find the average of each 500 values in a column [text file]
Please help, I have a text file with three columns of integer values of hv. I need to take 500 values in each column and replace them with their average.
A particular work if it could probably be simplified. Here are a few ideas... Many things could be improved even more.
Tags: NI Software
Similar Questions
-
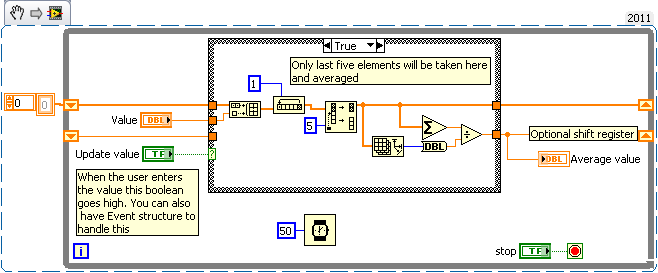
Find the average value of a buffer
Hello
In my VI Panel, I have a digital control, a button and a digital display.
When the user, enter a number in numerical order and press the button, the digital display should show the average value of all the past 5 values entered in the digital control, for example:
1st entry: 10-online average = 10 (as sum = 10)
2nd type: 0-online average = 5 (as sum = 10 + 0 = 10)
3rd enter: 5-online average = 5 (you get the idea...)
4 enter: 1-average online = 4
5 enter: 14-online medium = 6
6 enter: 2-online average = 4.4 (sum = 0 + 5 + 1 + 14 + 2 = 22, because the 1st value is thrown)
How to write this VI?
Thank you!!
You can also use arrays to hold the data in a registry change and find the average value of the last five items.
Good luck
-
Find the average of a set of times
Hi all
I have a spreadsheet with 52 pages (weeks of the year, sort of a planner) and every day I type in my wake-up time. Until the end of the week there are 7 times, then a column that has successfully made the average at that time. (see below) using this formula: AVERAGEIF(A3:G3,">5:59",A3:G3)
I intentionally do include only periods after 05:59 in the formula.

As you can see it does that very well. All the averages for each week are then sent to an "annual" table on another page (see below)

The problem when coming to this second table, each average weeks appears in the average annual table always shows the last time which was received (in this case, 09:22). In other words, it does not indicate the average. The formula I use for this table is: AVERAGEIF(C2:BC2,">5:59",C2:BC2)
So what on earth am I doing wrong?
Thank you :-)
I can't read anything in the second table you have posted... it's too small.
Perhaps to show how the weekly averages go weekly table at the annual table.
-
[HE] can I find the average Dove / invoices?
Nel pannello di controllo sono presenti transazioni solo mio, inutili finished tax, Dove posso find the average full di partita IVA mia e di Adobe?
Where can I find invoices with VAT codes to my membership of the CC?
OK solved, my fault. I have to go to adobe.com to creative.adobe.com... Thank you
-
How do you find the average value of all the data between two points on a single channel
I'm tring to calculate the average value of all data points in a single field between two distinct points
I rasthaus an illustration.
Hi smoothdurban,
I thought you wanted to specify the area of interest with the sliders of the band. If you rather automatically define the area of interest based on thresholds, etc., we cannot see the interactive nature of the example I sent.
What are the criteria used to determine the start and end of the region of interest lines?
I would be able to type this out for you if you sent a representative data set ([email protected])
Brad Turpin
Tiara Product Support Engineer
National Instruments
-
Need help finding the average across lines
Hi all
I have a requirement to find a way to several columns in a row. The trickiest part is it may or may not be a value in each of the lines and the average must be calculated for those that have a value. Let me give you an example:
col1 col2 col2, col4
1 NULL 3 5-> average will be (1 + 3 + 5) / 3 = 3
NULL NULL 2 4-> average will be (2 + 4) / 2 = 3.
A (acc to me dump) option is to get the entire file in the variable % ROWTYPE, scan through each of the columns, see if the value is not null and greater than 0, increment the counter (i) and calculate the sum. Finally make a sum / I. An average was 215 columns that it takes on average and having a separate if end seems illogical. There must be a smart solution to find this kind of average. Help, please.
Thank you
AristidesHey,.
SELECT (nvl (col1, 0), nvl (col2, 0), nvl (col3, 0) + nvl (col4, 0)) / (nvl2 (col1, 1, 0) + nvl2 (col2, 1, 0) + nvl2 (col3, 1, 0) + nvl2 (col4, 1, 0))
Table_name FROMI hope this helps.
-Annick
-
find the longest series of equal values in table
Hello
I had an array with Boolean values, something like this
[TTFFFFFFFFFFFFTTFFTTT]
and I need to find the longest window were the elements of the array is equal, in the above example, I want to find the index 2 and length 12 for longer window F and index 18, length 3 to T. everyone who has an idea how I can do this?
Hello Tudor,
There is so far, I don't know any loan service in labview to do what you want. However this seems not really hard to do.
You can link your table for a loop and to compare with each iteration, the current Boolean value to the previous. If the two are combined, for example, you can increment a counter until one is true and the other false. Then you can record the length in a separate shift register if this length is greater than pre-existing (initialize to 0).
On the index, you can save the terminal in the County of the foor in a turn loop register when the value N-1 of your table is different from the value of N, the following difference, if the length is the longest, you save this count minus one in another register.
I hipe this helps you.
Concerning
-
Hey,.
I have a table with two columns: FILE_ID (NUMBER), ARRIVAL_TIME (TIMESTAMP).
I want to understand the ARRIVAL_TIME medium of a given file. I can't find how to do this. When I try to run the following:
SELECT AVG (V.ARRIVAL_TIME)
FILE_ARRIVALS V WHERE FILE_ID = SOME_NUMBER
I get this error:
ORA-00932: inconsistent data types: expected NUMBER obtained TIMESTAMP
I found a lot of examples to get the average period between two dates or timestamps, but they didn't fit my needs.
Thank you!
Jeffrey Kevin Pry
Published by: jeffrey.pry on August 19, 2010 05:44If you are looking for just the time of day, then you might do something like:
SQL> WITH t AS ( 2 SELECT 1 file_id, sysdate arrival_time FROM dual UNION ALL 3 SELECT 1, sysdate + 1 FROM dual UNION ALL 4 SELECT 1, sysdate - 2 FROM dual UNION ALL 5 SELECT 2, sysdate - 3 FROM dual UNION ALL 6 SELECT 2, sysdate FROM dual) 7 SELECT file_id, TO_DATE(AVG(time_secs), 'sssss') 8 FROM (SELECT file_id, TO_NUMBER(TO_CHAR(arrival_time, 'sssss')) time_secs 9 FROM t) 10 GROUP BY file_id; FILE_ID TO_DATE(AVG(TIME_SEC ---------- -------------------- 1 01-aug-2010 08:57:14 2 01-aug-2010 08:57:14John
-
Where to find the log of PIF in 10.3.4.1 version file
OBIEE 1.3.4.1 on Linux. I put the server Debug = Debug level Configuration option. But where can I find the error log file. I often see error
When set up a report, where can I find the error log?The report cannot be rendered because of an error, please contact the administrator.
Search the furom and find a post talking about 11g in the log file.
But it is not the case in 10.3.4.1.Found it. BIEE_HOME\user_projects\domains\bifoundation_domain\servers\bi_server1\logs\bipublisher
Thank you very much for the help.Hello
Please take a look at this post:
http://bipconsulting.blogspot.com/2010/01/bi-Publisher-logging-debugging-part-3.htmlIf your question has been answered then please give the points and close the message
Thank you
Jorge
-
I have a user who normally can drag the Firefox download window files in an e-mail message in Outlook and creates this file as an attachment in the e-mail message. However, in recent times, the moved .pdf or other record shows only upward as a location of text file as:
\\file:%downloads%\randomfile.PDF
It is not a link, it's just text.
I tried to do a repair of Microsoft Outlook.
I uninstalled and reinstalled Firefox 19.
I tried dragging items from the Office to the e-mail and it works fine.
I can't drag and drop downloads to the desktop window.I just wanted to add that this user is using Windows XP Pro.
I just tried to back off at 18 and it works very well.
As for your question Xtinch, I tried to disable all addons in Outlook and Firefox and the problem still occurs. At this point I'm very convinced that it is a bug in Firefox, 19-20.
-
Find the average time required to process an order?
Hello
I followed four tables.
The data in TABLE COMPANY_ORDER_HISTORY or COMPANY_ORDER_HISTORY_ARCH of the TABLE can be used as below:/* There are other columns as well but just using the relevent columns.*/ CREATE TABLE COMPANY_ORDERS ( INTERNALORDERID NUMBER(10) NOT NULL, ORDERENTRYDATE DATE, SYSTEMID NUMBER(10) ) /* There are other columns as well but just using the relevent columns.*/ /* The data in archive table goes after each three months.*/ CREATE TABLE COMPANY_ORDERS_ARCH ( INTERNALORDERID NUMBER(10) NOT NULL, ORDERENTRYDATE DATE, SYSTEMID NUMBER(10) ) /* There are other columns as well but just using the relevent columns.*/ CREATE TABLE COMPANY_ORDER_HISTORY ( INTERNALORDERID NUMBER(10) NOT NULL, ITEMORDER NUMBER(10) NOT NULL, ENTRYDATE DATE NOT NULL, UPDATEDATE DATE, STATUSID NUMBER(10), INTERNALSTATUSID NUMBER(10) ) /* The data in archive table goes after each three months.*/ CREATE TABLE COMPANY_ORDER_HISTORY_ARCH ( INTERNALORDERID NUMBER(10) NOT NULL, ITEMORDER NUMBER(10) NOT NULL, ENTRYDATE DATE NOT NULL, UPDATEDATE DATE, STATUSID NUMBER(10), INTERNALSTATUSID NUMBER(10) )
Every day an order number is raised through different systems (identified by COMPANY_ORDERS. SYSTEMID). Now I need to find a day average time an order made, by SYSTEMID to reach a final statusid 7 (x), internalstausid 1430 (y) of his first entrytime in COMPANY_ORDER_HISTORY (IE for an orderid, the first entry of COMPANY_ORDER_HISTORY founded in updatedate or for an orderid, or the entrytime for an orderid when ITEMORDER = 1)SET DEFINE OFF; Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179058, 8, TO_DATE('08/03/2009 11:40:00', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 11:40:00', 'MM/DD/YYYY HH24:MI:SS'), 7, 1360); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179058, 10, TO_DATE('08/03/2009 11:42:16', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 11:42:16', 'MM/DD/YYYY HH24:MI:SS'), 7, 1430); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179180, 1, TO_DATE('08/03/2009 10:21:30', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 10:21:30', 'MM/DD/YYYY HH24:MI:SS'), -3, -3); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179180, 3, TO_DATE('08/03/2009 10:25:06', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 10:25:06', 'MM/DD/YYYY HH24:MI:SS'), 0, 0); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179180, 14, TO_DATE('08/03/2009 11:40:00', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 11:40:00', 'MM/DD/YYYY HH24:MI:SS'), 7, 1360); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179180, 16, TO_DATE('08/03/2009 11:42:17', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 11:42:17', 'MM/DD/YYYY HH24:MI:SS'), 7, 1430); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179184, 1, TO_DATE('08/03/2009 10:21:33', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 10:21:33', 'MM/DD/YYYY HH24:MI:SS'), -3, -3); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179184, 3, TO_DATE('08/03/2009 10:25:09', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 10:25:09', 'MM/DD/YYYY HH24:MI:SS'), 0, 0); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179184, 14, TO_DATE('08/03/2009 11:40:00', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 11:40:00', 'MM/DD/YYYY HH24:MI:SS'), 7, 1360); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179184, 16, TO_DATE('08/03/2009 11:42:18', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 11:42:18', 'MM/DD/YYYY HH24:MI:SS'), 7, 1430); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179185, 1, TO_DATE('08/03/2009 10:21:33', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 10:21:33', 'MM/DD/YYYY HH24:MI:SS'), -3, -3); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179185, 3, TO_DATE('08/03/2009 10:25:09', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 10:25:09', 'MM/DD/YYYY HH24:MI:SS'), 0, 0); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179185, 14, TO_DATE('08/03/2009 11:40:00', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 11:40:00', 'MM/DD/YYYY HH24:MI:SS'), 7, 1360); Insert into COMPANY_ORDER_HISTORY (INTERNALORDERID, ITEMORDER, ENTRYDATE, UPDATEDATE, STATUSID, INTERNALSTATUSID) Values (8179185, 16, TO_DATE('08/03/2009 11:42:17', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('08/03/2009 11:42:17', 'MM/DD/YYYY HH24:MI:SS'), 7, 1430); COMMIT;
Tables of archive can be reunited if the fake of the length of the period for which the order is archived.
Another desired suggestion is table archive is very large.
It will be appropriate to create a materialized view archived table, not seen that data last month and then join the Materialized view query (since the statistics must be shown to last a year...)?
Concerning
Published by: a R on October 28, 2009 06:02
Published by: a R on October 28, 2009 14:13Hello
First, initialize variables bind using some PL/SQL like this:
-- These parameters are passed by the user: VARIABLE p_statusid NUMBER VARIABLE p_internalstatusid NUMBER VARIABLE p_start_date VARCHAR2 (10) VARIABLE p_end_date VARCHAR2 (10) -- These parameters are derived from the ones that are passed: VARIABLE p_date_trunc VARCHAR2 (10) VARIABLE p_need_arch NUMBER DECLARE end_date DATE; start_date DATE; BEGIN :p_statusid := 7; :p_internalstatusid := 1430; :p_start_date := '03/08/2009'; :p_end_date := '04/08/2009'; start_date := TO_DATE (:p_start_date, 'DD/MM/YYYY'); end_date := TO_DATE (:p_end_date, 'DD/MM/YYYY'); -- The following parameters could be computed in the query, but it's messier :p_date_trunc := CASE WHEN end_date - start_date <= 1 THEN 'HH' WHEN MONTHS_BETWEEN (end_date, start_date) <= 1 THEN 'DD' WHEN MONTHS_BETWEEN (end_date, start_date) <= 6 THEN 'IW' ELSE 'MM' END; :p_need_arch := CASE WHEN start_date > ADD_MONTHS (SYSDATE, -4) THEN 0 -- dates are all within last 4 months, archive tables are not needed ELSE 1 -- some dates are older than 4 months ago, archive tables are needed END; END; /You don't absolutely have to do that, but it made the query much shorter and cleaner.
The query itself is:
WITH dop AS ( SELECT systemid, internalorderid FROM company_orders WHERE orderentrydate >= TO_DATE (:p_start_date, 'DD/MM/YYYY') AND orderentrydate < TO_DATE (:p_end_date, 'DD/MM/YYYY') + 1 -- UNION ALL -- SELECT systemid, internalorderid FROM company_orders_arch WHERE orderentrydate >= TO_DATE (:p_start_date, 'DD/MM/YYYY') AND orderentrydate < TO_DATE (:p_end_date, 'DD/MM/YYYY') + 1 AND :p_need_arch = 1 ) , coh AS ( SELECT internalorderid , MIN ( CASE WHEN itemorder = 1 THEN entrydate END ) AS h1_entrydate , MAX ( CASE WHEN internalstatusid = :p_internalstatusid AND statusid = :p_statusid THEN entrydate END ) AS hn_entrydate FROM company_order_history WHERE entrydate >= TO_DATE (:p_start_date, 'DD/MM/YYYY') GROUP BY internalorderid -- UNION ALL -- SELECT internalorderid , MIN ( CASE WHEN itemorder = 1 THEN entrydate END ) AS h1_entrydate , MAX ( CASE WHEN internalstatusid = :p_internalstatusid AND statusid = :p_statusid THEN entrydate END ) AS hn_entrydate FROM company_order_history_arch WHERE entrydate >= TO_DATE (:p_start_date, 'DD/MM/YYYY') AND :p_need_arch = 1 GROUP BY internalorderid ) SELECT dop.systemid , AVG (coh.hn_entrydate - coh.h1_entrydate) AS avereagetime , TO_CHAR ( TRUNC (coh.hn_entrydate, :p_date_trunc) -- + (1 / 24) , 'MM/DD/YYYY' || CASE WHEN :p_date_trunc = 'HH' THEN ' HH24:MI:SS' END ) AS periodstartdate FROM dop JOIN coh ON coh.internalorderid = dop.internalorderid GROUP BY dop.systemid , TRUNC (coh.hn_entrydate, :p_date_trunc) ORDER BY dop.systemid , TRUNC (coh.hn_entrydate, :p_date_trunc) ;The conditions
AND :p_need_arch = 1should "short-circuit" queries on the archived tables when it comes from kniown, the: parameter of p_start_date, that they are not necessary.
The coh subquery matches your original of subqueries h1 and h2. It is more effective to go through the tables only once. The WHERE clause in coh contain the conditions common to h1 and h2; conditions that apply only to the h1 or h2 are transferred in CASE expressions.
You always want to group by a date that is truncated. According to the: p_strart_date to: p_end_date Beach, you can truncate the next time down, day, week or month. the only difference is the 2nd argument to the TRUNC function.
When you group by weeks, I used the ISO weeks, which begin Monday and end on Sunday. If you need a different kind of week, it's a little more complicated. -
How to avoid the link of a null value in a column of link
Hello
How to avoid the link of a column with the value zero. Is that the link should be disabled for the column with the value null, and it must be enabled for all that have a value.
Ex
DEPTNO NAME (link column)
10 SCOTT
20 MAC
30 SMITH
40 -
50 SAM
I don't want to link to the value null in the name column, but the name remaining should have link. Please help me.
Kind regards
BarroHello
One way is like this:
1. create a column not displayed, called link_display in your report to return N or Y depending on whether you want the link by adding the SQL report:NVL2(name, 'Y', 'N') link_display2. in the header of the region, define a class for the column name using:
3. for the name column containing the link add link attributes: class = "" display_link_ #LINK_DISPLAY # ""
Rod West
-
Expand the new ID CC 11.4.0.90-column text
Yesterday I've updated IDS and noticed that the selector drop-down list for spanning text columns. Don't know where or how to do something that was so convenient. Can someone help me?
Thank you
EI
He is always there if you have the text tool and the paragraph of the control panel

But it's pretty far to the right, and with the spacing again in the update from yesterday, I wonder if he is too right to be seen? If this is the case, you can get it in the menu in the Control Panel, to the right of the Flash. If it's too much trouble, consider creating a keyboard shortcut (Edition > keyboard shortcuts).

And remember to use a screen resolution higher to show more of the buttons on the control panel.
-
How to find the value duplicate of each column.
I have it here are four columns,
How can I find the duplicate of each columns value.
with All_files like)
Select ' 1000 'like BILL, "2000" AS DELIVERYNOTE, CANDELINVOICE ' 3000', '4000' CANDELIVERYNOTE of all union double
Select ' 5000 ', ' 6000', ' 7000 ', ' 8000' Union double all the
Select '9000 ', '1000', '1100',' 1200' from dual union all
Select ' 1200 ', ' 3400', ' 6700 ', ' 8790' Union double all the
Select ' 1000 ', ' 2000', ' 3000 ', ' 9000' Union double all the
Select '1230', '2340', ' 3450 ', ' 4560' double
)
SELECT * from All_files
Output should be as shown below.
1000 2000 3000 4000
9000 1000 1100 1200
1200 3400 6700 8790
1000 2000 3000 9000
Required to check uniqueness columns.
Thank you.Hello
If you are not too concerned about performance, this should give you the desired result:
SELECT distinct INVOICE, DELIVERYNOTE, CANDELINVOICE, CANDELIVERYNOTE FROM ( SELECT a.*, count(*) over(partition by t.column_value) cnt FROM All_files a, table( sys.odcivarchar2list( a.INVOICE , a.DELIVERYNOTE , a.CANDELINVOICE , a.CANDELIVERYNOTE ) ) t ) WHERE cnt > 1 ; -
Subtract the average of a matrix of each element
Hello
I make a principal components analysis I have an original power of real matrix a matrix of covariance which gives the average to one of the nodes and want that subtract from each element of the matrix to form a new matrix. If it's hard to connect to the average of the covariance matrix is it possible just to find the average of the original matrix, and this by subtracting each element of the matrix to form a new matrix.
Thanks for your help
Concerning
Canalian
The average of a 2D array is simply the sum of all the elements, divided by the number of items (= the product of the dimensions).
All you need is the following (works for arrays with more than 2 dimensions):





Maybe you are looking for
-
Cannot depend on automatic updates
Hey, so a few days ago I started having a popup on my ipad in saying that automatic updates are not enabled on this device, and when I try to turn them on, they just turn off by itself after like 2 seconds. How can I fix it? or at least turn off the
-
HP 8600 (CM749A) supports duplex scanning? (Answer: no)
I can't find this information in the form. HP 8600 (CM749A) (no more, the lowest model) supports duplex (i.e. automatic two-sided) scanning?
-
Hi all I have a small application that consists of reading data from a serial port using the VISA READ function. The data source that I am trying to acquire the serial port is a microcontroller that sends a word or a byte (8bits). However, when you t
-
Received 8000ffff eror message when you try to install kb976932. Microsoft 'Fix it' did not help. If you have a solution, please let me know.
-
info from Bing wallpaper pictures
I like the background screenshots of Bing/Microsoft, which changes every few minutes, but how can I get information about a photo in particular, like where it was taken?