Table operation - Offset value
Hi all
I want to compensate my DAQ data. Could one of you help me with that? Thank you.
Table 2D is my DAQ data
1 1 1 1 1
2 2 2 2 2
3 3 3 3 3
4 4 4 4 4
I'd like to average the first 5 points of data such as offset values. I finished this part and I got the offset table 1 d
1
2
3
4
The function that I relize is at least offset from the data table values.
1 1 1 1 1 1 1 1 1 1
2 2 2 2 2 2 2 2 2 2
3 3 3 3 3 - 3 3 3 3 3
4 4 4 4 4 4 4 4 4 4
Is it possible, devrais I develop the table 1 d 2D table before you do the math? Thank you.
Get the first column, then subtract the 2D array.
Transposed simply because of the behavior of autoindexing. Here is an example.

Tags: NI Software
Similar Questions
-
Remove the table if the value not in APEX_APPLICATION. G_f01?
Hello again!
I have an apex_application.g_f01 that contains the values in the boxes, now I want apex to remove rows from the table that contains values that are not present in the G_f01 (what are disabled) on submit.
I can't understand the sql code to do this, could someone give an example?
This can be a simple thing, but I'm getting confused a lot with sql, maybe because I just php and java.
EgaSega wrote:
I have an apex_application.g_f01 that contains the values in the boxes, now I want apex to remove rows from the table that contains values that are not present in the G_f01 (what are disabled) on submit.
I can't understand the sql code to do this, could someone give an example?
This can be a simple thing, but I'm getting confused a lot with sql, maybe because I just php and java.
One possibility would be to create a collection of APEX containing key checked values and use that as the source of the lines to be kept in the SQL delete. Something like:
begin apex_collection.create_or_truncate_collection('CHECKED_VALUES'); for i in 1..apex_application.g_f01.count loop apex_collection.add_member( p_collection_name => 'CHECKED_VALUES' , p_c001 => apex_application.g_f01(i)); end loop; delete from t where not exists (select null from apex_collections c where collection_name = 'CHECKED_VALUES' and c.c001 = t.id); end; -
In the column of table when the values are grater that maximum linear axis it does not show the bar
Hi guys,.
In the column of table when the values are grater than there maximum linear axis it does not show the Bar.But I want to display the bar up to the maximum limit of the axis is linear without changing the limit max.
Consider following the example:
The values are 80 90 200 300
and here is the result:
Left: when I don't put maximum property of linear axis.
Right: when I put in maximum property of linear axis to 200.

Law 4th bar is not visible because the value of this bar is 300 which is excedding maxium. But I want the 4th bar to appear identical to 3 bar.
How can I do this?
Thanks in advance.
Then you should change the value of Y to the maximum value.
Another option, you should consider is changing the Render item column to reflect that the value is greater than the specified maximum value.
-
Update the value Table B if table A the value of different
Hi all
I'm using Toad for Oracle and need assistance with a trigger. I have two tables tables A and B Table with some of the same fields. I want to only update the values in the array B, if the values in table A are not equal values in table B table A update. Don't update the record where the primary key of the Table equal to the foreign key in the Table B. I have a sample script below, I hope someone can give me an example, I can develop and test. Thanks for reading also.
Published by: Nikki on December 6, 2011 07:50CREATE OR REPLACE TRIGGER AU_Table_A AFTER UPDATE ON Table_A FOR EACH ROW BEGIN If Table A :old.value != Table A :new.value then update --Update Table B value with Table A updated value Table B :old.value = Table A :new.value where Table A primary key = Table B foreign key ............ END IF; END;Hi Nikki,
If I understand correctly, then maybe
create or replace trigger au_table_a after update on table_a for each row when (old.value != new.value) begin update table_b set table_b.value = :new.value where table_b.foreign_key = :new.primary_key and table_b.value != :new.value; end au_table_a; /Note that the solution is not trying to handle NULL values. If you have NULL in to either A or B, we have to manage those specifically
Concerning
Peter -
How to build a list or a table with fixed values?
Is it possible to create a list or a table with fixed values, but with a variable length?
for example:
var columns = "name, age, function;
var insertParams = generateList ( listLen (columns), ',','.) » ); *
fact: insertParams = ',?,??
* (this function does not exist. This is just to illustrate what I need)
I know that this feature is easily created by creating a loop, but I was wondering if it was possible with a single line of code.
Thank you
If he can generate a table in the same way, which would be as well.
Our messages have clashed. But I think that repeatString() would do the trick. You could cut the rear comma with left() or convert it to a table. By default, ListToArray() will silently ignore the trailing comma.
-
Fill the table with random values
Another thing I've come across is this:
the table name is LOR, who has 3 fields NUMBER, DATA, TEXT with number, date and varchar2 data type.
On a page, I have a text field where if I write 3, then it would add 3 lines to the table with predefined values ("number, something like 2222, for 12 January 09, and for text, something like" Lorem ipsum dolor sit amet, 195kgs adipisicing elit"). So basically, with the number that I give, it populates the table with lines... How can I do this? Thanks for helping meINSERT INTO LOR SELECT 222 , sysdate , 'you string' FROM dual CONNECT BY level <= :Pxx_ -
Replace the subset of table operation
I have a code to a key VI event down that toggles the visibility of some indicators in response to press the function keys. Records using Boolean shift, the code worked with a few indicators.
To scale to a large number of indicators, I decided that I would need convert a registry to offset single Boolean array.
With the shift table Boolean register, for a given function key, the code reverse the Boolean value of the table for the property node Visible, then replaces the same item in the table of Boolean with the inverted Boolean value. The code does not work. Once the indicator is visible, he won't go invisible on the next push of button.
I watched the execution, display values. Looks like that replace it table subset VI is not replace the Boolean value with the updated value. In the attached screenshot, you can see where I got the element of the array once it has been "updated" to replace table VI of subset. Impossible to find all the bugs in the list of bug LV2013.
See the attached screenshot. What's wrong with this code? My apologies for the resolution of the screen capture. If necessary, I'll go back to the lab and try to capture a screenshot of higher resolution.
On-screen turned your empty Boolean arrayis, in other words, it has no elements. Subset of the table Replace does not work with an empty array.
See you soon,.
McDuff
-
Strange behavior while making the table operation DOUBLE... !
Hello
Can we do DML/DDL operation on table DOUBLE?
To know the answer, I have done below the operation and found a strange behavior...
-run 5 times...
INSERT INTO DOUBLE
VALUES ('P');
commit;
Select * twice;
o/p-
MODEL
1 P
2 P
3 P
4 P
5 P
---------------------------------
updated double
MODEL of value = "K";
commit;
Select * twice;
o/p-
MODEL
2 h
2 P
3 P
4 P
5 P
Odd: 1 single line update... Why? I was updating all the lines.
If I run new update of command like below...
updated double
set MODEL = 'K', where dummy = "P";
commit;
Select * twice;
o/p-
MODEL
2 h
1 h
3 P
4 P
5 P
STRANGE: Now next updated record with 'K'... like that, if I run 5 times this o/p is as below...
MODEL
2 h
1 h
6.
4 K
6: 00
-------------------------------------
REMOVE double; -This also has data of delting 1 by 1 row... Why?
Can anyone tell me about this operation of behaivor?
Please provide any information about the DML/DDl operation on DUAl
Rgds,
PChttp://asktom.Oracle.com/pls/asktom/f?p=100:11:7955478831730544:P11_QUESTION_ID:1562813956388
Tom says:
Let me start by saying:-DOUBLE is owned by SYS. SYS is the owner of the data dictionary,
so DOUBLE fits in the data dictionary. You must not modify the data dictionary
through SQL ever - weird things can and will happen - you are just a few of
them. We can do a lot of strange things happen in Oracle by updating the data dictionary.
It is recommended, supported or a very good idea.Double is just a convienence table. You do not need to use it, you can use anything you
Here you are. The advantage to double is the optimizer includes double is a special line, a
column table - when it is used in queries, it uses this knowledge during the development of the
plan.
...
the optimizer includes double is a special, magical table 1 row... It's just the way it works. If all goes well
you reset double back to 1 row after your tests, or you've just totally broken your database!
.. .dual = magic. Dual is a table of a line but with more than 1 or less is
dangerous. You update the data dictionary. You should expect naturally very bad
things are happening. -
operations on values separated by commas...
Hi all
We have histogramic values that are stored in a column, and from time to time, we need to spread them to fill the tables of history as:
table_1
C1 - c2 - c3
-------------------
a 1,1,1--11
a 2,2,2--11
a 3,3,3--11
b - 4, 4, 4-22
b - 5, 5, 5-22
c - 6, 6, 6-22
Select c1, sum? (c2), (c3) sum of the table_1 by c1 group;
C1 - sum? (c2) - sum (c3)
-----------------------------------------
a 6,6,6--33
b - 15, 15, 15-66
The goal is to make the seperaterly of operations with the first value, the second value,... separately.
Any ideas on this subject?
Thank you
EvrenHi, Evren,
Welcome to the forum!
Whenever you have a problem, it helps if you post your sample data in a form that people can use to actually re-create it.
CREATE TABLE and INSERT statements are great. for example:CREATE TABLE table_1 ( c1 VARCHAR2 (5) , c2 VARCHAR2 (20) , c3 NUMBER ); INSERT INTO table_1 (c1, c2, c3) VALUES ('a', '1,1,1', 11); INSERT INTO table_1 (c1, c2, c3) VALUES ('a', '2,2,2', 11); INSERT INTO table_1 (c1, c2, c3) VALUES ('a', '3,3,3', 11); INSERT INTO table_1 (c1, c2, c3) VALUES ('b', '4,4,4', 22); INSERT INTO table_1 (c1, c2, c3) VALUES ('b', '5,5,5', 22); INSERT INTO table_1 (c1, c2, c3) VALUES ('c', '6,6,6', 22);This isn't a very good design. If the elements of c2 are separate entities, they should be in separate columns (or perhaps on the lines of sepaarte, in a separate table, with a one-to-many relationship in table_1).
If you cannot change the structure of the table at all times (which is the best solution), then you will need to generate a result set that mimics that (more or less) every time you need to use this column as separate entities.
[This thread | http://forums.oracle.com/forums/thread.jspa?threadID=945432&tstart=0] shows how to split a delimited in parts list.Once you have calculated the individual totals, use it. operator to cram them in a single column, if necessary.
For example:SELECT c1 , SUM (TO_NUMBER (REGEXP_SUBSTR (c2, '[^,]+', 1, 1))) || ',' || SUM (TO_NUMBER (REGEXP_SUBSTR (c2, '[^,]+', 1, 2))) || ',' || SUM (TO_NUMBER (REGEXP_SUBSTR (c2, '[^,]+', 1, 3))) AS sum_c2 , SUM (c3) AS sum_c3 FROM table_1 GROUP BY c1 ;[email protected] wrote: Hi all,.
We have histogramic values that are stored in a column, and from time to time, we need to spread them to fill the tables of history as:table_1
C1 - c2 - c3
-------------------
a 1,1,1--11
a 2,2,2--11
a 3,3,3--11
b - 4, 4, 4-22
b - 5, 5, 5-22
c - 6, 6, 6-22Select c1, sum? (c2), (c3) sum of the table_1 by c1 group;
C1 - sum? (c2) - sum (c3)
-----------------------------------------
a 6,6,6--33
b - 15, 15, 15-66Are you sure that's the output you want from the data you gave?
When I run the query above with the same data, I get:C1 SUM_C2 SUM_C3 ----- -------------------- ---------- a 6,6,6 33 b 9,9,9 44 c 6,6,6 22 -
Generation of the table of all values of 30 at a time
Hey, I measure all 30 temperature both values and generate the table of values of 30
every minute...
How to extract a 30 value at the same time and at the same time! I'm a problem inside!
Here is a version with simpler data structures. Maybe this can give you some ideas.

-
Behavior strange table when getting values
I have a table that contains the TypeDef'd controls and I need to get a reference to the control of each element individually. To do this, I use the values property of the array Index that I put to the index of the item that I want to get. From there on, I can get a reference to the control. This occurs when the value of the table is changed through a simple value change event.
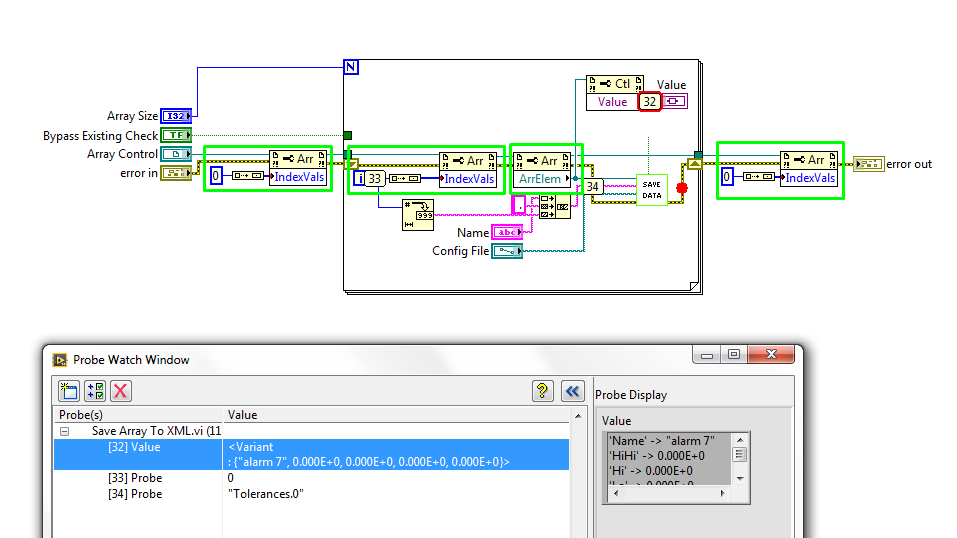
When you change the value of an element, and then by using the property of Index values for the reference control at this level, the control returned reference is not one that should be. What seems to happen when I change an element in an array, this item automatically becomes the index '0' in the table itself. It's a very strange behaviour and I tried to go around for a little while. I've attached pictures of the screw that I use to show you everything.
In the first image, I stressed the important portions in green. Going from left to right, the first Green Watch box that I'll put the index at which the table should be starting at 0. The reason I do this is because it is possible that the index display may be replaced by another value and lag between what we expect, it is (0). In the loop for, I set the property to Index values for what is the value of i. This, in theory, loop through all the items in the table, and then I get the value and the reference of this element. In the probe window, you can see the different values of the sons and I will refer to this in a second.
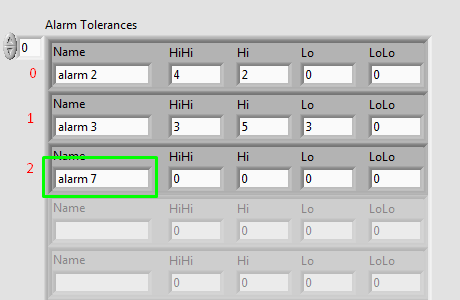
In the second picture you can see the value of the table on the real front. The values of the sensors in the first picture taken after that I changed the value of one of the properties of the "Alarm 7" line. The value of the façade, it is clear that the 'Alarm 7' index value is 2, but when you look at the probe in the first image there shows that it is at index 0. Anyone know why this is happening and how to get the references to their actual index?
1.
2.
-
Hello
I'm trying to achieve the following objectives:
1. in table A, select rows based on the values in column 2. something like SELECT * FROM TABLE A WHERE (COLUMN2 = 'X' or Column2 IS NULL)
2 and these values selected, I want to update Column3 from Table A if TableA.column1 = TableB.column1, but only if there is exactly one game. If there are multiple matches, column 3 of the table article updated.
That's what I've tried so far.
UPDATE TABLE_A
SET
TABLE_A.COLUMN3 = (SELECT COLUMN3 OF TABLE_B
WHERE ((TABLE_B.COLUMN1 = TABLE_A.COLUMN1) AND ( TABLE_B.COLUMN1 IN (SELECT Column1 FROM TABLE_B GROUP BY COLUMN1 , HAVING COUNT (*) = 1)))
WHERE EXISTS (SELECT * FROM TABLE_A)
WHERE ((TABLE_A.COLUMN2 = 'X' OU TABLE_A.COLUMN2 = 'Y') AND (TABLE_A.COLUMN4 IS NULL OR TABLE_A.COLUMN4 = ' ')));
More details on my DB environment:
Version Info:
Oracle Database 11 g Enterprise Edition Release 11.2.0.4.0 - 64 bit Production
PL/SQL Release 11.2.0.4.0 - Production
Toad, but, depending on whether the query updated all lines. I would really appreciate if someone could tell me how to fix my request.
Thanks in advance.
Exists it predicate in the block of update will be set to true if there is at least one row in table_a where column2 is X or Y and column4 is null or a space. You need to correlate exists it with the outer query query (I'm guessing on column1) to get the result I think you want. However, who would update all rows in table_a who meets the criteria, there is a corresponding row in table_b, affecting Column3 lines form null not matched or not. (Again), I'm guessing that's not your intention. If you only want to update the lines in table_a which have a corresponding line in table_b and meet the other predicate, then I think you want something more like:
Update table_a
Set table_a.column3 = (select column3 of table_b
where table_b.column1 = table_a.column1 and
Table_B.Column1 in (select column1 from table_b
Group by column1, having count (*) = 1))
where ((table_a.column2 = 'X' ou))
table_a.Column2 = 'Y') and
(table_a.column4 is null or)
table_a.column4 = ' ')) and
table_a.Column1 in (select column1 from table_b
Group by column1, having count (*) = 1)
John
-
ADF table change the value of a column rest after executeQuery
Referring to the instance, which is to correct the cause and especially implemented to solve this problem-
I'll have a search form and the basis of the table of results based on entity vo. The table of results is in mode editall. If I change the value in the inputtext for a line and I click on search again, I expect the value modified to reset. The text component is not autosubmit.
If I put resetactionlistener in the search button, it works, but it resets then some other components which I don't want. This makes me think under analysis is tris -.
'But chooses to render using the value sent instead of the value of the database '.
What is the correct implementation to handle this?
Stamped UI components (such as af:table) have resetStampState() method.
Then you can try something like:
table.resetStampState ();
AdfFacesContext.getCurrentInstance () .addPartialTarget (table);
Dario
-
Loading the values of XML tag parent in the Oracle table and the values of the child
<project>
<id>001</id>
<name>Math Project</name>
.
.
<team>
<id>1</id>
<name> Team Roger </name>
.
.
</team>
</project>
<project>
<id>002</id>
<name>Science Project</name>
.
.
<team>
<id>2</id>
<name> Team Alpha </name> .
</team>
<team>
<id>3</id>
<name>Team Romeo </id>
</project>It's the structure of the XML where the content is changed daily and the file is placed in "D:\Test_Dir". I'm trying to load a table (teams) with the details of the team and its corresponding parent, like this project:
proj_id team_id team_name
001 1 Team Roger
002 2 Team Alpha
002 3 Team Romeo
Below is the pl/sql block I wrote:
declare
cursor proj_cur is select project_id from projects;
proj_rec proj_cur%rowtype;
begin
for proj_rec in proj_cur
loop
INSERT INTO teams(team_id,team_name,project_id)
WITH t AS (SELECT xmltype(bfilename('TEST_DIR','SCRUM.xml'), nls_charset_id('UTF8')) xmlcol FROM dual)
SELECT
extractValue(value(x),'*/id')team_id
,extractValue(value(x),'*/name') team_name
,extractValue(value(y),'/project/id') project_id
FROM t,TABLE(XMLSequence(extract(t.xmlcol,'/scrumwise-export/data/account/projects/project'))) y
,TABLE(XMLSequence(extract(t.xmlcol,'/scrumwise-export/data/account/projects/project/people/teams/team'))) x
where (extractValue(value(y),'/project/id'))='emp_rec.project_id';
end loop;
end;This returns a cartesian product! Any help with this is much appreciated.A few additional tips BTW:
-do not use wildcards (*) when you really know the structure of the XML document and the name of the node you want to extract.
-use the UTF8 character set is not recommended because it supports any valid XML characters. Use rather AL32UTF8 .
So, similar to Kim:
select proj.project_id , team.team_id , team.team_name from xmltable( '/scrumwise-export/data/account/projects/project' passing xmltype(bfilename('XML_DIR','SCRUM.xml'), nls_charset_id('AL32UTF8')) columns project_id varchar2(3) path 'id' , teams xmltype path 'people/teams/team' ) proj , xmltable( '/team' passing proj.teams columns team_id number path 'id' , team_name varchar2(100) path 'name' ) team where exists ( select null from projects p where p.id = proj.project_id ) ;Or a shorter version using a single XMLTABLE:
select team.project_id , team.team_id , team.team_name from xmltable( 'for $i in /scrumwise-export/data/account/projects/project , $j in $i/people/teams/team return element r { element project_id {$i/id} , $j/id , $j/name }' passing xmltype(bfilename('XML_DIR','SCRUM.xml'), nls_charset_id('AL32UTF8')) columns project_id varchar2(3) path 'project_id' , team_id number path 'id' , team_name varchar2(100) path 'name' ) team where exists ( select null from projects p where p.id = team.project_id ) ;And if a project can have no team, you can the outer join the XMLTABLE 2nd instead:
, xmltable( '/team' passing proj.teams columns team_id number path 'id' , team_name varchar2(100) path 'name' ) (+) team -
ORA-02374: error loading conversion table / ORA-12899: value too large for column
Hi all.
Yesterday I got a dump of a database that I don't have access and Production is not under my administration. This release was delivered to me because it was necessary to update a database of development with some new records of the Production tables.
The Production database has NLS_CHARACTERSET = WE8ISO8859P1 and development database a NLS_CHARACTERSET = AL32UTF8 and it must be in that CHARACTER set because of the Application requirements.
During the import of this discharge, two tables you have a problem with ORA-02374 and ORA-12899. The results were that six records failed because of this conversion problem. I list the errors below in this thread.
Read the note ID 1922020.1 (import and insert with ORA-12899 questions: value too large for column) I could see that Oracle gives an alternative and a workaround that is to create a file .sql with content metadata and then modifying the columns that you have the problem with the TANK, instead of BYTE value. So, as a result of the document, I done the workaround and generated a discharge .sql file. Read the contents of the file after completing the import that I saw that the columns were already in the CHAR value.
Does anyone have an alternative workaround for these cases? Because I can't change the CHARACTER set of the database the database of development and Production, and is not a good idea to keep these missing documents.
Errors received import the dump: (the two columns listed below are VARCHAR2 (4000))
ORA-02374: error loading «PPM» conversion table "" KNTA_SAVED_SEARCH_FILTERS ".
ORA-12899: value too large for column FILTER_HIDDEN_VALUE (real: 3929, maximum: 4000)
"ORA-02372: row data: FILTER_HIDDEN_VALUE: 5.93.44667. (NET. (UNO) - NET BI. UNO - Ambiente tests '
. . imported "PPM". "' KNTA_SAVED_SEARCH_FILTERS ' 5,492 MB 42221 42225-offline
ORA-02374: error loading «PPM» conversion table "" KDSH_DATA_SOURCES_NLS ".
ORA-12899: value too large for column BASE_FROM_CLAUSE (real: 3988, maximum: 4000)
ORA-02372: row data: BASE_FROM_CLAUSE: 0 X '46524F4D20706D5F70726F6A6563747320700A494E4E455220 '.
. . imported "PPM". "' KDSH_DATA_SOURCES_NLS ' lines 229 of the 230 308.4 KB
Thank you very much
Bruno Palma
Even with the semantics of TANK, the bytes for a column VARCHAR2 max length is 4000 (pre 12 c)
OLA Yehia makes reference to the support doc that explains your options - but essentially, in this case with a VARCHAR2 (4000), you need either to lose data or change your data type of VARCHAR2 (4000) to CLOB.
Suggest you read the note.

Maybe you are looking for
-
I hope that the company or that someone can help me. I've owned an HP 17BII calculator. I used it for many years and had many precious equations programmed into the machine. I even asked graduate students to buy the calculator in my classes at UCL
-
Pavilion P6510f: I get an AMD RAIDXpert error message every day
I get the same error several times in less than a minute each time. The only difference seems to be the date/time group. I think that this occurred shortly after the upgrade from Windows 7 to Windows 10. AMD RAIDXpert[20/01/2016 11:01:45]Task b0 ti
-
Computer is stuck in a reboot loop, while security updats
ORIGINAL TITLE: reboot problem Computer is stuck in a reboot loop, while security updats
-
Pavilion dv6-3080el: HP Pavilion dv6-3080el ssd
Hello forum,. I (as the title suggests) a HP Pavilion dv6-3080el laptop bought a long time but always beautiful show.I want to make betterly making by introducing an SSD. Is it possible to replace cd player the ssd Pentecost?Then ay can you tell me w
-
Hello I have a client with unity 4.0.4 and the SQL was installed on the c: drive, which is lack of disk space. Is there a way I can move their SQL the D: drive. Thank you