Conversion table problem (FM unstructured for DITA, cannot create valid choicetable)
Hello
I'm trying to set up a table of FM migration to DITA. I was able to map most of my paintings on the table suuported in DITA style CLIENT access licenses, but I can not choicetables right.
My problem is the element specific FM for the body of the table.
It's my conversion table:

And that's what I get:

Where is my mistake? I tried several variants for fm-chbody, but the result is always the same.
Thanks for any help
Susanne
Susanne,
Two observations:
First, I tried your table of conversion to FM 10. As it is, I failed to the package body element. However, when I changed the first cell in the line fm-chbody to + TB:E:chrow or simply TB:chrow +, the element of body wrapped as expected.
Second, the Structure display you proposed shows that items in your results the fm-chheadrow and Charles are the two children of the tbody element. So, it seems that the two types of lines in your unstructured document appear as body lines. Applying a conversion of a document informal table cannot move content from a header to a body line line. Your fm-chheadrow rule only applies to lines in a table header and your fm-chbody rule applies only when all the lines in the body of the table are mapped to the Charles. Try to move the first line of your table to a header row and see what happens.
Good luck.
-Lynne
Tags: Adobe FrameMaker
Similar Questions
-
Cannot create instant when quieced cbt enabled on Windows server vm
Hello
yesterday I updated my ESXi 5.5 to 6.0 test environment and now I got the problem that my backup software cannot create a snapshot. So I tested and same trough VCenter can't cerate a snapshot of the quieced. I got this error message:
Fehler beim Speichern Snapshots: msg.snapshot.error - QUIESCINGERROR.
In the vmware.log I read a lot of mistakes, here are a few:
Could not open the file change tracking "/ vmfs/volumes/54aea31d-61d81d56-35f9-000423ba9740/srv01-Domaincontroller/srv01-Domaincontroller-000002 - ctk.vmdk ': invalid followed change or drive in use.
Node 19095c-cbt cbt creation failed with the error can't allocate memory (0xbad0014, out of memory).
Could not set vmkernel change Tracker: monitoring ESXi filter failed (0x143c). Drive will be open, but follow up information changes vill be invalidated.
Could not repair the disk signature writable snapshot 'scsi0:1 '.
Snapshot 62 failed: impossible to suspend the virtual machine (31).
When I stop the virtual machine, remove the ctk files and modify the configuratoin of the virtual machine for:
ctkEnabled = true (or false)
scsi0:1.ctkEnabled = false
scsi0:2.ctkEnabled = falseThen I can do an instant downturn. The false to the scsi0:x is important. When I switch back the configuration I can't do an instant downturn again.
This is the case the following OS:
Windows Server 2008 R2
Windows Server 2012
R2 Windows Server 2012
I can also cerate a snapshot of slowing to a virtual Windows 8.1 without problem computer and a Linux VM.
I have already created a case at VMware, but the defender was looking a bit, gave me a tip that does not work and told me that there nothing more, he can do it, because my Supermicro motherboard is not on the supported list.
This I don't understand, we are a partner of Enterprice of VMware, I want to test the new version in my test environment before I install this at a client. Now, I had a problem, and it seems that VMware will not help me because the motherboard is not ' t supported! But this is not like a hardware issue to me.
Here is maybe someone who has the same problem or can made a test what happens when you turn on the cbt for a virtual machine.
Kind regards
Stefan
Patch is available: http://kb.vmware.com/kb/2116126
-
ORA-02374: error loading conversion table / ORA-12899: value too large for column
Hi all.
Yesterday I got a dump of a database that I don't have access and Production is not under my administration. This release was delivered to me because it was necessary to update a database of development with some new records of the Production tables.
The Production database has NLS_CHARACTERSET = WE8ISO8859P1 and development database a NLS_CHARACTERSET = AL32UTF8 and it must be in that CHARACTER set because of the Application requirements.
During the import of this discharge, two tables you have a problem with ORA-02374 and ORA-12899. The results were that six records failed because of this conversion problem. I list the errors below in this thread.
Read the note ID 1922020.1 (import and insert with ORA-12899 questions: value too large for column) I could see that Oracle gives an alternative and a workaround that is to create a file .sql with content metadata and then modifying the columns that you have the problem with the TANK, instead of BYTE value. So, as a result of the document, I done the workaround and generated a discharge .sql file. Read the contents of the file after completing the import that I saw that the columns were already in the CHAR value.
Does anyone have an alternative workaround for these cases? Because I can't change the CHARACTER set of the database the database of development and Production, and is not a good idea to keep these missing documents.
Errors received import the dump: (the two columns listed below are VARCHAR2 (4000))
ORA-02374: error loading «PPM» conversion table "" KNTA_SAVED_SEARCH_FILTERS ".
ORA-12899: value too large for column FILTER_HIDDEN_VALUE (real: 3929, maximum: 4000)
"ORA-02372: row data: FILTER_HIDDEN_VALUE: 5.93.44667. (NET. (UNO) - NET BI. UNO - Ambiente tests '
. . imported "PPM". "' KNTA_SAVED_SEARCH_FILTERS ' 5,492 MB 42221 42225-offline
ORA-02374: error loading «PPM» conversion table "" KDSH_DATA_SOURCES_NLS ".
ORA-12899: value too large for column BASE_FROM_CLAUSE (real: 3988, maximum: 4000)
ORA-02372: row data: BASE_FROM_CLAUSE: 0 X '46524F4D20706D5F70726F6A6563747320700A494E4E455220 '.
. . imported "PPM". "' KDSH_DATA_SOURCES_NLS ' lines 229 of the 230 308.4 KB
Thank you very much
Bruno Palma
Even with the semantics of TANK, the bytes for a column VARCHAR2 max length is 4000 (pre 12 c)
OLA Yehia makes reference to the support doc that explains your options - but essentially, in this case with a VARCHAR2 (4000), you need either to lose data or change your data type of VARCHAR2 (4000) to CLOB.
Suggest you read the note.
-
I got following error when running tests on the Workbench 2.1
[February 19, 2014 16:27:10: TRANSPORT] [0] FRAME: Async command is monitored by the process of STAF 73
[February 19, 2014 16:27:10: FACTORYIMP] SETTING [0]: insert in the container
[February 19, 2014 16:27:10: TESTHASH] [0] INFO: VirtualMachine installation process
[February 19, 2014 16:27:10: VIRTUALMAC] [0] FRAMEWORK: the Setup() method called
[February 19, 2014 16:27:10: STAFBASE] SETTING [0]: command execution STAF: staf VTAF_VM localhost connect password of administrator agent 192.168.8.158 userid: 11:Infocore' 1 q ssl
[February 19, 2014 16:27:10: STAFBASE] [0] FRAME: command execution STAF: staf localhost VTAF_VM getvms anchor 192.168.8.158:administrator
[February 19, 2014 16:27:11: MULTITECH] [0] FRAME: called VTAF::TestLib:Sphere:Lib:STAFSDK:HostSystem:GetAllVMs (HostName = '192.168.8.150' password = 'infocore"username ="root") returned UNDEF
[February 19, 2014 16:27:11: VIRTUALMAC] [0] FRAMEWORK: new creation vaaivm1-150 VM from scratch...
[February 19, 2014 16:27:11: TESTHASH] [0] ERROR: cannot run processSetup for configuration: cannot run createHOMObj for configuration: No. GuestOS appearing in the XML file
[February 19, 2014 16:27:11: TESTHASH] WARN [0]: found objects that need to be cleaned
[February 19, 2014 16:27:11: VIRTUALMAC] [0] INFO: cleaning of the virtual machine: vaaivm1-150
[February 19, 2014 16:27:11: HOSTSYSTEM] [0] FRAME: HostSystem Cleanup() called
[February 19, 2014 16:27:11: HOSTSYSTEM] [0] FRAMEWORK: the location of the swapfile to the directory of the VM on the host 192.168.8.150 restoration VM...
[February 19, 2014 16:27:11: HOSTSYSTEM] SETTING [0]: setting VM Swapfile location to use the directory of the virtual machine
[February 19, 2014 16:27:11: STAFBASE] SETTING [0]: command execution STAF: staf VTAF_Host localhost connect password of administrator agent 192.168.8.158 userid: 11:Infocore' 1 q ssl
[February 19, 2014 16:27:11: STAFBASE] [0] FRAME: command execution STAF: staf localhost VTAF_Host setswapfilelocation anchor 192.168.8.158:administrator host 192.168.8.150
[February 19, 2014 16:27:31: MULTITECH] [0] FRAME: called VTAF::TestLib:Sphere:Lib:STAFSDK:HostSystem:SetSwapFileLocation (HostName = '192.168.8.150' password = 'infocore"username ="root") '1' returned
[February 19, 2014 16:27:31: HOSTSYSTEM] [0] FRAME: destruction of object 192.168.8.150...
[February 19, 2014 16:27:31: LOGMANAGEM] COMMENTS [0]: recovery log file 192.168.8.150 host vmkernel.log
[February 19, 2014 16:27:31: FILEUTILIT] [0] FRAME: PutTmpDirectory - called for destination host localhost
The same problem was sloved.
Re: Hardware Certification-do can not find the storage50info.txt file to...
-
Conversion tables and the entries in the table
I'm working on a conversion table for our former products of FM unstructured to DITA. I understand the basic concepts, but I'm having a problem with the table cells.
I have P:CellBody in my conversion table, in the first row, mapped at the entrance with a cellbody qualifier.
I also TC mapped at the entrance.
The same applies to P:CellHeading, and Th.
Therefore, my text is wrapped in two input elements. The context tab to show the item says:
entry
entry
line
TBODY
tgroup
Table
body
NoName
NoName
I'm sure it should be the same as above with the input only one element (and of course with the fixed NoNames which I think I know how to do; I just have not had here yet).
How to avoid get my cells wrapped in two input elements?
Thanks in advance,
Marsha
Marsha,
I don't understand what you're trying to do, or what is exactly in your conversion table. Be aware, however, that FrameMaker will always create elements for the basic elements that occur in your tables. The table of conversion that you give little control of how these items will be marked, but not question whether elements will exist.
If your conversion table contains lines such as:
P:CellBody entry cellbody TC: entry You will get the nested input elements. External is the cell of the table itself and inside is the paragraph. FrameMaker does not have a valid document to use the tag of the element itself to a cell and a container, so aside from the results is not what you wanted, they are not correct in FrameMaker.
If your table cells contain simple paragraphs and you don't want the elements for cells and paragraphs, your conversion table didn't even need to mention paragraph CellBody and CellHeading tags. Indeed, if your table formats using CellBody as paragraph format for cells in the body of a table and CellHeading as the paragraph format for the cells in the table, your ESD header didn't even apply the paragraph formats.
Another alternative is to include a paragraph tag in a table row of conversion for a table cell by combining TC: and P: to match table cells containing such paragraphs. For example:
TC: P:CellBody entry creates items named cell entry of table cells containing paragraphs tag CellBody. The paragraph in such a cell is not encapsulated in an extra element.
One final note is that TH: in a conversion table refers to the position of the entire table. his children are header lines. The analogue of table of TH body: to:, not TC.:
-Lynne
-
Server 8 installation error "Windows cannot be installed to this disk. the selected disk is a MBR partition table. The EFI system, Windows cannot be installed to GPT disks.

How do I resolve this problem and install windows 8 as usual? I have several partitions with data... I don't want to delete all partitions and create partitions from scratch and install the os...
How to get there?
Windows cannot be installed to this disk. the selected disk is a MBR partition table. The EFI system, Windows cannot be installed to GPT disks.
This could happen not only windows 8, but also windows 7, windows Server 2008, or 8 server 2008 R2... Troubleshooting steps will be similar for all windows to get this problem...
I had this problem when installing server 2008 r2 on a dell... T110 server without remove the other partitions or lose all the data on the other drivers, you can solve this problem...
simply, I have followed these steps using gparted and solved my problem... These measures will be useful for anyone with similar problem... . All the steps that I've documented here... All the steps I've documented here...
-
How to apply the Conversion Table of file FM.
I have a conversion table generated for a group of files that I am trying to structure. I want to be able to apply the conversion with Extendscript table. The script that I have does not save any file converted. I don't know why is it not save the file. I was under the impression that the "Structure Generator" should create the new file. If this incorrect.
Here is the code I am using.
var myFile = File.openDialog ("Select File to Convert"); var myCT = File.openDialog ("Select ConversionTable"); var CT = openFile (myCT.fsName, 0); applyConversionTable (myFile.fsName, CT) closeFile (CT); function applyConversionTable(fileName, CT){ var doc= openFile (fileName, 0); var name = fileName.replace(/[\w\.]+$/,"test.fm") CallClient("Structure Generator", "InputDocId " + doc.id); CallClient("Structure Generator", "RuleDocId " + CT.id); CallClient("Structure Generator", "OutputDocName " + name); CallClient("Structure Generator", "GenerateDoc"); closeFile (doc); } function openFile( fileName, visible){ var i = 0; var doc = 0; var openParams = GetOpenDefaultParams(); var retParams = new PropVals(); i = GetPropIndex(openParams, Constants.FS_AlertUserAboutFailure); openParams[i].propVal.ival = false; i = GetPropIndex(openParams, Constants.FS_MakeVisible); openParams[i].propVal.ival = visible; i = GetPropIndex(openParams, Constants.FS_FileIsOldVersion); openParams[i].propVal.ival = Constants.FV_DoOK; i = GetPropIndex(openParams, Constants.FS_FileIsInUse); openParams[i].propVal.ival = Constants.FV_ResetLockAndContinue; i = GetPropIndex(openParams, Constants.FS_FontChangedMetric); openParams[i].propVal.ival = Constants.FV_DoOK; i = GetPropIndex(openParams, Constants.FS_FontNotFoundInCatalog); openParams[i].propVal.ival = Constants.FV_DoOK; i = GetPropIndex(openParams, Constants.FS_FontNotFoundInDoc); openParams[i].propVal.ival = Constants.FV_DoOK; i = GetPropIndex(openParams, Constants.FS_RefFileNotFound); openParams[i].propVal.ival = Constants.FV_AllowAllRefFilesUnFindable; doc = Open(fileName, openParams, retParams); if (doc.ObjectValid() ===1){ doc.openedByScript = true; } else{ PrintOpenStatus(retParams); } return doc } function closeFile(doc){ Constants.FF_CLOSE_MODIFIED = 1; var res = doc.Close(Constants.FF_CLOSE_MODIFIED); }Ah, found the problem. I noticed this earlier, but do not think that it was important, it apparently. The other arguments must be all uppercase. Like this:
CallClient ("Generator of Structure", "INPUTDOCID" + doc.id); CallClient ("Structure Generator", "RULEDOCID" + CT.id); CallClient ("Generator of Structure", "OUTPUTDOCNAME" + name); CallClient ("Structure Generator", "StructureDoc"); I tested it and it works for me. FWIW, I think that it is a poor quality of a client API feature otherwise very slippery.
Russ
-
Conversion table, EDD, manage multiple formats table
Hello! I'm quite new to structured framemaker and I plan to migrate legacy documentation not structured in XML format. In documentation existing as well as ordinary tables I Note and warning messages in a table:

The icon is a paragraph with a frame higher TFP. format and table shading
When I generate a conversion table, framemaker creates that one set of items for the table cells, rows, etc. I'm a little confused about how to deal with these tables in the table of conversion and ESD file so that I can save the converted to XML file, then load it and get the same table format? I would appreciate any advice. Thank you!
Elektroneg,
It is always tempting to start a new project structured FM by converting existing documents. I recommend, however, that, until you are familiar with the structure, you start by building a structured model and ESD and take a good start on them debugging with the test data. Once you have created a catalog of the element, it will give you a target for a table of conversion and implementation of an XML application.
A table structured FM must have the elements on each side of the table: the entire table, any title of table, any position table, the body of the table, a table leg, all ranks, and each cell. Each of these item types can be used for one purpose. You cannot, for example, have a general element called TableSection which is used for the header, body and foot or an element called title, which is used for the section headings, but also the titles table. However, you can have several elements of each of these types.
A DSP defines all the elements for the tables and the various components of the table, including the command of no subitem. It can also define an initial table format the format applied when the table is created and the initial models that specify the names of the line items in a topic of table, foot or body, and those of the cells of each type of line. Note that these are the original formats and models of structure only.
In your case, for example, you can set a table format called Message with the shaded background desired. If the note and Attention messages have different icons, you can define two elements of the array, called Note, and called Attention. The body of a Note might be called NoteBody, and the only line of a NoteBody might be NoteRow. The two cells in a NoteRow could be called NoteIcon and MessageText and may contain paragraphs which forms have the same name as these elements. Tables of attention would be defined by analogy.
To generate a table of conversion that structure this content, remember that any table generated by FM conversion is only a starting point. The project creates the FM does not define several the table header, body, foot, line or cell elements. You can change the conversion table to do this. For example, the part of your grade conversion table will be something like:
Wrap this object or objects This element of
With this qualifier TC: P:NoteIcon
NoteIcon TC: P:MessageText MessageText TR:NoteIcon, MessageText NoteRow TB:NoteRow NoteBody T:NoteBody NoteTable This conversion table fragment defines a table cell that contains a NoteIcon paragraph labeled as a part of NoteIcon, a cell with a paragraph containing the MessageText tag to be a MessageText, a line containing an element tag NoteIcon followed a MessageText marked to be a NoteRow, a table containing a single element tag NoteRow to be a NoteBody , and a table composed only a NoteBody be labeled NoteTable.
-Lynne
-
Conversion Table helps with Note/caution
I'm almost finished my conversion table, but I'm having problems with two things: lists and notes/warnings. For simplicity and brevity, I'll discuss the lists in another post.
My < note > elements have an attribute of caution are simply formatted as a paragraph Level0. My conversion table looks like this:


I've looked at these for too long to be able to determine why the score is correctly convert paragraph tag, but the caution paragraph tag is just a paragraph.
TIA,
Marsha
Hi Marsha...
I think that the problem lies elsewhere... that seems essentially functional for me.
However, your TC: P: * maps look like they could cause problems, but not for what you describe (although this syntax isn't something I used so I could be all wet it).
Note that the default @type for
is "note", so there is no need to assign type = "note" a note regular... it's not bad, it is not necessary. See you soon,.
.. .Scott
-
Problem with Framemaker 9 Dita XML Files in Framemaker 10
I just upgraded to Framemaker 10. I meet a number of problems when trying to work with my help of Dita XML topics, that were last saved in Framemaker 9.
1. using the default Dita model
When I open one of my documents in Framemaker 10, the Dita 1.2 model ditabase.fm is automatically applied. Everything seems fine. But then when I convert the XML using Eclipse (which is essentially the html, so we go from XML to HTML format) using Dita Open Toolkit ant scripts, I see this message:
[pipeline] [DOTJ013E] [ERROR] failed to parse the referenced file 'html\c_licensing.xml' cause from under exception. Please correct the base on the exception message reference.
[pipeline] c_licensing.xml 25:Attribute 'xmlns:ditaarch' of the line must be declared for the element type "dita".Then, I opened the xml file in a text editor, and I saw this on line 25:
< dita xmlns:ditaarch = "http://dita.oasis-open.org/architecture/2005/" > ""
25 line seems to me. Am I missing something?
2 go to a model of Dita 1.1
I tried to get around the above problem. In Framemaker, I tried to put another structured as the default application. I closed all files and choose the structured Dita 1.1 application default (it defaults to the Dita 1.1. Composite app.)
Then I tried to open my file: I got this message inside Framemaker:
'Failed XML validation. Continue?
Error to the [path of ACCESS], line 25, tank 72, Message: attribute ' {http://www.w3.org/2000/xmlns/} ditaarch' is not declared for the element "dita"Sounds familiar, isn't?
I went from Dita 1.1 by default. Composite application structured with the Dita 1.1. Application of structured theme. Then I messed the source file and saved. The messages that I got in the FrameMaker log window included one above, plus I had a variety of messages to unknown element, things like:
Element unknown dita.
notion of unknown element,
various attributes are not reported for concept,
element unknown conbody.
If I go to the Dita 1.1 mash all these messages diappear except this one:
Attribute ' {http://www.w3.org/2000/xmlns/} ditaarch' is not declared for the element "dita"
My conversion scripts of Ant in the Dita Open Toolkit are still unable to process this file. They give the same message as above in (1) and the file is not converted to HTML.
Can someone help me with this problem? I also posted this question in the Group of users of Dita on Yahoo Groups. If I get an answer in one place, I'll post it in the other.Thank you
Nina P.
[transferred to dita-users]
Hi Nina...
The xmlns:ditaarch attribute must be the "topic" not dita root element. If demand for FM10 structure is the award that it is wrong. You create composite themes (multiple topics in a single file under the root of dita)? If this isn't the case, you can get rid of the total dita element and who can "solve" the problem.
The first mistake you get (#1) says that the xmlns:ditaarch attribute must be declared (that is, defined in the DTD)... It's not (because it is not supposed to be there (as I know). This is not to say that it must be declared in the DITA file.
Even for the #2 error... the composite 1.1 app is apparently set up correctly, so it's saying the same thing that the Old Testament said... "you have this attribute in the XML file, but it is not declared in the DTD.
Your subsequent error on the missing items is because you spent in the "topic" DTD, who does not know the dita element or elements based on concepts.
If you can unpack your files dita element (because you are just using a topic in each file), which can solve the problem. But you probably need to do is open these files in a text editor and remove the attribute of xmlns:ditaarch of them (he not really needs on the elements of the topic either since it is the default value). Then, I turn to the composite 1.1 as a default app. I'll take a look at the FM10 1.2 default app and see what happens. (I have not seen this problem since I was on DITA-FMx, which has its own structure of apps).
See you soon,.
.. .Scott
Scott Prentice
Leximation, Inc..
www.leximation.com
-
Cannot create relationship master detail for datablock
Hi guys, my form currently has a relationship master detail for 1 datablock and everything works well. I now have a need to do a datablock different, based on the same table as the previous datablock but for some reason any that it won't let me create the same master-detail relationships, as I did on the 1st slice (and I need the same relationships to sort the block shows the same data as the previous datablock).
Anyone know why it won't let me create the relationship?I encountered a similar problem before. When you say that you cannot create relationships is - it simply because you cannot select the master/detail through the wizard? If this is the case, you should be able to make the relationship manually, or at least I could when I had the same problem. Although I can't help, but wonder why it wouldn't let you select them in the wizard. There may be an underlying reason for this. But anyway, try and make the relationship manually and let me know if it works.
-
Changing aid necessary table problem
Hello. I hope someone can help me with this problem.
I have two tables, an and mv. Create the following script:
create table (mv)
the moduleId Char (2) CONSTRAINT ck_moduleId CHECK (moduleId in ("M1", "M2", "M3", "M4', 'M5', 'M6', 'M7', 'M8'")).
credit ck_credits Number (2) CONSTRAINT CHECK (credits (10, 20, 40));
constraint pk_mv primary key (moduleId)
);
create table (its)
stuId Char (2) CONSTRAINT ck_stuId CHECK (stuId ('S1', 'S2', 'S3', 'S4', 'S5')),
moduleId tank (2),
primary key constraint (stuId, moduleId) pk_sa,
constraint fk_moduleid foreign key (moduleId) references (moduleId) mv
);
And the scripts below is to insert data into the two:
insert into VALUES mv ("M1", 20)
/
insert into VALUES mv ("M2", 20)
/
insert into VALUES mv ("M3", 20)
/
insert into VALUES mv ("M4", 20)
/
Insert in mv VALUES ('M5', 40)
/
insert into VALUES mv ("M6", 10)
/
insert into VALUES mv ("M7", 10)
/
Insert in mv VALUES ('M8', 20)
/
insert into a VALUES ('S1', 'M1')
/
insert into a VALUES ('S1', 'M2')
/
insert into a VALUES ('S1', 'M3')
/
insert into a VALUES ('S2', 'M2')
/
insert into a VALUES ('S2', 'M4')
/
insert into a VALUES ('S2', 'M5')
/
insert into a VALUES ('S3', 'M1')
/
insert into a VALUES ('S3', 'M6')
/
Now for the real problems.
First of all, I need to try to overcome the problem of table mutation ensure that stuid = S1 in table its can not take the two moduleId M5 and M6.
Just one or the other. I created a single trigger, but runs aground because of the changing table problem.
The second problem that I need to overcome is that none of the stuids can have the ModuleID where total value of more than 120 credit credits. Credit value is stored in the table of mv.
Thank you very much in advance for any help.Use a statement-level trigger:
First of all, I need to try to overcome the problem of table mutation ensure that stuid = S1 in table its can not take the two moduleId M5 and M6.
SQL> create or replace trigger sa_trg 2 after insert or update on sa 3 declare 4 c number; 5 begin 6 select count(distinct moduleId) into c 7 from sa 8 where stuid = 'S1' 9 and moduleId in ('M5','M6'); 10 if c > 1 then 11 raise_application_error(-20001,'S1 on both M5 and M6!!'); 12 end if; 13 end; 14 / Trigger created. SQL> select * from sa; ST MO -- -- S1 M1 S1 M2 S1 M3 S2 M2 S2 M4 S2 M5 S3 M1 S3 M6 8 rows selected. SQL> insert into sa values ('S1','M5'); 1 row created. SQL> insert into sa values ('S1','M6'); insert into sa values ('S1','M6') * ERROR at line 1: ORA-20001: S1 on both M5 and M6!! ORA-06512: at "SCOTT.SA_TRG", line 9 ORA-04088: error during execution of trigger 'SCOTT.SA_TRG'The second problem that I need to overcome is that none of the stuids can have the ModuleID where total value of more than 120 credit credits. Credit value is stored in the table of mv
SQL> create or replace trigger sa_trg 2 after insert or update on sa 3 declare 4 c number; 5 begin 6 select count(distinct moduleId) into c 7 from sa 8 where stuid = 'S1' 9 and moduleId in ('M5','M6'); 10 if c > 1 then 11 raise_application_error(-20001,'S1 on both M5 and M6!!'); 12 end if; 13 14 select count(*) into c from ( 15 select stuid 16 from mv, sa 17 where sa.moduleid=mv.moduleid 18 group by stuid 19 having sum(credits)>120); 20 21 if c > 0 then 22 raise_application_error(-20002,'A student cannot have more than 120 credits!!'); 23 end if; 24 25 end; 26 / Trigger created. SQL> select stuid, sum(credits) 2 from mv, sa 3 where sa.moduleid=mv.moduleid 4 group by stuid; ST SUM(CREDITS) -- ------------ S3 30 S2 80 S1 100 SQL> insert into sa 2 values ('S1','M4'); 1 row created. SQL> select stuid, sum(credits) 2 from mv, sa 3 where sa.moduleid=mv.moduleid 4 group by stuid; ST SUM(CREDITS) -- ------------ S3 30 S2 80 S1 120 SQL> insert into sa 2 values ('S1','M7'); insert into sa * ERROR at line 1: ORA-20002: A student cannot have more than 120 credits!! ORA-06512: at "SCOTT.SA_TRG", line 20 ORA-04088: error during execution of trigger 'SCOTT.SA_TRG'Max
http://oracleitalia.WordPress.com -
Cannot create Alias name for Cardinal cannot right click maximum DF PROFI II CARD
Cannot create Alias name for Cardinal cannot right click to the maximum example of MAX installation instructions, does not match what I see. See attached picture.
At the suggestion of Ryan to technical support, I improved the VISA to 5.4.1 and the problem was solved.
Thank you.
-
Conversion of jpg to ASCII for code output ZPL-Zebra printer
I print on a Zebra ZM400 using the ZPL code. I can upload images to the printer using Zebra utilities and I remember these images to print on a label, but I have to be able to download pictures using the ZPL code (using the ~ DG command). The ~ DG command needs the JPG image to ASCII format. I have other images that were already converted to ASCII (by someone else) that I am able to print, so I know what I do works as expected, however my problem is that I have new images which must be converted to ASCII format required and I don't know how to do this.
So, my goal is to print a picture on a Zebra printer, but my real question is to know how to convert a JPG image to ASCII format (for the Zebra printer).
Let me know if you need more information.
Thank you
Hi Emily,.
Unfortunately, I have not well understand how this has been done before that the person who had previously completed a conversion is no longer works for our company.
The ZM400 printer uses ZPL II of Zebra language to create/format of labels and the printer setup/order. Instead of download chart (~ DG), I am now using the command object download (~ DY), located in the ZPL II (182 p) programming guide. This allowed me to use a. File PNG rather than JPG, which was easier to work with.
I was able to use a modified version of your suggested method to make it work. The ~ DY command takes a parameter (data) which is a 'hexadecimal ASCII string defining the image', which is defined as: "the data string sets the image and is a hexadecimal representation of ASCII image. Each character represents a horizontal nibble by 4 points. "So the method you suggested is exactly what I had to do, however I didn't say that it must be represented in hexadecimal ASCII code.
I converted the binary file reads (of the PNG) data into a byte array, then made a (padded two-digit in hexadecimal) number of channels within a loop conversion For to give the ASCII representation of the binary data. This gives a hexadecimal representation of ASCII to binary data. VI is attached.
Thanks for your help!
I encountered another problem: the PNG files took an eternity for the printer load into memory when printing (compared to the same image in Zebra. GRF format). I solved this re-reading the file saved on the printer, where it is native. GRF format (using the ^ HG command), then re-recording this output (now in the ZPL code formatted) to the printer. I guess there is a way to convert directly to the. Format of the GRF, but for now it does not work in my case.
Thanks again!
-
Creating tables in a nested for loop
Hi all.
I was stuck in this problem for quite a while now and I still don't know how to continue. Some outside the entrance would be greatly appreciated!
I'm doing the following:
-Take an array of numbers, to check if they are within a certain range (e.g. between 2 and 4)
-Build two new arrays: one with all the numbers that are inside the beach and the other with the rest.
An additional condition is that the amount and value of the range conditions will change (for example, it could be between 2 and 4 only / 2, 4 AND 6 and 7 according to the entry)
To treat this, I created two nested for loops - one that goes on a table that contains conditions of the beach and inside that actually go and check if the values are in the range. I think I did that part successfully, but the next part is confusing to me - how to actually create the tables separated within two loops for?
My apologies if I did not explain it well. Another method to support this problem is I want to translate following LabVIEW:
Ranges of table / / [1 5 7 10] exodus-> This means we want to divide numbers based on those who are in (1,2) and (4.5) against those who are not
Table of values / / [2 3 6 11 3]
EndOperationDelegate table / / array of values within the range
Table outValues / / Array of values out of rangefor m = 1:size (ranges)
for n = 1:size (values)
If (THE NUMBER IS on the INSIDE of EACH RANGE)
EndOperationDelegate = [EndOperationDelegate NEWNUMBER]
on the other
outValues = [outValues NEWNUMBER]
endend
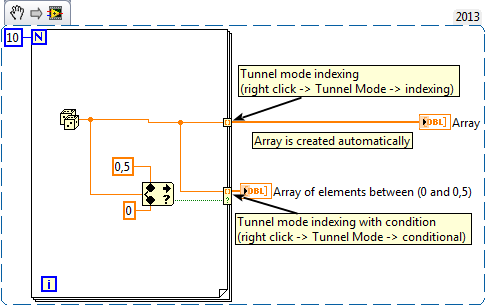
endSounds easy enough, but it gets so chaotic with Labview that I don't know what to do. I have attached a reference image - insertion in the array function is not in fact add to the table, it creates a new table. How can I save that for when the nested for the ends of the loop?
I have seen a few examples with shift registers which lie in a loop and I couldn't successfully that transfers in my block diagram.
Any help/direction would be greatly appreciated.
Hello!
See the following example to understand how you can create a table in the loop For

In your case, you also can uce conditional terminal to create a table only when then located nearby. It makes the code much cleaner that the structures of the case
Hope this helps, if not, let me know if I can help you!
Marcin



Maybe you are looking for
-
Portege R930 - 1-d 0 Ericsson Mobile Broadband - device H5321GW unknown
Morning all, We bought two Portégé R930 that came pre-installed with Windows 7 pro,We have upgraded to Windows 7 Enterprise,I downloaded the drivers and installed them fine, but I have problems with is the Ericsson H5321GW for Toshiba Broadband USIM
-
M30x-118 DVD not read and write all formats
Having problem with m30x-118 (Mat * a uj-820 s). It is not reading the cd - r/rw and DVD + r/rw but read commercial perfectly all cd/dvd - like video dvd or toshiba installation cd.While trying to open the disc - "d:\ is not accessible incorrect func
-
Hello I need measure the frequency of the signal sinuoidal that is developed by using LabVIEW FPGA. I tried to use the block analog measurement period.The value that I used are: 0 threshold, hysteresis 0.5.However, no matter what the frequency, the p
-
Microsoft will never ask me to send my Windows license key to them?
Is there any situation (home or business) where Microsoft send me a Windows license key will be asked? Or such a request will be a scam?
-
When I try to download my xbox controller, it says cannot find a volume for the extraction of the file. Please make sure you have the required permissions. What - what this means and how I can solve it? * original title - cannot find a volume for the