condition of gearbox fault indicators
Hello, I was given a few files to read and perform the signal processing to estimate the 4 lights for a gear box fault status. Also asked me to perform a frequency analysis using advanced techniques. I have used labview for the first time this week and the need to understand how to go on this issue.
Will be really grateful for the help for the lights of breakdown and analysis of the frequency
It looks like not LabVIEW is limiting your factor. Nobody's even immediately LabVIEW.
Instead, understand your algorithm. Just don't you said will allow someone to help you. This means that you probably don't understand the problem.
Signals how do you read?
What defines an error condition? (In other words, how would measure you a fault? Is it a fault if it exceeds a threshold? Is it a fault if she moves too fast? Is it a fault if it does not evolve?)
Are what is your analysis of frequency you supposed to do? Is there an 'Advanced' operational need in any specific technique or is it your way of saying that you want something more than just to see what is the frequency?
Tags: NI Software
Similar Questions
-
display initial, intermediate and final conditions in an indicator
I have two indicators, one aping a multicolor LED and the other a text string. I use an event inside a while loop to monitor a push of button that triggers a response.
At the beginning of the program, I want to put an initial condition for these two indicators for example the LED is off and string "to go". »
As the program is running, the LED color changes and updates of string according to a logic.
The program is tired of running it is account to 10 and decided to stop, affecting the LED and the chain to a timeout condition.
In addition, the user can hit the stop button, in which case the LED and the chain show a stop condition.
Problem is if I put the indicators on the registers on the left, I get the correct initial condition but to an incorrect final condition. If I put the indicators on the right records, I'm getting correct finals but incorrect initial conditions. How can I get the initial AND final conditions correct?
A slap in the right direction would be much appreciated.
Use the time-out period. Using a registry to offset, you can set the time-out of the structure of the event to be 0 for the first iteration and -1 for all other iterations. Yes, then you can update your indicators on the right. In the case of the time-out period, it is just wire your straight through statutes.
-
Hi all
I am running FM12.0.2.389 on Win7-SP1 (64-bit) laptop with i7 & 16 GB of RAM.
I reported this problem as a bug in the Adobe bug base, but they were not able to reproduce the bug with the files I sent. This leads me to believe that the conflict is perhaps the result of something gone wobbly or conflicting in my system. Here's what happens:
Using 'Set expression' triggers crash FM on the next file > save, displays the error message on the imported graphic and loss of data which has been marked with conditions to exclude "NOT" in the phrase Boolean build.
Steps to reproduce using my files (zipped):
1. open Ch1_Introduction - 4FC.fm.
2. create a build expression named 3DpartnerKitConditions using this definition:
not "LIVEonly" and not 'InstallOnly' and not ('Commentary' or 'Deleted' or 'Future' or 'international' or 'PostInstall' or 'Question' or 'SDinstallOnly')
3 file > save.
4. apply the expression of the construction.
5 file > save... (crash)
Result: All conditions excluded via Boolean DO NOT tag data is not longer in the file, as seen in Ch1_Introduction - droppedText.fm.
What I THOUGHT was going to happen are that tagged data excluded via Boolean DO NOT conditions should stay in the file but hidden and can be demonstrated easily through text show/hide conditional > show all with indicators of Condition Show. Sometimes it does not crash FM and must behave this way, but 90% of the time the result is the crash and data loss.
Other things that I am looking at, I think I have a few scripts or running plugins that have been written for previous versions of FM. Yes, I'm addicted to the things of CudSpan, Bruce Foster, Silicon Prairie, FrameExpert, Sundorne and Miaramo. I noticed that (admittedly written in FM11) SafetyMIF causes crash FM at the exit, but as we use the Git repositories for incremental recording, trying to produce regularly the MIF is quite complicated the case, and record the bin file from FM bloats the referential way too technical to be happy at all.
I don't know what triggers the question of expression Boolean tag, but I really, really need to solve. I'm a solo writer (for now) with a very heavy load of docs and deadlines that can be managed by only sound sourcing methods. Thus, these files depend on variables, condition labels, shared files between different books, shared graphics and overlays of text, if any.
Someone in the community can help me find a way to identify the root cause? I plan to approach troubleshooting by first uninstalling FM, cleaning the trash to uninstall typical Windows, reinstall fresh FM, then adding the plugins one at the time and the attempt running Boolean tag setting after each plugin is added to see if I can tell which one is the trigger of the question. If it is a corrupt, obtained FM facility that would solve the problem, too. What do you think guys?
Thank you
René
Rene,
It is a healthy approach and probably the only thing, because there may be interactions between them (even though I probably have most of the same and do not see the odd-ball accident during recording).
Bruce Foster those who aren't are not compatible with FM12 (or even 11) - too old. Some of the plugins of Chris also had problems with FM11 and 12 If you don't have the correct MS 32-bit operating times installed (even on a 64-bit operating system).
-
I have a strange problem with a QML file. My first level NavigationPane has an attached SystemDialog:
attachedObjects: [ SystemDialog { id: confirmCancelDialog title: qsTr("Confirm") body: qsTr("There are unsaved changes.") confirmButton.label: qsTr("Discard and Close") cancelButton.label: qsTr("Abort... Don't Close") customButton.label: qsTr("Save... Then Close") } ]The Page just under the NavigationPane has an action of "Cancel". This code works fine:
ActionItem { title: qsTr("Cancel") ActionBar.placement: ActionBarPlacement.OnBar imageSource: "asset:///images/ic_cancel.png" onTriggered: { var result; if (settingsNavPane.dirty) { confirmCancelDialog.exec() result = confirmCancelDialog.result } else { result = 2; } if (result == 2) { // ---Force FeedDetailsEdit page to reload values next time feedDetailsEdit.feedEdit = null; scrollView.scrollToPoint(0, 0); parentSheet.close(); } else if (result == 6) { // ---Save then close saveAndClose(); } } }Even if I use two statements if() here to test if the 'result' is 2 or 6, my usual practice would be to use one instead:
ActionItem { title: qsTr("Cancel") ActionBar.placement: ActionBarPlacement.OnBar imageSource: "asset:///images/ic_cancel.png" onTriggered: { var result; if (settingsNavPane.dirty) { confirmCancelDialog.exec() result = confirmCancelDialog.result } else { result = 2; } switch(result) { case 2: // ---Force FeedDetailsEdit page to reload values next time feedDetailsEdit.feedEdit = null; scrollView.scrollToPoint(0, 0); parentSheet.close(); break; case 6: // ---Save then close saveAndClose(); break; } } }.. .but it does not work. When result == 2 switch correctly gives control to the "box 2: ' block, but the 'feedDetailsEdit.feedEdit = null;' statement never returns, and the rest of the cases never block runs, so does not close the page. Normally when I encounter a statement that behaves in this way, it is because there is a syntax error that is not taken at the time of the design, as an unitialized variable or object, for example, but in this case the exact same block of code works fine when in an if-else block, but not in a switch case block.
The code also works very well if I'm hard on the conditions surrounding the fault block completely:
ActionItem { title: qsTr("Cancel") ActionBar.placement: ActionBarPlacement.OnBar imageSource: "asset:///images/ic_cancel.png" onTriggered: { var result; if (settingsNavPane.dirty) { confirmCancelDialog.exec() result = confirmCancelDialog.result } else { result = 2; } // ---Force FeedDetailsEdit page to reload values next time feedDetailsEdit.feedEdit = null; scrollView.scrollToPoint(0, 0); parentSheet.close(); } }25 years of professional business development experience with many languages such as C/C++ and JavaScript, but this one I left me speechless. Why the variation that does not work?
Maybe it's this bug in Qt, which cannot have been fixed yet? https://bugreports.Qt-project.org/browse/QTBUG-17012
(If this is the case, apparently adding braces around the code in each case individual would work around the issue. Maybe try it.)
-
Conditional tag indicators are visible in the generated output.
W7, FM 13.0.1.385
Hi, as above really: when I print to pdf, indicators of conditional tag print the pdf file.
Any ideas?
You must disable them before printing. IIRC, uncheck the option 'Show Condition indicators' in the conditional window. I think you can do it at the level of the pound on all files at the same time.
-
Satellite L50 - B - 1 M 9 - indicators not lighted
Hey guys,.
Unfortunately, my first post is a small problem.
I bought a brand new Satellite L50 - B - 1 M 9, everything works well except my indicators for Wi - fi and battery. I am talking about the small LED lamps on the front right-hand side of the laptop. I use Win8 64 bit and so much worse if wi - fi is on / off battery uses DC or not these two indicators remain lit all the time.Can you help me with this one?
Greetings from Varna in Bulgaria!
Hello
This strange s that the two indicators should operate as follows.
WiFi/BT indicator should amber lights when the BT or WLan is enabled.DC IN / battery indicator shows the condition on the DC-IN and charge the battery. White color indicates that the battery is fully charged, so that feeding properly.
The LED would change to amber if the battery is partially charged or it s not charged.Anyway, if there is no feature of LED sign, I guess there must be a problem with the hardware of LED. I think it would be a good idea to check the unit by the authorized service provider.
-
e9180f fires on ARC fault breakers
My new office of e9180f (POS) causes my AFCI rooms to fire every other time it is started. I tried the following to work around the problem, but nothing seems to solve the problem:
1 start the computer from GFCI protected outlets - doesn't do not have problems with any protected circuit breaker out trigger. Not a reasonable solution since I need the computer in the room, it is currently configured.
2. start the other AFCI protected taken computer - triggered AFCI breaker second leading me to think that there is a problem with the computer.
3. start the computer from the inverter - makes absolutely no difference... Thank you HP support for telling me to spend $150 on a piece of hardware that I didn't need.
Through my UPS (that does not need) I know that my computer takes a 250W maximum. Since my computer now runs on a perfectly conditioned 120V, I can easily say that my point 2 (any) amp draw comes far close overloading the AFCI 15 amp breakers.
My questions: what other troubleshooting steps should I take? Is it likely that my computer is causeing a failure of the bow that fires the AFCI that prevents my house burning (i.e. What on ARC fault breakers are designed to prevent)? Are there opportunities that the HP support will recognize that their company might sell defective products and they need to be more tolerant to angry customers like me ask a little question help?
Thank you
Teal'c
SOLVED.
I replaced power supply Delta HP installed in my brand-new HPE-180 t with a Corsair TDX650W memory and the problem seems to have disappeared. I didn't no AFCI breaker. If it happens again I re-post.
The powersupply Delta 460W HP HPE-180 t stock was causing my AFCI fires about 50% if the time. I have add a Seagate 1 TB hard drive for the system which I suspect caused the HP / Delta power on default of arc more frequently when starting up the load sent the power supply out of the frequency range of 50-60 hz.
Being a loyal customer of HP, I actually bought 2 HPE-180 t in January 2010 and one for me and one for my son. My son is running his on a circuit which is not on fault of ARC and had no problems so far.
Have a great day!
-
NEITHER 9233 Microphone conditioning of signals
Following an update of LabVIEW 2009 Pre - polarised FAT microphones work correctly with 9233 modules OR multifunction data acquisition. (They have been used regularly since 2007).
There is an important distortion of the signal calibrated showing the cutout of the positive part of the trace to higher levels of entry.
Connection from one system to the external packaging of signals MIC shows perfect sinusoid using the same (FAT 40AE) microphone capsule, (BOLD 26CF) amplifier, cable and NI 9233 - we have 2 examples of each element.
The only element that seems common to the fault is the conditioned signal of the NI 9233 following the update of LabVIEW 8.6 in 2009. I tried to change the level of excitement from 2mA to 4 and 8 with no benefit (specification of FAT said 4mA nominal 2-20 MA). I noticed that there are a few changes in the terminal configuration option dialog, but after trying to change this, it is the only viable option "nickname".
The determination of sources of external power and excitement for the microphone is not an option for practical reasons, but it does not restore the original function.
Is there a change documented 9233 with LabVIEW 2009 service or is there a simple solution to this change in behavior?
Thank you.
The interests of other users, it seems that the microphone needs a little more excitement to 114dB, where cut when it is used with the 9233 which can only provide 2mA. The installer works fine at 94dB, where 2mA is enough excitement. There are no errors appearing in the software, since it is a hardware limitation.
Kind regards
Michael S.
Technical sales engineer
NEITHER UK & Ireland -
Update of the indicators of the façade is trolling in the test of the functions in the provider DLL
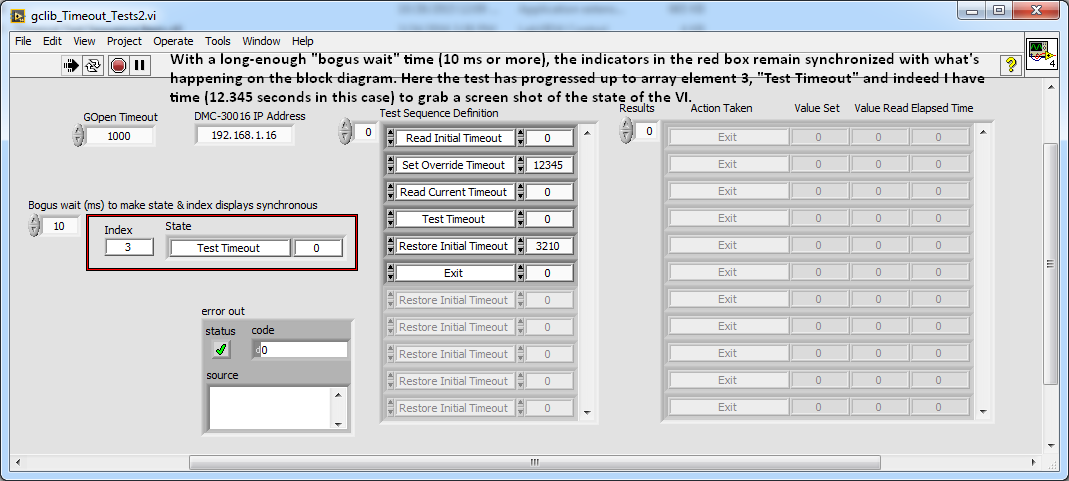
I'm looking to see if someone can explain a behavior to display weird LabVIEW I see when to test some timeout works in a third party DLL. I have a work around in place but I would still like to know why, without the workaround, the information displayed by the indicators on the front panel are not synchronized with what is happening in the execution of the VI, even though I tried all sorts of things to impose the synchronization. Note that to run the VI in a useful way, you need to be able to communicate with a Galil axes via an Ethernet controller, and which, for the most part, limited this discussion to what the experts among you know happen under the hood of LabVIEW in situations like this.
This is what looks like the VI when my work around (false wait added) is active. It's a small state machine that uses the elements of the array "Test Sequence" to tell him what to do in each step of its implementation. Here he plays a first time-out value, sets a new value of timeout, reading again, the timeout by asking a READING of the controller (without having first asked to say anything), followed by restoring the initial time-out and then tests to stop. The two indicators in the red rectangle are there to show the current status of the execution, and it is this pair of indicators which are not synchronized with the State of the actual program.
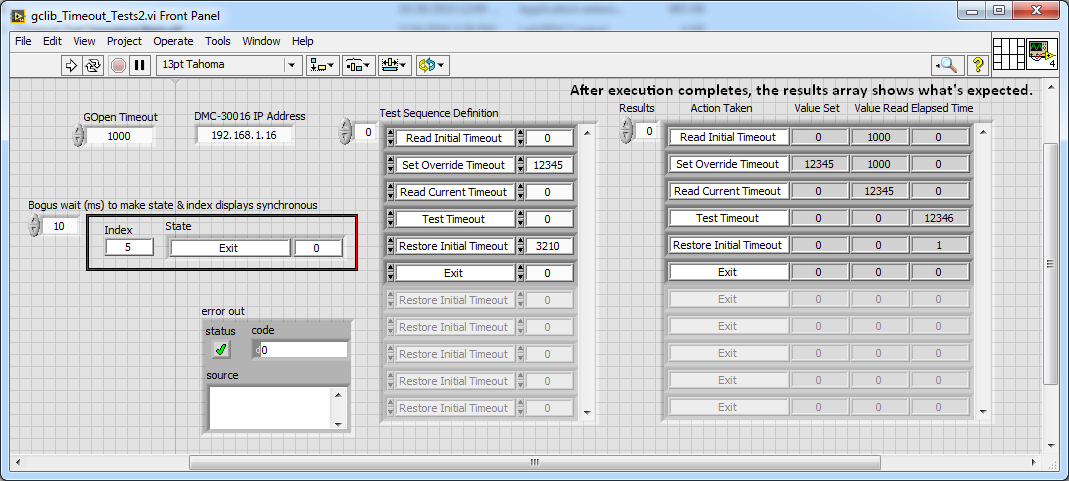
When execution completes, it is what we see.
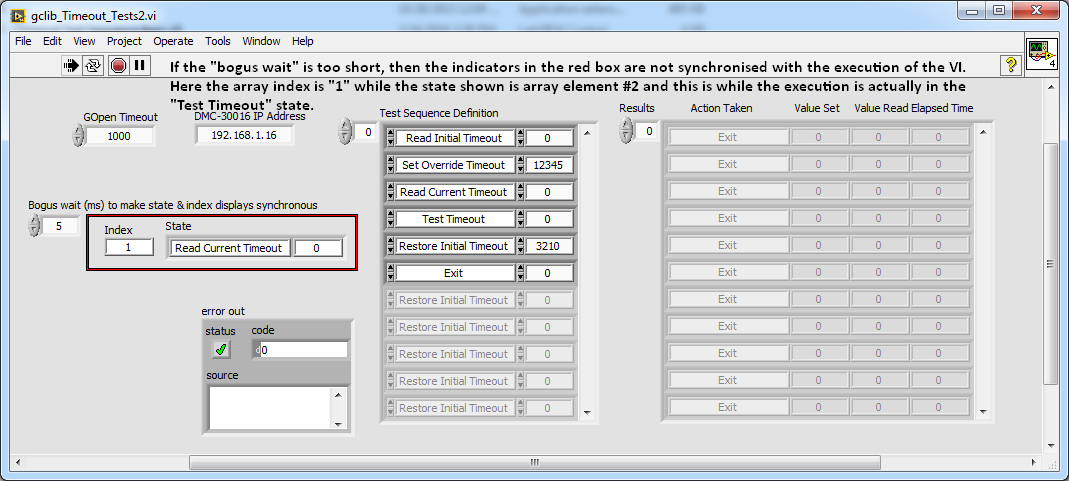
If the false timeout is too short, then the indicators are not synchronized with the State of the program, or in this case, with the other. Note that the only time wherever the VI display is static enough for me to take a screenshot as it is during the period of "Test Timeout. When the time-out occurs Finally, things be synchronized and the same results are displayed.
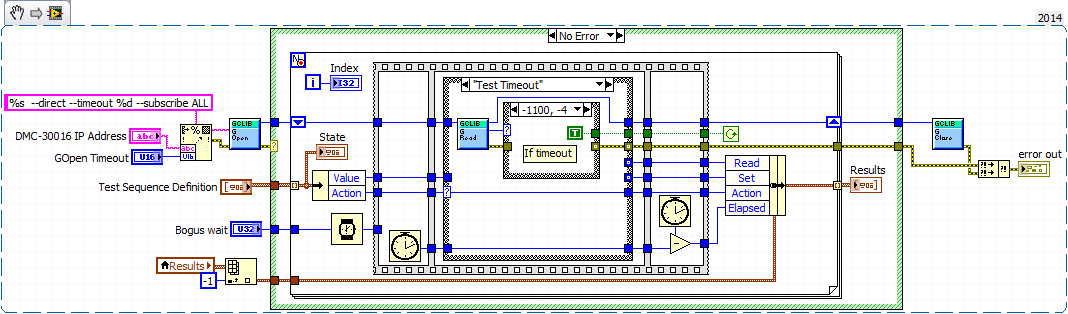
Here's the code. I am also attaching a folder zipped with the code, just because I don't know if the extracts are smart enough to include all the dll referenced by library call nodes.
Here on the left of the loop indicator 'State' and 'Index' terminals can be seen. The 'fake Wait' needed to make the indicators work synchronously appears below in the same area. Before coming with this 'fix' things I've tried, what has not worked, were:
- addition of the structure of flat sequence seen here with the indicators in the first panel
- Entrance to the 'value' property nodes using linked to two indicators with their outputs error Garland at the entrance of the error on the function 'G Read' (test timeout).
- defining indicators for "synchronous display" (apparently this parameter actually only works with the multi-threaded code, which I don't believe it is)
- setting false property to "postpone updates on the front panel.
Another thing that worked linked a "probe" to any data path entrance side of the conditional structure. I thought that it causes also a few milliseconds of delay as the expectation.
My best guess at what happens is that display updates are "launch and forget" actions that occur on parallel execution paths in the single execution thread and function on obtaining some of the main process to complete time slices. But when the main process is the name of an external library, which, outside the library can't share time with all other processes that can run in the same thread. All this makes sense?
This is because all these CFLN calls to the dll are set to run in the UI thread (to view the color orange on the top of the node).
If they eat the cycles in the UI thread, they may not leave enough cycles to LabVIEW to make updates to the user interface of the front panel.
What make these 3 part of the dll? They need to run in the UI thread? Is there a problem with the standby so that the DLLs are not pounding the UI thread?
-
under condition of read/write terminals on the side of the connector (basic training 3)
Hello
During my practice towards the review of the CLD, I examine the Core 3 online training material too. I just read a few tips of 'best practices' on the forum, for example this post:
It should be noted, that we should not use terminals (which are on the connector pane) to the inside of while loop or condition of the structure. Neither control, nor indicators (read/write terminals): "terminals conditionally read or written on the side of the connector are BAD!"
I can find many examples in the online training materials, when the indicators and controls are placed inside while loop and the case of structures in a Subvi.
I guess I should not do this during my review of the CLD, as they will run benchmark on my project? Should not be the core training materials updated some time? Or it's just not too important to have terminals on the outside? I would lose points during the CLD Exam my project as in the Core 3 screws?
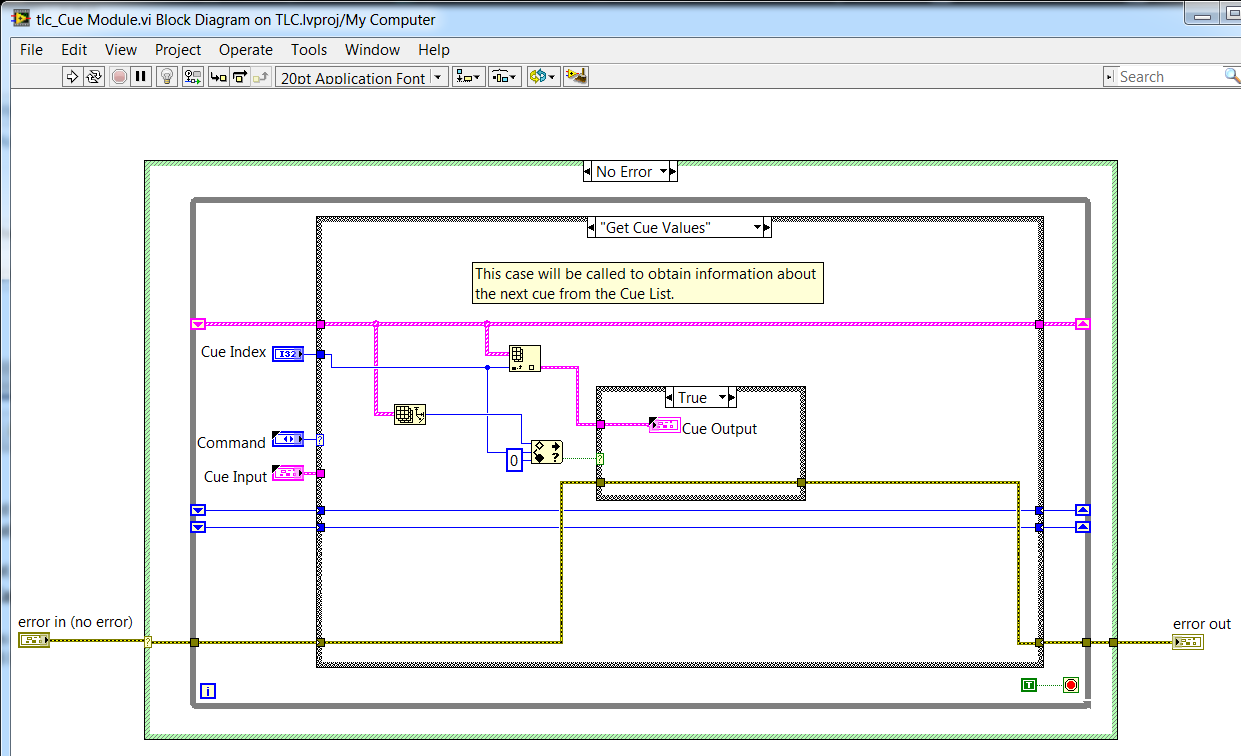
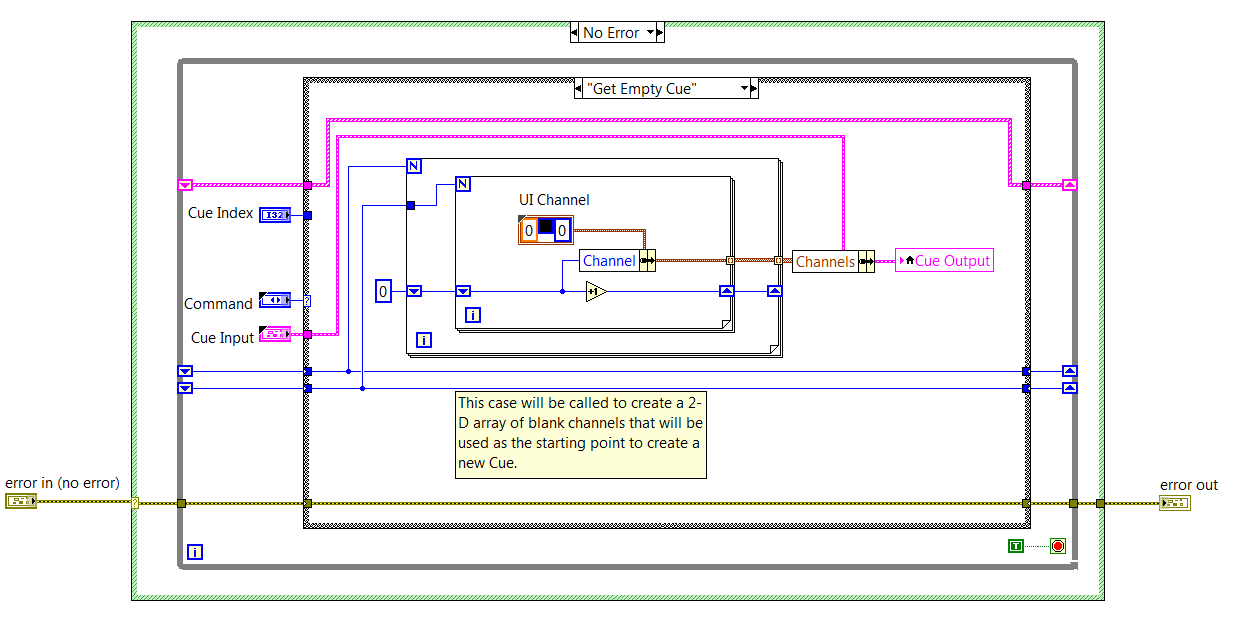
example 1: Core 3, exercise 4-6 design of an error-handling strategy:
EDIT:
What's even more ugly in this project, is that, in the case of 'Get empty Cue', the Cue output indicator is updated via a local variable, because the indicator is not accessible via 'outside ': wire
Nice catch on the training material. that the application would take an if subject to a review of the CLD test graders.
As noted in the nugget: sentencing of perfomance for conditionally reached terminals is a function of the size of the data. So, it is sometimes acceptable for simple data. The larger point being to learn about compromise and make the right choice for your code.
Preping for the CLD on other means of hand knowing that VI Analyzer will run on your project. Like any other code review you walk in - know the guidelines for the review and code to ' review ' as well as 'reply spec.'
I've not seen an instance where an example of shipping (2013 and later versions) would fail this test VIA (there are a few screws deep inside the vi.lib which can date back to before the adoption of this recommendation from style)
-
Jitter of RT! Can multiple readings to a variable / cluster cause a deadlock condition?
Howdy do.
While gradually develop and test an application on a crio9068 (RT linux) I started to see 'finished later?' in my main timed loop indicator flicker. Start pulling my hair out trying to figure out how to prevent this. I did a 'max hold' vi and can see the longest execution time for each image.
The application runs fine at about 75% of CPU with the Panel open load, and the majority of the iterations run at the time. Sometimes I'll have a 'pic' at run time, all four managers in the timed loop take significantly longer than normal to run and the indicator 'late' says.
A few questions I've had accumulate while chasing this:
-If I use local varables to pass data between the loops, but only write to the variable in one place, can I still cause a condition of blocking/jitter by competing readings of this memory space?
-If I use a node FPGA read/write to pass data between the FPGA and the timed loop, I should expect this causes a problem? I selectively disabled a lot of my code, and it seems that is where some of the delay occurs. What me stem, it's that these parts of the code have not changed in the recent development and the thing never used to run to the end.
-On the theme of the node FPGA read/write, I assumed before that I should not write to the same FPGA FP element in different subvis. However, the code is set up so that there are several parallel calls to the read/write node, just with different selected items. Is that BAD?
-Similarly, if I ungroup and read the same item in a cluster in a "parallel" mode control, can this cause a deadlock situation, or is it the same as unbundling and wiring away in several places?
-I am thanks to the recently renamed "software calibration and management toolkit NI (SCM)," formerly Drivven CalView, to manage the communication between the RT and a windows host. He is also careful fault management stuff. Anyone else using it, and is it possible that I am getting jitter by having too many calpoints in my deterministic loop?
No indication on any of the above would be greatly appreciated. If I don't make sense on any of the above points I do excerpts from example to describe.
Hi Matt,
What about under the name of multithreading - the same thread can run on multiple cores, but everything in a timed loop will always hold in a single thread. For reference (see 'Set the execution order for screws of real-time synchronization'):
LabVIEW Help: Synchronization of deterministic Applications (real time Module)
http://zone.NI.com/reference/en-XX/help/370622L-01/lvrtconcepts/timing_control_loops/
To cache the runtime data, I didn't have a specific method for mind, rather I generally try to catch at least one instance of the hiccups by capturing variables of interest in the shift registers or a FGV, just to see if there is any kind of difference. This may not be useful in your case, as I suspect it's interactive execution, what causes the problem.
Regarding the interactive performance and determinism, there is really no way of knowing what will happen, but it will often cause the kind of behavior that you see now. Because you are more or less continuous between the target and the host data, everything hangs in the network or on the computer host can set the RT system, especially if you read or write data on the front panel. Given that all of your curls are delayed at the same time, it seems the most likely scenario, unless you have a VI reentrant or similar shared between all the loops - I have seen that a few times with managers error or stop sharing. Given that these spots are quite often (it resembles something like 1/100 iterations, I would recommend put in some shared variable RT FIFO benchmarking and the deployment of the application as a stand-alone RTEXE.) It should be fairly easy at that time see if instability persists.
Best regards
-
In windows 7, which is a memory "hard fault"?
Windows 7 resource monitor displays a window marked "defects hard memory/100s." I have occaisionally see spikes of zero. Does that mean I have faulty RAM?
Hello
Hard faults do not represent an error condition. They are a normal part of treatment of memory.
Hard fault, it simply means that the block of memory must be extracted the pagefile (virtual memory) instead of physical memory (RAM).
An excessive number of hard faults may indicate a need to increase the physical memory.
See the following article for a complete description of the different terms used for memory management.
Management measures of main memory and memory logic
http://TechNet.Microsoft.com/en-us/magazine/ff382715.aspx
Let us know if you have any other questions.
Concerning
-
I can define a polcy fault underneath that can handle all the defects? Basically, I did not provide the name of Rift, or any condition.< faultPolicy version = "2.0.1" id = 'defects '.
' xmlns:env = ' http://schemas.xmlsoap.org/SOAP/envelope/ "
" xmlns: XS =" http://www.w3.org/2001/XMLSchema "
xmlns=" http://schemas.Oracle.com/BPEL/faultpolicy "" "
" xmlns: xsi =" http://www.w3.org/2001/XMLSchema-instance ">
< condition >
< faultName >
< condition >
< Ref action = "ora-rethrow-fault" / > or any other action that I love here.
< / condition >
< / faultName >
< / conditions >
Yes, you can we have a similar use where we wanted to send an email in all cases, we used the slot fault policy file.
-
Using fault-political with the Ombudsman and db adapter does not work
Help, please! I am stuck on this during 2 days...
Hi friends.
In my project I am trying to give a treatment with the exception of a db adapter executes a pl/sql procedure.
I'm forcing a raise_application_error in the procedure to handle the exception, and I would fault the police to treat it as "action man".
The db adapter is wired to a mediator:
JMS-service-> Ombudsman-> db Jca adapter
When I'm with the exception of the log says:
9d8bff56a1 due to: LINK. JCA-12563 []
Exception occurred when the link was invoked.
Exception occurred during invocation of the JCA binding: "JCA binding run operations reference 'PersistirODS' has no reason to: stored procedure call error.»
Error trying to prepare and execute the FORNECEDOR. UPSERTFORNECEDOR API.
There is an error occurred so that the preparation and execution of the FORNECEDOR. UPSERTFORNECEDOR API. Cause: java.sql.SQLException: ORA-20101: Deu Merda
ORA-06512: at the 'FORNECEDOR. UPSERTFORNECEDOR', line 405
ORA-06512: at line 1
Make sure that the API is defined in the database and that the settings match the signature of the API. This exception is considered non reproducible, probably due to an error of modeling. To be classified as reproducible to the contrary to add property nonRetriableErrorCodes with the value "-20101" to your deployment descriptor (i.e. weblogic - RA.Xml). Auto retry a reproducible fault set composite.xml for this invoke these properties: jca.retry.interval, jca.retry.count and jca.retry.backoff. All properties are integers.
".
The called JCA adapter threw an exception of resource.
Please review the error message above carefully to determine a resolution.
]]
and then it looks like it tries to run police of fault, but it says:
[2014 04-10 T 20: 01:39.667 - 03:00] [AdminServer] [WARNING] [] [oracle.integration.platform.faulthandling] [tid: Workmanager:, Version: 0, scheduled = false, started = false, queue time: 0 ms\n] [userId: weblogic] [ecid: 11d1def534ea1be0:-1fa77a00:145468d59e7: - 8000 - 000000000002801 a, 0] [APP: soa-infra] [RejectedMsgHandling] Impossible to enforce policies on the message rejected with id - 60046 []
oracle.fabric.common.FabricException: cannot resolve the link to a fault policy [blamed the activity details:]
Name of activity = null
The activity Id = null
Activity lineNumber = null
Reference name = null
WsdlLocation = null
ActivityType = null
]
Here are my files fault-policies and fault-links:
<? XML version = "1.0" encoding = "UTF-8"? >
" < faultPolicyBindings xmlns: xsi =" http://www.w3.org/2001/XMLSchema-instance "
" xsi: schemaLocation =" " http://schemas.Oracle.com/BPEL/faultpolicy .. / xsd/FaultBindings.xsd '
xmlns=" http://schemas.Oracle.com/BPEL/faultpolicy "> "
< faultPolicy composite = "political malpractice" / >
< / faultPolicyBindings >
<? XML version = "1.0" encoding = "UTF-8"? >
" < faultPolicies xmlns: xsi =" http://www.w3.org/2001/XMLSchema-instance "
" xsi: schemaLocation =" " http://schemas.Oracle.com/BPEL/faultpolicy .. / xsd/FaultPolicies.xsd '
xmlns=" http://schemas.Oracle.com/BPEL/faultpolicy "> "
< faultPolicy id = "political malpractice" >
< condition >
" < faultName = xmlns:medns ' http://schemas.Oracle.com/mediator/faults "" "
name = "medns:mediatorFault" >
< condition >
< Ref action = "by default-human-intervention" / >
< / condition >
< / faultName >
" < faultName = xmlns:rjm ' http://schemas.Oracle.com/SCA/rejectedmessages "name ="rjm:PersistirODS"> "
< condition >
< Ref action = "by default-human-intervention" / >
< / condition >
< / faultName >
< faultName >
< condition >
< Ref action = "by default-human-intervention" / >
< / condition >
< / faultName >
< / conditions >
< action >
< Code action = "by default-human-intervention" >
< humanIntervention / >
< / action >
< / actions >
< / faultPolicy >
< / faultPolicies >
Once again
Help, please! I am stuck on this during 2 days...
Guys... My fault...
Just changed from parallel sequencial and it worked...
-
Black border added around object build conditional HR.
We have recently updated since TCS5 2015 release and now we have a problem.
The HR project is related to the FM band. There are a few pictures that are defined with a conditional tag build. These HR images are created with a black box around the edge. If I remove the CBT in FM, the black box disappears in HR.
In FM, there is a setting for TCC of 'Indicators of Condition Show' where, if on, places a color border around each photo flagged. It died in FM, but it seems to be stuck on HR, and I can't find in any case to turn it off.
If the frame anchored on the FM band is empty, then HR does not add the box. If I add anything in the anchored frame, returns the box.
If I turn off the option in HR to "Distill use to generate an Image", the image quality decreases abruptly, and the box will now appear under the image itself.
If you change the image in HR, it shows that the black frame is part of the image, so something is added during import.

This is not happened is any previous version of the TCS. How can I lose the box?
Hello
Thank you for reporting this issue. We have reproduced it and we'll fix it in the next update.
We can provide you with the solution private, if necessary.
-Ritesh Srivastava
Adobe TCS team

Maybe you are looking for
-
Scanning PC settings appears every day
Whenever I have begin to macOS, I get a window of "Scan-from-PC. It does list some scanners and does not include the option Add / Remove. There is a "Scan of operating Panel settings" button which takes me for a nearly identical and all as useless sc
-
Last Friday, when I got a message on my computer. I started my computer and waited for my coming screen lock. But it does not.To place a display that showed a message (HDD error please run the System Diagnostics hard drive test.) Hard drive 1 (3F1) f
-
Troubleshooting printer offline
Printer offline can be resolved in 2 ways. Quick fix: reboot the router, restart the printer & computer -printer offline error can happen again if the router has a dynamic IP address (most consumer routers using dynamic IP) Permanent solution: 1. pri
-
How can I configure the lifecam system?
I don't know anything about the system. your expedited procedure is not good if you know what is needed to set up the contact, everyone should be on live messenger? How can I da% one? what I need is information that must implement the system of life
-
Description of error: 80246008
When I try to install a windows update, it keeps in default and it gives me an error code 80246008 '." I click on "get help with this error. And then he told me to open "Services" and then right click on "Background Intelligent Transfer Service". But