Help for Oracle to use an index
Unfortunately, I'm stuck with Oracle 8i. I have a fairly complex view which, at the time of the call, will have values specified for the columns in the view.The full view will look something like this - even if real life tables are slightly different and a little more complex. (view has been developed [another post | http://forums.oracle.com/forums/thread.jspa?threadID=1043162 & messageID = 4163818 #4163818]):
select a.skuid,
sum(a.qty) qty,
a.lot,
b.status
status
from (
select skuid,
lot,
1 qty,
row_number() over(partition by skuid order by lot) rn
from lot,
(
select rownum rnum
from all_objects
where rownum <= (select sum(qty) from lot)
)
where rnum <= qty
) a,
(
select skuid,
status,
sum(qty) over(order by qty desc) - qty + 1 start_rn,
sum(qty) over(order by qty desc) end_rn
from status
) b
where b.skuid = a.skuid
and a.rn between b.start_rn and end_rn
group by a.skuid,
b.status,
a.lot
order by a.skuid,
b.status,
a.lotFor now, concentrate on the online portion "a":
select skuid,
lot,
1 qty,
row_number() over(partition by skuid order by lot) rn
from lot,
(
select rownum rnum
from row_gen
)
where rnum <= qtyselect skuid, lot, sum(qty) from
(
select skuid,
lot,
1 qty,
row_number() over(partition by skuid order by lot) rn
from lot,
(
select rownum rnum
from row_gen
where rownum <= (select max(qty) from lot)
)
where rnum <= qty
AND SKUID = 'SKUA' -- <--- Note indexed column here
)
group by skuid, lotExecution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=RULE
1 0 SORT (GROUP BY)
2 1 VIEW
3 2 WINDOW (SORT)
4 3 COUNT
5 4 NESTED LOOPS
6 5 VIEW
7 6 COUNT (STOPKEY)
8 7 TABLE ACCESS (FULL) OF 'ROW_GEN'
9 5 TABLE ACCESS (BY INDEX ROWID) OF 'LOT'
10 9 INDEX (RANGE SCAN) OF 'LOT_SKU' (UNIQUE)select skuid, lot, sum(qty) from
(
select skuid,
lot,
1 qty,
row_number() over(partition by skuid order by lot) rn
from lot,
(
select rownum rnum
from row_gen
where rownum <= (select max(qty) from lot)
)
where rnum <= qty
)
WHERE SKUID = 'SKUA' -- <--- Note indexed column here,
-- since inner view will be an Oracle view, not inline view
group by skuid, lotExecution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=RULE
1 0 SORT (GROUP BY)
2 1 VIEW
3 2 WINDOW (SORT)
4 3 COUNT
5 4 NESTED LOOPS
6 5 VIEW
7 6 COUNT (STOPKEY)
8 7 TABLE ACCESS (FULL) OF 'ROW_GEN'
9 5 TABLE ACCESS (FULL) OF 'LOT'So, is it possible to write this request (which will be a view) such as Oracle (8i) realizes he can carry the values specified in the Interior selects and use the index for them?
Published by: kent b on March 16, 2010 08:29
Adding a / * + INDEX() * / index in the Interior, select help a little, but is still nowhere near as fast when the skuid is specified in the internal selection.
Hello
Here is another solution to this problem that uses any CONNECT BY and does not assume that this amount represents an integer.
In your previous thread
Re: Very challenging FINDS to write (call for help)
Solomon has shown how we can avoid "explode" status in units, using a total cumulative.
The solution below does the same thing for many, as well.
SELECT l.skuid
, LEAST (l.max_qty, s.max_qty)
- GREATEST (l.min_qty, s.min_qty) AS qty
, l.lot
, s.status
FROM ( -- Begin in-line view l to get data from lot
SELECT skuid
, lot
, SUM (qty) OVER ( PARTITION BY skuid
ORDER BY SUBSTR (lot, 1, 1)
, TO_NUMBER (SUBSTR (lot, 2))
) - qty AS min_qty
, SUM (qty) OVER ( PARTITION BY skuid
ORDER BY SUBSTR (lot, 1, 1)
, TO_NUMBER (SUBSTR (lot, 2))
) AS max_qty
FROM lot
) l -- End in-line view l to get data from lot
, ( -- Begin in-line view s to get data from status
SELECT skuid
, status
, SUM (qty) OVER ( PARTITION BY skuid
ORDER BY CASE
WHEN status = 'AVAIL' THEN 1
WHEN status = 'RES' THEN 2
WHEN status = 'HOLD' THEN 3
END
) - qty AS min_qty
, SUM (qty) OVER ( PARTITION BY skuid
ORDER BY CASE
WHEN status = 'AVAIL' THEN 1
WHEN status = 'RES' THEN 2
WHEN status = 'HOLD' THEN 3
END
) AS max_qty
FROM status
) s -- End in-line view s to get data from status
WHERE l.skuid = s.skuid
AND l.min_qty < s.max_qty
AND s.min_qty < l.max_qty
ORDER BY l.skuid
, l.max_qty
, s.max_qty
;
Published by: Frank Kulash, March 16, 2010 13:23
It might be easier to manage if we pull the min_qty of the max_qty, like this:
SELECT l.skuid
, LEAST (l.max_qty, s.max_qty)
- GREATEST (l.min_qty, s.min_qty) AS qty
, l.lot
, s.status
FROM ( -- Begin in-line view l to get data from lot
SELECT skuid, lot
, max_qty
, max_qty - qty AS min_qty
FROM ( -- Begin in-line view to get max_qty
SELECT skuid, lot, qty
, SUM (qty) OVER ( PARTITION BY skuid
ORDER BY SUBSTR (lot, 1, 1)
, TO_NUMBER (SUBSTR (lot, 2))
) AS max_qty
FROM lot
) -- End in-line view to get max_qty
) l -- End in-line view l to get data from lot
, ( -- Begin in-line view s to get data from status
SELECT skuid, status
, max_qty
, max_qty - qty AS min_qty
FROM ( -- Begin in-line view to get max_qty
SELECT skuid, status, qty
, SUM (qty) OVER ( PARTITION BY skuid
ORDER BY CASE
WHEN status = 'AVAIL' THEN 1
WHEN status = 'RES' THEN 2
WHEN status = 'HOLD' THEN 3
END
) AS max_qty
FROM status
) -- End in-line view to get max_qty
) s -- End in-line view s to get data from status
WHERE l.skuid = s.skuid
AND l.min_qty < s.max_qty
AND s.min_qty < l.max_qty
ORDER BY l.skuid
, l.max_qty
, s.max_qty
;
Tags: Database
Similar Questions
-
How it warns Oracle to use an index for the join of two tables...
How to prevent the Oracle to use an index for the join of two tables to get a view online that is used in an update statement?
O.K. I think I should explain what I mean:
When you join two tables that have many entries sometimes there're better is not to use an index on the column that is used as a criterion to join.
I have two tables: table A and table B.
Table A has 4,000,000 entries and table B has 700,000 entries.
I have a join of two tables with a numeric column as join criteria.
There is an index on this column in A table.
So I instead of
I want to usewhere (A.col = B.col)
in order to avoid Oracle using the index.where (A.col+0 = B.col)
When I use the join in a select query, it works.
But when I use the join as inline in an update statement I get the error ORA-01779.
When I remove the '+ 0' the update statement works. (The column is unique in table B).
Any ideas why this happens?
Thank you very much in advance for any help.
Hartmut cordiallyYou plan to use a NO_INDEX hint as shown here: http://www.psoug.org/reference/hints.html
-
Not a dba and need help for Oracle 11 G
I have install an output db in space and I can't get the client that I work to install the spacewalk to connect to the db.
output in the configuration of the client space (research forward and reverse and can ping by short/longname and IP.)
# output extravehicular-installation - disconnected - external-db
* Setting the Oracle environment.
* Setting up database.
* Database: set up the connection of database for Oracle backend.
Name of the database service (SID)? spcwlk
Name of database to host [localhost]? spacedb.domain.com
Database (listener) port [1521]?
The database connection error: ORA-12543: TNS:destination host unreachable (DBD ERROR: OCIServerAttach)
DB server
listener.ora # Network Configuration file: /u01/app/oracle/product/11.2.0/dbhome_1/network/admin/listener.ora
# Generated by Oracle configuration tools.
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = CIP)(KEY = EXTPROC1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = spacedb.domain.com) (PORT = 1521))
)
)
ADR_BASE_LISTENER = / u01/app/oracle
lsnrctl start $
LSNRCTL for Linux: Version 11.2.0.1.0 - Production on 18-SEP-2014 11:17:37
Copyright (c) 1991, 2009, Oracle. All rights reserved.
From /u01/app/oracle/product/11.2.0/dbhome_1/bin/tnslsnr: Please wait...
TNSLSNR for Linux: Version 11.2.0.1.0 - Production
System settings file is /u01/app/oracle/product/11.2.0/dbhome_1/network/admin/listener.ora
Log messages written to /u01/app/oracle/diag/tnslsnr/db-obrien/listener/alert/log.xml
Listen on: (DESCRIPTION = (ADDRESS = (PROTOCOL = ipc) (KEY = EXTPROC1521)))
Listen on: (DESCRIPTION = (ADDRESS = (PROTOCOL = tcp)(HOST=spacedb.domain.com) (PORT = 1521)))
Connection to (DESCRIPTION = (ADDRESS = (PROTOCOL = IPC) (KEY = EXTPROC1521)))
STATUS of the LISTENER
------------------------
Alias LISTENER
Version TNSLSNR for Linux: Version 11.2.0.1.0 - Production
Start date 18 - SEP - 2014 11:17:39
Uptime 0 days 0 h 0 min 0 sec
Draw level off
Security ON: OS Local Authentication
SNMP OFF
Parameter Listener of the /u01/app/oracle/product/11.2.0/dbhome_1/network/admin/listener.ora file
The listener log file /U01/app/Oracle/diag/tnslsnr/spacedb/listener/alert/log.XML
Summary of endpoints listening...
(DESCRIPTION = (ADDRESS = (PROTOCOL = ipc) (KEY = EXTPROC1521)))
(DESCRIPTION = (ADDRESS = (PROTOCOL = tcp)(HOST=spacedb.domain.com) (PORT = 1521)))
The listener supports no services
The command completed successfully
Hello
Please add below lines to your listner.ora file and reload the listner.
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME =
) (ORACLE_HOME =
) (GLOBAL_DBNAME =
) )
)
Thank you
Jihane Narain Sylca
-
I Iconia Tab A500 running 3.0, need help update, I downloaded the entire updaes list in the supprt of acer, all versions, 3.0, 3.1, 3.2 and 4., I read on the acer support somewhere I can use a microSD card to update my device, as acer provides automatically, when I try it says 'poor network connection '. moving instead of anthoer. ", I have to update all the updates that are listed, or can I only update, using the 4. 0? to get the last known update. I also downloaded, 'Documents, applications, drivers, patches and O.S... How do I intsaller all these updates, I think that running the lowest version available, please help me... Thank you in advance.
There are some instructions step by step on the site, but basically you check out the file "update.zip" download, copy to the root of a FAT32 formatted microSD card, then start in recovery mode (press one of the volume buttons [which it depends if you are landscape or portrait mode] and hold, then the power press and hold). From there, you can choose to update in the zip file it finds on the map.
It is important before you have the correct version of the update, it's different for different regions of the world, and you will not be able to upgrade the (for example) Brazil version from the US site.
-
Hello Experts,
My name is Rohan and I work as an Oracle DBA now, I fell on the ASM and I want to learn it.
I have a knowledge base of Oracle ASM and I also configured/created an instance using DBCA.
Now for the best understanding I want to create the same with the command line.
Everyone please give me the great tutorial for the same?
I'm using oracle 11.2.0.3 on windows.
Thanks in advance.
CREATE DATA base should be with the ORACLE_SID set to the desired database SID, not the SID of the DSO. Also, if you have (as in 11 g) two separate ORACLE_HOMEs for the ASM and the database, the DATA CREATE database must be run ORACLE_HOME database.
Hemant K Collette
-
Hello
I use Oracle Apex 4.01 in Oracle 10 g.
I am trying to create a page of Apex, sort of time table system. In this page I have 3 text items field and the other two are date fields. and two buttons.
You must submit (B1) and the other is to add any folder (B2).
My job is if I press the add another button to record (B2) then a new line with the same types of items (3 items) must be created in the page and if I press this button once again and then a new line with the same elements must be created on the page and so on.
Example of
The initial Page view: Point 1, Item2, Item3 B1, B2
When you press B2: point 1, Item2, Item3
Article 1, Item2, Item3 B1, B2
When B2 press again: point 1, Item2, Item3
Article 1, Item2, Item3
Article 1, Item2, Item3 B1, B2
so now...
Finally if I press send, but all the values I entered must be stored in the table.
Example, if I press the B2 3 times and press B1, then these 3 records are stored in the table.
Can someone tell me please how to do this in the Apex.
Thank you
RikRik,
It looks like the basic functionality of the tabular presentation.
-David
-
HELP FOR PHOTOSHOP TO USE LIGHTROOM!
HELP I need to be able to go from lightroom directly into photoshop... apparently something was accidentally changed and I don't have this ability... .can someone help me restore my settings lightroom prior 5?
Windows or Mac?
- go to the Lightroom preferences > external editing > click on Choose under additional External Editor > you choose installation of Photoshop in the Applications folder in the finder
-
Dear all
I need help with the following problem:
Clicking on the tab help for help with photoshop first time get in "photoshop online help could not be displayed because you are not connected to internet" but I'm connected to the internet.
Appreaciate help on this problem.
MSD
I find it easier and faster to use just this link, which goes to the same place as aid > online help for Photoshop:
Using Photoshop | Photoshop help
To bookmark so that you can find.
-
Version of DB: database Oracle 11 g Enterprise Edition Release 11.2.0.3.0 - 64 bit Production
I have a table my_table as below:
create table my_table
(
my_code varchar2 (6).
my_id varchar2 (24).
forced pk_1 primary key (my_code, my_id)
);
Primary_key here's a composite key that contains columns 1 (my_code) and 2 (my_id).
Is there that a difference in the way below queries is executed in terms of performance (use of indexing in the extraction).(a) select * from my_table where my_code = '123' and my_id = "456";
(b) select * from my_table where my_id = '456' and my_code = '123';
The understanding I have the order of the column in the where clause should be identical to the sequence in
What primary key draws for indexing to be used by oracle in oracle other DML queries ignores indexing
However when I used explain plain both show the same query cost with single scan with index rowid.
so I don't know if I'm wrong in the concept that I have. Kindly help.Thanks in advance,
GerardYour question is answered in the Performance Tuning Guide
14.1.4 choosing composite indexes
A composite index contains several key columns. Composite indexes can provide additional benefits compared to the index to single column:
- Improved selectivity
Sometimes the two or more columns or expressions, each with a low selectivity can be combined to form a composite with a high selectivity.
- Reduced IO
If all columns selected by a query are a composite index, then Oracle may return these values in the index without access to the table.
A SQL statement can use a path on a composite index if the statement contains constructions that use a main part of the index.
Note:
This is no longer the case with the skip index scans. See "Index Skip Scans".
A main part of an index is a set of one or more columns that have been specified first and consecutively in the list of columns in the
CREATEINDEXstatement that created the index. - Improved selectivity
-
Why doesn't Oracle use my index?
Hi guys, imagine I have a table with columns A, B, C, D
It has a (non-unique) index on column D
When I run the query:
"SELECT A, B and C WHERE D > = ' 1.1.2010.
the index is never used, and it takes 20 minutes. The table has about 7 million lines. It doesn't matter what size of my result set is (even for a few lines), the plan of execution always shows me a full table scan. Only when I create an index on all 4 columns, the index is used. But this isn't a solution, because in my real application, I have about 20 columns in my SELECT clause. I also rebuilt the indexes and statistics.
Can someone help me?
Thank you!890408 wrote:
Well, then this is the result of 3 queries:Well, Oracle did what I thought it would be then. Don't you see how your density changed (and now matches the 1/NUM_DISTINCT)? Before this etait.33333 and now it's de.0024. So the estimated cardinalities went from 2 624 862 to 19 492 making it much more attractive index the optimizer.
As I mentioned in my previous post, you should be aware of your inclination of data. A large part of your data in this column is in the period of 01/01/1970. If someone asks for this Oracle is likely to try to use an index to chase these data that is not optimal.
-
Paging query needed help for large table - force a different index
I use a slight modification of the pagination to be completed request to ask Tom: [http://www.oracle.com/technology/oramag/oracle/07-jan/o17asktom.html]
Mine looks like this to extract the first 100 lines of everyone whose last name Smith, ordered by join date:
The difference between this and ask Tom is my innermost query returns just the ROWID. Then, in the outermost query we associate him returned to the members table ROWID, after that we have cut the ROWID down to only the 100 piece we want. This makes it MUCH more (verifiable) fast on our large tables, because it is able to use the index on the innermost query (well... to read more).SELECT members.* FROM members, ( SELECT RID, rownum rnum FROM ( SELECT rowid as RID FROM members WHERE last_name = 'Smith' ORDER BY joindate ) WHERE rownum <= 100 ) WHERE rnum >= 1 and RID = members.rowid
The problem I have is this:
It will use the index for the column predicate (last_name) rather than the unique index that I defined for the column joindate (joindate, sequence). (Verifiable with explain plan). It is much slower this way on a large table. So I can reference using one of the following methods:SELECT rowid as RID FROM members WHERE last_name = 'Smith' ORDER BY joindateSELECT /*+ index(members, joindate_idx) */ rowid as RID FROM members WHERE last_name = 'Smith' ORDER BY joindate
Whatever it is, it now uses the index of the column ORDER BY (joindate_idx), so now it's much faster there not to sort (remember, VERY large table, millions of records). If it sounds good. But now, on my outermost query, I join the rowid with the significant data in the members table columns, as commented below:SELECT /*+ first_rows(100) */ rowid as RID FROM members WHERE last_name = 'Smith' ORDER BY joindate
As soon as I did this join, this goes back to the use of the index of predicate (last_name) and perform the sort once he finds all the corresponding values (which can be a lot in this table, there is a cardinality high on some columns).SELECT members.* -- Select all data from members table FROM members, -- members table added to FROM clause ( SELECT RID, rownum rnum FROM ( SELECT /*+ index(members, joindate_idx) */ rowid as RID -- Hint is ignored now that I am joining in the outer query FROM members WHERE last_name = 'Smith' ORDER BY joindate ) WHERE rownum <= 100 ) WHERE rnum >= 1 and RID = members.rowid -- Merge the members table on the rowid we pulled from the inner queries
My question therefore, in the query full above, is it possible that I can get to use the ORDER of indexing BY column to prevent having to sort? The join is what makes go back to using the predicate index, even with notes. Remove the join and just return the ROWID for these 100 records and it flies, even over 10 millions of documents.
It would be great if there was some generic hint that could accomplish this, such as if we change the table/column/index, do not change the indicator (indicator FIRST_ROWS is a good example of this, while the INDEX indicator is the opposite), but any help would be appreciated. I can provide explain plans for the foregoing, if necessary.
Thank you!
-
Use-business cases for Oracle JET
Dear team,
Get your hands wet with Oracle JET and found it interesting. However, can you help me with the use case where it can be used effectively? Can you give us some specific use cases where Oracle JET is the ideal solution? (if possible with justification on why it is perfect fit)
Best regards
Hari
In one sentence you say that JET usage case is when you want to use a JavaScript/HTML5/REST of the architecture of your UI layer, and you want to have:
Support for accessibility and internationalization of your user interface
Ability to view the data in a variety of ways
Ability to implement best practices of Oracle Alta UI
For us at Oracle, which is true for many of our commodities are for example.
-
query not using the index for some user
Hello
I have a query that is running in less than a second for sys, system, or schema owner. However, another user (test_user) take 30 seconds to run the same query.
I certainly dba and privileges identical to test_user as schmea_user, but the result is the same.
I checked
Select * from V$ SYS_OPTIMIZER_ENV;
Both are the same for both users.
I have check the plan to explain to both users. I noticed that for sys/system/schema_owner, the query uses an index, but not the test_user.
All have experience the issue where a user uses an index, but not the other?
Thank you for any assistance.Thank you for the display of formatting output, this output is much easier to read.
One of the first things you notice about the execution plans that is for the owner non-schema "SQL_ID, 0wcs85uywn72m, number of children 1" appears in the output of DBMS_XPLAN, while "SQL_ID 0wcs85uywn72m, child number 0" (the same SQL_ID but a different number of child) appears for the schema owner. "" Whereas the SQL_ID is the same, which indicates that the client requires exactly the same SQL statement, so it's a good start.
Then, note that in the predicate for the nonschema owner information section the following appears (sometimes with the order of the two conditions switched in position) as a condition placed on each table that is available in the schema:
filter(("SEAL_FLAG" IS NULL OR "SEAL_FLAG"'Y'))The above suggests the presence of the virtual private database (or a superset of private database virtual) generated the predicates. You should be able to confirm that this is the case by querying V$ VPD_POLICY using the SQL_ID which was displayed in the DBMS_XPLAN output:
SELECT * FROM V$VPD_POLICY WHERE SQL_ID='0wcs85uywn72m';As a test, I made a few minor adjustments to the example on this page:
http://Antognini.ch/2011/09/optimizer_secure_view_merging-and-VPD/
I changed the name of T to T12 and TESTUSER table specified for the schema names. I then created the function S of this page as follows:CREATE OR REPLACE FUNCTION s (schema IN VARCHAR2, tab IN VARCHAR2) RETURN VARCHAR2 AS BEGIN RETURN 'ID < 10'; END; /I then added a couple of lines in the T12 test table:
INSERT INTO T12 VALUES (1,1,NULL); INSERT INTO T12 VALUES (4,1,NULL); INSERT INTO T12 VALUES (10,1,NULL); INSERT INTO T12 VALUES (12,1,NULL); COMMIT;With an active 10053 trace, I executed the following SQL statement:
SELECT id, pad FROM t12 WHERE spy(id, pad) = 1The SQL_ID (in my case, found in the 10053 trace file) was 6hqw5p9d8g8wf, so I checked V$ VPD_POLICY to this SQL_ID:
SELECT * FROM V$VPD_POLICY WHERE SQL_ID='6hqw5p9d8g8wf'; ADDRESS PARADDR SQL_HASH SQL_ID CHILD_NUMBER OBJECT_OWNER OBJECT_NAME POLICY_GROUP POLICY POLICY_FUNCTION_OWNER PREDICATE ---------------- ---------------- ---------- ------------- ------------ ------------ ------------------------------ ------------------------------ ---------------------- ------------------------------ ------------------------------------------------------------------------------------ 000007FFB7701608 000007FFB7743350 1518838670 6hqw5p9d8g8wf 0 TESTUSER T12 SYS_DEFAULT T_SEC TESTUSER ID < 10As noted above, the VPD test function named S added the predicate "ID".< 10"="" to="" the="" sql="">
There are not many clues in the 10053 trace file in my test VPD generated additional predicates. Trace the following was found shortly after the beginning of the file (this is the SQL statement initially presented):
----- Current SQL Statement for this session (sql_id=6hqw5p9d8g8wf) ----- SELECT id, pad FROM t12 WHERE spy(id, pad) = 1I searched then down in the trace for final after changes query file (to be noted that this sentence could be slightly different in different versions of database Oracle). That's what I found:
Final query after transformations: ******* UNPARSED QUERY IS ******* SELECT "T12"."ID" "ID","T12"."PAD" "PAD" FROM "TESTUSER"."T12" "T12" WHERE "TESTUSER"."SPY"("T12"."ID","T12"."PAD")=1 AND "T12"."ID"<10 kkoqbc: optimizing query block SEL$F5BB74E1 (#0)Note that the final query after transformation shows how the final version of the query that has been rewritten by the query optimizer before the SQL statement has been executed and this version of the query includes AND "T12". "" IDENTITY CARD ".<10. if="" i="" was="" attempting="" to="" determine="" how="" that=""><10 predicate="" was="" added="" to="" the="" sql="" statement,="" i="" would="" start="" at="" the="" "current="" sql="" statement="" for"="" line="" in="" the="" trace="" file="" and="" search="" down="" the="" trace="" file="" for=""><10* -="" in="" this="" case,="" the="" following="" is="" what="" i="" found="" as="" the="" first="" search="" result,="" very="" close="" to="" the="" "current="" sql="" statement="" for"="" line="" in="" the="" trace="">
************************** Predicate Move-Around (PM) ************************** PM: PM bypassed: Outer query contains no views. PM: PM bypassed: Outer query contains no views. query block SEL$F5BB74E1 (#0) unchanged FPD: Considering simple filter push in query block SEL$F5BB74E1 (#0) "TESTUSER"."SPY"("T12"."ID","T12"."PAD")=1 AND "T12"."ID"<10 try to generate transitive predicate from check constraints for query block SEL$F5BB74E1 (#0) finally: "TESTUSER"."SPY"("T12"."ID","T12"."PAD")=1 AND "T12"."ID"<10As can be seen from the above (because the predicate again appeared before and after the line containing the word "Finally: '), the AND"T12 ". "" IDENTITY CARD ".<10 predicate="" was="" already="" added="" to="" the="" original="" sql="" statement="" by="" the="" time="" the="" predicate="" move-around="" section="" of="" the="" trace="" file="" was="" written,="" and="" that="" is="" the="" first="" mention="" of=""><10 in="" the="" trace="" file.="" in="" your="" case,="" you="" would="" search="" the="" 10053="" trace="" file="">
"SEAL_FLAG" IS NULLIf V$ VPD_POLICY revealed that there are virtual private database (VPD) generated predicates applied to the SQL statement, take a look at the following article in the Oracle documentation library:
http://docs.Oracle.com/CD/B28359_01/network.111/B28531/VPD.htmThis article lists the different points of view, who can be interviewed to learn more about the VPD rules which are in force in the schema. For example, with my SPV test:
SELECT * FROM ALL_POLICIES; OBJECT_OWNER OBJECT_NAME POLICY_GROUP POLICY_NAME PF_OWNER PACKAGE FUNCTION SEL INS UPD DEL IDX CHK ENA STA POLICY_TYPE LON ------------------------------ ------------------------------ ----------------------------- ------------------------------ ------------------------------ ----------------------------- ------------------------------ --- --- --- --- --- --- --- --- ------------------------ --- TESTUSER T12 SYS_DEFAULT T_SEC TESTUSER S YES YES YES YES NO NO YES NO DYNAMIC NOHe knows performance issues related to the use of VPD, some of which are Oracle Database version-dependent, and some have been fixed in recent versions. Take a look at the following articles if you have access to My Oracle Support:
MetaLink (MOS) Doc ID 728292.1 ' known performance problems when you use transparent encryption data and indexes on the encrypted columns.
MetaLink (MOS) Doc ID 967042.1 "How to investigate Query Performance regressions Caused by VPD (FGAC) predicates?"You might find working through the second of the above that the problem is caused by a bug in database Oracle.
On a side note. Execution plans you have published include the 0 value in the column starts many of the operations in the execution plan. 0 indicates that the operation never actually executed. A 0 is included in the column starts on the line that includes the FULL ACCESS of TABLE of PEOPLE_TRANSACTIONS at least to the OPC. Value 123, a full table of PEOPLE_TRANSACTIONS table scan PROPERTY_CONTAINER_ID was not actually performed.
Charles Hooper
http://hoopercharles.WordPress.com/
IT Manager/Oracle DBA
K & M-making Machine, Inc. -
Can we remove a rdf model using the Jena for Oracle adapter?
Hello
I use the adapter for Oracle Jena API, using java. I want to remove the database model when ever needed. Is it possible to delete the database template.
GOS GraphOracleSem = new GraphOracleSem (oracle, modelName);
MOS ModelOracleSem = new ModelOracleSem (gos);
mos.removeAll ();
This code removes the model data do not remove the model. Can we delete all of the data model. Any help?
Thank you
KKSHello
In the latest version of the adapter of Jena, there is a dropSemanticModel API in the oracle.spatial.rdf.client.jena.OracleUtils class.
It is a static method. The settings are simple.See you soon,.
Zhe Wu
-
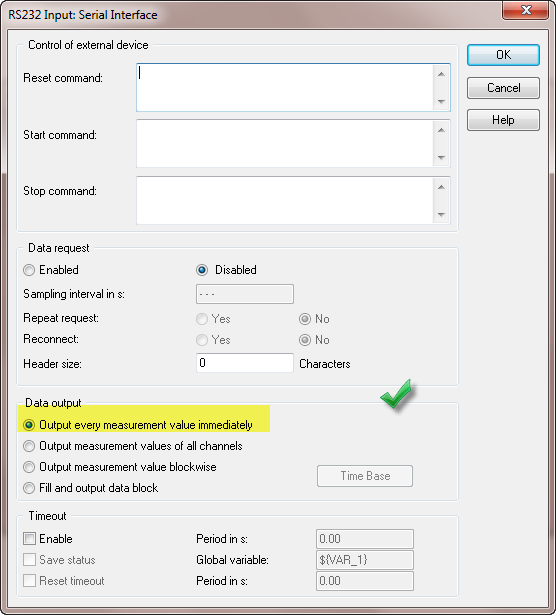
I can collect data from a hygrometer in a text file using the RS232 port with the following T75.2F:H17.0% format, these data are collected using a data logger software. I was wondering if I can collect this data for later analysis using Dasylab. Any help is appreciated.
The setting below causes the error. Change for the second selection, output values of all channels.
Maybe you are looking for
-
Time series: finding max and min for each month
Hello world. I'm working on a datasheet that has collected the data points for all day for the past 15 years. A column stores the date and column B contains a numeric value. I want to do the following: Create a new table (call it table #2) that: (1)
-
Impossible to deploy the database of NOR-XNET to target RT PC
Hello I am trying to deploy a XNET database to a target RT PC simply by following the tutorial here: http://digital.ni.com/public.nsf/allkb/9847EF6F2D867BC186257DCE00626236 However, when I click on deploy nothing happens; I get no error message and t
-
Hi I have a aspire 5336. But I'm expirencing difficulties, data burning / music / pictures etc.
I want to burn CD/DVD without any failure. Please help me to restore my settings to factory records.
-
How can I make my verbatim and go portable hard drive work plug / he does not see my computer.
I have a problem taking my verbatim branch and go 500 GB on my computer using xp nothing happens / it works on windows 7 and xp professional / / can someone help / using easy solutions / I'm 63 years old, / thank you
-
computer laptop quit working now I can't come back, suggestions
I have a HP Pavilion dv7 purchased 2009. I got a low disk space error yesterday and done a disc cleanup, but I did not stop then.