Transformation slow simple SQL extraction
Hello!
I have a query:
SELECT A.PID, A.ID, B.SID, (SELECT COUNT (*)
Of
B TREE_VIEW WHERE B.PID = A.ID) TREE_VIEW WHERE A.PID = BRANCH_COUNT
V ('P30_BRANCH_ID') ORDER BY ID
Table CN_SECTION has 131 000 lines, TREE_VIEW - view, which limit only the number of columns in the table.
External system query runs in 5 seconds, but on DB (from TOAD), it runs from 0,5 sec.
TKPROOF:
SQL ID: 7m1ykt8rc626r
Plan of Hash: 1808150050
SELECT A.PID, A.ID, a. theNAME, (SELECT COUNT(*)
Of
TREE_VIEW B WHERE B.PID = A.ID) BRANCH_COUNT OF TREE_VIEW = an A.PID WHERE
V ('P30_BRANCH_ID') ORDER BY ID
call number of cpu elapsed disc question current lines
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Run 1 0.00 0.00 0 0 0 0
Go get 1 4.87 5.50 0 16330 0 22
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3 4.87 5.50 0 16330 0 22
Lack in bookstores during parsing cache: 0
Optimizer mode: ALL_ROWS
The analysis of the user id: 68 (recursive depth: 2)
Operation of line Source lines
------- ---------------------------------------------------
22 SORT GLOBAL (cr =15620 pr =0 pw =0 time=0 us)
0 TABLE ACCESS FULL CN_SECTION (cr =15620 pr =0 pw =0 time=0 us cost =206 size=120 card =24)
22 SORT ORDER BY (cr =16330 pr =0 pw =0 time=84 we cost =221 size=336 card =24)
22 TABLE ACCESS FULL CN_SECTION (cr =710 pr =0 pw =0 time=2457 we cost =220 size=336 card =24)
I think that the problem is. Why could that be? What can I do something to fix?
Hi Plugif,
You use a function to get the value of P30_BRANCH_ID. Have you tried to use a variable to link instead?
In the case of Apex, use: P30_BRANCH_ID
If outside Apex, set a variable to this value or pass it as a parameter and use this variable in your query.
--
Patrick
Tags: Database
Similar Questions
-
Output is not as expected (getting wrapped) for a simple sql script
Hello
I try to run a simple sql script with a few queries including a semi colon output (;) when text file separated that later - I can open in excel.
My SQL file contains in part the code - below
SELECT
"PORTFOLIO" | « ; » ||
"CONTRACT # | « ; » ||
"CONS_INV #" | « ; » ||
"CUSTOMER #" | « ; » ||
"CLIENT_NAME | « ; » ||
'MESSAGE ' | « ; » ||
"REQUEST_ID" | « ; » ||
"BILL_TO_COUNTRY" | « ; » ||
"BILL_TO_ADDRESS1" | « ; » ||
"BILL_TO_ADDRESS2" | « ; » ||
"BILL_TO_ADDRESS3" | « ; » ||
"BILL_TO_ADDRESS4" | « ; » ||
"BILL_TO_CITY" | « ; » ||
"BILL_TO_POSTAL_CODE" | « ; » ||
"BILL_TO_STATE" | « ; » ||
"BILL_TO_PROVINCE" | « ; » ||
"BILL_TO_COUNTY" | « ; » ||
"SHIP_TO_COUNTRY | « ; » ||
"SHIP_TO_ADDRESS1" | « ; » ||
"SHIP_TO_ADDRESS2" | « ; » ||
"SHIP_TO_ADDRESS3" | « ; » ||
"SHIP_TO_ADDRESS4" | « ; » ||
"SHIP_TO_CITY" | « ; » ||
"SHIP_TO_POSTAL_CODE" | « ; » ||
"SHIP_TO_STATE | « ; » ||
"SHIP_TO_PROVINCE" | « ; » ||
"SHIP_TO_COUNTY" | « ; » ||
"INVOICE_DATE | « ; » ||
"INVOICE_CREATION_DATE" | « ; » ||
"PARTIALLY_DROPPED" | « ; » ||
"AMOUNT".
OF the double
/
SELECT "DOUBLE
/
SELECT "error Code" | « ; » ||' Error message "OF the DOUBLE
/
SELECT lookup_code. « ; » || Description
OF fnd_lookup_values
WHERE lookup_type = 'CUST_ERROR. '
/
The issue I'm facing is that the output of the competitive program file comes out bit so enter each line only 132 characters in a line and therefore gets pushed in the next row in excel.
Output-
PORTFOLIO; CONTRACT #; CONS_INV #; CUSTOMER #; CLIENT_NAME; MESSAGE; REQUEST_ID; BILL_TO_COUNTRY; BILL_TO_ADDRESS1; BILL_TO_ADDRESS2; BILL_TO_A
DDRESS3; BILL_TO_ADDRESS4; BILL_TO_CITY; BILL_TO_POSTAL_CODE; BILL_TO_STATE; BILL_TO_PROVINCE; BILL_TO_COUNTY; SHIP_TO_COUNTRY; SHIP_TO_ADDR
ESS1; SHIP_TO_ADDRESS2; SHIP_TO_ADDRESS3; SHIP_TO_ADDRESS4; SHIP_TO_CITY; SHIP_TO_POSTAL_CODE; SHIP_TO_STATE; SHIP_TO_PROVINCE; SHIP_TO_COUN
TY; INVOICE_DATE; INVOICE_CREATION_DATE; PARTIALLY_DROPPED; AMOUNT
Please advice on all of the commands that I can use in the script sql in order to expand the output page or any other workaround solutions!
Please answer as soon as possible if you can help me!
Thank you!SQL * MORE?
SQL> set lin 1000 SQL> spool your_file_out.csv SQL> your_query SQL> spool offKind regards
Malakshinov Sayan -
How to make this simple sql run faster?
Here is a very simple sql, but it takes too long to finish as an hour or more, and the problem is in the table. It's a huge table with 17660025 lines.
In addition, upd_dt is indexed.
Execution plan seems to be no problem: (is 9i, and I do not think that it would not perform better if the UNIQUE HASH is used instead of SORT UNIQUE)select distinct (dstn_type) from ims_ets_prty_msge where ims_ets_prty_msge.upd_dt > sysdate - 30;
Here is some info on the table----------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost | ----------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 6 | 78 | 1409 | | 1 | SORT UNIQUE | | 6 | 78 | 1409 | | 2 | TABLE ACCESS BY INDEX ROWID| IMS_ETS_PRTY_MSGE | 856K| 10M| 10 | |* 3 | INDEX RANGE SCAN | IMS_ETS_PRTY_MSGE_INDX5 | 154K| | 2 | ----------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("IMS_ETS_PRTY_MSGE"."UPD_DT">SYSDATE@!-30) Note: cpu costing is off
The thing is that we must make it run faster.NUM_ROWS BLOCKS EMPTY_BLOCKS AVG_SPACE CHAIN_CNT AVG_ROW_LEN 17129540 455259 622 502 455278 188
And all I can think is to create a bitmap on dstn_type (low cardinality) index and partition the table using upd_dt;
So my question would be is anyway that we can get a better response time without having to make that kind of change?
Or is this kind of change really help?
Any thoughts would be appreciated!
Thank youHave you thought about putting an index on (upd_dt, dstn_type)?
With the query you posted, and this index, it should be possible to use a full scan of the index, no visit to the table at all.
A bitmap index would not be a good idea, if it is an OLTP application / table.
-
Is there a way to get a 'default' DataTemplate based on a simple sql query?
Hi all
I wonder if there is a way to produce a default value of the DataTemplate (or at least the dataStructure of the model portion).
I like to call a trigger beforeReport to fill in the data for the report as such, I have to use dataTemplate instead of a simple SQL query, "select * from table_name". I have more than 50 columns on the report so I was hoping that I could not manually built a dataTemplate (or at less the part of dataStructure) for each report just be able to call a trigger.
Thanks in advance for your ideas.
Kind regards
YahyaYou need not define the cases you need the xml structure to be automatically decided by BEEP.
This datatemplate allows you to get the following structure
.. .. .. .. .. .. |
/LIST_ROW>.. .. -
Slow down execution SQL - extracting data from the FACT Table
taHi,
We have a SQL that runs slowly.
Select / * + ALL_ROWS PARALLEL (F 8) * /.
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_GRP_ID,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_BIL_UNT_ID,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_BNF_PKG_CD,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_UNDWR_CD,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_CAC_CD,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_RTMS_HLTH_COV_CD,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_ACTUR_RSRV_CATEG_CD,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_BNF_TYP_CD,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_GRP_BGIN_DT,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_GRP_END_DT,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_PLN_SEL_CD,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_SBGRP_NM,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_SBGRP_TYP_CD,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_SBGRP_TYP_DESC,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_COBRA_IND,
IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_SBGRP_POL_NBR,
IA_OASIS_GRP_CAPTR_D.GRP_POL_CD,
IA_OASIS_MBR_CAPTR_D.MBR_CAPTR_SBSCR_ALTN_ID,
IA_OASIS_MBR_CAPTR_D.MBR_CAPTR_RLNSP_CD,
IA_OASIS_MBR_CAPTR_D.MBR_CAPTR_GNDR_CD,
IA_OASIS_MBR_CAPTR_D.MBR_CAPTR_BTH_DT,
IA_OASIS_MBR_CAPTR_D.MBR_CAPTR_MBR_ID,
IA_OASIS_MBR_CAPTR_D.MBR_CAPTR_SBSCR_SCTR_CD,
IA_OASIS_MBR_CAPTR_D.MBR_CAPTR_SBSCR_RGN_CD,
IA_OASIS_MBR_CAPTR_D.MBR_CAPTR_SBSCR_ZIP_CD,
IA_OASIS_MBR_CAPTR_D.MBR_CAPTR_BDGT_RPT_CLS_CD,
IA_OASIS_MBR_CAPTR_D.MBR_CAPTR_WORK_DEPT_CD,
IA_OASIS_MBR_CAPTR_D.BSC_DUAL_IN_HOUSE_IND,
IA_OASIS_MBR_CAPTR_D.MEDCR_HICN_NUM,
IA_OASIS_CLM_SPEC_D.CLM_PRI_DIAG_CD,
IA_OASIS_CLM_SPEC_D.CLM_PRI_DIAG_BCKWD_MAP_IND,
IA_OASIS_CLM_SPEC_D.CLM_PRI_ICD10_DIAG_CD,
IA_OASIS_CLM_SPEC_D.ICD_CD_SET_TYP_CD,
IA_OASIS_CLM_SPEC_D.CLM_APG_CD,
IA_OASIS_CLM_SPEC_D.CLM_PTNT_DRG_CD,
IA_OASIS_CLM_SPEC_D.CLM_PROC_CD,
IA_OASIS_CLM_SPEC_D.CLM_PROC_MOD_1_CD,
IA_OASIS_CLM_SPEC_D.CLM_PROC_MOD_2_CD,
IA_OASIS_CLM_SPEC_D.CLM_POS_CD,
IA_OASIS_CLM_SPEC_D.CLM_TOS_CD,
IA_OASIS_CLM_SPEC_D.CLM_PGM_CD,
IA_OASIS_CLM_SPEC_D.CLM_CLS_CD,
IA_OASIS_CLM_SPEC_D.CLM_ADMIT_TYP_CD,
IA_OASIS_CLM_SPEC_D.CLM_BIL_PROV_PREF_STS_CD,
IA_OASIS_CLM_SPEC_D.CLM_BIL_PROV_PRTCP_STS_CD,
IA_OASIS_CLM_SPEC_D.CLM_ATTND_PROV_PRTCP_STS_CD,
IA_OASIS_CLM_SPEC_D.CLM_BIL_PROV_PLN_STS_CD,
IA_OASIS_CLM_SPEC_D.CLM_NDC,
IA_OASIS_CLM_SPEC_D.CLM_BRND_GNRC_CD,
IA_OASIS_CLM_SPEC_D.CLM_ACSS_PLS_OOP_IND,
IA_OASIS_CLM_SPEC_D.CLM_BNF_COV_CD,
IA_OASIS_CLM_SPEC_D.CLM_TYP_OF_BIL_CD,
IA_OASIS_CLM_SPEC_D.CLM_OOA_CD,
IA_OASIS_CLM_SPEC_D.CLM_SANCT_LAT_CALL_IND,
IA_OASIS_CLM_SPEC_D.CLM_SANCT_DED_PNLTY_IND,
IA_OASIS_CLM_SPEC_D.CLM_SANCT_COPAY_IND,
IA_OASIS_CLM_SPEC_D.CLM_SANCT_PCT_COPAY_IND,
IA_OASIS_CLM_SPEC_D.CLM_SANCT_FLAT_DLR_COPAY_IND,
IA_OASIS_CLM_SPEC_D.CLM_SANCT_HMO_ACCUM_COPAY_IND,
IA_OASIS_CLM_SPEC_D.CLM_BIL_ALLOW_APPL_CD,
IA_OASIS_CLM_SPEC_D.CLM_TMLY_FIL_APPL_CD,
IA_OASIS_CLM_SPEC_D.CLM_TPLNT_APPL_CD,
IA_OASIS_CLM_SPEC_D.CLM_ADJ_CD,
IA_OASIS_CLM_SPEC_D.GRP_PRVDR_TIER_CD,
IA_OASIS_CAPITN_CLM_D.CAPITN_CLM_SS_CD_CD,
IA_OASIS_CAPITN_CLM_D.CAPITN_CLM_HMO_COV_LVL_CD,
IA_OASIS_CAPITN_CLM_D.CAPITN_CLM_FUND_POOL_CD,
IA_OASIS_CAPITN_CLM_D.CAPITN_CLM_HMO_PRDCT_CD,
IA_OASIS_CAPITN_CLM_D.CAPITN_CLM_BNF_CATEG_CD,
IA_OASIS_CAPITN_CLM_D.CAPITN_CLM_ADJ_TYP_CD,
IA_OASIS_CAPITN_CLM_D.CAPITN_CLM_IPA_ACSS_PLS_IND,
IA_OASIS_CAPITN_CLM_D.CAPITN_CLM_FUND_ID,
IA_OASIS_CAPITN_CLM_D.CAPITN_CLM_FUND_DESC,
CLM_CLS_PLN_CAPTR_D.CLM_CLS_PLN_GRP_ID,
CLM_CLS_PLN_CAPTR_D.CLM_CLS_PLN_CLS_ID,
CLM_CLS_PLN_CAPTR_D.CLM_CLS_PLN_CLS_DESC,
CLM_CLS_PLN_CAPTR_D.CLM_CLS_PLN_PLN_ID,
CLM_CLS_PLN_CAPTR_D.CLM_CLS_PLN_PLN_DESC,
CLM_CLS_PLN_CAPTR_D.CLM_CLS_PLN_PRDCT_CATEG_CD,
CLM_CLS_PLN_CAPTR_D.CLM_CLS_PLN_PRDCT_CATEG_DESC,
CLM_CLS_PLN_CAPTR_D.CLM_CLS_PLN_PRDCT_ID,
CLM_CLS_PLN_CAPTR_D.CLM_CLS_PLN_PRDCT_DESC,
CLM_CLS_PLN_CAPTR_D.CLM_CLS_PLN_MTL_LVL_CD,
CLM_CLS_PLN_CAPTR_D.HIOS_PLN_ID,
CLM_CLS_PLN_CAPTR_D.HIX_GRP_ID,
OASIS_CLM_MBR_XREF. LGCY_SBSCR_ID,
OASIS_CLM_MBR_XREF. LGCY_MBR_SFX_ID,
OASIS_CLM_MBR_XREF. FACETS_SBSCR_ID,
OASIS_CLM_MBR_XREF. FACETS_MBR_SFX_ID,
OASIS_CLM_MBR_XREF. LGCY_CUST_ID,
OASIS_CLM_MBR_XREF. LGCY_GRP_ID,
OASIS_CLM_MBR_XREF. LGCY_BIL_UNT_ID,
OASIS_CLM_MBR_XREF. FACETS_PRNT_GRP_ID,
OASIS_CLM_MBR_XREF. FACETS_GRP_ID,
OASIS_CLM_MBR_XREF. FACETS_CLS_ID,
OASIS_CLM_MBR_XREF. FACETS_CONVER_MBR_EFF_DT,
IA_OASIS_TOT_PROV_CUR_D.PROV_ID AS BEN_BILLING_PROV,
IA_OASIS_TOT_PROV_CUR_D.PROV_ID AS BEN_ATTENDING_PROV,
IA_OASIS_TOT_PROV_CUR_D.PROV_ID AS BEN_PCP_NUMBER,
IA_OASIS_TOT_PROV_CUR_D.PROV_ID AS BEN_IPA_NUMBER,
EDW. CLM_CAPITN_F.CLM_CAPITN_FRST_SVC_DT_SK,-CAL_DT Dimension is associated and had CAL_DT_SK column
EDW. CLM_CAPITN_F.CLM_CAPITN_LST_PRCS_DT_SK,-CAL_DT Dimension is associated and had CAL_DT_SK column
EDW. CLM_CAPITN_F.CLM_CAPITN_FRST_LOC_DT_SK,-CAL_DT Dimension is associated and had CAL_DT_SK column
EDW. CLM_CAPITN_F.CLM_CAPITN_CHK_DT_SK,-CAL_DT Dimension is associated and had CAL_DT_SK column
EDW. CLM_CAPITN_F.CLM_CAPITN_ADMIT_DT_SK,-CAL_DT Dimension is associated and had CAL_DT_SK column
EDW. CLM_CAPITN_F.CLM_CAPITN_ICN,
EDW. CLM_CAPITN_F.CLM_CAPITN_LN_NBR,
EDW. CLM_CAPITN_F.CLM_CAPITN_PD_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_BIL_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_ALLOW_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_ALLOW_DY_NBR,
EDW. CLM_CAPITN_F.CLM_CAPITN_UNT_OF_SVC_QTY,
EDW. CLM_CAPITN_F.CLM_CAPITN_COB_SAV_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_COINS_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_RSN_CHRG_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_WTHLD_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_DED_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_SANCT_LAT_CALL_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_SANCT_DED_PNLTY_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_SANCT_COPAY_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_SANCT_PCT_COPAY_AMT,
EDW. CLM_CAPITN_F.SANCT_FLAT_DLR_COPAY_AMT,
EDW. CLM_CAPITN_F.SANCT_HMO_ACCUM_COPAY_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_TOT_NEGOT_RT_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_LN_NEGOT_RT_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_SEC_ALLOW_AMT,
EDW. CLM_CAPITN_F.CLM_CAPITN_GATWY_ID,
EDW. CLM_CAPITN_F.CLM_CAPITN_PROV_AGR_ID,
EDW. CLM_CAPITN_F.CLM_CAPITN_F_SNPSHOT_MO_SK
OF EDW. Partition CLM_CAPITN_F (JAN2012),
EDW. IA_OASIS_GRP_CAPTR_D IA_OASIS_GRP_CAPTR_D,
EDW. IA_OASIS_MBR_CAPTR_D IA_OASIS_MBR_CAPTR_D,
EDW. IA_OASIS_CLM_SPEC_D IA_OASIS_CLM_SPEC_D,
EDW. IA_OASIS_CAPITN_CLM_D IA_OASIS_CAPITN_CLM_D,
EDW. CLM_CLS_PLN_CAPTR_D CLM_CLS_PLN_CAPTR_D,
EDW. OASIS_CLM_MBR_XREF OASIS_CLM_MBR_XREF,
EDW. IA_OASIS_TOT_PROV_CUR_D IA_OASIS_TOT_PROV_CUR_D
WHERE
EDW. CLM_CAPITN_F.CLM_CAPITN_IA_GRP_CAPTR_EDW_SK = IA_OASIS_GRP_CAPTR_D.GRP_CAPTR_EDW_SK (+) and
EDW. CLM_CAPITN_F.CLM_CAPITN_IA_MBR_CAPTR_EDW_SK = IA_OASIS_MBR_CAPTR_D.MBR_CAPTR_EDW_SK and
EDW. CLM_CAPITN_F.CLM_CAPITN_IA_CLM_SPEC_EDW_SK = IA_OASIS_CLM_SPEC_D.CLM_SPEC_EDW_SK and
EDW. CLM_CAPITN_F.CLM_CAPITN_IA_CLM_EDW_SK = IA_OASIS_CAPITN_CLM_D.CLM_EDW_SK and
EDW. CLM_CAPITN_F.CLM_CLS_PLN_CAPTR_EDW_SK = CLM_CLS_PLN_CAPTR_D.CLM_CLS_PLN_CAPTR_EDW_SK and
EDW. CLM_CAPITN_F.MBR_XREF_SK = OASIS_CLM_MBR_XREF. MBR_XREF_SK (+) and
EDW. CLM_CAPITN_F.CLM_CAPITN_IA_BIL_PROV_EDW_SK = IA_OASIS_TOT_PROV_CUR_D.PROV_EDW_SK and
EDW. CLM_CAPITN_F.CLM_CAPITN_ATTND_PROV_EDW_SK = IA_OASIS_TOT_PROV_CUR_D.PROV_EDW_SK and
EDW. CLM_CAPITN_F.CLM_CAPITN_IA_PCP_EDW_SK = IA_OASIS_TOT_PROV_CUR_D.PROV_EDW_SK and
EDW. CLM_CAPITN_F.CLM_CAPITN_IA_IPA_PROV_EDW_SK = IA_OASIS_TOT_PROV_CUR_D.PROV_EDW_SK (+);
--------------------------------------------------------------------------------
Oracle Database 11 g Enterprise Edition Release 11.2.0.4.0 - 64 bit Production
PL/SQL Release 11.2.0.4.0 - Production
CORE Production 11.2.0.4.0
AMT for Solaris: 11.2.0.4.0 - Production Version
NLSRTL Version 11.2.0.4.0 - Production
VALUE OF TYPE NAME
------------------------------------ ----------- ------------------------------
OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES boolean FALSE
optimizer_dynamic_sampling integer 2
optimizer_features_enable string 11.2.0.4
optimizer_index_caching integer 0
OPTIMIZER_INDEX_COST_ADJ integer 100
the string ALL_ROWS optimizer_mode
optimizer_secure_view_merging Boolean TRUE
optimizer_use_invisible_indexes boolean FALSE
optimizer_use_pending_statistics boolean FALSE
optimizer_use_sql_plan_baselines Boolean TRUE
Please suggest how this can be optimized.
VALUE OF TYPE NAME
------------------------------------ ----------- ------------------------------
db_file_multiblock_read_count integer 32
VALUE OF TYPE NAME
------------------------------------ ----------- ------------------------------
DB_BLOCK_SIZE integer 32768
CURSOR_SHARING EXACT string
-
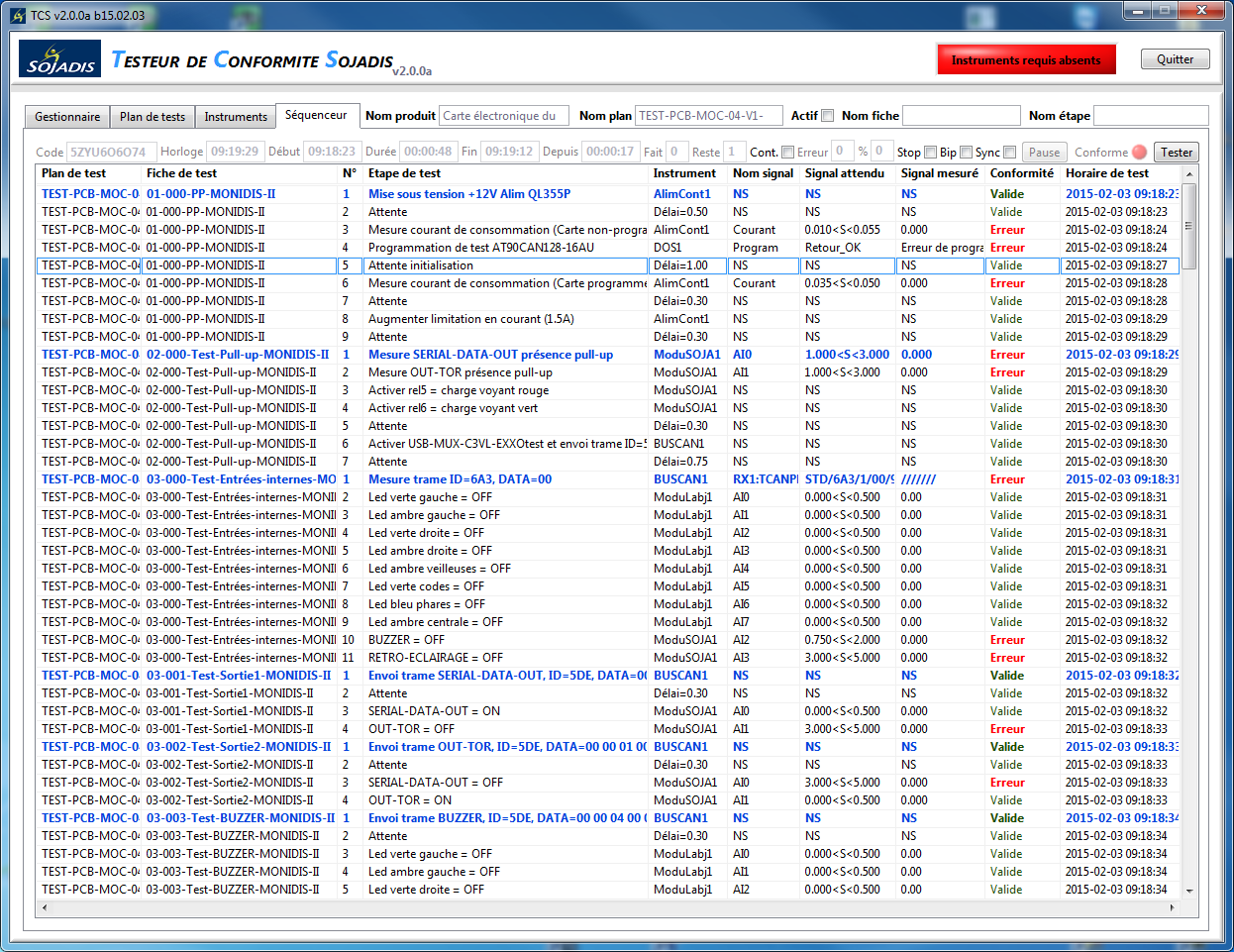
Impressive transformation slow due to the updating of the user interface
Hello
I feel a huge slow down in my test as engine
I update the display after each test. It consists of a rather
"simple table" with a subtle change of color and bold
to indicate the failure or success of the test:
I have also tried several things to determine what routine was
make the program almost crawling like a snail, here's my
results:
No UI refresh: 0m48s (same as Teststand with no updates of the user interface)
The discount but no page table switch: 1m06s
Bay of refreshment and switch page: 1m26s
There are 314 tests, up to 314 redraw and possibly
switch page 314 to reposition the view. Which gives the
following user interface refresh costs:
Update of the table: 18 years/314 = 57ms (replacing just a single line, Center to top)
Switch to page: 20 s/314 = 64ms (bottom right corner)
Is this really the case? Is there a way to make the refresh of the user interface
faster? Create two separate loops/threads, one to make
the test, one for updating the UI asynchronously?
I understood for an overall picture about different
widgets, but here I'm 'just' display of channels...
David Koch
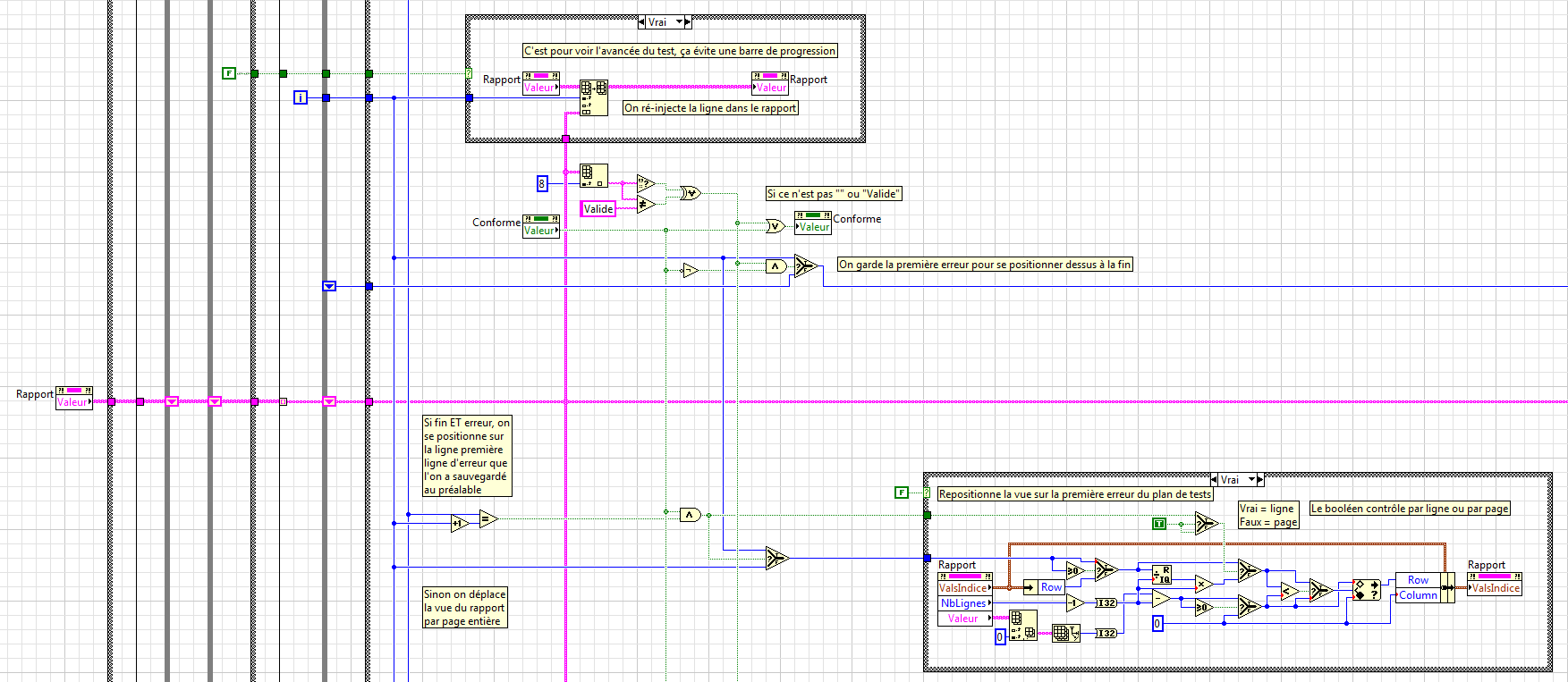
Well, multi-listbox control is a problem if your change causes access to the muliple property node. For each property node LabVIEW normally does a refresh of the user interface which is very quickly. Fortunately, there is a fairly easy way to fix this.
Use a node of property for the current VI (just drop a property node and change its class type VI Server-> VI reference) to get the reference of the Panel. Then use another property node connected to your reference of the Panel and select update from the Panel to postpone. Set this value to true before your Listbox (and any other updated user interface) and set the value to false then.
-
Hi guys,.
The below SQL is to do a full table scan.
SELECT AA, STATUS, CC, DD, FF, FF, GG, INCIDENT_ID
OF THE TEST
WHEN STATUS = 'F'
AND INCIDENT_ID = '15434';
1. After you have created an index on two columns STATUS and INCIDENT_ID, he did a scan of interval.
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
---------------------------------------------------2 - access ("STATUS" = 'F' AND "INCIDENT_ID" = '15434')
2. I have delete the index and create again but this time on a single column INCIDENT_ID. It has the same behavior as the foregoing, do a scan of interval.
PLAN_TABLE_OUTPUT
-------------------------------------------
-------------------------------------------1 - filter ("DELETE_IND" = 'F')
2 - access ("PAYMENT_DET_ID" = '15434')The only different is the predicate as above.
Plan with the same cost, explain.
Therefore, can I create indexes only for incident_id? instead for 2 columns? What is actually recommended?
SELECT AA, STATUS, CC, DD, FF, FF, GG, INCIDENT_ID
OF THE TEST
WHEN STATUS = 'F'
AND INCIDENT_ID = '15434';
Thank you
Hello
(1) there seems to be an inconsistency in your message: you use STATUS/INCIDENT_ID in one case and DELETE_IND/PAYMENT_DET_ID in the other, it's confusing
(2) the difference between a single column and several (concatenated) column index here is quite simple. A multi-column index will match your completely predicate, that is, lines that meet the two conditions will return the INDEX RANGE SCAN. A single-column index will only select lines according to the requirement on the indexed column. So the question is, is quite good selectivity?
Let me give you an example: imagine that you have a table that describes the entire population of our planet, and you consider indexing columns COUNTRY_OF_ORIGIN and NATIVE_LANGUAGE. In this case, it is obvious that NATIVE_LANGUAGE does not provide any significant additional selectivity (as in most countries, there are only few languages), so a single-column index would suffice. If you consider a different pair of columns, for example COUNTRY_OF_ORIGIN and AGE, then combined selectivity is much stronger that the selectivity of each column only, so a concatenated index would be useful.
So all down to selectivity, namely, how to combine selectivity refers to the selectivity of single column.
Best regards
Nikolai
-
Apex 4.2: really simple SQL date of issue
Hello
Anyone can get this SQL query with the correct date for Apex syntax?
Select * from table
where datecolumn > ' 2010-03-31'
I tried with #2010-03-31 #; I tried the dd-mm-yyyy; I tried the backslashes; I tried to use a date() function; and I tried cast() and I'm stumped.
As far as I remember, I put the global date format in dd-mm-yyyy.
The column that I need to analyze will finally be a timestamp with time zone column (for a plugin works).
However at this point, I can't do a simple working either date column, so it's just a problem of syntax newbie.
Help appreciated!
Thank you
EmmaHi Emma,
because you use a literal string, you must specify the format;select * from table where datecolumn >to_date( '2010-03-31', 'YYYY-MM-DD')Kofi
-
Updates simple SQL with the key issue of research
Hi, I have two tables TA and TB, where TA contains the fields IDS, FULLNAME, TYPE and tuberculosis contains the fields ID, MIDDLENAME
I want to update the names in TB for first names only according to TA where TB.ID = TA.ID and TA. TYPE = 'ABC '.
I wrote this
setting a day of TB B MIDDLENAME set =
(
Select substr (FULLNAME, instr (FULLNAME, ' ') + 1, instr (FULLNAME, ' ', 1) - length (FIRSTNAME) - 2) of
(
SELECT ID, FULLNAME, substr (FULLNAME, 1, instr (FULLNAME, ' ')-1) first NAME
Ta
where TYPE = 'ABC '.
) AT
where A.ID = B.ID
)
I want to know if there may be no optimization because this SQL is super slow at the moment.
Server Oracle 11 g is
Thank you!Maybe (easier to write, you can use the fusion too)
update (select b.middlename existing_middle, substr(a.fullname, instr(a.fullname,' ',1,1) + 1, instr(a.fullname,' ',-1,1) - instr(a.fullname,' ',1,1) - 1 ) extracted_middle from tb b, ta a where a.id = b.id and a.type = 'ABC' ) set existing_middle = extracted_middleHave no where clause after update, you update all lines
update TB B set MIDDLENAME = (select substr(FULLNAME,instr(FULLNAME,' ') + 1,instr(FULLNAME,' ', -1) - length(FIRSTNAME) - 2) from (select ID,FULLNAME,substr(FULLNAME,1,instr(FULLNAME, ' ') - 1) FIRSTNAME from TA where TYPE = 'ABC' ) A where A.ID = B.ID )Concerning
Etbin
Edited by: Etbin on 28.7.2012 10:13
merge into tb b using (select id, substr(fullname, instr(fullname,' ',1,1) + 1, instr(fullname,' ',-1,1) - instr(fullname,' ',1,1) - 1 ) extracted_middle from ta where type = 'ABC' ) a on a.id = b.id when matched then update set b.middlename = a.extracted_middle -
We wanted to capture the changes with goldengate and run it on the other side as a regular script.
for this we need extract goldendate to save the changes made as plain sql...
Can you help me get started?Steven is right. You use the FORMATSQL parameter in your snippet. And your statement will look like this:
ESQL SAMPLE
USERID *, PASSWORD *.
FORMATSQL ORACLE
RMTHOST 0.0.0.0, MGRPORT 7809
RMTFILE. / dirdat/esql.dat, PURGE
TABLE my_table;But do not forget that FORMATSQL should come before RMTFILE.
-
SQL query simple SQL Developer takes, the wizzard of XE does not work
Hello everyone
I wrote this simple query that developer SQL works well, but when I try to run a report based on this sql query, it tells me invalid sql statement. It's true, maybe it's not valid because this IF clause in there... but Developer SQL seems to be very tolerant or includes more...
I wrote this is because obviously if there is no Boss, ie = 0 then I would get an error when it division by 0, so I put that 0 just for selecting the right
If count (bosses) > 0
Select company, zip code.
sum (Boss/staff)
assessment
Group of company, zip code
Thank you very much
AlvaroOk. This should work:
Select company, zip code.
-case when count (staff)! = 0 here end sum (Boss/staff)
assessment
Group of company, zip codeIf this does not work, could you please explain, how your table looks like?
-
Difficult requirement with this simple SQL query
OK, here's the deal: Let's say I have the following data
The first line you see (from the year 1900 to 3000) represents the default line of an employee (emp_id). The condition is that:with test_data as ( select 1 as emp_id, to_date('01/01/1900','dd/mm/yyyy') as start_date, to_date('01/01/3000','dd/mm/yyyy') as end_date from dual union select 1 as emp_id, to_date('20/01/2008','dd/mm/yyyy') as start_date, to_date('22/01/2008','dd/mm/yyyy') as end_date from dual union select 1 as emp_id, to_date('23/01/2008','dd/mm/yyyy') as start_date, to_date('26/01/2008','dd/mm/yyyy') as end_date from dual union select 2 as emp_id, to_date('23/01/2008','dd/mm/yyyy') as start_date, to_date('26/01/2008','dd/mm/yyyy') as end_date from dual union select 2 as emp_id, to_date('01/01/1900','dd/mm/yyyy') as start_date, to_date('01/01/3000','dd/mm/yyyy') as end_date from dual union select 3 as emp_id, to_date('01/01/1900','dd/mm/yyyy') as start_date, to_date('01/01/3000','dd/mm/yyyy') as end_date from dual ) select * from test_data EMP_ID START_DATE END_DATE ---------- ---------- ---------- 1 01-01-1900 01-01-3000 1 20-01-2008 22-01-2008 1 23-01-2008 26-01-2008 2 01-01-1900 01-01-3000 2 23-01-2008 26-01-2008 3 01-01-1900 01-01-3000
When a date is provided, if there is only a default value for an employee (and), select the default value.
If a default value exists (from the year 1900 to 3000) AND several lines exist for an emp_id, then throw the default date range and select the line when the supplied date is between. There won't be any overlap with date ranges that are not default (1900 to 3000).
So, if I select the date to_date ('2008-01-24', ' dd/mm/yyyy'), the query must return:
It is because even if a default value exists for emp_id 1 and 2, the shorter date range prevails. Emp_id 3 had only the default and no lines, by default (from 1900 to 3000) should be extracted.EMP_ID START_DATE END_DATE ---------- ---------- ---------- 1 23-01-2008 26-01-2008 2 23-01-2008 26-01-2008 3 01-01-1900 01-01-3000
I tried the functions analytical for this, but only got on this point:
No idea how to filter then, if I provide, say, to_date ('2008-01-24', ' dd/mm/yyyy')with test_data as ( select 1 as emp_id, to_date('01/01/1900','dd/mm/yyyy') as start_date, to_date('01/01/3000','dd/mm/yyyy') as end_date from dual union select 1 as emp_id, to_date('20/01/2008','dd/mm/yyyy') as start_date, to_date('22/01/2008','dd/mm/yyyy') as end_date from dual union select 1 as emp_id, to_date('23/01/2008','dd/mm/yyyy') as start_date, to_date('26/01/2008','dd/mm/yyyy') as end_date from dual union select 2 as emp_id, to_date('23/01/2008','dd/mm/yyyy') as start_date, to_date('26/01/2008','dd/mm/yyyy') as end_date from dual union select 2 as emp_id, to_date('01/01/1900','dd/mm/yyyy') as start_date, to_date('01/01/3000','dd/mm/yyyy') as end_date from dual union select 3 as emp_id, to_date('01/01/1900','dd/mm/yyyy') as start_date, to_date('01/01/3000','dd/mm/yyyy') as end_date from dual ) select * from ( select emp_id, start_date, end_date, row_number() over (partition by emp_id order by start_date) ct from test_data ); EMP_ID START_DATE END_DATE CT ---------- ---------- ---------- ---------- 1 01-01-1900 01-01-3000 1 1 20-01-2008 22-01-2008 2 1 23-01-2008 26-01-2008 3 2 01-01-1900 01-01-3000 1 2 23-01-2008 26-01-2008 2 3 01-01-1900 01-01-3000 1
any ideas?Please provide sample data!
I know most simple is to apply your deadline for the original dataset this should return no more than two records by emp_id. Then add a column row_number for the limited returned data partitioned by emp_id and ordered on the difference between the dates of beginning and end that should be the default value of the record second when there is more than one record for a given emp_id. The last step is to select only the records of this intermediate step that have a row_number 1:
with test_data as ( select 1 as emp_id, to_date('01/01/1900','dd/mm/yyyy') as start_date, to_date('01/01/3000','dd/mm/yyyy') as end_date from dual union select 1 as emp_id, to_date('20/01/2008','dd/mm/yyyy') as start_date, to_date('22/01/2008','dd/mm/yyyy') as end_date from dual union select 1 as emp_id, to_date('23/01/2008','dd/mm/yyyy') as start_date, to_date('26/01/2008','dd/mm/yyyy') as end_date from dual union select 2 as emp_id, to_date('23/01/2008','dd/mm/yyyy') as start_date, to_date('26/01/2008','dd/mm/yyyy') as end_date from dual union select 2 as emp_id, to_date('01/01/1900','dd/mm/yyyy') as start_date, to_date('01/01/3000','dd/mm/yyyy') as end_date from dual union select 3 as emp_id, to_date('01/01/1900','dd/mm/yyyy') as start_date, to_date('01/01/3000','dd/mm/yyyy') as end_date from dual ) , t1 as ( select td.*, row_number() over (partition by emp_id order by end_date-start_date) ord from test_data td where to_date('24/01/2008','dd/mm/yyyy') between start_date and end_date ) select emp_id, start_date, end_date from t1 where ord=1; -
Need help troubleshooting transformation slow speed on my new iMac
New iMac, purchased in August 2015, worked well until this week. Now, everything happens very slowly. Color wheel, slow, typing speed, applications crashing, etc.
It's an iMac with 1.4 GHZ Intel Core i5 and 8 GB of memory. From this moment, I have 433.16 free BG to 498.93.
I just upgraded to 10.11.1, but the speed slowed down before the upgrade.
I have a suspicion of naivety that recent web video game adventures of my son may have something to do with the slow down. He's young, and he may have clicked on somehing involuntarily. Is there a way to eliminate unintentional downloads? Other suggestions?
Thank you!
It is likely that you are right, but you can download Entrecheck http://www.etresoft.com/etrecheck to make sure.
Post your results in this thread.
-
Reference Dell r710 12core 32 GB super slow with sql and need help exch2010
Hi all and thanks in advance.
I have a new r710 which has a great for a few months then it has slowly degraded until now, it's an analysis on all the vm, I can't tell which one is it slows down because all the performance counters show a lot of place in all categories. I've been doing the reconnection to the datastore2 and datastore1, then I get a restored connection. I moved the Exchange 2010 vm to the datastore3 that does not have errors, but it is still slow. I wonder if I should move all the vm off the other two data stores and delete, and rescan the esxi for storage and back as data 1 and 2 stores. I have esxi 4.0 not improved update2. and there an esxi license and there 6 installation of drives western digital black 1 TB in raid1 3 - then I have every configuration of raid as a logical drive which is then turned into a data store.
I don't know if the downturn is the hardware or a virtual machine is pulling them down - I'll start out them one by one to test tonight, but the advice or opinions are welcome.
I don't know what your storage looks like initially but I would recommend HAVE TO go with update 2 - we had all sorts of problems with particular storage when you use storage VSA as the left hand. Update 2 provided some great improvements to the vmkernel regarding VMFS.
You can also publish newspapers vmkernel of any of the host in question and we can take a loo at it.
Seriously, update your esx/esxi servers is always a good practice when you have weird problems.
See you soon,.
Chad King
VCP-410. Server +.
Twitter: http://twitter.com/cwjking
If you find this or any other answer useful please consider awarding points marking the answer correct or useful
-
Essentially, here's my script
With the code above, what I wanted to do is to get the storeid field, prodid (product which hasa sale minimum in stores) and the total sales of product by prodid--Get the storeid, prodid, sales, and summation of sales per product ID accross all stores SELECT storeid, prodid, sales, SUM(sales) OVER (PARTITION BY prodid ORDER BY sales DESC) FROM salestbl; storeid prodid sales Group Sum(sales) ----------- ------ ----------- ---------------- 1001 A 100000.00 170000.00 1002 A 40000.00 170000.00 1003 A 30000.00 170000.00 1003 B 65000.00 65000.00 1001 C 60000.00 115000.00 1002 C 35000.00 115000.00 1003 C 20000.00 115000.00 1003 D 50000.00 110000.00 1001 D 35000.00 110000.00 1002 D 25000.00 110000.00 1001 F 150000.00 150000.00
Now, I came up with this to do.
My question would be, if you have the same scenario:select tblA.storeid, tblA.prodid, tblA.sales, tblA.sales_sum_per_prod from (SELECT storeid, prodid, sales, SUM(sales) OVER (PARTITION BY prodid) as sales_sum_per_prod FROM salestbl) as tblA, (SELECT prodid, min(sales) as min_sales FROM salestbl group by prodid) as tblB where tblA.prodid=tblB.prodid and tblA.sales=tblB.min_sales; storeid prodid sales sales_sum_per_prod ----------- ------ ----------- ------------------ 1003 A 30000.00 170000.00 1003 B 65000.00 65000.00 1001 F 150000.00 150000.00 1002 D 25000.00 110000.00 1003 C 20000.00 115000.00
How would you write the SQL?
Is there an approach much more in terms of simplicity or performance?
I want to try your solution and ideas so that I can test here and finally compare the plan of the explain command.
I'm looking forward to an another or even better approach to solve my problem.
Thanks in advance ^_^Hello
Here's one way:
WITH got_analytics AS ( SELECT storeid, prodid, sales , SUM (sales) OVER ( PARTITION BY prodid ) AS group_sum_sales , ROW_NUMBER () OVER ( PARTITION BY prodid ORDER BY sales ) AS r_num FROM salestbl ) SELECT storeid, prodid, sales, group_sum_sales FROM got_analytics WHERE r_num = 1 ;If you would care to post CREATE TABLE and INSERT instructions for the sample data, and then I could test it.
Published by: Frank Kulash, 28 February 2012 06:49
Changed "SELECT SELECT" "Select".
Maybe you are looking for
-
Hey everybody, When running beta, I noticed this and it is still a question on the full release that my storage is hooked to the calculation. any fixed or alternative work
-
Title bar turns gray and does not, has something to do with Adblock more.
at the opening of the homepage, the title bar at the top of page grey towers and the page doesn't meet. like ad block is causing problems. Can someone help me with this?. Thank you.
-
I can not install firefox and get a message do not have the permissions etc.
It is said that some features may not work if I download as long as the current user and it offers me the opportunity to do as another user. I am the administrator and nothing seems to get past this screen
-
My Scanner does not work! Error: Make sure that the feature is open
I have a copier, printer, fax, scanner printer HP all-in-one. Everything works but the scanner. The message says "make sure the feature is open. Open HP printing software. Shares of select the scanner. Then select manage the Scan to computer. How
-
Original title : My system keeps thinking there is a update it needs to close and restart to. No way to get rid of this problem? I'm trying to upgrade a program on my computer, it I get a message that an another update has been installed and to resta