Regular expression breaks script
I have the following statement of regular expressions in my JSX file:
var regex = /[^/]*(?=\.[^.]+($|\?))/; // Doesn't work while this does: var regex = /[\u0400-\u04FF]+/;
.. .and it breaks execution of my script for unknown reasons. What's not here? I thought the syntax / theRegEx.
(comment to the statement of regex solves the problem and the script runs normally)
I tested the regex here:
RegExr: Learn, build, & Test of RegEx
.. .on this string: "c:/Users/martin.dahlin/Desktop/Test/lolFile.lol".
gives me "lolFile" without the quotes.
xbytor is right, there is really no "regex-standard/compliance. Basic things work quite universally, but there are the specifics of the platform and conventions and you just test & work around them.
That said, get into your regular expression to Tester online regex and a debugger: JavaScript, Python, PHP, and PCRE gives and error "/ separator unescaped ', i.e. must be ' / [^\/] * (?)» = \. [ ^.] +($|\?)) /". Also the use of the explicit constructor is a tad safer, typos lead more reasonable errors.
Tags: Photoshop
Similar Questions
-
Divide a CSV with a regular Expression
I'm working on a script that will read the CMYK values from a CSV file and add the nuances of the Swatches palette. I can easily split the CSV entering a comma (.split(",");), but I can't seem to get a regular expression to separate by commas and new lines.
Here is the code snippet I have right now is not working:var fileIn = new File("/Users/brianp/Desktop/AVL-PMS-TEMP.csv"); fileIn.open(); var csvIn = fileIn.read(); fileIn.close(); var regEx = "/,|\\n/"; csvRecords = csvIn.split(regEx);I am barking the wrong tree here?
I could change the CSV advance to find all line breaks and replace them with commas, but it looks more elegant to adapt my code for the CSV file is delivered.
Thanks in advance!
csvRecords = csvIn.split(/[,\n\r]/);
This is the shortcut. To preset the regex, to leave out the quotation marks:
var regEx = / | \n/ ;
Better to add the CR (\r) as well.
Use the classes of characters [...] If you can instead of alternatives (... |...), they are more effective (allegedly).
Peter
-
I have a large body of text that I am breaking into individual words (as part of an experimental project of indexing).
I can break the text into a list in a paragraph break for each word space (a simple find and replace).
But I want proper nouns to stay intact.
So I'll try to write a script of the regular expression that finds all occurrences of two contiguous words that begin in a capital letter, then replace the space between the two words with an underscore.
Sigmund Freud becomes Sigmund_Freud.
Does anyone know how I would write this script?
Thank you!!!
You don't need a script, you can do it in the interface:
Search: (\u[-\w]+)\x{20}(?=\u[-\w]+)
Change: $1_
\u[-\w]+ is the abbreviation of "letter followed capital one or more of the characters dash/word"; This is the first name.
\x{20} refers to the space.
followed by an another \u[-\w]+, the family name. This one is in an advanced search, so the whole expression paraphrases that "find a word that begins with a capital letter followed by a space if it is followed by another word beginning with a letter from the uc.
Peter
-
Build a regular expression for data series of Arduino.
All,
I have a few Arduinos Council integrated into a test configuration that I can't save the data of. I now need to be able to see my data in real-time as it comes on the serial port. I found a VI that seems like it should work, my problem is that I can't get a regular expression to work.
The VI is not mine, but if I can get this working, I can easily put it in my VI.
Here's my Arduino code; This is the timestamp, followed four data points, with delimiters tab. It prints on the serial port as
190876 762314 814437 1108235 1091719
Serial.print(sTime); //Serial.print(", "); Serial.print("\t"); data = getdata(dataRead); data = data>>4; Serial.print(data); //Serial.print(", "); Serial.print("\t"); data = getdata(dataRead1); data = data>>4; Serial.print(data); //Serial.print(", "); Serial.print("\t"); data = getdata(dataRead2); data = data>>4; Serial.print(data); //Serial.print(", "); Serial.print("\t"); data = getdata(dataRead3); data = data>>4; Serial.println(data);I think it is especially a problem with regular expression. Any advice or pointers would be great.
I wish there was a place where you just have to copy and paste my thong in and get a regular expression.
Do not use bytes to the port!
Take advantage of the termination character you have. Activate it on the series set up and set it to the newline character.
Now the VISA Read will wait until she has the entire line (or timeout if it does not). Then you can analyze your data out there.
I think the problem with your code, it's that you're looking for a backslash n. Not a line break. Turn it on the style of display of this constant and you will see it is fixed for normal display and backslash is no bar display.
-
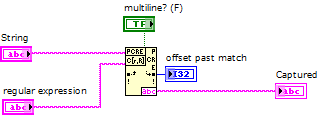
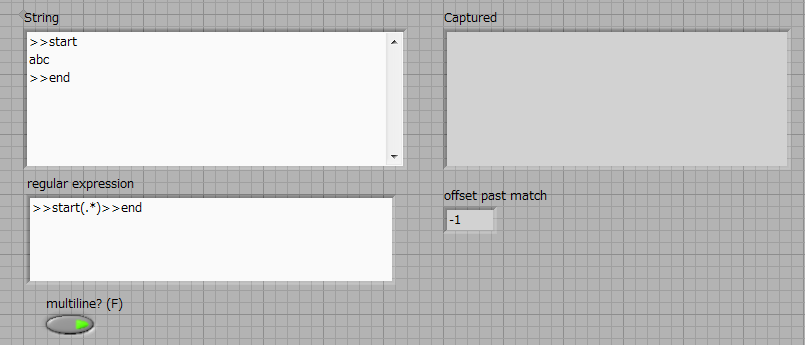
How to capture multiple line String using regular expressions?
Hello
I have a simple program like this:
What I want to accomplish is to capture everything between > start and > to end with a single regular expression matching node. It seems that the definition of multiples? true or False does not help.
I'm using LabVIEW 2012.
If it is impossible to capture using a single node, that's fine. But I want to assure you that I can make full use of this node without combining several others.
Thank you!
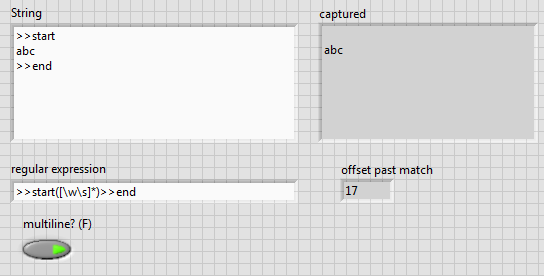
> start([\w\s]*) > end
A point matches any character except line break characters. You have two of them.
-
Regular Expressions do not work
With the help of sensors 4.X, VMS2.2
It seems that the normal regualar expressions are not accepted as valid by CiscoWorks. Example:
If I wanted to match for "Red Duck", but the number of spaces between each letter had to be 0-5 I would use spaces:
[R] {0-5} e [] {0-5} [d] {0-5} D {0-5} [] u] {0-5} [c] {0-5} k [] {0-5}
That the expression would be: R e d D uc k, Red D u c k and similar.
Why they are not allowed in String.TCP?
SO the question is, WHERE can find a list of regular expressions ACCEPTED, that works with sensors 4.X. I found a list that works with 3.X sensors... it did not work at all. Here, any help would be great.
Eric
Duck of red in google returns as red + duck in Google. Space will be replaced by a plus (+) sign or % 20 as it goes over HTTP (the browser for this).
The regular expression must be (including breaks):
[Rr] [+] * [Ee] [+] * [JJ] [+] * [JJ] [+] * [Uu] [+] * [Cc] [+] * [Kk]
You can't repeat a pattern of three characters like [%] 20.
-
Oracle regular expressions - splits the string into words for
Hello
Nice day!
My requirement is to split the string into words.
So I need to identify the new line character and the semicolon (;), comma and space like terminator for string entry.
Please note that I am currently embedded blank and the comma as separator, as shown below.
Select regexp_substr('test)
TO
string in words, "([^, [: blanc:]] +) (', 1, 1) double;"How to integrate the semicolons and line break characters in regular expression Oracle?
Please notify.
Thanks and greetings
Sree
This has nothing to do with REGEXP. Is SQL * more parser does not not a semicolon at the end of the line:
SQL > select ' testto, mm\;
ERROR:
ORA-01756: city not properly finished chainSQL >
Just break the chain:
SQL > select regexp_substr ('testto, mm\;' |) '
2 string into words
3 \w+',1,level ',') of double
4. connect by level<= regexp_count('testto,mm\;'="" ||="">
5 string in words
6 ','\w+')
7.REGEXP_SUBSTR ('TESTTO, MM\;' |') STRINGIN
--------------------------------------
Testto
mm
string
in
WordsSQL >
Or modify SQL * more the character of endpoints:
SQL > set sqlterm.
SQL > select regexp_substr ('testto, mm\;)
2 string into words
3 \w+',1,level ',') of double
4. connect by level<=>
5 string in words
6 ','\w+')
7.REGEXP_SUBSTR ('TESTTO, MM\;) STRINGINTOWO
--------------------------------------
Testto
mm
string
in
WordsSQL >
SY.
-
REGULAR EXPRESSION - names of Split.
Hello guys,.
I have a question about regular expressions. Here are some names:
WITH T AS ( SELECT 'Bill CLINTON' as name FROM dual UNION ALL SELECT 'Christiano RONALDO' FROM dual UNION ALL SELECT 'Barack Hussein OBAMA' FROM dual UNION ALL SELECT 'JUAN JOSE Miguel Ange' FROM dual UNION ALL SELECT 'Miguel Ange JUAN JOSE' FROM dual UNION ALL SELECT 'RONALDO Christiano' FROM dual ) SELECT name FROM t;
I want to break this chain. I want something like that
RESULT: Bill CLINTON Christiano RONALDO Barack Hussein OBAMA Miguel Ange JUAN JOSE Miguel Ange JUAN JOSE Christiano RONALDO
Is this possible? Any idea?
Thank you guys
This works with your data, but as Frank said, much more unusually still exists:
SQL> WITH T AS 2 ( 3 SELECT 'Bill CLINTON' as name FROM dual UNION ALL 4 SELECT 'Christiano RONALDO' FROM dual UNION ALL 5 SELECT 'Barack Hussein OBAMA' FROM dual UNION ALL 6 SELECT 'JUAN JOSE Miguel Ange' FROM dual UNION ALL 7 SELECT 'Miguel Ange JUAN JOSE' FROM dual UNION ALL 8 SELECT 'RONALDO Christiano' FROM dual UNION ALL 9 -- 10 SELECT 'M''BONGO Jesus' FROM dual UNION ALL 11 SELECT 'Jesus M''BONGO' FROM dual UNION ALL 12 SELECT 'Jean-Baptiste POQUELIN MOLIERE MANY OTHER NAMES' FROM dual UNION ALL 13 SELECT 'Jean Michel JARRE' FROM dual UNION ALL 14 SELECT 'JARRE HEAD Jean Michel' FROM dual 15 ) 16 SELECT rtrim(regexp_substr(name, '([[:upper:]'']{2,}[ -]*)+')) as last_name 17 , rtrim(regexp_substr(name, '([[:upper:]][[:lower:]]+[ -]*)+')) as first_name 18 FROM t; LAST_NAME FIRST_NAME -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- CLINTON Bill RONALDO Christiano OBAMA Barack Hussein JUAN JOSE Miguel Ange JUAN JOSE Miguel Ange RONALDO Christiano M'BONGO Jesus M'BONGO Jesus POQUELIN MOLIERE MANY OTHER NAMES Jean-Baptiste JARRE Jean Michel JARRE HEAD Jean Michel 11 rows selected. -
Find the words (wild cards) using regular expressions
I'm testing to see if the words are present for revision 1 of a drawing of the cartridge.
The script search the digit 1 followed by a date, a title, and 4 sets of initials.
The number 1 is static, (date, title and original are the cards that they are different for each design).
I use regular expressions to match the words.
The regular expression highlighted in blue is the number 1 and the date.
Him remains highlighted in orange does not match the title and initials.
If anyone can help with the regular expression that is most appreciated.
Once I got that work will add the form fields for the initials, noting only the console at this point for the tests.
numWords = this.getPageNumWords (0);
number of words on the page
loop through the words on the page
for (var j = 0; j < numWords-1; j ++)
{/ / get the pair of words to test}
ckWords = this.getPageNthWord (0, j) + ' ' + this.getPageNthWord (0, j + 1); test words
Check if 1 26.05.16 THE STRENGTHENING REVISED MM SB AE GM word string is present
If (ckWords.match(/ ^ 1\s [0-9] {1,2}.)) [0-9] {1,2}. [0-9] {2} \s\w+(\s+\w+){1,7}/))
{
Console.println (ckWords);
}
}
You can use something like this:
ckWords = this.getPageNthWord (0, j) + ' ' + this.getPageNthWord (j, 0, + 1) + ' ' + this.getPageNthWord (0, + 2 j) + ' ' + this.getPageNthWord (0, j + 3) + ' ' + this.getPageNthWord (0, j + 4) + ' ' + this.getPageNthWord (0, j + 5) + ' ' + this.getPageNthWord (0, j + 6);
If (! ckWords.match (/ ^ 1\s\d {1,2} \.\d {1,2} \.\d {2} \s\w+ (?:-s + \w +) {1.8} \s([A-Z]{2})\s([A-Z]{2})-s ([A - Z] {2}) \s([A-Z]{2})$ /)) ckWords + ckWords + "" + this.getPageNthWord (0, j + 7);
If (! ckWords.match (/ ^ 1\s\d {1,2} \.\d {1,2} \.\d {2} \s\w+ (?:-s + \w +) {1.8} \s([A-Z]{2})\s([A-Z]{2})-s ([A - Z] {2}) \s([A-Z]{2})$ /)) ckWords + ckWords + "" + this.getPageNthWord (0, j + 8);
If (ckWords.match (/ ^ 1\s\d {1,2} \.\d {1,2} {2} \s\w+ \.\d (?:-s + \w +) 1.8 ([A - Z] {2}) \s([A-Z]{2})\s([A-Z]{2})\s {} \s([A-Z]{2})$ /))
{
...
-
The regular expression problem
Dear friends,
In my script I have some sections that test the contents of an edit field before it is processed further.
Perfectly things like the following:
var re_Def = /#[A-Za-z][A-Za-z0-9_]+/; // valid variable name ? items = ["#correct", "notcorrect", "#This_is4", "#thisIs", "@something", "#ALLOK", "", ]; // search 0 -1 -1!! -1!! -1 -1!! -1 <--- incorrect method // test true false true true false true false <--- correct method for (var j = 0; j < items.length; j++) { var item = items[j]; alert ("'" + item + "' ==> " + item.search(re_Def) + "\n" + re_Def.test(item)); } var re_Def = /(\[ROW +\d+\]|\[COL +\d+\]|\[CELL +\d+, +\d+\]|Left *\(\d*\)|Right *\(\d*\)|Above *\(\d*\)|Below *\(\d*\))/; items = ["[ROW 17]", "[Row n]", "[ROW n]", "[CELL 3, 9]", "[CELL 3 9]", "Abbove()", "Right(3)"]; // result true false false true false false true for (var j = 0; j < items.length; j++) { alert ("'" + items[j] + "' ==> " + re_Def.test(items[j])); }But what follows always returns false, independly of the content of the string element:
var re_Def = /{[EFJ]\d*}|{I}/; // valid format def? var item = "{E27}"; var result = re_Def.test(item); alert (result); // false !!RegEx buddy told me, that
-l' REGULAR expression is correct
-the result must be true, not false-The verbose definition of the RegEx is:
Match is the following regular expression (attempting the next alternative only if this one fails) "{\d* [EYF]}."
Match the character "{" literally "{}".
Match a single character present in the list "J" "[EYF]."
Match a single digit 0. 9 paper"\d*»
Between zero and unlimited times, as many times as possible, giving as needed (greedy) «*»
Match the character "}" literally "}".
Or match number 2 below (the entire match attempt fails if it cannot match) regular expression "{i}".
Match the characters "{i}" literally "{i}".Typo unrecognized? Test the faulty method?
Results are fake, as soon as I use the list of characters []] - but look at the first block of code: there are also lists of character they are treated properly.
The braces in the regular expression must be escaped to be taken literally:
var re_Def = /\{[EFJ]\d*\}/;Kind regards
JoH
-
Regular Expressions of Drivng me crazy!
Oracle Version 11 GR 2
Scripts of test data
CREATE TABLE REGEX_TEST
(ID NUMBER 4,
VARCHAR2 (50) COMMENTS
);
Insert into REGEX_TEST (ID, COMMENTS) values (1, "< Little Red Riding Hood > #title");
Insert into REGEX_TEST (ID, COMMENTS) values (2, "#title < Little Red Riding Hood > #publisher < Penguin >");
Insert into REGEX_TEST (ID, COMMENTS) values (3, ' #title < Little Red Riding Hood > #publisher < Penguin > #pages < 30 > ");
Congratulations to Frank Kulash to provide the following SQL to clean the field of comments only properly marked the text in the field
Properly tagged text is defined as
Start by #.
then nameOfHashTag
then < valueOfHashTag >
The number or name of hashtags is variable and is not known at design time
The Frank provided SQL is (with a slight mod)
Original, SELECT comments
REGEXP_REPLACE (comments
, '(^|>)[^#.*<]*'
"\1") that cleaned
of REGEX_TEST;
Source language CLEANED #title < little Red Riding Hood > #title < little Red Riding Hood > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > FIRST QUESTION: I understand the [^ #. * <] * component - search for zero or more occurrences of anything that is not a # tracking of zero or more characters, then a < and I understand the () sets a capturing group, but I don't understand how it works - 1 is probably a reference to the Group?
Now, I add a few more - lines to see how he treats badly marked text that is
void <>
text that is not marked
text is not enclosed by sharp hooks
Insert into REGEX_TEST (ID, COMMENTS) values ('4, #title <>");
Insert into REGEX_TEST (ID, COMMENTS) values (5, "#title <>#publisher < Penguin >");
Insert into REGEX_TEST (ID, COMMENTS) values (6, "#title < Little Red Riding Hood > text that isn't marked < Penguin > #publisher");
Insert into REGEX_TEST (ID, COMMENTS) values (7, "#title oops I forgot #publisher < Penguin > rafters").
Original, SELECT comments
REGEXP_REPLACE (comments
, '(^|>)[^#.*<]*'
"\1") that cleaned
of REGEX_TEST;
Source language CLEANED #title < little Red Riding Hood > #title < little Red Riding Hood > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > #title <> #title <> #title <>#publisher < penguin > #title <>#publisher < penguin > #title < little Red Riding Hood > text that is not signposted #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #title oops I forgot the #publisher < Penguin > rafters #title oops I forgot the #publisher < Penguin > rafters SECOND QUESTION: Is there any way I can specify that the <>cannot be empty - I played a bit with the +? but impossible to get what I want. Similarly, the latter (without text no sharp hooks)-I guess this would be impossible because you don't know if it was wong, until you have met the # next date you would be somehow to follow back and ignore the whole group.
I learned two things in this
1. regular expressions are extremely powerful
2. but they will drive you crazy?
Once again thanks a lot for the help
BTW - I managed to do what I had to do it using a lot of PL/SQL code, but not very fast!
Hello
So, you want only the substrings that are well-formed attribute/value pairs (attribute or value may be missing). You want to ignore anything in the comments that is not part of a well-formed pair.
It is not very difficult to get a single well-formed pair. The problem is that there is no good way to say 'everything that is not part of a well-formed pair '. One solution is to extract from each pair trained well on a separate line and then re - combine them into a single string by id, like this:
WITH split_data AS
(
SELECT id
comments
REGEXP_SUBSTR (comments,
, '#' || -sign #.
'[^<]+' || ="" --="" 1="" or="" more="" of="" any="" characters="" except="">
'<' || ="" --=""><>
'[^>]+' || -1 or several characters any except >
'>' -- > sign
1
LEVEL
) AS well_formed_pair
LEVEL AS pair_num
OF regex_test
([LEVEL CONNECTION <= regexp_count="" (comments,=""> <> <[^>] + > ')
AND PRIOR id = id
AND PRIOR SYS_GUID () IS NOT NULL
)
SELECT id
commented THAT the original
LISTAGG (well_formed_pair) WITHIN GROUP (ORDER BY pair_num)
THAT cleaned
OF split_data
GROUP BY id, comments
ORDER BY id
;
The 2nd argument of REGEXP_SUBSTR above is actually the same as the 2nd argument of REGEXP_COUNT. I wrote one of them in a more detailed form, hoping to make it clear what happens if has been done. You can write an expression so be it.
The result is just what you asked:
ID CLEANED ORIGINAL
--- ---------------------------------------- ---------------------------------
1 #title#title 2 #title
#publisher #title #pu
blisher 3 #title
#publisher #title #pu
#pages<30> blisher #pages<30> 4 #title<>
5 #title<>#publisher
#publisher 6 #title
#title #pu text
is not marked #publisherblisher 7 #title oops I forgot that the rafters whoops # #title forgotten angle br
Editorackets #publisher -
I need help you rename a file using regular expressions in Bridge.
Hello
I work at a University, and we are working through files for our theses and Dissertations. We were renamed to make them more coherent. I wonder if there is a regular expression that could help in this process?
Examples come from current file names;
- THESIS H343G 1981
- Thesis of 1981 g996e
- THESIS-1981-A543G
I just need to change the actual file names. how they are formatted.
Where appropriate on the thesis.
Hyphens (-) in all white space.
First letter, last letter is lower case on appeal no (H343g)
If the list above should look like;
- Thesis-1981-H343g
- Thesis-1981-G996e
- Thesis-1981-A543g
I've seen people do some pretty cool things with regular expressions! Any help would be greatly appreciated. Thank you!
You would be better to use a script to do this as an example because I don't think it would be possible in the new name of bridge.
Using ExtendScript Toolkit or a text editor to copy the code in any event and save it to sub Filename.jsx
This must be recorded in the appropriate folder. It is located by going to preferences in Bridge, select Startup Scripts, this will open the folder where the script should be saved.
Once this is done close and restart Bridge.
Usage: Goto the Tools Menu and select Rename PDF files
Be sure to only test the code with some files copied to a separate first folder to make sure it's what you want.
The script will make all PDF files in the selected folder.
#target bridge if( BridgeTalk.appName == "bridge" ) { renamePDFs = MenuElement.create("command", "Rename PDFs", "at the end of Tools"); } renamePDFs.onSelect = function () { app.document.deselectAll(); var thumbs = app.document.getSelection("pdf"); for( var z in thumbs){ var Name = decodeURI(thumbs[z].spec.name); var parts = Name.toLowerCase().replace(/\s/g,'-').match(/(.*)(-)(.*)(-)(.*)(\.pdf)/); var NewName = parts[1].replace(/^[a-z]/, function(s){ return s.toUpperCase() }); NewName += parts[2]+parts[3]+parts[4]+parts[5].toUpperCase().replace(/[A-Z]$/, function(s){ return s.toLowerCase() }); NewName += parts[6]; thumbs[z].spec.rename(NewName); } }; -
AFExactMatch and regular Expressions
Hello
I'm working on something similar to this .
My first shot at it. Found it useful messages of try67 and George. I'm almost there and now, I'm stumped.
My Custom Format Script is the following:
Custom Format script for the text field
If (event.value) event.value += '% ';
My typing a custom Script is the following:
Custom keystroke script
DigOnlyKS();
My custom calculation script is the following:
If (event.value == "") event.value = 0;
My Javascript Document is:
function DigOnlyKS() {}
Get everything that is currently in the field
var val = AFMergeChange (event);
Refuse entry if other thing that the figures
Event.RC = AFExactMatch (/ \d* /, val);
Event.RC = AFExactMatch (/^100\.0| [1-9] {1,2}\.\d{1}|0\.\d{1}$/, val);
}
Valid entries must be: 100.0, 1.0 to 99.9, and 0.1 to 0.9.
The regular Expression seems to work on the Regex testers online.
However, I can't enter anything in the field with the foregoing.
If replace my Regex with the link above - ^ \d+\. ? \d{0,2}$ - I can enter data in the field.
However, if I remove the? the - ^\d+\.\d{0,2}$ - regex to require (I think) the decimal places, I can't enter anything in the field.
Clearly, Miss something.
Thank you.
Regular expression is not appropriate for a typo script until the value has been committed, and even in this case, it may be too restrictive (for example, does not allow for ".") 9 »).
The way I would be inclined to implement would be to put the strike and Validate Format (not calculate) scripts to call the following functions, respectively.
// Custom Keystroke script calls this function percent_ks() { AFNumber_Keystroke(1, 1, 0, 0, "", false); } // Custom Format script call this function percent_fmt() { AFNumber_Format(1, 1, 0, 0, "", false); if (event.value) event.value += "%"; } // Custom Validate script calls this function percent_val() { if (event.value === "") event.value = 0; // Only allow numbers from 0 to 100 if (+event.value >= 0 && +event.value <= 100) { // round to nearest tenth event.value = util.printf("%.1f", event.value); } else { event.rc = false; app.alert("Your error message goes here.", 3); } }It lets you enter values outside the valid range, but the validation script takes care of it. It also allows more than one digit to the right of the decimal, but the validation script it rounds up to the tenth closest. Make sense?
Edit: correction of fault
-
Regular expressions in the field of Validation does not.
I really hope someone can help me. I'm quite familiar with regular expressions, but for some reason, I can't it to work.
Environment: Windows XP
Adobe Acrobat version 8.12
Scenario:
In a text field of the form, the user enters a full path.
This is the code that runs when the user leaves the field:
/ * Test alternatives
var validChars = / ^ \w [:\\]$/
var validChars = / ^ \w :\\$/var validChars = / ^ [A - Z] [a - z] [0-9] [:\\_]$/
*/
var validChars = / ^ [A-Za-z0-9 :\\_]$/If (event.value! = "")
{
If ((event.value) validChars.test is false)
{
App.Alert ("Invalid character. Only alphanumeric, colon, underscore, backslask and spaces are valid characters. ») ;
Event.RC = false;
}
}The characters allowed in the path are: alphanumeric, underscore, colon, backslash (\), and space.
I tried all the expressions above with c:\aoa_apps and they all fail: alert the invalid character appears.
I've added alerts to print the event.value and that seems to be ok.
I tried all of them with c:aoa_apps and they still fail. Finally, I tried caoa_apps and they still aren't.
I checked each of the expressions in a small validator of expression that I have and they seem to be ok.
I'm cross-eyed looking for a reason why it's a failure. So, apparently, that I do something stupid, again, I'm new to scripting Adobe Acrobat. But for the life of me, I can't.
Can anyone spot the problem?
Any help is greatly appreciated.
caerial.
How you set up your regexp, only the first character is tested. Try
place a * before the $.
-
regular expressions in ActionScript?
I've been watching the Adobe programming Action Script (pdf) publication and it
Specifies the ECMA-262 3rd edition specification. But the specification do not seem
specify exactly what type of version and the regular expression engine is used.
Is - this POSIX or PERL compatible regular expressions (or both)?
I have read and used the classic O'Reilly Mastering Regular Expressions text
and regular expressions encoded in javascript/php/etc. (regular expressions anywhere
can be used, Apache configuration file, other server configuration files, etc. etc. etc.)
There is a difference in the type of engine used, while the performance is
concerned, as well as the range of syntax is valid to a particular implementation.
Thank you
JK
Maybe you are looking for
-
Problem to use the stylus on the Libretto W100
I'm afraid because I bought the booklet model w100, but I can't effectively use any pen can someone help me? Thank you very much!!!
-
Satellite L505-141 - update the display driver?
I want to update the 5156 ATI mobility radeon video card driver. I checked in the Device Manager the driver already installed on my machine, the version of it is 8.653, similar to that offered by download herehttp://EU.computers.Toshiba-Europe.com/in
-
Help! I deleted all MyRIO software and it is stuck in safe mode
Hello In the NI MAX interface, I saw that there was a new version of the software to intall, in the section where it is possible to add and remove items from software to MyRIO among a list with checkboxes. The last option in this list was something l
-
HP Pavilion DV4 Entertainment Note book - adapter specification - reg 1502TU
Mr President I bought HP Pavilion laptop DV4 Entertainment Notebook 1502TU on 3.2.2010... I lost the charger / adapter. I want to buy a new one. So I wan t to know the specifications of the compatible charger/adapter to the laptop. Please guide me gi