ADF AND SOA: WHAT IS THE RELATIONSHIP BETWEEN THE ADF AND SOA
Hello worldsomeone can such me what is the relationship of the ADF with SOA?
How are they related? or no relationship at all?
ADF is part of the SOA?
Why ADF?
Why SOA?
Thanks in advance guys.
Kind regards
Raja.
ADF is a framework that helps you to create applications that are designed according to SOA best practices.
With ADF, you build reusable business services that can be exposed and consumed in SOA flows. Moreover ADF allows you to create parts of the user interface of your SOA application.
There are other points of integration between the Oracle SOA suite and Oracle ADF - I recommend to watch this for an overview:
http://download.Oracle.com/otn_hosted_doc/JDeveloper/11gdemos/Introduction_To_ADF/Introduction_To_ADF.html
http://download.Oracle.com/otn_hosted_doc/JDeveloper/11gdemos/ADFInsider-SOA/OracleInsider-SOA.html
Tags: Java
Similar Questions
-
What is a relationship between the data store and LUN?
Hello
I added 3 LUNS to a data store, but I can't list them since the MOB data store. Could someone tell me how to do it.
Thanks in advance.
Lee
LUNS was formatted as VMFS and created a data store? If not, it will not be displayed. You can search for available LUNS that can be used to create a VMFS with QueryAvailableDisksForVmfs volume
=========================================================================
William Lam
VMware vExpert 2009
Scripts for VMware ESX/ESXi and resources at: http://engineering.ucsb.edu/~duonglt/vmware/
Introduction to the vMA (tips/tricks)
Getting started with vSphere SDK for Perl
VMware Code Central - Scripts/code samples for developers and administrators
If you find this information useful, please give points to "correct" or "useful".
-
What is the relationship between the library of Photos and the iPhoto library?
I'm asking this question here because I can't find all the relevant information online.
I was dealing with imac a client recently who had a full boot drive. I noticed that his old iPhoto library used 126GB while she had already made the transition to the Photos. His photo library said that he was using a lot more (200 + if I remember correctly). I copied the iPhoto on an external drive library and deleted. Then, I opened the contents of the package and imported pictures remains in program pictures to make sure that I wasn't actually remove all of his memories. Once the work is finished, I was surprised to see that there are more than 6 GB of free space on his computer. What gives? Is there a relationship between the old iPhoto library and new photo library? If so, what is it? Is what I did without danger? I understand at the time that she will not be able to return to iPhoto. But what I'm missing?
Thanks in advance for your comments.
No - they are totally separate - connection or relationship of any kind is not
or the other can be deleted without any effect on the other - but it won't save much space at all and is not recommended - which is exactly what you have seen- Photos saves disk space to share images with your iPhoto or Aperture - Apple Support libraries
LN
-
What is the relationship between the source code (LKS) file and the process file (L4P)?
I know that Lookout produces a file of source code with an LKS extension when you save a file to process. Can someone explain the relationship between the two files, especially while the (L4P) process is running?
- Is this just a backup file can be recompiled in a process file?
- A file corrupt LKS cause strange problems with operation process file?
I currently have a very strange intermittent behavior with a process file run. I first thought that the problem was associated with my Fieldpoint and/or their configuration modules. Since then, I found that my process file has a file corrupt LKS. I repaired and recompiled my LKS file to a new file to process. I still don't know if I have solved the problem or not. So, the problem is intermittent, I did that about 20-30 SECONDS to resolve the problems there before he goes. Then he can not show up again for another 2-3 days.
The .lks file is just the source code of your process. It can be opened by a different version of lookout, but does not have the .l4p file.
The .lks file is not be used while a process is running. Lookout does not read the file more after his execution. So it should not affect the running process.
What kind of problem, is it?
-
What is the difference between the ADF and ADF Essentials?
What is the difference between the ADF and ADF Essentials?
and how to ensure that the essentials of the ADF is enough for the project rather then ADF.
Thanks in advance.
Hello
The main problem is, you are not allowed to deploy critical applications of the ADF in the clustered environment.
Kuba
-
What are the relationships between the logging and IKM?
What is the best method to use in the following scenario:
I have about 20 tables with the large amount of data sources.
I need to create interfaces that join the source tables in target tables.
The tables are inserted every few seconds with about hundreds of thousands lines.
There may be a gap of a few seconds between the insertion of different tables that could be attached.
The source and target tables are on the same Oracle instance and schema.
I want to understand the role of: 'Logging CDC' and "IKM - incremental" and
How can I use it in my script?
In general, what are the relationships between "Logging" and 'IKM '?
Use both? Or maybe it's better deelte and insert the target tables?
I want to understand what is the role of "Logging CDC"?
Can 'IKM - incremental' work without "logging"?
Must 'Logging' have PK on the tables?
What should I do if I can't say PK (there may be several identical lines)?
Yael thanks in advanceuser604062 wrote:
Hello
Thanks for your quick response!No probs - its still fresh in memory I did a major project on this topic last year (400 tables, millions of lines per day (inserts, updates, deletes), sup-5 minute latency). The problem is it isn't that well written on the web, that you have read the blog of the example I linked to in my first answer? See also here: http://odiexperts.com/changed-data-capture-cdc/
Always on logging:
My source table is inserted all the time.
The interface to join the source table in the target table.In ODI, the correct term would be your source table "fits" in the table target, unless you mean literally that want to join the the source with the taget table table? My question if you want to do with the result of the join?
What exactly the "journaling" CDC updates?
It updates the model of ODI? interfaces? The source of data in the model of ODI? The target table?Logging CDC configures and deploys the data capture mechanism (Triggers or log based capture, IE Logminer/streams/Goldengate) - it is not updated the model as such, she pointed out the metadata of the model of ODI repositoty as a CDC data store, allowing you, the developer say ODI to use log data if you wish (reported in the interface) There is no change in the target table, you get an indicator of metadata (IND_UPD) against a line during the integration (in C$ and I have tables$) that tells you if its insertion (I) and update (U) or deletion (D). It had ' lines allow you to synchronize the deletions, but yoy say its inserts only then you probably used use this option. "
So the only changes are the source table to your interface, another diary data (if you use logging) or the table of the actual source (if not using the logging).This is the main thing that I don't understand!
I hope I made a little clearer.
Try the following as a quick test:
Reverse a source table an engineer and the target (at least) table.
Import the update incremental LKM and IKM.
Import of the JKM you want to use.Create an interface between the source and the target without any deployed JKM.
Configure the options of JKM on the model, the "Start log" to start the process of capture - this is quite a complex stage and a lot of things to understand what is happening in the source database, better to check code ODI sends to the database and to review the documentation of Oracle database for a description of what his weight (instantiate Tables (, sets of creating change, creation of subscribers etc. establishment of newspaper groups, creating views Journalising etc.) -you will need to consult your Source DBA database initially as ODI wants to make many changes to the source DB (in mode Archivelog process max, parallelism, size, Java etc.)Now, edit your interface and mark the table source for use "Journalized data bank.
Restart your interface
Compare the difference in the generated code in the journal of the operator, see the differences of the operator.>
Thank you, Yael
-
What gets the relationship between the number of blocks and coherent?
QUESTION:SQL> CREATE TABLE TEST(ID INT ,NAME VARCHAR2(10)); SQL> CREATE INDEX IND_IDN ON TEST(ID); SQL> BEGIN 2 FOR I IN 1 .. 1000 3 LOOP 4 EXECUTE IMMEDIATE 'INSERT INTO TEST VALUES('||I||',''LONION'')'; 5 END LOOP; 6 COMMIT; 7 END; 8 / SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS(USER,'TEST',CASCADE=>TRUE); SQL> SELECT DISTINCT DBMS_ROWID.rowid_block_number(ROWID) BLOCKS FROM TEST; BLOCKS ----------- 61762 61764 61763 >> above , there have 3 blocks in table TEST . SQL> SET AUTOTRACE TRACEONLY; SQL> SELECT * FROM TEST; Execution Plan ---------------------------------------------------------- Plan hash value: 1357081020 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1000 | 10000 | 2 (0)| 00:00:01 | | 1 | TABLE ACCESS FULL| TEST | 1000 | 10000 | 2 (0)| 00:00:01 | -------------------------------------------------------------------------- Statistics information ---------------------------------------------------------- 0 recursive calls 0 db block gets 72 consistent gets >> there have 72 consistent gets 0 physical reads 0 redo size 24957 bytes sent via SQL*Net to client 1111 bytes received via SQL*Net from client 68 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1000 rows processed SQL> SELECT /*+ INDEX_FFS(TEST IND_IDN)*/ * FROM TEST WHERE ID IS NOT NULL; Execution Plan ---------------------------------------------------------- Plan hash value: 1357081020 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1000 | 10000 | 2 (0)| 00:00:01 | |* 1 | TABLE ACCESS FULL| TEST | 1000 | 10000 | 2 (0)| 00:00:01 | -------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("ID" IS NOT NULL) Statistics information ---------------------------------------------------------- 1 recursive calls 0 db block gets 72 consistent gets >> there have 72 consistent gets 0 physical reads 0 redo size 17759 bytes sent via SQL*Net to client 1111 bytes received via SQL*Net from client 68 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1000 rows processed SQL> SELECT COUNT(*) FROM TEST; Execution Plan ---------------------------------------------------------- Plan hash value: 1950795681 ------------------------------------------------------------------- | Id | Operation | Name | Rows | Cost (%CPU)| Time | ------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 2 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | | | | 2 | TABLE ACCESS FULL| TEST | 1000 | 2 (0)| 00:00:01 | ------------------------------------------------------------------- Statistics information ---------------------------------------------------------- 0 recursive calls 0 db block gets 5 consistent gets >> there have 5 consistent gets 0 physical reads 0 redo size 408 bytes sent via SQL*Net to client 385 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> SELECT COUNT(*) FROM TEST WHERE ID IS NOT NULL; Execution Plan ---------------------------------------------------------- Plan hash value: 735384656 -------------------------------------------------------------------------------- - | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- - | 0 | SELECT STATEMENT | | 1 | 4 | 2 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 4 | | | |* 2 | INDEX FAST FULL SCAN| IND_IDN | 1000 | 4000 | 2 (0)| 00:00:01 | -------------------------------------------------------------------------------- - Predicate Information (identified by operation id): --------------------------------------------------- 2 - filter("ID" IS NOT NULL) Statistics information ---------------------------------------------------------- 0 recursive calls 0 db block gets 5 consistent gets >> there have 5 consistent gets 0 physical reads 0 redo size 408 bytes sent via SQL*Net to client 385 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> SELECT COUNT(ID) FROM TEST WHERE ID IS NOT NULL; Execution Plan ---------------------------------------------------------- Plan hash value: 735384656 -------------------------------------------------------------------------------- - | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- - | 0 | SELECT STATEMENT | | 1 | 4 | 2 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 4 | | | |* 2 | INDEX FAST FULL SCAN| IND_IDN | 1000 | 4000 | 2 (0)| 00:00:01 | -------------------------------------------------------------------------------- - Predicate Information (identified by operation id): --------------------------------------------------- 2 - filter("ID" IS NOT NULL) Statistics information ---------------------------------------------------------- 0 recursive calls 0 db block gets 5 consistent gets >> there have 5 consistent gets 0 physical reads 0 redo size 409 bytes sent via SQL*Net to client 385 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed
What gets the relationship between the number of blocks and coherent? How to calculate become consistent?You can see that your uniform is getting down to 6 to 12, is it not? Reading of the below thread Asktom.
http://asktom.Oracle.com/pls/Apex/f?p=100:11:0:P11_QUESTION_ID:880343948514Aman...
-
What are the relationship between JPA and Hibernate, JPA and TopLink?
What are the relationship between JPA and Hibernate, JPA and TopLink?
Can APP instead of Hibernate and TopLink?The Java Persistence API (JPA) is the persistence of mapping relational object
standard for Java. Hibernate and TopLink provide a Java Open source object-relational mapping framework.
They provide an implementation for the Java Persistence API. In my opinion, Hibernate and TopLink support JPA
and they can also be seen as complementary to APP.We will wait to see the opinions of the other person.
-
What is the difference/relationship between a subject and a page?
Hi all
I'm not sure of the relationship between a topic and a new page: it seems that a subject can be made up of pages, but when I look at the HTML of the subject, there is no new section (DIV) for the addition of the page.
Also, not sure about the relationship between the book and the pages/topics.
You would be grateful if someone could either point of reference material or provide a few clarifying words on that.
Thank you, Donna
In regards to the benefits of the pages pointing to topics:
Placeholders (table of contents Pages) allow a single topic to appear in several places in the table of contents. If the table of contents used directly the subject, each topic could appear only in one place. For example, maybe help is divided into sections, user and administrator, and administrators and regular users can add coordinates to a person in the application. Using a placeholder allows a single procedure to be created (as the task is the same for both users) and then referenced in the two sections of the table of contents. If the subjects were used directly, two different subjects will have to be created. You can also organize your subjects in a folder structure that suits you and use a different structure in the table of contents.
The placeholder allows also a display name different be used, for example, if you have a long topic name but want a shorter name to appear in the table of contents, or if the topic appears in several places in your table of contents and you want to focus slightly different in each place, say for different groups of users.
-
What are the difference and relationship between automatic update optimizer...
What are the difference and relations between optimizer automatic update and Automatic Setup SQL?
In my opinion, they are the same.Nothing! ATO is used when you call the STA to grant any question. The STA is nothing else than an API to the ATO.
HTH
Aman... -
the trust relationship between this machine and the primary domain failed
Hi I have a virtual server (Server 03) with a vista machine, I can log on to the vista computer, but it happens with the trust relationship between this machine and primary domain failed. I tried to delete the domain vista machine, but he says you need to keep a main area
Any suggestions gratefully received
Hello
Your question is more complex than what is generally answered in the Microsoft Answers forums. It is better suited for Windows Server on Technet. Please post your question in the Technet forums. You can follow the link to your question:
-
The trust relationship between this workstation and the primary domain failed.
The trust relationship between this workstation and the primary domain failed. This only happens on the Windows 7 desktop. It is sporadic. Add the computer account to the domain is not a viable solution. It happens far too often.
There is nothing coherent we found on systems that are removed from the field. Some time its workstations users, sometimes its laptops to students and sometimes he posts of laboratory work. Different types of systems use different images. All images are syspreped before creating the image.
Hi Geoffrey,.
Your question of Windows 7 is more complex than what is generally answered in the Microsoft Answers forums. It is better suited for the IT Pro TechNet public. Please post your question on the Technet Windows 7 Security Forum
Lisa
Microsoft Answers Support Engineer
Visit our Microsoft answers feedback Forum and let us know what you think. -
The relationship between workstation and domain fails approval
In our environment, we have Windows Server 2008 with Windows 7 machines. Lately some Windows 7 machines have received the error that does not have a trust relationship between workstation and domain and users are unable to connect to the machine. We know a fix by removing the machine in the field and join again the machine. I am currently trying to find the cause of this problem, your help will be appreciated.
Thank you for visiting the Microsoft answers community.
The question you have posted is linked to a domain environment and Windows Server and would be best suited in MS TechNetWindows Server Forum orTechnet Windows 7 Security Forum. Please visit this link to find a community that will provide the support you want. Thank you!
Lisa
Microsoft Answers Support Engineer
Visit our Microsoft answers feedback Forum and let us know what you think. -
relationship between the active layer and enable layer
I use AE CC 12.2.1. I think that is not specific to the AE version but something general.
When I read my layer by extendscript property, it shows layer.enabled = true and layer.active = false. If I change layer.enabled from false to true, the active property seems to follow the enabled property also. I don't know the meaning of 'active', because even layer.active = false, there is no problem to manage the layer in AE.
I would like to know something.
1. How do the status layer.active to AE UI even I check it in the source of the script?
2. What is the difference between layer.active = false and true?
3. What is the relationship between the layer active and active layer?
Thanks in advance.
[Moved to After Effects - moderator script forum]
In general, a layer is activated if the eyeball is on in the timeline panel. It is active if the layer is activated and that the model currently is between the points layer and output. You can control the active state. The active state is determined by the active state, in and out of the points and the current time.
There are some exceptions (audio layers, other layers prone, etc.), but that's about all.
Dan
-
What is the difference between Facelets and JSP XML document?
Hello
When you create a new page, in the dialog box "Create a JSF Page" it is a choice called 'Type of Document' to select "Facelets" or "the JSP XML".
May be he one please tell me what is the difference between them. And what should I choose if I want to include ajax code in my page.
Thanks in advance
Facelets creates a facelets page
JSP creates a JSP page
Facelets - is default and the official display for JSF, compact JSP pages Manager has been used to view JSF pages but don't bear all component Facelets comes in picture under open source APACHE license. It supprts all components used by JSF (Java Server Faces) user interface.
Facelets has been developed by Jacob Hookom in 2005.
If you create a Facelets fragment in taskflow bounded, taskflow must be abandoned in a JSF (the parent page) page not in the .jspx (JSP XML) page.
If you try to deposit in the JSP XML page-
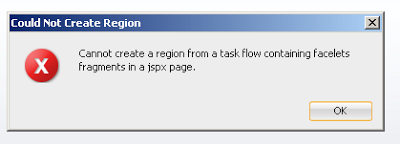
JSP, XML - jspx is Variant XML of the JSP (Java Server Pages) to support XML document. The JSP XML fragments are used in ADF inorder to support the XML document and more powerful techniques of page validation.
If you create xml jsp fragments in taskflow bounded, taskflow must be abandoned in a JSP XML (.jspx) (the parent page) page not in the JSF page.

Maybe you are looking for
-
When I disconnect from e-mail, go on yahoo news and choose an article to read, the sidebar will not go upward and downward to read the article and the timer comes on for awhile. The message "mozilla firefox does not." This happened for some time. Tha
-
4540 proBook s: it is said: "Blocked in charge", but it does not load (4540 s)
My 4540 s has recently problems with charging the battery. When I plug in, on the taskbar, it says: "Clogged, supported", however it does not load. He is not above 0%. I followed the steps here are like uninstall "Microsoft ACPI Control method batter
-
Laptop crashes! Need help please
This week my 4 year old laptop hp pavalion dv6 laptop started crashing. Then I started trying to find the problem and fix it. First, I checked my drive c on the mistakes and done a Defrag. My computer has no problems with these tasks. Secondly, I che
-
network card not working do not cause windows cannot pilot (code31)
Can't get online with my laptop
-
G8 Pavilion laptop hardware error - new hard disk?
Hello, I spoke with a representative from HP and I wanted a second opinion. Here are the facts: Possible virus causing the model to be very slow and have errors at the start up. Problems of gel even in "safe mode". Decided to do a "System Restore" us