Storage of data in a table all N cycles 2D
I try to save data and index of all cycles N, then put them in a 2D array.
I managed to save the data of all cycles N, but I have some difficulty to save them with zeros in the meantime.
G E.
I save all 3 cycles I y
0 0 0 0
1 10 3 30
2 20 6 60
3 30
4 40
5 50
6 60
7 70
8 80
9 90
10 100
Please refer to the attached VI
Thank you
Try this.
Tags: NI Software
Similar Questions
-
problem with the storage of the data in the table
Hello
I'm having the problem on the storage of data in the table. My problem is that whenever he makes a loop, the table just keep replacing them rather save to the next index. At 0, the value is 123, and 1 is 234. But I saw that all the data capture all crush to 0 until the last data see the 0. How can I fix this problem?
-
How publish data from the table with some data loss all post in the forum
I wonder how people are displayed the data in the table or the result of a query with losing them its format from Sqlplus display when they post in the forums of Oracle. I searched on the basis of knowledge of DB but I see no article about it. can you please help me or direct me to this link, I tried different options using code and other tags but nothing has worked, thank you for your help. Thank you.
Edited by: Ariean October 3, 2011 12:34You can click on the link to the FAQ at the top right: http://wikis.sun.com/display/Forums/Forums+FAQ.
-
Storage of the data in a table problem
Hi guys,.
I have the following schema:
< xsd: element name = "Details" type = "DetailsType" / >
< xsd: complexType name = "DetailsType" >
< xsd: SEQUENCE >
< xsd: element name = "count" type = "xsd: Integer" / >
< xsd: element name = "loop" type = "xsd: Integer" / >
< xsd: element name = "test" type = "xsd: Integer" / >
< xsd: element name = "test2" type = "xsd: String" / >
< xsd: element name = "test3" type = "xsd: String" / >
< xsd: element name = "ReceiptArr" type = "xsd: String" maxOccurs = "unbounded" / >
< / xsd: SEQUENCE >
< / xsd: complexType >
where I said ReceiptArr in a table.
I try to copy the data in the table, but it does not work.
I want the data to be like that
ReceiptArr [1] = 12345
ReceiptArr [2] = 23456
ReceiptArr [3] = 78900
.
.
.
etc.
Here is my statement copy of bpel
< copy >
< expression = "ora:getNodes ('receiveInput_Get_InputVariable', 'CashReceipt', concat ('/ ns2:CashReceipt / ns2:Detail [', bpws:getVariableData('DebtorVar','/ns9:Details/ns9:loop'),'. / ns2:receipt_number'))" / >
< variable = "DebtorVar."
Query = "Concat ('/ NS9:Details / NS9:ReceiptArr [', bpws:getVariableData('DebtorVar','/NS9:Details/NS9:loop'),']')" / >
< / copy >
and it fails, does anyone know how I can complete my table in bpel?
Thank you
KHello
I had to do in the past, and this is the approach I used. Create two variables, one for a number of records and the other as an index of the loop. The index of the loop the value 1 and get a number of nodes in the xml data in the entry for the second variable. Then the loop through the input xml data while the loop index is less than the record number, set the value of your table and incrementing the index of the loop, the use of brackets around the loop index (i.e. open close bpws:getVariableData('Variable_loopIndex') of the angle. I see that when I post this message, this part of the code is eating, and in my browser at least when I replace the ASCII for support, it is displayed instead of the media.There might be better ways to address the issue, but it worked for my process. I have not tested the below with your types to xml schema, but here's an example of how this can stand as a model using my code:
condition = "bpws:getVariableData('Variable_loopIndex') < = bpws:getVariableData('Variable_recordCount')" > "
Query = "/ ns2:CashReceipt / ns2:Detail / ns2:receipt_number [bpws:getVariableData('Variable_loopIndex')]" / > ""
Query = "/ ns9:Details / ns9:ReceiptArr [bpws:getVariableData('Variable_loopIndex')]" / > ""
Hope this helps
CandacePublished by: cmcavaney on June 25, 2009 08:26
-
Hello
This morning, I lost all my week end test data. You know a procedure secure my data in the event of an accident of electricity?
Attached my VI. I export my datas from the table when necessary...
Thanks a lot for your support
Rémi
remi69330 wrote:
This morning, I lost all my week end test data. You know a procedure secure my data in the event of an accident of electricity?
Save a file on your hard drive. You should do this anyway. I recommend that you take a look at the producer/consumer and use the second loop to write the data to a file.
-
storage of output in a table problem
Hello
I am trying to store the analog data in a table and then save it as a csv file. But for some reason, I get only 1 value in my saved file. Please look at attached picture of the block diagram. I can't move all save loop as process (0.05 seconds) writing slows the rate of acquisition of file block. I'm trying to store all the values output from a large table and at the end to save all values in a single file. But the table seems to be adding

Sine
Sorry, but I didn't look carefully at what you were doing. You still need a registry change so that a new result will be added to a previous result.
-
Storage of certain values, but not all
Hi all
I had trouble putting implement this: store a few values of some iterations of the loop as reference and use the reference to subtract any new value produced of the iterations of the loop later.
For example:
My sensor generates a table (size: 768) by timed loop iteration.
I want to generate an array of background reference to iteration to iteration #220 #201. Currently I use the stacked shift (shift 20 saved stack) register to store the array generated by my sensor. The final basic table is averaged over 20 registees shift tables:
Background reference table = (array array 1 + 2 +.. .array 20) / 20
I want to remove this reference table background of table all collected subsequently the.
new table - (table table 1 + 2 +.. .array 20) / 20
The new table can by any array to a later iteration of the timed loop (#221 or beyond).
In other words, I can't generate a table of fixed reference to normalize the data in real time, I've gotten. And the fixed reference table is harvested in the same channel that data in real time.
How can I do this? (I tried the case structure over the stacked shift register, but it does not work...)
Thank you!
What you want to do is not clear. Tell me if that's what you want to do:
- Each iteration, get 768 points in a table "sample".
- Throw sample 1 to 200 bays.
- Calculate the average of berries sample of 201 to 220. Call this average table of sample.
- For all the "future" sample bays (what you want), record the Array - table of average sample sample.
Is this correct? If so, your algorithm can be expressed as a loop While (each loop Gets the data in a table in the sample) within which there is a Case statement to which is connected the index of the loop ('i'). If you increment 'i' before you wire this switch of case, the entries of your case will vary from 1... However, many samples you take, what makes easier "metering".
Create the following cases:
- .. 200 (which means that it is<= 200).="" this="" is="" the="" "do="" nothing"="" case="" where="" you="" throw="" the="" data="">
- 201, 219. It's "amounts Accumulate in the bays of the sample in a shift (initialization of the registry to an empty array) register.
- 220 add the final sample, divide by 20 and save (in the same shift register) as average sample table.
- 221... take your sample matrix, subtract table of average sample (of the shift register) and do what you want to do with your referenced sample.
If it's your algorithm, it is very simple to implement (as you can see). If you want to do something else, you will need to tell us specifically what you want to do, but maybe with the description I provided only, you might be able to understand for yourself how vary the algorithm. If you're still stuck, clarify what you have tried (this is very useful if you attach your code, which means a VI (not an image, please, if this is an 'executable image', as will us want to try it and it ourselves).) Among other things, the ambiguity in the description of Word of the algorithms are usually easier to understand by looking at the code.
Bob Schor
-
concatenate the data in 2 tables in a third table as well as in CONCATENATE strings
Hello. as the title says, I wish to only concatenate the data in 2 tables in a similar third table that concatenate strings don't. All tables should be 1 d. For example, suppose that there is 1 table with the following: 1. 2; 3; 4 and table 2 with:; b; c; d. I would like a table 3 either 1 a, 2 b, 3 c, 4 d. Now this could be done easily with above mentioned concatenate strings, then table construction. but table 1 and 2 have something like 150 items. Rather painful. Any ideas?
Hold arrays of two strings in a loop for example, concatentate the strings inside the loop and run the result réécrirait array3.
Autoindexing manages table manipulations.
MIke...
-
Leak memory in a simple loop to save data in the table?
Hello world
I'm trying to set up a simple code to read a certain amount of data in a table at a fixed sampling rate and put these data in a local variable. I'll put this on one OR cRIO-9073 using the scanning engine and the data comes from one NOR 9208 with a speed of approximately 250 Hz scanning, even if it is not really important at the moment.
I made this little test VI which I suspect contains a memory leak, but I'm not able to identify it. The reason for my suspicion is that when I run the vi on a VMWare virtual machine (LabVIEW 2010 on Windows XP) it claims soon that it is short-term memory. Of course, the problem is perhaps elsewhere, but I hope that someone more experienced with LabVIEW programming will be able to find all the bugs very easily because it is really a piece very simpel to code. :-)
I have included a copy of the VI with a screenshot to illustrate.
Regards, Martin
PS my code looks a bit awkward, so if anyone has a better solution, I'd be very happy to learn about it!
Hello Martin,
I would try a different approach to your problem. Currently you reshape your table each iteration of the loop. This means that the allocator memory of LV must find a new piece of contiguous memory each iteration of the loop. You're probably fragment your memory and so short of contiguous blocks of memory, leading to the release of messages from memory.
For these types of tasks, I recommend having an array of fixed size that you initialize outside the loop and then use the Replace table subset in the loop for updating the values. This avoids the problem of allocating memory you use in.
Alternatively, since I assume that you use the local variable to pass data to another loop, you can use a FIFO RT to manage data. A RT FIFO resembles a queue of LV, but it is designed so that you can keep determinism in your application. Set up an acquisition loop that exports data from the 9208 every 4ms in a RT FIFO. Then set up your processing loop to run at a slower pace - say every 200ms. The processing loop reads all the elements of the FIFO until it is empty every 200ms or a number of samples. The RT FIFO is fixed size, if you need to make it large enough to contain at least 200/4 = 50 samples. For more security, you should do several times bigger, maybe 200 samples. You can try different sizes of the FIFO and also to the different periods of your processing loop to your application's specifications.
Using this method you do not have to create a counter to track items, since the reading of FIFO function can tell you how many items is in the FIFO and also when it is empty.
I recommend you the example of Communication of FIFO of RT which comes with LabVIEW to get an idea of how to use these functions.
Gerardo
-
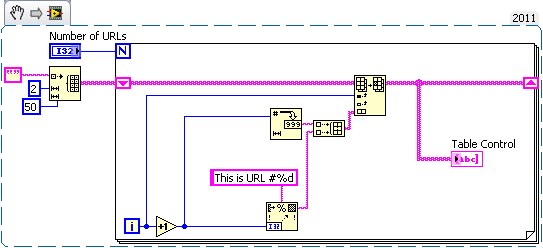
Writes the string data in a table
Hello
I am facing a problem in writing the data in the table. Here is its description:
1. I created a code that reads the URL from OPC.server.
2. I need to display it in a table. Since the number of URL is known, I defined the rows in the Table.
3 but am not able to display these URLS in the table.
This problem can be simply put on 'how to write string in the table. property node can be used and if so, what assets can be used?
I'm still a beginner in this... so would like help of all my colleagues LabVIEWers there
Thank you best regards &,.
Nadège.
This is a base update. The initialize array must be specified as a number greater than your maximum number of URLS.
-
Selection of data into a table
Hello
I'm trying to enter data in a table by using an instruction box to select the values of interest.
The problem is this, I am under a for loop and every time that it runs, it reads a specific value in the table (table 1), using the for loop index as the index for table 1. So I check whether this specific value = preset value
If Yes: the case statement writes the index in a table (table 2).
If it is not: the case statement writes a constant - I would like to not have to do, but unfortunately the case loop must have all the input terminals connected.
I would like the main table consist only of interest and no default values / values constant.
Any ideas?
You're abusing table to build. Wire you a table in a table entry and other values or the other. See the example I have attached.
-
How to add data to the table using Manager POST for restful Apex application
Hi all
I managed to create a service application web Manager restful using GET for the Restful service module. I am able to get the data in row on the presentation of a table row id in the application. But I can't find an appropriate example, how the new data in the table can be posted or deleted. I created a POST handler for a URI scheme and look forward on how to proceed. Any help would be really appreciated.
Source for the POST Manager:
Start
insert into ALL_BOOKS values(:id,:book);
end;
Also created 2 parameters id and the book.
Hi jerry2134,
jerry2134 wrote:
I managed to create a service application web Manager restful using GET for the Restful service module. I am able to get the data in row on the presentation of a table row id in the application. But I can't find an appropriate example, how the new data in the table can be posted or deleted. I created a POST handler for a URI scheme and look forward on how to proceed. Any help would be really appreciated.
Source for the POST Manager:
Start
insert into ALL_BOOKS values(:id,:book);
end;
Also created 2 parameters id and the book.
Check out the following tutorials OBE, that explains the creation of GET and POST RESTful Web Services and how to use them in the APEX.
- Creation and use of RESTful Web application services Express 4.2
- Creation and use of RESTful Web application services Express 5.0
Also what yo mean "looking forward on how to proceed? Do you want to or created for use/consume in your Oracle APEX application hosted RESTful web services?
If Yes, in your Application, you must create a RESTful Web Service reference -> shared components. Then, create a form/report based on Web Service reference.
Kind regards
Kiran
-
Hi friends,
I'm trying to load records into the rules of the product table of the table with the following...
create table product)
prod_id varchar2 (20).
prod_grp varchar2 (20).
from_amt number (10),
to_amt number (10),
share_amt number (10)
);
Insert into product (prod_id, prod_grp, from_amt, share_amt) Values ('10037', "STK", 1, 18);
Insert into product (prod_id, prod_grp, from_amt, share_amt) Values ('10037', "NSTK", 1: 16.2);
Insert into product (prod_id, prod_grp, from_amt, to_amt, share_amt) Values ('10038', "NSTK", 1, 5000, 12);
Insert into product (prod_id, prod_grp, from_amt, to_amt, share_amt) Values ('10038', "STK", 5001, 10000, 16);
Insert into product (prod_id, prod_grp, from_amt, share_amt) Values ('10038', "STK", 10001, 20);
Insert into product (prod_id, prod_grp, from_amt, to_amt, share_amt) Values ('10039', "NSTK", 1, 8000, 10);
Insert into product (prod_id, prod_grp, from_amt, share_amt) Values ('10039', "STK", 8001, 12);
create table rules)
rule_id varchar2 (30),
rule_grp varchar2 (10),
rate_1 number (10),
point_1 number (10),
rate_2 number (10),
point_2 number (10),
rate_3 number (10),
point_3 number (10)
);
Criteria of loading in the rules of the table:
rule_id - "RL" | Product.prod_id
rule_grp - product.prod_grp
rate_1 - product.share_amt where from_amt = 1
point_1 - product.to_amt
rate_2 - if product.to_amt in point_1 is not NULL, then find product.share_amt of the next record with the same rule_id/prod_id where from_amt (of the next record) = to_amt (current record -
point_1) + 1
point_2 - if product.to_amt in point_1 is not NULL, then find product.to_amt of the next record with the same rule_id/prod_id where from_amt (of the next record) = to_amt (current record - )
point_1) + 1
rate_3 - if product.to_amt in point_2 is not NULL, then find product.share_amt of the next record with the same rule_id/prod_id where from_amt (of the next record) = to_amt(current )
Enregistrement-point_2) + 1
point_3 - if product.to_amt in point_2 is not NULL, then find product.to_amt of the next record with the same rule_id/prod_id where from_amt (of the next record) = to_amt (current record - )
point_2) + 1
I tried to load the first columns (rule_id, rule_grp, rate_1, point_1, rate_2, point_2) via the sql loader.
SQL > select * from product;
PROD_ID PROD_GRP FROM_AMT TO_AMT SHARE_AMT
-------------------- -------------------- ---------- ---------- ----------
10037 STK 1 18
10037 NSTK 1 16
1 5000 12 NSTK 10038
10038 5001-10000-16 STK.
10038 10001 20 STK.
10039 1 8000 10 NSTK
10039 STK 8001 12
produit.dat
PROD_ID | PROD_GRP | FROM_AMT | TO_AMT | SHARE_AMT
"10037' |'. STK' | 1. 18
"10037' |'. NSTK' | 1. 16.2
'10038' |' NSTK' | 1. 5000 | 12
'10038' |' STK' | 5001 | 10000 | 16
'10038' |' STK' | 10001 | 20
"10039' |'. NSTK' | 1. 8000 | 10
"10039' |'. STK' | 8001 | 12
Product.CTL
options (Skip = 1)
load data
in the table rules
fields ended by ' |'
surrounded of possibly ' '.
trailing nullcols
(rule_id POSITION (1) ""RL"|: rule_id")
rule_grp
from_amt BOUNDFILLER
point_1
share_amt BOUNDFILLER
, rate_1 ' BOX WHEN: from_amt = 1 THEN: share_amt END.
, rate_2 expression "(sélectionnez pr.share_amt de produit pr où: point_1 n'est pas null et pr.prod_id=:rule_id et: point_1 =: from_amt + 1)" "
, expression point_2 "(sélectionnez pr.to_amt de produit pr où: point_1 n'est pas null et pr.prod_id=:rule_id et: point_1 =: from_amt + 1)" "
)
He has not any support only values in rate_2, point_2... no error either... Not sure if there is another method to do this...
Please give your suggestions... Thank you very much for your time
Hello
Thanks for posting the CREATE TABLE and INSERT instructions for the sample data; It's very useful!
Don't forget to post the exact results you want from this data in the sample, i.e. what you want the rule table to contain once the task is completed.
As ground has said, there is no interest to use SQLLDR to copy data from one table to another in the same database. Use INSERT, or perhaps MERGE.
2817195 wrote:
Thank you for your answers... I thought it would be easier to manipulate the data using sql loader... I tried to use insert but do not know how to insert values in point_2, rate_3, rate_2, point_3, columns... For example, when point_1 is not null, need to do a find for the next with the same rule_id record and if the inserted record = pr.from_amt + 1 point_1 then RATE_2 should be inserted with this pr.share_amt of this record...
SQL > insert into the rules)
2 rule_id,
rule_grp 3,.
rate_1 4,.
point_1 5,.
rate_2 6,.
point_2 7,.
rate_3 8,.
9 point_3)
10. Select
11 'RL ' | PR.prod_id RULE_ID,
12 pr.prod_grp RULE_GRP,
13 CASES WHEN END of pr.from_amt = 1 THEN pr.share_amt RATE_1,
14 pr.to_amt POINT_1,
15 (select pr.share_amt from product pr where point_1 is not null and rules.rule_id = pr.prod_id and point_1 = pr.from_amt + 1) RATE_2,
16 (select pr.to_amt from product pr where point_1 is not null and rules.rule_id = pr.prod_id and = pr.from_amt + 1 point_1) POINT_2,.
17 (select pr.share_amt from product pr where point_2 is not null and rules.rule_id = pr.prod_id and = pr.from_amt + 1 point_2) RATE_3,.
18 (select pr.to_amt from product pr where point_2 is not null and rules.rule_id = pr.prod_id and = pr.from_amt + 1 point_2) POINT_3
19 product pr;
(select pr.share_amt from product pr where point_1 is not null and point_1 = pr.from_amt + 1) RATE_2,
*
ERROR on line 15:
ORA-00904: "POINT_1": invalid identifier
Help, please... Thank you very much
This is what causes the error:
The subquery on line 15 references only 1 table in the FROM clause, and this table is produced. There is no point_1 column in the product.
A scalar subquery like this can be correlated to a table in the Super request, but the only table in the FROM (line 19) clause is also produced. Since the only table that you read is produced, only columns that you can read are the columns of the product table.
You use the same table alias (pr) to mean different things 5. It's very confusing. Create aliases for single table in any SQL statement. (What you trying to do, I bet you can do without all these subqueries, in any case.)
-
Insert data from 3 tables of diff with some transpose logic
Hi all
I need to create a MS which will have three settings:
Mast_report_id number, posted_on_date date, number of redord_id
I have four tables which one is the destination and reset three source tables:
The source tables:
1 - mast_report
create the table MAST_REPORT
(
MAST_REPORT_ID Number (38) not null,
ANNUAL NUMBER (38),
TITLE VARCHAR2 (500),
STATUS VARCHAR2 (10),
DATE OF POSTED_ON,
NO_OF_PAGES NUMBER (8).
BILLABLE_PAGES NUMBER (8).
MAST_LANGUAGE VARCHAR2 (20).
CONTRIBUTOR VARCHAR2 (80).
CRAWL_DATE TIMESTAMP (6) default sysdate,.
FILE_NAME VARCHAR2 (30),
PAGE_PRICE NUMBER (10,2).
DOC_PRICE NUMBER (10,2).
CONTRIBUTOR_ID NUMBER (20)
);
2 - report_details:
create the table REPORT_DETAILS
(
RECORD_ID Number (38) not null,
DOC_ID Number not null, (38)
ATTRIBUTE_TYPE VARCHAR2 (10),
ATTRIBUTE_VALUE VARCHAR2 (200),
REPORT_TYPE VARCHAR2 (100),
ATTRIBUTE_ID VARCHAR2 (80)
);
3 - filters_for_docid:
create the table FILTERS_FOR_DOCID
(
FILTER_ID Number not null, (38)
CONTRIBUTOR VARCHAR2 (100),
AUTHOR VARCHAR2 (100) default not null, "No. FILTERS".
COUNTRY VARCHAR2 (100) default not null, "No. FILTERS".
VARCHAR2 (100) region "No. FILTERS" not null default,
COMPANY VARCHAR2 (100) default not null, "No. FILTERS".
INDUSTRY VARCHAR2 (100) default not null, "No. FILTERS".
VARCHAR2 (100) of the default OBJECT not null, "No. FILTERS".
CREATED_DATE TIMESTAMP (6) SYSTIMESTAMP not null default,
REPORT_TYPE VARCHAR2 (100) default not null, "No. FILTERS".
NOM_FLUX VARCHAR2 (200),
CHANNEL_ID NUMBER (8).
NUMBER OF CU_ID
);
Destination table: filtered_document
database version:
BANNER 1 Oracle Database 11 g Release 11.2.0.1.0 - 64 bit Production 2 PL/SQL Release 11.2.0.1.0 - Production 3 CORE 11.2.0.1.0 Production 4 AMT for Linux: Version 11.2.0.1.0 - Production 5 NLSRTL Version 11.2.0.1.0 - Production As I menteioned above the user will pass three parameters: Mast_report_id, posted_on_date, redord_id
Here, I need to take more condition (>) to the three parameters.
For the extraction of data, the logic is below:
Mast_report table has two columns mast_report_id and posted_on, we need to take a larger than the condition as:
"Select * from mast_report where and mast_report_id > 7326280 and posted_on > 25 may 2015;
It will show many recordings roughly 10,000 with all the columns including annual column, this annual column is card with doc report_details of the table
Now report_details table, we need recover data with annual report_details = (all the table of mast_report annual that we extract our first query) and record_id > settings of this sp record id.
lets assume he'll again get 10000 files with all the columns.
Now the main logic is to extract the data of using our highest performance and the third table FILTERS_FOR_DOCID.
Assume that this is the result of our query above:
RECORD_ID ANNUAL ATTRIBUTE_TYPE ATTRIBUTE_VALUE REPORT_TYPE ATTRIBUTE_ID 1 70574112 69222703 COMPANY TGS NOPEC GEOPHYSICAL COMPANY ASA SOCIETY REPORT 100203621 2 71123704 69222704 COMPANY VOLVO AB SOCIETY REPORT 100062389 3 70962874 69222713 COMPANY PARTNERRE LTD. SOCIETY REPORT 100037448 4 70569150 69222713 COMPANY PARTNERRE LTD. SOCIETY REPORT 100037448 5 70567888 69222729 COMPANY VITAMIN SHOPPE INC. SOCIETY REPORT 108008193 6 70385748 69222749 COMPANY ABB LTD. SOCIETY REPORT 100096991 7 70962865 69222756 COMPANY METTLER-TOLEDO INTERNATIONAL INC. SOCIETY REPORT 100081108 8 70568978 69222756 COMPANY METTLER-TOLEDO INTERNATIONAL INC. SOCIETY REPORT 100081108 9 70385761 69222777 COMPANY SUNCOR ENERGY INC. SOCIETY REPORT 100063497 10 70569389 69222784 COMPANY SYMANTEC CORP. SOCIETY REPORT 100043382 11 71126764 69222786 COMPANY ARROW ELECTRONICS INC. SOCIETY REPORT 100084937 here if using separate attribute_type of report_details, we have:
Select distinct report_details attribute_type;
ATTRIBUTE_TYPE 1 Object 2 INDUSTRY 3 COUNTRY 4 REGION 5 AUTHOR 6 COMPANY Here you can see over the structure of the third table table FILTERS_FOR_DOCID where above these distinct values of the second table are the columns of the third:
And you can see the output of the query above to report_details table, including the attribute_type and attribute_type value.
Here, we need to find in the third table with each attribute_type and values of his attribute_type_value with the topic of the third table columns, industry,... He values.
as: consider attribute_type values 'COMPANY' and its "TGS NOPEC GEOPHYSICAL COMPANY ASA" attribute_value now we need to find
in SOCIETY the third table cloumn with value "TGS NOPEC GEOPHYSICAL COMPANY ASA"... same for others...
I must now go look for these lines of the third table which all combinations get matched, need us compare with like operator between the attribute_type column value and the value of the columns in the third diff table.
Thanks in advance
I have impleted above the requirement using pivot, CTE, and cases in where clause.
Thanks for all the help
-
Need a sql script loader to load data into a table
Hello
IM new to Oracle... Learn some basic things... and now I want the steps to do to load the data from a table dump file...
and the script for sql loader
Thanks in advance
Hello
You can do all these steps for loading data...
Step 1:
Create a table in Toad to load your data...
Step 2:
Creating a data file... Create your data file with column headers...
Step 3:
Creating a control file... Create your control file to load the data from the table data file (there is a structure of control file, you can search through the net)
Step 4:
Move the data file and the control file in the path of the server...
Step 5:
Load the data into the staging table using sql loader.
sqlldr control =
data = connect as: username/password@instance.
Maybe you are looking for
-
How to control the content of the ipod in itunes 12.5.1.21?
After the upgrade to itunes on my pc 12.5.1.21 the old 'device' icon near the toolbar is inactive (grayed out). I can see my devices in the left pane and I can see the contents of my ipod nano but I can't find where I can specify what to synchronize
-
Saving iOS Apps in iTunes Mac after disabling save iOS Apps
I can't seem to re - activate my Mac iTunes iOS applications record. I turned it off when I had very little storage, now I have more and you want to activate it. I tried everything I found. I use an iTunes account, and this is the installation & auth
-
where is add on option for new tab
I don't have the + (plus) sign to add a new tab in the line of the tab. So, basically, I need to go to file and click "new tab". Not practical for me.
-
I can't see anything in "my pictures".
'Windows Picture and Fax Viewer' seem to have removed itself which means that I can't see anything in "my pictures". Have tried the system restore several times with no luck and find nothing to reinstall on the microsoft Web site. Any ideas how I can
-
Rotary decoder in real-time and 'pulse shifter '.
Hello world I'm putting in place a rotating decoder for use as a shifter of pulsation by labview real-time. Basically, this means I have two input channels (ttl-legumes, ~ high 20us) rotary engine. A channel contains a pulse at each CA (angle cranc)