Concatenation of the columns with no grouped columns
Hi all
Oracle Database 11 g Enterprise Edition Release 11.2.0.3.0 - 64 bit Production
PL/SQL Release 11.2.0.3.0 - Production
CORE Production 11.2.0.3.0
AMT for Linux: Version 11.2.0.3.0 - Production
NLSRTL Version 11.2.0.3.0 - Production
I have a normal table,
Here is a simulated with data table
{code}
SELECT "P1" as c1, c2 1 OF DOUBLE UNION ALL
SELECT "P2", 1 FROM dual UNION ALL
SELECT "P3", 2 FROM dual UNION ALL
SELECT "P4", 2 DOUBLE
{code}
I need output like this:
P1 + P3
P1 + P4
P2 + P3
P2 + P4
LISTAGG tried but it didn't work.
{code}
SELECT a GROUP (COMMANDER IN c1) OVER (PARTITION BY c2) FROM LISTAGG(t.c1, '+')
(SELECT "P1" as c1, c2 1 OF DOUBLE UNION ALL
SELECT "P2", 1 FROM dual UNION ALL
SELECT "P3", 2 FROM dual UNION ALL
SELECT "P4", 2 DOUBLE) t;
{code}
How to concatenate based on non grouped column here?
ThX
Shan.
Hello
Oh! You want to generate all possible combinations of the different values of c2.
Forget LISTAGG: it generates a list of a group or partition of lines that all have something in common, for example, they all have the same value of c2.
You want just the opposite. You want a list where the items have nothing in common, that is, they all have different values of c2. CONNECTION BY can do that.
If c2 is always consecutive integers (no gap) from 1, you can do this:
SELECT LTRIM (SYS_CONNECT_BY_PATH (c1, '+'))
, '+'
) AS combination
T
WHERE CONNECT_BY_ISLEAF = 1
START WITH c2 = 1
CONNECT BY PRIOR c2 + c2 = 1
;
If c2 does not meet these requirements, you can generate c2_num this fact:
WITH got_c2_num AS
(
SELECT c1, c2
DENSE_RANK () OVER (ORDER BY c2) AS c2_num,
T
)
SELECT LTRIM (SYS_CONNECT_BY_PATH (c1, '+'))
, '+'
) AS combination
OF got_c2_num
WHERE CONNECT_BY_ISLEAF = 1
START WITH c2_num = 1
CONNECT BY c2_num = 1 + PRIOR c2_num
;
Whatever it is, you need not to know how many different values of c2 will take place.
Tags: Database
Similar Questions
-
Create the form with named group presentations
JDev ADF BC 11.1.2.1.0
Need to create a form that contains named layouts group, also the group layout content should be presented in two columns.
Suppose for example that three provisions of different group named with some components, next to hand left and right of the browser window.
Group layouts will be aligned under another provision of the group.
Hope that the requirement is clear.Put a component in the layout panelGroup panelBox. You can provide a title for the group box.
-
The list of all names of virtual machines that are attached to the computer with script group
I need a script that would list all the virtual machines names that are attached to the Machine group as the bellows screenshot:

Ce can be in any language I just need to get this information.
I tried to Watch in database and found vm names of in table [ecm_dat_machines] and Group of/ids in names of table [ecm_sysdat_machine_groups] but I don't find table that would be assign vm to the Group.
I serait appreciate any help or clue as I already spent a lot of time on this task.
Attached file of import/export includes a view created for the SQL below, as well as a SQL report that uses this perspective to the computers by group in the VCM UI.
Note that the functions used in the join of the query criteria are there to ensure that only valid/active/license machines are displayed, these date data and time are adjusted to the time zone of the user, and that the users do not see that their role does not have access to groups of computers.
SELECT
m.machine_name,
mg.machine_group_name,
mg.machine_group_desc,
DATEADD (mi, utc.utc_offset, m.date_last_contact) as date_last_contact
OF dbo.ecm_dat_machine_group_machines_xref mgx
JOIN dbo.ecm_dat_machines m
ON mgx.machine_id = m.machine_id
Join dbo.ecm_dat_machine_groups mg
ON mgx.machine_group_id = mg.machine_group_id
JOIN dbo.ecm_dat_roles_machine_group_xref rmx
ON mgx.machine_group_id = rmx.machine_group_id
AND rmx.role_id = dbo.role_current)
JOIN dbo.ecm_fn_machines_valid_t (vm)
ON mgx.machine_id = vm.machine_id
JOIN dbo.ecm_user_utc_offset (utc)
1 = 1
-
Hello
I am migrating an application from 3 APEX APEX 4.2 on a thing I noticed with the classic reports when I put them in the model 23, it's that the first section break has break notch under the headings of columns for this section of line while the remaining lines properly have it display above the headers on the subsequent sections of group.
When I look at firebug code I saw that all the tables but the first, the break line is included in the last line of the previous table, so I can see how it did not work for the holidays since.I have tow questions.
1. is it really intentional because it seems not terribly elegant and my users to zero immediately above as a perceived bug.
2. is there a reasonable job around always use headers repeat on break? I have multiple reports on the same page in places so switch to interactive reports is not a quick fix for me in this case.
Example of a question can be seen at apex.oracle.com at home
Thank you
Brad
Roadling wrote:
Hello
I am migrating an application from 3 APEX APEX 4.2 on a thing I noticed with the classic reports when I put them in the model 23, it's that the first section break has break notch under the headings of columns for this section of line while the remaining lines properly have it display above the headers on the subsequent sections of group.
1. is it really intentional because it seems not terribly elegant and my users to zero immediately above as a perceived bug.
The Standard report template definition in issue 23 contains
theadandtbodyelements:Before the column header
Column title template
#COLUMN_HEADER# After the title column
After the lines
#PAGINATION##EXTERNAL_LINK##CSV_LINK#This is intentional, the best practice for marking up HTML tables. What is not expected is the problem that arises when this model is used with the break of repeat titles on break formatting option. The repeated headings result table consisting of soup of tags containing several poorly constructed tbody and thead, which is not valid elements.
2. is there a reasonable job around always use headers repeat on break? I have multiple reports on the same page in places so switch to interactive reports is not a quick fix for me in this case.
Create a copy of the report model Standard in Standard (break formatting) for use with reports of the break, remove the
theadandtbodydefinitions of template tags and the breakdown of the reports to use the new model of change. (Or, if you use mainly break reports using the Standard template, keep the tags in the copy and remove them from the original in order to minimize the number of reports, you need to change.)Personally, I would create a report model of line custom to break complex reports in order to be able to have complete control over the structure and presentation.
-
FRM-30187: size of the column of type CHAR in the record group must be between 1 and 2000.
Hi, forms 6i, db 10g
I created a lov based on this query
select * from items_qty_vu -- database view
and the view code is
CREATE OR REPLACE FORCE VIEW items_qty_vu (serial, item_id, expiry_date, qty) AS WITH item_units_plus AS (SELECT item_id, unit_id, factor, LEAD (factor, 1, 1e99) OVER (PARTITION BY item_id ORDER BY factor) AS next_factor, ROW_NUMBER () OVER (PARTITION BY item_id ORDER BY factor DESC) AS rnk FROM item_units) SELECT ID.serial, ID.item_id, ID.expiry_date, SUBSTR (SYS_CONNECT_BY_PATH ( TRUNC ( MOD (( ID.qty - ID.qty_allocated ), iup.next_factor ) / iup.factor ) || ' ' || u.unit_name, ', ' ), 3 ) AS qty FROM item_detail ID JOIN items i ON i.item_id = ID.item_id JOIN item_units_plus iup ON iup.item_id = ID.item_id JOIN units u ON u.unit_code = iup.unit_id WHERE CONNECT_BY_ISLEAF = 1 START WITH iup.rnk = 1 CONNECT BY iup.rnk = PRIOR iup.rnk + 1 AND ID.serial = PRIOR ID.serial ORDER BY ID.serial;
When I compile the form, I face the error FRM-30187,
If I replace my query "select * from items_qty_view" with "select item_id, serial, expiry_date of items_qty_vu", it compiles successfully.
As salamualikum, Salem,.
You must follow my instructions carefully.
1. Select the record group.
2. go in the record group property
3. Select and open the column specifications
4. highlight the column and check the decrease of the length, the bellows of the size that you cross more than 2000 then 2000.
Compilation of now and you're done.
Wow. you did.
Hamid
-
How to INSERT a SELECT statement with a GROUP BY clause on a table with an IDENTITY column?
n an application, I intend to truncate and insertion on a 12 c Oracle database, but have found this problem with a
IDENTITYcolumn. Even if theINSERT... SELECTstatement works on mostSELECTuses I tried, if this statement was also aGROUP BYclause, it does not work, delivering a "ORA-00979: not aGROUP BYexpression ' complaint. Some examples of code:create table aux ( owner_name varchar2(20), pet varchar2(20) );insert into aux values ('Scott', 'dog');insert into aux values ('Mike', 'dog');insert into aux values ('Mike', 'cat');insert into aux values ('John', 'turtle');create table T1 (id number generated always as identity,owner_name varchar2(20),pet_count number );select owner_name, count(*) as pet_count from aux group by owner_name; -- works just fine
insert into T1 (owner_name, pet_count) select owner_name, count(*) as pet_count from aux group by owner_name; -- doesn't workThe select statement works by itself, but it fails as an INSERT... SELECT statement.
Appreciate the help!
Looks like a bug. You must open the SR with Oracle. Meanwhile, you could materialize select:
SQL > insert into T1 (owner_name, pet_count)
2 with t as (select / * + materialize * / owner_name, count (*) as pet_count to the owner_name group)
3. Select owner_name, pet_count t
4.3 lines were created.
SQL > select * from t1;
ID OWNER_NAME PET_COUNT
---------- -------------------- ----------
1 John 1
Scott 2 1
3 Mike 2SQL >
Keep in mind index THAT MATERIALIZE is undocumented.
SY.
-
Select only the lines with the duplicate data in columns
Hello
I try to find roles here in duplication. I created a script for me the employee, the name of the State, the title of the post, the end date and the union_id.
Select
p.emp_no,
p.Surname | «, » || p.Forenames,
p.person_status,
j.job_title,
j.end_date,
j.union_idperson p
inner join appointee_history ah on trim (ah.emp_no) = trim (p.emp_no) and ah.change_date = (select max (change_date) in the appointee_history where ah.emp_no = emp_no)
join in-house job j on trim (j.job_title) = trim (ah.job_title) and trim (j.org_unit) = trim (ah.org_unit)
where j.change_date = (select max (j2.change_date) of j2 work
where trim (j2.job_title) = trim (j.job_title) and trim (j.org_unit) = trim (j2.org_unit))and p.person_status like 'a % '.
and p.emp_no not like 9% '
and j.union_id is not null
order of j.union_idHowever, I'm looking only for duplication through the union_id. I tried a having count (*) > 1 but the emp_no is configured to be separate, and I get and not a single - group function error.
Can anyone recommend a way to do this please? I would be very grateful.
Hello
2729819 wrote:
... So the expected results.

See you soon
This is what produces the query I posted earlier, if you use the new table and the columns and (unlike me) come out MORE correctly:
WITH got_cnt AS
(
SELECT emp_no
person_status
function
union_id
COUNT AS NTC (*) OVER (PARTITION BY union_id)
SAMPLE
)
SELECT person_status, emp_no, union_id, function
OF got_cnt
WHERE cnt > 1
ORDER BY union_id
;
You can get the same results with the COUNT aggregate function, but it should be faster, because it requires only a single pass through the table.
-
Can be used with aggregate functions on large total rollup of the column
Hi all
I'm trying manipulate/aggregate on the grand total of the columns in the rollup package, can I do this? I use ROLL upward to avoid many groups nested clauses as below.
GROUP OF base.campaign, cij.avordertype, cij.invoiceaccount
)
)
Campaign of GROUP BY, invoiceaccount
) campaign group;
with
base_t as
(CHECK THE ICJ. AVBILLINGCAMPAIGN CAMPAIGN, ICJ. ORDERTYPE AVORDERTYPE,
NVL (SUM (CASE WHEN ICJ. (AVORDERTYPE = '01' THEN AVAMOUNT END CH.), 0) SUMAVAMOUNT_01,
SUM (CH. SUMAVAMOUNT_ALL AVAMOUNT),
CIJ.avordertype,
CIJ.invoiceaccount,
MIN (CIJ.invoiceid) firstinvoice_inrange,
COUNT (SEPARATE ICJ. REFFACTURE bills),
Sum (ch.avamount) invoicesamount
NVL (SUM (CASE
WHEN cij.avordertype = '01' CAN
COUNT (SEPARATE ICJ. REFFACTURE)
(END), 0)
OF CUSTINVOICEJOUR ICJ JOIN AVCOURIERHIST CH
ON substr (nls_lower (ICJ. DATAAREAID), 1, 7) = substr (nls_lower (CH. DATAAREAID), 1, 7)
AND SUBSTR (NLS_LOWER (ICJ. REFFACTURE), 1, 43) = SUBSTR (NLS_LOWER (CH. AVINVNUMBER), 1, 43)
WHERE substr (nls_lower (CH. DATAAREAID), 1, 7) = "201" AND SUBSTR (NLS_LOWER(CIJ.)) AVORDERTYPE), 1: 21) IN ('01 ', ' 09')
AND SUBSTR (NLS_LOWER (CH. AVCARGOCOMPANYID), 1: 25) = '06333675'
AND CH. AVINITIALDATE BETWEEN to_date ("'31.03.2014', ' dd.mm.yyyy") AND to_date ("'31.03.2014', ' dd.mm.yyyy")
GROUP BY ROLLUP (ICJ. AVBILLINGCAMPAIGN, ICJ. AVORDERTYPE, ICJ. INVOICEACCOUNT))
Select * from base_t;
Moreover, I can do anything with the help of ROLL UP clause instead of the bottom?
GROUP OF base.campaign, cij.avordertype, cij.invoiceaccount
)
)
Campaign of GROUP BY, invoiceaccount
) campaign group;
Concerning
Charlie
ROLLUP is used to obtain the aggregate more or less value. Here is an example
For the subtotal of wages to each level of deptno.
SQL > select deptno, empno, sum (sal)
2 of PEM
Group 3
4 by deptno, rollup (empno);DEPTNO EMPNO SUM (SAL)
---------- ---------- ----------
10 7782 12450
10-7839-5000
10 17450
20 7369 12975
20 7566 12975
20 7788 13000
20 7876 11101
20 50051
30 7499 11600
30 7521 11250
30 7654 11250
30 7698 12850
30 7844 11500
30 5845014 selected lines.
To get the subtotal of wages to each level of deptno and finally get a grand total
SQL > select deptno, empno, sum (sal)
2 of PEM
Group 3
4 by cumulative (deptno, empno);DEPTNO EMPNO SUM (SAL)
---------- ---------- ----------
10 7782 12450
10-7839-5000
10 17450
20 7369 12975
20 7566 12975
20 7788 13000
20 7876 11101
20 50051
30 7499 11600
30 7521 11250
30 7654 11250
30 7698 12850
30 7844 11500
30 58450
12595115 selected lines.
-
How can I replace the value of the column with a particular value in SQL
Hi all
Is someone can you please tell me how can I format my output with the replacement of a column value with a specific value that really depends on the current value of the column
I am executing the following SQL statement
Select state, count (id) from < table_name > where composite_dn = < composite_dn_name > Group by State;
My current performance is:
State Instance number
1 3
3 28
I want to replace the value in the State column as follows
No.OfInstances State
3 filled
28 faulted
I want '1' to be reppaced of 'Done' and '3' is replaced by 'Faulted. '
Is is possible with SQL or PL/SQL, if it is then how I can achieve this required. Help, please!
Thanks in advance!
Published by: Roshni Shankar on October 27, 2012 12:38 AMHi Claude,.
I guess this CASE clause can be simulated by a DECODE and also it is very easy to use.
See - http://www.techonthenet.com/oracle/functions/decode.phpselect decode(t1.state,t2.state_id,t2.state_name), t1.count_id fromt2, (select state,count(id) count_id from where composite_dn= group by state) t1 where t1.state = t2.state_id; HTH
Vanessa B.Published by: Vanessa B on October 27, 2012 14:02
-link addedPublished by: Vanessa B on October 27, 2012 14:19
-added code sample -
Set the line report radio group when it is clicked on a link column.
Can Hi anyone help?
I have a sql report with a group on the left radio record selector, it is used on click to fill out some additional fields in the page. I also have a column of link on the right side of the report that is used to display another page in popup. What I want is to synchronize the group radio selector when the link is clicked (i.e. Select and click on the current online radio group when the link column is selected).
Page layout
RG1 link pencil icon line details
RG2 link pencil icon line details
RG3 link pencil icon line details
additional field 1
additional field 2
Report of the attributes - link URL column.
JAVASCRIPT: modalWin2 ('f? p = & APP_ID.: #SHOW #: & SESSION.: SAVE_STATUS: no);
I guess I can call another function of javascript in the URL from the link above, and somehow, I get the number of the line of the selected link. I think that if I can get that I can use the code below, where n is the row number of the selected link.
JavaScript: -.
var l_check = $x_FormItems ($x('EVENT_HIST1'), 'radio');
checked l_check [n] = true;
var l_click is l_check [n] ravishing ();.
Thanks, PetePete:
One way to resolve your condition is as below
Modify the report query to be something similar to
select apex_item.radiogroup(40,empno,null,null,'id=rg_'||rownum) rad, ename, ' ' link_column
from emp
' link_column
from empAnd the JS function fx as
function fx(emp,rgId) { $x(rgId).checked=true; // checks radio on this row modalWin2('f?p=&APP_ID.:' + emp + ':&SESSION.::::SAVE_STATUS:N'); // popup page call }CITY
-
Why only a Yahoo Group displays the column group name?
I belong to several Yahoo groups and get individual emails from 3 of them. They all worked well until May 8, 2014, when the Freex news group began to display only "[email protected]" in the column. It's always like that. I can't be sure it's a Yahoo problem, like the other groups I am a member of display the senders display name and e-mail address.
The attachment is a snip of the CT showing how it was and how it has changed.
Please tell us how to get back to the display names and addresses.locate this address in your address book, and then delete.
-
Entries are concatenated in the same column in the excel file
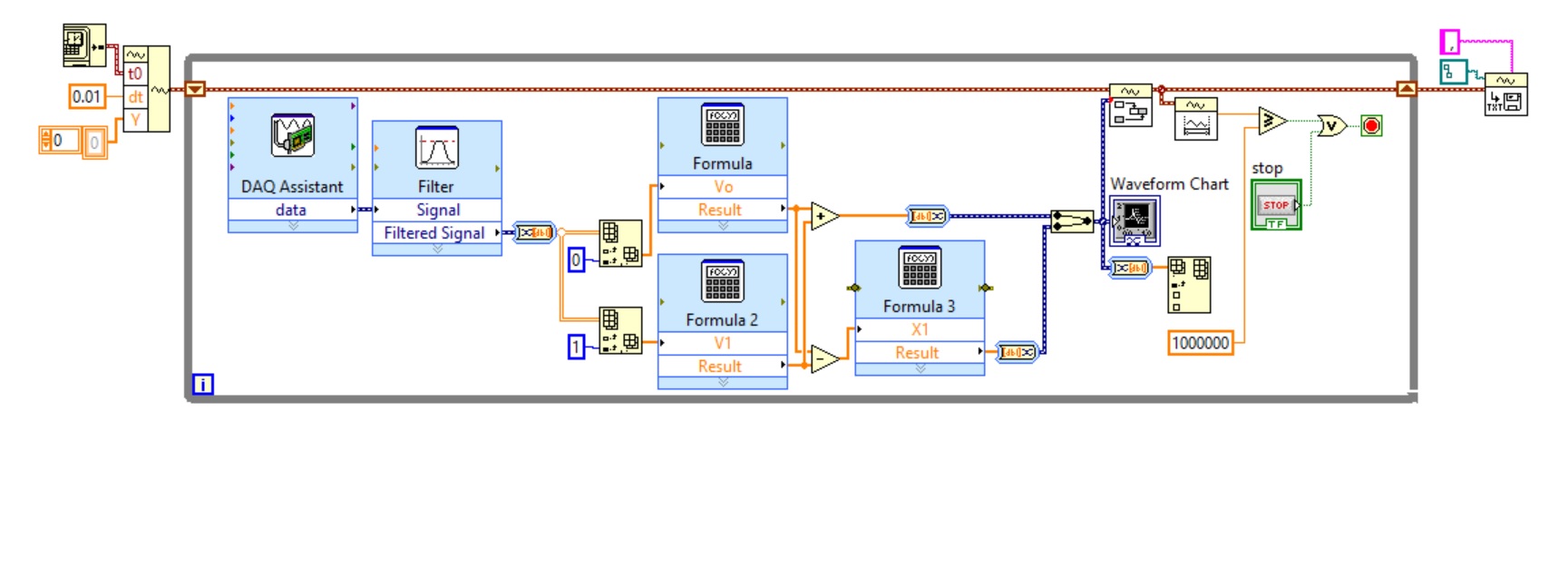
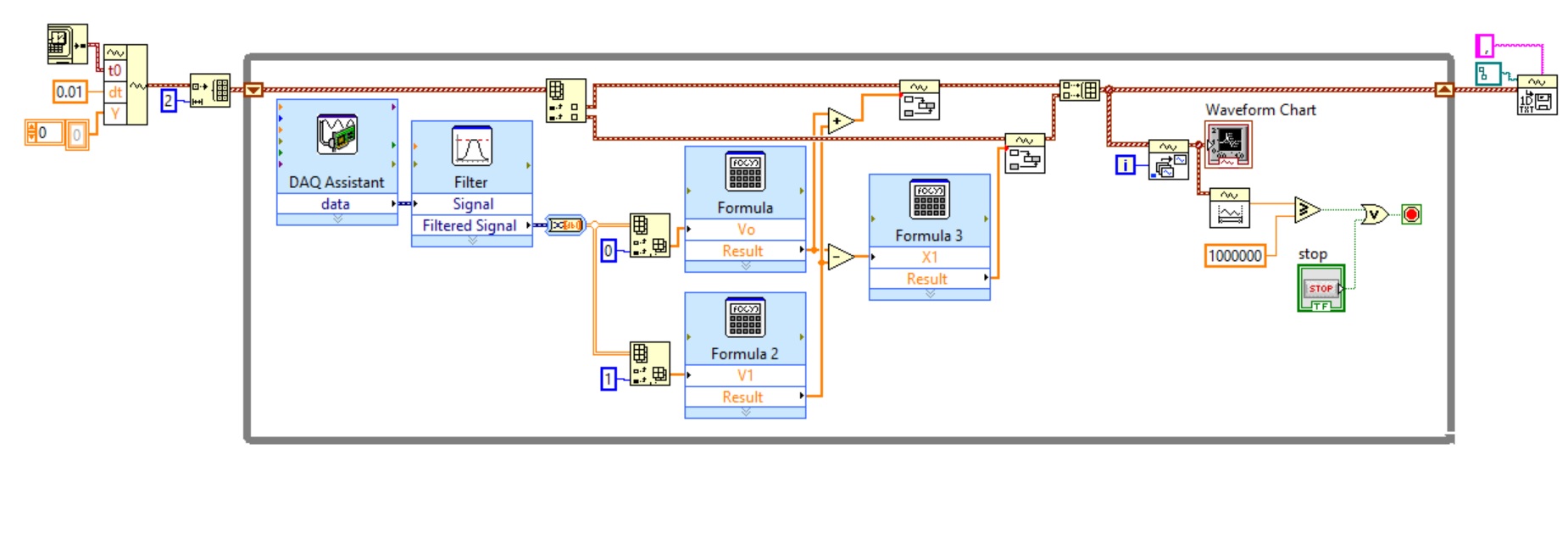
Hi, I really need help in this emergency. The problem is when I open the spreadsheet file after you run the program below, all the values that I believe are concatenated in the same column. However, there are 2 different analog inputs which I want in 2 different columns. I'm getting the 2 waveforms in the same graph, but when I open the excel file, it seems that the entries are concatenated in the same column. Someone knows how to fix this? Thank you very much.
Hi Ben 64,.
Thanks a lot again. I did as you said and I removed the dynamic data and logged files added directly to the results. I'm still checking if the program works as I can branch only when I return to work tomorrow. Tell me if you think it might be able to work this time. Thanks a lot again!
-
SQL Loader - ignore the lines with "rejected - all null columns."
Hello
Please see the attached log file. Also joined the table creation script, data file and the bad and throw the files after execution.
Sqlldr customer in the version of Windows-
SQL * Loader: release 11.2.0.1.0 - Production
The CTL file has two clauses INTO TABLE due to the nature of the data. The data presented are a subset of data in the real world file. We are only interested in the lines with the word "Index" in the first column.
The problem we need to do face is, according to paragraph INTO TABLE appears first in the corresponding CTL lines file to the WHEN CLAUSE it would insert and the rest get discarded.
1. statement of Create table : create table dummy_load (varchar2 (30) name, number, date of effdate);
2. data file to simulate this issue contains the lines below 10. Save this as name.dat. The intention is to load all of the rows in a CTL file. The actual file would have additional lines before and after these lines that can be discarded.
H15T1Y Index | 2. 19/01/2016 |
H15T2Y Index | 2. 19/01/2016 |
H15T3Y Index | 2. 19/01/2016 |
H15T5Y Index | 2. 19/01/2016 |
H15T7Y Index | 2. 19/01/2016 |
H15T10Y Index | 2. 19/01/2016 |
CPDR9AAC Index | 2. 15/01/2016 |
MOODCAVG Index | 2. 15/01/2016 |
H15TXXX Index | 2. 15/01/2016 |
H15TXXX Index | 2. 15/01/2016 |
3. the CTL file - name.ctl
DOWNLOAD THE DATA
ADD
IN THE TABLE dummy_load
WHEN (09:13) = "Index".
TRAILING NULLCOLS
(
COMPLETED name BY ' | ',.
rate TERMINATED BY ' | '.
COMPLETED effdate BY ' | '. ' TO_DATE (: effdate, "MM/DD/YYYY").
)
IN THE TABLE dummy_load
WHEN (08:12) = "Index".
TRAILING NULLCOLS
(
COMPLETED name BY ' | ',.
rate TERMINATED BY ' | '.
COMPLETED effdate BY ' | '. ' TO_DATE (: effdate, "MM/DD/YYYY").
)
invoke SQL loader in a file-> beats
C:\Oracle\product\11.2.0\client\bin\sqlldr USERID = myid/[email protected] CONTROL=C:\temp\t\name.ctl BAD=C:\temp\t\name_bad.dat LOG=C:\temp\t\name_log.dat DISCARD=C:\temp\t\name_disc.dat DATA=C:\temp\t\name.dat
Once this is run, the following text appears in the log file (excerpt):
Table DUMMY_LOAD, charged when 09:13 = 0X496e646578 ('Index' character)
Insert the option in effect for this table: APPEND
TRAILING NULLCOLS option in effect
Column Position Len term Encl. Datatype name
------------------------------ ---------- ----- ---- ---- ---------------------
NAME FIRST * | CHARACTER
RATE NEXT * | CHARACTER
EFFDATE NEXT * | CHARACTER
SQL string for the column: ' TO_DATE (: effdate, "MM/DD/YYYY").
Table DUMMY_LOAD, charged when 08:12 = 0X496e646578 ('Index' character)
Insert the option in effect for this table: APPEND
TRAILING NULLCOLS option in effect
Column Position Len term Encl. Datatype name
------------------------------ ---------- ----- ---- ---- ---------------------
NAME NEXT * | CHARACTER
RATE NEXT * | CHARACTER
EFFDATE NEXT * | CHARACTER
SQL string for the column: ' TO_DATE (: effdate, "MM/DD/YYYY").
Record 1: Ignored - all null columns.
Sheet 2: Cast - all null columns.
Record 3: Ignored - all null columns.
Record 4: Ignored - all null columns.
Sheet 5: Cast - all null columns.
Sheet 7: Discarded - failed all WHEN clauses.
Sheet 8: Discarded - failed all WHEN clauses.
File 9: Discarded - failed all WHEN clauses.
Case 10: Discarded - failed all WHEN clauses.
Table DUMMY_LOAD:
1 row loaded successfully.
0 rows not loaded due to data errors.
9 lines not loading because all WHEN clauses were failed.
0 rows not populated because all fields are null.
Table DUMMY_LOAD:
0 rows successfully loaded.
0 rows not loaded due to data errors.
5 rows not loading because all WHEN clauses were failed.
5 rows not populated because all fields are null.
The bad file is empty. The discard file has the following
H15T1Y Index | 2. 19/01/2016 |
H15T2Y Index | 2. 19/01/2016 |
H15T3Y Index | 2. 19/01/2016 |
H15T5Y Index | 2. 19/01/2016 |
H15T7Y Index | 2. 19/01/2016 |
CPDR9AAC Index | 2. 15/01/2016 |
MOODCAVG Index | 2. 15/01/2016 |
H15TXXX Index | 2. 15/01/2016 |
H15TXXX Index | 2. 15/01/2016 |
Based on the understanding of the instructions in the CTL file, ideally the first 6 rows will have been inserted into the table. Instead the table comes from the line 6' th.
NAME RATE EFFDATE H15T10Y Index 2 January 19, 2016 If the INTO TABLE clauses were put in the CTL file, then the first 5 rows are inserted and the rest are in the discard file. The line 6' th would have a ""rejected - all columns null. "in the log file. "
Could someone please take a look and advise? My apologies that the files cannot be attached.
Unless you tell it otherwise, SQL * Loader assumes that each later in the table and what clause after the first back in the position where the previous left off. If you want to start at the beginning of the line every time, then you need to reset the position using position (1) with the first column, as shown below. Position on the first using is optional.
DOWNLOAD THE DATA
ADD
IN THE TABLE dummy_load
WHEN (09:13) = "Index".
TRAILING NULLCOLS
(
name POSITION (1) TERMINATED BY ' | '.
rate TERMINATED BY ' | '.
COMPLETED effdate BY ' | '. ' TO_DATE (: effdate, "MM/DD/YYYY").
)
IN THE TABLE dummy_load
WHEN (08:12) = "Index".
TRAILING NULLCOLS
(
name POSITION (1) TERMINATED BY ' | '.
rate TERMINATED BY ' | '.
COMPLETED effdate BY ' | '. ' TO_DATE (: effdate, "MM/DD/YYYY").
)
-
Select the lines with the maximum value for a date where another column is different from 0
Hello
I need to write a query on a table (called DEPRECIATION) that returns only the rows whose date maximum (PERENDDAT_0 column) for a specific record (identified by AASREF_0), and where the other column in the table called DPRBAS_0 is different from 0.
If DPRBAS_0 is equal to 0 in all the lines of a specific record, then return the line with date maximum (PERENDDAT_0 column).
To be clearer, I give the following example:
Suppose we have the following data in the table of DEPRECIATION:
AASREF_0 PERENDDAT_0 DPRBAS_0 I20110010743 31/12/2015 0 I20110010743 31/12/2014 0 I20110010743 31/12/2013 0 I20110010856 12/31/2016 0 I20110010856 31/12/2015 0 I20110010856 31/12/2014 332 I20140012238 12/31/2016 445 I20140012238 31/12/2015 445 I20140012238 31/12/2014 0 The query must return only the following lines:
AASREF_0 PERENDDAT_0 DPRBAS_0 I20110010743 31/12/2015 0 I20110010856 31/12/2014 332 I20140012238 12/31/2016 445 Thanks a lot for your help!
This message was edited by: egk
Hello Egk,
The following query works for you.
SELECT AASREF_0, PERENDDAT_0, DPRBAS_0
FROM (SELECT AASREF_0,
PERENDDAT_0,
DPRBAS_0,
ROW_NUMBER)
DURING)
AASREF_0 PARTITION
ORDER BY
CASE WHEN DPRBAS_0 <> 0 THEN 1 OTHER 0 END DESC,.
PERENDDAT_0 DESC)
RN
DEPRECIATIONS)
WHERE rn = 1
-
update of NULL in the column with the values of the adjacent column
Examples of data
with test_data as (select 1 as one, null as two, 2 as three,5 as four, 6 as five, null as six from dual union all select 1 as one, null as two, 2 as three,5 as four, 6 as five, null as six from dual) select * from test_data;
This is one of those cases, the case may be where any value of a column can be null
or two similar columns can be null. If the column is null then I want to update the adjacent column
average value of the column, if the first column is null so I want to take the next non-null column and update, if the last column is null
so I want to take prev not zero column and to update.
In this case would be my expected output
Un Two Three Four Five Six 1 1.5 2 5 6 6 1 2 3 5 6 6 Prospects for the future the suggesion or advice.
Or, using Analytics:
SQL> with test_data (id, one, two, three, four, five, six) as ( 2 select 1, 1 , null, 2 , 5, 6, null from dual union all 3 select 2, 1 , null, 3 , 5, 6, null from dual union all 4 select 3, 1 , null, null, 5, 6, null from dual union all 5 select 4, null, null, null, 5, 6, null from dual 6 ) 7 select * 8 from ( 9 select id 10 , cell 11 , case when next_nn is not null and prev_nn is not null 12 then (next_nn + prev_nn)/2 13 else nvl(next_nn, prev_nn) 14 end val 15 from ( 16 select id 17 , cell 18 , val 19 , last_value(val) ignore nulls over(partition by id order by cell) as prev_nn 20 , first_value(val) ignore nulls over(partition by id order by cell range between current row and unbounded following) as next_nn 21 from test_data 22 unpivot include nulls (val for cell in (one as 1, two as 2, three as 3, four as 4, five as 5, six as 6) ) 23 ) 24 ) 25 pivot ( min(val) for cell in (1 as "ONE", 2 as "TWO", 3 as "THREE", 4 as "FOUR", 5 as "FIVE", 6 as "SIX") ) 26 ; ID ONE TWO THREE FOUR FIVE SIX ---------- ---------- ---------- ---------- ---------- ---------- ---------- 1 1 1,5 2 5 6 6 2 1 2 3 5 6 6 3 1 3 3 5 6 6 4 5 5 5 5 6 6


Maybe you are looking for
-
e-mail to contact apple about spyware?
This is going to be a long post im sorry but I have tried to provide as much information as possible. I have an ipod 6th generation and I managed to download something w/spyware I guess? I got a vpn on and was a downlaoder app, I learned a bunch of t
-
connect to the computer using a usb cable, not recognized by the computer
Hello the ZTE open, I already checked the "usb mode" in the settings, but the computer can not see my storage when it is connected by a usb cable, so I can't transfer any file on. Draft of microSD on the device is quite embarrassing, an idea?
-
Hardware config DAQ in System Explorer should match real material channels?
I'm filling System Explorer configuration in controller > hardware > chassis > DAQ hardware. In this case, I have a PCIe_6343 Council. Not all e/s (digital, analog meters), of the Board of Directors must be defined in the solution Veristand System Ex
-
HP Pavilion g6-1371sa cannot connect wireless Internet
Hello Just bought a new laptop for my son, but cannot make it work wireless (he connects very well with an ethernet cable). Have been well than all the assistants of troubleshooting, but with no joy. Relevant information; Network adapter updated - Ra
-
GMA shows Chinese characters after upgrade
Guys, It's real strange, I've updated the graphics driver and guess what, when I click right on the icon to the graphic media in the task bar, is Chinese. Can anyone help? Thanx.