What better way to Bootcamp?
I have the standard 2015 early Macbook Pro. All up to date with OS El Captian. Unfortunately, I have not upgraded the SSD (sorely regret). I now want to have bootcamp on my device for school work and games. So I was wondering is it better to move all my files to a HARD drive and bootcamp exterior windows half half partition on the SSD flash disk internal. OR bootcamp for an external drive could possibly get a Lacie Rugged with thunderbolt and HARD USB 3.0 drive. Thank you
Put a small (about 50 + GB) C: on the internal disk and external use (say D :) for all your programs/files. If you lose C:, re - install Windows without loss of data. Establish a strict regime of OS X backups, Windows and Windows System Restore point.
Tags: Windows Software
Similar Questions
-
What better way to macbook pro chrome or firefox
Hello
I need to have my 2 email and Facebook 2 accounts open at the same time keeping instead of having to connect and again, which is better for the macbook pro firefox or chrome?
Thanks in advance
Tracey xx
Firefox. Chrome is a glutton of resources among browsers. Have you also thought about Safari or opera?
Ciao.
-
What better way to use Win XP - Satellite L350-150 or Sat P300 - 18 M
Hey Yes,.
I m planning on purchasing a L350-150 or a P300 - 18 m and I would like to install Win Xp on it.
I have a Win XP CD I want to use for this purpose.These models have the problems to decommissioning in Win Xp. (e.g., hard disk, etc.)
See you soon.
Hello
I think you should search here a little bit because there are many threads that describes various issues and solve simple problems
As far as I know Windows XP should run on both computers mobile service without worry
And for both sets of the Windows XP drivers are available on the European driver Toshiba page.Concerning
-
How to see what beta worm I am to-deeper than the help | About Firefox - registry...?
I am enrolled in the beta channel but because pop - up notification is so fast I someties don't see that a new beta version is available. I consulted the filehippo regularly to see what updates are out there, but I want to have a way I can find what beta, I'm in-help | About Firefox not to-how can I find that? looked in the registry, but have not found what I want
any ideas?
Ciao
sawVersion beta, just like other versions of development, is supposed to act as a valid version to avoid problems with the (browser) user agent sniffing and to have a user agent that has an attached specific beta version would be this brake.
- Bug 728831 - do not expose the level of Firefox (13.X.Y) patch in the chain, do not show the major version (13.X)
(please, do not comment in the bug reports: https://bugzilla.mozilla.org/page.cgi?id=etiquette.html)
-
Is there a better way to do it?
Okay, so I try to dial numbers to create a RPG character, and I think I found a way to transfer information from one sheet to the other. The specific cell transferred from sheet 1 (capacity degreasing) differs according to a variable of box chain drop in a cell on the worksheet 2.
What I have is: = IF (C2 = 'Force', ability Scores: $E$ 2, IF (C2 = 'Agility', ability Scores: $E$ 3, IF (C2 = 'Constitution', ability Scores: $E$ 4, IF (C2 = 'Intelligence', ability Scores: $E$ 5, IF (C2 = 'Wisdom', ability Scores: $E$ 6, IF (C2 = "Charisma", ability Scores: $E$ 7))) )))
And while this works, I wonder if there is a better way to implement.
Any ideas?
HI Durzan,
This sounds like a job for one of the search functions. Main table on the left, on the right ability Scores.

Main, column C contains three cells in the context menu.
Hand, D2: = VLOOKUP (C, ability Scores: A:E, 5, 0)
Filled down.
Kind regards
Barry
-
There must be a better way to do this
There must be a better way to do this!
25 separate reports - 1 voltage recorded by chanel every minute for 21 hours (end - times will have to be changed)
Anyone has ideas/directions
CC
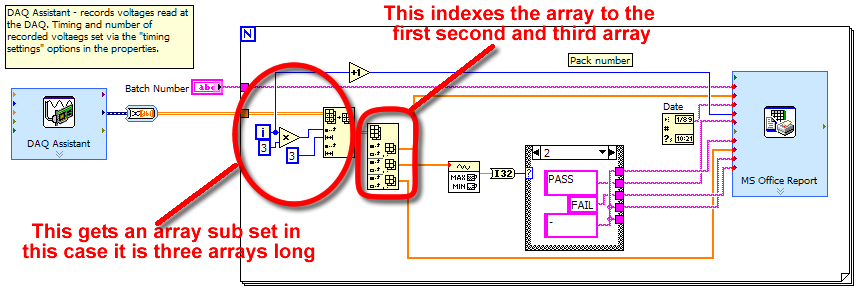
The DAQ Assistant reads the tensions based on the timings specified, which means that if I set the number of samples finish say 20 and the frequency of samples to 1, then data acquisition will take 20 seconds to save 20 data points (one second) per channel. Then the DAQ pump data to the loop that creates reports (N number of reports).
TO answer this question: the DAQ Assistant will do exactly what you suggest here.
Two questions:
-the loop will be able to separate the different channels ie first report contains data AI1, AI2 and AI3, then the second contains data AI4, AI5 AI6 etc.. ? What is the purpose of the table screws?
TO answer this question: If you look inside the front loop, you see I have the sub table value function. I have set the index to the increment and then multiply 3 X. The first time in the loop take 0 and multiply by 3 and I get zero. second time through I multiply 1 X 3 and get 3. The second thing I have on the sub table set is giving him a length of 3. This will make return three matrices. So this will give me the next three tables each time through. So the first time through I get AI0 AI1, AI2 AI3 AI4, AI5 second time or however you have configured channels.
- and what is the function of painting that the subset of table is wired to (can not find the icon of my pallet table)?
TO answer this question: Index table. Handel, it automatically becomes a 2D array.
-
A better way to make a continuous read/write on a NOR-6008
Hello
I use a USB of NOR-6008 module and have a loop of the software configuration where I acquire analog signals, digital signals, then, then put a digital high or low and repeat. I use digital multiplex outside the material so that I can use 6 of the analog inputs to read 12 signals. The digital inputs that I have are connected to the buttons on a panel that are used for the entry instead of the screen of the computer of the user. My loop is also to build a buffer zone of all the signals on the analog and digital lines that I read in so I can on average and this process elsewhere in the program.
The question that I am running is because this loop is very slow and on the final product is performed on a touch screen, XP Embedded PC and just this acquisition loop begins again as much CPU as the rest of my program. I would say that drops of loops on 4 or 5 cycles per second, which means that my update of 2 multiplex signals or longer than a second time. I would really like to better performance and does not use as much of my CPU resources.
I use a way simple enough to make the loop of the acquisition, by setting the parameters I, reading, deleting the task, defining the parameters DI, read, erase the task and then by setting the parameters, write about it and delete the task, which gives a slight delay and repeat.
Any thoughts on a better way to start the read/write that what I'm doing?
I have attached the code examples in the loop of the acquisition that I use.
Thank you!
First of all, the best plan is to move the chain DAQmx before the loop to create and use a start DAQmx, then write in the loop, then clear once the loop ends. This configuration must be done once, not every time you write the channel. This should speed things up considerably.
-
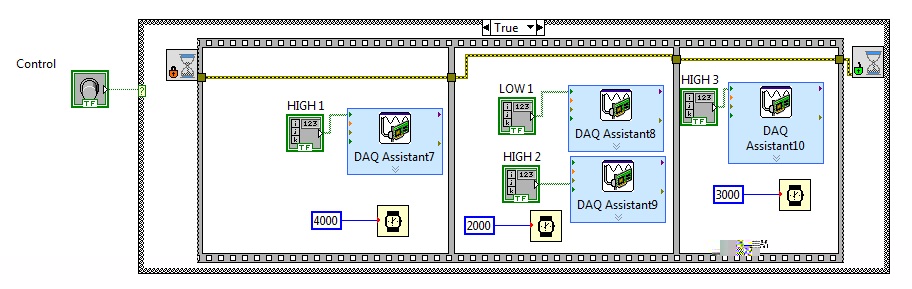
Is there a better way to generate the custom timed digital signals
I'm trying to generate the digital output from the top and down with delays on different lines. Each daq assistant is activate single line on a port USB 6501. There more complex high and lows that I need to generate variable time difference between high and low. There is codebelow that does what I'm trying to achieve, but for a model executing high and low signal is much of your time to do it this way. I'm sure there is a better way to do it, I'm not an expert on labview so I only discovered its potential. Anyone can suggest a more effective and a quick way to do it. I would like to hgihly appreciate. Thank you!
I've not shown in the code below, but using the DAQ assistant, I initialized lines at low logic level.
-
Multi-terrain graphs, is there a better way?
I'm still not good at graphics in LabView, but I think I do a few programs and I can usually get a graph to show with what I want to show him only a few hours of dinking with it autour...
In any case using graphics certainly made for messy code unless there is a better way to this thread. Basically, this chart shows the four temperature sensors and is updated every minute. A check of stabilization is carried out every 15 minutes. Apparently the only way I could get the multiple locations with time that x-axis it are use an xy graph, but I have my reading on the index individually and each put in it is the own shift register and add it to the chart separately.
There must be a better way?
I think that part of your problem is that you are not aware of the option 'Concatenate entries"to build array. You don't need several bays to build the set of clusters, we made connections in graph (pink wire). Just expand the build, wire all clusters, then right-click on the picture of construction and choose 'Concatenate entries. Then, you can use a cluster to store all your berries to graph (orange wire) which will be greatly cleans your diagram.
-
Hi guru, I was able to get what I want, but I find there must be a better way/more efficient way to write this sql?
Database: Oracle 11g
This is the create for the test database statement:
create table sample_test (prog_id number (9) DEFAULT 0 NOT NULL, chan_rights CHAR (2) DEFAULT ' ' NOT NULL)
This is the insert statement:
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A1')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A2')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A3')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A4')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A5')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A6')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A7')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'A1')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'A2')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'A3')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'B1')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'B2')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'B3')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'B4')
Here's what I did to get the data:
Select distinct a.prog_id, rt_cnt, CASE
WHEN a.rt_cnt = 7
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A1')
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = "A2")
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = "A3")
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A4')
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A5')
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A6')
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A7')
THEN "A_ONLY".
else 'SINGLE '.
end CHAN_GROUP
from (select prog_id, count (chan_rights) rt_cnt
of sample_test
Prog_id group) a, b sample_test
where a.prog_id = b.prog_id
That appears as follows:
PROG_ID RT_CNT CHAN_GROUP 495641 7 UNIQUE 555633 7 A_ONLY As seen:
1 / I count how many rights is available, and in this case, each program gets a "7"
Set 2 / from these data, for each programme, I try to make sure it belongs to the company chan_rights right, for example, "A_ONLY". Therefore, as shown, Prog_ID 495641 does not contain "A_ONLY" channels listed in the case statement and there is unique. "A_ONLY" should only contain A1 to A7 inclusive and nothing else.
Can I create a function that returns the value "Chan_Group", but is there a better way to rewrite the statement 'BOX' like a LOOP or something? I have millions of records to go through and someone told me that using "is" slows down the database so just thought that I could ask ahead...
Please indicate if there is a better and more efficient method to get what I need?
Thank you
John
I would do something like
select prog_id, rt_cnt, (case when rt_cnt = 7 and num_a = 7 then 'A_ONLY' else 'UNIQUE' end) chan_group from (select prog_id, count(chan_rights) rt_cnt, sum( case when chan_rights in ('A1','A2','A3','A4','A5','A6','A7') then 1 else 0 end ) num_a from sample_test group by prog_id)View of inline, I count the number of values chan_rights, as well as the number that are in your list of A1 - A7. In the outer query, I implement the logic that checks that the two charges are 7.
Here is an example of sqlfiddle this http://www.sqlfiddle.com/#! 4/95438/2
Justin
-
Is there a better way to set up my root directory
I started to design a Web site for my new project, but I'm not a Web Designer by trade and I just want to check that I've set up my root directory of the site correctly and that there is not a better way. The screenshot below shows what I have right now

I have not yet started to design real pages or customize almost anything because I first wanted to check that I had put in place the root properly. Is there a better way to implement or have I set up in the best possible way
If there is a better way, or if I made mistakes then please tell me.
Jay
No idea if there is a better way. Can tell you that my sites are configured in exactly in the same way.
-
A better way to get all the text style ranges in a table
I am trying to get all the text varies from the style of my document into one. I'm scripting in JavaScript, which I'm not very familiar with, so maybe that's the problem.
This is what, in my view, should work:
app.activeDocument.stories.everyItem().textStyleRanges
The above doesn't give me a text string, not an array of objects of text style than I expected. If I were using Applescript I would ask just for the beaches of text style object reference, but it is not a property that I found in the javascript object model.
So I resorted to what is slower, but gives me what I want:
var allStyleRanges = new Array(); for (var g = 0; g < myStories.length; g++) { var storyStyleRanges = (myStories[g].textStyleRanges); for (var s = 0; s < storyStyleRanges.length; s++) { allStyleRanges.push(storyStyleRanges[s]); }; };Does anyone have a better way?
Lev,
May it as your requirment...
alert(app.activeDocument.stories.everyItem().textStyleRanges.everyItem().getElements())
Concerning
Siraj
-
Now that we have liquid, is there a better way to make an Alphabet for Webapp elements filter when you have more than 500 Articles?
I am using the JQuery ListNav, but my webapp now has too many items. Liquid filter by chain to make a filter of the alphabet?
{module_webapps id = "16734" filter = 'all' template="/Layouts/WebApps/Applications/dashboard-list-a.tpl' = 'collection' render}
What else can I use in the parameter 'filter '?
Thank you!
Shannon
Udemy as a tutorial on it. Practical examples of liquid for Adobe Business Catalyst markup . It was called list Rolodex. This is the solution you want.
-
UNION ALL GROUP THEN SQL - is a better way
Hi gurus of SQL,.
Just try my luck to see if there is a better way to write the following SQL code. I don't know if the UNION ALL + GROUP BY is the best way. Is it better to use a FULL OUTER JOIN instead?
Thanks for your time.
See you soon
Ligon
... and here's the planSELECT x.task_id, x.task_name, max(x.actual_effort) actual_effort, max(x.date_completed) date_completed, max(x.status) status FROM ( SELECT t.task_id, t.task_name, NULL actual_effort, NULL date_completed, NULL status FROM tt_tbl_tasks t, tt_tbl_emps e, tt_tbl_references r WHERE /*t.task_status = 'Y' AND*/ t.task_start_dt <= menu_util.get_date('15/02/2010',menu_util.df) AND NVL(t.task_end_dt,SYSDATE+9999) >= menu_util.get_date('15/02/2010',menu_util.df) AND e.emp_id = 'MEARS_MP' AND t.task_id = e.task_id AND r.ref_type = 'FREQUENCY' AND t.task_frequency = r.ref_id AND is_event_ready (p_start_dt => t.task_start_dt, p_end_dt => t.task_end_dt, p_check_dt => menu_util.get_date('15/02/2010',menu_util.df), p_freq => to_number(r.ref_name)) = 'Y' UNION ALL SELECT t.task_id, t.task_name, ev.actual_effort, ev.date_completed, ev.status FROM tt_tbl_tasks t, tt_tbl_emps e, tt_tbl_events ev WHERE ev.date_completed = menu_util.get_date('15/02/2010',menu_util.df) AND t.task_id = ev.task_id AND e.emp_id = 'MEARS_MP' AND t.task_id = e.task_id )x GROUP BY x.task_id,x.task_name
Plan SELECT STATEMENT ALL_ROWSCost: 11 Bytes: 178 Cardinality: 2 18 HASH GROUP BY Cost: 11 Bytes: 178 Cardinality: 2 17 VIEW TTDB. Cost: 10 Bytes: 178 Cardinality: 2 16 UNION-ALL 8 NESTED LOOPS 6 NESTED LOOPS Cost: 5 Bytes: 88 Cardinality: 1 4 NESTED LOOPS Cost: 4 Bytes: 65 Cardinality: 1 2 TABLE ACCESS BY INDEX ROWID TABLE TTDB.TT_TBL_TASKS Cost: 4 Bytes: 52 Cardinality: 1 1 INDEX RANGE SCAN INDEX TTDB.TT_TBL_TASKS_IDX_START_DT Cost: 2 Cardinality: 5 3 INDEX UNIQUE SCAN INDEX (UNIQUE) TTDB.TT_TBL_EMPS_PK Cost: 0 Bytes: 13 Cardinality: 1 5 INDEX UNIQUE SCAN INDEX (UNIQUE) TTDB.TT_TBL_REFERENCES_PK Cost: 0 Cardinality: 1 7 TABLE ACCESS BY INDEX ROWID TABLE TTDB.TT_TBL_REFERENCES Cost: 1 Bytes: 23 Cardinality: 1 15 NESTED LOOPS Cost: 5 Bytes: 64 Cardinality: 1 13 NESTED LOOPS Cost: 5 Bytes: 102 Cardinality: 2 10 TABLE ACCESS BY INDEX ROWID TABLE TTDB.TT_TBL_EVENTS Cost: 3 Bytes: 36 Cardinality: 2 9 INDEX RANGE SCAN INDEX TTDB.TT_TBL_EVENTS_IDX_DT_COMPLETED Cost: 1 Cardinality: 2 12 TABLE ACCESS BY INDEX ROWID TABLE TTDB.TT_TBL_TASKS Cost: 1 Bytes: 33 Cardinality: 1 11 INDEX UNIQUE SCAN INDEX (UNIQUE) TTDB.TT_TBL_TASKS_PK Cost: 0 Cardinality: 1 14 INDEX UNIQUE SCAN INDEX (UNIQUE) TTDB.TT_TBL_EMPS_PK Cost: 0 Bytes: 13 Cardinality: 1Something like that I guess.
select t.Task_ID ,t.Task_Name ,p.Actual_Effort ,p.Date_Completed ,p.Status from ( select t.Task_ID as Task_ID ,t.Task_Name as Task_Name from tt_tbl_Tasks t ,tt_tbl_Emps e ,tt_tbl_References r where t.Task_Start_Dt <= Menu_Util.Get_Date('15/02/2010',Menu_Util.Df) and nvl(t.Task_End_Dt,sysdate + 9999) >= Menu_Util.Get_Date('15/02/2010',Menu_Util.Df) and e.Emp_ID = 'MEARS_MP' and t.Task_ID = e.Task_ID and r.Ref_Type = 'FREQUENCY' and t.Task_Frequency = r.Ref_ID and is_Event_Ready (p_Start_Dt => t.Task_Start_Dt, p_End_Dt => t.Task_End_Dt, p_Check_Dt => Menu_Util.Get_Date('15/02/2010',Menu_Util.Df), p_Freq => to_number(r.Ref_Name)) = 'Y' ) t left join ( select Task_ID ,Task_Name ,Actual_Effort ,Date_Completed ,Status from ( select t.Task_ID as Task_ID ,t.Task_Name as Task_Name ,ev.Actual_Effort as Actual_Effort ,ev.Date_Completed as Date_Completed ,ev.Status as Status ,row_number() over (partition by t.Task_ID, t.Task_Name order by ev.Actual_Effort desc ,ev.Date_Completed desc ,ev.Status desc) rn from tt_tbl_Tasks t ,tt_tbl_Emps e ,tt_tbl_Events ev where ev.Date_Completed = Menu_Util.Get_Date('15/02/2010', Menu_Util.Df) and t.Task_ID = ev.Task_ID and e.Emp_ID = 'MEARS_MP' and t.Task_ID = e.Task_ID ) where rn = 1 ) p on t.Task_ID = p.Task_ID and t.Task_Name = p.Task_NameThe join type and if you filter by null will determine what your require, then its up to you to experiment.
-
Looking for a better way to write this SQL
Oracle version 11R2
Version of the OS (any)
What I try to do is write a query that finds Public synonyms without a target object. I came up with this, but I think there is a better way.
object_type is null appears to be weak. It seems that the target object must be better.Select s.owner, s.synonym_name, s.table_name, s.table_owner, s.db_link, InitCap(o.object_type) object_type from sys.DBA_SYNONYMS s, sys.DBA_OBJECTS o where s.synonym_name is not null and s.table_owner = o.owner (+) and s.table_name = o.object_name (+) and s.owner = 'PUBLIC' and object_type is null;
Your comments, observations, questions welcome.I don't know exactly what 'better' means in this context (faster, easier to read, etc.), but I tend to use a NOT EXISTS
SELECT s.* FROM dba_synonyms s WHERE owner = 'PUBLIC' AND s.db_link IS NULL AND NOT EXISTS ( SELECT 1 FROM dba_objects o WHERE o.owner = s.table_owner AND o.object_name = s.table_name )I added the criteria DB_LINK to filter the public synonyms referring to objects in remote databases that obviously do not exist in the local DBA_OBJECTS.
Justin


Maybe you are looking for
-
Everytime I try and reorganize my favorites they won't stay where I put them!
Everytime I try and reorganize my favorites (when I save one that is not at the end, more that it lies in the middle of the list) and another one of my friends got moved on accident, I can't make them stay in place. I used to be able to just click on
-
I would like to unsubscribe to the newsgram of hp who get as an email on my iphone. Any suggestions?
-
How much noise is expected on 6353 digital output lines?
I'll send a signal to pass a set of relay reed with the port on a pci-e 6353. When the line is low, the noise is ~ 10 mV. When it is high, the noise is ~ 30-40mV. The noise seems to be done through the signal lines in the reed relays. What is the lev
-
Hello I need a text box where users can change their name. I tried the EditField and BasicEdit - field but when I press return on one of them it actually moving fields to the bottom of the screen! I just need a box where users can enter information (
-
Install esxui in esxi 6.0.0 - vibformatError
I try install ui in esxi 6.0 with the following commandcommand:[root@localhost:/tmp] esxcli software vib install - v http://download3.VMware.com/software/VMW-tools/esxui/esxui-offline-bundle-6.x.zip[VibFormatError]Header of archive incorrect VIBfilen