Sequential read
I have a 8 GB fuze and spent a lot of time editing the ID3Tags. I edited the tags secifically so that when you goto ALBUMS to music in a specific order. The problem is that if I choose 'say' 10th album, he plays on this album, but does not proceed to the next album automatically. Is there a simple way to do this, or I asking to much. I know that if I chose to PLAY ALL that I could manually flip through all the songs until I got to the place where I want to start, but it's tedious rediculously. And don't tell me about setting up playlists, because this isn't an option.
OK, the list go is your friend now. Hold each album you want to add to the list and start the list go, he's going to play all the songs in the album or random order if you prefer.
Tags: SanDisk Sansa
Similar Questions
-
DB file sequential reads on the table scan complete and LRU (new)
I would like to add a question on the subject
According to MOS doc ument 1457693.1
«.. signs diluvium readings of the caching blocks can be divided into a number of small multiblock and self-contained bed. »
The question is if sequential readings of db file submitted by a FULL SCAN operation will be cached on LRU or MRU list?
I'm afraid the flushes of heat/floods the buffer cache with a lot of FULL SCAN db file sequential reads.
For which direct path series reason readings will be inapplicable, so using this new feature of 11g is out of scope for this question.
Thank you for your interest,
Rainer Stenzel
There are a few different patterns of behavior depends on the size of the table (relative to the size of the buffer cache), but the key question is probably "readings will increment the counter of touch" - because if they are not the blocks will fall the LRU list fairly quickly, if they do then the blocks could (after a few tablescans) eventually be promoted in half hot from the cache.
I did some quick tests (that requires a little care in the Installer) which suggest the number touch was not incremented has therefore not had any effect on the question of if the block would get preferential treatment when they have reached the end of the LRU.
I'm a little puzzled by your expression: "cached on LRU or MRU list" - it's not two different lists; but people talk about "the end of the MRU of the LRU list.
Concerning
Jonathan Lewis
-
DB file sequential read and read of the direct path
Hello
Could someone please clear my doubts about 'db file sequential read' and ' path direct reading. And help me understand the tkprof report correctly.
Please suggest if my understanding for scenario below is correct.
We have a 11.2.0.1 ' cluster 2 node rac version + asm' production and environment of his test environment that is a stand-alone database.
The query performs well in production compared to the test database.
The table is to have 254 + columns (264) with many lobs coulumns however LOB is not currently selected in the query.
I read in metalink this 254 table + column a intra-line-chaining, causing "db file sequential read" full table Scan.
Here are some details on the table which is similar to the prod and test, block size is 8 k:
What I understand less tkprof in production environment for a given session is:TABLE UNUSED BLOCKS TOTAL BLOCKS HIGH WATER MARK ------------------------------ --------------- --------------- --------------- PROBSUMMARYM1 0 17408 17407
1 - the request resulted in disk 19378 readings and 145164 consistent readings.
2 19378 disc bed, 2425 reads disc has given rise to the wait event 'db file sequential read'.
This statement is correct this disc remaining readings were "db file sequential reads" but real quick so didn't wait event tied to it?
3 - 183 'direct path read' there also. Is it because of the order by clause of the query?
The same query when ran in no no rac - asm test stand alone database has given below tkprof.SQL ID: 72tvt5h4402c9 Plan Hash: 1127048874 select "NUMBER" num from smprd.probsummarym1 where flag ='f' and affected_item = 'PAUSRWVP39486' order by num asc call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 1 0.53 4.88 19378 145164 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 3 0.53 4.88 19378 145164 0 0 Misses in library cache during parse: 0 Optimizer mode: ALL_ROWS Parsing user id: SYS Rows Row Source Operation ------- --------------------------------------------------- 0 SORT ORDER BY (cr=145164 pr=19378 pw=0 time=0 us cost=4411 size=24 card=2) 0 TABLE ACCESS FULL PROBSUMMARYM1 (cr=145164 pr=19378 pw=0 time=0 us cost=4410 size=24 card=2) Elapsed times include waiting on following events: Event waited on Times Max. Wait Total Waited ---------------------------------------- Waited ---------- ------------ SQL*Net message to client 1 0.00 0.00 ges message buffer allocation 3 0.00 0.00 enq: KO - fast object checkpoint 2 0.00 0.00 reliable message 1 0.00 0.00 KJC: Wait for msg sends to complete 1 0.00 0.00 Disk file operations I/O 1 0.00 0.00 kfk: async disk IO 274 0.00 0.00 direct path read 183 0.01 0.72 db file sequential read 2425 0.05 3.71 SQL*Net message from client 1 2.45 2.45
Does this mean that:
1-here too, reads happen through "db file sequential read", but they were so fast that has failed to the wait event?
2. "direct path read," it's because of the order clause in the query. "
For trace files in the database Production and Test, I see that 'direct path read' is against the same data file that's stored table.SQL ID: 72tvt5h4402c9 Plan Hash: 1127048874 select "NUMBER" num from smprd.probsummarym1 where flag ='f' and affected_item = 'PAUSRWVP39486' order by num asc call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 1 0.00 0.06 0 0 0 0 Fetch 1 0.10 0.11 17154 17298 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 3 0.10 0.18 17154 17298 0 0 Misses in library cache during parse: 0 Optimizer mode: ALL_ROWS Parsing user id: SYS Rows Row Source Operation ------- --------------------------------------------------- 0 SORT ORDER BY (cr=17298 pr=17154 pw=0 time=0 us cost=4694 size=12 card=1) 0 TABLE ACCESS FULL PROBSUMMARYM1 (cr=17298 pr=17154 pw=0 time=0 us cost=4693 size=12 card=1) Elapsed times include waiting on following events: Event waited on Times Max. Wait Total Waited ---------------------------------------- Waited ---------- ------------ SQL*Net message to client 1 0.00 0.00 Disk file operations I/O 1 0.00 0.00 db file sequential read 3 0.00 0.00 direct path read 149 0.00 0.03 SQL*Net message from client 1 2.29 2.29
Then how come 'this direct path read' because of the order by clause of the query and would have been in sort field size or pga?
Or this direct path read extracts real PGA disk data, and "db file sequential read" do not extract data?
I know, it's 'direct path read' is wait event when data are asked in PGA drive or what kind segment or temp tablespace is used.
Here is the example of trace file in the Production database:
Here are the trace file for the test database:*** 2013-01-04 13:49:15.109 WAIT #1: nam='SQL*Net message from client' ela= 11258483 driver id=1650815232 #bytes=1 p3=0 obj#=-1 tim=1357278555109496 CLOSE #1:c=0,e=9,dep=0,type=1,tim=1357278555109622 ===================== PARSING IN CURSOR #1 len=113 dep=0 uid=0 oct=3 lid=0 tim=1357278555109766 hv=138414473 ad='cfc02ab8' sqlid='72tvt5h4402c9' select "NUMBER" num from smprd.probsummarym1 where flag ='f' and affected_item = 'PAUSRWVP39486' order by num asc END OF STMT PARSE #1:c=0,e=98,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1,plh=1127048874,tim=1357278555109765 EXEC #1:c=0,e=135,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1,plh=1127048874,tim=1357278555109994 WAIT #1: nam='SQL*Net message to client' ela= 2 driver id=1650815232 #bytes=1 p3=0 obj#=-1 tim=1357278555110053 WAIT #1: nam='ges message buffer allocation' ela= 3 pool=0 request=1 allocated=0 obj#=-1 tim=1357278555111630 WAIT #1: nam='enq: KO - fast object checkpoint' ela= 370 name|mode=1263468550 2=65610 0=1 obj#=-1 tim=1357278555112098 WAIT #1: nam='reliable message' ela= 1509 channel context=3691837552 channel handle=3724365720 broadcast message=3692890960 obj#=-1 tim=1357278555113975 WAIT #1: nam='ges message buffer allocation' ela= 2 pool=0 request=1 allocated=0 obj#=-1 tim=1357278555114051 WAIT #1: nam='enq: KO - fast object checkpoint' ela= 364 name|mode=1263468550 2=65610 0=1 obj#=-1 tim=1357278555114464 WAIT #1: nam='KJC: Wait for msg sends to complete' ela= 9 msg=3686348728 dest|rcvr=65536 mtype=8 obj#=-1 tim=1357278555114516 WAIT #1: nam='ges message buffer allocation' ela= 2 pool=0 request=1 allocated=0 obj#=-1 tim=1357278555114680 WAIT #1: nam='Disk file operations I/O' ela= 562 FileOperation=2 fileno=6 filetype=2 obj#=85520 tim=1357278555115710 WAIT #1: nam='kfk: async disk IO' ela= 5 count=1 intr=0 timeout=4294967295 obj#=85520 tim=1357278555117332 *** 2013-01-04 13:49:15.123 WAIT #1: nam='direct path read' ela= 6243 file number=6 first dba=11051 block cnt=5 obj#=85520 tim=1357278555123628 WAIT #1: nam='db file sequential read' ela= 195 file#=6 block#=156863 blocks=1 obj#=85520 tim=1357278555123968 WAIT #1: nam='db file sequential read' ela= 149 file#=6 block#=156804 blocks=1 obj#=85520 tim=1357278555124216 WAIT #1: nam='db file sequential read' ela= 155 file#=6 block#=156816 blocks=1 obj#=85520 tim=1357278555124430 WAIT #1: nam='db file sequential read' ela= 4826 file#=6 block#=156816 blocks=1 obj#=85520 tim=1357278555129317 WAIT #1: nam='db file sequential read' ela= 987 file#=6 block#=156888 blocks=1 obj#=85520 tim=1357278555130427 WAIT #1: nam='db file sequential read' ela= 3891 file#=6 block#=156888 blocks=1 obj#=85520 tim=1357278555134394 WAIT #1: nam='db file sequential read' ela= 155 file#=6 block#=156912 blocks=1 obj#=85520 tim=1357278555134645 WAIT #1: nam='db file sequential read' ela= 145 file#=6 block#=156920 blocks=1 obj#=85520 tim=1357278555134866 WAIT #1: nam='db file sequential read' ela= 234 file#=6 block#=156898 blocks=1 obj#=85520 tim=1357278555135332 WAIT #1: nam='db file sequential read' ela= 204 file#=6 block#=156907 blocks=1 obj#=85520 tim=1357278555135666 WAIT #1: nam='kfk: async disk IO' ela= 4 count=1 intr=0 timeout=4294967295 obj#=85520 tim=1357278555135850 WAIT #1: nam='direct path read' ela= 6894 file number=6 first dba=72073 block cnt=15 obj#=85520 tim=1357278555142774 WAIT #1: nam='db file sequential read' ela= 4642 file#=6 block#=156840 blocks=1 obj#=85520 tim=1357278555147574 WAIT #1: nam='db file sequential read' ela= 162 file#=6 block#=156853 blocks=1 obj#=85520 tim=1357278555147859 WAIT #1: nam='db file sequential read' ela= 6469 file#=6 block#=156806 blocks=1 obj#=85520 tim=1357278555154407 WAIT #1: nam='db file sequential read' ela= 182 file#=6 block#=156826 blocks=1 obj#=85520 tim=1357278555154660 WAIT #1: nam='db file sequential read' ela= 147 file#=6 block#=156830 blocks=1 obj#=85520 tim=1357278555154873 WAIT #1: nam='db file sequential read' ela= 145 file#=6 block#=156878 blocks=1 obj#=85520 tim=135727855515
Thanks & Rgds,*** 2013-01-04 13:46:11.354 WAIT #1: nam='SQL*Net message from client' ela= 10384792 driver id=1650815232 #bytes=1 p3=0 obj#=-1 tim=1357278371354075 CLOSE #1:c=0,e=3,dep=0,type=3,tim=1357278371354152 ===================== PARSING IN CURSOR #1 len=113 dep=0 uid=0 oct=3 lid=0 tim=1357278371363427 hv=138414473 ad='c7bd8d00' sqlid='72tvt5h4402c9' select "NUMBER" num from smprd.probsummarym1 where flag ='f' and affected_item = 'PAUSRWVP39486' order by num asc END OF STMT PARSE #1:c=0,e=9251,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1,plh=1127048874,tim=1357278371363426 EXEC #1:c=0,e=63178,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1,plh=1127048874,tim=1357278371426691 WAIT #1: nam='SQL*Net message to client' ela= 2 driver id=1650815232 #bytes=1 p3=0 obj#=-1 tim=1357278371426766 WAIT #1: nam='Disk file operations I/O' ela= 1133 FileOperation=2 fileno=55 filetype=2 obj#=93574 tim=1357278371428069 WAIT #1: nam='db file sequential read' ela= 51 file#=55 block#=460234 blocks=1 obj#=93574 tim=1357278371428158 WAIT #1: nam='direct path read' ela= 31 file number=55 first dba=460235 block cnt=5 obj#=93574 tim=1357278371428956 WAIT #1: nam='direct path read' ela= 47 file number=55 first dba=136288 block cnt=8 obj#=93574 tim=1357278371429099 WAIT #1: nam='direct path read' ela= 80 file number=55 first dba=136297 block cnt=15 obj#=93574 tim=1357278371438529 WAIT #1: nam='direct path read' ela= 62 file number=55 first dba=136849 block cnt=15 obj#=93574 tim=1357278371438653 WAIT #1: nam='direct path read' ela= 17 file number=55 first dba=136881 block cnt=7 obj#=93574 tim=1357278371438750 WAIT #1: nam='direct path read' ela= 35 file number=55 first dba=136896 block cnt=8 obj#=93574 tim=1357278371438855 WAIT #1: nam='direct path read' ela= 22 file number=55 first dba=136913 block cnt=7 obj#=93574 tim=1357278371438936 WAIT #1: nam='direct path read' ela= 19 file number=55 first dba=137120 block cnt=8 obj#=93574 tim=1357278371439029 WAIT #1: nam='direct path read' ela= 36 file number=55 first dba=137145 block cnt=7 obj#=93574 tim=1357278371439114 WAIT #1: nam='direct path read' ela= 18 file number=55 first dba=137192 block cnt=8 obj#=93574 tim=1357278371439193 WAIT #1: nam='direct path read' ela= 16 file number=55 first dba=137201 block cnt=7 obj#=93574 tim=1357278371439252 WAIT #1: nam='direct path read' ela= 17 file number=55 first dba=137600 block cnt=8 obj#=93574 tim=1357278371439313 WAIT #1: nam='direct path read' ela= 15 file number=55 first dba=137625 block cnt=7 obj#=93574 tim=1357278371439369 WAIT #1: nam='direct path read' ela= 22 file number=55 first dba=137640 block cnt=8 obj#=93574 tim=1357278371439435 WAIT #1: nam='direct path read' ela= 702 file number=55 first dba=801026 block cnt=126 obj#=93574 tim=1357278371440188 WAIT #1: nam='direct path read' ela= 1511 file number=55 first dba=801154 block cnt=126 obj#=93574 tim=1357278371441763 WAIT #1: nam='direct path read' ela= 263 file number=55 first dba=801282 block cnt=126 obj#=93574 tim=1357278371442547 WAIT #1: nam='direct path read' ela= 259 file number=55 first dba=801410 block cnt=126 obj#=93574 tim=1357278371443315 WAIT #1: nam='direct path read' ela= 294 file number=55 first dba=801538 block cnt=126 obj#=93574 tim=1357278371444099 WAIT #1: nam='direct path read' ela= 247 file number=55 first dba=801666 block cnt=126 obj#=93574 tim=1357278371444843 WAIT #1: nam='direct path read' ela= 266 file number=55 first dba=801794 block cnt=126 obj#=93574 tim=1357278371445619
Vijay911786 wrote:
Direct path readings can be done on the series tablescans in your version of Oracle, but if you have chained rows in the table and then Oracle can read read read the beginning of the line in the path directly, but must make a single block in the cache (the db file sequential read) to get the next part of the line.
It is possible that your production system has a lot of chained rows, while your test system is not. As corroboration (though not convincing) indicator of what you might notice that if you take (reads disc - db file sequential reads) - who might get you close to all the blocks direct read - the numbers are very similar.
I'm not 100% convinced that it's the answer for the difference in behavior, but worth a visit. If you can force and indexed access path in the table, do something like "select / * + index (use {pk}) * / max table (last_column_in_table)" and check the number of "table fetch continued lines" could be close to the number of db file sequential reads you. (There are other options for the counting of the chained rows that could be faster).
Concerning
Jonathan Lewis -
"the db file sequential read" waiting for event slow down an application.
"the db file sequential read" waiting for event slow down an application.
It is a rather strange problem. There is an update statement that hangs on the wait event 'db file sequential read' and until you restart the database, the query works fine. It happens once a week, usually Monday or after several days of large amount of work.
I checked the processor and is fine, memory is very good, although the SGA and PGA have taken maximum memory. Flow of the disc seems to be ok since each another session on the basis of data looks very good.
I guess that there is a missing configuration to avoid having to restart the database each week.
Any help is greatly appreciated.Hello
If you want same order of the tables as plain exp after reboot just go with ordered hint
UPDATE item_work_step SET user_name = :b1, terminal = SYS_CONTEXT ('USERENV', 'TERMINAL'), status_cd = 'IN PROCESS' WHERE item_work_step_route_id = (SELECT item_work_step_route_id FROM (SELECT /*+ORDERED */ iws.item_work_step_route_id FROM user_role ur, work_step_role wsr, work_step ws, app_step aps, item_work_step iws, item_work iw, item i WHERE wsr.role_cd = ur.role_cd AND ws.work_step_id = wsr.work_step_id AND aps.step_cd = ws.step_cd AND iws.work_step_id = ws.work_step_id AND iws.work_id = ws.work_id AND iws.step_cd = ws.step_cd AND iws.status_cd = 'READY' AND iw.item_work_id = iws.item_work_id AND iw.item_id = iws.item_id AND iw.work_id = iws.work_id AND i.item_id = iws.item_id AND i.item_id = iw.item_id AND i.deleted = 'N' AND i.item_type_master_cd = :b3 AND ur.user_name = :b1 AND aps.app_name = :b2 AND ( iws.assignment_user_or_role IS NULL OR ( iws.assignment_user_or_role IN ( SELECT ur.role_cd FROM user_role ur WHERE ur.user_name = :b1 UNION ALL SELECT :b1 FROM dual) AND iws.assignment_expiration_time > SYSDATE ) OR ( iws.assignment_user_or_role IS NOT NULL AND iws.assignment_expiration_time <= SYSDATE ) ) AND (iws.pend_date IS NULL OR iws.pend_date <= SYSDATE ) ORDER BY aps.priority, LEAST (NVL (iw.priority, 9999), NVL ((SELECT NVL (priority, 9999) FROM item_work WHERE item_id = i.parent_id AND work_id = 42), 9999 ) ), DECODE (i.a3, NULL, 0, 1), NVL (iw.sla_deadline, (SELECT sla_deadline FROM item_work WHERE item_id = i.parent_id AND work_id = 42) ), i.parent_id, i.item_id) unclaimed_item_work_step WHERE ROWNUM <= 1)If you want to get rid of the nested loops use USE_HASH
UPDATE item_work_step SET user_name = :b1, terminal = SYS_CONTEXT ('USERENV', 'TERMINAL'), status_cd = 'IN PROCESS' WHERE item_work_step_route_id = (SELECT item_work_step_route_id FROM (SELECT /*+ORDERED USE_HASH(ur wsr ws aps iws iw i) */ iws.item_work_step_route_id FROM user_role ur, work_step_role wsr, work_step ws, app_step aps, item_work_step iws, item_work iw, item i WHERE wsr.role_cd = ur.role_cd AND ws.work_step_id = wsr.work_step_id AND aps.step_cd = ws.step_cd AND iws.work_step_id = ws.work_step_id AND iws.work_id = ws.work_id AND iws.step_cd = ws.step_cd AND iws.status_cd = 'READY' AND iw.item_work_id = iws.item_work_id AND iw.item_id = iws.item_id AND iw.work_id = iws.work_id AND i.item_id = iws.item_id AND i.item_id = iw.item_id AND i.deleted = 'N' AND i.item_type_master_cd = :b3 AND ur.user_name = :b1 AND aps.app_name = :b2 AND ( iws.assignment_user_or_role IS NULL OR ( iws.assignment_user_or_role IN ( SELECT ur.role_cd FROM user_role ur WHERE ur.user_name = :b1 UNION ALL SELECT :b1 FROM dual) AND iws.assignment_expiration_time > SYSDATE ) OR ( iws.assignment_user_or_role IS NOT NULL AND iws.assignment_expiration_time <= SYSDATE ) ) AND (iws.pend_date IS NULL OR iws.pend_date <= SYSDATE ) ORDER BY aps.priority, LEAST (NVL (iw.priority, 9999), NVL ((SELECT NVL (priority, 9999) FROM item_work WHERE item_id = i.parent_id AND work_id = 42), 9999 ) ), DECODE (i.a3, NULL, 0, 1), NVL (iw.sla_deadline, (SELECT sla_deadline FROM item_work WHERE item_id = i.parent_id AND work_id = 42) ), i.parent_id, i.item_id) unclaimed_item_work_step WHERE ROWNUM <= 1)and for small tables, you can try adding for example FULL (your) FULL (wsr)
It can be rewritten in a different way, but it's the fastest way to try how query will be if you rewrite it. Check the explain plan command if certain partially ordered tables are not joined because you can get the Cartesian join, it seems that it will be ok.
View query result in the em console.
Concerning
-
Reason for 'control file sequential read' wait?
Hello
We have a 10.2.0.4.0 2. node RAC database on Windows 2003 (all 64-bit).
By looking at the 'top 5 timed events' section AWR reports (for 1 hour), we still see the 'time of CPU", as the number one event (due to our application, certain questions if all goes well in the study now by developers...), but recently I see"sequential read from the command file"as the event number two, with 3 574 633 expects and 831 time s. I was hoping to find out what was causing this high number of expectations. I started by trying to find a particular query that has experienced this expectation often, so I ran this SQL:
As I hoped, the sql_id top of page returned really stands out, with an equal number of 14 182 (the next sql_id has a counter of 68). This is the text of the sql for this id:select sql_id, count(*) from dba_hist_active_sess_history where event_id = (select event_id from v$event_name where name = 'control file sequential read') group by sql_id order by 2 desc ;
(Ok, code a little strange, but I already have them change it.)WITH unit AS( SELECT UNIQUE S.unit_id FROM STOCK S, HOLDER H WHERE H.H_ID = S.H_ID AND H.LOC_ID = :B2 AND S.PROD_ID = :B1 ) SELECT DECODE((SELECT COUNT(*) FROM unit), 1, unit_ID, NULL) FROM unit WHERE ROWNUM = 1 ;
My question is:
Why / what is this code should read in the control file?
Kind regards
ADOS
PS - I also checked the block number in dba_hist_active_sess_history for this sql_id and event_id p2, and it is still one of the 5 blocks in the controlfile. I've spilled the controlfile, but do not see anything interesting (even if it is true, it is the first time I've thrown a controlfile so have no idea really what to do!).Hello
ADO wrote:
WITH unit AS( SELECT UNIQUE S.unit_id FROM STOCK S, HOLDER H WHERE H.H_ID = S.H_ID AND H.LOC_ID = :B2 AND S.PROD_ID = :B1 ) SELECT DECODE((SELECT COUNT(*) FROM unit), 1, unit_ID, NULL) FROM unit WHERE ROWNUM = 1 ;This query contains a subquery factoring clause; and as it refers to the unit twice in the main part, chances are subquery factoring is to be materialized in a global temporary table in the schema SYS with SYS_TEMP_ Name% and is accessible on two occasions in the execution plan later (check presence stage of TRANSFORMATION TABLE TEMP). The step of filling of this intermediate table requires you to write in the temporary tablespace - and it's done via direct writing. Each direct entry to the segment (i.e. directly in the file on the disk) requires a data file status check - what is online or offline - that is done by access control files. So you see these expectations. This is one of the many things why subquery factoring is not good for production OLTP environments.
-
query on dba_free_space ends waiting for events db file sequential read
Hi all
Env: 10gr 2 on Windows NT
I gave the query
Select tablespace_name, sum (bytes) / 1024/1024 dba_free_space group by tablespace_name and her for still waiting.
I checked the event waiting for v$ session and «db file sequential read»
I put a trace on the session before launching the above query:
I took the AWR report (for 1 hour) and the top 5 events are out like,
OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
-----
Parse 1 0.06 0.06 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 0 0.00 0.00 0 0 0 0
-----
total 2 0.06 0.06 0 0 0 0
Misses in library cache during parse: 1
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
----------------------------------------
db file sequential read 13677 0.16 151.34
SQL*Net message to client 1 0.00 0.00
db file scattered read 281 0.01 0.53
latch: cache buffers lru chain 2 0.00 0.00
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------
Parse 13703 0.31 0.32 0 0 0 0
Execute 14009 0.75 0.83 0 0 0 0
Fetch 14139 0.48 0.74 26 56091 0 15496
------
total 41851 1.54 1.89 26 56091 0 15496
Misses in library cache during parse: 16
Misses in library cache during execute: 16
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
----------------------------------------
db file sequential read 26 0.00 0.12
1 user SQL statements in session.
14010 internal SQL statements in session.
14011 SQL statements in session.
Event Waits Time (s) (ms) Time Wait Class
The PHYRDS (from dba_hist_filestatxs) on my system01.dbf is 161,028,980 for the final nod.
------
db file sequential read 1,134,643 7,580 7 56.8 User I/O
db file scattered read 940,880 5,025 5 37.7 User I/O
CPU time 967 7.2
control file sequential read 4,987 3 1 0.0 System I/O
control file parallel write 2,408 1 1 0.0 System I/O
Could someone shed some light on what is happening here?
TIA,
JJIn certain circumstances, questioning the dictionary can be slow, usually due to problems with bad bad statistics-related implementation plans, trying to collect statistics using dbms_stats.gather_fixed_objects_stats (); It has worked for me before.
You can also read Note 414256.1 poor performance for Tablespace Page in Grid Control display Console that also indicates a possible problem with the trash.HTH
Enrique
-
Sequential read of several record stores
I'm a newbie using OEID 3.0 and crawled of CloverETL to store some data (using IAS) in the field of data. I am analyzes each Web site in a separate record store, and I encountered this problem in CloverETL I can't solve:
So I have several record stores (rs1, rs2,..., rs1000), and what I have to do is run a graph (the same graph) sequentially to all those record stores, by means of changing the name of component record store 'Record store Reader. " The chart simply stores RS data in a data field. Could you help me how to do this? Basically, I need a loop to re-run the graph each time by changing the 'Instance of record bank' property on each iteration.
Thank you!
I noticed that you said you were doing with IAS Web site analysis (as opposed to the CMS analysis or file system). In the analysis of Web site, personally, always out of analysis of XML instead of a recordstore. As the webcrawls have not any mechanism of CDC (change data capture) you find yourself really lead the entire analysis whenever there is no way to detect the page website for only analyze this change that changed incrementally. For the analysis of file system and the CMS analysis, recordstores are very discount to accomplish and follow the gradual change.
So, if you decide, like me, to the output in XML format to the analysis of your Web site, you can waive the reading of the RS and simply use an XML reader to retrieve several XML files.
HTH,
Dan
-
sequential reading of the image and plot greyscale
Hi all
I have attached a VI wrote in LV version 8.2. All I am trying to make bed image sequence from a specified location in the PC and get the value in pixels for those of all of the images and want to save it in a file. When I run the vi it says error - 1074395995 IMAQ read file not found.
Any help would be appreciated.
Hi Theresa,
As Andrey says put the extension on the end and it works. for example, change:
'C:\Documents and Settings\Administrator\Desktop\Modulation speckle depth for Malinowski to low frequency\2Hz2.8Vpk-pkRHOE\2Hz20001' to
"C:\Documents and Settings\Administrator\Desktop\Modulation depth of speckle to Malinowski to low frequency\2Hz2.8Vpk-pkRHOE\2Hz20001.jpg.
or any file format are your photos.
Thank you
-
Sequential read of a collection
Hello!
I defined a collection in this way...
TYPE TABLA_SITUACION_TRIB_ACT IS TABLE OF INDEX VARCHAR2 (2) BY VARCHAR2 (10);
g_SituacionesDeclaActual TABLA_SITUACION_TRIB_ACT;
When I load this collection...
How to read this collection in order?
Of course the next "solution" does not work... :-)
BECAUSE me IN 1.g_tabla_situacion_trib. COUNTY
LOOP
v_valor: = G_TABLA_SITUACION_TRIB (i). COD_DECE_SITR;
END LOOP;SQL> declare 2 TYPE TABLA_SITUACION_TRIB_ACT IS TABLE OF VARCHAR2(2) INDEX BY VARCHAR2(10); 3 g_SituacionesDeclaActual TABLA_SITUACION_TRIB_ACT; 4 idx varchar2(10); 5 begin 6 g_SituacionesDeclaActual ('a') := 'aa'; 7 g_SituacionesDeclaActual ('b') := 'bb'; 8 g_SituacionesDeclaActual ('c') := 'cc'; 9 idx := g_SituacionesDeclaActual.first; 10 while idx is not null 11 loop 12 dbms_output.put_line ('Result: '||g_SituacionesDeclaActual(idx)); 13 idx := g_SituacionesDeclaActual.next(idx); 14 end loop; 15 end; 16 / Result: aa Result: bb Result: cc PL/SQL procedure successfully completed. -
Read multiple files in the folder and add data to a file
Hello world
Normal 0 false false false MicrosoftInternetExplorer4 / * Style Definitions * / table. MsoNormalTable {mso-style-name: "Table Normal" "; mso-knew-rowband-size: 0; mso-knew-colband-size: 0; mso-style - noshow:yes; mso-style-parent:" ";" mso-padding-alt: 0 cm 0 cm 5.4pt 5.4pt; mso-para-margin: 0 cm; mso-para-margin-bottom: .0001pt; mso-pagination: widow-orphan; do-size: 10.0pt; do-family: "Times New Roman"; mso-ansi-language: #0400; mso-fareast-language: #0400; mso-bidi-language: #0400 ;} "}
I have several (hundreds) text files in a folder. I want to combine the data of the files into a single file. It must of course begin to file the oldest and sequentially read the files to the latest changes and add all the data in a new txt file.
Here are the typical two consecutive files comma separated data:
2009-02-17, 23:17:04, ff1c, 00ff, 0093, 0000, 0100 and 0001-ffff, d3ae, 0cce, 0 cd 4, DC 4, 00 c 2 0, 000 a, 09e4, 0609, 0000 and 0000, 17 c 7
2009-02-17, 23:17:06, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3af, DC 0 5, 0 cd 7, 0ccf, 00C 2, 000e, 09e6, 0608, 0003, 0000, 17 c 7
2009-02-17, 23:17:09, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3b0, 0 cd 2, cd 0 1, 0 cd 5, 00bb, 000d, 09f1, 0608, 0000 and 0000, 17 c 7
2009-02-17, 23:17:11, ff1c, 00ff, 0093, 0000, 0100 and 0001-ffff, d3b1, 0c 21, 0ccf, 0 cd 3, 00 c 2, 000 a, 09e3, 0608, 0000 and 0000, 17 c 7
2009-02-17, 23:17:14, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3b2, 0cc9, DC 0 5, 0 cd 7, 00 c 4, 0008, 09e4, 0608, 0000, 0002, 17 c 8
2009-02-17, 23:17:16, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3b3, 0 cd 2, cd 0 6, 0 cd 7, 00bf, 000d, 09eb, 0608, 0000 and 0000, 17 c 8
2009-02-17, 23:17:19, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3b4, 0cc9, 0 cd 8, 0 cd 2, 00 c 2, 0009, 09ea, 0608, 0000 and 0000, 17 c 8
2009-02-17, 23:17:21, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3b5, 0 cd 2, cd 0 1, 0 cd 1, 00 c 2, 0009, 09e8, 0608, 0000, 0001, 17 c 82009-02-17, 23:17:24, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3b6, 0 cd 3, cd 0 3, 0 cd 3, 00, 000d, 09eb, 0608, 0001, 0001, 17 c 9
2009-02-17, 23:17:26, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3b7, 0ccd, 0 cd 8, 0 cd 4, 00bc, 0006, 09e6, 0608, 0001, 0003, 17 c 8
2009-02-17, 23:17:29, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3b8, 0 cd 2, cd 0 3, 0 cd 3, 00C6, 000d, 09e9, 0608, 0001, 0001, 17 c 9
2009-02-17, 23:17:31, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3b9, 0ccf, DC 0 3 0 cd 4, 00ba, 000d, 09e8, 0608, 0000 and 0000, 17 c 8
2009-02-17, 23:17:34, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3ba 0c1b, 0 cd 3, cd 4 0, 00 c 0, 0009, 09e9, 0607, 0001, 0000, 17 c 8
2009-02-17, 23:17:36, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3bb, 0 cd 3, cd 4 0, 0 DC 3, 00 c 2, 000 a, 09e8, 0607, 0001, 0003, 17 c 9
2009-02-17, 23:17:39, ff1c, 00ff, ffff 0093, 0000, 0100, 0001, d3bc, 0 cd 4 0 DC 4, DC 0-2, 00b 5, 000d, 09e9, 0607, 0001, 0002, 17 c 9
2009-02-17, 23:17:41, ff1c, 00ff, ffff 0093 0100, 0000, 0001, d3bd, 0cbd, 0 cd 4, 0 DC 7, 00 c 2, 0009, 09e8, 0607, 0001, 0001, 17 c 9Text files have no header just the RAW file as seen above.
Would appreciate any help. Thank you in advance.
Concerning
Dan
Hi Dan,.
I don't know what version of LabVIEW u using, I have attached the vi in the 8.5 v. My vi sorts the file names by order alphabetical use get info file vi to do sorting like u mentioned

-
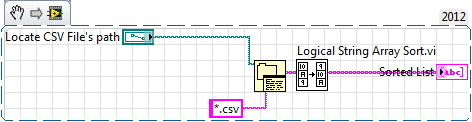
sequential files, playback of a folder in LabVIEW 2012 problem
Respected Sir/Madam,
I tried to make a program that
can read the files sequentially on a folder and add all the second column in the set
files into a single file (*.csv).
Unfortunately it is the reading of files as (1,10,100,1000, 11, 19,...), but I want to
go read the files in sequential format (1,2,3, 4... 1000).
For your kind references, here I have attached the vi and the example files
("renamefiles folder" - data-sample test, you'll need to read)
in order).
(using "rename the folder files" will easily understand the sequential)
problem reading) (if you add zero in front of the file name and make those same numbers; will give the good sequential)
reading)
Please find the attached documents and do what is necessary as soon as POSSIBLE.Thanking you.
Kind regards
Sasmas Mahat
E & CEE, IIT Kharagpur
Mob: + 919474504030You must use some kind of logic alpha like this: http://zone.ni.com/devzone/cda/epd/p/id/12 and place it after your folder list vi
-
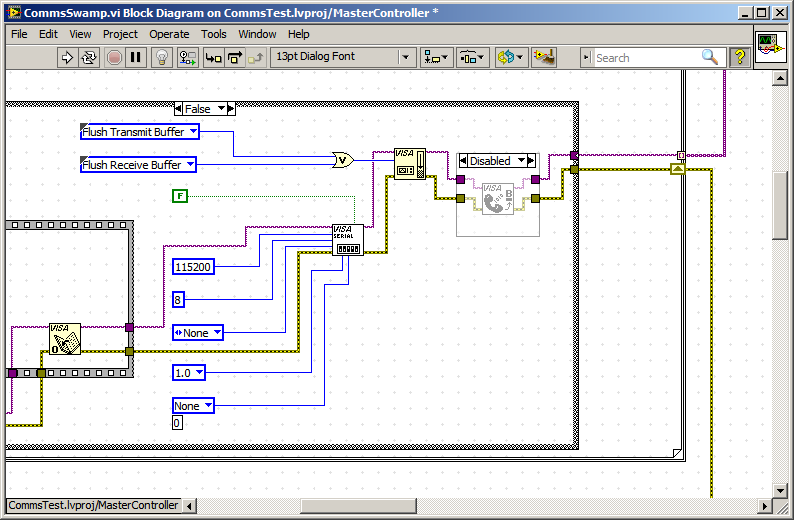
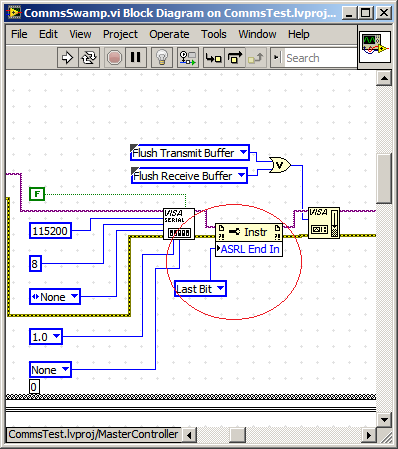
How to stop the series 'VISA read' the sends packets instead of bytes available.
Dear Labvillians,
Highlights:
How can I stop series "VISA read" send me packages rather bytes?
Background:
I have a system which publishes series of 14 bytes on a semi-regular interval packets.
At busy times, the producer of these these queues of data packets, effectively producing Super-paquets multiple of 14 times larger than 8 packages (112 bytes) bytes.
My protocol handler is designed to process bytes, packets, or packets Super.
Now, my request has multiple devices and the order of message processing is essential to the proper functioning.
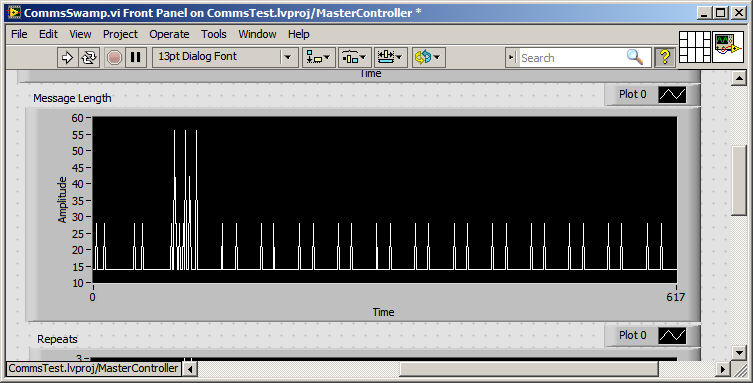
My observation is that read VISA waits until the end of a package / super package before moving the data to the application code. (See chart below)
My expectation is that VISA read should give me bytes available, get too smart for itself and not wait for a package.
.
I noticed this on PXI, PC shipped, PSC and, more recently, cRIO
I've experimented with Scan interface the cRIO rate, which helps to reduce the backlog of packages but don't decide to package under read byte.
I understand that a solution is FPGA code write to handle and pass the bytes by R/T-FIFO, and there are some great examples on this site.
Unfortunately, it does not help with FPGA devices not.
I have also dabbled in the event based sequential reads, but he is evil on vxWorks devices.
Any help is appreciated
It is helpful to sometimes talk to yourself.
I hope that is useful for someone sprinkle in the future
-
How do you know the speed of read/write of a flash drive?
Who knows a program to read/write speed?
Hi Cristi,
Thanks for posting in the Microsoft Community.
An indication of the standard flash drives read/write speeds is the following:
USB 2.0:
Sequential write speed range = 4-10 MB/S
Sequential read speed range = 15 to 25 MB/S
USB 3.0:
Sequential write speed range = upto20 MB/S
Sequential read speed range = upto45 MB/S
These reading and writing speeds offer a guide to the read/write Flash Drive performance and have been identified in recent tests. Please note that we are changing the components USB Flash Drive at any time based on the availability and cost. This means that the read/write speeds above cannot be guaranteed.
You can use your favorite search engine to search for this application that measures the speed of read/write of flash drives.
Warning: Using third-party software, including hardware drivers can cause serious problems that may prevent your computer from starting properly. Microsoft cannot guarantee that problems resulting from the use of third-party software can be solved. Software using third party is at your own risk.
Hope this information helps. For any other corresponding Windows help, do not hesitate to contact us and we will be happy to help you.
-
An insert in TWG read a lot of UNDO
Hello
I have an insert in a TWG (whose one index for its primary key) that is read a lot of UNDO (db file sequential read file #= 2).
I can't think of a good reason for it.
Here's a tkprof:
SQL ID: hash of Plan 4xwgpzxtgg4s5: 0
INSERT INTO xxxxx.xxxxxxxxxxxxxxxxxx (INCOUNT, INNUM)
VALUES
(: v1,: v2)
call the query of disc elapsed to cpu count current lines
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 0 0.00 0.00 0 0 0 0
Run the 113 0.09 0.09 36 173 838 6830
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Total 113 0.09 0.09 36 173 838 6830
Chess in the library during parsing cache: 0
Optimizer mode: ALL_ROWS
The analysis of the user id: 108
Elapsed time are waiting on the following events:
Event waited on times max wait for the Total WHEREAS
---------------------------------------- Waited ---------- ------------
SQL * Net message to client 17 0.00 0.00
SQL * Net client message 17 0.01 0.04
DB file sequential read 36 0.05 0.02
All are file #= 2:
WAITING #2390071304: nam = 'db file sequential read' ela = 735 file #= 2 block # 46834 blocks = 1 obj #= 0 tim = 3960230031525
WAITING #2390071304: nam = 'db file sequential read' ela = 713 file #= 2 #= 46835 blocks = 1 obj #= 0 tim = 3960230032327
WAITING #2390071304: nam = 'db file sequential read' ela = 659 file #= 2 #= 46836 blocks = 1 obj #= 0 tim = 3960230033125
WAITING #2390071304: nam = 'db file sequential read' ela = 648 file #= 2 block # 46837 blocks = 1 obj #= 0 tim = 3960230034030
EXEC #2390071304:c = 0, e = 3535, p = 4, cr = 5, cu = 38, SIG = 0, r is 52, dep = 0, og = 1, plh = 0, tim = 3960230034104
And there is another thing I don't understand. Each EXEC has only a single LINK, such as:
LINKS FOR #2390071304:
Link #0
oacdty = 02 mxl = 22 (22) mxlc = 00 wrong = 00 = 00 = 00 pre scl
oacflg = 01 fl2 = 1000000 frm = 00 csi = 00 siz = 48 off = 0
kxsbbbfp = bln 8e785608 = 22 = 02 = 05 flg avl
value = 12
Link #1
oacdty = 02 mxl = 22 (22) mxlc = 00 wrong = 00 = 00 = 00 pre scl
oacflg = 01 fl2 = 1000000 frm = 00 csi = 00 siz = off 0 = 24
kxsbbbfp = bln 8e785620 = 22 avl = flg 05 = 01
value = 7961958
However, the execs reported about 50 lines (as you can see the number of lines in the tkprof)
Any idea of the reason for this?
Thank you very much
Kind regards
Franck.
Check if the recording of flashback is enabled.
Others explain the curiosity to see a single set of values of bind variables when you table inserts - playback of cancellation could be "physical reads for new return of flame." I have provided a brief description in the last comment to the next note of the RTO: Flashback - high load
Concerning
Jonathan Lewis
-
Is it reasonable to require a Full table Scan (Direct path read) on a large Table
Hello
I have an Oracle 11.2.0.3 on a Sun Solaris 10 sparc with SGA 25 GB machine
One of my made SQL an analysis of indexes on the table to 45 GB where the size of the index is 14FR and the thourghput for the sequential read is 2MBPS.
so now (Index) 14 000 Mo, 14 GB / 2 MB = dry 7000 = 2 hours to scan the index.
Flow of the direct path read is 500 Mbps for an another SQL and reads assimilate them all live.
and because of this flow, a read (FTS) of direct path on the table of 7 GB out in 12-13 seconds. So in my case, it probably takes 100 seconds to scan the entire table. It is a monthly report and does not often.
Should I try to use a trick to force sql to do a full scan and exploit the possibilities of direct reading and is done in a few minutes? Assuming it to do a FTS (direct play)
Of course, it will be tested and verified, but the question is, is this a sensible apprioach? is - anyone has experience by forcing it?
Any suggestions would be helpful... I'll test this on a different machine tomorrow.
Best regards
Maran
82million lines and a grouping of 18million factor? And really 17million from lines to recover? However, your result set after the hash join is 3500 lines, although the optimizer expects 16 lines.
I would say that the statistics are not representative or not in use for this SQL. Certainly, the index does not match query predicates.
The fact that the index is also using the virtual columns only adds to confusion.
Hemant K Collette
Maybe you are looking for
-
I lost my bookmarks toolbar and can't find a way to get it back
I accidentally closed my toolbar line tha's my favorites in there and I can't figure out how to get back. I've removed Mozilla and re-uploaded, but it came the same way.
-
Hi all I play a .wav file using play a sound file vi. I made the file a constant. It works very well. But I'm afraid that if I give my book vi and vague to someone else to run, there may be issues such as the path of the audio file can be not the sam
-
When I wear apps, videos n pics on sd card, they are not work...Sometimes 4 k videos do not play... What is the problem?From the card sd or phone?What can I do?
-
How can I / display a photo or an image with information/inscription beside or below the picture. using a Windows Livemail email or a hotmail.co.uk email which will be sent to the recipients. This would serve to inform the beneficiaries of a concert
-
Impossible to uninstall programs and I can't connect to my wireless internet more.
OK, I was on my computer which is Windows xp and messing around and install stuff and I tried to delete the register norton 360 and when I did, I think I remove accedently another thing I shouldn't. When I go to uninstall some programs that it happe