History of archivelog in table v$ perhaps complete?
Hi all9i
OEL 5.6
Our database of the value in archivelog mode, but we continue to remove the archive logs because we do cold backup all day at 12:00.
Since then, we have only the hours of 09:00 - 18:00 and apps window treatment.
All users go home after 18:00. Then we closed the database and perform all the directory/u01/oradata tar where all data files.
Then we delete all archive logs.
My question is... Since we do manual removal of the archivelogs (and not rman delete obsolete logs) means in the dictionary of data views all the logs are still saved?
I'm afraid that the dictionary of data for archiving logs will get full since generate us a lot of newspapers every day.
Comments or suggestions please...
Thank you very much
Yxz
You can query V$ CONTROLFILE_RECORD_SECTION to see the number of entries on the ArchiveLogs that are present in the controlfile. Oracle will wrap the entries to avoid hitting problems «archivelog full story»
Retention of the inputs is determined by CONTROLFILE_RECORD_KEEP_TIME. Assuming that the value is 7 (days), {i.e. the default value}, the number of archivelog records maintained in the controlfile will be the maximum number of the archivelogs in a 7 day period. If in the past you had 1000 archivelogs in 7 days, the controlfile pushed to accommodate 1000 entries - even though in current days you build only 250 archivelogs in 7 days.
You can also query V$ ARCHIVED_LOG to see the archivelog that are actually present in the controlfile.
Hemant K Collette
Tags: Database
Similar Questions
-
Joining tables to return complete results
Dear all
I have two tables
Table 1
SEQ Chassis EngineNo_ NO_ *.
1 11111111 E111111
2 22222222 E222222
3 33333333 E333333
Table 2
Vseq Chassis no Audit DATE_ *.
1 11111111 1/11 / 2008
2 22222222 1/11 / 2008
3 44444444 1/11 / 2008
I want to get the result as follows
Chassis EngineNo_ NO_ *.
11111111 E111111
E222222 22222222
E333333 33333333
44444444
Please note that the requirement is to get all the lines of table 1 and table 2 the removal of duplicates.
Can any body How to write this in PL/SQL
Thanks in advance
Mithra
Published by: user496263 on December 3, 2008 22:21Why not try an outer join complete with separate
Select distinct tab2.Chassis_no,tab1.engine_no from table1 tab1 full outer join table2 tab2 on tab1.Chassis_no =tab2.Chassis_no;Published by: Rajneesh Kumar on December 4, 2008 12:12
-
This is 20.0 Firefox desktop OS
Hey, as explained in the support article I linked to before, this setting will not be available when you set firefox to use the custom settings for history (you set ever "remember history").
-
REORG table does not completely
Hello
I'm trying to re - org 2 tables but not able to claim the entire space. Please check the details below and tell me why I'm not able to get the required space full after re - org.
Before re - org result
OWNER Table-name Tablespace_name ACTUAL_MB OPTIMAL_MB CLAIMABLE_MB
YBWETL GOODS_RECEIPTS YBWETLDAT 1573 1218 * 355 *.
YBWETL INVOICE_RECEIVED YBWETLDAT 1408 1162 * 246 *.
After re - org result
OWNER Table-name Tablespace_name ACTUAL_MB OPTIMAL_MB CLAIMABLE_MB
YBWETL GOODS_RECEIPTS YBWETLDAT 1453 1218 * 235 *.
YBWETL INVOICE_RECEIVED YBWETLDAT 1383 1174 * 209 *.
Request used:
----------------
Select t.table_name, t.owner, s.tablespace_name,
Round(s.bytes/1024/1024) actual_MB,.
Round ((t.num_rows+1) * t.avg_row_len/1024/1024) optimal_MB,.
Round(s.bytes/1024/1024)-
Round ((t.num_rows+1) * t.avg_row_len/1024/1024) CLAIMABLE_MB
from dba_tables t, s dba_segments
where t.owner = s.owner and s.owner = '& owner_name'
and t.table_name = s.segment_name
(and round(s.bytes/1024/1024) - round ((t.num_rows+1) * t.avg_row_len/1024/1024) > 50
CLAIMABLE_MB desc order
Order of re - org:
----------------
ALTER TABLE YBWETL. GOODS_RECEIPTS SHRINK SPACE;
ALTER TABLE YBWETL. INVOICE_RECEIVED SHRINK SPACE;
Order ussed to collect statistics:
--------------------------------
exec dbms_stats.gather_table_stats ('YBWETL', 'GOODS_RECEIPTS', estimate_percent = > 100, granularity = > 'ALL', level = > 4);
exec dbms_stats.gather_table_stats ('YBWETL', 'INVOICE_RECEIVED', estimate_percent = > 100, granularity = > 'ALL', level = > 4);
Published by: 988104 on March 15, 2013 04:40
Published by: 988104 on March 15, 2013 04:47
Published by: 988104 on March 15, 2013 04:49
Published by: 988104 on March 15, 2013 04:50Your formulas of "Optimal" and "Due" do NOT take into account
(a) PCTFREE
(b) general expenses fixed in each block
(c) the inputs ITL
(d) overhead of the chaining lineNormally, I use an adjustment factor of anywhere from 10 to 20%. So my BEST would be 10 to 20% lower than your BEST.
In addition, these calculations are not justification for rebuild / shrink a table if the table will 'grow up' again with the new pads and large updates.
Hemant K Collette
-
Too many queries on a table scan request complete
Hello
I am facing a strange (at least for me :) behavior of my Oracle 10.2.0.3 Server based on HP - UX rx6600.
Have a table with apparently about 100 records that takes a long time and shows an excessive amount of queries run on the drive.
Walk in the footsteps of my session and go the following
call the query of disc elapsed to cpu count current lines
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Run 1 0.00 0.00 0 0 0 0
Get 8 4.72 37.99 323196 323292 0 102
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 10 4.72 38,00 323196 323292 0 102
The table is accessible via the full analysis:
Rows Row Source operation
------- ---------------------------------------------------
102 S05_SIM_RTDB TABLE FULL ACCESS (cr = 323292 pr = 323196 pw = time 0 = 430 US)
Do not understand why access us so many times the disc with all these queries (I made a SQL > select < key field name > of S05_SIM_RTDB ;))
On a similar system, I got a normal as number:
call the query of disc elapsed to cpu count current lines
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Run 1 0.00 0.00 0 0 0 0
Get 15 0.00 0.00 0 216 0 199
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 17 0.00 0.00 0 216 0 199
If you have advice on where start watching this would be really appreciated, thanks!
MikeMay be a trace of the 10046 event with expected offer some previews?
-
Table of contents completely destroyed export
Hello
a COT of person never turned out like this when you export to PDF?
Thank you!
Well you do not have a tab stop, so it seems
I've seen it before where the tabs look like (see below) and it has messed up the page layout when exporting to PDF format.

Tab stop exactly where the first line indent is.
-
Hello
I read conflicting information about the return type that has a table function must or may use.
First, I am a student of a book that says:
Function in pipeline returns the data types:
The main constraint for the pipeline functions, it is the return type must be a collection type autonomous which can be used in SQL - i.e. a VARRAY or table nested.
and then in the next sentence...
More precisely a pipeline function can return the following:
A stand-alone nested table or VARRAY, defined at the schema level.
A nested table or VARRAY that has been declared in a package type.
This seems to go against the first quoted sentence.
Now, before reading the above text I had done just my own test to see if a packed type would work because I thought I had read somewhere that it would not, and he does not (the test code and this output is at the end of this question). When I arrived in the text above, after my test, so I was naturally confused.
So, I'm going to PL/SQL reference that says:
RETURN data type
The data type of the value returned by a function table in pipeline must be a type collection defined either at the level of schema or within a package (therefore, it cannot be a type of associative array).
I tried to call a function that returns a collection of VARRAY type packaged in both SQL and PL/SQL (of course below is SQL all in any case) and no work.
Now I'm wondering what is a TABLE function must use a schema type and a function table in pipeline can use a packaged type? I see that I created and called a function table but examples of Oracle see the creation and use of a function table in pipeline.
Edit: I should add that I read the following sentence in the SF book on p609 in * table functions: "this type of nested table must be defined as an element of level diagram, because the SQL engine must be able to resolve a reference to a collection of this kind."
So that it begins to resemble table functions should return a schema type and pipelined table functions, perhaps because that they don't in fact return a collection, rather they return (RowSource) content, can use the schema types or types of packages. Is this correct?
Can someone clarify this for me please?
Thank you in advance,
J
CREATE OR REPLACE PACKAGE PKGP28M
VAT-type is varray (5) number;
END;
/
DISPLAY ERRORS
create or replace type VAT is varray (5) number;
/
display errors
create or replace function tabfunc1 return pkgp28m.vat as
numtab pkgp28m.vat:=pkgp28m.vat();
Start
numtab.extend (5);
because loop me in 1.5
numtab (i): = trunc (dbms_random. Value (1.5));
end loop;
Return numtab;
end;
/
display errors
create or replace function tabfunc2 as return VAT
numtab vat:=vat().
Start
numtab.extend (5);
because loop me in 1.5
numtab (i): = trunc (dbms_random. Value (1.5));
end loop;
Return numtab;
end;
/
display errors
exec dbms_output.put_line (' call tabfunc1 (returns the packaged type) :');)
Select * from table (tabfunc1)
/
exec dbms_output.put_line (' call tabfunc2 (returns the type of schema) :');)
Select * from table (tabfunc2)
/
declare
RC sys_refcursor;
number of v;
Start
dbms_output.put_line (' in anonymous block1 - open rc to select in the table (tabfunc1) (returns the packaged type) :');)
Open rc to select table column_value (tabfunc1);
loop
extract the rc in v;
When the output rc % notfound;
dbms_output.put_line (' > ' | to_char (v));
end loop;
close the rc;
end;
/
declare
RC sys_refcursor;
number of v;
Start
dbms_output.put_line (' in anonymous block2 - open rc to select in the table (tabfunc2) (returns the type of schema) :');)
Open rc to select table column_value (tabfunc2);
loop
extract the rc in v;
When the output rc % notfound;
dbms_output.put_line (' > ' | to_char (v));
end loop;
close the rc;
end;
/
Scott@ORCL > @C:\Users\J\Documents\SQL\test29.sql
Package created.
No errors.
Type of creation.
No errors.
The function is created.
No errors.
The function is created.
No errors.
the call of tabfunc1 (returns the packaged type):
PL/SQL procedure successfully completed.
Select * from table (tabfunc1)
*
ERROR on line 1:
ORA-00902: invalid data type
the call of tabfunc2 (returns the type of schema):
PL/SQL procedure successfully completed.
COLUMN_VALUE
------------
1
4
1
1
3
In anonymous block1 - open rc to select in the table (tabfunc1) (returns the packaged type):
declare
*
ERROR on line 1:
ORA-00902: invalid data type
ORA-06512: at line 6
In anonymous block2 - open rc to select in the table (tabfunc2) (returns the type of schema):
> 1
> 2
> 4
> 2
> 3
PL/SQL procedure successfully completed.
Post edited by: Jason_942375
But the compilation of the PIPELINED WILL CREATE the schematic function types automatically. And the TABLE function, applied to the PIPELINED function, use these types of hidden patterns.
-
Characters Czechs corrupt in the Table of contents
Hello world.
I'm working on a project large enough help in Czech. This isn't something that I started from scratch, I took during a colleague who recently left our company, so I don't know much about how it was done.
The project is made of 3 elements, resulting in 3 CHMS which are then copied into the same folder with other CHM using some sort of algorithm.
Once all of these files (CHMS 4 in total) are copied to the folder Help software, they are shown as a component only when you click the button in the software - which means that you see a table of contents complete with chapters of each 3 files).
The problem is when I compile the individual CHMS, I get the message " " "characterparameters HTML help a not supported for the selected language. Do you want to continue? »
If I continue, the file is compiled and when I open it, the table of contents seems ok. However, when I copy with the other files and open in the software (a program of type CAD) some characters are replaced with something else:

I use Robo help 10 and the police in the files is Verdana. I read on another thread than the police could be the problem, but I don't know how to change in all files (except perhaps to Internet Options in the chm directly?)
My regional settings are also defined in Czech when I compile the file, so it shouldn't be a problem. However, whenever I compile, I get this message and corrupt characters are displayed using the software.
Can anyone help with this?
Thanks in advance.
ChristinaI use RH 9.
From my experience, namely character such problems can sometimes more an art than a science. This is what it looks like anyway.
A few issues involved can be:
- Language for non-unicode programs office must match the output of the Control Panel, in the dialog box language and region , on the administration tab, make sure that the language of non-unicode programs is set to the target language.
- Language settings in RoboHelp - under file | Project settings, ensure that you have set the language in HR in Czech for all projects. In addition, in the pod of single Source Layouts, right-click on the output and choose Properties in the drop-down list, and language , make sure that it is set in Czech.
- Encoding of characters in the file itself - open the file (in this case .hhc) within a text editor like Notepad ++ and in menu coding , check its character encoding. By experience, it must be on encode them in UTF-8 encode in UTF-8 without BOM.
- Character encoding in the tag XML - also in Notepad ++, check the coding in the first
tag line 1. My hhc file that we translated into Czech, it is set to
-
Tables merged does not appear in the expected location
I generated a merge document that incorporates a Table. Once completed in v4.3, the table appears in the middle of the first page of the merged document. In the latest 5.5.2 table starts on the second page only, but since it's a long table break occurs on pages 2 and 3 of the merged document. How it makes the Table appear on the first page?
Update: the problem in merged letters disappeared after update Pages 5.6.1.
-
Hey guys,.
IM extracting data from a database and store it as a cluster of tables 1 d and now I want to find an element in a table using the table. After completing the two individual tables I try and seek help search 1 d table comparing to a fourth value has already generated. I was hoping to use the index of table 1 d search to enter something at this level since the other table.
Table im trying to look for a currently a single element, the element im trying to find, but I get a - 1 return.
can you see what I'm doing wrong here? is there something I don't understand not all table 1 d search?
Thank you guys
A common problem here is white space (spaces, tabs, and newline characters, etc.). Try to use Whitespace Trim on the search string and the elements of the array before the search.
-
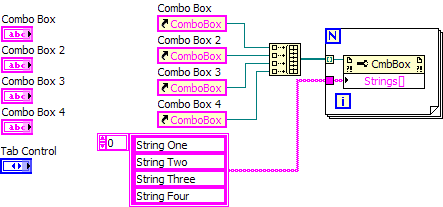
Update of list box strings [] programmatically in a table
Hello
I have an application that has several sites on the front where the user can select variables shared by using a shared variable control. I would like to replace these controls, which are heavy for the operator to select from variables published, to drop-down list boxes that list only the names of variables in a current published library. I have no problem cela providing you a shared list of variables and update the strings [] property in a drop-down list box. Then I can easily convert data types to use as shared variables elsewhere in my program.
However, I have a few questions. First, in some cases, the shared variable controls are inside a table, and I do not know how to fill the combo box selections in the table. Perhaps there is an easy way that I'm missing...?
Second, there are a lot of controls of shared variable that I will need to update the areas drop-down list, and in each case, I have to fill out of th drop-down list boxes programmatically. Is there an easier way to do it with the custom controls or type defs or something, so that I can just bring a control on the front panel that will always fill up with variables shared in my library?
Thanks in advance for the help.
Michael Hampson
XL Automation, Inc.
I rarely disagree with Ben, but a driving force seems to be overkill for a job you want to do it once when the application starts. Simply create a first reference your comboboxes (shouldn't be too much work unless you have a large number of them), then loop through the array, as shown:
-
How to convert a table 1 d of cluster of 5 items in a table of numbers 2D? (a graph historical data)
Hello
in my vi, I have an array with 5 slots displaying measurement data.
The user must be able to record all the data in the history of the card at any time. (for example the user looks at the picture and something happens, then it based on a 'save' - button)
I know that I can read the data in the history with a property node. This isn't the problem. The problem is, how to deal with the data? The type of history data is a table 1 d of cluster of 5 elements.
I convert these data somehow in a 2 D-table of numbers or strings, so that I can easily save it to a text file.
How to convert a table 1 d of cluster of 5 items in a table of numbers 2D?
I use LabVIEW 7.1
Johannes
Hallo Johannes,
the photo shows the trivial way:

-
How can I find the top row of a single table, split among several images in each image.
Hi all.
Thanks in advance.
You can browse all the cells in a row column * and ask the first insertion of a text on his cell point user.user parentTextFrames [0].
If the ID value has changed, the cell is in a different text frame. As well as its line.
CC-2015, it might be a little different, because we have a new type of cell: CellTypeEnum.GRAPHIC_TYPE_CELL (not insertionPoints pave the way).
You can also:
Reproduce all text blocks in history, in that the table is sitting and control for unique tables in duplicates.
Uwe
* edit
-
Muse has a widget that allows users to book tables and/or pay to take?
I've used the Muse to set up my portfolio. Now a new challenge - I need to create a Web site for mobile / tablet users that allows flat navigation, booking tables and perhaps a widget that allows them to pay online prior to the test? I scanned through the tutorials, but not found anything related to the pages of the e-economy.
Hello
No such widget in Muse, but you will need a third-party service to achieve, where you will store the data as who reserved the table, for how long etc. You can nest them in Muse and it should work. An example is given below
Let me know if you have any question.
-
Tuning sql insert that inserts 1 million lines makes a full table scan
Hi Experts,
I'm on Oracle 11.2.0.3 on Linux. I have a sql that inserts data into a table of History/Archives of a table main application based on the date. The application table has 3 million lines. and all the lines that are more then 6 months old must go in a table of History/Archives. This was decided recently, and we have 1 million rows that meet this criterion. This insertion in table archive takes about 3 minutes. Plan of the explain command shows a full table scan on the main Board - which is the right thing, because we are pulling 1 million rows in the main table in the history table.
My question is that, is it possible that I can do this sql go faster?
Here's the query plan (I changed the names of table etc.)
INSERT INTO EMP_ARCH SELECT * FROM EMP M where HIRE_date < (sysdate - :v_num_days); call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 2 0.00 0.00 0 0 0 0 Execute 2 96.22 165.59 92266 147180 8529323 1441230 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 4 96.22 165.59 92266 147180 8529323 1441230 Misses in library cache during parse: 1 Misses in library cache during execute: 1 Optimizer mode: FIRST_ROWS Parsing user id: 166 Rows Row Source Operation ------- --------------------------------------------------- 1441401 TABLE ACCESS FULL EMP (cr=52900 pr=52885 pw=0 time=21189581 us)
I heard that there is a way to use opt_param tip to increase the multiblock read County but did not work for me... I will be grateful for suggestions on this. can collections and this changing in pl/sql also make it faster?
Thank you
OrauserN
(1) create an index on hire_date
(2) tip 'additional' use in the 'select' query '
(3) run ' alter session parallel DML'; before you run the entire statement

Maybe you are looking for
-
Other unable to download Update July 2016, anyone?
If the Podcast app appears in iTunes on the update tab. However, when I click on download, I get an error message with: Podcasts is available only on iOS. To get podcasts, search for it on the App Store on your iOS device. of course, which is an emp
-
Satellite A500 - colors slightly bluish to LED TFT
HelloIs it normal that my LED of Toshiba A500 display has a slightly bluish colors? This is my first LED screen. Best regardsMazu
-
I am trying to decide between getting Zorin OS or Windows 8, but it feels like a bit of a RIP-OFF than a duty pay $70 more for the System Builder version. If I transfer this hard drive to a new computer, would I be able to use the upgrade? Is to us
-
keyboard shortcut to open the clip in first Pro CC
Is there a quick way / keyboard shortcut to select the next clip in the project bin after having previewed 1 clip in the Source monitor Panel?
-
How can I add presets for ambient light on a mac?
I'm migration away from windows and moving to a Macbook pro. I have accumulated several presets I use in the develop module. How can I add them to my Mac?