Export InDesign text in a text file with paragraph styles
Hello
is it possible to export text in InDesign in a text file with included paragraph styles?
I want not only to include the formatting of the text that I must have still all paragraph styles applied to the text after the export.
Thank you
With the text tool in the ready to type text block. Choose file > export > RTF (Rich Text Format)
For all text to export text all images must be strung. If they don't you will have to do them individually.
If you just want a select few paragraphs then highlight and choose then export > RTF
Which can be opened in Word with all styles of tact.
It is unclear with your workflow is here, can you elaborate on what you are trying to do?
Tags: InDesign
Similar Questions
-
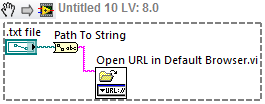
How to open a text file with Notepad to labview vi?
Hello
How can I run a program of a vi?
I want to open a text file with Windows7-block-notes after a file-path-control selelecting and pressing a button.
Thx for the help
Another option is the URL opened in VI of default browser located in the HUD assistance. If you use the path to the string function, you can feed the result as a URL, and the Windows shell knows the default program-oriented, which is Notepad.
Edit-
-
Hello
for my test application, I want to store test data in a text file with header. It should be like this:
name, series, count, current, min. Max run
Mister Smith
1234567890
111
10
1000
data:
1 345 34
2 355 23
3 360 34
...
The first row are only on the lines of header information. ' data: ' is the beginning of the data marker. The data consists of a number, the average value of the current regulation time in s.
Now I write an array of strings in the file text, but if the length of the header of Exchange I overwrite the data. For example, the name is Mister John Smith.
In my program, I can create a new file with header and I cannot change the header later. In the routine of the measure, I put the data in the file.
How can I solve this?
Thank you
Schwede
Hallo Schwede,
Here is an example:

Carefule and do a few checks, at this time, it will reduce 'your comments' when it exceeds 512 bytes...
-
Multi load: error downloading the text file with more than 5 times
Hi all
I am getting below error while trying to load a text file with more than five periods of data through Multi charge.
" File can not be treated because the number of specified periods exceeds the available periods!" ".
FLTFILE_TO_PLANNING3
BUDGET
30/04/2013
6
Q.
A, C, UD1 UD2 UD3, UD4, UD5, UD6, UD7, UD8, V, V, V, V, V, V
AC_11102, CC_104204, Local, year 0, target, Final Budget, SA_000000, P_000001, HSP_InputValue, entry, 60, 70, 80, 90, 100, 110
AC_11102, CC_104207, Local, year 0, target, Final Budget, SA_000000, P_000000, HSP_InputValue, entry, 60, 70, 80, 90, 100, 110
AC_12542, CC_102101, Local, year 0, target, Final Budget, SA_000000, P_000000, HSP_InputValue, entry, 60, 70, 80, 90, 100, 110
AC_11102, CC_113242, Local, year 0, target, Final Budget, SA_000000, P_002478, HSP_InputValue, entry, 60, 70, 80, 90, 100, 110
AC_11102, CC_113243, Local, year 0, target, Final Budget, SA_000000, P_000000, HSP_InputValue, entry, 60, 70, 80, 90, 100, 110
AC_17802, CC_113244, Local, year 0, target, Final Budget, SA_000000, P_000856, HSP_InputValue, entry, 60, 70, 80, 90, 100, 110
AC_11102, CC_113511, Local, year 0, target, Final Budget, SA_000000, P_000000, HSP_InputValue, entry, 60, 70, 80, 90, 100, 110
AC_11102, CC_124111, Local, year 0, target, Final Budget, SA_000000, P_000521, HSP_InputValue, entry, 60, 70, 80, 90, 100, 110This file works fine with 5 periods.
Please notify.
APR
Hello
Yes, table period contol FDM was not properly defined. Now it works fine. Thank you very much.
APR
-
Unload tables to text file with delimiter;
I want to empty all table data in a text file with. as a delimiter without applying a | ; || between the fields. Is there a ' select * from myTable ' method;
And this applies to other tables.
Want to run a script every day to ftp to other sources or keep them as backup.
Thanks for your help.You must call the sqlplus from a shell script. Think you're in a windows environment. So you can have something like this
create a run.bat file or command called run.cmd batch file and place the following code in there and save it
This command file will create a new file called run.sql in the c:\ drive which will be managed by sqlplus.
DateTime variable will create value "mmddyyyyhh24miss" (depending on your settings for date format) and be preceded by ".txt".set mydatetime=%date:~0,2%%date:~3,2%%date:~6,4%%time:~0,2%%time:~3,2%%time:~6,2% echo set linesize 124 > c:\run.sql echo set colsep ';' >> c:\run.sql echo set pages 0 >> c:\run.sql echo set head off >> c:\run.sql echo set verify off >> c:\run.sql echo set echo off >> c:\run.sql echo set trimspool on >> c:\run.sql echo set feedback off >> c:\run.sql echo spool c:\%mydatetime%.txt >> c:\run.sql echo select * from tab ; >> c:\run.sql echo spool off >> c:\run.sql echo exit >> c:\run.sql sqlplus -s user/passw0rd@connect @c:\run.sqlNote: You can add all the environment variables with a single instruction set in sqlplus Parry set linesize 124, etc.
But I have separated them for readabilityJust run from the command prompt
c: > run.cmdSee your updated file pending with current datetime.txt and go to the c:\ drive
-
Export to text file paragraph Style
I have an InDesign document (several really), where I would like to extract all the text formatted with a paragraph style to create a glossary.
I looked at ChangeCaseofSelectedStyle ExportAllStories and Dave Saunder trying to cobble something together (my scripting skills are next to zero). I had that day, now I'm stuck and errors.
Any help?
If ((app.documents.length! = 0) & & (app.selection.length! = 0)) {}
myDoc = app.activeDocument;
myStyles = myDoc.paragraphStyles;
myStringList = myStyles.everyItem () .name;
myExportFormatList = ['Text only', 'RTF', 'Text referenced InDesign'];myDialog = app.dialogs.add var ({name: "ExtractParagraphByStyle"})
{with (MyDialog)}
{with (dialogColumns.Add ())}
with (dialogRows.add ()) {}
with (dialogColumns.add ()) {}
staticTexts.add ({staticLabel: "Style of paragraph :"});})
}
with (dialogColumns.add ()) {}
myStyle = dropdowns.add({stringList:myStringList,selectedIndex:0,minWidth:133});)
}
}
with (dialogRows.add ()) {}
with (dialogColumns.add ()) {}
staticTexts.add ({staticLabel: "export as :"}); "})
}
with (myExportFormatButtons = {radiobuttonGroups.add ())}
radiobuttonControls.add ({staticLabel: "Text only", checkedState:true});})
radiobuttonControls.add({staticLabel:"RTF"});)
radiobuttonControls.add ({staticLabel: "InDesign tagged text"});
}
}
}
}
myReturn = myDialog.show ();
If (myReturn == true) {}
Get the values of the dialog box.
myExportFormat = myExportFormatButtons.selectedButton;
myDialog.destroy;
myFolder is Folder.selectDialog ("select a file");.
If ((mondossier! = null) & & (app.activeDocument.stories.length! = 0)) {}
myExtractParagraphByStyle (myExportFormat, myFolder);
}
}
else {}
() myDialog.destroy; s
}
}myExportStories function handles the export of the stories.
myExportFormat is a number between 0-2, where 0 = text only, 1 = 3 = tagged text and rtf.
myFolder is a reference to the folder in which you want to save your files.
function myExtractParagraphByStyle (myExportFormat, myFolder) {}
for (myCounter = 0; myCounter < app.activeDocument.stories.length; myCounter ++) {}
monarticle = app.activeDocument.stories.item (myCounter);
myID = myStory.id;
{Switch (myExportFormat)}
case 0:
myFormat = ExportFormat.textType;
myExtension = 'txt '.
break;
case 1:
myFormat = ExportFormat.RTF;
myExtension = ".rtf".
break;
case 2:
myFormat = ExportFormat.taggedText;
myExtension = 'txt '.
break;
}
myFileName = "StoryID" + myID + myExtension;
CheminMonFichier = myFolder + "/" + myFileName.
myFile = new File (myFilePath);
myStory.exportFile (myFormat, myFile);
}
}
+++ Functions start here +++function errorExit (message) {}
If (arguments.length > 0) {}
If (app.version! = 3) {beep()} / / CS2 includes beep() function.
Alert (message);
}
Exit(); CS ends with a beep; CS2 left silently.
}The example script, export all the text to the file might give you some clues:
ExportAllText.jsx
An InDesign CS4 JavaScript
//
Export all the text in the active document with a single
text file. To do this, the script will create a new document,
combine the stories in the new document using export/import
and then export the text into the new document.
main();
main() {} function
mySetup();
mySnippet();
myTeardown();
}
function mySetup() {}
myDocument var = app.documents.add ();
myDocument.viewPreferences.horizontalMeasurementUnits = MeasurementUnits.points;
myDocument.viewPreferences.verticalMeasurementUnits = MeasurementUnits.points;
myDocument.viewPreferences.rulerOrigin = RulerOrigin.pageOrigin;
myPage var = myDocument.pages.item (0);
var myTextFrameA = myPage.textFrames.add ();
myTextFrameA.geometricBounds = [72, 144, 72, 288];
myTextFrameA.contents = 'This is story 1.';
var myTextFrameB = myPage.textFrames.add ();
myTextFrameB.geometricBounds = [72, 300, 228, 288];
myTextFrameB.contents = 'This is the story 2.';
var myTextFrameC = myPage.textFrames.add ();
myTextFrameC.geometricBounds = [72, 444, 312, 288];
myTextFrameC.contents = 'This is the story of 3.';
}
function mySnippet() {}
//
If (app.documents.length! = 0) {}
If (. stories.length app.documents.item (0)! = 0) {}
myExportAllText (app.documents.item (0) .name);
}
}
//
}
function myTeardown() {}
}
//
function myExportAllText (myDocumentName) {}
var monarticle;
File name for the exported text. Specify a valid file on your system path.
var myFileName = "/ c/test.txt ';
If you want to add a line of separation between the floors, myAddSeparator set to true.
var myAddSeparator = true;
var myNewDocument = app.documents.add ();
var app.documents.item (myDocumentName) = myDocument;
var myTextFrame = myNewDocument.pages.item (0).textFrames.add ({geometricBounds:myGetBounds (myNewDocument, myNewDocument.pages.item (0))});
var myNewStory = myTextFrame.parentStory;
for (myCounter = 0; myCounter)< mydocument.stories.length;="">
monarticle = myDocument.stories.item (myCounter);
Export the story as tagged text.
myStory.exportFile (ExportFormat.taggedText, leader (myFileName));
Import (place) the file at the end of the temporary history.
myNewStory.insertionPoints.item(-1).place (File (myFileName));
If the imported text does not end with a return, enter a return
to keep the stories running together.
If (myCounter! = myDocument.stories.length-1) {}
If (myNewStory.characters.item(-1).contents! = '\r') {}
myNewStory.insertionPoints.item(-1).contents = "\r";
}
if(myAddSeparator == true) {}
myNewStory.insertionPoints.item(-1).contents = '-\r ";
}
}
}
myNewStory.exportFile (ExportFormat.taggedText, File("/c/test.txt));
myNewDocument.close (SaveOptions.no);
}
//
function myGetBounds (myDocument, myPage)}
var myPageWidth = myDocument.documentPreferences.pageWidth;
var myPageHeight = myDocument.documentPreferences.pageHeight
if(MyPage.Side == PageSideOptions.LeftHand) {}
var myPage.marginPreferences.left = myX2;
myX1 = myPage.marginPreferences.right var;
}
else {}
var myPage.marginPreferences.left = myX1;
myX2 = myPage.marginPreferences.right var;
}
var myY1 = myPage.marginPreferences.top;
myX2 var = myPageWidth - myX2;
var myY2 = myPageHeight - myPage.marginPreferences.bottom;
return [myX1, myY2, myY1, myX2];
} -
Is there a way to open the text files with arbitrary extensions?
As part of the mobile platform iOS, is possible to open arbitrary text files that have an arbitrary extension? For example, in the course of my work day, I meet regularly with plain text files that have an .out extension. I'd love to be able to open these simply with iOS notes without renaming them in .txt. I meet many of them and only need to do this for a few minutes, so take the time to rename them significantly adds both.
On the desktop a BONE can generally "open with", then choose the application. I'm looking for the equivalent in iOS. Please note that to access the files on iOS is not a problem with icloud drive, dropbox, etc.. they just can not be opened easily. Simple text editor, word processor not full blown.
You will need a software that can handle the file.
Usually the file management applications can manage any type of file. I like the 5 Documents to Readdle, it can open almost anything.
https://iTunes.Apple.com/us/app/documents-5-file-system-PDF/id364901807?Mt=8
The equivalent of 'Open with' in the iOS is "open in", 'Share xxx' or even 'Copy To '.
How to get to it, depends on where the file is located.
ICloud drive for example, you can do open the file in a specific application by holding your finger on the icon of the file and by selecting more «...» "in the menu that appears, and then selecting"Share point... ". "and finally select an application from the list.
-
AppleScript - extraire extract values from a table, create a text file with these values
Hello world
Lets say I have a table that looks a bit like this

And this table I would create 2 text files (or even more, depending on how many switchnames are there) who look a bit like these


Is it still possible?
I suppose to create a Service (which can be called in numbers) with Automator which includes an Applescript script - but - no idea since the script is not one of my strong suits.
There is not need to be perfect, because tables are not necessarily the model presented above - so to tweek the script to the application will be necessary. The text files can be created/saved in the same folder as the file numbers is in.
Y at - it script-genius out there?
See you soon
Florian
Select the column of fist of the data, and then run this script by copying the Forum and paste it into the script editor. The files will appear on the desktop
say application "Numbers".
say front document to tell the worksheet active
say ( class is worn) fromfirst table whose selection range
selectionRange defined in column 1 of the selection
set cnt to 0
the value destRange for range
the value currentList to {}
-the list of switches
Repeat with acellule in selectionRange cells
-say acellule to set the value on the NTC
pass the value to the value of cell
if and ((cnt > 0) (switch is not missing value) and (currentList is not contain switch)) then
switch and the value in the currentList currentList
end if
NTC put to the cnt + 1
end Repeat
-Display dialog box "to the list of items is:" & currentList & "a list" & (currentList County) ".
Repeat with aswitch in currentList
" game textOut to '# Script generated with Applescript for switch' & aswitch &"
# on "& (today's date) &"
!
conf t
"
set cnt to 0
Repeat with acellule in selectionRange cells
-say acellule to set the value on the NTC
pass the value to the value of cell
-Display dialog "aswitch is []" & aswitch & "] and switch is []" & switch & "]".
if (aswitch contains the switch) then
the value cellCol to address a column of first cell of acellule
address of line of first cell value cellRow in of acellule
value to the aport (value of the cell of the column (cellCol + 1) cellRow) integer
the value vlan for the (value of the cell cellRow of column (cellCol + 2)) integer
the value desc to the (value of the cell cellRow of column (cellCol + 3))
" put to textOut textOut &.
!
"" IG 1/0 interface / "& aport &.
switchport mode access
switchport access vlan "" & vlan & ""
Description LINK TO "" & desc & ""
"
on the other
-Display dialog box "did not: []" & aswitch & "] and []" & switch & "]".
end if
NTC put to the cnt + 1
end Repeat
Set myFile to open for access (path to the Office as text) & aswitch & '_output.txt' the with write permission
textOut write to myFile
MyFile close access
end Repeat
end say
end say
end say
-
Reading of the text files with mixed data types.
I was able to read a text file ASCII with different types of numbers (whole, real) and the chains are associated. However, I can't read a timestamp that is in the calendar and the clock for carpet (dd/mm/yy HH). In view of the line
34 03/26/12/11 01:23:45 56 78 90
I want to read the time directly, but so far all I can do is read the date and time as a string. If the reading string is the best I can do, how to convert a value of internal time?
No need to separate the date/time string in two different things. Do it in one fell swoop.

-
Download text files with non-English characters
I use an Apex page to download text files. Can I retrieve the contents of the wwv_flow_files.blob_content files and convert them into varchar2 with utl_raw.cast_to_varchar2, but the characters like o, to, u become garbage.
What could be the problem? Characters lost when files are stored in wwv_flow_files or when I do the conversion?
Some other info:
* I don't see wwv_flow_files. DAD_CHARSET has the value 'ascii', wwv_flow_files. FILE_CHARSET is null.
* Try utl_raw.cast_to_varchar2 (utl_raw.cast_to_raw ('aoeu')) returns "aoeu" correctly;
* NLS_CHARACTERSET setting is AL32UTF8 (not only English ASCII)Hello
Take a look at the csv upload - suggestion required with characters non-English in the csv file , it might help you.
Thank you
Manish -
Mapping of the 2 text files with conditions
Hello
Just trying to get my head around what would be the best solution that could be implemented in ODI with the next task I.
I have 2 text files, that the first file is in the format
AccCode | ChildCodeStart | ChildCodeFinish
1000-1099 B1000
1100-1199 B1001
The second text file
ChildCode | Alias
1000 depenses1
1001 depenses2
1100 available1
1101 disponibles2
The logic is now that I want to AccCode the first map file and match all the codes in the file two which are between ChildCodeStart and ChildCodeFinish
So my output
AccCode | ChildCode | Alias
B1000 1000 depenses1
B1000 1001 depenses2
B1001 1100 available1
B1001 1101 disponibles2
I don't know what would be the best route for this in ODI, I should load the files in the tables first or can make directly via an interface?
Thanks for any help
JohnHello
Yes, it is necessary to use a package... Sorry I forgot to mention. The package defines the 'stream of action '.
Good to hear it works...
Cezar Santos
-
How to write graph of waveform data to text file with the option to the user to do
So, I'm new to labview and will have bad to write a program in particular. I have a waveform graph that runs for 120 seconds, generating a sine curve. I am, however, having a time difficult get the program to write the x and are coordinated in a text file. I've attached what I have so far.
The first task I was assigned was to write a program that creates a curve of snusoidal on the front panel by adding a data point every half second for 120 seconds. The plot should starts only if the user presses a button to start.
The next part is to give the user an option to write the data generated in a file of worksheet called 'sine.txt '. The file name and location should be hard-coded. The file must contain the x and there contact information of each data point in columns separated by tabs, also known as the delimited.
I spent several hours refining the attached program, and I can't seem to make it work right. Any suggestions would be helpful at this stage.
Sincerely,
A student of chemistry frustrated whose research mentor is out of town

First, you create files Excel. You create text files. And it seems that your writing on a file already created X (time) vs Y (curve of data) that is delimited by tabs.
All you do is simply too complicated or a Rube Goldberg.
All you need is the joint.
-
How to read a text file with line breaks
Hello
I'm reading a text file in a textFrame. We read in, but does not include line breaks is just a big long line of text. I use the following code to read the file. I tried to insert a \n character after each readln() but that has not helped. I also tried to create a variable that the readln() was crammed in before setting the textFrame.contents variable, but which does not work either. I'm puzzled. Any help would be appreciated, thanks.
While (! notesDoc.eof) {}
noteTextRef.contents += notesDoc.readln ();
}Doug
Just use fileObect.read () instead of fileObect.readln () / / read online also try to use instead of \n \r
-
Script Export single Pages with the name and file custom paragraph Style?
I have a document called "mydocument".
I have a several pages in the document.
Each page has a title of"style with a stylesheet called point title.
I need to export each page as individual .jpg with a custom file name
myDocument-01 - title.jpg
01 is the page number
Seemed like a simple request... but it turns out that it's a little challenging.
This scipt below, that I found on another thread a little work
It gives me a
Title1.jpg
But I can't figure out how...
1. Add the name of "mydocument".
2. have a 0 on the 1-digit numbers
Can someone please guide me, I would be eternally grateful.
if (app.documents.length != 0) { var myDoc = app.activeDocument; MakeJPEGfile(); } else{ alert("Please open a document and try again."); } function MakeJPEGfile() { for(var myCounter = 0; myCounter < myDoc.pages.length; myCounter++) { if (myDoc.pages.item(myCounter).appliedSection.name != "") { myDoc.pages.item(myCounter).appliedSection.name = ""; } var myPageName = myDoc.pages.item(myCounter).name; var myJpegPrefix = ""; var isStyleExist = true; //Checking the existing of the paragraph style (filename) try { myDoc.paragraphStyles.item("title"); } catch (myError) { isStyleExist = false; } if (isStyleExist) myJpegPrefix = getParagraphContent(myDoc.paragraphStyles.item("title"), myDoc.pages.item(myCounter)) + myPageName; app.jpegExportPreferences.jpegQuality = JPEGOptionsQuality.high; // low medium high maximum app.jpegExportPreferences.exportResolution = 72; app.jpegExportPreferences.jpegExportRange = ExportRangeOrAllPages.exportRange; app.jpegExportPreferences.pageString = myPageName; var myFilePath = "~/-client/JOYS - Just Organize Your Stuff/-Art/-art-book-kindle/" + myJpegPrefix + ".jpg"; var myFile = new File(myFilePath); myDoc.exportFile(ExportFormat.jpg, myFile, false); } } // The new function, but needs to add checking the file name rules. function getParagraphContent (paragraphStyle, currentPage) { var paragraphContent = null; for (var c = 0; c < currentPage.textFrames.length; c++) { for (var i = 0; i < currentPage.textFrames.item(c).paragraphs.length; i++) { if (currentPage.textFrames.item(c).paragraphs.item(i).appliedParagraphStyle == paragraphStyle) { paragraphContent = currentPage.textFrames.item(c).paragraphs.item(i).contents; // Remove spaces and returns at the end: paragraphContent = paragraphContent.replace(/\s+$/, ''); // Replace remaining spaces with hyphen: paragraphContent = paragraphContent.replace(/\s+/g, '-'); // Make lowercase: paragraphContent = paragraphContent.toLowerCase(); return paragraphContent; } } } return paragraphContent; }Thank you Mi!
One more step.
I just need to remove the extension .indd.
My file name is now
myDocument.indd - 01 - title.jpg
If (app.documents.length! = 0) {}
myDoc var = app.activeDocument;
MakeJPEGfile();
}
else {}
Alert ("Please open a document and try again.");
}
function MakeJPEGfile() {}
for (var myCounter = 0; myCounter< mydoc.pages.length;="" mycounter++)="">
If (. appliedSection.name myDoc.pages.item (myCounter)! = "") {}
myDoc.pages.item (myCounter).appliedSection.name = "";
}
var myPageName = myDoc.pages.item (myCounter) .name;
var myJpegPrefix = "";
var isStyleExist = true;
Audit of the existing paragraph style (filename)
try {}
myDoc.paragraphStyles.item ("title");
}
{} catch (MonErreur)
isStyleExist = false;
}
If (isStyleExist)
myJpegPrefix = getParagraphContent (myDoc.paragraphStyles.item ("title"), myDoc.pages.item (myCounter)) + '-0 "+ myPageName;
app.jpegExportPreferences.jpegQuality = JPEGOptionsQuality.high; low medium high maximum
app.jpegExportPreferences.exportResolution = 72;
app.jpegExportPreferences.jpegExportRange = ExportRangeOrAllPages.exportRange;
app.jpegExportPreferences.pageString = myPageName;
var CheminMonFichier = "" ~/-client/JOYS - just organize your Stuff Art / /-art-book-kindle / "+" / "+ myDoc.name +"-"+ myJpegPrefix +".jpg";
var myFile = new File (myFilePath);
myDoc.exportFile (ExportFormat.jpg, myFile, false);
}
}
The new feature, but it will add filename rules checking.
function getParagraphContent (paragraphStyle, currentPage)
{
var paragraphContent = null;
for (var c = 0; c)< currentpage.textframes.length;="">
{
for (var i = 0; i)< currentpage.textframes.item(c).paragraphs.length;="">
{
If (currentPage.textFrames.item (c).paragraphs.item (i) .appliedParagraphStyle is paragraphStyle)
{
paragraphContent = currentPage.textFrames.item (c).paragraphs.item (i) .silence;
Remove the spaces and returns at the end:
paragraphContent = paragraphContent.replace (/ \s+$ /, ");
Replace the remaining spaces with hyphen:
paragraphContent = paragraphContent.replace (/ \s + / g, '-');
Make lowercase:
paragraphContent = paragraphContent.toLowerCase ();
Return paragraphContent;
}
}
}
Return paragraphContent;
}
-
Possible bug with paragraph styles?
Make a page with three breakpoints
Add a block of text for the breakpoint
Type "The CO2 is carbon dioxide" in text
Format of the text frame in red "BOLD" (from the text window)
Click on 'Create a new style of the applied attributes' (in the window paragraph styles)
Apply the new style to two other break points
Select the number 2 in the largest block of breakpoint text and format it as a script (from the text window)
Select the text block, and then select 'Copy the formatting of the text-> all breakpoints'
Check that all three break points seem correct
Save the Muse site
Narrow muse site
Site open from muse
Note that the formatting has been removed from all three break points
Anyone else do this?
The only workaround that I understood is not to copy text formatting to all the break points. He made the very tedious text formatting, but seems to work.
Hi williamb72631036,
I am able to reproduce the problem. You certainly found a bug, and I think you're right that this has to do with the help of "copy the text formatting of...» ». I can actually reproduce the bug without the help of paragraph styles.
The only workaround that I understood is not to copy text formatting to all the break points. He made the very tedious text formatting, but seems to work.
Rather than use the copy text formatting at all breakpoints, try switching the tool "4 t / 1 t" text in all of the breakpoints.

When the setting is "4t" (as in the screenshot), then any changes you make to the text attributes are automatically applied through breakpoints. Just be sure to return it 1 "t" If you need to make a change in a specific breakpoint. Note that this is a comprehensive framework for setting and not by text.
I hope this helps! And thanks for reporting this issue with clear steps.
Anna




Maybe you are looking for
-
I use OS x 10.11.5. The set automatic Letter Wizard in place my email with the erroneous e-mail servers IMAP account. I use a POP3 account on the servers 'brighthouse '. Now my account sues IMAP servers "TWC" for mail entering and leaving. I also hav
-
G6-2231tx Pavilion: warranty expired
I had my warranty due to expire July 31, 2016. And I got my network card was replaced on July 29, 2016. After a week of card replacement, it began to cause problems. I was told that because if the modified part causing problemwithin 3 months from the
-
I bought this PC in July 2011 and it is out of warranty. After that of being harassed at level to Windows 10 months I decided to do it, but rather than the upgrade, I did a clean install from the laptop was malfunctioning. I read on the Microsoft s
-
Satellite A200 PSAE6E: Impossible to install the audio drivers after installing Win XP realtek
Hello... Recently, I repartitioned my laptop HD to install XP and kubuntu (it came with vista)... However, I was not able to install audio drivers for its audio devices... The laptop is a toshiba Satellite A200-PSAE6E and everest indicates the follow
-
admin password necessary for "A Basic Guide to migrate to Mac-Intel?
I will not be setting up a new mac tomorrow, and I read this guide. A Basic Guide to the migration of files from one computer to another The person whose Mac is probably does not know the password and certainly do not have a disc of Tiger. (She may h