Collect table statistics take longer for large tables
Version: 11.2I noticed brings his stats (via dbms_stats.gather_table_stats) takes more time for the large tables.
As number of rows must be calculated, collection of statistics on the table a big would naturally be a little longer (running COUNT (*) SELECT internal).
But for a table not partitioned with 3 million lines, it took 12 minutes to retrieve the stats? Outside the County info and the row index what other information is collected for the table stats gather?
Size of the Table is actually important for the collection of statistics?
USER_TABLES DESC
and also
USER_IND_STATISTICS
USER_PART_COL_STATISTICS
USER_SUBPART_COL_STATISTICS
USER_TAB_COL_STATISTICS
USER_TAB_STATISTICS
USER_TAB_STATS_HISTORY
USER_USTATS
USER_TAB_HISTOGRAMS
USER_PART_HISTOGRAMS
USER_SUBPART_HISTOGRAMS
Tags: Database
Similar Questions
-
Collection of statistics takes forever after adding new index - why?
Hello everyone,
I'm on Oracle 11.2.0.2. Collection of statistics for one of my paintings takes extremely long (several hours), and I don't know why.
I'm inserting about 11,000 new records in a table with 5.3 million existing records using a INSERT INTO... SELECT...
This insert takes a little more than 3 minutes
Then I collect stats using:
DBMS_STATS.gather_table_stats ('SCOTT', 'S_RMP_EVALUATION_CSC_MESSAGE', estimate_percent = > DBMS_STATS.) AUTO_SAMPLE_SIZE);
It takes 2 hours.
If the number of records increases, the time it takes for the stats increases (8 hours after 70,000 newly inserted records)
I don't have this problem until recently, I created the I_S_RMP_EVAL_CSC_MSG_ACTIONSindex, but I do not understand why it would cause a radical change like that. Especially since the insertion of records to update the index takes only a few minutes.
I'm writing the create for the table and the index statements in the table below.
There are about 5.3 million records in the table. The table uses about 7.8 GB of space for the 'regular' table data and 37.6 GB for the LOB. Use the index:
Index Space used I_S_EVALUATION_CSC_MSG_LMID:
152 MB I_S_EVALUATION_CSC_MSG_IDLM:
144 MB PK_S_RMP_EVALUATION_CSC_MESSAG:
118 MB I_S_RMP_EVAL_CSC_MSG_ACTIONS: 5 MB CREATE TABLE "QQRCSBI0"."S_RMP_EVALUATION_CSC_MESSAGE" ( "ID" NUMBER(22,0) NOT NULL ENABLE, "XML_MESSAGE_TEXT" CLOB, "CREATION_TIME" TIMESTAMP (6), "LAST_UPDATE_TIME" TIMESTAMP (6), "NEXT_UPDATE_SYNC_TS" TIMESTAMP (6), "SW_VERSION_XML" VARCHAR2(100 BYTE), "DWH_LM_TS_UTC" DATE DEFAULT NULL NOT NULL ENABLE, CONSTRAINT "PK_S_RMP_EVALUATION_CSC_MESSAG" PRIMARY KEY ("ID") USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS NOLOGGING STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "STAGING" ENABLE ) SEGMENT CREATION IMMEDIATE PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "STAGING" LOB ("XML_MESSAGE_TEXT") STORE AS BASICFILE ( TABLESPACE "STAGING" ENABLE STORAGE IN ROW CHUNK 8192 RETENTION NOCACHE LOGGING STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) ) ; CREATE INDEX "QQRCSBI0"."I_S_EVALUATION_CSC_MSG_IDLM" ON "QQRCSBI0"."S_RMP_EVALUATION_CSC_MESSAGE" ("ID", "DWH_LM_TS_UTC") PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "STAGING" ; CREATE INDEX "QQRCSBI0"."I_S_EVALUATION_CSC_MSG_LMID" ON "QQRCSBI0"."S_RMP_EVALUATION_CSC_MESSAGE" ("DWH_LM_TS_UTC", "ID") PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS NOLOGGING STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "STAGING" ; CREATE BITMAP INDEX "QQRCSBI0"."I_S_RMP_EVAL_CSC_MSG_ACTIONS" ON "QQRCSBI0"."S_RMP_EVALUATION_CSC_MESSAGE" (DECODE(INSTR("XML_MESSAGE_TEXT",'<actions>'),0,0,1)) PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "STAGING" ;What causes this extreme long to collect statistics, and what I can do to fix that (apart from the removal of the index again)? Why collect stats lasts much longer than the update data and indexes?
Thank you...
It's a VIRTUAL column - Oracle does not store the value of the function in the table for each line, it simply records the description of the decisive function in the column definition in the data dictionary. The index takes the calculated actual value (with the identifier of the line from each value), but Oracle does not have a mechanism to watch the index when collecting column statistics. (In fact, such a mechanism could only be created for a single column still index).
Concerning
Jonathan Lewis
-
performance degrades after the collection of statistics
Oracle 11 g 2 OEL 5
We have several very large tables (40 million lines and more) and recently we gathered stats on tables and it degraded our performance. He began to do table scans complete rather than use the index. The same queries are very well in other environments. Only difference is the collection stats. Logically, the performance should be better after the collection of statistics. But it is rather poor.
I ran track 10053 on request and I see that the cardinality and the cost is medium high in the inefficient environment. A test, I have restored the old stats in the environment and it put everything back to normal - the query runs quickly again. Note that the restored stats were collected for more than a year. Should not collect us statistics regularly on very large tables?
Thank you.Hello
the stats of the default collection behavior is to determine the number of cells (i.e. a histogram is necessary or not and if yes, how accurately must be) automatically, depending on distribution and usage of the column of data in different types of predicates. This means that, in many cases collection histogram is almost a random process - once you get a histogram, the next time that you don't have, even if there is almost no change. This is (unfortunately) the normal behavior.
I could quite at the bottom of your question - the optimizer esteem seem to be all correct in the second case, it is not clear to me why the plan that is so bad (there are also some other problems, as lines of 40G supposed to be returned by one of the nested loops, or estimation of cardinality missing for another nested loop). But in any case, histograms and bind variables do not mix, so you can just solve your problem by specifying method_opt => "for columns
- size 1' to disable the histograms for this table.
Best regards
Nikolai -
Collection of statistics on partitioned and non-partitioned tables
Hi all
My DB is 11.1
I find that the collection of statistics on partitioned tables are really slow.
I used the following script:TABLE_NAME NUM_ROWS BLOCKS SAMPLE_SIZE LAST_ANALYZED PARTITIONED COMPRESSION ------------------------------ ---------- ---------- ----------- ------------- ----------- ----------- O_FCT_BP1 112123170 843140 11212317 8/30/2011 3:5 NO DISABLED LEON_123456 112096060 521984 11209606 8/30/2011 4:2 NO ENABLED O_FCT 115170000 486556 115170 8/29/2011 6:3 YES SQL> SELECT COUNT(*) FROM user_tab_subpartitions 2 WHERE table_name =O_FCT' 3 ; COUNT(*) ---------- 112
It costs 2 minutes for the first two tables to gather statistics respectively, but more than 10 minutes for the partitioned table.BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => user, tabname => O_FCT', method_opt => 'for all columns size auto', degree => 4, estimate_percent =>10, granularity => 'ALL', cascade => false); END; /
Time of collection of statistics represents a large part of the time of the whole lot.
Most of the work of the lot are at full load, which case all partitions and subpartitions will be affected and we cannot collect just specified partitions.
Does anyone have experiences on this subject? Thank you very much.
Best regards
Leon
Published by: user12064076 on August 30, 2011 01:45Hi Leon
Why don't collect you statistics to the partition level? If your data partitions will not change after a day (score range date for ex), you can simply do to the partition level
GRANULARITY-online 'SCORE' for partition level and
GRANULARITY-online 'SUBPARTITION' for subpartition levelYou collect global stats whenever you can not require.
Published by: user12035575 on August 30, 2011 01:50
-
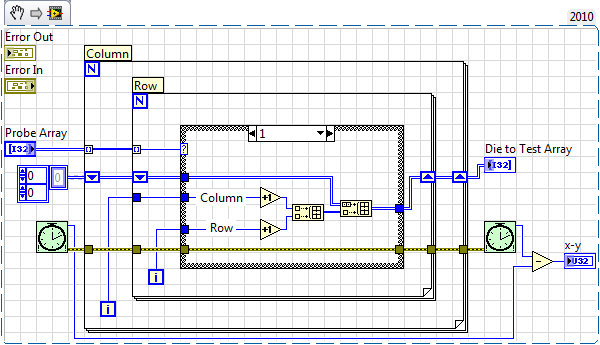
Request: Make these more fast screws for large tables
Hey everybody,
Did anyone mind take a look at these two screws? They work very well for small data sets, but they are starting to take up to 200ms each for large arrays (~ 5000 rows x 2 columns). The first actually sends data to the 2nd, so the total delay when running these screws may be 400, 500 ms. Too much to use them in real time.
Reminder of how they are used:
The user can click or click-and - dragging on a graph of intensity to create a card to die to test. These VI are run to update a list of that die are selected and a list of how the machine will move. In mode click - drag, these VI create a very big delay in the response of the public Service.
First VI:
The entrance is a 2D table 1 or 0, indicating the test or not test. The output is a 2D line (Nx2) table, column numbers should be probed.
Second VI:
The entrance is a table 2D (Nx2) R, C numbers (from the 1st VI). This VI calculates a relative movement of the current matrix with the following matrix. The output is a table 2D (Nx2) of the relative motions (Y, X). Example: ((2,4), (5.1)) back in ((0,0), (3, -3)).
I've already cut the running time up to half of what it was, but it is still not fast enough. And Yes, the limits of error are not connected, I know :-)
Screws (also attached):
So, what do you think? Is there some Subvi I don't know which completely replaces the 1st VI? Is one of the Subvi I use inherently slow?
-
collection of statistics on a remote table
Hello
Is it possible and how to collect statistics on remote tables of non-Oracle?
In my set up an Oracle Server (11g r2) is connected to an Oracle Server remote gateway to Oracle and DB2 server through ODBC gateway. All queries are distributed and heterogeneous, that is, the access data of the two remote servers. The query optimizer uses the real on remote tables from Oracle statistics, while for DB2 tables some default values are used. The difference between the default values and actual statistics is huge.
I found in a user's guide this column selectivity cannot be collected for tables non-Oracle. Is it possible to collect general statistics such as number of rows from the tables? It would be different if I use DRDA gateway to access DB2?
ConcerningRuslan,
The HS_FDS_SUPPORT_STATISTICS = TRUE parameter is supported using DG4ODBC, even if it is not documented. However, as already said it depends on the ODBC driver and the database non-Oracle to what is returned when set.
To see if it is used by the pilot, then check track of debug gateway. With the parameter set to true, then you should see explicit SQLStatistics ODBC calls. If these are not present then the parameter is to have no effect. You can also view an ODBC trace for these calls.Kind regards
Mike -
Takes too long for episodes of tv shows to download
When I buy a tv episode or a series of iTunes the length of the time it takes for that download is very long. In fact, it takes longer than the actual download episode episode. I'm doing something wrong? Surely a minite 34 episode should not take 50 minutes to download on my Ipad or iphone.
Can anyone help with this?
Generally, this indicates that you have a slow internet connection.
-
My computer takes much longer for the initial start as before?
Original title: startupmy computer takes much longer for the initial start as before?
I suggest to do the following:
(1) Windows Update and install all updates
(2) run disk clean up and defragnment
Check disk run 3)
Check 4) Add/Remove programs and uninstall programs you want
(5) run full system scan, with:
http://www.Microsoft.com/security/scanner/en-us/default.aspx
You can also take a look at:
-
Why it takes so long for the BlackBerry vendor to deal with accounts?
Why it takes so long for the BlackBerry vendor to deal with accounts?
I put in my request 3 days ago, and it has not yet been verified.
Hello
Could you please PM me your name of the seller? Do you get the email that asks you to send the document ID/commercial? If this isn't the case, please try to chcek your spam folder.
Kind regards
Satya
-
PC Windows 7 after authentication of login take longer startup time for show desktop
My PC takes longer to show desktop. It's really annoying. I want ot fast to the top of my PC. According to me, it's a starter problem or due to a lot of useless data. Below more details on my PC Configuration:------------------Information System------------------Time of this report: 06/01/2012, 21:32:21Computer name: USB - PCOperating system: Windows 7 Home Premium 32 - bit (6.1, Build 7601) Service Pack 1 (7601.win7sp1_gdr.111025) - 1505Language: English (regional setting: English)Manufacturer: Hewlett-PackardModel: HP Pavilion dv4 Notebook PCBIOS: Default system BIOSProcessor: Intel (r) Core (TM) 2 Duo CPU T6600 2.20 GHz (2 CPUs), ~2.2GHzMemory: 4096 MB RAMAvailable OS memory: 3038MB RAMPage file: 2180MB used, 10856 MB of available spaceWindows Dir: C:\WindowsDirectX version: DirectX 11DX setup parameters: not foundDPI setting: Using System DPISystem DPI setting: 96 DPI (100%)DWM DPI Scaling: disabledDxDiag Version: 6.01.7601.17514 32 bit UnicodeHi GOWTHAMU. S,
· Did you do changes on the computer before the show?
Follow these methods.
Method 1: Disconnect all external devices and try to start the computer.
Method 2: Run the troubleshooter of performance.
Open the troubleshooter of Performance
http://Windows.Microsoft.com/en-us/Windows7/open-the-performance-Troubleshooter
Method 3: Follow these steps:
Step 1: Start the computer in safe mode and check if the problem persists.
Start your computer in safe mode
http://Windows.Microsoft.com/en-us/Windows7/start-your-computer-in-safe-mode
Step 2: If the problem does not persist in safe mode, perform a clean boot to see if there is a software conflict as the clean boot helps eliminate software conflicts.
Note: After completing the steps in the clean boot troubleshooting, follow the link step 7 to return the computer to a Normal startupmode.
Method 4: Follow the steps in the article.
Optimize Windows 7 for better performance
http://Windows.Microsoft.com/en-us/Windows7/optimize-Windows-7-for-better-performance
Ways to improve your computer's performance
http://Windows.Microsoft.com/en-us/Windows7/ways-to-improve-your-computers-performance
Method 5: Update the chipset and other drivers.
Updated a hardware driver that is not working properly
http://Windows.Microsoft.com/en-us/Windows7/update-a-driver-for-hardware-that-isn ' t-work correctly
-
Help, why does take hours for my acer make 3 windows updates, when my static pc does in a few minutes.
Thanks for any help.
Help, why does take hours for my acer make 3 windows updates, when my static pc does in a few minutes.
Thanks for any help.
Without real specifications-, I venture to say that the machine is old and slow, maybe not the latest hardware device drivers installed, could have some system problems that must be resolved, etc.
-
Purge the concurrent request and/or Manager Data - take long & end with error completed
Purge the concurrent request and/or Manager Data - take long & end with error completed.
What ever the age values 30,70,1000
****
Select count (*) in the FND_CONCURRENT_PROCESSES;
COUNT (*)
-----
32149
****
Select count (*) from the FND_CONCURRENT_REQUESTS;
COUNT (*)
-----
585499
****
Request of min | Application of Max date | Date
-------------------- --------------------
SEPT. 13.-10 10 OCTOBER 13
My problem is now solved
the cause of the problem was:
After the clone for the new Production Server FND_CONCURRENT_PROCESSES & FND_CONCURRENT_REQUESTS table 'old' lines were still talking to the node that is no longer available in the new production to LOGFILE_NAME and OUTFILE_NAME columns.
And after the removal of these lines, executes the request was very quick and works as it should work now.
Thanks for all the help I get here and with the SR team too
-
Collection of statistics online
Hi all
Is it possible to collect statistics for a schema that use sound. When I try to analyse the tables to a diagram, it shows that the statistics for this table are locked. So is it possible that rather than analyze a table, one by one, I can go for gathering statistics for schema objects of this scheme while is still in use (such as DML or select statements issued on these schema objects).
DB version: 10.2.0.4
Version of the OS: RHEL 5.8
DB type: CARS
Kind regards
Imran KhanImran khan says:
Hi Mark,Why is there a question about the inability to update statistics? Someone has locked the collection of statistics.
How can we check if statistics collection has been locked? Are you talking about on the level of the db, or for a particular schema or its purpose? As far as I know in oracle 10g statistics are collected automatically (if I have a lot of m).
Kind regards
Imran KhanPublished by: imran khan on December 24, 2012 07:33
Well, as SB said, just look at the relevant information in the documentation for your version.
If you don't have local copies of the documentation for your version, you can find copies for recent versions here:
http://www.Oracle.com/technetwork/indexes/documentation/index.html
(or docs.oracle.com or tahiti.oracle.com)
I recommend you watch DBMS_STATS package and the [USER |] ALL THE | S/n] _TAB_STATISTICS view (s).
Those who should have what you need.
-
Collection of statistics with the cascade option is slow
Hi all.
The database is 11.2.0.3 on a linux machine.
I published the following command, but the session was a bit slow.
The size of the table is about 50 GB and has 3 clues.
I said 'degree = 8' for parallel processing.
When collecting statistics on the table, parallel slaves have been invoked and gather statistics on the table ended pretty quickly.
However, when he goes to the collection of statistics on indexes, only an active session was invocked and so "level = 8" option is ignored.
My question is:
Do I need to use dbms_stats.gahter_index_stats instead of the option "cascade" in order to gather statistics on indexes with parallelism?
Thanks in advance.exec dbms_stats.gather_table_stats(ownname=>'SDPSTGOUT',tabname=>'OUT_SDP_CONTACT_HIS',estimate_percent=>10, degree=>8 , method_opt=>'FOR ALL COLUMNS SIZE 1',Granularity=>'ALL',cascade=>TRUE);
Best regards.Hello
This could happen due to the index being created as NOPARALLEL. Try to redefine with DOP = 8 and see if that helps (running a quick test to verify this before making any expensive DDLS).
Best regards
Nikolai -
How long for an application appears in iTunes store?
Hello
Already had my approval of Apple and I wanted to start my app in the store.
Can choose us as the launch date for the day? Otherwise and I choose tomorrow will be time table US?
How long does take to appear in the store?
I hope that it is not "within 24 hours"... If if what did U experience? How long for your
Thank you
Minia,
usually, if you do not select a later date for the launch, your application appears in some stores within 1-4 hours.
See you soon,.
Tomek

Maybe you are looking for
-
We have FF 13.0.1 and he did strange things... as not to recognize styles. In particular, text/css generated by Dreamweaver CS3 is not displayed. Also, we find that the graphics are not repeated, even if the code is telling the browser to do so. Thes
-
After the sync of the iPod, music parts are not not on iPod
I hope I'm asking my question to the right group. If this isn't the case, I'll be happy to submit my isse by another if done to group. I recently asked CSA 1) if iTunes could support/recognize an iPod and iPad on the ITunes App even on the same comp
-
How to stop the webcam icon to appear on my screen?
I've already disabled.
-
How can I recover my hijacked user account and e-mail?
My user account has been hijacked and changed the password. I can't open an account or access my saved emails, etc..
-
Hotmail could not send your message because the server was busy. Please try again later appear guard when I try to send an email? What should do?