Cluster 2 nodi + batteria Hdd-3XNSB2J (8565682699)
Seguito ad a software problem abbiamo la auswechseln uno dei 2 Nodi del Cluster, ora pero non riusciamo a farlo riconoscere dalla batteria di HDD connessa in Fibra Ottica.
Few need di UN supporto tecnico.
Grazie
Francesco Falcone - Assistenza Tecnica
the sto contattando by mail.
Tags: Dell Products
Similar Questions
-
original title: SQL Server 2008
We have SQL Server 2005 cluster (3 node cluster) and if we improve this nodes to 2008 R2, can the databases associated with the named instance remain to the version of SQL Server 2005, I seem to disagree with this notion, but still need to validation of the pro.
One way I can think of to achieve this scenario changes the compatibility level to SQL Server 2005 when the node has been upgraded to SQL Server 2008, so we can upgrade databases to SQL 2008 as and when the vendors provide support for this version.
Hello
Here is the Vista forums
Try the links below:
SQL Server forums
http://social.technet.Microsoft.com/forums/en-us/category/SQLServer/
SQL Server TechCenter
http://TechNet.Microsoft.com/en-us/SQLServer/bb265254.aspx
Blogs and Forums SQL server 2008
http://www.Microsoft.com/sqlserver/2008/en/us/forums-blogs.aspx
-
typedef red dot coercion cluster with node property value
Hello!
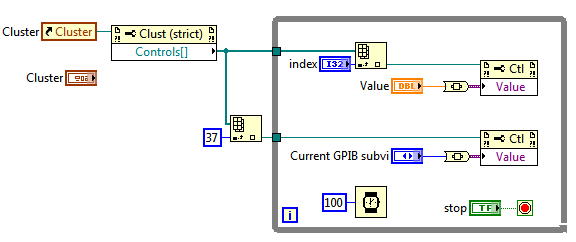
I have a project more vast, where I have parallels of DAQ and other calculations. In the project that I have spend all my relevant data between different parts of the program by using a typedef cluster control, so if I need to add the new element, it updates everywhere in my project. My problem is, when I want to update the items of this control on the graphical interface of typdef in what concerns changes in different places in my program, I use the property for this node. It works normally, but sometimes, I get a really strange behavior... sometimes the enum element not updated and so on...
I have attached a simplified version, only including the party concerned...
No idea what I did wrong?
Thank you very much!
The attached file and the picture shows a way to write about the control with nodes of property.
Run the program. You can change the "current GPIB Subvi" selection or select a control (via index) and set its value.
You can use a def enum type to select the desired control if you know that the order of the controls will not change.
Steve
-
Routing connections via a single node in a cluster 2 node RAC
Hello world
My client has the following requirement: a RAC cluster active/active (for example/node1 node2), but with only one of the nodes being used (node1) and the other sitting there just in case.
For things like services, I'm sure it's pretty simple - just have the value preferred on node1 and available on node 2.
For connections, I guess I'd just the VIP in order in the file of tns, but with LOAD_BALANCING = OFF, so they go through tns entries in the order (ie the node 1 and node 2), then this would allow even the vip failover if node 1 is out of service.
What sounds right? Did I miss something?
Thank you very much
ORSuser573914 wrote:
My client has the following requirement: a RAC cluster active/active (for example/node1 node2), but with only one of the nodes being used (node1) and the other sitting there just in case.
Why? What is the reason for a node ' + just in case + '- and how and when is "turned on" when this situation of just-in-case?
It is not much any sort of sense of sight high availability or redundancy.
For connections, I guess I'd just the VIP in order in the file of tns, but with LOAD_BALANCING = OFF, so they go through tns entries in the order (ie the node 1 and node 2), then this would allow even the vip failover if node 1 is out of service.
What sounds right? Did I miss something?
Does not work on 10g - may not work on 11g. The listener can and don't transfer connections, according to what say the TNS connect string. If you do connect not via a SID entry but through a SERVICE entrance, and this service is available on several nodes, you can't (and won't often) be connected to instantiate on only one IP address that you have used in your connection to TNS.
Basic example:
// note that this TEST-RAC alias refers to a single specific IP of a cluster, and use // SERVICE_NAME as the request /home/billy> tnsping test-rac TNS Ping Utility for Linux: Version 10.2.0.1.0 - Production on 18-JAN-2011 09:06:33 Copyright (c) 1997, 2005, Oracle. All rights reserved. Used parameter files: /usr/lib/oracle/xe/app/oracle/product/10.2.0/server/network/admin/sqlnet.ora Used TNSNAMES adapter to resolve the alias Attempting to contact (DESCRIPTION = (ADDRESS=(PROTOCOL=TCP)(HOST= 196.1.83.116)(PORT=1521)) (LOAD_BALANCE=no) (CONNECT_DATA=(SERVER=shared)(SERVICE_NAME=myservicename))) OK (50 msec) // now connecting to the cluster using this TEST-RAC TNS alias - and despite we listing a single // IP in our TNS connection, we are handed off to a different RAC node (as the service is available // on all nodes) // and this also happens despite our TNS connection explicitly requesting no load balancing /home/billy> sqlplus scott/tiger@test-rac SQL*Plus: Release 10.2.0.1.0 - Production on Tue Jan 18 09:06:38 2011 Copyright (c) 1982, 2005, Oracle. All rights reserved. Connected to: Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bit Production With the Partitioning, Real Application Clusters, Data Mining and Real Application Testing options SQL> !lsof -n -p $PPID | grep TCP sqlplus 5432 billy 8u IPv4 2199967 0t0 TCP 10.251.93.58:33220->196.1.83.127:37031 (ESTABLISHED) SQL>So we have connected to the node RAC 196.1.83.116 - and this listener we handed over to node RAC 196.1.83.127. The GR 11 2 earpiece seems to behave differently - it does not have a transfer of work (based on a quick test, I did on a RAC 11.2.0.1) in the above scenario.
This question-how do you deal with just-in-case situation? How do you get the clients to connect to node 2 when node 1 is out of service? Do you rely on the virtual IP address of the node 1 be set on node 2? It's a safe and 100% guaranteed method?
It may take a while (minutes, maybe more) for an address virtual IP switch to another node. Meanwhile, any client using this virtual IP address connection will fail. Is this acceptable?
I don't know - I don't like this concept of your customer to treat the RAC nodes as a sort of database waiting for a situation of just-in-case . I don't see any logic in this approach.
-
Why isn't the Thinkpad X100e no battery, HDD, wifi, power light?
Can anyone help?
Hello
My ThinkPad X100e (Type 3508-CTO) has the following three indicators:
- Power - solid Green around power button when the system is running
- Sleep - solid Green if standby (standby), flashes when entering or coming out of sleep
- Battery - switch between solids,-flashing slow and fast-flashing Green and solid, flashing slow and fast-flashing orange according to the load
The other lights are probably not present because of the space, power and cost reasons, but access to Microsoft Windows 7 and Lenovo connections indicate the status of the connection Wireless on the screen and you can use a program like HddLed indicator, DriveGLEAM or DKHardDrive-light to see the situation of activity for the hard drive. on the screen.
Kind regards
Aryeh Goretsky
-
Replication Failover clustering & Hyper-v on a two-node cluster
Hello
We have two identical servers. One to use as a main server, which houses two virtual machines. The other should be used as a back up in case the main server is not somehow. We planned on using a solution of third-party software to back up our virtual machines and launch them in the event of failure of the principal server. However, we discovered just gave the failover clustering in Windows Server R2 2012.
We have tried to set up a cluster 2 nodes, with our virtual machines properly replicated to the backup server. Excited by the present, we tried then to simulate failure of the primary server (by pulling on the cable network). We were a little disappointed to find that the backup server is not automatically run virtual machines. We did a survey and read than a solution of two nodes requires storage space for additional network (in addition to our two servers).
I wonder if that's okay? In other words, a two-node failover cluster requires separate network storage space. If this is not correct, can someone point me to a set of instructions to correctly configure a two-node failover cluster that will automatically launch the virtual machines on the server backup (in the case of a failure of the principal server).
Thank you
Mike Goldweber
Hello
Post your question in the TechNet Server Forums, as your question kindly is beyond the scope of these Forums.
http://social.technet.Microsoft.com/forums/WindowsServer/en-us/home?category=WindowsServer
See you soon.
-
Can I install a unordered nonclustered sql named instance on the existing cluster node
I have a two node (A node / node B) SQL 2008 R2 cluster.
I was asked to install a SQL instance not cluster on node A in the cluster.
This would be an instance named (node A/namedSQLinstance) and have his own records for the database files.
I have an ip address and a DNS entry
Is it possible to do?
Thanks :)
Hi Hoodster,The question you posted would be better suited in the TechNet Forums. Please see the link for support.Hope this information helps. -
Essbase Cluster node not get is expanding in the Regional service console
Dear all,
We use version Hyperion 11.1.2.1. I faced a new problem in Regional service console. The Essbase Cluster-1 node in the service console Regional expanding not when I tied to drilled her. For this reason, I am unable to view the applications, calculation scripts, etc. We need to run calc scripts and to add new members in the application. Any body experienced this before? Kindly guide me to solve this problem issue.
Thank you
SC
If you use the web console EAS, then make sure you are using a supported Java version, if it is supported, and then try adding the server essbase with the hostname instead of cluster.
See you soon
John
-
Cannot add the drives shared to the cluster nodes
ESX 3.5
I am trying to set up a cluster "2 nodes in a box". According to the guide of cluster (http://www.vmware.com/pdf/vi3_35/esx_3/vi3_35_25_u1_mscs.pdf), I created the shared disks (quorum & data) using:
vmkfstools .vdmk - c
The discs create successfully and I can see them at VIC, but when I add the disk to the virtual machine, it appears in the selection window.
Any ideas?
Oh! The mistake was all the time under our noses
vmkfstools - cdmk Kala
VMDK, not VDMK
---
MCSA, MCTS, VCP, VMware vExpert 2009
-
Stop and restart the cssd on all cluster nodes
Hello
Release our system to operate under linux Red Hat Enterprise Linux Server 5.3 (Tikanga) 2.6.18 - 128.1.1.el5
Our ASM is 11.1.0.7.0 block of POWER 2
Only ASM is clustered. Databases are not.
2 cluster nodes (Clusterware 11.1.0.7.0)
I have two questions:
1. we need to stop and start the cssd (crsctl stop crs, crsctl start crs) on both our 2 nodes of clusters.
In our test group, I stopped first the ASM and dbs all running on 2 nodes
Then I got arrested and restarded the cssd on the first node, and then on the second node. What is the good order or procedure?
I noticed after the cssd (crsctl stop crs) stopped the process "/ bin/sh /etc/init.d/init.cssd fatal" was always present. I waited for 30 seconds, but he was always there. Then I restarted the cssd (crsctl start crs) in any case. Why was the fatal process always there? It happened on both nodes. After you restart the cssd, I killed the "/ bin/sh /etc/init.d/init.cssd fatal" on both nodes. He was evidently reappear.
in the event that we want to restart both nodes of the cluster, should 2 - I start by disabling the crs before restart the cluster of 2 knots (crsctl disable crs), and then turn it back on after that 2 linux servers are back (crsctl enable crs)?
Thank you, manHello
So, for the closure of this thread, which is the appropriate procedure - for them stopping and restarting the cssd on the two cluster 2 node - among the two below:
1 - do a "crsctl stop Sir' and then 'crsct start crs' on the first node. Then do the same thing on the second node
2. make a "Sir crsctl stop" on both nodes. Then do 'crsct start crs' on both nodesI want to avoid is the two nodes start to restart because of the cssd.
You can run 'crsctl stop/start' at the same time on both nodes or so as you want (1 or 2), no problem.
If you start the clusterware on a first node and later the second node, just make sure that all services who were on the first node the second node have been properly resettled on the second node.
Kind regards
Levi Pereira -
Satellite Pro L500: amber flashing indicator - battery won't charge
When power charge light blinks yellow.
Battery does not charge and if the battery has been removed the laptop stops.When this problem does not occur.
In addition, when the power cord is removed, battery charge for a few moments then yellow flashing lights and load stops. When the stop, the battery charges normal and 100% charged battery gives almost 4 hours of time.
Can you please guide on the problem. Is the power supply problem? or the battery? or the card mother/material?
How to check the problem?
It seems that you already posted a similar topic topic with your laptop a few years ago.
http://forums.computers.Toshiba-Europe.com/forums/thread.jspa?threadID=63225In the first case, it seems that your battery was the troublemaker.
You are talking about charging light. I m not very well what LED it should be.
There are 5 LEDs - from left: DC IN / power / battery / HDD, ODD / Bridge Media SlotThe first DC IN indicator lights green when power is form adapter correctly provided HQ. However, if the output voltage of the AC adapter is abnormal or if power outages computers, this LED will turn off.
The second left power led lights green when the laptop is turned on. If turn you the phone mode standby, this indicator flashes orange.
The third battery indicator show the conditions of the accusation of pulp. Green indicates that the battery is fully charged, orange indicates the battery is charging and orange blinking indicates a low battery level.
Question:
Are you able to turn on the unit without the battery, but using only an adapter connected?
Usually, this should be possible even if the battery isn't inserted. -
Satellite Pro 4300. Connection battery pos request.
This laptop works EXCEPT that I had to battery pos. Connector of the PSU cables skt of entry into the connector on the control panel back power from the battery. So it does not load not etc. Still works fine on the external power supply.
Opens fully - found damage to connecting cables between the battery/HDD Board to the motherboard that I can fix it (due short direct somehow by the previous owner).
However, there is now no connection terminal + of the battery anywhere - DC melted something and not obvious where + 10.8V terminal connects to rest from the computer. In other words, the positive terminal of the battery connects not anywhere, and of course it should.
Help please?Hi Tim
I put t really know what kind of help do you expect. As you know that feeding is a very sensitive area and it should be controlled by technicians because a small mistake can cause with engraving and damaging equipment. Please don t play with him because it is very risky.
-
If I run two ASAs in cluster mode, is there a special setting that I need to do on the modules of sfr?
The pair of cluster ASAs forwards traffic to the two modules of sfr?
Documentation is very vague on the subject of sourcefire, clustering, everything he says really is to "maintain a coherent policy on the modules of sfr and do not use areas during your period.
Are there additional licenses required? IE I have control of x 2 + protect however only 1 AMP / URL license
Does this mean that only SFR modules can process the malware and URL filtering?
Any help would be greatly appreciated
Thank you
Are you running the ASAs in a pair of Active-Standby HA with module of firepower on each of them?
If so, the licensing of the modules must match each module. Otherwise, you will not be able to appply URL filtering and policy file (AMP) on one of the modules.
If the ASAs are truly in a cluster 2 nodes (not active-Standby) so it is even more important that licenses match because only by flow of traffic can take another Member as a transfer device.
Ideally simply build you a set of policies in the Management Center FireSIGHT and apply them to two modules of firepower.
-
vSPhere VM without protection in cluster HA
Hello user of VMware
I have a very strange problem with my vmware ha cluster and nfs.
vSphere is installed on two servers HP ProLiant DL380 Gen8
vCenter runs on a HP ProLiant DL160 G6.
NFS and iSCSI is already running on a HP ProLiant DL180 G8
In my data center, I have configured a cluster HA and DRS, on two cluster nodes that are mounted the iscsi and nfs data banks.
If I create or move a virtual machine for the data nfs virtual machine storage will be unprotected, but if I move the iscsi data store the virtual machine, the virtual machine will be protected.
The virtual machine could not be vSphere protected HA and HA cannot attempt to restart after a power failure.
I found many users with these problems and I tried the following:
-Disable and enable the HA option
-Delete cluster nodes, cluster of delete, create the cluster add nodes again.
-Remove the old VirtualCenter and installed a new windows with the latest version of vCenter Server
But nothing helps, does anyone have an idea?
Thank you.
If you have vswitch0 with 2 interfaces vmk. management and one for vmotion and nfs?
you have configured LACP or something similar on the physical switches? If so you must select the IP load balancing hashing type...
This is perhaps the reason why the cluster think the cluster is not high available
It could also be a known error of vmware: http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2020082
Compare the version. Maybe you are concerned.
-
Disable the single node rac 11 GR 2
Hello
We have 2 node rac 11r2 aim to test how to disable a node oracle 11 g 2?
Thank you
Hello
Still not very clear, but what I understand is -.
"We have 2 node oracle rac 11rg r2 for the objective test when running on the database of the two node 1 & 2 we must restart the node 2nd server sometimes." What happens to the databases and cluster? "
As you're running 2 bow TIE, if stop you the instance on node 2, db will still be available for access that users can connect to the instance on node 1 1. If take you down the instance and the cluster on node 2, node always 1 and 1 instance will be available to the user.
HTH
Anand
Maybe you are looking for
-
Toshiba virtual Store account Reset - 30316
Please re on my password for the store virtual pls Account no.: 30316
-
Overheating after update all in game WOW
Yesterday I updated my computer with the new windows updates. And after that, my computer seemed to have much more hot as usual (it's a laptop). Checked by Speedfan, and he says that my video card was getting to 100 + C when I was playing world of
-
I got a printer to someone, but he doesn't know where is the power cable. I looked at and it seems not to be a standard power cable, but now I'm wondering where I can find this cable. The printer is a HP Photosmart all-in-one printer (CN255B) (produc
-
Hauppauge HVR-1800 with FIOS STB, IR hardware not detected
Hauppauge HVR-1800 with FIOS STB? Controller cable IR? I have a Verizon FIOS set-top box (Motorola) and installed a Hauppauge HVR-1800. Through the installation the first time I came across the roadblock "IR hardware not detected." Large. Went out an
-
Cannot access the drive after you type the correct password for BitLocker. Access is denied.
Hi all! I really have a problem with my disc drive BitLocker encrypted. On my PC at the beginning (from 2009), with OS win7, I encrypted my external WD 500 GB MY BOOK hard drive. Unfortunately, old PC died:(et il y a un problème.) Now on my new compu