Stop Cluster commands or crs stop
Hello
When you run the command:
crsctl stop crs the whole Oracle Clusterware (CRS & OHAS) are arrested.
When you run the command crsctl stop clusterware , layer CRS is stopped but the layer OHAS still running.
In which cases allows an command or other ?
Hello
"crsctl stop/start/no return cluster" has entered the picture with ohasd. These commands can be used from any node in the cluster for audit/start/stop on same node or remote resources.
These commands in independent OS communicate with relevant activities such as audit/start/stop ohasd.
This command affects only the level cluster resources and not operating system-level resources.
Kind regards
Vautrin - Oracle
Tags: Database
Similar Questions
-
[AllObjects] cluster does not match the cluster command?
I have a control group of string for which I'm looking to get the labels for each of the individual channels. My goal, as part of a larger project, is to pass differently labelled strings but same size cluster in this sub - VI and then write the labels string & text in a file. However, the index of the references in the [property] AllObjects coincide with the command I gave the cluster stands... why? If this isn't the case, of the order of the cluster objects, how is the order of [] AllObjects calculated?
Is there maybe a property that I am on that can match the elements of allObjects, go back to them within the cluster?
Or any other suggestions to get the labels of controls within the cluster while maintaining the same command as the cluster?
You use the Controls property of [] of the class Cluster for the commands in the order in which cluster. I don't know what order the AllObjs [] property returns... maybe the order in which they were dropped at the outset? The reason why there are two properties is because [AllObjs] would include also all the decorations inside the cluster.
-
Cluster commands cause a loop for hanging or LabVIEW to hang
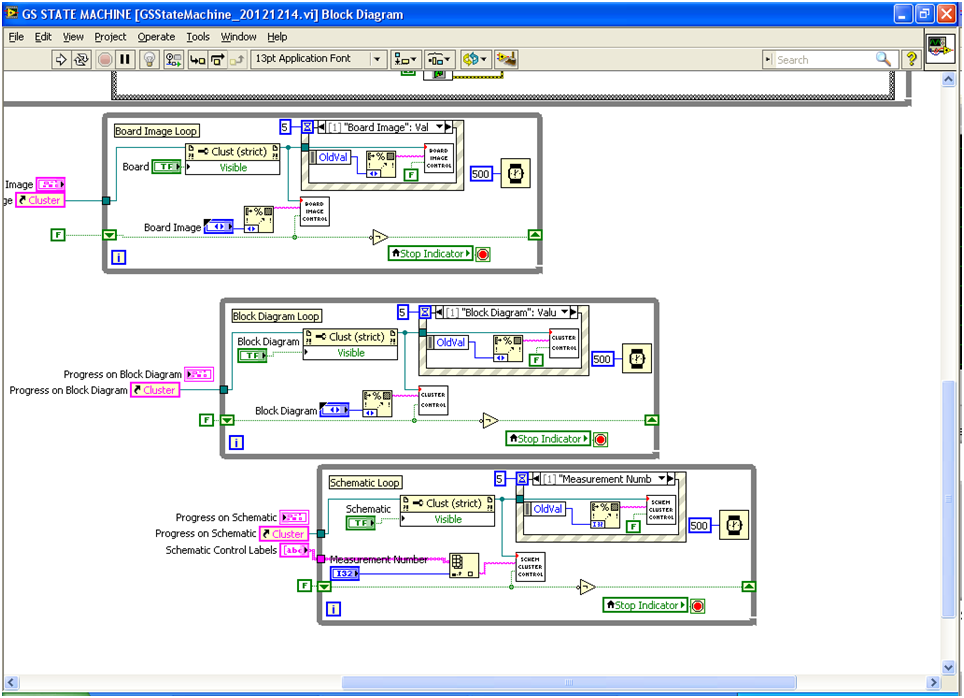
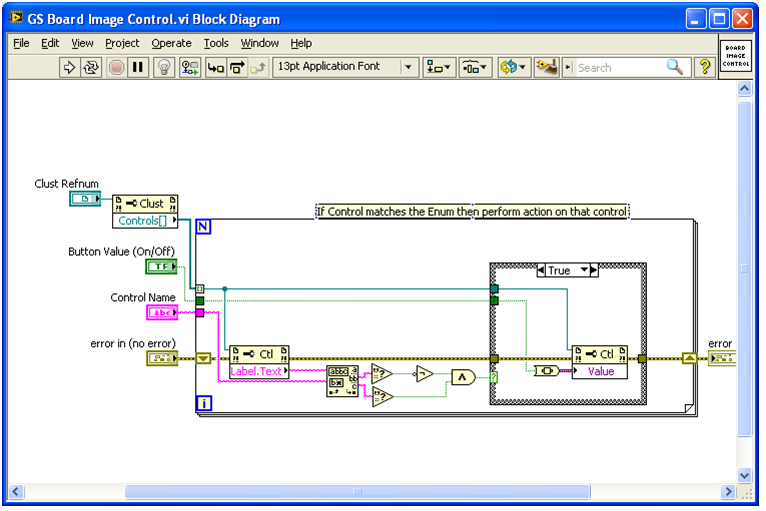
I'm working on a program that has three groups. Each cluster has LED controls inside them. During the test the controls Board Image, block diagram and number of measure will be changed accordingly. When the survey, all loop this one most are often those (Board picture) from the top and bottom (figure). LabVIEW sometimes becomes unresponsive and I have to cancel the program. Any suggestions?
A red flag that I see so far is that fair to the code that I can see, there are three structures separate event in your code - which are in the other events? You must only have or need one.
Why you both a timeout event AND one 500 msec waiting in each loop? The event of timeout is not doing anything.
Are there errors when LV becomes insensitive? Oh yes, it's true, none of these clusters of error are connected so you don't know...
Mike...
-
Hello.
I want to order the cluser conductor. R-VMCNDTRM-K9 part number includes cluster free license. I need to order a K9-VMCNDTRM-R or two for cluster?
Yes, you will need to order two instances of the driver. Virtual conductor that will each have their own serial number and associated keys options.
-
Hello
I created a new cluster to stop/start agent resource. I realized that when I stop agent by using the command "emctl stop agent", agent is restarted automatically in 3 seconds. What is the reason for this?
Here is the command I used to create a resource:
Here's the script:crsctl add resource agent -type local_resource -attr " ACTION_SCRIPT=/oracle/ora11202/grid/crs/script/agent.sh, DESCRIPTION=Agent, DEGREE=1, ENABLED=1, AUTO_START=restore, START_TIMEOUT=120, UPTIME_THRESHOLD=1h, CHECK_INTERVAL=60, STOP_TIMEOUT=120, SCRIPT_TIMEOUT=120, RESTART_ATTEMPTS=3, OFFLINE_CHECK_INTERVAL=60, START_DEPENDENCIES=, STOP_DEPENDENCIES="
vi agent.sh #!/bin/sh export ORACLE_HOME=/oracle/agent11g case $1 in 'start') /oracle/agent11g/bin/emctl start agent RET=$? ;; 'stop') /oracle/agent11g/bin/emctl stop agent RET=$? ;; 'check') /oracle/agent11g/bin/emctl status agent RET=$? ;; esac exit $RETSQL * more is now integrated with crs now. If you stop the database with SQL * Plus, crs does not interpret this as a failure of the database and does not attempt to restart the database. But if the instance falls down for a reason, the crs will try to show the instance automatically. For example, try to kill the pmon/smon process for this instance and see what happens.
In the case of the resource of your agent, when you stop the agent manually the crs interprets this as a defective component and try that restarts automatically. If you stop the agent via the crsctl command, then crs considers this as a defective component and he won't try to make appear the resource.
-
Sun Cluster 3.2u3 (11/09) and Oracle RAC 11g R2 compatibility
Hi all
I am facing a problem when integrating 3.2u3 Sun Cluster with RAC Oracle 11 g R2.
I installed 10u8 Sun Solaris on Sun SPARC M5000 02 servers. These two servers have already installed Sun Cluster 3.2u3, almost resource for RAC groups have also been set up. (Except for the Framework CRS resource and database resources Proxy).
After installing and configuring RAC Oracle 11g R2, I tried to integrate it with Sun Cluster with the utility 'clsetup '.
At the start of the utility run commands to create new resources, I pointed out that this process has failed, the output is:
-------------------------
> Check the Configuration of the Oracle database resources
>
> The following configuration of Sun Cluster will be created.
>
>
> To view details for an option, select the option.
>
> Name value
> ==== =====
> 1) CRS Framework Resource N... crs_framework-rs
> 2) resource Framework RAC G... cars-framework-rg
> 3) database Proxy resource... rac_server_proxy-rs
> 4) database Proxy resource... rac_server_proxy-rg
> 5) node list bltp-db1, db2-Clint
> 6) oracle CRS Home/u01/grid
> 7) CRS OCR and voting disks /ocr, / vote
Bltp > 8 oracle database name)
> 9) oracle Home/u01/oracle/db
> 10) oracle SID oracle_sid {bltp-db1} = pttb1, oracle_s...
>
(> c) create a Configuration
(> q) Quit
(>?) Help
>
> Option: c
>
> * Orders running Sun Cluster... | 14 Jul 10:01:20 bltp-db1 SC [SUNW.crs_framework.crs_framework_validate]: error: shutdown The Oracle CRS script > "" / etc/init.d/init.crs "is missing.*_"
> / 14 Jul 10:01:20 Cluster.RGM.global.rgmd bltp-db1: VALIDATE failed on resource < crs_framework-r >, < rac-framework-rg >, a group resources time used: 0% to > < 300 seconds timeout >
>
>
> View results
>
>
> ERROR: the following error occurred during the creation of the
> configuration
>
> clresource: Clint-db1 - error: Stop The Oracle CRS script "/ etc/init."
' > d/init.crs ' is missing.
>
> clresource: (C189917) VALIDATE crs_framework-r, resource group resource
> rac-framework-rg, came out with the nonzero exit status.
> clresource: (C720144) crs_framework-r resources resources Validation
> Group rac-framework-rg on the bltp-db1 node failed.
> clresource: (C891200) cannot create resources "crs_framework r".
>
>
>
> ERROR: nonzero exit status
>
> the following Sun Cluster commands have been executed
>
> Configuration commands...
>
>
> / usr/cluster/bin/clresourcegroup online - emM rac-framework-rg
>
> / usr/cluster/bin/clresourcetype register SUNW.crs_framework:2
>
> create a/usr/cluster/bin/clresource t SUNW.crs_framework:2 g rac-framework-rg - p
> Resource_dependencies = rac-framework-r - p resource_dependencies_offline_restart = scal-
> ocr - r {local_node}, scal-vote-r {local_node} crs_framework-rs
>
>
> Configuration of resources for Oracle 10 g R2 or 11g Real Application Clusters
> database instances failed.
-------------------------
I think that this error is is produced due to some scripts to the CCR of Oracle 11 g R2 have been changed in the content and location.
So my question is: 3.2u3 work can Sun Cluster with Oracle 11g R2 RAC?
Please help me to have a response in this case.
Thank you very much
HuyNQ.What I read Sun Cluster 3.2 is not supported with RAC 11 g R2 up to this time of September.
The feature will be available via a patch of the cluster database.Sun Cluster is currently looking into /etc/init.d/init.crs to start the CRS (11g R1). With 11g R2, the startup for the GRID script is now etc/init.d/ohasd.
SC supports HA 11 g R2, but not of CARS at the moment.
-
$GRID_HOME/bin/crsctl check crs fails with CRS-4535: cannot communicate wit
Hi all
I have an instance RAC 11 GR 2 with 2 nodes running 11.2.0.3 on OEL 5 day 8 64-bit environment
After a physical reboot of the node1 the cluster on node 1 will not start
When I try to run the command on node 1 below
$GRID_HOME/bin/crsctl check crs
the following error appears
CRS-4638: Oracle high availability Services is online
CRS-4535: cannot communicate with Cluster Ready Services
CRS-4530: communication failure communicating with Cluster Synchronization Services daemon
CRS-4534: can not communicate with the event Manager
Cluster node 2 and db instance on node 2 is running.
When I try to run the command on node 1 below
# ps - ef | grep d.bin
root 7548 1 0 19:58? 00:00:05 /oracle/app/11.2.0/grid/bin/cssdmonitor
root 9295 1 0 17:06? 00:01:03 /oracle/app/11.2.0/grid/bin/ohasd.bin restart
Oracle 10085 1 0 17:07? 00:00:08 /oracle/app/11.2.0/grid/bin/oraagent.bin
Oracle 10097 1 0 17:07? 00:00:00 /oracle/app/11.2.0/grid/bin/mdnsd.bin
Oracle 10107 1 0 17:07? 00:00:08 /oracle/app/11.2.0/grid/bin/gpnpd.bin
root 10118 1 0 17:07? 00:00:04 /oracle/app/11.2.0/grid/bin/orarootagent.bin
Oracle 10121 1 0 17:07? 00:00:34 /oracle/app/11.2.0/grid/bin/gipcd.bin
root 10135 1 6 17:07? 00:13:10 /oracle/app/11.2.0/grid/bin/osysmond.bin
root 10327 1 0 17:07? 00:00:52 /oracle/app/11.2.0/grid/bin/ologgerd - M d /oracle/app/11.2.0/grid/crf/db/srv-bioradb1
root of 11917 10052 0 20:32 pts/1 00:00:00 grep d.bin
looking forward to doc or recommendation how to start clusterware on node1
Thanks and greetings
SoniHello
Offering to see metalink doc below.
Top 5 Grid Infrastructure startup problems [ID 1368382.1]
Thank you
-
root access to some commands crsctl
The GI Version: 11.2.0.3
Platform: Red Hat Enterprise Linux 5.8
Most of the commands of crsctl can be run while connected as a network user. But some of the crsctl commands as below to be executed while connected as user root.
What type crsctl commands must be run as root? Is there a list or is there a way to identify?$ crsctl start cluster -n sdasher199 CRS-4563: Insufficient user privileges. CRS-4000: Command Start failed, or completed with errors.That's as close as I've seen... it tells you what commands require root:
http://docs.Oracle.com/CD/E11882_01/RAC.112/e16794/crsref.htm
-
: Cannot communicate with the Cluster ready Services
Hi all
We have a two-node cluster for our QA environment. Version database 11.2.0.2. UNIX people upgraded the kernel version and we relinked binaries. After the restoration of the links, the CRSD is not coming, and therefore the RAC database is DOWN.
Here are some checks:
The entrances to some of the papers are:+ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/bin>./crsctl start cluster CRS-2672: Attempting to start 'ora.crsd' on 'argalephdbqa1' CRS-2676: Start of 'ora.crsd' on 'argalephdbqa1' succeeded +ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/bin>./crsctl start has CRS-4640: Oracle High Availability Services is already active CRS-4000: Command Start failed, or completed with errors. +ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/bin>id uid=0(root) gid=0(root) groups=0(root),1(bin),2(daemon),3(sys),4(adm),6(disk),10(wheel) +ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/bin>./crsctl status resource -t CRS-4535: Cannot communicate with Cluster Ready Services CRS-4000: Command Status failed, or completed with errors. +ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/bin>./crsctl start crs CRS-4640: Oracle High Availability Services is already active CRS-4000: Command Start failed, or completed with errors. +ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/bin>sqlplus '/as sysasm' SQL*Plus: Release 11.2.0.2.0 Production on Thu Dec 13 22:30:08 2012 Copyright (c) 1982, 2010, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 - 64bit Production With the Real Application Clusters and Automatic Storage Management options SQL> select name, state from v$asm_diskgroup; NAME STATE ------------------------------ ----------- DATA1 MOUNTED FLASH MOUNTED QUORUM MOUNTED +ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/bin>./crsctl stat res -t -init -------------------------------------------------------------------------------- NAME TARGET STATE SERVER STATE_DETAILS -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- ora.asm 1 ONLINE ONLINE argalephdbqa1 Started ora.cluster_interconnect.haip 1 ONLINE ONLINE argalephdbqa1 ora.crf 1 ONLINE ONLINE argalephdbqa1 ora.crsd 1 ONLINE OFFLINE ora.cssd 1 ONLINE ONLINE argalephdbqa1 ora.cssdmonitor 1 ONLINE ONLINE argalephdbqa1 ora.ctssd 1 ONLINE ONLINE argalephdbqa1 OBSERVER ora.diskmon 1 ONLINE ONLINE argalephdbqa1 ora.drivers.acfs 1 ONLINE ONLINE argalephdbqa1 ora.evmd 1 ONLINE INTERMEDIATE argalephdbqa1 ora.gipcd 1 ONLINE ONLINE argalephdbqa1 ora.gpnpd 1 ONLINE ONLINE argalephdbqa1 ora.mdnsd 1 ONLINE ONLINE argalephdbqa1 +ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/bin>crsctl stat res -t CRS-4535: Cannot communicate with Cluster Ready Services CRS-4000: Command Status failed, or completed with errors. +ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/bin>crsctl query css votedisk ## STATE File Universal Id File Name Disk group -- ----- ----------------- --------- --------- 1. ONLINE 8faab9ebb1514f7fbf2360c9cbd32b77 (ORCL:QUORUM_DISK1_1) [QUORUM] 2. ONLINE 18ce8b4afc2f4f8fbf908de3848d893e (ORCL:QUORUM_DISK1_2) [QUORUM] 3. ONLINE 89822108feb64f06bfa324d5d8ea4928 (ORCL:QUORUM_DISK2_1) [QUORUM] Located 3 voting disk(s). +ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/bin>ocrcheck PROT-602: Failed to retrieve data from the cluster registry PROC-26: Error while accessing the physical storage ORA-27300: OS system dependent operation:open failed with status: 13 ORA-27301: OS failure message: Permission denied ORA-27302: failure occurred at: sskgmsmr_7
/U01/app/oragrid/11.2.0.2/log/argalephdbqa1/alertargalephdbqa1.log:
/U01/app/oragrid/11.2.0.2/log/argalephdbqa1/CSSD/ocssd.log:+ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/log/argalephdbqa1>tail -10 alertargalephdbqa1.log 2012-12-13 22:24:54.733 [ohasd(10136)]CRS-2771:Maximum restart attempts reached for resource 'ora.crsd'; will not restart. 2012-12-13 22:54:02.426 [client(24168)]CRS-1013:The OCR location in an ASM disk group is inaccessible. Details in /u01/app/oragrid/11.2.0.2/log/argalephdbqa1/client/ocrcheck_24168.log. 2012-12-13 22:57:23.301 [client(24312)]CRS-1013:The OCR location in an ASM disk group is inaccessible. Details in /u01/app/oragrid/11.2.0.2/log/argalephdbqa1/client/crsctl_oracle.log. 2012-12-13 22:57:30.575 [client(24341)]CRS-1013:The OCR location in an ASM disk group is inaccessible. Details in /u01/app/oragrid/11.2.0.2/log/argalephdbqa1/client/crsctl_oracle.log. 2012-12-13 22:57:40.981 [client(24531)]CRS-1013:The OCR location in an ASM disk group is inaccessible. Details in /u01/app/oragrid/11.2.0.2/log/argalephdbqa1/client/crsctl_oracle.log.
/U01/app/oragrid/11.2.0.2/log/argalephdbqa1/crsd/crsd.log:+ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/log/argalephdbqa1/cssd>tail -10 ocssd.log 2012-12-13 23:09:01.671: [ CSSD][1116453184]clssnmSendingThread: sending status msg to all nodes 2012-12-13 23:09:01.671: [ CSSD][1116453184]clssnmSendingThread: sent 4 status msgs to all nodes 2012-12-13 23:09:05.679: [ CSSD][1116453184]clssnmSendingThread: sending status msg to all nodes 2012-12-13 23:09:05.679: [ CSSD][1116453184]clssnmSendingThread: sent 4 status msgs to all nodes 2012-12-13 23:09:09.687: [ CSSD][1116453184]clssnmSendingThread: sending status msg to all nodes 2012-12-13 23:09:09.687: [ CSSD][1116453184]clssnmSendingThread: sent 4 status msgs to all nodes 2012-12-13 23:09:14.697: [ CSSD][1116453184]clssnmSendingThread: sending status msg to all nodes 2012-12-13 23:09:14.697: [ CSSD][1116453184]clssnmSendingThread: sent 5 status msgs to all nodes 2012-12-13 23:09:19.707: [ CSSD][1116453184]clssnmSendingThread: sending status msg to all nodes 2012-12-13 23:09:19.707: [ CSSD][1116453184]clssnmSendingThread: sent 5 status msgs to all nodes
Any suggestion on how to continue?+ASM1@argalephdbqa1:/u01/app/oragrid/11.2.0.2/log/argalephdbqa1/crsd>tail -15 crsd.log 2012-12-13 22:24:48.899: [ OCRRAW][3322856016]proprio_repairconf: Failed to retrieve the group public data. CSS ret code [20] 2012-12-13 22:24:48.901: [ OCRRAW][3322856016]proprioo: Failed to auto repair the OCR configuration. 2012-12-13 22:24:48.901: [ OCRRAW][3322856016]proprinit: Could not open raw device 2012-12-13 22:24:48.901: [ OCRASM][3322856016]proprasmcl: asmhandle is NULL 2012-12-13 22:24:48.903: [ OCRAPI][3322856016]a_init:16!: Backend init unsuccessful : [26] 2012-12-13 22:24:48.903: [ CRSOCR][3322856016] OCR context init failure. Error: PROC-26: Error while accessing the physical storage ORA-01031: insufficient privileges 2012-12-13 22:24:48.904: [ CRSMAIN][3322856016] Created alert : (:CRSD00111:) : Could not init OCR, error: PROC-26: Error while accessing the physical storage ORA-01031: insufficient privileges 2012-12-13 22:24:48.904: [ CRSD][3322856016][PANIC] CRSD exiting: Could not init OCR, code: 26 2012-12-13 22:24:48.904: [ CRSD][3322856016] Done.Martin.morono wrote:
Any suggestion on how to continue?
Filing of an SR (service request) with the support of the Oracle would be the prudent thing to do.
-
CRS starts does not after reboot
Hello
I just installed RAC in a test environment using vmware server 2. I have Oracle Enterprise Linux 5 and used oracle 11g (11.2.0.1). I have not yet installed the software database and the oracle grid infrastructure has just installed.
When I restart the node and deliver 'crsctl check crs', I see after release.
[root@rac2 ~] # crsctl check crs
CRS-4638: Oracle high availability Services is online
CRS-4535: cannot communicate with Cluster Ready Services
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is online
Now, "crs_stat t" does not work unless I manually start the crs daemon by using the command "crsd start." Why the crs daemon starts not automatic unlike 10 g RAC. Is this a normal behavior and what is a good way to make this daemon to auto-start.
SalmanI guess you run crsctl check crs immediately after the restart. It doesn't take long for the crs start and you don't have to start it manually. By default, crs is started automatically and if for any reason any you disabled, you can enable it using 'crsctl enable the crs '.
You can also check the status of different services using the:
# crsctl check crsd -
Hi all
I am subsequently helps him learn how to use the cluster to reduce the number of inputs/outputs, but it is quite confusing that how do you know which is which. It follows from the order, whether or not we have added to the cluster? I put a cluster contains 4 numbers DBL as an entry of my Subvi. I name the elements of each DBL as A, B, C, D. In the main code, I create a cluster contains 4 DBL and trying to feed on this cluster in the Sub - VI. But how do I know what number I feed in the main code is A, B, C and D?
For example, I create a Subvi with the participation of a single cluster. The cluster has 4 numbers DBL named A, B, C and D.
Now if want to feed a cluster in this sub - VI, I create a cluster and connect the 4 digits in this cluster. But if I use the bundle cluster, I need to connect the number in order thus to fill A, B, C and D. But if this Subvi was created by someone else, how can indicate the order of the elements in the cluster WAITED?
First, you must give the elements of the cluster in the control Subvi the same names (A, B, C, D) as used in the VI call and also to ensure that the order of cluster is the same. If you are not sure fight the cluster command, you can reorder the items (right click) and select the desired command. And Yes, the initial cluster order is the order in which you have added the items.
Generally, it is preferable that the cluster a typedef and used worldwide. This way to the typdef change is propagated to all the places where it is used.
It is often more auto-documentent and cleaner to use together and ungroup by name. A constant of diagram of typedef wire upward 'bundle by name' to make the labels available.
-
Hi guys,.
I need help. In my example below, there are two tabs of page with a cluster of three buttons within each tab. In the block diagram, I have a while loop with a cluster of events with event Cluster 1 and Cluster 2 all the items selected. I also have a class of Cluster connected to a property with the exposed [] controls property node. I'm currently editing the Boolean text of the I pressed the button.
Does anyone know how to do this? I can't expose properties that I need based on which button I clicked on. I hope I don't have to have an event for each button that is in each cluster. Which sucks.
All the points in the right direction would be greatly appreciated.
P.S. I use this instead of download my VI which has some SubVIs with her and each cluster has a different number of buttons associated with each cluster.
Right then here's what you can do. Get the reference of the cluster command that has been changed. Then read the old value and a previous to see boolean value has changed. Get references to the control in the cluster, and then remove the reference to the control that has changed its value. Cast to a boolean class, then replace the text. Now, if you want an error checking, because you can have Boolean values in your cluster.
-
Get-Cluster output blank list?
I hope that it should be easy, but it baffled me completely. I set up a script that will ask a number of questions and deploy a virtual machine based on the answers. One of my articles of the code is one 'other' section instead of choosing from a menu, the person who runs the script can manually enter things like the name of the Cluster, the name of Resource Pool and data store. I invite to the Cluster name, and then run a Get-Cluster command to output a list of Resource Pools, prompt the user to choose a pool, then run a command to list data warehouses available on the hosts in a cluster. This is where it gets weird. If I manually run these commands in a Windows Powershell CLI, they work fine, but when I run it in a .ps1 script, the list of data store outputs blank lines in the place where the list should be. Here are some very stripped of this code:
$ClusterInput = Read-Host "Enter the VMware cluster name" Connect-VIServer vcenter | Out-Null Get-Cluster $ClusterInput | Get-ResourcePool | Select @{N="Resource Pool";E={$_.Name}} | Where-Object {$_.'Resource Pool' -ne 'Resources'} $ResourcePool = Read-Host "Enter the name of a Resource Pool listed above to place the virtual machine" $myCluster = Get-Cluster -Name $ClusterInput | Get-ResourcePool $ResourcePool Write-Host "Retrieving a list of Datatores in cluster $ClusterInput..." Get-Cluster $ClusterInput | Get-VMHost | Get-Datastore | Sort NameThe last line, 07, what shows empty lines. Line 03 outputs very well and is basically the same thing.
I can assign a variable to the line 07 and then run through a loop to exit, but the format is not as nice as the only line should be able to do on its own
Any ideas?
Try changing the last line to
Get-Cluster $ClusterInput | Get-VMHost | Get-Datastore. Sort name | Out-host
-
CRS does not come after reboot the server in Oracle11g r2 11.2.0.1.0
Dear Oracle gurus
Our platform:
ORACLE11G r2 RAC/GRID 11.2.0.1.0
ReadHat Enterprise Linux5.3 64-bit
RAC - 2 NŒUD
[root@xyz-ch-aaadb-02 evmd] # /u01/app/11.2.0/grid/bin/crsctl check crs
CRS-4638: Oracle high availability Services is online
CRS-4535: cannot communicate with Cluster Ready Services
CRS-4530: communication failure communicating with Cluster Synchronization Services daemon
CRS-4534: can not communicate with the event Manager
RAC - 1 NŒUD
[root@xyx-ch-aaadb-01 crsd] # /u01/app/11.2.0/grid/bin/crsctl check crs
CRS-4638: Oracle high availability Services is online
CRS-4535: cannot communicate with Cluster Ready Services
CRS-4530: communication failure communicating with Cluster Synchronization Services daemon
CRS-4533: Event Manager is online
RAC - 1 NŒUD
crsd.log
2011-08-21 00:35:27.913: [CSSCLNT] [3047883232] clssscConnect: gipc request failed with 29 (0x16)
2011-08-21 00:35:27.913: clsssInitNative [CSSCLNT] [3047883232]: connection failed, rc 29
2011-08-21 00:35:27.914: [CRSRTI] [3047883232] CSS isn't ready. Status received 3 of CSS. Waiting for a status of good...
2011-08-21 00:35:28.915: [CSSCLNT] [3047883232] clssscConnect: gipc request failed with 29 (0x16)
2011-08-21 00:35:28.915: clsssInitNative [CSSCLNT] [3047883232]: connection failed, rc 29
2011-08-21 00:35:28.916: [CRSRTI] [3047883232] CSS isn't ready. Status received 3 of CSS. Waiting for a status of good...
RAC - 2 NŒUD
crsd.log
2011-08-21 00:38:52.225: [CSSCLNT] [3198087648] clssscConnect: gipc request failed with 29 (0x16)
2011-08-21 00:38:52.225: clsssInitNative [CSSCLNT] [3198087648]: connection failed, rc 29
2011-08-21 00:38:52.225: [CRSRTI] [3198087648] CSS isn't ready. Status received 3 of CSS. Waiting for a status of good...
2011-08-21 00:38:53.228: [CSSCLNT] [3198087648] clssscConnect: gipc request failed with 29 (0x16)
2011-08-21 00:38:53.228: clsssInitNative [CSSCLNT] [3198087648]: connection failed, rc 29
2011-08-21 00:38:53.228: [CRSRTI] [3198087648] CSS isn't ready. Status received 3 of CSS. Waiting for a status of good...
Please help solve the problem.
Let me know if you required information.
Concerning
Hitesh Gondaliahitgon wrote:
We correctly the required permissions and ownership changes before we install the RAC.
But after restarting the server.Please find the required papers.
[root@xyz-ch-aaadb-01 ~] # ls-l/dev/sd *.
BRW - r - 1 root disk 8, 0 21 August 00:20 / dev/sda
BRW - r - 1 root disk 8, 1 Aug 21 0020: / dev/sda1
BRW - r - disc 1 root 8, 2 21 August 00:20 / dev/sda2
BRW - r - 1 root disk 8, 3-21 August 00:20 / dev/sda3
BRW - r - 1 root disk 8, 4 August 21, 00:20 / dev/sda4
BRW - r - 1 root disk 8, 5 August 21, 00:20 / dev/sda5
BRW - r - 1 root disk 8, 6 August 21, 00:20 / dev/sda6
BRW - r - 1 root disk 8, 16, 21 Aug 00:20 / dev/sdb
BRW - r - 1 root disk 8, 32 21 August 00:20 / dev/sdc
BRW - r - 1 root disk 8, 48 21 August 00:20 / dev/sdd
BRW - r - 1 root disk 8, 49-21 August 00:20 / dev/sdd1
BRW - r - 1 root disk 8, 64 21 August 00:20 / dev/sde
BRW - r - 1 root disk 8, 65 21 August 00:20 / dev/sde1
BRW - r - 1 root disk 8, 80 21 August 00:20 / dev/sdf
BRW - r - 1 root disk 8, 81 21 August 00:20 / dev/sdf1
BRW - r - 1 root disk 8, 96 21 August 00:20 / dev/sdg
BRW - r - 1 root disk 8, 97-21 August 00:20 / dev/sdg1
BRW - r - 1 root disk 8, 112 21 August 00:20 / dev/sdh
BRW - r - 1 root disk 8, 113 21 August 00:20 / dev/sdh1[root@xyz-ch-aaadb-02 ~] # ls-l/dev/sd *.
BRW - r - 1 root disk 8, 0 21 August 00:20 / dev/sda
BRW - r - 1 root disk 8, 1 Aug 21 0020: / dev/sda1
BRW - r - disc 1 root 8, 2 21 August 00:20 / dev/sda2
BRW - r - 1 root disk 8, 3-21 August 00:20 / dev/sda3
BRW - r - 1 root disk 8, 4 August 21, 00:20 / dev/sda4
BRW - r - 1 root disk 8, 5 August 21, 00:20 / dev/sda5
BRW - r - 1 root disk 8, 16, 21 Aug 00:20 / dev/sdb
BRW - r - 1 root disk 8, 32 21 August 00:20 / dev/sdc
BRW - r - 1 root disk 8, 48 21 August 00:20 / dev/sdd
BRW - r - 1 root disk 8, 49-21 August 00:20 / dev/sdd1
BRW - r - 1 root disk 8, 64 21 August 00:20 / dev/sde
BRW - r - 1 root disk 8, 65 21 August 00:20 / dev/sde1
BRW - r - 1 root disk 8, 80 21 August 00:20 / dev/sdf
BRW - r - 1 root disk 8, 81 21 August 00:20 / dev/sdf1
BRW - r - 1 root disk 8, 96 21 August 00:20 / dev/sdg
BRW - r - 1 root disk 8, 97-21 August 00:20 / dev/sdg1
BRW - r - 1 root disk 8, 112 21 August 00:20 / dev/sdh
BRW - r - 1 root disk 8, 113 21 August 00:20 / dev/sdh1Concerning
Hitesh GondaliaHello
Permission vote drive and the drive to vote changed after the reboot. sustain the permissions and ownership of roc and drive to vote even after reboot. check out this storage admin, they should be able to do.
After this test restart again and see the resultHope this helps
See you soon
-
We are having RAC Database 11.2.0.2 on cluster 3 knots. OS: RHEL 5.6
When OPatch auto is used to apply the patch we need stop all instances on the node and the cluster command or auto automatically stop and start all processes running from ORACLE_HOMEopatch auto care, please visit:
http://docs.Oracle.com/CD/B16240_01/doc/EM.102/e15294/options.htmAuto command
----------------------------
Ordinarily, a patch Clusterware requires several manual steps before and after you apply the hotfix, such as:Stop all dependent databases
Stopping Clusterware resources
Running scripts before patch
Closure of the Clusterware
Running the scripts after patch
Departure Clusterware and dependent databases
Automatic control of opatch automates all of these tasks to the CRS home patch and all the other houses there is place of RDBMS.

Maybe you are looking for
-
Cannot add photos to my Gallery of photos from my PC
Tonight I have successfully downloaded a picture from my PC to my photostream (clicked right on the photo/add to the shared album). Went to charge a second picture and all of a sudden cannot download any photo to any photostream. It manifests and all
-
HP 110-219: replacement motherboard
Hello guys. its my first time posting a question and I would ask to recommend what motherboard to buy as a replacement for my current. I would like to put a graphic as a 960 gtx card but the motherboard doesn't have pcie connectors and the graphics c
-
A relatively simple matter. Using of 1456 CVS and a Basler VBAI camera A622F 3.0, how to reduce the size of the full image while grabbing a picture from the camera via an external trigger? For example, if the size of the real matrix of the camera is
-
Come eliminare password protection contenuti e internet
Finestra di bolcco dei contenuti mi sta doing impazzire desidero eliminare questo controllo grazie
-
How to add a shortcut to add speech recognition to type the username on Vista Start
As a disabled person, I use Dragon NaturallySpeaking to run a computer most of the time. Right now I use a mouth stick to type at first upward, and I would like to be able to add an icon to start the program so I can enter a login with voice. Thank y