concatenation of tables
Hello again. I try to combine two complete tables using JS and borrowing from a script that I found (in red). The goal is to finish by filling the variable 'bothArrays' with all 6 animals separated by commas.
1.
var firstArray = ["cat", "dog", "snake"];
var secondArray = ["frog", "cow", "eagle"];
window.cpAPIInterface.setVariableValue (bothArrays, firstArray.concat (secondArray));
Thanks to other people on this forum, I realize how a long way-
2.
var firstArray = ["cat", "dog", "snake"];
var secondArray = ["frog", "cow", "eagle"];
window.cpAPIInterface.setVariableValue ("bothArrays", firstArray [0] + ', ' + firstArray [1] + ', ' + firstArray [2] + ', ' + secondArray [0] + ', ' + secondArray [1] + ', ' + secondArray [2]);
Could someone please report the error on my first attempt shorter?
The concat() method will create a new table that contains all the elements of the two tables. This isn't what you want, at least if your second job flow results in what you expect.
var botharrays = firstArray.concat (secondArray);
This would result in:
["cat", "dog", "snake", "frog", "cow", "eagle"] as a content of the last table. But you cannot store an array in a variable of Captivate.
Tags: Adobe Captivate
Similar Questions
-
Want to combine two tables with different numbers of lines 2d
I'm out data in a file in 2d tables, then adding more as it goes, and I run into issues when the size changes.
2D arrays must be of rectangular shape, so those empty space you have it will be filled with the default value of any data type you are using. See attachment for the concatenation of tables:
-
With concatenation execution plan
Hi all
Could someone help to find out why concatenation is used by the optimizer and how I avoid it.
Oracle Version: 10.2.0.4
table of IFE.entityids were brought - partitioned on the data_provider column.select * from ( select distinct EntityType, EntityID, DateModified, DateCreated, IsDeleted from ife.EntityIDs i join (select orgid from equifaxnormalize.org_relationships where orgid is not null and related_orgid is not null and ((Date_Modified >= to_date('2011-06-12 14:00:00','yyyy-mm-dd hh24:mi:ss') and Date_Modified < to_date('2011-06-13 14:00:00','yyyy-mm-dd hh24:mi:ss')) OR (Date_Created >= to_date('2011-06-12 14:00:00','yyyy-mm-dd hh24:mi:ss') and Date_Created < to_date('2011-06-13 14:00:00','yyyy-mm-dd hh24:mi:ss')) ) ) r on(r.orgid= i.entityid) where EntityType = 1 and ((DateModified >= to_date('2011-06-12 14:00:00','yyyy-mm-dd hh24:mi:ss') and DateModified < to_date('2011-06-13 14:00:00','yyyy-mm-dd hh24:mi:ss')) OR (DateCreated >= to_date('2011-06-12 14:00:00','yyyy-mm-dd hh24:mi:ss') and DateCreated < to_date('2011-06-13 14:00:00','yyyy-mm-dd hh24:mi:ss')) ) and ( IsDeleted = 0) and IsDistributable = 1 and EntityID >= 0 order by EntityID --order by NLSSORT(EntityID,'NLS_SORT=BINARY') ) where rownum <= 10; Execution Plan ---------------------------------------------------------- Plan hash value: 227906424 ------------------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | ------------------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 10 | 570 | 39 (6)| 00:00:01 | | | |* 1 | COUNT STOPKEY | | | | | | | | | 2 | VIEW | | 56 | 3192 | 39 (6)| 00:00:01 | | | |* 3 | SORT ORDER BY STOPKEY | | 56 | 3416 | 39 (6)| 00:00:01 | | | | 4 | HASH UNIQUE | | 56 | 3416 | 38 (3)| 00:00:01 | | | | 5 | CONCATENATION | | | | | | | | |* 6 | TABLE ACCESS BY INDEX ROWID | ORG_RELATIONSHIPS | 1 | 29 | 1 (0)| 00:00:01 | | | | 7 | NESTED LOOPS | | 27 | 1647 | 17 (0)| 00:00:01 | | | | 8 | TABLE ACCESS BY GLOBAL INDEX ROWID| ENTITYIDS | 27 | 864 | 4 (0)| 00:00:01 | ROWID | ROWID | |* 9 | INDEX RANGE SCAN | UX_TYPE_MOD_DIST_DEL_ENTITYID | 27 | | 2 (0)| 00:00:01 | | | |* 10 | INDEX RANGE SCAN | IX_EFX_ORGRELATION_ORGID | 1 | | 1 (0)| 00:00:01 | | | |* 11 | TABLE ACCESS BY INDEX ROWID | ORG_RELATIONSHIPS | 1 | 29 | 1 (0)| 00:00:01 | | | | 12 | NESTED LOOPS | | 29 | 1769 | 20 (0)| 00:00:01 | | | | 13 | PARTITION RANGE ALL | | 29 | 928 | 5 (0)| 00:00:01 | 1 | 3 | |* 14 | TABLE ACCESS BY LOCAL INDEX ROWID| ENTITYIDS | 29 | 928 | 5 (0)| 00:00:01 | 1 | 3 | |* 15 | INDEX RANGE SCAN | IDX_ENTITYIDS_ETYPE_DC | 29 | | 4 (0)| 00:00:01 | 1 | 3 | |* 16 | INDEX RANGE SCAN | IX_EFX_ORGRELATION_ORGID | 1 | | 1 (0)| 00:00:01 | | | ------------------------------------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(ROWNUM<=10) 3 - filter(ROWNUM<=10) 6 - filter(("DATE_MODIFIED">=TO_DATE(' 2011-06-12 14:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "DATE_MODIFIED"<TO_DATE(' 2011-06-13 14:00:00', 'syyyy-mm-dd hh24:mi:ss') OR "DATE_CREATED">=TO_DATE(' 2011-06-12 14:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "DATE_CREATED"<TO_DATE(' 2011-06-13 14:00:00', 'syyyy-mm-dd hh24:mi:ss')) AND "RELATED_ORGID" IS NOT NULL) 9 - access("I"."ENTITYTYPE"=1 AND "I"."DATEMODIFIED">=TO_DATE(' 2011-06-12 14:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "I"."ISDISTRIBUTABLE"=1 AND "I"."ISDELETED"=0 AND "I"."ENTITYID">=0 AND "I"."DATEMODIFIED"<=TO_DATE(' 2011-06-13 14:00:00', 'syyyy-mm-dd hh24:mi:ss')) filter("I"."ISDISTRIBUTABLE"=1 AND "I"."ISDELETED"=0 AND "I"."ENTITYID">=0) 10 - access("ORGID"="I"."ENTITYID") filter("ORGID" IS NOT NULL AND "ORGID">=0) 11 - filter(("DATE_MODIFIED">=TO_DATE(' 2011-06-12 14:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "DATE_MODIFIED"<TO_DATE(' 2011-06-13 14:00:00', 'syyyy-mm-dd hh24:mi:ss') OR "DATE_CREATED">=TO_DATE(' 2011-06-12 14:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "DATE_CREATED"<TO_DATE(' 2011-06-13 14:00:00', 'syyyy-mm-dd hh24:mi:ss')) AND "RELATED_ORGID" IS NOT NULL) 14 - filter("I"."ISDISTRIBUTABLE"=1 AND "I"."ISDELETED"=0 AND (LNNVL("I"."DATEMODIFIED">=TO_DATE(' 2011-06-12 14:00:00', 'syyyy-mm-dd hh24:mi:ss')) OR LNNVL("I"."DATEMODIFIED"<=TO_DATE(' 2011-06-13 14:00:00', 'syyyy-mm-dd hh24:mi:ss'))) AND "I"."ENTITYID">=0) 15 - access("I"."ENTITYTYPE"=1 AND "I"."DATECREATED">=TO_DATE(' 2011-06-12 14:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "I"."DATECREATED"<=TO_DATE(' 2011-06-13 14:00:00', 'syyyy-mm-dd hh24:mi:ss')) 16 - access("ORGID"="I"."ENTITYID") filter("ORGID" IS NOT NULL AND "ORGID">=0)
Is there a better way to rewrite this sql OR is it possible to eliminate the concatenation?
Thank youAs general approach, see the tuning wires:
[url http://forums.oracle.com/forums/thread.jspa?threadID=863295] How to post a sql tuning request
[url http://forums.oracle.com/forums/thread.jspa?messageID=1812597] When your query takes too longThe approach is essentially, for where the estimates are more inaccurate compared to actual expenditures and can find the reasons why.
Most of the time, if the statistics are accurate and then the estimates are correct, you will have a good plan. -
CBO bug or not, or else develop do not consider the function index
SQL> create table test_fun_or as select object_id+sysdate id,object_name from 2 dba_objects; Table created. SQL> create index i_test_fun_or on test_fun_or(id,'a') nologging; //I don't know why oracle consider it as function index Index created. SQL> create index i_test_fun_or_1 on test_fun_or(object_name) nologging; Index created. SQL> set autot trace exp SQL> exec dbms_stats.gather_table_stats(user,'TEST_FUN_OR',estimate_percent=>null,method_opt=>'for all columns size 1'); PL/SQL procedure successfully completed. SQL> select * from test_fun_or where id=sysdate or object_name='aa'; Execution Plan ---------------------------------------------------------- Plan hash value: 3247456674 --------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3 | 87 | 219 (3)| 00:00:03 | |* 1 | TABLE ACCESS FULL| TEST_FUN_OR | 3 | 87 | 219 (3)| 00:00:03 | --------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("OBJECT_NAME"='aa' OR "ID"=SYSDATE@!) SQL> select /*+ use_concat */ * from test_fun_or where id=sysdate or object_name='aa'; //or expand don't use index i_test_fun_or Execution Plan ---------------------------------------------------------- Plan hash value: 3161566054 ------------------------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 3 | 87 | 224 (3)| 00:00:03 | | 1 | CONCATENATION | | | | | | |* 2 | TABLE ACCESS FULL | TEST_FUN_OR | 1 | 29 | 219 (3)| 00:00:03 | |* 3 | TABLE ACCESS BY INDEX ROWID| TEST_FUN_OR | 2 | 58 | 5 (0)| 00:00:01 | |* 4 | INDEX RANGE SCAN | I_TEST_FUN_OR_1 | 2 | | 3 (0)| 00:00:01 | ------------------------------------------------------------------------------------------------ Predicate Information (identified by operation id): --------------------------------------------------- 2 - filter("ID"=SYSDATE@!) 3 - filter(LNNVL("ID"=SYSDATE@!)) 4 - access("OBJECT_NAME"='aa') SQL> drop index i_test_fun_or; Index dropped. SQL> create index i_test_fun_or on test_fun_or(id,object_name) nologging; Index created. SQL> alter table test_fun_or modify object_name not null; Table altered. SQL> select /*+ use_concat */ * from test_fun_or where id=sysdate or object_name='aa'; Execution Plan ---------------------------------------------------------- Plan hash value: 1705821130 ------------------------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 3 | 87 | 8 (0)| 00:00:01 | | 1 | CONCATENATION | | | | | | |* 2 | INDEX RANGE SCAN | I_TEST_FUN_OR | 1 | 29 | 3 (0)| 00:00:01 | |* 3 | TABLE ACCESS BY INDEX ROWID| TEST_FUN_OR | 2 | 58 | 5 (0)| 00:00:01 | |* 4 | INDEX RANGE SCAN | I_TEST_FUN_OR_1 | 2 | | 3 (0)| 00:00:01 | ------------------------------------------------------------------------------------------------ Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("ID"=SYSDATE@!) 3 - filter(LNNVL("ID"=SYSDATE@!)) 4 - access("OBJECT_NAME"='aa')Jinyu wrote:
Thanks Jonathan, I don't have 11.2.0.2 on-site, I'll test it later, I just test it on 11.2.0.1If you see the notes of fixed a bug fixes for 11.2.0.2 Group (Doc ID:1179583.1) it's bug 8352378 "allow index GOLD-Expansion functions.
Concerning
Jonathan Lewis -
build the table by concatenating berries 2
Greetings,
I have the need to combine tables 1 d (Qty 2) to TestStand for the first time each. They both will always be the same size. I would build by concatenating.
Table 1 (String): some number 1, some number2, some Number3
Table 2 (string): string description1, description2 string, string description3
Output array: some number 1 string description1, some number 2 string description2, some Number3 string description3 (so it would be total 3 items)
Thanks in advance for any help.
Chazzzmd
Hello
You can concatenate 2 strings in TestStand using the operator ' + '.
Example:
Locals.Output = Locals.String1 + "" + Locals.String2
Concatenate individual pieces of the string into arrays of strings, an easy approach would be to use a loop structure to browse table and concatenate all of them. Please find below a sequence file simple (I created it in 2010 TestStand) it does using the "For Each" as well as "Looping" property loop structure within the parameters of the step. I hope this helps you.
-
Concatenation FDM Import Table script
Hi all
First post here, so let me know if I'm making mistakes or leaving out critical information. I'm trying to use FDM for importing a pipe delimited text file, use the mapping feature, and then export the new data to a .txt file. The problem is that the entity on the finished side dimension must be a concatenation of the fields of the entity and the division. What I tried to do is to write a script for the field of the entity on the tables import screen.
Function Div_Ent_Comb (lngCatKey, dblPerKey, strLoc, strWorkTableName)
'------------------------------------------------------------------
"Integration oracle Hyperion FDM IMPORT script:
'
"Created by: cwinslow"
"Creation date: 2014-10-09 15:34:39.
'
' Object:
'
'------------------------------------------------------------------
'Set variables '.
Dim strCombination As String
Dim strDivision As String
Dim strEntity As String
' set where the combo will go
strCombination = Trim (DW. Utilities.fParseString(strRecord, 29, 8, "|"))
"Store column 7 of 11 of a delimited file
strDivision = Trim (DW. Utilities.fParseString(strRecord, 29, 5, "|"))
"To store the column 8 of the 11 of a delimited file
strEntity = Trim (DW. Utilities.fParseString(strRecord, 29, 8, "|"))
strCombination = strDivision & strEntity
End If
End Function
Error when importing is as follows:
Error: An error occurred importing the file.
Detail: Object Variable or With block variable not set
What I want to happen is when I import the file, is for the entity column show the result of the concatenation before going through the validation part.
If you're just trying to concatenate two fields to use as a source for a mapping for the entity dimension, there is a much easier way to do this without script. In your import format to create two entries for the target dimension i.e. entity. The first line contains a reference to the field of the entity of your source (data field 8 of 29), the 2nd line will contain the reference to the field of the Division of your source (data field 5 of 29). If you do this FDM will automatically concatenate the 2 fields together for you.
-
Concatenation of the name of the table in the Insert query
Greetings,
Oracle Version - Oracle9i Enterprise Edition Release 9.2.0.6.0 - 64 bit Production
I want to write a procedure in which we give the name of the table in the Insert at runtime through cursor
But the problem isinsert into tra_temp
Select * tra_smi23 of
in statement above 23 must be dynamic like tra_smi | 23
Here is my code, but something is notKindly help
create or replace procedure ascursor c1 is
Select op_ID, operators OP_NAME where OP_NAME like '% TRA '.
and OP_ID <>9;
Start
run immediately 'truncate table tra_temp;
for rec in c1
loop
insert into tra_temp
Select * from tra_SMI | ' recomm. OP_ID';
commit;
When exit c1% notfound;
end;
Hello
Then you must change the insert statement for: run immediately ' insert into tra_temp select * from tra_SMI'| recomm. OP_ID;
Concerning
Mr. Mahir Quluzade
-
Reset table to allow the continuous addition
Hello
I am writing a program that collects the data and returns an array with each iteration of a loop For.
The berries are concatenated into a larger painting.
Then the big Board grows with each iteration of the loop For.
Now, I found that if I call my program several times without leaving LabVIEW, the new implementation adds the table again to the former.
This happens even if I specify a new file to write apparently, the table is never recovered and remains in memory even after I have stop running.
I tried "Reset Array" on the forum, but in this case I don't want to just re - initialize, I want to eliminate any value in this table.
Can someone help me with this?
I'm relatively new to LabVIEW.
Thank you very much
Nicolas
Simply right click on the left edge of the left shift register and select "create constant. Voila!
(This will automatically create a constant of the correct type, in this case an empty a 1 d array of strings)
-
subset of table truncate the end of the 2d array
The intention was to make a program that would generate asynchronous several different signals in a buffer. Then something would consume the buffer - an output daq, and signal processing. I created a dummy consumption which takes only 1% over the beginning of the buffer. Whenever the buffer is smaller than the specified size, more signal will be added at the end.
I ran into a problem where the function of the subset of the Array is truncate the end of the subset sometimes, so I disassembled the program until a congruent portion of the code exists to cause the problem. It seems to be the use of memory or related allowance. Maybe I'm doing something that I shouldn't be, but it seems like a bug in labview. In the block diagram, I have a note that shows a waveform wire that goes to a case statement. Just remove this thread causes it to work properly as seen by the consistency of the waveform on the front panel.
I'm using Labview 2014 (without SP1)
I would be grateful for any ideas.
To work around the problem, use the copy always at the moment. I'll try to engage someone R & D of LabVIEW to get the last word.
In any case, it seems unnecessary to carry all these t0 (which is always zero!) and dt (which is always the same. Constantly from waveforms to bays and back just really clutters the code. If dt would be different between the waveforms, you would have a much bigger problem
 .
.I understand that your actual code is much more complicated and what you show is just the tip of the iceberg lettuce.
Here is a general overview of execution project ideas.
- Use 'building the table' (concatenation mode) instead of "insert into array. It's cleaner.
- Use simpler and easier to read the code to find the size of the table smaller
- Only use tables. You can define once and dt for all graphs.
- Use the correct representation for buffer size controls.
- Don't place unnecessary sequence structures.
- I don't think that you really need that local variables, the terminal is written often enough (stops you extra copy of the immense tables in memory!)
- Do not know what is the structure of matter, but I left it in for now.
- Add conditionally empty bays, just wire the table via unchanged instead.
- ...

-
size of a table in an access database
Hello
I try to know the size of a table in the access database, then I would be to turn it into a string value, but I have no success.
I have attached a JPEG of my code.
in the concatenated string should appear "rapportx.png" where x represents the size of the table
You must use 'Decimal string' to convert the number to text.
Please also note that the size "Array" returns a 2D array in your case: If you have two dimensions.
Finally, and above all, to count the number of records it reveal be more efficient to use the sql count() function:
http://www.w3schools.com/SQL/sql_func_count.asp
Kind regards
Marco
-
String concatenation without loop
Hello
I have an array of strings containing numbers in engineering as format below:
5.34000E - 10
3.23245E - 1
-8.43560E - 9
I'm trying to concatenate to this array of strings to a header, which is a unique, formed string using the string concatenation function. So, I would that my output as follows:
Header line 1
Header line 2
Row header 3
5.34000E - 10
3.23245E - 1
-8.43560E - 9
However, the result is currently reads:
Header line 1
Header line 2
Row header 3
5.34000E - 103.23245E - 1 - 8.43560E - 9
I can get the desired result using a loop for, but I do not like concatenate them strings function seems to run very slowly in the loop. Is there a way I can get the desired result without using a loop for?
Thank you.
It is a real possibility that concatenate strings runs slowly in a loop For. change the statement "I find that Array Build runs slowly in a for loop" and we would get a serious discussion of fly memory. Absolutely no difference here, maybe even worse because the strings are more difficult to predict than most data types. There is perhaps not a miracle solution to make it faster, but there might be ways to ensure there are no longer than necessary. I probably just build the header as its own array of channels and build table allows to reach the two (concatenate entries of course). Writing to text file will manage an array of strings directly when the time comes.
-
concatenate the bunches to the table with enums
Hi I'm trying to concatenate three tables 1 d filled an i32 and an enum.
When I look at my table concatenated, I lose my enum information... It is 0,1,2,3,4 etc. instead of the channel names?
Does anyone have a solution for this?
Best regards
Thijs
How exactly did you 'look' table concatenated? If you use a digital indicator instead of listed, the VI will run, but you will lose the enum names.
However, if you the probe wire, and/or right click > create indicator... you should not encounter the problem, in which case the problem must be somewhere else.
-
Hello
Im trying to convert a 'table 2D channels' to a 'string '. I got a simple/effective way to do this?
My 2D array is user input in a list/table field. The output must be a string data type, which can be read using the indicator drop-down list box or a string indicator...
In other words, the entry of a table should be converted into a data type similar to an entry in a zone of control of chain... I went through some of the forums and discussions, I quite couldn't understand exactly how the conversion is made...
Thank you
Eureka says:
Im trying to convert a 'table 2D channels' to a 'string '.
I agree with crows that is not not clear at all what you want. To convert an array of strings into a single string, simply use the string concatenation.

If the string must have separators, use "table to a spreadsheet string.
-
Adds data to the binary file as concatenated array
Hello
I have a problem that can has been discussed several times, but I don't have a clear answer.
Normally I have devices that produce 2D image tables. I have send them to collection of loop with a queue and then index in the form of a 3D Board and in the end save the binary file.
It works very well. But I'm starting to struggle with problems of memory, when the number of these images exceeds more than that. 2000.
So I try to enjoy the fast SSD drive and record images in bulk (eg. 300) in binary file.
In the diagram attached, where I am simulating the camera with some files before reading. The program works well, but when I try to open the new file in the secondary schema, I see only the first 300 images (in this case).
I read on the forum, I have to adjust the number of like -1 in reading binary file and then I can read data from the cluster of tables. It is not very good for me, because I need to work with the data with Matlab and I would like to have the same format as before (for example table 3D - 320 x 240 x 4000). Is it possible to add 3D table to the existing as concatenated file?
I hope it makes sense :-)
Thank you
Honza
- Good to simulate the creation of the Image using a table of random numbers 2D! Always good to model the real problem (e/s files) without "complicating details" (manipulation of the camera).
- Good use of the producer/consumer in LT_Save. Do you know the sentinels? You only need a single queue, the queue of data, sending to a table of data for the consumer. When the producer quits (because the stop button is pushed), it places an empty array (you can just right click on the entry for the item and choose "Create Constant"). In the consumer, when you dequeue, test to see if you have an empty array. If you do, stop the loop of consumption and the output queue (since you know that the producer has already stopped and you have stopped, too).
- I'm not sure what you're trying to do in the File_Read_3D routine, but I'll tell you 'it's fake So, let's analyze the situation. Somehow, your two routines form a producer/consumer 'pair' - LT_Save 'product' a file of tables 3D (for most of 300 pages, unless it's the grand finale of data) and file_read_3D "consume" them and "do something", still somewhat ill-defined. Yes you pourrait (and perhaps should) merge these two routines in a unique "Simulator". Here's what I mean:
This is taken directly from your code. I replaced the button 'stop' queue with code of Sentinel (which I won't), and added a ' tail ', Sim file, to simulate writing these data in a file (it also use a sentinel).
Your existing code of producer puts unique 2D arrays in the queue of data. This routine their fate and "builds" up to 300 of them at a time before 'doing something with them', in your code, writing to a file, here, this simulation by writing to a queue of 3D Sim file. Let's look at the first 'easy' case, where we get all of the 300 items. The loop For ends, turning a 3D Board composed of 300 paintings 2D, we simply enqueue in our Sim file, our simulated. You may notice that there is an empty array? function (which, in this case, is never true, always False) whose value is reversed (to be always true) and connected to a conditional indexation Tunnel Terminal. The reason for this strange logic will become clear in the next paragraph.
Now consider what happens when you press the button stop then your left (not shown) producer. As we use sentries, he places an empty 2D array. Well, we dequeue it and detect it with the 'Empty table?' feature, which allows us to do three things: stop at the beginning of the loop, stop adding the empty table at the exit Tunnel of indexing using the conditional Terminal (empty array = True, Negate changes to False, then the empty table is not added to the range) , and it also cause all loop to exit. What happens when get out us the whole loop? Well, we're done with the queue of data, to set free us. We know also that we queued last 'good' data in the queue of the Sim queue, so create us a Sentinel (empty 3D table) and queue for the file to-be-developed Sim consumer loop.
Now, here is where you come from it. Write this final consumer loop. Should be pretty simple - you Dequeue, and if you don't have a table empty 3D, you do the following:
- Your table consists of Images 2D N (up to 300). In a single loop, extract you each image and do what you want to do with it (view, save to file, etc.). Note that if you write a sub - VI, called "process an Image" which takes a 2D array and done something with it, you will be "declutter" your code by "in order to hide the details.
- If you don't have you had an empty array, you simply exit the while loop and release the queue of the Sim file.
OK, now translate this file. You're offshore for a good start by writing your file with the size of the table headers, which means that if you read a file into a 3D chart, you will have a 3D Board (as you did in the consumer of the Sim file) and can perform the same treatment as above. All you have to worry is the Sentinel - how do you know when you have reached the end of the file? I'm sure you can understand this, if you do not already know...
Bob Schor
PS - you should know that the code snippet I posted is not 'properly' born both everything. I pasted in fact about 6 versions here, as I continued to find errors that I wrote the description of yourself (like forgetting the function 'No' in the conditional terminal). This illustrates the virtue of written Documentation-"slow you down", did you examine your code, and say you "Oops, I forgot to...» »
-
Rotate several tables of channels 1 d
Hello
I have a vi that eventually writes some data to a log (.txt) file. In the data that are written, there are a few tables. In a particular section, I have three arrays of strings that I try to handle it with no luck. Here is an example of what I have now, and subsequently, where I want to be:
Present:
x 1
x 2
x 3
Y1
Y2
Y3
Z1
Z2
Z3
Desire:
x 1 y1 z1
x 2 y2 z2
x 3 y3 z3
Where x, y and z represent the three tables of sepreate channels. These tables is then concatenated with other data to generate the log file. It seems that no matter what I do (build, transpose, index, etc...) I still end up with the vertical arrangement in my log file - I'm sure I'm overlokking something trivial, but it's deceiving me right now.
I cannot post my code because of security, but will provide any more detais needed. Thanks in advance.
I think you are looking to do a table build followed by a transposition.
Your build array must have 3 entries.
Feed it to X, Y and Z and you should get
x 1, x 2, x 3
Y1, y2, y3
Z1, z2, z3
Hit this result with the conversion and you should get
x 1 y1 z1
x 2 y2 z2
x 3 y3 z3
What do you use to write to the log file?
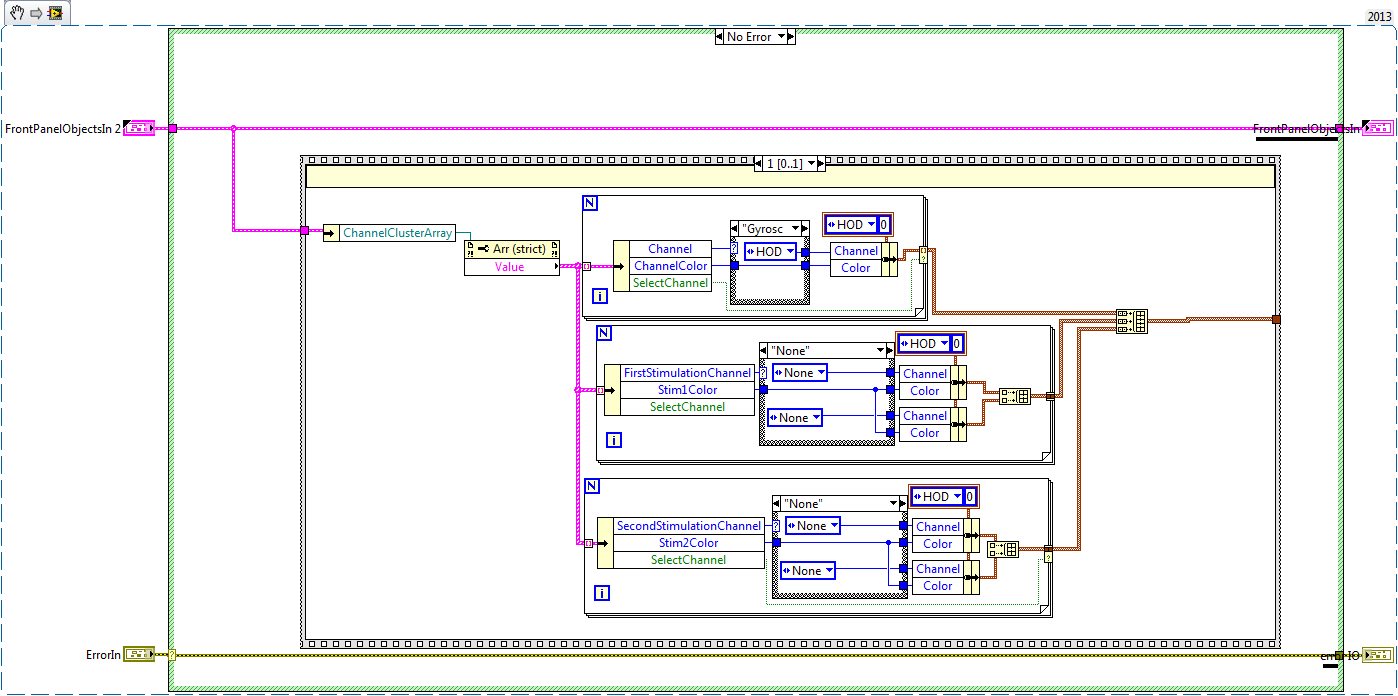
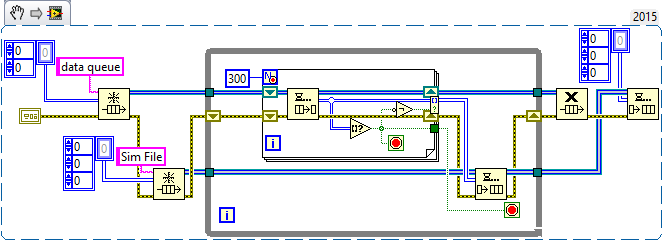
Maybe you are looking for
-
The TMZ site darkens. OK the Explorer. removed addons, hiding
When I type in the TMZ.com Web sites developed for a few minutes and then the screen goes dark. I deleted all cookies, disabled add-ons, MZ works in safe mode and added tells TMZ, an exception, and nothing does. I also have a problem with downloading
-
How I can install Fedora core 2 in my M70-159?
I try to install Fedora Core 2 in my M70-159 laptop, but I get the message that there is no HARD disk found.Can any body tell me how to install fedora. Thank you
-
When I check my battery icon it says, ' Condition: replace soon "why?
Recently my 2010 Macbook Pro battery icon when you press says "Condition: replace soon" why?
-
Stuff missing GPL for 6.4.0 released
When the Netgear will release the GPL sources for the 6.4.0 output? The page http://kb.netgear.com/app/answers/detail/a_id/2649/~/gpl-open-source-code-for-programmers does not list 6.4.0 so far.
-
1073807346 error occurred at the VISA write to rsspecan_core_write.vi
Possible reasons: VISA: (Hex 0xBFFF000E) the given reference of session or the object is not valid. I use a USB port for connection of GPIB to a Rohde Schwarz FSV30 of Windows 7 spectrum Analizer. My program works 100% in LabView, but the problem com