How to parse this string into an array
Someone sees an easy way to parse this string into an array of type
[Street 1, 2, city, zip code]
the string:
'
[
[address = "Paris Ltd, 5 North Street, Athens, SW1X 9the"]
[address = "Paris Ltd, 5 North Street, Athens, SW1X 9the"]
]
'
THX
If you want just the address as a single entry as myArray [1] = 'Paris Ltd, 5 North, Athens, SW1X 9A Street', then try this:
If you really want the different elements had a blast, you would need a picture of structures, so you get .street1 myArray [1] = 'Paris Ltd ':
Note: As Steve has pointed out, you may need to test for listLen() on the addressList object to determine whether or not there is a street.2 entry in any given row.
Tags: ColdFusion
Similar Questions
-
How to divide a string into an array of strings in separate tables
Greetings,
I have an array of strings which displays strings in a text file. I read each line of the text file and put it in an element of the matrix of the chain.
Now, I'm trying to divide each string for each part of the chain, then put in a separate table. Each element in the chain is separated by a comma. I hit a brick wall at this point and would like to help please?
The purpose of this is so that I have 4 tables that will be ready their item values and set variables based on these values until I went through all the elements in each array.
Attached example.
Also my VI is attached.
Thanks in advance for your help.
Then just use Index Array on 2D array provided.

-
How to split a string into several substrings parent using a delimiter
Hello
I am forced to split a string into several substrings parent using a delimiter.
And insert these substrings in variuou of the columns of a table in a row.
For example. The sting is: ABC * DEF * GHI * JKH *.
where ' *' is the separator.
Desired output:
Col1 Col2 Col3 Col4 Col5
------- -------- -------- ------- ---------
JKH GHI ABC DEF (null)
Could you please guide me how can I achieve this.
Thank you
Bogoss
Hello Salim,
Leave the thread for reference... got this excerpt:
with t as
(
Select "c: its: hgfd:1:23" Str
)
Select
REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 1, null, 1) col1
, REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 2, null, 1) col2
, REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 3, null, 1) col3
, REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 4, null, 1) col4
, REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 5, null, 1) col5
t;
This code snippet works well, but for the fixed columns. Here are 5 predefined columns.
But I need to have a logic that I can browse the string any No.. sometimes.
For example. If I get 3 secondary channels of the parent chain... I need to insert into 3 columns.
And if I get 6 strings under... I need to insert into 6 columns.
Could you please help me develop a logic like that.
I use Oracle database 10g.
And the data are currently being collected on external table... but I can store in a variable or a column of a database table.
Thank you
Bogoss
-
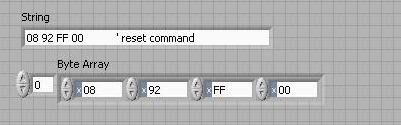
How to convert a string to byte array
Hello
I want to convert a string with a hexadecimal number in the array of bytes, this string includes a cutting-edge information, but I don't want to add this tip to arry bytes.
detailed information please see the photo. I hope someone can give me some instructions, thank you very much.
The accepted solution of Giedrius.S is not correct, based on the image shown in the first post. That the solution will not eliminate the spaces before the tip, and the string to byte array to convert individual characters '0', '8', 'space', '9', etc. for them to byte values. The right solution, based on the image below:

-
How to run a script in environment unix and how to run this program into a toad
Hello guys
Please help me!
How to run a script in the unix environment (Group of programs (cursor, programs...) stored in a file file.sql).
file.sql luks like this
WHENEVER OSERROR EXIT FAILURE
WHENEVER SQLERROR EXIT SQL. SQLCODE
SET the position
SET serveroutput size 1000000
coil ins2aais_jobs;
SELECT "FILE IS: ins2aais_jobs' FROM dual;"
SELECT "STARTED:' began, to_char (sysdate," YY/MM/DD HH24:MI:SS) TIME FROM dual; "
DECLARE
lv_upd_ct number: = 0;
lv_ins_ct number: = 0;
lv_exp_ct number: = 0;
---------------------
date of lv_FROM_date;
date of lv_to_date;
lv_mon_or_week varchar2 (20);
date of lv_week_end_date;
lv_month_indicator varchar2 (8);
-------------------------------------------------
Aais CURSOR IS
SELECT the ID substr (ID, 1, 7), SSN, FNAME, LNAME
, SUCCESS, COMPENSATE, INSTALLATION
, MODU, DRIVE, REVERSE, SUCC_RATE
TRANS_TOTAL, FILE_NAME, WEEK_END_DATE
RUN_DATE
OF weekly_aais;
-------------------------
I aais % rowtype;
-------------------------
PROCEDURE p_ins (r1 aais % ROWTYPE) IS
BEGIN
BEGIN
INSERT INTO AAIS_JOBS
(ID, SSN, SUCCESS, COMPENSATE, INSTALL, MODU
, DRIVE, REVERSE, SUCC_RATE, TRANS_TOTAL
FILE_NAME, WEEK_END_DATE, RUN_DATE
AAIS_FNAME, AAIS_LNAME
)
VALUES
(r1.ID, r1. SSN, r1. SUCCESS, r1. COMPENSATE, r1. INSTALLATION, r1. MODU
r1. DISK, r1. CONVERSELY, r1. SUCC_RATE, r1. TRANS_TOTAL
r1. File_name, r1. WEEK_END_DATE, r1. RUN_DATE
r1. FNAME, r1. LNAME
);
lv_ins_ct: = lv_ins_ct + 1;
EXCEPTION
WHILE OTHERS then
DBMS_OUTPUT. PUT_LINE ('ERROR IN THE INSERT STATEMENT');
DBMS_OUTPUT. Put_line (SQLERRM);
lv_exp_ct: = lv_exp_ct + 1;
END;
END;
------------------------------
PROCEDURE p_disp_msg IS
BEGIN
DBMS_OUTPUT. Put_line (' number of insertion: ' | to_char (lv_ins_ct));
DBMS_OUTPUT. Put_line (' number of Exceptions: ' | to_char (lv_exp_ct));
lv_ins_ct: = 0;
lv_exp_ct: = 0;
END;
---------------------------
BEGIN
lv_FROM_date: = to_date ('& 1', 'DD-MON-RR');
lv_to_date: = to_date ('& 2', 'DD-MON-RR');
lv_mon_or_week: = 'and 3';
lv_month_indicator: = di.get_month_ind (lv_mon_or_week, lv_FROM_date, lv_to_date);
------------------------------------
REMOVE FROM AAIS_JOBS
WHERE WEEK_END_DATE = lv_to_date;
-------------------------------------
COMMIT;
Aais OPEN;
LOOP
EXTRACT the aais IN i;
OUTPUT WHEN aais % NOTFOUND;
BEGIN
p_ins (i);
END;
END LOOP;
Aais CLOSE;
commit;
DBMS_OUTPUT. PUT_LINE ('INSERT INTO TABLE JOBS AAIS');
p_disp_msg;
-----------------------------------
END;
/
SELECT "FINISHED: ' | '. TO_CHAR (sysdate, "MM/DD/YY HH24:MI:SS'") FROM dual
/
spool off
"exit";
and also how we organize this into a toad?
Thank you.Hello
You vous connecter connect to oracle through unix and SQL prompt, run these commands in a .sql file.
Toad, you can run the instructions individually by selecting the sql statements or in a set with the F5 key.
Kind regards
AJR -
Simple question: how to divide the string into multiple lines concatenated?
Hi people,
Maybe it's an easy question.
How to split a string that is concatenated into multiple lines by using the SQL query?
ENTRY:
Delimiter = ', '.select 'AAA,BBB,CC,DDDD' as data from dual
Expected results:
I'm looking for something nice to feature "an opposite to «sys_connect_by_path»»data ------------ AAA BBB CCC DDDD
Thank you
Tomaswith t as (select 'aaaa,,bbbb,cccc,dddd,eeee,ffff' as txt from dual) -- end of sample data select REGEXP_SUBSTR (txt, '[^,]+', 1, level) from t connect by level <= length(regexp_replace(txt,'[^,]*'))+1 REGEXP_SUBSTR(TXT,'[^,]+',1,LE ------------------------------ aaaa bbbb cccc dddd eeee ffff -
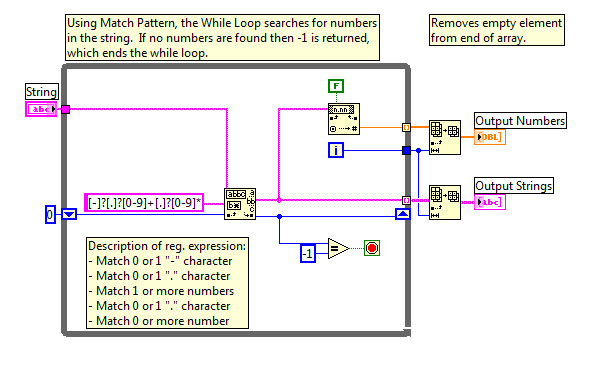
Parse the string into two double
Hello everyone, once again
I'm taking a string of numbers that can be anywhere from - 999999.999999 to + 999999.99999 and separate them into two double rooms. For example, if a user entry - 10000, 10000 - two doubles would be-10000 and-10000. If the user has entered - 10.11111- + 20.00111 he got out - 10.11111 and 20.00111. The VI "Extract the numbers" did perfectly, but I need a way to return the results in two double rooms instead of an array of doubles. I also results to return all the digits after the decimal point for reasons of precision. I use this code within one of my States in a state machine and the driver I use only accepts double rooms.
The code of "Extract the numbers" VI is attached. Thank you all!
Hi buickgn,
When your code works, you should only use IndexArray on outputs. If not, try this one:

-
How to split a string into columns
Hi all
Have a strings like this, where the delimiter is
Thanks in advance10:00 | x1 | 2 | RO | P | Con ausilio | y1 10:10 | x2 | 1 | RO | | | y2 10:20 |x3 | 3 | | | | y3 10:30 |x4 | 3 | RO | N | Con aiuto | y4 10:40 |x5 | 1 | RO | | | y5 how can I break it up into columns, for example, the first char(before first pipe) insert in first variable, then, after first pipe, second characters in a other column ans so on col1 := '10:00'; col2 := 'x1'; col3 := '2'; col4:= 'RO'; col5 := 'P'; col6 := ' Con ausilio '; col7 := 'y1'; col1 := '10:10'; col2 := 'x2'; .. and so onHello
If you want to split the string str into 7 columns :
SELECT TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 1)) AS col1 , TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 2)) AS col2 , TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 3)) AS col3 ... , TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 7)) AS col7 FROM table_x ;If you want to split it inot 7 variables :
col1 := TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 1)); col2 := TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 2)); col3 := TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 3)); ... col7 := TRIM (BOTH FROM REGEXP_SUBSTR (str, '[^|]+', 1, 7)); -
Hello
I have the string as Wednessday, June 13, 2009 | 12 AM GMT, I want to analyze and convert data type Date. I did the same on J2SE, but class SimpleDateFormat does not parse method in RIM API.
Please suggest.
Thank you
RJ
If you are looking for an answer on how to do it in Java, you're the best post your question in the Java development forums.
-
[JS] [ID4] How to parse a string variable
I know it's the sort of thing that any competent writer should already know, but then again, I never claimed to be competent.
I have a script that helps in indexing, and I want to add a feature. In some cases, InDesign sorts alphabetically differently that I would. For example, "applesauce cake' come before"Apple stuffing." (Can tell you I do cookbooks?) I think that the space must classify alphabetically before any letter, while InDesign treats space as if he were not there.
So my script involves a generate a dialogue in which I can change the "sort by:' attribute of the entries." I try to catch each of these challenges alphabetiziation and replace the space with the number '1' so it will sort my way.
The text box "sort by" in my dialog box is populated with the contents of the selection, I do before running the script. I want to do is to have the script change all spaces in 1 itself, and then present the results in the text box. I don't know how to change a variable of string in this way.
Who wants to help the incompetent?
There are several functions for string manipulation. Look in any JavaScript book for more details. For example, to replace all spaces in a string by 1s, follow these steps:
myString = myString.replace (' ', '1')
Other useful string functions are () .slice,. search() and. indexOf(). And as Michael mentioned, some simple rational expressions of learning is well worth the effort.
Peter
-
split a string into separate variables
Suppose I have a procedure that returns the following for the parameter,
V_STR: = ' 10077500733 | 10077500733 | 14/04/2015 | Τ | AJ240557 | 2012 | GREECE | GR | MAN | 00108337640 | CLARKSON | DAVID"
How to cut this string into separate variables?
for example v1 = 10077500733
v3 = 14/04/2015
v4 = null;
Thank you
with qry (STR) as)
Select ' 10077500733 | 10077500733 | 14/04/2015 | T | AJ240557 | 2012 | GREECE | GR | MAN | 00108337640 | CLARKSON | DAVID' the double
)
Select the level,
RTrim (regexp_substr (str, ' [^ |] *(.| $) ', 1, level), ' |') ASPLIT
of qry
connect by level<= length="" (regexp_replace="" (str,="" '[^|]+'))="" +="">
LEVEL ASPLIT 1 '10077500733' 2 '10077500733' 3 April 14, 2015" 4 5 ' T ' 6 'AJ240557 '. 7 '2012 '. 8 "GREECE". 9 "GR". 10 "THE MAN". 11 '00108337640' 12 "CLARKSON." 13 "DAVID." -
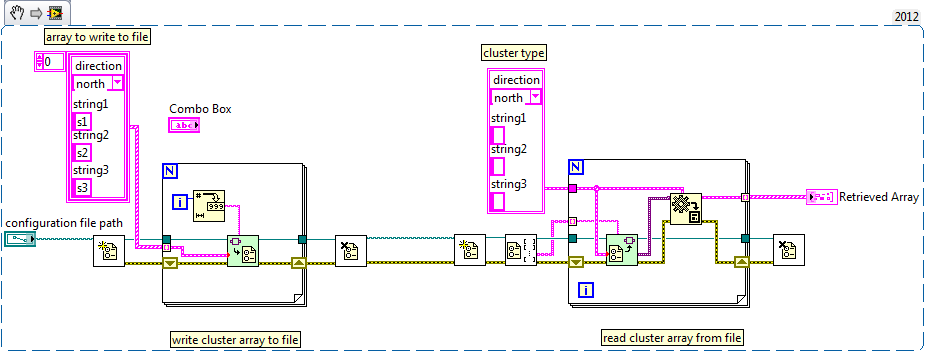
Table 2D cluster table how insert table 2d of strings in an array of cluster?
I have a cluster with 4 channel 3 elements of the string constants and 1 is a list box drop-down chain.
I can save the Bay of cluster to deposit without any problem.
Now, I want to read the file is saved in the Bay of cluster.
How can I insert a table 2d of strings into an array of cluster?
rcard53762 wrote:
I have a cluster with 4 channel 3 elements of the string constants and 1 is a list box drop-down chain.
I can save the Bay of cluster to deposit without any problem.
Now, I want to read the file is saved in the Bay of cluster.
How can I insert a table 2d of strings into an array of cluster?
It would be useful to have an example of what real cluster Bay look like the typical data. One way to do is by saving the content of the table cluster in a configuration file (.ini extension) and then use the OpenG screws of the Variant Configuration file to store and retrieve data from the configuration file. You can get these screws in the VI package manager.
Here is an example. The generated configuration file is also attached.
Ben64
-
How to parse a comma delimited by the string in BPEL 11.1.1.4
I have the MyTag element in xml. I get value for MyTag as Eng, [email protected] (separated by commas) in the BPEL workflow.
I need to parse this string separated by commas in BPEL and extract
Eng AND [email protected]
How can I do this in BPEL? What is the process?Hello
If you get the value like Eng, [email protected] and say that tempVariable Eng, [email protected] data. So, here you go...
substring-after (bpws:getVariableData('tempVariable'), ','), use it in the Expression Builder on the side of the copy operation and that assign to the variable (variable database entry). This will give you [email protected]
substring-before (bpws:getVariableData('tempVariable'), ','), use it in the Expression Builder on the side of the copy operation and that assign to the variable (variable database entry). This will give you in English
I hope this helps...
Thank you
N -
I can't deduct the answer to this question (topic/post title) of the help of LabVIEW on the functions.
Intuitively, it seems that the two representations of data are equal to the memory and so goes between the two should essentially be a no-op when the code is compiled... but is it? (assuming that the length of the array of strings/remains constant, can I go back repeatedly without performance?)
As a string of LabVIEW is a handful and any other type of data except tables aren't a handful; that implies to me that a string = U8-table-grip handle and so a string into an array of U8-could be a memory or inefficient operation since no conversion actually take place?
The reason I ask, is that when you work with for example TCP Read or read VISA, 'data' reading is always a string, but according to what you are doing, this string is often more efficiently processed/interpreted if converted to an array of U8 and I just want to know if (memory and CPU point of view) I can move freely between the chain and U8 array and return depending on what format is most appropriate to a point?
(Also, I'm at this stage fairly certain that the "array of strings of bytes" is cleaner AND more efficient than a type-cast to an array of U8 strin... but I could be wrong.)
I did some tests on this just now, and my conclusion is that it is completely in place. The local users group had a coding challenge when this became relevant to my solution.
-
Split a string into lines {< string1 >} | {< string2 >}
I implemented the Oracle text search in my database. Now I have this query
Select ctx_thes.syn ('RED', 'MY_THESAURUS') of double;
the output is displayed as
{RED} | {MIXTURE OF RED} | {TABLE RED} | {RED}
and I want to get the words in separate lines, i.e.
Red
Mixture of Red
Red table
Red wine
How to split the string into lines?
SELECT * FROM ( SELECT DISTINCT REGEXP_SUBSTR ('{RED}|{RED BLEND}|{RED TABLE}|{RED WINE}', '({)([A-Z]+ *[A-Z]*)(})', 1, LEVEL, 'i', 2) val FROM DUAL CONNECT BY LEVEL <= REGEXP_COUNT ( '{RED}|{RED BLEND}|{RED TABLE}|{RED WINE}', '|') + 1) WHERE val IS NOT NULL;
Maybe you are looking for
-
Hi all Currently I use a Hp Officejet Mobile 100 in my Jeep in the field FRO my work. I have egt tired to change ink, not to mention the expense. I want to install a small laser priner. I bought a Pro Laserjet 1102w and converter of Schumacher 150
-
I try to print a 4 X 6 photo. Photo appears in the Viewer, but the text is printed instead of the photo? Have a 5530 craving. I posted this on 6-11 (now 6-12) and have no answers. How long does take a response?
-
HP Pavilion 1312sr: HP Pavilion 1312sr (B1Q12EA)
Помогите преобрести диск (и) восстановления officially ноутбука HP Pavilion 1312sr (B1Q12EA)
-
My battery will be getting is more fully charged. Even when it is plugged it never went from 6%-
My battery will be getting is more fully charged. Even when it is plugged it never was 6% - What can I do to remedy this?
-
BlackBerry smartphones can not get rid of the icon on the bar indication
There is a number 1 followed by what looks like the WiFi icon, except that it is yellow instead of white.