How to specify a table in Index?
I've looked everywhere, I can think of for this: How can I specify a particular table in a table in Index?I found the statement "You can choose many options of creating table and table organizations (such as the partitioned tables, organized in tables and external tables index) meet the diverse needs of a company." in the SQL Developer Data Modeler 3.0 Users Guide, but not other references such as the way to achieve this.
Thank you
Mike
You must open "Relational model", then "models". After choosing an Oracle implementation. Once this done, under "Tables", you will find your table in the physical model. Double-click the table that you want to make an IOT. On the "General" tab in the menu drop-down 'Organization' you can choose: "INDEX". 'Apply' ing and / or keys 'Ok' from the main menu, 'See'--> 'File DDL Editor_'--> 'Generate'--> 'Ok', you will see your table took the DDL generated for an IOT.
Tags: Database
Similar Questions
-
Clear on how the table of Index OpenG works with a 2D Arrray
Hello
I don't understand how to use the undex OpenG table with a table entry 2D. I joined the contest help window, said that aid
"For 2D tables, connect the clues and indices 0 1 entries to specify the items you want.
So what does really mean? I wired the vi as requested and the vi always puts a 1 d table. So are the lines of entries in table two indexes and columns or what?
I am sure that you send in your line indices table and the table of the column indices and get out of your table 1 d of elements.
(i.e. rank table [1,5,7] and table column [4,8,10] gives you a table 1 d elements (1,4), (5.8), (7.10))
-
How to specify the tablespace for a India primary key in create table statement
How to specify the storage space for a primary key index in a create table statement?
Does the following statement is true?
Thank youCREATE TABLE 'GPS'||TO_CHAR(SYSDATE+1,'YYYYMMDD') ("ID" NUMBER(10,0) NOT NULL ENABLE, "IP_ADDRESS" VARCHAR2(32 BYTE), "EQUIPMENT_ID" VARCHAR2(32 BYTE), "PACKET_DT" DATE, "PACKET" VARCHAR2(255 BYTE), "PACKET_FORMAT" VARCHAR2(32 BYTE), "SAVED_TIME" DATE DEFAULT CURRENT_TIMESTAMP, CONSTRAINT "UDP_LOG_PK" PRIMARY KEY ("ID") TABLESPACE "INDEX_DATA" ) TABLESPACE "SBM_DATA";
Published by: qkc November 9, 2009 13:42As orafad noted, you can use the documentation using ESCALATION clause, i.e.
SQL> ed Wrote file afiedt.buf 1 CREATE TABLE GPS 2 ("ID" NUMBER(10,0) NOT NULL ENABLE, 3 "IP_ADDRESS" VARCHAR2(32 BYTE), 4 "EQUIPMENT_ID" VARCHAR2(32 BYTE), 5 "PACKET_DT" DATE, 6 "PACKET" VARCHAR2(255 BYTE), 7 "PACKET_FORMAT" VARCHAR2(32 BYTE), 8 "SAVED_TIME" DATE DEFAULT CURRENT_TIMESTAMP, 9 CONSTRAINT "UDP_LOG_PK" PRIMARY KEY ("ID") USING INDEX TABLESP ACE "USERS" 10 ) 11* TABLESPACE "USERS" SQL> / Table created.Justin
-
How FLASHBACK all TABLEs and indexes in a certain pattern for a restoration of p?
Today I read a few web pages on how to use FLASHBACK to restore to a Restore Point.
Unfortunately, all of these examples show just how to restore a single TABLE for example
FLASHBACK TABLE t to RESTORE POINT before_we_do_anything;
But how can I FLASHBACK all TABLEs (and indexes and other dependent objects) in a certain pattern to a one-step restore point)?
FLASHBACK myschema.* to before_we_do_anything POINT of RESTORATION;
does not work.
PeterThere is nothing like that. However, you could flashback the entire database to a point in time. It would of course have implications through patterns all the good.
Nicolas.
-
How do you know the name of table or index that has the segment?
Hi all
I want to move the data to the LOB_TABSPC on LOB_TABSPC1 tablespace. I almost moved my data. But when I checked the LOB_TABSPC tablespace, there is still a segment:
Line: -.
Select dba_segments nom_segment, nom_partition, SEGMENT_TYPE, nom_tablespace, HEADER_FILE, HEADER_BLOCK, BYTES, BLOCKS, EXTENTS where OWNER = 'xxx' and nom_tablespace = 'LOB_TABSPC. '
Rank # nom_segment nom_partition SEGMENT_TYPE nom_tablespace HEADER_FILE, HEADER_BLOCK BYTES BLOCKS SCOPES
1 SYS_IL0000103064C00019$ $ SYS_IL_P87 INDEX PARTITION 18 59 131072 16 2 LOB_TABSPC
2 SYS_IL0000103064C00019$ $ SYS_IL_P88 INDEX PARTITION 18 67 65536 8 1 LOB_TABSPC
3 SYS_IL0000103064C00018$ $ SYS_IL_P83 INDEX PARTITION 18 27 196608 24 3 LOB_TABSPC
4 SYS_IL0000103064C00018$ $ SYS_IL_P84 INDEX PARTITION 18 35 196608 24 3 LOB_TABSPC
5 SYS_LOB0000103064C00018$ $ SYS_LOB_P81 LOB PARTITION 18 11 34603008 4224 48 LOB_TABSPC
6 SYS_LOB0000103064C00018$ $ SYS_LOB_P82 LOB PARTITION 18 19 33554432 4096 47 LOB_TABSPC
7 SYS_LOB0000103064C00019$ $ SYS_LOB_P85 LOB PARTITION 18 43 11534336 1408 26 LOB_TABSPC
8 SYS_LOB0000103064C00019$ $ SYS_LOB_P86 LOB PARTITION 18 51 13631488 1664 28 LOB_TABSPC
Line: -.
I don't know the table or index that has these segments to move into the new tablespace.
Please help me...Use the dba_lob_partitions view.
-
How to collect statistics of Tables and index
Hi all
Please help me in the collection of statistics of Tables and index.
Thank youfor tables
exec dbms_stats.gather_table_stats ("SCOTT", "EMPLOYEES");for indexes
DBMS_STATS.gather_index_stats exec ('SCOTT', 'EMPLOYEES_PK');Visit this link for details
http://nimishgarg.blogspot.com/2010/04/Oracle-dbmsstats-gather-statistics-of.html -
10.1.3: how the client ID of the elements in a specified af:table?
Hi all
I have an af:table (let's say the departments) with some columns (say DeptName) is one of them and (say) a range of 15 ranks. Normally, modulo naming containers, the clientId of the field DeptName is of the form:
Departments: 0_indexed_row_in_af_table:DeptName
So, for example, DeptName field in the third row of the table will be
Departments: 2:DeptName
The problem occurs when, due to, say, a data change and refresh, a partially separate set of lines appears in the table when updating. Then, all the old lines reappear will keep their old , but News clientIds lines will get new numbers, from 15. So, if the update the first and third rows in the first and fourth, retains, and retrieves new lines for the second and third position the client ID for the first fields in four departments such as they appear in the table will be:
Departments: 0:DeptName
Departments: 15:DeptName
Departments: 16:DeptName
Departments: 2:DeptName
If new data completely , the table will be rendered starting with departments: 15:DeptName.
My question: is there a way to understand, by program, what the customer for a particular area of DeptName ID will be, assuming that the table could have been refreshed with partially or completely new data in an arbitrary number of times?
Thanks much for any help.
AvromHello
Try something like the following:
RichTable table = // Get the table component instance somehow; int rowIndex = // Find the right row and get its INDEX in the ResultSet and/or data, not the row key // Save row state Object oldRowKey = table.getRowKey(); try { table.setRowIndex(index); UIComponent field = table.getChildren().get(columnIndex).getChildren().get(0); // Get the field from column columnIndex field.getClientId(FacesContext.getCurrentInstance()); // Since setRowIndex was called, the id should be correct } finally { // Restore state table.setRowKey(oldRowKey); }The idea of rowKey vs rowIndex is rowKey is stable to ensure that a key to the given line is always the same line (very useful to avoid a strange problem with sorting), while the line index change with the position of the line.
Kind regards
~ Simon
-
Write only the range specified 2D table data to a string worksheet?
Hi all
My problem today is a simple, but for the life of me, I can't find an answer using search. I have a table of 2D data points (values of Y) with their corresponding index numbers. When I start my VI, I retrieve a table of 10's of thousands of values, but I want to be able to extract only a few hundred values (specifically, one or two periods of a periodic sound of the waves) at the most to display in a string of spreadsheet for further calculations in Excel.
I managed to get the data written to the string of spreadsheet easily, but I'm stumped on how to specify the range (using the index values) to allow to write in the worksheet line. I tried "delete table", but I must be missing some functionality, because I can't seem to remove all values above one index max and min specified index below (in order to simply get the values between max and min).
Help a beginner?
Appreciated.
Use the subset of the table?
-
New tables and indexes created do not appear in the view dba_segments
Hi all
I created 3 tables and indexes, but these items do not appear in dba_segments views. Is this a normal behavior? Previously, with dictionary managed tablespace, I can specify the least possible to create, at the table/index is created. But I don't know how works the locally managed tablespace. Please do advice. Thank you much in advance.
I am using Oracle 11 g R2 (11.2.0.1.0) for Microsoft Windows (x 64), running on Windows 7.
To reproduce this problem, I created the tablespaces as follows:
CREATE TABLESPACE CUST_DATA
DATAFILE ' d:\app\asus\oradata\orcl11gr2\CUST_DATA01. DBF' SIZE 512K
AUTOEXTEND ON NEXT MAXSIZE 2000 K 256K
MANAGEMENT UNIFORM LOCAL 256K SIZE MEASURE
SEGMENT SPACE MANAGEMENT AUTO;
CREATE TABLESPACE CUST_INDX
DATAFILE ' d:\app\asus\oradata\orcl11gr2\CUST_INDX. DBF' SIZE 256K
AUTOEXTEND ON NEXT MAXSIZE 2000 K 128K
MANAGEMENT UNIFORM LOCAL 128K SIZE MEASURE
SEGMENT SPACE MANAGEMENT AUTO;
CREATE TABLE CUSTOMER_MASTER (CUST_ID VARCHAR2 (10))
CUST_NAME VARCHAR2 (30),
E-MAIL VARCHAR2 (30),
DATE OF BIRTH,
ADD_TYPE CHAR (2) CONSTRAINT CK_ADD_TYPE CHECK (ADD_TYPE ("B1", "B2", "H1", "H2")),
CRE_USER VARCHAR2 (5) DEFAULT USER,.
CRE_TIME TIMESTAMP (3) DEFAULT SYSTIMESTAMP.
MOD_USER VARCHAR2 (5).
MOD_TIME TIMESTAMP (3),
CONSTRAINT PK_CUSTOMER_MASTER PRIMARY KEY (CUST_ID) USING INDEX TABLESPACE CUST_INDX)
TABLESPACE CUST_DATA;
SQL > SELECT TABLE_NAME, nom_tablespace
USER_TABLES 2
3 WHERE TABLE_NAME LIKE '% CUST. "
TABLE_NAME, TABLESPACE_NAME
------------------------------ ------------------------------
CUSTOMER_MASTER CUST_DATA
SQL > SELECT INDEX_NAME, nom_tablespace
2 FROM USER_INDEXES
3 WHERE TABLE_NAME LIKE '% CUST. "
INDEX_NAME TABLESPACE_NAME
------------------------------ ------------------------------
PK_CUSTOMER_MASTER CUST_INDX
SQL > SELECT nom_segment, SEGMENT_TYPE, nom_tablespace, BYTES
2 FROM WHERE USER_SEGMENTS;
no selected lineAn extension to what Sybrand said:
There is a parameter called differed_segment_creation, who runs the behavior.
If it is set to TRUE (the default), no segments will be allocated until you fill your table / index.
Try to insert a row. You will see your table and index in dba_segments.
See for more information
http://docs.Oracle.com/CD/E14072_01/server.112/e10595/tables002.htm
-
Partitioned Tables and indexes
Hello
I have a question on the table and index partitioning. My scenario is:
Charge 2 mio records in table T once a month. Loaded records are added to existing records, and once loaded data is never changed.
At some point, I want to delete the older recordings, so I intend to this partition table.
T table looks like:
My plan is to partition T over the period, and I'm trying to read through the conceptscreate table t (id number(10) not null constraint t_pk primary key, period number(10) not null, contract number(10) not null, attr number(10) not null); create unique index t_ux1 on t(contract,period); create index t_ix2 on t(period);
http://download.Oracle.com/docs/CD/B19306_01/server.102/b14220/partconc.htm#g471747
My question is now, how to manage the indexes, the t_pk, the t_ux1 and the t_ix2. Concepts of say,
«1. If the table partitioning column is a subset of index keys, use a local index.»
"2. If the index is unique, use a global index. If this is the case, you are finished. »
So, that's how I read it
-t_pk is unique, so this should be global
-t_ux1 of columns is a subset, unless I have misunderstood (?), which should be local
-index t_ix2 column is the same as the partitioning column, so it must be local
Is this right, this t_ux1 should be a local partioned index, even if the period is the second column in the index?
If true, what will happen when a partion fell?
I am new in this area, so please feel the comment as you wish.
Concerning
Peter
BANNER
----------------------------------------------------------------
Oracle Database 10 g Enterprise Edition release 10.2.0.3.0 - 64bi
PL/SQL version 10.2.0.3.0 - Production
CORE Production 10.2.0.3.0
AMT for IBM/AIX RISC System/6000: Version 10.2.0.3.0 - production
NLSRTL Version 10.2.0.3.0 - ProductionPeter Gjelstrup wrote:
My question is now, how to manage the indexes, the t_pk, the t_ux1 and the t_ix2. Concepts of say,
«1. If the table partitioning column is a subset of index keys, use a local index.»
"2. If the index is unique, use a global index. If this is the case, you are finished. »
So, that's how I read it
-t_pk is unique, so this should be global
-t_ux1 of columns is a subset, unless I have misunderstood (?), which should be local
-index t_ix2 column is the same as the partitioning column, so it must be localIs this right, this t_ux1 should be a local partioned index, even if the period is the second column in the index?
A partitioned index locally can only be defined as unique if the partition key is part of the columns in the index. Imagine what the database would have to do if this is not the case: in order to verify if a newly added or updated value violates the uniqueness, it will have to travel all the partitions in a serialized operation - means that no one else could do the same thing at the same time. Since he is a killer of serious scalability in terms of locking and contention, this is not allowed.
So: Your T_UX1 index can be defined as a unique index that is local because it contains the partition key. Although the index is not prefixed ("Prefix" means that it is divided by the left side of the columns in the index) which means that there may be access patterns where all partitions should be scanned or the optimizer cannot use a method of size of effective partition according to the way the index is reached.
Your T_PK index cannot be set as local because it must be unique (you can not use a local non-unique index in this case), but does not contain your partition key. It must be a global index. An overall index can be partitioned as well (different from the underlying table) but it doesn't have to be.
Depends on how you access your data you have not T_IX2 index when partitioning by this key because it corresponds to the partition key and therefore could not actually be used by the mechanism of partition pruning that limit your query to the scores of individuals.
If you have more than one MAS environment where running queries are used longer, you should be fine with the index the in general (because they could be analyzed in parallel in parallel operations), but if you have an OLTP environment, then you should avoid local no prefix indexes due to the potential problem that you need to analyze all partitions.
Be borne in mind that with partitioning adds an important layer of complexity to other areas: in particular the options available to the optimizer and analyze cost optimizer statistics. Depends on how you access your statistical data must be maintained on several levels now (level of score and at the global level, in the case of subpartitioning may be still at this level). If your data is important and you rely on "global" level statistics (these are always the case when the optimizer at the time analysis cannot limit access to a single partition) then in the pre - 11 g databases analyze these "global" level statistics can take a lot of time and resources, since actually , you need data several times (once for the partition and even global level).
Presenting this partitioning may mean other potential problems in terms of execution that change (not for the better sometimes) plans and how to effectively collect statistics. Note that g 11 addresses the issue of 'statistics' by introducing the so-called "extra" global statistics. Greg Rahn wrote a [blog note | http://structureddata.org/2008/07/16/oracle-11g-incremental-global-statistics-on-partitioned-tables/] on this nice feature.
>
If true, what will happen when a partion fell?
Since you're already on 10g, you can specify the database to update the scores of the local index using the UPDATE of the INDEX clause, while 9i could maintain only an overall index and it is up to you to rebuild the local index partitions after the partition DDL on the table (according to the DDL operation).
Kind regards
RandolfOracle related blog stuff:
http://Oracle-Randolf.blogspot.com/SQLTools ++ for Oracle (Open source Oracle GUI for Windows):
http://www.sqltools-plusplus.org:7676 /.
http://sourceforge.NET/projects/SQLT-pp/Published by: Randolf Geist on Sep 30, 2008 16:39
Added statistics / optimizer warning when you use the partitioning
-
How to build a table of TDMS file open
Hello
Examples NI TDMS - Express write data .vi (time domain), I can build a PDM file with 2 channels (sine and square waveforms) data, which are stored as test.tdms.
Using Express read .vi data (time domain), 2 channels of waveform data are read. How to build a table later? How to separate the 2 channels of data in the tables 1-2 and manipulate the data using table functions?
For example,.
I want to collect 100 from index100 between channel 0 and their average. I want to take 50 samples from the channel 50 1 index and double each element.
Thank you for your help.
Hey Bing.
You can perform operations on different channels in the 2D table using the table to index. This will allow you to choose the channel to operate on, then you can perform the operation inside a loop on each element. In the included code snippet, I used a shift register to find the total cumulative values in channel 0 and then divided by the number of samples.
I recommend you read some tutorials LabVIEW and bases of knowledge on topics that are related to yours. These could help a lot.
I hope that my suggestions help,
Chris
-
How to build a table using incoming data stream?
I'm programming in VBAI but use LV as my Interface of Inspection. The VBAI program will go into a finite loop (x 1000) and the digital indicator with dbl vaule of food in front of the LV Panel if the value double is in order.
In LV, how to build a table (index 0-999) with this stream?
-
How to create a table in if/else or structure without 0-case?
Hello
I tried to do for a while now.
I only managed to think about this in three ways:
1. (what I'm doing right now
 create the table through a loop for, fills the table in automatic indexing.) Filled it with many of if true and with a '0' if the value false. The idea was to remove the 0 later in the code. However, this seems very inefficient.
create the table through a loop for, fills the table in automatic indexing.) Filled it with many of if true and with a '0' if the value false. The idea was to remove the 0 later in the code. However, this seems very inefficient.2 make use of a registry change, which automatically adds the correct number of a table. The problem is that the table will keep growing and growing and at the very least would enormously slow down my program. At worst, it would break.
So my question is: how to create a table that if a comparison is true, it puts the item in and if not, it does nothing?
I have attached a PNG of my code snippet.
Kind regards
David.
If you want to only affect exactly as much memory as you need for the table, you can count the number of true elements in the table of Boolean everything first and then assign one of exactly this size. In this way, you are more memory and time-efficient whether overuse (such as allocation of an array of I32 as big as the whole table boolean) or underallocating (from zero element and let it grow automatically whenever you add on).
Count the true values, allocate an array only the great and then replace each value in this new table with indexes / "I ' value where the real exists." An excerpt from VI:
-
How to build the table with all the combinations of a source table?
Hello
I have a 2D array that contains the list of the power user-defined settings. The number of PSs (table rows) is not fixed. For example - 3 PSs:
Stage of Min Max name
PS1 3.0 3.6 0.3
PS2 0.9 1.2 0.1
PS3 1.7 1.9 0.1
I need to build, from this list, a table of all the combinations as below:
PS1 PS2 PS3
3.0 0.9 1.7
3.0 0.9 1.8
3.0 0.9 1.9
3.0 1.0 1.7
3.0 1.0 1.8
3.0 1.0 1.9
3.0 1.1 1.7
3.0 1.1 1.8
3.0 1.1 1.9
3.0 1.2-1.7
3.0 1.2-1.8
3.0 1.2-1.9
3.3 0.9 1.7
3.3 0.9 1.8
3.3 0.9 1.9
3.3 1.0 1.7
3.3 1.0 1.8
3.3 1.0 1.9
3.3 1.1 1.7
3.3 1.1 1.8
3.3 1.1 1.9
3.3 1.2 1.7
3.3 1.2 1.8
3.3 1.2 1.9
3.6 0.9 1.7
3.6 0.9 1.8
3.6 0.9 1.9
3.6 1.0 1.7
3.6 1.0 1.8
3.6 1.0 1.9
3.6 1.1 1.7
3.6 1.8 1.1
3.6 1.1 1.9
3.6 1.2 1.7
3.6 1.2 1.8
3.6 1.2 1.9
How to build this table programmatically?
(Note also that the number of rows in the source table is not fixed).
Thanks in advance!
Hi Berezka,
using a magic of automatic indexing:
-
How can I download document while index of area recreation
CREATE TABLE my_docs)
ID NUMBER (10) NOT NULL,
name VARCHAR2 (200) NOT NULL,
doc BLOB NOT NULL
);
ALTER TABLE my_docs ADD)
CONSTRAINT my_docs_pk PRIMARY KEY (id)
);
CREATE SEQUENCE my_docs_seq;
DIRECTORY to CREATE or REPLACE documents AS "C:\work"
CREATE OR REPLACE PROCEDURE load_file_to_my_docs (p_file_name IN my_docs.name%TYPE) AS
v_bfile BFILE.
v_blob BLOB;
BEGIN
INSERT INTO my_docs (id, name, doc)
VALUES (my_docs_seq. NEXTVAL, p_file_name, empty_blob())
RETURN doc INTO v_blob;
v_bfile: = BFILENAME ('DOCUMENTS', p_file_name);
Dbms_Lob.FileOpen (v_bfile, Dbms_Lob.File_Readonly);
Dbms_Lob.LoadFromFile (v_blob, v_bfile, Dbms_Lob.Getlength (v_bfile));
Dbms_Lob.FileClose (v_bfile);
COMMIT;
END;
/
EXEC load_file_to_my_docs ('any_document_of_PDF_DOC_DOCX');
-Download any DOCUMENT size 10 m approx. 4-5 documents.
CREATE INDEX my_docs_doc_idx ON my_docs (doc) INDEXTYPE IS CTXSYS. CONTEXT PARAMETERS ("sync (on commit)");
DROP INDEX my_docs_doc_idx;
now to re-create the indexes on the same column
CREATE INDEX my_docs_doc_idx ON my_docs (doc) INDEXTYPE IS CTXSYS. CONTEXT PARAMETERS ("sync (on commit)");
- at the same time in another session try to download any document in the table above
you will face ORA-29861: area index is shown LOADING/FAILURE/UNUSABLE
How can I download document while index of area recreationYou can use:
Your_index ALTER INDEX REBUILD PARAMETERS online ("REPLACE LEXER your_lexer");
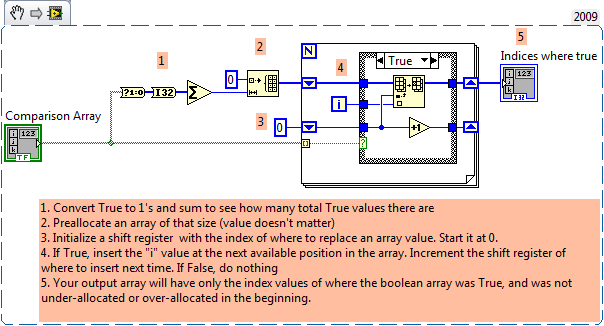
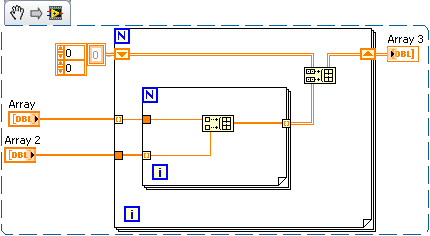
Maybe you are looking for
-
History: My iMac 27' was overwhelming at all times. Do not reboot, I have to unplug the computer 15 sec to turn it back on. Started about three months ago. Called the Apple service, re-installed El Capitan. Re-installed my apps: notability, Google Re
-
Cannot click on anything whatsoever in the browser firefox on a Mac under OS 10
I have lots of Mac Mini, I had a few problems of late where I bring Firefox I can't get anything in response within the browser, I can click on file and Firefox completely, but I can not click on the address bar or any other site to a computer lab. I
-
OfficeJet pro 8600 in small print
After a few years of trouble-free operation, my 8600 printer started printing from the internet really tiny catalog. Yet it prints well regular applications such as Word, Excel, etc. What have I done to her?
-
The dreaded blue screen on startup with Windows XP
Get the dreaded blue screen at startup. Use Windows XP and my PC of becomes as much as the screen connection, but when I select my login name, that the blue screen appears. If I choose one of the other names the process gets a little further, but the
-
Original title: "the instruction at 0x6434c5e9 referenced memory at 0x0ef2ea80. The memory could not write. "And the instruction at 0x6434c5e9 referenced memory at 0x0ef2ea80. The memory could not be written. I have Windows Vista and I use speech rec