Help needed to extract the pipe-delimited fields in a CLOB data type
HelloI had a table with clob field as indicated below.
CREATE TABLE TRANSACTION_INFO
(
TRASACTION_ID CLOB,
LOG_ID NUMBER
)
Insert into TRANSACTION_INFO
(TRASACTION_ID, LOG_ID)
Values
('354502002020910|000000610214609663||09/27/09 08:02:37|RNEW|DC25|MOTOROLA|8802939198', 123);
Insert into TRANSACTION_INFO
(TRASACTION_ID, LOG_ID)
Values
('354599892020910|000000610214609663||09/27/10 08:12:47|SOLD|DC23||8802939198', 456);
COMMIT;SUBSTRING function fails if there is lack of character in all fields.
Also when there is a null value in all the areas, how can I be able to get as a null value? Basically, I want to get the values in a defined way.
How can we achieve this?
Select Substr (TRASACTION_ID, 1, Instr (TRASACTION_ID, '|')-1) field1,
Substr (TRASACTION_ID, 17, Instr (TRASACTION_ID, '|')+2) field2
From TRANSACTION_INFO;
output should be like as shown
FIELD1 FIELD2 FEILD3 FEILD4
354502002020910 000000610214609663 09/27/09 08:02:37
354599892020910 000000610214609663 09/27/10 08:12:47Rede
SQL> with transaction_info (trasaction_id, log_id)
as (
select '354502002020910|000000610214609663||09/27/09 08:02:37|RNEW|DC25|MOTOROLA|8802939198', 123 from dual union all
select '354599892020910|||000000610214609663||09/27/10 08:12:47|SOLD|DC23||8802939198', 456 from dual union all
select '|000000610214609663||09/27/10 08:12:47|SOLD|DC23||8802939198', 456 from dual
)
--
--
select trim(regexp_substr (trasaction_id, '[^|]+', 1, 1)) f1,
trim(regexp_substr (trasaction_id, '[^|]+', 1, 2)) f2,
trim(regexp_substr (trasaction_id, '[^|]+', 1, 3)) f3,
trim(regexp_substr (trasaction_id, '[^|]+', 1, 4)) f4,
trim(regexp_substr (trasaction_id, '[^|]+', 1, 5)) f5
from (select regexp_replace(replace (trasaction_id, '|', '| '),'^\|', ' |') trasaction_id from transaction_info)
/
F1 F2 F3 F4 F5
-------------------- -------------------- -------------------- -------------------- --------------------
354502002020910 000000610214609663 09/27/09 08:02:37 RNEW
354599892020910 000000610214609663
000000610214609663 09/27/10 08:12:47 SOLD
3 rows selected.
Tags: Database
Similar Questions
-
How to extract a value of sql xml column clob data
Hi guys,.
I need help with the following. I have a column with data type xml (clob data). I need to extract the information in the < RI4 > tag and the < RI6 > tag.
I truncated the data, but there is a repetition of the < RI4 > tag and consequenty internal to that tag RI6. However, each tag RI4 and RI6 has different data.I would be grateful if you can help me with this:
<a xsi:schemaLocation="som location.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:somlocation"> <b>Some stuff here</b> <c> <someinfo>blah</someinfo> <someinfo2>blah2</someinfo2> </c> <EffectiveDateTime>2015-10-01T00:00:00+10:00</EffectiveDateTime> <CurrencyCode>AUD</CurrencyCode> <RequiredInformation> <RequiredInformation2> <RequiredInformation3> <RI4>someinfo</RI4> <RI5> <RI6> <a1>1</a1> <b1>9.13</b1> </RI6> <RI6> <a1>2</a1> <b1>8.75</b1> </RI6> <RI6> <a1>3</a1> <b1>78.90</b1> </RI6> <RI6> <a1>4</a1> <b1>200</b1> </RI6> <RI6> <a1>5</a1> <b1>17.59</b1> </RI6> </RI5> </RequiredInformation3> </RequiredInformation2> </RequiredInformation> </a>
I think that since it's the repetition I might need to make some sort of PL/SQL programming, but I really need help here to build this announcement also a way to extract the information.
Any help would be greatly appreciated.
Kind regards
You can parse your XML like this
SQL> with t 2 as 3 ( 4 select 5 ' 6 Some stuff here 7
8 11blah 9blah2 102015-10-01T00:00:00+10:00 12AUD 1314 42 ' xml_str 43 from dual 44 ) 45 select t1.ri4, t2.a1, t2.b1 46 from t 47 , xmltable 48 ( 49 xmlnamespaces(default 'urn:somlocation', 'http://www.w3.org/2001/XMLSchema-instance' as "xsi") 50 , '/a/RequiredInformation/RequiredInformation2/RequiredInformation3' passing xmltype(t.xml_str) 51 columns 52 ri4 varchar2(10) path 'RI4' 53 , ri5 xmltype path 'RI5' 54 ) t1 55 , xmltable 56 ( 57 xmlnamespaces(default 'urn:somlocation') 58 , '/RI5/RI6' passing t1.ri5 59 columns 60 a1 number path 'a1' 61 , b1 number path 'b1' 62 ) t2; RI4 A1 B1 ---------- ---------- ---------- someinfo 1 9.13 someinfo 2 8.75 someinfo 3 78.9 someinfo 4 200 someinfo 5 17.59 SQL>15 4116 40someinfo 1718 3919 221 209.13 2123 262 248.75 2527 303 2878.90 2931 344 32200 3335 385 3617.59 37 -
Insert/update the column with the clob data type
Hi all
ORCL Version: 11g.
I have a table with the clob data type.
Test12
(col1 clob);
I'm trying to insert/update to update the column with more than 4000 characters.
But due to the limitation of tank 4000, I could not Insert/Update.
Need your help in resolving this issue.
THX
Rod.
The limit of 4000 characters is incorrect. That pertains only to the varchar2 data type. A clob can hold more than 4 G.
Here is an example that shows how to insert it, I found...
Otherwise, here is a way 'dirty' to do.
insert into your_table (COLA, COLB)
values
(PRIMARY_KEY, PART 1 OF DATA)
;
Update your_table
Define COLB = COLB | PART 2 OF BIG DATA
where COLA = PRIMARY_KEY;
Update your_table
Define COLB = COLB | PART 3 OF BIG DATA
where COLA = PRIMARY_KEY;
.. and so on...
I don't know that I personally recommend the second style... But he could do the job.
-
Problem with the CLOB data type.
Greetings,
I am facing a problem with the CLOB data type. I know that the CLOB data type is 4 GB (I use Oracle 9i). But in the Pl Sql procedure, I can only store 34305 size for a CLOB variable character data.
This is the test script that I am trying to run.
DECLARE
-Local variables here*.
I have INTEGER;
C_1 CLOB.
BEGIN
FOR Rec IN (SELECT
*
ACCORDING TO THE TABLE)
LOOP
C_1: = c_1 | Rec.Clo_1;
END LOOP;
EXCEPTION
WHILE OTHERS THEN
Dbms_Output.put_line (SQLERRM);
END;
Here variable C_1 range value 34305 good character regardless of type CLOB. Now the above script fails if query my buckle - huge number of return values. It is throwing the exception "error during transfer of files ORA-06502: PL/SQL: digital error or value."
He would be grateful if someone can help me on this.
Thank you.You are probably better off using DBMS_LOB.append, instead of the concatenation of varchar2 (|).
And... take off your when-other Manager exceptions, please...
-
Problem with the length of a CLOB data type
Hello
In my application, I have a page with an interactive report of written blogs - on this page, you can add a new blog (text box - CLOB data type), discovered a blog or edit a blog.
There is something going wrong with the size of the blog text. I know APEX cannot accept that 32K text and I've seen the great value saving thread, but this isn't the solution to my problem.
The problem is that when I add a blog with say about 4000 characters, it is saved in the database, but the interactive report, when I click on the view or edit icons for this blog, the blog text field appears empty. For small items (< 4000 characters), there is no problem.
Anyone know why this is happening and how to fix this?
Thank you!There seems to be a bug in the calculation of the value of the element Source when the Source Type is a SQL query and the data type of the selected column is CLOB. I'll file a bug for this. For now, I have demonstrated how you can use a type of function PL/SQL source instead. Please see point P3_TEXT:
beginfor c1 in (select blog_textfrom blogwhere blog_id = :P3_BLOG_ID) loop return c1.blog_text;end loop;return null;end;
Scott
-
Need to extract the global name
Hello
I'm working on 11 GR 2 on RHEL.
I am trying to extract the global name under the name of the comic.
For example: If the db name is sample and if global name is sample.london.uk.com so I only need london.uk.com
I tried to use something like REGEXP_substr (global_name, '[..] ([A-Z] * [0-9] * []] *---*'), but it does not work.
I want to extract LONDON.UK.COMSQL> select global_name, REGEXP_substr(global_name, '[.][A-Z]*[0-9]*[-]*[.]*' ) gname from global_name; GLOBAL_NAME GNAME ------------------------------ ------------------------------ SAMPLE.LONDON.UK.COM .LONDON.
Any suggestions?I want to extract LONDON.UK.COM
SQL> with global_name as ( select 'SAMPLE.LONDON.UK.COM' global_name from dual ) -- -- select global_name, regexp_substr (global_name, '\.(.*)',1,1,null,1) gname from global_name / GLOBAL_NAME GNAME ------------------------------ ------------------------------ SAMPLE.LONDON.UK.COM LONDON.UK.COM 1 row selected. -
Help needed - "cannot download the folio on your local drive.
Hello
(WARNING: for the first time post :-))
I have trouble downloading my folio published. During the last 24 hours I repeatedly get the following error (after a long wait with the status 'Preparation content by downloading... ") on different computers (Mac/PC) and browsers:
An error occurred during the export of the folio
Could not download the folio on your local drive
My first version is delivered to an Android app (created using the viewer Builder) and has been incorporated into an iOS app (also created using View Designer). All this worked without any problems and I can export this now.
In order to optimize the folio for the new iPad, I decided to use the PDF option that required me to rebuild the folio. The content is identical to the bar a few dates changed from 2011 to 2012. I just need to export the folio so I can incorporate into an update iOS application. The folio is not (at this stage) given to the Android app.
I hope someone can help :-)
Andrew
Edit: Using the new Adobe Content Viewer I see TWO versions of the folio - one with the lightning bolt blue - but maybe that's normal?
Hi Philippe,.
Thanks for the reply. After a lot of testing, I discovered that my preview of the cover images were the problem. I've been using PNG files and when I used the versions JPG export worked.
Maybe that's a one-time problem, but I thought I'd share the solution in any case.
Kind regards
Andrew
-
SQL queries for reports help: need to reverse the data in the column in columns [O
Hi all
I'm looking for help in writing SQL, where I need to reverse the data in the columns column.
My data in DB is as below.
VALUE OF NAME OF MONTH
Jan-10 M1 5
Jan-10 M2 8
Jan-10 M3 9
Feb-10 M1 4
Feb-10 M2 6
Feb-10 M3 2
M4 10 Feb 10
M1 10 Mar 21
Mar-10 M2 6
Power required for the declaration will be like:
MONTHS M1 M2 M3 M4
Jan-10 5 8 9
Feb-10 4 6 2 10
21 Mar-10 6
How can I do this using SQL. [ORACLE 10g]?
I can make use of server Oracle BI also.
Please help me on this...I think this is wrong forum to ask this question. You want to do it in OBIEE or at the DB level. In oBIEE you can do in a table privot view.
Thnaks,
Knani -
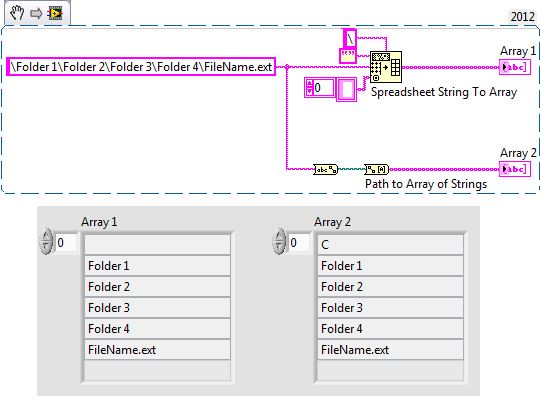
Analyzes the string and extract the string delimiter
Hello
Basic questions. Is this possible with the scan of regular expression of the string to extract the string that are in the specified delimiters. Here is an example:
Name of the \\Name of the folder 1\Name to the folder 2\Name to the folder 3\File
Chain analysis can produce the following by specifying the regular expression on the right:
1 folder name
Name of the folder 2
Name of the folder 3
File name
I tried \\\%s\\%s\\%s\\%s but the %s stops on the first white space.
Thank you
Michel
RavensFan suggested the service appropriate for your condition, but you can also use an alternative, which is "spreadsheet of array of strings.
-
Change the length of a Table column (CHAR data type)
Hi gurus,
SQL > select * from version $ v
BANNER
----------------------------------------------------------------
Oracle Database 10g Release 10.2.0.3.0 - 64 bit Production
PL/SQL version 10.2.0.3.0 - Production
CORE Production 10.2.0.3.0
AMT for Linux: release 10.2.0.3.0 - Production
NLSRTL Version 10.2.0.3.0 - Production
I need to increase the length of a CHAR of a table data type column (currently it's tank (3) and you want to change to char (4)). Here are more details on the table:-
- Contains more than 20 million lines.
- Table contains several indexes.
- Table is referenced by several tables (about 60 tables) and it refers to several tables (about 3)
- Table has 4 complex triggers. Triggers call procedures and packages.
What I've tried so far
1 disabled all triggers and ran ALTER statement to increase the length. It took hours and did not finish in a reasonable amount of time, even if no error, but it took more than 12 hours.
2 tried DBMS_REDEFINITION package but it does not work with the standard version of Oracle 10 g.
I think to try next
I think same Optics:
Say my name of the existing table is OLD_T1 where the length of column need to increase
-Create a copy (with increased column length) table of OLD_T1, Say NEW_T1
-Move data from in OLD_T1 to the new table NEW_T1
-Lower OLD_T1 (or rename it to OLD_T1_TMP)
-Rename NEW_T1 to OLD_T1
-Create all indexes, triggers, constraints etc..
I wish to confirm, if my approach is correct? Or someone has a better idea to do this?
Please note: I know that the CHAR data type gives the problem but it is an old system and I don't have authority to change the design of database.
Appreciate any comment/suggestion
Thanks in advance
> I mean, can any application break if it depends on fixed-length?
Yes, because the code can be expected completed on the right areas.
-
Table design for the newspaper error due to a xml data type
Hello
I am trying to create a table of error log, but I get the below error
ORA-20069: unsupported column or the types found:
Table on which I am trying to create a column with the xml data type.
Is there a way to create the error table for tables with the XML data type.
Thank you
PAL
http://docs.Oracle.com/CD/E11882_01/server.112/e41084/statements_9014.htm#SQLRF55101
Concerning
Etbin
http://docs.Oracle.com/CD/E11882_01/AppDev.112/e40758/d_errlog.htm#ARPLS680
Look at the skip_unsupported setting
-
help how to extract the ref cursor in the table field
Hello.
I have a query similar to the following:
Expecting to get several lines, I want this select this option to be in bulk sampled in a table variable nested (of another type of nested table) which is copied to an out parameter in a procedure. I have some doubts:select department_id, cursor (select employee_id from employees where department_id = d.department_id) from departments d
1 should. what I create the column in the inner nested table that will keep the result of the ref cursor? Ref cursor colunm? A sort of column Adrien?
2. If the column in the nested table inside that will keep the result of the ref cursor is another array, how can I write the result of the entire query in a single volume?
(I want to bulk collect everything in a single query, I know how to do with pl/sql do not inflate but using two nested for loops, that's what I try to avoid).
Thanks in advance.It would be simpler:
declare type dep_emp_list_tbl_type is table of sys.OdciVarchar2List; v_dep_emp_list_tbl dep_emp_list_tbl_type; v_dep_id_tbl sys.OdciNumberList; begin select department_id, cast(multiset(select employee_id from hr.employees where department_id = d.department_id) as sys.OdciVarchar2List) bulk collect into v_dep_id_tbl,v_dep_emp_list_tbl from hr.departments d; end; /SY.
-
Need help, need to install the SSD Samsung 830 on my HDX16T
I have a laptop HP Hdx16t Entertainment, and I was wondering if someone can explain what I need, or how to install until I open it myself. Right now all I have is real laptop and the Samsung 830 256 gb SSD. Do I need other cables of? or the disk hard is just snap? It's an easy task? I have never replaced one of front. Any help would be greatly appreciated. Sorry for my noob question.
Hello:
It should be pretty easy to do it yourself.
Here is the link to the service manual for your laptop.
http://h10032.www1.HP.com/CTG/manual/c01612461.PDF
See Chapter 4 for R & R procedures.
You must transfer the material from the original to your new SSD (caddy, connector and screws).
Paul
-
Help - need to consolidate the partitions on the hard disk after system recovery
There are 4 partitions on my laptop Lenovo w/Vista. They are the main with the system OS etc. files partition, then an extended 9.7 GB partition labeled volume D: 98 GB of unallocated space and then finally the OEM with the recovery image section. I want to create a partition that is important as the C: volume with all that on it. The only other partition would be the volume of the OEM. Now when I try to use the unallocated space (create a simple volume with quick format) it says the operation cannot be completed because there is not enough space on the hard drive; that cannot be true because the unallocated space is 98 GB +. I got the OS to the factory setting thinking that it would be re - format the hard disk for the installation of 2 original score. No luck. I need help! We cannot add a lot of apps of software in the form of program files before the C: drive runs out of space. Help!
Answered in the other Forum.
Mick Murphy - Microsoft partner
-
Help needed to upgrade the CLI Version of power...
Dear team,
I need your help to upgrade my powercli API, here are the details
PowerCLI installed (ver. 5.0.0.3501)
OS: win2k3
for the most part all ESX worm is 4.1.0 260247
vCenter version: 4.1.0 (258902) and 345043
When I opened powercli it takes a long time to open (about 15 minutes)... and following is the blink of an eye the same.

for the new version of powercli, please help me with he download link = the same thing.
concerning
Mr. VMware
Because I would upgrade PowerShell first PowerCLI is based on PowerShell. Although I don't know if it's important.
ESX 4.1 is not mentioned in the VMware vSphere PowerCLI 5.1 Release 1 Release Notes. This means that it is not supported. In this case, you can better keep PowerCLI 5.0. Or upgrade to PowerCLI 5.0.1 you can download from http://www.vmware.com/downloads/download.do?downloadGroup=PCLI501.

Maybe you are looking for
-
How can I send my tracphone jpeg to my g-mail?
I have a tracfone, how do I send the JPEGs of my phone to my g-mail for download to the folder?
-
I just installed a crucial 256 GB ssd in my HP Pavilion laptop dv7 I bought at hp 2010-11. My problem is how can I change the ide to ahci mode mode?
-
I use e-mail to Windows 8 for over a year. All of a sudden, one morning, none of my email accounts open. The e-mail client opens, and the points turn in a circle without end. None of my emails has. I have four different e-mail - 2 on Google accounts,
-
Slip between the pages - Muse 2016
I'm new to Muse and I can be looking in the wrong places, but I am struggling to find a response to date to what, in my view, should be a simple question...Is it possible to set up a simple Muse site, where the user can slide between pages on a Table
-
Dear Sir/Madam, as my Mac Air proved to be malware. I had to reset my computer. My adobe has been deleted by the agent from the computer. Now I have to reinstall my computer, can I have a serial number again? Thank you. I received your response, I st