use of variables?
Hi allI'm new to obiee. Can someone help out me on the use of variables in obiee (DPR).
Whats the difference between the repository and session variables. And also initialization blocks, static variables, dynamic variables? Help, please
Hi Sai chand,
variable easily value and we can do it everywhere where we need to use...
variables to repository contains the value according to the given query block initialization.
As soon Server BI starts these variables affected with values and depends on the refreshment of time we mentioned for these variables, each time mentioned, beer server run the query and assign values to the varaibels...
Life for these variables is: as long as BI Server stops...
Session variables are variable pre-defined as user, group, loglevel... etc.
They are related to security.
persistence for these variables time are as long as the session closed.
If you give me your email ID, I will send you I about document variables.
Tags: Business Intelligence
Similar Questions
-
Using global variables in a device custom
Hello world
I have problems with the passing of data through my device customized using global variables. I want to allow a user to select a RIO device address when you set up the system definition file. This is recorded in a global variable using the hand Page VI. I would later use this RIO device address in RT driver to deploy a bitfile. I can hard-code, but it is much more convenient to use a global.
When I try to store the address of the global variable, it updates the value temporarily (I confirmed that the structure of the event recognizes the change of value). When I click the node of the tree to define system linked to the Main Page VI and then click on it again, the hand Page VI runs again. I wrote the code to repopulate the address of device of RIO with the last value stored in the global variable, but it is empty. I've included the VI global variables in my build, so I can't imagine why it can reset this value.
Any help would be appreciated!
Thank you
Mitch
Have you tried to use the custom device properties to store this value instead of GVs?
Configuration VI, you can set this property, and if I'm not mistaken, you can read these properties on the RT driver.
-
WARNING: Incompatible Arg. You can't use stack Variables If generating series is not defined
What does this message mean?
"WARNING: incompatible Arg. you can't use stack Variables If generating series is undefined."
Where can I put generate series only?
Thank you
Derek
Hi Derek,.
Not all LabVIEW C Generator settings are compatible with each other. In this case, you must define generate series only (aka 'disable parallel execution') If you want to generate the code uses the variable stack.
-
Use the variable based on Chncalculate to tiara
I need to use a variable in the ChnCalculate function but only takes the text then how to incorporate the varaible in text inside this function. It keeps on undefined variable beep where, as I have already defined at the beginning of the program and also value.
Hi coolguru,
The syntax error is in your first line, it should be instead:
GlobaDim "a".
Brad Turpin
Support Engineer product DIAdme
National Instruments -
Use of Variables shared with RT-project / home-VI
Hi all
I have a small question which is certainly easy to answer for those who have already worked with a RT - VI containing two periods loops and a user interface that is deployed on a host PC.
Q: is there an advantage to the data acquisition in the urgent loop by using a variable shared unique process (active FIFO) and then through the data on the host computer the nondeterministic loop simply through a shared network-published (new FIFO active) variable that directly passes the data on the host PC?
Thanks in advance,
David
Hi Kolibri,
The advantage of having the network publishes the variables in your non-deterministic loop as opposed to the evanescent loop is that it reduces the resources needed to perform the evanescent loop.
Send the data to a different loop in the same program with unique shared variable or process with RT FIFOs requires fewer resources than to send data over the network. This allows the loop of high priority execute more deterministic way, without having to manage communication networks.
Kind regards
Stephen S.
-
Can I use a variable in step of TS Message for field 'waiting time '?
Is it possible to use a variable (inhabitants, parameters, etc.) for the field "Wait time" in the stage of message TestStand?
TestStand 4.1
Thank you
Rafi
Go to the step settings > properties > Expressions > Expression Pre and enter something like:
Step.TimeToWait = Locals.MyTimeToWait
-
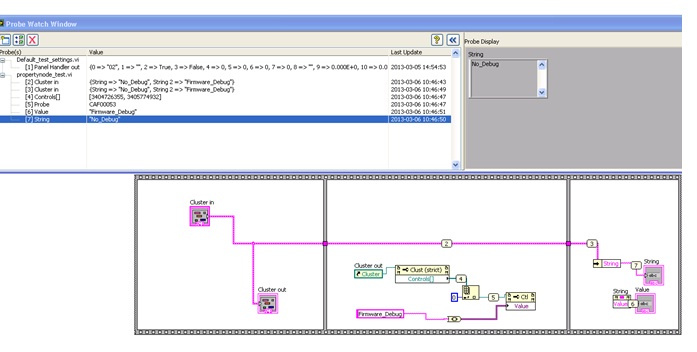
new to labview :-) and I have a problem when I want to change the value of a string in bunches, and I want to implement this using the node value of property instead of writing directly to the stream or by using the variable, enclosed is the picture. No matter, I have change in cluster (control) or value of Popery out (indicator) cluster, the value (sensor 7) dataflow keeps unchanged even I gave the new value by value of property node. Thank you to give me some advice about this.
Hi GerdW
Thanks a lot for your answer. The reason I'm stubbornly tring to break the flow of DATA is: we have a test system that have about 100 screws, they have a few connected flow, some of them will be unbundling a cluster dataflow chain to check the value in order to make the different cases. Now I want to insert user event by changing the control and influential cases during run time.
As I initially uses a global variable (to control cases) instead of unbundle string data flow, it works well. But then, I found there are a lot of screws that are using the string unbundle. One of the 'lazy' means, I tried is to change the value via the property node (because that way, I did not need to find all the places where using the unbundle string and replace them with the global variable), then I noticed a problem with "dataflow", the value in the stream of cluster in fact will not be changed by changing the value of the property node.
I did a test with VI simple (like the picture in last post), and after reading your advice, I tell myself that I need to understand the concept of "DATAFLOW" in labview, it seems that my "lazy" way can not work in this scenario.
I have attached the criterion VI here, have you furthur suggestions on what I can do in this case?
Mant thanks!
Minyi
-
Why LabVIEW example projects using Global Variables?
I'm puzzled. I've been pretty good programmers LabVIEW talks (including some who work for the OR) and came away with the impression that Global Variables should, as a general rule, be avoided, with functional Global Variables (alias VI Globals) generally preferred for "local memory".
I have studied some of the example distributed with LabVIEW, 2012 and 2013, in particular the proposed acquisition in real time and am struck by the use of Global Variables, where I'd be inclined to use instead a FGV. For examples, to stop all the loops on the RT target, the overall "All the RT loop Stop" is defined; 'Constants' of configuration (such as timeouts, Streme network names, the names of the journal folder) are kept as Globals; Streme network endpoints are stored in Globals.
[Note - there is a weird spelling of the second word of the network Streme, above - when I tried to post with the correct spelling, I got an error message saying this word is 'not allowed in this community".] I apologize for the offense, but I must confess that I do not understand what the problem with the help of the spelling of this word...]
Why use Globals in these cases, rather than write a bunch of VIGs to hold these data? Note that almost all these Globals are 'Read' essentially (written once when a resource is acquired, for example) or "Read Only" (treated as if they were a constant). Indeed, read-only variables can be written as a Subvi with only an output terminal, acting as a (visible, due to the icon) constant.
I can see advantages to this approach. On the one hand, VIGs can have error bounds who run the data flow (I just spotted a bug "data flow" in code, I am developing that is based on this model, to read configuration data to an XML file in a world and in the same VI, Global wiring to a "use - me" terminal, but with no guarantee that I'll read the overall after I write it).
It is, I suppose, a matter of 'speed' - perhaps Global Variables are 'faster' than VIGs (especially if the VIG 'sits' on an error line). My thought, however, is that this difference is likely to be trivial, especially as these VIGs (or Globals) tend to become "occasional" calls (with the exception of the indicator 'all the loop Stop' which is called once per line).
Are there other arguments or considerations that make a Variable global to a better choice than a VIG? Is there a reason that LabVIEW developers put in these start-up of projects LabVIEW?
BS
I have to ask, how do you use functional Global Variables? Like just a Get and Set? If so, you can use a global variable.
Yes, globals are faster and use much less overhead. At the summits of CLA in recent years, we talked about using globals. The most common use is for Write-Once-Read Many and writing-never-Read Many with configuration data. It's a good idea to use globals with the constants that can change on you. It turns out that the world will have the same performance as a constant in this case. This is done so that you don't have 1 place to edit the 'constant '.
The rule on "Globals are evil" actually goes back several years when NEITHER had the huge "people of the country are bad" vendata. But NEITHER explains well how to do things properly. So I found people, instead of using local variables, using the value property node. It's even worse because the property causes thread swaps and kills your performance. It wasn't until I shouted to people to use wires and shift registers I have seen improvements in the way in which people wrote their code. So people are always riffling in the use of globals and decided to use FGVs with the EEG and fixed rather cases. But this does not solve the problem of the conditions of race with critical data and you cause an additional burden.
So from my experience, I use globals all the time for configuration data. Yes, you must be careful about the race conditions. But as long as you understand that it is a common and useful practice.
I would not use a global variable for data that are constantly changing (use registers to offset or Action motor) and/or processes that have critical sections of code (use a motor of Action).
NOTE: I use the definition of Mercer to FGV (a Get/Set only) and motor Action (many cases which specifically affect the data).
-
IAM having the following query to load the data of my DataModel
DataSource { id: firstSource source: "db/duDatabase.db" query: "SELECT title FROM how_to ORDER BY howToId ASC limit 10" onDataLoaded: { firstModel.insertList(data); } }My Question is:
How can I use a variable to set the limit in the query
That is to say, I want something like that
query: "SELECT title FROM how_to ORDER BY howToId ASC limit variableName"
Please please help me. IAM stuck here.
query: "SELECT title OF how_to ORDER BY howToId limit of ASC"+ NomDeLaVariable"
-
Estimate of poor cardinality using Bind Variables
Hi I'm using the 11.2.0.4.0 Oracle version. I have a query that is underway for the plan of the poor execution by the estimate of poor cardinality for two tables (I've extracted and published this part only) as I mentioned below, the individual conditions for which the estimate goes bad and moving entire query execution path.
These are for two tables and currently we use BIND variable for them in our code, and I notice, its best estimate gives with literals. I need to know how to handle this scenario that I need this query to execute for all types of volumes. Is there something I can do without changing the code, as it works well for most of the execution? In the current scenario of the main query that uses those below tables providing a plan (index + nested loop) that works very well for small volume, but running for 10 hr + for large volume as ideally its going to the same regime.
And Yes, most time that this request will be hit for small volume, but killing some appearance of large volume presents the performance of the queries.
Here are the values of the variable binding.B1 VARIABLE VARCHAR2 (32);
B2 VARIABLE VARCHAR2 (32);
B3 VARIABLE NUMBER;
B4 VARIABLE VARCHAR2 (32);
B7 VARIABLE VARCHAR2 (32);
B5 VARIABLE NUMBER;
B6 VARIABLE NUMBER;EXEC: B1: = 'NONE ';
EXEC: B2: = NULL;
EXEC: B3: = 0;
EXEC: B4: = NULL;
EXEC: B7: = NULL;
EXEC: B5: = 0;
EXEC: B6: = 0;---- For TABLE1------- -- Published Actual VS Etimated cardinality -- With bind values select * from TABLE1 SF WHERE ( (SF.C1_IDCODE = :B4) OR (NVL (:B4, 'NONE') = 'NONE')) AND ( (SF.C2_ID = :B3) OR (NVL (:B3, 0) = 0)); Plan hash value: 2590266031 ----------------------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem | ----------------------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 28835 |00:00:00.08 | 2748 | 46 | | | | |* 1 | TABLE ACCESS STORAGE FULL| TABLE1 | 1 | 11 | 28835 |00:00:00.08 | 2748 | 46 | 1025K| 1025K| | ----------------------------------------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - storage((("SF"."C1_IDCODE"=:B4 OR NVL(:B4,'NONE')='NONE') AND ("SF"."C2_ID"=:B3 OR NVL(:B3,0)=0))) filter((("SF"."C1_IDCODE"=:B4 OR NVL(:B4,'NONE')='NONE') AND ("SF"."C2_ID"=:B3 OR NVL(:B3,0)=0))) -- With literals select * from TABLE1 SF WHERE ( (SF.C1_IDCODE = null) OR (NVL (null, 'NONE') = 'NONE')) AND ( (SF.C2_ID = 0) OR (NVL (0, 0) = 0)); Plan hash value: 2590266031 -------------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | -------------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 28835 |00:00:00.03 | 2748 | | | | | 1 | TABLE ACCESS STORAGE FULL| TABLE1 | 1 | 28835 | 28835 |00:00:00.03 | 2748 | 1025K| 1025K| | -------------------------------------------------------------------------------------------------------------------------------------- --------For TABLE2 ----------------------- -- Published Autotrace plan, as it was taking long time for completion, and actual cardinality is 45M, but its estimating 49 With bind value--- --withbind value select * from TABLE2 MTF WHERE ( (MTF.C6_CODE = TRIM (:B2)) OR (NVL (:B2, 'NONE') = 'NONE')) AND ( (MTF.C3_CODE = :B1) OR (NVL (:B1, 'NONE') = 'NONE')) AND ( (MTF.C4_CODE = :B7) OR (:B7 IS NULL)) AND ( (MTF.C5_AMT <= :B6) OR (NVL (:B6, 0) = 0)) AND ( (MTF.C5_AMT >= :B5) OR (NVL (:B5, 0) = 0)); Execution Plan ---------------------------------------------------------- Plan hash value: 1536592532 ----------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | ----------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 49 | 10437 | 358K (1)| 01:11:43 | | | | 1 | PARTITION RANGE ALL | | 49 | 10437 | 358K (1)| 01:11:43 | 1 | 2 | |* 2 | TABLE ACCESS STORAGE FULL| TABLE2 | 49 | 10437 | 358K (1)| 01:11:43 | 1 | 2 | ----------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - storage(("MTF"."C4_CODE"=:B7 OR :B7 IS NULL) AND ("MTF"."C3_CODE"=:B1 OR NVL(:B1,'NONE')='NONE') AND ("MTF"."C5_AMT"<=TO_NUMBER(:B6) OR NVL(:B6,0)=0) AND ("MTF"."C5_AMT">=TO_NUMBER(:B5) OR NVL(:B5,0)=0) AND ("MTF"."C6_CODE"=TRIM(:B2) OR NVL(:B2,'NONE')='NONE')) filter(("MTF"."C4_CODE"=:B7 OR :B7 IS NULL) AND ("MTF"."C3_CODE"=:B1 OR NVL(:B1,'NONE')='NONE') AND ("MTF"."C5_AMT"<=TO_NUMBER(:B6) OR NVL(:B6,0)=0) AND ("MTF"."C5_AMT">=TO_NUMBER(:B5) OR NVL(:B5,0)=0) AND ("MTF"."C6_CODE"=TRIM(:B2) OR NVL(:B2,'NONE')='NONE')) -- with literal select * from TABLE2 MTF WHERE ( (MTF.C6_CODE = TRIM (null)) OR (NVL (null, 'NONE') = 'NONE')) AND ( (MTF.C3_CODE = 'NONE') OR (NVL ('NONE', 'NONE') = 'NONE')) AND ( (MTF.C4_CODE = null) OR (null IS NULL)) AND ( (MTF.C5_AMT <= 0) OR (NVL (0, 0) = 0)) AND ( (MTF.C5_AMT >= 0) OR (NVL (0, 0) = 0)); Execution Plan ---------------------------------------------------------- Plan hash value: 1536592532 ----------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | ----------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 45M| 9151M| 358K (1)| 01:11:41 | | | | 1 | PARTITION RANGE ALL | | 45M| 9151M| 358K (1)| 01:11:41 | 1 | 2 | | 2 | TABLE ACCESS STORAGE FULL| TABLE2 | 45M| 9151M| 358K (1)| 01:11:41 | 1 | 2 | ----------------------------------------------------------------------------------------------------------- select column_name,num_nulls,num_distinct,density from dba_tab_col_statistics where table_name='TABLE2' and column_name in ('C3_CODE','C4_CODE','C5_AMT','C6_CODE'); C3_CODE 0 65 0.0153846153846154 C4_CODE 0 2 0.5 C5_AMT 0 21544 4.64166357222429E-5 C6_CODE 1889955 71 0.0140845070422535933257 wrote:
((SF. C1_IDCODE =: B4) OR (NVL (: B4, 'NONE') = 'NONE'))
In fact for literals, I did not find any section of the predicate after running the sql code with activation "set autotrace traceonly explain."
The main problem is with another large query whose cardinality is underestimated due to the presence of these table (table1, table2) with the above mentioned clause, and the query is for the analysis of index + nested with values of Bind loops and take 10 hr +, whereas with literals, its completion in ~ 8minutes with FTS + Hash Join.
Your real problem is that you try to have just a single SQL query handle all POSSIBLE thanks to the use of embedded FILTERS ' either / or ' filters in the WHERE clause. You want only a select this OPTION to run whatever filters have been selected at run time by the user or the application using it. And it would never work. You really need to SELECT different queries for different combinations of filter conditions.
Why? Think for a minute. How Oracle works internally? A SQL SELECT query gets analyzed and an execution plan is produced which is stored in the library cache and gets REUSED on all subsequent executions of this query - except in certain cases where there may exist several plans run through several cursors of the child. So with only SELECT a query you only AN execution plan in the library cache, to be used by all THE executions of this query, regardless of the value of your run-time binding variables.
Lets put another way - each library cache execution plan is associated with a SQL statement. If you want a DIFFERENT execution plan then you need run a DIFFERENT SQL statement. That's how you get a different execution plan - by running a different SQL statement. Running the SAME SQL query generally you will get the SAME execution plan every time.
In addition, because of the "either / or" filters that you use you will end up generally with a full Table Scan on each of the referenced tables. Why? Given that the optimizer must produce an implementation plan that manages all possible contingencies for all values of possible bind variables in the SELECT. If the optimizer should choose to use any index based on one of these "either / or" filters then it would only help performance when real value was provided, but it would be really bad if a NULL value was supplied. If the optimizer ends up ignoring the index because they are not always optimal for all possible input values and instead chose a plan that is "good enough" for all input values possible. That means that it will use a scanning Table full.
I hope you can see that it is precisely what is happening for you with your query. You select this OPTION to manage the different combinations of filter, which leads to the execution plan only one, which leads to scans full Table on the referenced tables in these ' either / or ' filters.
The solution? Build queries SELECT DIFFERENT when input values are NULL. How you do that? Read this article to ask Tom that tells you:
http://www.Oracle.com/technetwork/issue-archive/2009/09-Jul/o49asktom-090487.html
To sum up - when you have real value for a bind variable 'bind_var1' add the following filter to your CHOICE:
AND column_name1 =: bind_var1
When the binding variable is NULL, add the filter according to your CHOICE:
AND (1 = 1 OR: bind_var1 IS NULL)
Now, you'll have 2 queries SELECT must be performed, which have exactly the same number of variables in the same order bind, which is important. When you then run one of these variations, Oracle can analyze and optimize each one SEPARATELY, with a single execution by the SELECT query plan.
When you provide a real value, the filter is a normal 'column = value' that the optimizer can use all indexes on this column, because NULL values are not referenced.
When there is no real value, the optimizer will analyze the '1 = 1 GOLD' and realize that "1 = 1" is set to TRUE and GOLD, it is quite TRUE regardless because the binding variable is null or not. This means that the optimizer will actually REMOVE this filter, because it filters nothing because it is always TRUE. You will end up with an operating plan based on the other filters in the query, which is what you want because you have no filter on this column.
What is it - producing distinct SELECT queries to determine if you have a real value to filter or not you end up with DIFFERENT execution plans for each of them, and each of them is OPTIMAL for this particular set of filters. Now you get good performance for each variation of the performance of the SELECTION, rather than sometimes good and sometimes very bad when using SELECT only one. It is impossible to try to get multiple shots of execution 'optimal' out of a SELECT query. That's why you get mediocre performance under different bound the values of the variables.
John Brady
-
How many times can I use a variable binding in a query of the VO?
Is it possible that I can use a variable binding in a query of VO just once?
I test a query that keeps throwing the Houston-27122 error by pressing the application module tester. I tried to limit the problem to the simplest possible case, and it seems that the error is caused by the fact that I use the same variable bind two or more times.
When the query looks like this:

I have run, enter 'x' and it returns me the result.
When I change to:

I have run, enter the value

and immediately get the error

The same thing in sqlplus runs without problem:

My version of JDev is build JDEVADF_11.1.1.9.0_GENERIC_150314.0718.6673
Please, advise.
P. S. where can I find documentation queries are supported in your? In particular, I'm interested if I can use WITH the clause. There seems to be some confusion on this matter (see, for example, Oracle SQL WITH clause support - JDeveloper and ADF)
Thank you.
It depends on:
Open your VO in JDev and go the the query page.
In the lower part, there is a drop down 'link type', it is usually set to "JDBC-positional. In this case, you will need to provide the bind value for each occurrence of the variable binding separately.
You could change that to "named" (don't remember the exact name). But beware, this will also affect all relatioships master retail to others your. I think that this is not a good idea to change the style of binding to a single VO.
Good bye
DPT
-
How to set a variable to an attribute pageFlowScope on Create Insert without using session variable
Hi Experts ADF,
JDeveloper 12 c.
I have a VO as below:-
SELECT Departments.DEPARTMENT_ID,
Departments.DEPARTMENT_NAME,
Departments.LOCATION_ID,
Departments.MANAGER_ID
DEPARTMENTS of MINISTRIES
WHERE Departments.DEPARTMENT_Name =: bindDeptName
And taskflow as below:-which starts with a default activity as ExecuteWithParams that defines the variable of the VO to the pageFlowScope variable binding.
When the page loads, it now has a button create that is mapped to the CreateInsert operation. Now I have @overridden create the method below. How to pass the pageflowscope variable to the EOImpl.java without using a Variable of Session. If any other approach is there please suggest.
EOImpl.java
@Override protected void create (AttributeList attributeList) {} this.setAttributeInternal (DEPARTMENTNAME, "msg"); -> Msg value here should be replaced by variable scope pageflow. Super.Create (AttributeList); } Thanks in advance
Roy
Roy, do not access a page flow or session scope variable in the model layer.
Instead, you use the createWithParams to pass the variable to the create method via the link layer. An example can be found here http://andrejusb.blogspot.de/2011/02/createwithparams-operation-for-oracle.html
Timo
-
Using a variable in an Insert / Select
Oracle 11 g 2
It is a block of the size of the code. I want to use a variable in the clause values an Insert / Select using the execute immediate statement.
g_sysdate date := sysdate
I can't ' use sysdate directly because it is a long-term process. We attribute sysdate to g_sysdate at the beginning of the procedure and we stored in several tables. Therefore, it has the same value everywhere.
I'm getting ORA-00904: "G_SYSDATE": invalid identifier
create table usa.work_time ( id number , work_status_id number , work_task_id number , txt_msg varchar2(255) ) / create table usa.work_time_arc ( id number , work_status_id number , work_task_id number , txt_msg varchar2(255), archived_dt date ) / insert into usa.work_time values(1,2,3,'hello'); commit ; DECLARE v_query varchar2(2000); g_sysdate date := sysdate ; v_tbl_arc varchar2(61) := 'usa.work_time_arc'; v_tbl_src varchar2(61) := 'usa.work_time'; v_tab_cols varchar2(2000) := 'id,work_status_id,work_task_id,txt_msg'; v_id number := 9521; BEGIN v_query := 'insert /*+ append */ into '||v_tbl_arc || ' (' || v_tab_cols || ',archived_dt)' || 'select ' || v_tab_cols || ',g_sysdate from ' || v_tbl_src || ' where id = :id'; dbms_output.put_line(v_query); execute immediate v_query using v_id ; END ; / ERROR at line 1: ORA-00904: "G_SYSDATE": invalid identifier ORA-06512: at line 14That should do it.
DECLARE v_query varchar2(2000); g_sysdate date := sysdate ; v_tbl_arc varchar2(61) := 'usa.work_time_arc'; v_tbl_src varchar2(61) := 'usa.work_time'; v_tab_cols varchar2(2000) := 'id,work_status_id,work_task_id,txt_msg'; v_id number := 9521; BEGIN v_query := 'insert /*+ append */ into '||v_tbl_arc || ' (' || v_tab_cols || ',archived_dt)' || 'select ' || v_tab_cols || ',:g_sysdate from ' || v_tbl_src || ' where id = :id'; dbms_output.put_line(v_query); execute immediate v_query using g_sysdate, v_id ; END ; / -
How to use a variable as a column name in a select statement
Hello, I am using
Oracle Database 11 g Enterprise Edition Release 11.2.0.3.0 - 64 bit Production
PL/SQL Release 11.2.0.3.0 - Production
I have a procedure looking for groups that have not been updated for the current month. The columns are month_01, month_02, month_03 etc. I'm becoming if I can automate every month, but I need to be able to use a variable as the name of the column for the month. Can someone help me with this?
Example of Table
CREATE TABLE TEST_TABLE ( IDENTITY_CODE NUMBER(10), YEAR_S NUMBER(5), MONTH_01 NUMBER(18,2), MONTH_02 NUMBER(18,2), MONTH_03 NUMBER(18,2), MONTH_04 NUMBER(18,2), MONTH_05 NUMBER(18,2), MONTH_06 NUMBER(18,2), MONTH_07 NUMBER(18,2), MONTH_08 NUMBER(18,2), MONTH_09 NUMBER(18,2), MONTH_10 NUMBER(18,2), MONTH_11 NUMBER(18,2), MONTH_12 NUMBER(18,2) ); INSERT ALL INTO TEST_TABLE VALUES(640,2015,124,123,125,126,127,128,547,888,987,567,145,685) INTO TEST_TABLE VALUES(098,2015,587,874,0,587,652,222,444,777,885,999,657,547) INTO TEST_TABLE VALUES(608,2015,587,874,687,587,652,222,444,787,885,999,657,547) select 1 from dual;
Here's my current procedure
CREATE OR REPLACE PROCEDURE RRM_EMAIL_NOTIFICATION IS v_output VARCHAR2(10000); v_message VARCHAR2(1000); v_date date; cursor v_check is SELECT * FROM (SELECT '640' AS ds FROM DUAL UNION ALL SELECT '098' AS ds FROM DUAL UNION ALL SELECT '608' AS ds FROM DUAL UNION ALL SELECT '618' AS ds FROM DUAL UNION ALL SELECT '617' AS ds FROM DUAL UNION ALL SELECT '614' AS ds FROM DUAL UNION ALL SELECT '610' AS ds FROM DUAL UNION ALL SELECT '616' AS ds FROM DUAL UNION ALL SELECT '643' AS ds FROM DUAL) WHERE LPAD (ds, 3, '0') NOT IN (SELECT DISTINCT (SUBSTR (IDENTITY_CODE, 2, 3)) AS Blah_Blah_Blah FROM TEST_TABLE WHERE month_03 <> 0 AND year_s = 2015 AND ( SUBSTR (IDENTITY_CODE, 2, 3) = '640' OR SUBSTR (IDENTITY_CODE, 2, 3) = '098' OR SUBSTR (IDENTITY_CODE, 2, 3) = '608' OR SUBSTR (IDENTITY_CODE, 2, 3) = '618' OR SUBSTR (IDENTITY_CODE, 2, 3) = '617' OR SUBSTR (IDENTITY_CODE, 2, 3) = '614' OR SUBSTR (IDENTITY_CODE, 2, 3) = '610' OR SUBSTR (IDENTITY_CODE, 2, 3) = '616' OR SUBSTR (IDENTITY_CODE, 2, 3) = '643')); BEGIN v_date := SYSDATE; open v_check; loop fetch v_check into v_output; exit when v_check%NOTFOUND; v_message := v_message || chr(13) || v_output; END LOOP; close v_check; send_mail('The RRM one-time initiatives that have not been processed for '||v_date|| ' are ' || chr(13) ||v_message,'[email protected]','RRM ONETIMES NOT PROCESSED FOR ' || v_date); END RRM_EMAIL_NOTIFICATION;I need to be able to substitute the name e.g. MONTH_01 with a variable column so that it will be MONTH_ | "" some months "
A variable can be created as v_month: = 'month_ | TO_CHAR (T_DATE, 'MM')
If I'm not mistaken that should come out as month_03 for March
The output should be in an email as follows:

Something like:
CREATE OR REPLACE PROCEDURE RRM_EMAIL_NOTIFICATION IS
v_output VARCHAR2 (10000);
v_message VARCHAR2 (1000);
date of T_DATE;
v_check SYS_REFCURSOR;
BEGIN
T_DATE: = SYSDATE;
Open the v_check FOR
Q' {}
SELECT *.
FROM (SELECT '640' DS DUAL FROM
UNION ALL
SELECT '098' LIKE ds FROM DUAL
UNION ALL
SELECT '608' LIKE ds FROM DUAL
UNION ALL
SELECT '618' LIKE ds FROM DUAL
UNION ALL
SELECT '617' LIKE ds FROM DUAL
UNION ALL
SELECT '614' LIKE ds FROM DUAL
UNION ALL
SELECT '610' LIKE ds FROM DUAL
UNION ALL
SELECT '616' LIKE ds FROM DUAL
UNION ALL
SELECT '643' DS DUAL FROM)
WHERE LPAD (ds, 3, '0') NOT IN
(SELECT DISTINCT (SUBSTR (IDENTITY_CODE, 2, 3)) AS Blah_Blah_Blah
FROM TEST_TABLE
{WHERE month_}' | TO_CHAR (T_DATE, 'MM') | Q'{ <> 0
AND year_s = 2015
AND SUBSTR (IDENTITY_CODE, 2, 3))
'640'
'098'
, ' 608 "
'618'
'617'
'614'
'610'
'616'
'643')
)
}';
loop
extract the v_check in v_output;
When the output v_check % NOTFOUND;
v_message: = v_message | Chr (13) | v_output;
END LOOP;
close v_check;
send_mail ("one-time initiatives the RRM that haven't been treated for ' |") T_DATE | «are» | Chr (13) | v_message,' [email protected]',' ONETIMES UNPROCESSED for RRM ' | T_DATE);
END RRM_EMAIL_NOTIFICATION;
-
DATACOPY function problem using several variables quick
Hello
I have problem when I use more variables and then a quick calculation with DATACOPY function. When I put a prompt variable in function DATACOPY it works but when I add one or more it gives me error Essbasse (I can see it in the Essbase Administration journal not in the syntax checking process):
Not valid [Calc Script syntax
DATACOPY Q1020-> Dec-> 'FY14'-]
[Fri Jul 11 15:04:25 2014] Local/TS_PLAN/Prihodi/admin@Native Directory/1004/Error (1200421)
Error occurred at or after the line [8]
-Essbase put FY14 because it is rapidly Variable in this error above.
I try datacopy function with this:
DATACOPY Q1020-> Dec-> "FY14 '... It works
DATACOPY Q1200-> Dec-> {YearPrompt}... It works
DATACOPY Q1200-> Dec-> {YearPrompt}-> {ScenarioPrompt} it doesn't it break on variable ScenarioPrompt.
Thank you
Finally, I solved my problem. That was the problem Essbasse how to understand the spaces between the dimensions. I didn't not use quotes for members and I put space between the arrows. It gave me an error I think because he did not understand space as the space. Now, when I use quotes and remove the space between the arrows cross dimensions it works.
-
Use of Variables in a Script of Essbase report
I know you can use a variable in a script with Essbase report & at the beginning of the name. Example & CurMonth. This works very well for me. But, you can use & FcstMonths when the value of the months are more than one Member? It works in a calc script when & FcstMonths = March, April, may, June... etc, but, when I use it in a report script, the script will not validate the saying "unknown member of the value. I tried to change it to January.February.March... etc. I also tried February: December. None of them does not seem to work. Is it just not possible for Essbase report? Thanks in advance.
If you want to include a list of members in the report script, you specify the members separated by spaces. If you set the variable...
"Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec"
... I think you'll find that it works.






Maybe you are looking for
-
Cannot open file because Windows needs to know what program created the file
After downloading some files when I try to open the file, I get the message cannot open the file, windows needs to know what program created the file. Any suggestions?
-
HP laptop - 15-r114ne: VGA and USB Driver does not
Hello My newly purchased HP for laptop - 15-r114ne can't see the devices connected via the USB Ports. I do not see the load connected wih on my android phone, but I can't access the device. Then the screen brightness is not reduced; It is very diffic
-
What is the mode of connection (ME918LL/A) current Airport Extreme support?
I have a setup of the airport with two airports of previous generation connected in Bridge mode. (NOTE that this is not the same thing as a network via a wifi - connection Wi - Fi). I want to upgrade one of the units. I believe I read somewhere that
-
Local server connect to a domain license server
I have a server terminal server running under windows 2012 locally (domain a) My license server is running on windows 2012 arrived in the area. Forest mode I try to establish a connection between the 2 of them and it fails. *** To identify possible l
-
Is node/host usually means a client computer or it means that the window Server computer?
Is node/host usually means a client computer or it means that the window Server computer?