------------------------- ---------------------------------
1 #title#title 2 #title
#publisher #title #pu
blisher 3 #title
#publisher #title #pu
#pages<30> blisher #pages<30> 4 #title<>
5 #title<>#publisher
#publisher 6 #title
#title #pu text
is not marked #publisherblisher 7 #title oops I forgot that the rafters whoops # #title forgotten angle br
Editorackets #publisher -
Need help with a simple regular expression replacement
Hello everyone,
He comes to the table that I have to work with.
My select statement isCREATE TABLE "TBL_ACCOMMODATION" ("ACCOMMODATION_ID" NUMBER, "HOTEL_NAME" VARCHAR2(100), "ADDRESS" VARCHAR2(200), "LOCATION" VARCHAR2(100), "PHONE" VARCHAR2(50), "EMAIL_ADDRESS" VARCHAR2(60), "CONTACT_PERSON" VARCHAR2(60), "STATUS" CHAR(1), "CREATED_BY" VARCHAR2(10), "CREATED_DATE" DATE, "MODIFIED_BY" VARCHAR2(10), "MODIFIED_DATE" DATE, "MOBILE" VARCHAR2(50)) REM INSERTING into TBL_ACCOMMODATION Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (147,'Testt','Auckalnd','Henderson','565756776','[email protected]','Jasmine','A',null,null,'JEEJJ',to_date('23/10/12','DD/MM/RR'),null); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (129,'Kirby Hotel','25A Aitken Street Wellington','Wellington','04 918 8513','[email protected]','Deahdoow Maharg','A',null,null,'LEAN',to_date('14/02/13','DD/MM/RR'),'027 356 4333'); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (167,'Avenue ee','10 Wellington Street Wellington','Wellington','4444444','[email protected]','James','A',null,null,'LEAN',to_date('21/02/13','DD/MM/RR'),null); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (185,'Quadrant Hotel','10 Waterloo Quadrant, Auckland','Auckland','9555555','[email protected]','Quentin QQ','A',null,null,'LEAN',to_date('04/03/13','DD/MM/RR'),null);
I have to use the function replace twice. One is to replace the Chr (13) a comma is second band a comma where there are two commas.SELECT acc.hotel_name || '(' || replace(replace(acc.address,chr(13),', '),',,',',') || ')' FROM TBL_ACCOMMODATION acc inner join ijs_seminar s ON acc.accommodation_id = s.accommodation_id where s.seminar_id = :P27_SEMINAR_ID
I don't know much about regular expressions.
If someone can show me a better way to handle this using the regular expression rather than a heavy means above.
Thanks in advance
AnnHi, Ann.
Ann586341 wrote:
Hello everyone,He comes to the table that I have to work with.
CREATE TABLE "TBL_ACCOMMODATION" ("ACCOMMODATION_ID" NUMBER, "HOTEL_NAME" VARCHAR2(100), "ADDRESS" VARCHAR2(200), "LOCATION" VARCHAR2(100), "PHONE" VARCHAR2(50), "EMAIL_ADDRESS" VARCHAR2(60), "CONTACT_PERSON" VARCHAR2(60), "STATUS" CHAR(1), "CREATED_BY" VARCHAR2(10), "CREATED_DATE" DATE, "MODIFIED_BY" VARCHAR2(10), "MODIFIED_DATE" DATE, "MOBILE" VARCHAR2(50)) REM INSERTING into TBL_ACCOMMODATION Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (147,'Testt','Auckalnd','Henderson','565756776','[email protected]','Jasmine','A',null,null,'JEEJJ',to_date('23/10/12','DD/MM/RR'),null); ...Thanks for posting the sample data. You post the results, but the validation of the existing query which I suppose, produced good results. I can't run this query, because it requires the ijs_seminar table and a connection variable that also has no post, but I can just comment on the join and the WHERE clause.
Is this really the best set of sample data for this question? This problem involves Chr (13) and repeated commas, but I don't see any s CHR (13) or repeated commas in the sample data. In addition, it seems that there are a lot of columns that play no role in this issue and just to make things difficult to read.
My select statement is
SELECT acc.hotel_name || '(' || replace(replace(acc.address,chr(13),', '),',,',',') || ')' FROM TBL_ACCOMMODATION acc inner join ijs_seminar s ON acc.accommodation_id = s.accommodation_id where s.seminar_id = :P27_SEMINAR_IDI have to use the function replace twice. We need to replace the Chr (13) by a comma,.
As posted, inside REPLACE replaces Chr (13) with a comma and a space which could be important if you then pick up consecutive commas.
second is the band a comma where there are two commas.
I don't know much about regular expressions.
If someone can show me a better way to handle this using the regular expression rather than a heavy means above.Assuming you want to replace Chr (13) with just a comma, then an equivalent would be:
SELECT acc.hotel_name || '(' || REGEXP_REPLACE ( acc.address , '[,' || CHR (13) || ']{1,2}' , ',' ) || ')' AS h FROM tbl_accommodation acc INNER JOIN ijs_seminar s ON acc.accommodation_id = s.accommodation_id WHERE s.seminar_id = :P27_SEMINAR_ID ;In the argument to REGEXP_REPLACE 2nd
[xy]{1,2}medium 1 to 2 characters of set of x and y. This could be
x or
there or it could be 2 characters
XY or the other way
YX or it could be the same characters 2
XX or
YYREGEXP_REPLACE is slower that REPLACE. Even if your original expression is longer, it may be more effective. (Performance may be not a problem in this case.)
-
Find and replace - regular expression to help?
How can I find ' <!-* PAGE footer AREA *-> "and replace it and evething after with my new coding of footer on all my pages.
The problem is:
The code in my existing page footer area is not the same on all pages.
I want to replace it with a new one on all pages
I watch the operators of regular expressions, not found patern that works...
Thanks in advence for your help
The following regular expression is the and everything up, but not including the closing tag:
[\s\S]+(?=<\/body>)
Use it in the search field and put the comment and the code to the footer in the field replace. Select use regular expression.
Always make a backup before using a regular expression on many pages.
-
When a string of characters, I'm interested, is buried in an e-mail, I would find these emails. It seems that as the code needed to find an email is already in place, it would take very little effort/code/support added to extend the search capabilities of more effectively, as it is available in spreadsheets.
This particular forum has these capabilities, suggesting that users find useful installation.
Are there reasons preventing these facilities being added to T/B? I find that the ability would frequently help me in search of my email.
FiltaQuilla both Expression search/GmailUI provide functionality, specifically the regular expressions.
FiltaQuilla aims to improve the message filters and has a useful side effect in improving the CTRL + SHIFT + f find. Research of expression increases the QuickFilter bar. Or rather weird global research assistance, but I work around this by using a Saved Search folder, where you use a dialog similar to the message filters and can make use of the enhancements offered by one of these modules.
-
The z570 has not a regular Express card slot (only a mini one)?
The z570 has not a regular Express card slot (only a mini one)?
Hi KiteEye and welcome to the community,
It doesn't have an Express card slot.
The small slot located is a memory card reader.
Dave
-
According to the link below, TS supports regular expressions. Can anyone provide an example where to write regular expressions?
I might be easier to do via a plug-in of .net, but TS permitting, I might go with it.
http://zone.NI.com/reference/en-XX/help/370052N-01/tsref/infotopics/find_regular_expressions/
Hello
Yes, there is a member of the PropertyObject.Search, but the result is search results, so I wonder how to use in the execution sequence?
What a simple solution using only 4 lines in Exression statement to realize this split and trim?
Concerning
Jürgen
-
Problem on regular expressions
Hi all
I'm working on a project that require me to separate the following examples:
+ 0, + 0.0000 E1, - 4.33 + E1, - 4.222 + E1, - 6.33 + E2, - 6.55 + E2
What I need is the final four results separately:
-4.33 + E1.
-4.222 + E1,
-6.33_E2,
-6.55 + E2.
I'm totally cool regular expression. Any help is appreciated!
Thank you
+ Kunsheng
Hi, Kunsheng
Good evening exercise to learn regular expressions...
For example, quick and dirty:

I have the strong feeling that something's wrong here (I guess in ([0-9] + [1-9] +)), but in any case the above code is just starting point for you.
Andrey.
-
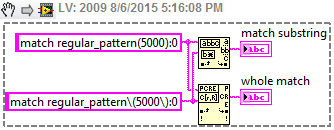
Use matching of regular expressions to search for parentheses
Hi all
I am currently looking for a particular pattern in a string, I can't display the exact string, but say its something like that. corresponds to regular_pattern (5000): 0
I'm also looking for the a different model at the same time, so I have to use the corresponding regular expression and the | function. I can't understand how to match this model because the regular expression function allows parentheses unless I put them in the legs, and that does not help me for this.
Any advice?
Thank you
Matt
Have you tried to escape the bracket?
-
Regular expression matching receives only two digit in brackets
Hello
I use the regular expression of the correspondence with the following expression. It is only able to get all the numbers that are not mere numbers. I want to retrieve all the values which lie between >< in="" the="" string="" and="" create="" an="">
Then
182 2 would be output
182
2
Any help would be appreciated. I've attached what I have so far. Right now I still have the >< and="" it="" can="" only="" grab="" numbers="" that="" are="" not="" single="">
Use (>.) [ ^(<>)]*)< *="" instead="" of="">
-
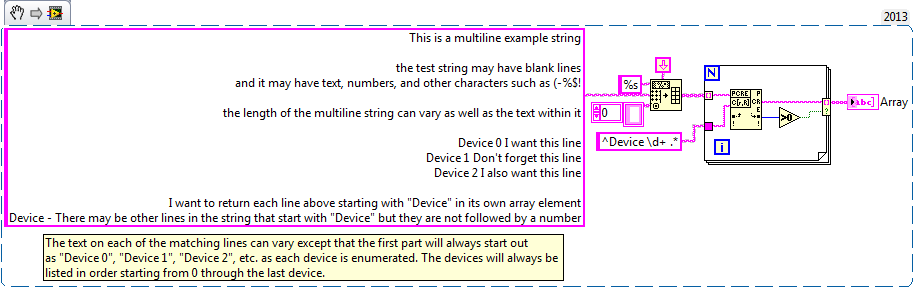
Multiline - Regular Expression Match string
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
aaronb wrote:
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
Corresponding regular expression works well for this.
Ben64
-
regular expression for something that does not have a fixed sequence
Hello
Just having a little trouble with a regular expression. I have an input string and I want to find something that is not this string, so
Input = Hello
Match = Hello
Football game? = False
Entry = Hello1
Match = Hello
Football game? = False
Input = Hello
Match = goodbye
Football game? = True
As I thought that I understood it, to enter as a regular expression in the regular Expression.vi of Match would be ~ (Hello).
If I understand as well, I can't do this by using the match pattern.
Maybe you good people can correct me. Thank you!
-
Complex regular expressions without multiple passes
Does anyone know of a tool that can handle more complex regular expressions without chaining of multiple copies of the VI regular expressions?
For example, if I have a XML string as
Power supply error has occurred.
Sorensen SGA166/188 and I am interested in the tag method to retry only, I could write a regular expression something like
.*
.* to parse the string inside the tag.
kc64 wrote:
For example, if I have a string like
My email address is [email protected]. Please no spamming not me.
and I am interested in the domain name of the email only address, I could write a regular expression something like
@(\w)*\. (com: net | org)
to parse the string 'gmail '.
Forgive me if I am away from base, but I'm flying blind at the moment (not LV to test what I say). You can add to the power of a regular expression using submatches or capture groups. The regular expression you wrote will grab (I think) @gmail.com for the entire game. Let's say you want to get 'gmail' without a second function call. You can do the first group of a little dishonest selection by moving the * inside the parentheses. Then, on the BD pull down on the bottom of the function of regular expression matching to expose a variable number of submatches (both should be in this case). The first should be 'gmail '. The second one should be "com."
In summary, @(\w*)\.) (com: net | org) should give you gmail in the first submatch. Of course, my Perl is a little rusty and LV cannot apply in the same way.
Maybe you are looking for
-
I can't 'play' (xfinity) comcast TV on this XP machine but I can't if I use Explorer?
This computer uses XP. Latest version of Firefox works well. I can't launch the Comcast/Xfinity TV stuff, but all the other tricks video works fine. I can run the TV stuff if I use Windows Explorer. I have Windows 7 on all my other computers and Fire
-
iMac 24 "aluminum, Intel 2.4 GBh, 4 GB ram, how do revive, no OS installed currently
New on Mac! Mine is an iMac 24 "aluminum mid-2007, GBh, 4 GB of ram 2.4 Intel processor. Problem is that this former owner deleted the operating system from the hard drive. Powered on, I can hear the DVD player, speakers put to the test with a sound,
-
my iphone 6 s sim card no service
Please help me
-
HP G62t and Microsoft Office Starter 2010
My previous HP laptop (dv2854se) in brick after only 2 years. The NVIDIA graphics card has overheated and destroyed my laptop, which is a question well documented with this laptop, but unfortunately the laptop was no longer under warranty. I just bou
-
slow to connect and browse the internet
I run win xp spk3 I connect very slow to the internet with google chrome or ie8 my email is with the same supplier and is fast, as always, I scanned in safe mode for malmare and found is there any help for this problem?