common components of jar, naming, best practices
11.1.2.1 forms
I added a few components of pot. For example, Directprint.jar
As they have dependencies on other common components, you must download and add in the formsweb.cfg
For example, Directprint must fontbox, pdfbox and commons-logging
This components are alive, so change their versions.
Well, now I have java in 1.6-1.8 guests, so I used it to upgrade some components of the jar.
For example from pdfbox - 1.8.6.jar to pdfbox - 1.8.11.jar
The question is: what is the best practice? The version of the name of band (rename just pdfbox.jar) so I don't have to change formsweb.cfg or preserve the name and line archive file formsweb.cfg?
If you rename the file... you have to do before everything that manifests properties adding and signing a hassle?
I guess it's a matter of taste and requirement. Personally I don't like the version numbers in the file names, because ultimately I don't like what version I am running a certain file... as long at it works. I certainly do not want to change the file name in each config file I do and do not remember to add it.
However; If you want to be able to move forward and backward between the versions I guess it's easier to have a version number in the file name. If you encounter a no - Go in the current version just swap the file name in the configuration files. Of course, if you implement version control, you can update to revision until the problem is introduced, generating the .jar file from scratch and redeployed. If you don't have version control, you can only hope that you have a backup of your file.
By simply adding a version number in the file name, you will need to update the formsweb.cfg whenever you add a new version of your jar file. By not doing this you will not have to do.
Both have their advantages and disadvantages, you will have to decide for yourself what best suits your needs.
If you rename the file... you have to do before everything that manifests properties adding and signing a hassle?
Yes. The manifest must not care about the file name, but the process of signing only.
see you soon
Tags: Oracle Development
Similar Questions
-
Best practices in the selection of the type of authentication
Hello
I use Jdeveloper 11.1.2.1. I had reviewed the security and best practices (sorry Chris!) on the selection of authentication types.
Frankly, I prefer basic HTTP authentication because it creates a popup of connection for you (simple - less coding), but I met some documents which make me wonder if this is to be avoided.
1. This tutorial uses an approach based on the forms: http://docs.oracle.com/cd/E18941_01/tutorials/jdtut_11r2_29/jdtut_11r2_29.html
2. this video of Frank Nymphius (in 42 minutes) uses Basic authentication: http://download.oracle.com/otn_hosted_doc/jdeveloper/11gdemos/AdfSecurity/AdfSecurity.html
3. fusion Developer Guide for Oracle Application Development Framework 11 g Release 2 (11.1.2.1.0) says:
The most commonly used types of authentication are authentication HTTP Basic and form authentication
It also indicates that the forms-based login page is a JSP or HTML file, [and] you will not be able to change with ADF Faces components.
4. the States of Oracle Fusion Developer Guide (Frank Nymphius) which has a side effect of basic authentication is that a user will be authenticated for all other applications that are running on the same server - you must not use it if your application requires disconnecting...
5. the manual of Jdeveloper Oracle 11 g tells that basic authentication must NOT be used at all (page 776) because it is used primarily for older browsers and is NOT secure according to current standards.
I was able to use Basic authentication, and Digest Http authentication very well, did not attempt to based on the forms for the moment.
For fun, I tried to choose the type of authentication of Client HTTPS and received this very worthy error message (and readable - wonder for java, huh?):
RFC 2068 Hypertext Transfer Protocol--HTTP / 1.1:
10.4.2 401 unauthorized
The request requires user authentication. It MUST contain a header field WWW-Authenticate (section 14.46) containing a fault that is applicable to the requested resource. The client MAY repeat the request with a suitable authorization (section 14.8) header field. If the application already includes identification of the authorization information, then the 401 response indicates that authorization was refused for those credentials. If the 401 response contains the same challenge as the previous answer, and that user agent has already attempted at least once authentication, then the user SHOULD be presented the entity that was given in the response, since that entity MAY include diagnostic information relevant. HTTP access authentication is explained in section 11
I'm sure there is one that depends on the answer to that, but I would use the most reasonable and safe type - without too much cost if possible.Hello
Basic authentication makes base64 encoding and is OK to use if the site is accessed from HTTPS. The browser actually sends authentication of users with every request, which makes this approach - if used outside of https - less than optimal. The base forms authentication is easy to implement and more record only basic authentication, it sends a name of user and password to each request. The recommendation is always use HTTPS for secure sites. Most of our samples describing the connection use https as it is a configuration that is not extended within what samples are supposed to demonstrate. For safety, "without much overhead if possible" means to weaken security. In your case, if you have tried the digest authentication so I guess that's the one with the least amount of overload
Frank
-
ADF Faces & BC: best practices for project implementation
Season greetings my fellow JDevelopers!
Our group of software works with ADF for about 5 years and over the years, we have accumulated a good amount of knowledge in collaboration with JDeveloper and ADF. A large part of our current structure of demand was resurrected in the early days of JDeveloper 10 where there are more codes samples floating around, then there was the 'best practices' documentation. I understand that this is a subjective question, and varies from one site to another, but in my view, there is a set of common practices, our group began to identify as essential to the rationalization of a development process (reusable decorated with user interface components, modular common biz logic, the development with svn, continuous integration/build team, etc...). One of our development objectives is to minimize the dependence between each engineer as everyone is responsible for the client and middle tier application without losing the consistency of coding. After speaking with a couple of the ACE to the last openworld, I understand a large part of our planned architectural requirements are filled with JDeveloper 11 (with the introduction of models, declarative elements, bordered of workflow, etc...) but lack of time on the results expected to come, we are still almost a year away before moving to this new version. Here's some of our group/application.
JDeveloper version: 10.1.3.4
Number of developers: 7
Responsibilities of the developer: build both faces & collection bc
We currently have two applications in our production environments.
1.A flavor of the dynamic module from Steve Muench jdbc connection credentials
2 core application ADF Faces & BC
In our Core ADF Faces application, we get the following structure:
OurApplication
-OurApplicationLib (common framework files)
-OurApplicationModel (project BC)
src/org/ourapp/module1
-src/org/ourapp/module 2
…
-OurApplicationView (project faces)
OurApp/public_html/module1
OurApp/public_html/module2
…
SRC/org/ourapp/support/module1
SRC/org/ourapp/support/module 2
…
SRC/org/ourapp/pageDefs /.
Total number of application Modules: 15 (including a RootApplicationModule that references the specific AMs module)
Display of number objects total: 171
Total number of entities: 58
Total number of files BC: 1734
Total number of JSP pages: 246
Total number of pageDefs: 236
Total number of cases of navigation in faces - config.xml: 127
Total number of application files: 4183
Application size total: 180megs
Are there other ways to divide this application? IE: module specific projects with distinct faces-config files/databindings? If so, how can these files be "hooked" together? A couple of aces has recommended that we must separate all files of the entity in its own project that make sense. In addition, we look at maven builds that must remove the pesky model.jpr files that gets constantly "touched". I would love to hear how other groups organize their application and anything else, they would like to share as a best practice ADF.
See you soon,.
WesAfter discussions in the summer/fall by members of the ADF methodology group, I have published a wiki page ADF Coding Standards that people may find useful:
[http://wiki.oracle.com/page/ADF+Coding+Standards]It aims to ADF 11g and is intended to be a living document - if you have any comments or suggestions please post them to the ADF methodology ([http://groups.google.com/group/adf-methodology?hl=en]) google group.
-
Java native interface: best practices?
Hi all
I'm trying to access a database with the C API from a tomcat/glassfish server by using API native Java.
I put the environment in the context of the application for all users will share the same instance of the database.
first question: is this a good idea? What would be the best practice? can I use this application in a multithreaded environment?
The problem was that the 'System.loadLibrary' method is called whenever my application is redeployed: If an exception was thrown (library already loaded), because the server has already loaded the db library in a previous deployment. To solve the problem, I put a silencer ' try... catch...» "around this System.loadLibrary in the source code of com/sleepycat/db/internal/db_javaJNI.java
2nd question: is there a way to avoid this hack?
Thank you for any response
StoneHi Pierre,.
Sorry for the delay in his response to this request.
In answer to your first question, it is to access a Berkeley DB environment handle from multiple threads in Java. No specific configuration is required.
The second question is not specific to Berkeley DB: it applies to any library JNI accessed via a class loader other than the system class loader. For example, see this thread:
http://forums.Sun.com/thread.jspa?threadID=633985
In the case of Berkeley DB, where you're unlikely to deploy a version update on the fly, the simplest solution is to make sure that the native library is loaded by the class loader running Tomcat with db.jar common/lib, and no WEB-INF/lib of your webapp.
Kind regards
Michael Cahill, Oracle Berkeley DB. -
Code/sequence TestStand sharing best practices?
I am the architect for a project that uses TestStand, Switch Executive and LabVIEW code modules to control automated on a certain number of USE that we do.
It's my first time using TestStand and I want to adopt the best practices of software allowing sharing between my other software engineers who each will be responsible to create scripts of TestStand for one of the DUT single a lot of code. I've identified some 'functions' which will be common across all UUT like connecting two points on our switching matrix and then take a measure of tension with our EMS to check if it meets the limits.
The gist of my question is which is the version of TestStand to a LabVIEW library for sequence calls?
Right now what I did is to create these sequences Commons/generic settings and placed in their own sequence called "Functions.seq" common file as a pseduo library. This "Common Functions.seq" file is never intended to be run as a script itself, rather the sequences inside are put in by another top-level sequence that is unique to one of our DUT.
Is this a good practice or is there a better way to compartmentalize the calls of common sequence?
It seems that you are doing it correctly. I always remove MainSequence out there too, it will trigger an error if they try to run it with a model. You can also access the properties of file sequence and disassociate from any model.
I always equate a sequence on a vi and a sequence for a lvlib file. In this case, a step is a node in the diagram and local variables are son.
They just need to include this library of sequence files in their construction (and all of its dependencies).
Hope this helps,
-
encoding issue "best practices."
I'm about to add several command objects to my plan, and the source code will increase accordingly. I would be interested in advice on good ways to break the code into multiple files.
I thought I had a source file (and a header file) for each command object. Does this cause problems when editing and saving the file .uir? When I run the Code-> target... file command, it seems that it changes the file target for all objects, not only that I am currently working on.
At least, I would like to have all my routines of recall in one file other than the file that contains the main(). Is it a good/bad idea / is not serious? Is there something special I need to know this?
I guess what I'm asking, what, how much freedom should I when it comes to code in locations other than what the editor of .uir seems to impose? Before I go down, I want to assure you that I'm not going to open a can of worms here.
Thank you.
I'm not so comfortable coming to "best practices", maybe because I am partially a self-taught programmer.
Nevertheless, some concepts are clear to me: you are not limited in any way in how divide you your code in separate files. Personally, I have the habit of grouping panels that are used for a consistent set of functions (e.g. all the panels for layout tests, all the panels for execution of / follow-up... testing) in a single file UIR and related reminders in a single source file, but is not a rigid rule.
I have a few common callback functions that are in a separate source file, some of them very commonly used in all of my programs are included in my own instrument driver and installed controls in code or in the editor of the IUR.
When you use the IUR Editor, you can use the Code > target file Set... feature in menu to set the source file where generated code will go. This option can be changed at any time while developing, so ideally, you could place a button on a Panel, set a routine reminder for him, set the target file and then generate the code for this control only (Ctrl + G or Code > Generate > menu control reminders function). Until you change the target file, all code generated will go to the original target file, but you can move it to another source after that time.
-
Material LV real-time Ethernet com best practices
Hello
I just started to learn the LV in real-time, and until I get a new cRIO I just played with a former PSC-2220.
Everything works, I am reading the tutorals nice about RT and deployment/running example to this target applications.
However, I don't know what is the best practice, the IP address of this device handling. For easy installation, after a device reset (and install the new RT runtimes, etc) I put just the HW to obtain the dynamic IP address of my router (DHCP). My laptop connects to the same router via wifi.
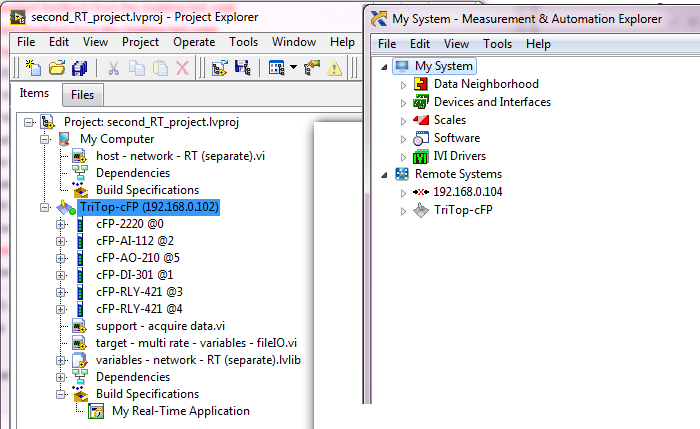
However, since after a few resets the target Gets a new IP (192.168.0.102, previous IP was... (104), I have to manually change the IP address in my project. Is it possible that the LV auto detects the target in my project? In addition, it seems that MAX retains the old information and creates a new line for the same target... so I guess that if the problem persists, MAX is going to fill?
 See screenshots below.
See screenshots below.As a solution, I'll try to use static IP for the target, so it must always use the same IP address.
What is the common procedure to avoid this kind of problems? Just using static IP? Or miss me him too something else here?
Thank you!
I just always use static IP addresses. It avoids just all kinds of questions, especially if you have several systems on the same network.
-
Best Practice Guide for stacked N3024 switches
Is there a guide to BP for the configuration of the 2 N3024s stacked for the connections to the server, or is the same eql iscsi configuration guide.
I'm trying to:
1) reduce to a single point of failure for rack.
(2) make good use of LACP for 2 and 4 nic server connections
(3) use a 5224 with it's 1 lacp-> n3024s for devices of unique connection point (ie: internet router)
TIA
Jim...
Barrett pointed out many of the common practices suggested for stacking. The best practice is to use a loop for stacking and distributing your LAG on multiple switches in the stack, are not specific to any brand or model of the switch. The steps described in the guides of the user or the white papers generally what is the recommended configuration.
http://Dell.to/20sLnncMany of the best practices scenarios will change of network-to-network based around what is currently plugged into the switch, and the independent networks needs / requirements of business. This has created a scenario where the default settings on a switch are pre-programmed for what is optimal for a fresh switch. Then recommended are described in detail in white papers for specific and not centralized scenarios in a single document of best practices that attempts to cover all scenarios.
Express.ypH N-series switches are:
-RSTP is enabled by default.
-Green eee-mode is disabled by default.
-Frother is enabled by default.
-Storm control is disabled by default.Then these things can change based on the towed gear and needs/desires of the whole of society.
For example, Equallogic has several guides that recommendations of configuration detail to different switches.
http://Dell.to/1ICQhFXThen on the side server, you would like to look more like the OS/server role. For example a whitepaper VMware that has some network settings proposed when running VMware in an iSCSI environment.
http://bit.LY/2ach2I7I suggest making a list of the technology/hardware/software, which is used on the network. Then use this list to acquire white papers for specific areas. Then use these white papers best practices in order to ensure the switch configuration is optimal for the task required by the network.
-
Best practices for the application of page multi Landscape/Portrait
Hello
I am looking for information on track to develop auto guide demand in pure actionscript with new components of qnx.fuse, but there is not a good example in real code. Every time I tried to make it resizable layout to get deformated fluid only components in portrait or landscape mode.I have a simple application with the point main and 3 displays:
public class Main extends NavigatorSprite { public function Main() { addEventListener(Event.ADDED_TO_STAGE, init); stage.nativeWindow.visible = true; stage.scaleMode = StageScaleMode.NO_SCALE; stage.align = StageAlign.TOP_LEFT; stage.nativeWindow.activate(); } private function init(e:Event):void { removeEventListener(Event.ADDED_TO_STAGE, init); navigator.pushView(View1); } } public class View1 extends ViewSprite { private var container:Container; private var button_two:LabelButton; private var button_three:LabelButton; public function View1 { addEventListener(Event.ADDED_TO_STAGE, init); } private function init(e:Event):void { removeEventListener(Event.ADDED_TO_STAGE, init); container = new Container(); var layout:RowLayout = new RowLayout(); container.layout = layout; button_two = new LabelButton(); button_two.label = "to page 2"; button_two.width = 150; button_two.height = 45; button_two.addEventListener(MouseEvent.CLICK, handleTwoClicked); container.addChild(button_two); button_three = new LabelButton(); button_three.label = "to page 3"; button_three.width = 150; button_three.height = 45; button_three.addEventListener(MouseEvent.CLICK, handleThreeClicked); container.addChild(button_three); addChild(container); } private function handleTwoClicked(e:Event):void { navigator.pushView(View2); } private function handleThreeClicked(e:Event):void { navigator.pushView(View3); } } public class View2 extends ViewSprite { private var container:Container; private var back:BackButton; public function View2 { addEventListener(Event.ADDED_TO_STAGE, init); } private function init(e:Event):void { removeEventListener(Event.ADDED_TO_STAGE, init); container = new Container(); var layout:RowLayout = new RowLayout(); container.layout = layout; back = new BackButton(); back.label = "Back"; back.width = 100; back.height = 45; back.addEventListener(MouseEvent.CLICK, goBack); container.addChild(back); addChild(container); } private function goBack(e:Event):void { navigator.popView(); } } public class View3 extends ViewSprite { private var container:Container; private var back:BackButton; public function View3 { addEventListener(Event.ADDED_TO_STAGE, init); } private function init(e:Event):void { removeEventListener(Event.ADDED_TO_STAGE, init); container = new Container(); var layout:RowLayout = new RowLayout(); container.layout = layout; back = new BackButton(); back.label = "Back"; back.width = 100; back.height = 45; back.addEventListener(MouseEvent.CLICK, goBack); container.addChild(back); addChild(container); } private function goBack(e:Event):void { navigator.popView(); } }Is there for example some best practices how to modify this code to have pages and components with the same sizes in portrait and landscape? On presentation buttons size always 150 width and height 45 and wil containers have stageWidth and stageHeight.
Thank you if someone could help with this problem
Hello
Try listening to a shift in focus screen with this code:
stage.addEventListener(Event.RESIZE, onResizeHandler, false, 0, true);
You can only change the width/height of your components to the event based on the width/height of the floor.
I will guard against specifying specific sizes, if you want your code to work on devices BB10. I recommend using %'s.
Kind regards
Dustin
-
Best practice? Storage of large data sets.
I'm programming a Client to access the customer address information. The data are delivered on a MSSQL Server by a Web service.
What is the best practice to link these data namely ListFields? String tables? Or an XML file with is analyzed?
Any ideas?
Thank you, hhessel
These debates come from time to time. The big question is how normally geet she on the phone after
someone asks why BB does not support databases. It is there no magic here - it depends on what you do with
the data. Regarding the General considerations, see j2me on sun.com or jvm issues more generally. We are all
should get a reference of material BB too LOL...
If you really have a lot of data, there are libraries of zip and I often use my own patterns of "compression".
I personally go with simple types in the store persistent and built my own b-tree indexing system
which is also j2se virtue persistable and even testable. For strings, we'll store me repeated prefixes
that only once even though I finally gave up their storage as only Aspire. So if I have hundreds of channels that start "http://www.pinkcat-REC".
I don't store this time. Before you think of overload by chaining these, who gets picked up
the indexes that you use to find the channel anyway (so of course you have to time to concatenate pieces)
back together, but the index needs particular airspace is low).
-
Best practices for the DRM version
Hi Experts,
I need a help on the sub query, any suggestions are very appreciated.
I want to know what is the best practice to keep DRM versions when I have a certain common hierarchies of upstream DRM applications.
While my flow to downstream applications are different i, various e-business.
What I have to keep these hierarchies as different versions or is it possible to manage with these hierarchies in a single version.
The reason for this request is, I need to map hierarchies of my Commons on hierarchies of two different companies located in two different versions, and if I'm not mistaken the mapping of members is not possible in two different versions.
do I have to have these common hierarchies in two different versions, that i then e for two companies different or any lead time is possible to have them in one version and match them to the members of the second version.
Hope you get my request, please return back if no confusion in my question.
Thank you
Madhabika
Hello
The best way to group related hierarchies is to put them in a group of hierarchies, Versions are mainly used to maintain the data lifecycle, or good if you have quite foreign game of hierarchies you can keep them in different versions and their life cycles maintain separately.
Inter communication Version and mappings are impossible, so if members are mapped, good thing would be to keep them in only one version.
Thank you
Denzz
-
Best practices for handling logic conditional dialogue/popup in the ADF?
Here's the scenario:
I have a page that shows a popup programmatically in a method of bean support. The popup asking the user a yes / no question and subsequent logical path is determined by their response. However, if the popup is visible or not in the first place is conditional. In addition, there is an additional logic in the original method, apart from the logic of popup, that must be met.
The problem with this is that the ADF seems to spin off the popup in another thread and prevents the execution of logic in the original method at the same time, while you wait for the response from the user. However, the desired effect is that the program stops until the user has answered the question in the context menu.
I was not able to understand in an elegant way to make this happen. Ideally, I think that the solution is to encapsulate the logic that occurs after the popup is displayed (or not shown) in the original method and call it from the popup action listener if the popup is displayed (if not call it the original method of). However, the logic should be encapsulated requires the use of some local variables that have been put forward for the popup to appear. There is no way to get these values to the popup action listener method to pass them on to the encapsulated logic (aside from the creation of global static variables in the bean, which seems to be a bad solution).
Another idea I had was to get the logic ' show/do not see the popup' workflow. However, it seems that for every single popup would make the really complicated workflow.
Is there a 'best practice' recommended to handle this situation? It must be a common problem, and it seems that I will talk all wrong.
However, the desired effect is that the program stops until the user has answered the question in the context menu.
This will not happen in any web environment, including ADF.
You will have different events for each life cycle:
1 - opening popup: popupFetchListener event
2 - Click on OK, Cancel buttons: DialogListener event
3 - Press the Esc button: popupCancelledEvent
You can share data between these events on pageFlowScope, or viewScope.
But if you use the ADF BC, you might be better to use transient attributes on the objects in view.
-
I'm looking for help to share best practices to upgrade the Site Recovery Manager (SRM), if someone can summarize the preparatory tasks?
Hello
Please check the content below, you may find useful.
Please refer to the URL: Documentation VMware Site Recovery Manager for more detailed instructions.
Important
Check that there is no cleanup operation pending on recovery plans and there is no problem of configuration for the virtual machines that protects the Site Recovery Manager.
1 all the recovery plans are in ready state.
2 the protection status of all protection groups is OK.
3 the status of the protection of all the individual virtual machines in the protection groups is OK.
4 the recovery of all groups of protection status is ready.
5. If you have configured the advanced settings in the existing installation, note settings you configured before the upgrade.
6 the vCenter local and remote server instances must be running when you upgrade the Site Recovery Manager.
7 upgrade all components Server vCenter Site Recovery Manager on a site until you upgrade vCenter Server and Site Recovery Manager on the other site.
8 download the setup of Site Recovery Manager file in a folder on the machines to be upgraded the Site Recovery Manager.
9 make sure no other facilities-\no updates windows restarts done shoud
Procedure:
1. connect to the machine on the protected site on which you have installed the Site Recovery Manager.
2. backup the database of Site Recovery Manager by using the tools that offers the database software.
3. (optional) If you upgrade of Site Recovery Manager 5.0.x, create a 64-bit DSN.
4 upgrade the instance of vCenter Site Recovery Manager server that connects to vCenter Server 5.5.
If you upgrade a vCenter Server and Site Recovery Manager 4.1.x, you upgrade the instances of vCenter Server and Site Recovery Manager server in the correct sequence until you can upgrade to Site Recovery Manager 5.5.
a upgrade vCenter Server 4.1.x to 5.0.x server.
b Update Site Recovery Manager of 4.1.x to 5.0.x.
c upgrade server vCenter Server 5.0.x to 5.5.
Please let me know if it helped you or not.
Thank you.
-
Recommendations or best practices configuration Oracle HTTP Server Oracle Webcenter 11g Portal
Hello everyone.
I'm looking for recommendations or best practices configuration Oracle HTTP Server Oracle Webcenter 11 g Portal
I appreciate if you could give me some references and/or experiences.
Thank you very much in advance.
Best regards.
Configurations may vary depends on place on your needs, in general you can see Configuration high availability for the Web - 11 g Release 1 (11.1.1) layer components
Use the configuration WebTier documents to the address above if it is sufficient for your needs.
-
Best practices for network configuration of vSphere with two subnets?
Well, then I'll set up 3 ESXi hosts connected to storage shared with two different subnets. I configured the iSCSI initiator and the iSCSI with his own default gateway - 192.168.1.1 - targets through a Cisco router and did the same with the hosts configured with its own default gateway - 192.168.2.2. I don't know if I should have a router in the middle to route traffic between two subnets since I use iSCSI ports linking and grouping of NETWORK cards. If I shouldn't use a physical router, how do I route the traffic between different subnets and use iSCSI ports binding at the same time. What are the best practices for the implementation of a network with two subnets vSphere (ESX host network: iSCSI network)? Thank you in advance.
Install the most common iSCSI would be traffic between hosts and
the storage is not being routed, because a router it could reduce performance.
If you have VLAN 10(192.168.1.0/24) iSCSI, VLAN 20 (192.168.2.0/24) ESX
MGMT and VLAN 30 (192.168.3.0/24) comments VMs and VLAN 40 (192.168.4.0/24)
vMotion a deployment scenario might be something like:
NIC1 - vSwitch 0 - active VMK (192.168.1.10) MGMT, vMotion VMK (192.168.4.10)
standby
NIC2 - vSwitch 1 - current (VLAN30) guest virtual machine port group
NIC3 - vSwitch 2 - active VMK1 (192.168.1.10) iSCSI
NIC4 - vSwitch 2 - active VMK2 (192.168.1.11) iSCSI
NIC5 - vSwitch 1 - current (VLAN30) guest virtual machine port group
NIC6 - vSwitch 0 - MGMT VMK (192.168.2.10) standby, vMotion
VMK (192.168.4.10) active
You would place you on VLAN 10 storage with an IP address of something like target
192.168.1.8 and iSCSI traffic would remain on this VLAN. The default value
gateway configured in ESXi would be the router the VLAN 20 with an ip address of
something like 192.168.2.1. I hope that scenario help set some options.
Tuesday, June 24, 2014 19:16, vctl [email protected]>
Maybe you are looking for
-
My documents are gone can anyone help please?
My computer started as usual this AM and I used it for about 1/2 hour. After sitting idle for an hour, my screen was empty, my photos generally drive like a screen saver so I thought that my monitor is dead. I rebooted to check. I have a background i
-
This message appears when I try to send a Tablet 'list '. If I am addressing all the recipients individually (expanded) sends the e-mail.
-
Improvement/Bug? -Email always starts in the "Inbox all the»
I have two email accounts set up - an IMAP and Exchange. When I start the email it shows me always all messages in my Inbox. I would like to first of all it showing my default account (Exchange, in my case). Is this possible? If so, it's a bug or I'm
-
How to connect two Dell UltraSharp U2414H 24 inch screen LED monitors daisy chain?
I just bought two Dell UltraSharp U2414H 24 inch screen LED monitors, but it is unclear how two monitors must be linked together. Cable does not seem to be provided? Can anyone help?
-
Not able to see the media server on Win 7 Home Premium 64-bit - please help
I have a smart TV which has DLNA work. I can see shared media on a mind DIFFERENT PC Win 7 Starter, Win 7 Home Premium 64 bit. They use the same home network / local, the same router. It deos not matter if I use Plex or Nero Home 4. I checked fire