Looking for a better way to write this SQL
Oracle version 11R2Version of the OS (any)
What I try to do is write a query that finds Public synonyms without a target object. I came up with this, but I think there is a better way.
Select
s.owner, s.synonym_name, s.table_name, s.table_owner, s.db_link, InitCap(o.object_type) object_type
from
sys.DBA_SYNONYMS s, sys.DBA_OBJECTS o
where
s.synonym_name is not null
and
s.table_owner = o.owner (+)
and
s.table_name = o.object_name (+)
and
s.owner = 'PUBLIC'
and
object_type is null; Your comments, observations, questions welcome.
I don't know exactly what 'better' means in this context (faster, easier to read, etc.), but I tend to use a NOT EXISTS
SELECT s.*
FROM dba_synonyms s
WHERE owner = 'PUBLIC'
AND s.db_link IS NULL
AND NOT EXISTS (
SELECT 1
FROM dba_objects o
WHERE o.owner = s.table_owner
AND o.object_name = s.table_name )
I added the criteria DB_LINK to filter the public synonyms referring to objects in remote databases that obviously do not exist in the local DBA_OBJECTS.
Justin
Tags: Database
Similar Questions
-
Hi guru, I was able to get what I want, but I find there must be a better way/more efficient way to write this sql?
Database: Oracle 11g
This is the create for the test database statement:
create table sample_test (prog_id number (9) DEFAULT 0 NOT NULL, chan_rights CHAR (2) DEFAULT ' ' NOT NULL)
This is the insert statement:
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A1')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A2')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A3')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A4')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A5')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A6')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A7')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'A1')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'A2')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'A3')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'B1')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'B2')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'B3')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'B4')
Here's what I did to get the data:
Select distinct a.prog_id, rt_cnt, CASE
WHEN a.rt_cnt = 7
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A1')
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = "A2")
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = "A3")
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A4')
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A5')
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A6')
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A7')
THEN "A_ONLY".
else 'SINGLE '.
end CHAN_GROUP
from (select prog_id, count (chan_rights) rt_cnt
of sample_test
Prog_id group) a, b sample_test
where a.prog_id = b.prog_id
That appears as follows:
PROG_ID RT_CNT CHAN_GROUP 495641 7 UNIQUE 555633 7 A_ONLY As seen:
1 / I count how many rights is available, and in this case, each program gets a "7"
Set 2 / from these data, for each programme, I try to make sure it belongs to the company chan_rights right, for example, "A_ONLY". Therefore, as shown, Prog_ID 495641 does not contain "A_ONLY" channels listed in the case statement and there is unique. "A_ONLY" should only contain A1 to A7 inclusive and nothing else.
Can I create a function that returns the value "Chan_Group", but is there a better way to rewrite the statement 'BOX' like a LOOP or something? I have millions of records to go through and someone told me that using "is" slows down the database so just thought that I could ask ahead...
Please indicate if there is a better and more efficient method to get what I need?
Thank you
John
I would do something like
select prog_id, rt_cnt, (case when rt_cnt = 7 and num_a = 7 then 'A_ONLY' else 'UNIQUE' end) chan_group from (select prog_id, count(chan_rights) rt_cnt, sum( case when chan_rights in ('A1','A2','A3','A4','A5','A6','A7') then 1 else 0 end ) num_a from sample_test group by prog_id)View of inline, I count the number of values chan_rights, as well as the number that are in your list of A1 - A7. In the outer query, I implement the logic that checks that the two charges are 7.
Here is an example of sqlfiddle this http://www.sqlfiddle.com/#! 4/95438/2
Justin
-
Looking for a better way to count the responses to the survey questions
Hello all - I have created a survey for a site and now want to display the results to the admins of the site. I am trying to display the countdown - the number of times that a question has been answered in a certain way. I realize that I may need to build the investigation itself differently and how it stores data, but here is how it goes far.
There are 10 questions, each with 4 options of radio button groups. The database table contains a column for each issue and stores the value of the selected option button. So it's pretty simple.
Now on the results page, that it's the only way I can think to do, but there must be a better way. For each answer, I create a Recordset filtered on the issue and the value option, then display the total number of records. Which works great, but count each option, which means that 40 recordsets on the page - al simply determine "how many times was the Question 1, Option was selected and how many times has the Question 1, selected Option B and so on.»
The only other thing I can think it maybe is a better way to count the occurrences of these values in the table is with PHP or in the SQL itself. Or, perhaps, if the values themselves are entirely digital and follow a kind of model I can use a solution of math.
Thoughts, solutions, and ideas are welcome! Thank you.
Your problem is a bad design. You should have a separate line for each answer, not to separate the columns. It also makes the very rigid investigation. A simple design would include a few tables - a master of the investigation that stores the questions and response table that contains a foreign key to the question number in the master, the answer, as well as any other details you need to capture. You might get more elaborate, but it's essential. Your result page and then just be a single recordset with a simple query with a group by clause.
I urge you to review this before going any further.
-
looking for a better way to add many groups of
Hello
I'm new to G language and I find it quite difficult to figure out how to deal with table in labview. I am creating the over $ 15 consine functions (discrete) each with different frequencies. I use the loop and consine function to generate the table for each COS, but to add each other (adding the element by element), I have to use a loop again? I'm really curious to know if there is another way to generate the sum of all these cosine at a time and convert the result into a single table. Someone suggested using the form and loop for, but I don't understand how to use the form and how to make the result?
You can create and add in the same iteration using a registry to offset.
Here's a quick demo, adding five functions sinus with different numbers of cycles. You should be able to adapt it to your problem.
-
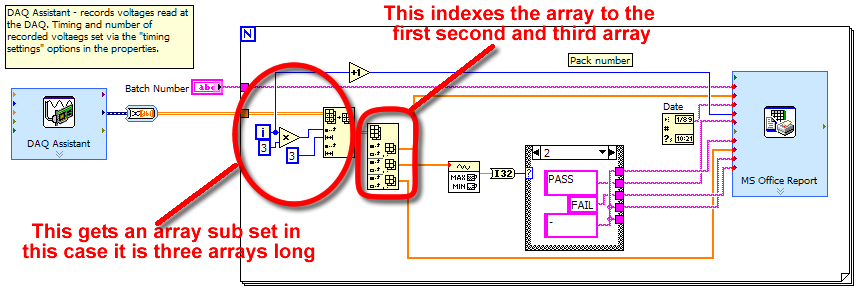
There must be a better way to do this
There must be a better way to do this!
25 separate reports - 1 voltage recorded by chanel every minute for 21 hours (end - times will have to be changed)
Anyone has ideas/directions
CC
The DAQ Assistant reads the tensions based on the timings specified, which means that if I set the number of samples finish say 20 and the frequency of samples to 1, then data acquisition will take 20 seconds to save 20 data points (one second) per channel. Then the DAQ pump data to the loop that creates reports (N number of reports).
TO answer this question: the DAQ Assistant will do exactly what you suggest here.
Two questions:
-the loop will be able to separate the different channels ie first report contains data AI1, AI2 and AI3, then the second contains data AI4, AI5 AI6 etc.. ? What is the purpose of the table screws?
TO answer this question: If you look inside the front loop, you see I have the sub table value function. I have set the index to the increment and then multiply 3 X. The first time in the loop take 0 and multiply by 3 and I get zero. second time through I multiply 1 X 3 and get 3. The second thing I have on the sub table set is giving him a length of 3. This will make return three matrices. So this will give me the next three tables each time through. So the first time through I get AI0 AI1, AI2 AI3 AI4, AI5 second time or however you have configured channels.
- and what is the function of painting that the subset of table is wired to (can not find the icon of my pallet table)?
TO answer this question: Index table. Handel, it automatically becomes a 2D array.
-
Hello
I have a problem and I realized a simplified version of it:
The id of the requirement to join these two tables based on:create table deals (id_prsn number, id_deal number, fragment number); create table deal_values (id_prsn number, id_deal number, value_ number, date_ date); insert into deals values(1,1,50); insert into deals values(2,2,40); insert into deals values(1,3,50); insert into deals values(2,4,80); insert into deals values(1,5,20); insert into deals values(2,6,80); insert into deal_values values(1,1,10 ,sysdate - 3); insert into deal_values values(2,2,208, sysdate - 3); insert into deal_values values(2,4,984, sysdate - 3); insert into deal_values values(1,null,134,sysdate - 3); insert into deal_values values(1,1,13, sysdate - 2); insert into deal_values values(2,2,118, sysdate - 2); insert into deal_values values(2,4,776, sysdate - 1); insert into deal_values values(1,null,205,sysdate - 1); insert into deal_values values(2,null,-5,sysdate - 1);
1.) ID_PRSN and ID_DEAL
2.) max DATE_ grouped per person and deal
(3.) in the case that ID_DEAL is defined in the AGREEMENTS, but not defined in the DEAL_VALUES table, I have to join this records to DEAL_VALUES based on the person where id_Deal is null.
Number 3 gives me headache. I realized the following query:
It returns the correct result of he,select *from ( select a.id_prsn, a.id_deal, a.fragment, b.value_, b.date_, max(b.date_) over (partition by b.id_prsn, b.id_deal) max_date from deals a inner join deal_values b on a.id_deal = b.id_deal or b.id_deal is null and not exists (select 1 from deal_values where id_prsn = a.id_prsn and id_deal = a.id_deal) and a.id_prsn = b.id_prsn ) where date_ = max_Date;
ID_PRSN ID_DEAL FRAGMENT VALUE_ DATE_ MAX_DATE
1 1 50 13 16.10.2012 09:59:48 16.10.2012 09:59:48
1 3 50 205 17.10.2012 09:59:48 17.10.2012 09:59:48 OK
1 5 20 205 17.10.2012 09:59:48 17.10.2012 09:59:48 OK
2 2 40 118 16.10.2012 09:59:48 16.10.2012 09:59:48
2 4 80 776 17.10.2012 09:59:48 17.10.2012 09:59:48
2 6 80-5 17.10.2012 09:59:48 17.10.2012 09:59:48 OK
but the join clause:
in fact the query much slower.on a.id_deal = b.id_deal or b.id_deal is null and not exists (select 1 from deal_values where id_prsn = a.id_prsn and id_deal = a.id_deal) and a.id_prsn = b.id_prsn
I was wondering is there a different way to write this join and manage the logic.
Thanks in advanceHere's a different approach:
select * from ( select a.id_prsn, a.id_deal, a.fragment, B.value_, b.date_, ROW_NUMBER() over( partition by a.ID_PRSN, a.ID_DEAL order by B.ID_DEAL nulls last, B.DATE_ desc ) RN from DEALS a join DEAL_VALUES B on a.ID_PRSN = B.ID_PRSN and a.ID_DEAL = NVL(B.ID_DEAL, a.ID_DEAL) ) where rn = 1 order by 1, 2;"nulls last" is the default sort order; I just put that for clarity.
Published by: stew Ashton on October 18, 2012 12:58
-
Can you help me? Is there a simpler way to write this short code?
Hi, I'm quite new to coding and EDGE and think there must be a simpler way to write this? :
sym.getSymbol("USA_animation").play ();
sym.getSymbol("World_map").play ();
sym.getComposition () .getStage ().getSymbol("UK_animation").$("UK").fadeOut ();
sym.getComposition () .getStage ().getSymbol("UK_animation").$("Piechart").fadeOut ();
sym.getComposition () .getStage ().getSymbol("UK_animation").$("people").fadeOut ();
sym.getComposition () .getStage ().getSymbol("UK_animation").$("PeopleText").fadeOut ();
sym.getComposition () .getStage ().getSymbol("UK_animation").$("UKText").fadeOut ();
sym.getComposition () .getStage ().getSymbol("AUS_animation").$("AUSTRALIA").fadeOut ();
sym.getComposition () .getStage ().getSymbol("USA_animation").$("USA").show ();
sym.getComposition () .getStage ().getSymbol("USA_animation").$("USAText").show ();
Can you help me?
Obivious to increase efficiency is
var USA_animation = sym.getSymbol ("USA_animation")
USA_animation. Play();
sym.getSymbol("World_map").play ();
USA_animation.$("UK").fadeout ();
USA_animation.$("PieChart").fadeout ();
USA_animation.$("people"). fadeOut();
USA_animation.$("PeopleText").fadeout ();
USA_animation.$("UKText").fadeout ();
USA_animation.$("AUSTRALI_A").fadeout ();
USA_animation.$("USA"). Show();
USA_animation.$("USAText"). Show();
If you perform a single operation on all the symbols of the "USA_animation" child, you can also reduce somethinng as
sym.getSymbol("World_map").play ();
var USA_animation = sym.getSymbol ("USA_animation")
USA_animation. Play();
var childSymbols = USA_animation.getChildSymbols (); f
for (var i = 0; i)
childSymbols [i] .fadeOut ();
I don't know if these are the best ways, but these are in a way that I could think of.
Let us know if offer you a lot shorted way to write this
-
I'm looking for the best way and the best way to get a product key for my windows 7 Edition family.
Hello. I'm looking for the best way and the best way to get a product key for my windows 7 Edition family. Thanks Bob
Original title: product windows keys 7
The cheapest option is the OEM System Builder for Windows 7 Home Premium license, but has some license restrictions:
Amazon.com: Windows 7 Home Premium 64 - Bit System Builder...
The OEM of Windows 7 versions are identical to the versions commercial full license with the following exception:
-OEM versions don't offer any free direct support from Microsoft technical support Microsoft
-OEM Licenses are tied to the computer first you install and activate it on
-OEM versions allow all hardware upgrades except for an upgrade to a different model motherboard
-OEM versions does not move directly from an older Windows operating system
What is OEM software? :
http://support.Microsoft.com/GP/oemsupport_1/en-GBLicensing FAQ:
http://www.Microsoft.com/OEM/en/licensing/sblicensing/pages/licensing_faq.aspxOR
A detail that does not have these restrictions:
Where can I still get Windows 7?
Full version - Microsoft Windows 7 Home Premium
Version upgrade - Microsoft Windows 7 Home Premium Upgrade
Family Pack: Upgrade of Microsoft Windows 7 Home Premium Family Pack (3 users)
-
Most clean way to write this expression GREP
Hello
I have a GREP expression which is now:
InDesign
InDesign CS
InDesign CS2 (or 3,4,5)
InDesign CS2 (or 3,4,5)
.. .and this is what it looks like... I don't know there is a way to write, but I can't ahven managed to run... any thoughts there ;-)

Thank you!
Babs
Hi Babs! Chips a glance, shall we.
First of all, I fill a frame with placeholder text; then I add "InDesign" and all its variants up randomly in the text, with spaces around and there followed by punctuation.
Then I create a character style "Hi-lite" adapted; a light blue background, so I can see exactly what is being matched. Then, I go to my definition of standard paragraph and create a GREP style with Preview on. Then it's just a case of the entry of codes and look at the preview.
Hang on while I do it. (You can use a ready earlier.)
Here you are:
\bInDesign (CS [2345]?)? (~]s)?\b
fits all blue below. Note it does not match "InDesign CS6" (and more recent); If you do not want to be prepared for the future, you would use
\bInDesign (CS\d?)? (~]s)?\b
Look at how the combination of parentheses and question mark together define strings: it's all or nothing with those. The \b's are just to force - define whole words, no funny stuff admitted directly before or after the speech - punctuation is fine.

-
Is there a better way to make this pop up?
I have a VI that has more than 900 void screw which has been developing since the Labview V5. It has a control loop and a loop of data. The vehicle currently has half a dozen or more Windows vi it appears for different reasons. Most collect all of the data passed to them but don't have to return data. I called the sub, it opens and the data is passed but he shares time with the main window, so I can not change anything in the main window as the Sub keeps seizing control.
I came up with this solution attached below, but it seems that there must be a better way? I don't know that I just lack. I need to be able to start in a field of the program running on a while loop and sends the data to the it in an another while loop which collects data while giving full control to the main VI.
Thanks for any help.
-
There must be a better way to do this (frustration of RAM Preview)
I loaded one 01:20 second Full HD clip in sequels. I need to edit the video based on some sounds in the video and see if I match them correctly by the image previewed with the sound.
The problem is that I'm frustrated due to After effects does not not like first. First who thought it was a good idea is not to integrate sound in sequels? Secondly, I have an i7 processor sandy bridge, and 16 GB of ram, but he always takes time to render the preview ram (with still no effect on it).
Ram preview is my only option for sound, but the problem is every time I hit the ram preview it starts the video all the way from the beginning. It's frustrating because I want to start at a specific time. Imagine having a video more long where editing must take place at the end.
Professional projects of people out there doing a lot more complicated, you guys how to work around this problem?
Why can't after that effects do some basic things like first as make fast with the sound? Is it because of the Mercury engine and 64-bit?
It is one of the best products on the market, there must be a better way of doing things?
No need to preview RAM just to hear the sound, use the comma on the numeric keypad key to play an audio preview only.
If you want to mark certain audio events, twirl down the properties for the audio until you see the waveform and then use it to synchronize audio and animations.
And if you want RAM Preview from your current position, simply press the 'B' button to set your start of work area to the playhead, and then the RAM previews will begin from that point.
Use ctrl - drag to scrub audio & video. Use ctrl-alt-drag to scrub just audio.
AE has all the audio features of first (and), he just behaves in a different way.
-
What is the most effective way to run this sql
I have a sql like this:
As you can see, the sql calculate a field value to another view (View1 view2 View3, view4).select ((select q_avg24 from view1 where years=2009 and qtr=1) - (select q_avg24 from view1 where years=2010 and qtr=1)) as sub_s1_avg24, ((select q_avg24 from view2 where years=2009 and qtr=1) - (select q_avg24 from view2 where years=2010 and qtr=1)) as sub_s2_avg24, ((select q_avg24 from view3 where years=2009 and qtr=1) - (select q_avg24 from view3 where years=2010 and qtr=1)) as sub_s3_avg24, ((select q_avg24 from view4 where years=2009 and qtr=1) - (select q_avg24 from view4 where years=2010 and qtr=1)) as sub_s4_avg24 from dual
It returns the difference between the 2 years.
In this sql, you can see she will solicit the views of the 2 x 4 = 8 times to get result table.
Each query sql (select statement) return a result within 5 seconds, then... for total = 8 X 5 = 40secs...
40 dry is not so big problem... but in fact, I have at least 5 games queries (select statements) with other parameters are not an entry for the calculation of this query...
There are a lot of your time in SQL that results from: (8X5secs) x 5 = 200secs...
I would like to know is there a solution better if we face such problems?
Thank you!!!You can use as... not tested...
But if you provide additional information on the data, I think we can think best solutionselect sum(decode(id,1,decode(yers,2009,av,0),0))-sum(decode(id,1,decode(yers,2010,av,0),0)) av1, sum(decode(id,2,decode(yers,2009,av,0),0))-sum(decode(id,2,decode(yers,2010,av,0),0)) av2, sum(decode(id,3,decode(yers,2009,av,0),0))-sum(decode(id,3,decode(yers,2010,av,0),0)) av3, sum(decode(id,4,decode(yers,2009,av,0),0))-sum(decode(id,4,decode(yers,2010,av,0),0)) av4 from( select 1 id,q_avg24 av,years from view1 where years in (2009,2010) and qtr = 1 union all select 2 id,q_avg24,years from view2 where years in (2009,2010) and qtr = 1 union all select 3 id,q_avg24,years from view3 where years in (2009,2010) and qtr = 1 union all select 4 id,q_avg24,years from view4 where years in (2009,2010) and qtr = 1)Published by: JAC on March 30, 2012 13:31
-
Honestly, I really looked everywhere for this.
The problem is that, while tinkering in SQL Developer and knowing that in the spreadsheet I can just execute individual instructions by placing the cursor on the SQL statement I want to run I tried to do an INSERT query that would allow me to run an INSERT statement for... Well many inserts.
I thought I could use a brand of continuation but nothing I've tried has worked.
INSERT INTO
HF_easy_drinks
VALUES
("Blackthorn", "tonic water", 1.5, 1.0, "pineapple juice", "mix with ice").
("Blue Moon", "soda", 1.5 "Blueberry Juice",. 75, "mix with ice, strain")
;
I ended up doing just individual INSERT statements, which was not as convenient.
INSERT INTO HF_easy_drinks
VALUES ('Blackthorn', 'tonic water', 1.5, 1.0, "pineapple juice", "mix with ice");
INSERT INTO HF_easy_drinks
VALUES ('Blue Moon', 'soda', 1.5, 'Blueberry Juice',. 75, "mix with ice");
Hello
Perhaps you might prefer "an" insert like this:
INSERT INTO hf_easy_drinks (x, y, z,...)
SELECT "Blackthorn", "tonic water", 1.5, 1.0, "pineapple juice", "mix with ice" OF THE double
UNION ALL SELECT 'Blue Moon', 'soda', 1.5, 'Blueberry Juice',. 75, "mix with ice, strain ' FROM dual
SELECT UNION ALL... OF the double
SELECT UNION ALL... OF the double
;Best regards
Bruno Vroman.
-
I am looking for a SIMPLE way to add my robots.txt file
I read up on this subject. But I wasn't able to do it again.
I found this:



You can follow the guidelines of Google to create a robots.txt file and place it in the root of your remote site.
https://support.Google.com/webmasters/answer/156449?hl=en
Thank you
Vinayak
----------------
Once you create a robots.txt like this:
user-agent: ia_archive
Disallow: /.
(1) where do you put 'head labels? Do you need them?
I would insert it in muse that looks like this
< head >
user-agent: ia_archive
Disallow: /.
< / head >
or just put it anywhere inside the 'head' tag
(2) put the robots.txt file in a folder?
I've heard this, but it just doesn't seem right.
(3) OK you have the
-Properties Page
-Metadata
-HTML < head >
Can I copy and paste my right robot.txt info in there? I don't think I can and make it work. According to the info I found (that I posted above), the robots.txt 'file' you 'place at the root of your remote site.
(4) where is the 'root of my remote sit?
How can I find that?
I read other people having problems with this.
I thank very you much for any help.
Tim
I need Terry White to make a video on it LOL
Maybe I'll ask.
I thought about it.
However, with the help of Godaddy, the file was not placed between the
and, so I'm still a little nervous.It is recommended to:
///////////////////////////////////
1. re: file robots.txt for sites of the Muse
Vinayak_Gupta , April 19, 2014 01:54 (in response to chuckstefen)
You can follow the guidelines of Google to create a robots.txt file and place it in the root of your remote site.
https://support.Google.com/webmasters/answer/156449?hl=en
Thank you
Vinayak
/////////////////////////////////////
Place the robots.txt file to the root "of your remote site.
and that (Godaddy) is not between the
I checked the robot file that I created here
New syntax Robots.txt Checker: a validator for robots.txt files
and other than me not to capitalize
the 'u' in the user-agent, it seems to work. When my site is analyzed, she does not miss a robots.txt file
user-agent: ia_archive
Disallow: /.
Problem solved, unless I find an easy way to place the robots.txt file placed between the head tags (and better).
I'll keep my ears open, but don't worry too much on this subject.
Step 1) write the code of robots that you want to
Step 2) save the file as a txt
Step 3) contact your Web hosting provider / upload in the root of the Web site in a single file
Step 4) check with a robot's checker that I listed above
What was shake me:
-where to put
-the difference between files and folders, it seemed I would be to load a file for some reason any.
-I was expecting something like the
list of the news LOL -
Looking for a better (larger) keyboard
I have a new G 3rd generation and the use of the standard KB is a little too small for my fat fingers, outside rotaing screen does anyone know of a better keyboard (bigger) look I don't mind if the keyboard is on 4 lines, but all suggestions are welcome, don't mind paying for the application If it is decent
APE1
Download keyboard shortcut key. It is better there. You can resize the keyboard according to your size.


Maybe you are looking for
-
I have an iPhone with 9.3.1 6. When I try to send a few pictures or even set it as my desktop background, they say they are 'Impossible to share '. Anyway is it me or do I need to bring it to a store?
-
How to return to windows installer? Bootcamp
After my bootcamp partition, the computer has been restarted with the windows installer. I got to the part that says select partition to install windows. I read the message that he is not the right format requires NTFS. Well, I clicked format and it
-
Hi, once windows 7 installed successfully 5 updates I tried to restart the computer, but it would not be closed after that some time I did a cold longer closed. After booting even once, Windows 7 does not recognize the updates, as it is installed and
-
HP PSC1315 with Windows XP wireless printing.
Is their a router out there that I can buy to use my HP PSC1315 wireless-ly? Everything in our House is Windows XP.
-
Several BSOD occurred, even for the selection 'Reply' to a Mozilla Thunderbird e-mail!
I use a HP Pavilion dv7-7121nr Notebook PC [64-bit Win 7 Home Premium, 6 GB RAM, AMD A8] which I had for a month. I use DriverGenius and DriverUpdate to ensure that I have all the latest drivers installed and. I use Norton for security protection. I