in literal newline character
is it possible to put a line break character in a literal? Or a < br >? Is it possible to make the TEBs line wrap?
Cp7/PC.
Thank you.
No to your first question.
Wrap of TEB: you must check "See the scroll bar" somewhere, I'm on Captivate 8 but of course you have it in an accordion in Captivate 7 as well.
Another idea: have you ever tried the interaction text scrolling? This is another way for users to enter text. In CP7 you are not able to control what is displayed, you cannot clear the text (for TEB either, not even not to CP8)
I used it here: matters of custom Hotspot in Captivate 8 - Captivate blog
Tags: Adobe Captivate
Similar Questions
-
Dear all,
Please help me with a query that replace the newline with null characters.
Suppose that I have a field test string and value in it's...
testString ="Hello, this is Yvon
->->-> (Average gap newline character should be replaced by NULL)
It is also Jean Louis"
Please, help me with a query to achieve the highest case talk.
Thanks and greetings
Yvon Das
Not sure you understand... maybe something like that?
SQL > select ' Hello, this is Yvon
2 it is also Yvon ' double.
"HELLO, THISISMONOJTHISISALSOMONOJ.
-----------------------------------------
Hello, this is Yvon
It is also Yvon
SQL > select replace ("Hello, this is Yvon
2 it is also Yvon ', chr (10), null)
3 double;
REPLACE ("HELLO THISISMONOJTHISISALSOMONO")
----------------------------------------
Hello, this is Jean Louis is also Jean-Louis
SQL >
-
manage the CLOB data delimited by tabs with the newline character
Hi all
I have a table with a column of type CLOB data where my data are delimited by tabs. For the new line I Chr (10) as the separator between the lines. Someone knows how to handle this character in order to select these data in separate lines.
Here is the example:
create table xx_test1(col1 clob); insert into xx_test1 values (TO_CLOB('1'||chr(9)||'5467'||chr(9)||'41773'||chr(9)||'5467'||chr(9)||'169407'||chr(9)||'GBP'||chr(9)||'08-Feb-2016'||chr(9)||'08-Feb-2016'||chr(9)||'UK Accrual Invoice'||chr(9)||'UK Accrual - import'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'RDWHMP.03.00025.IND'||chr(9)||''||chr(9)||'300'||chr(9)||'15'||chr(9)||'Each'||chr(9)||'ZZU'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'PL Imported Invoices'||chr(9)||'119'||chr(9)||'229'||chr(9)||'340'||chr(9)||'450'||chr(9)||'560'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'Franchise COGS'||chr(9)||'12'||chr(9)||'13'||chr(9)||'14'||chr(9)||'15'||chr(9)||'Y'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'10'||chr(9)||'0'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''|| chr(10) || '2'||chr(9)||'5467'||chr(9)||'41773'||chr(9)||'5467'||chr(9)||'169407'||chr(9)||'GBP'||chr(9)||'08-Feb-2016'||chr(9)||'08-Feb-2016'||chr(9)||'UK Accrual Invoice'||chr(9)||'UK Accrual - import'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'RDWHMP.03.00025.IND'||chr(9)||''||chr(9)||'10'||chr(9)||'15'||chr(9)||'Each'||chr(9)||'ZZU'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'PL Imported Invoices'||chr(9)||'120'||chr(9)||'230'||chr(9)||'341'||chr(9)||'451'||chr(9)||'561'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'Franchise COGS'||chr(9)||'12'||chr(9)||'13'||chr(9)||'14'||chr(9)||'15'||chr(9)||'Y'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'10'||chr(9)||'0'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''));I'll try this one, but it does not work. The last column is not correct and it returns the value of the next line and also does not continue to the end (I presume it's due to the position of the character hardcoded in regexp_substr). Any ideas how to handle?
WITH c_file_imp_data AS (SELECT dbms_lob.substr(col1, 32767, 1) src FROM xx_test1) SELECT --regexp_subsr is finding the position of the x occcurrance of a tab delimitter to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 1), chr(9))), --RECORD_ID to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 2), chr(9))), --BILL_TO_CUSTOMER_NUMBER, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 3), chr(9))), -- BILL_TO_LOCATION, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 4), chr(9))), -- SHIP_TO_CUSTOMER_NUMBER, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 5), chr(9))), -- SHIP_TO_LOCATION, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 6), chr(9)), -- CURRENCY, to_date(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 7), chr(9)), 'DD-MON-YYYY'), -- GL_DATE, to_date(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 8), chr(9)), 'DD-MON-YYYY'), -- TRANSACTION_DATE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 9), chr(9)), -- TRANSACTION_TYPE_NAME, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 10), chr(9)), -- TRANSACTION_SOURCE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 11), chr(9)), -- TERMS, to_date(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 12), chr(9)), 'DD-MON-YYYY'), -- DUE_DATE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 13), chr(9)), -- PAYMENT_METHOD, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 14), chr(9))), -- SALESREP_NUMBER, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 15), chr(9)), -- ITEM, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 16), chr(9)), -- DESCRIPTION, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 17), chr(9))), -- QUANTITY, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 18), chr(9))), -- UNIT_SELLING_PRICE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 19), chr(9)), -- UNIT_OF_MEASURE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 20), chr(9)), -- WAREHOUSE, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 21), chr(9))), -- TAX_RATE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 22), chr(9)), -- TAX_CODE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 23), chr(9)), -- GL_ACCOUNT_STRING, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 24), chr(9))), -- CURRENCY_EXCHANGE_RATE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 25), chr(9)), -- LINE_TRX_DFF_CONTEXT_VAL, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 26), chr(9)), -- LINE_TRANSACTION_FIELD1, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 27), chr(9)), -- LINE_TRANSACTION_FIELD2, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 28), chr(9)), -- LINE_TRANSACTION_FIELD3, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 29), chr(9)), -- LINE_TRANSACTION_FIELD4, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 30), chr(9)), -- LINE_TRANSACTION_FIELD5, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 31), chr(9)), -- LINE_TRANSACTION_FIELD6, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 32), chr(9)), -- LINE_TRANSACTION_FIELD7, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 33), chr(9)), -- LINE_TRANSACTION_FIELD8, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 34), chr(9)), -- LINE_TRANSACTION_FIELD9, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 35), chr(9)), -- LINE_TRANSACTION_FIELD10, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 36), chr(9)), -- LINE_TRANSACTION_FIELD11, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 37), chr(9)), -- LINE_TRANSACTION_FIELD12, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 38), chr(9)), -- LINE_TRANSACTION_FIELD13, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 39), chr(9)), -- LINE_TRANSACTION_FIELD14, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 40), chr(9)), -- LINE_TRANSACTION_FIELD15, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 41), chr(9)), -- INV_LINE_INFO_DFF_CONT_VAL, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 42), chr(9)), -- NO_ANIMALS, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 43), chr(9)), -- MX_WEIGHT, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 44), chr(9)), -- MX_SLAUGHTER, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 45), chr(9)), -- REBILLED, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 46), chr(9)), -- NON_STAT, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 47), chr(9)), -- ATTRIBUTE12, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 48), chr(9)), -- ATTRIBUTE13, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 49), chr(9)), -- ATTRIBUTE14, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 50), chr(9)), -- ATTRIBUTE15, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 51), chr(9)), -- ATTRIBUTE8, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 52), chr(9)), -- ATTRIBUTE11, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 53), chr(9)), -- ATTRIBUTE2, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 54), chr(9)), -- ATTRIBUTE3, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 55), chr(9)), -- ATTRIBUTE4, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 56), chr(9)) -- ATTRIBUTE9 FROM c_file_imp_data
Oracle DB version: 12 c
Thanks in advance,
Alex
with
xx_test1 as
(select TO_CLOB ('1' |)) Chr (9) | "5467' | Chr (9) | "41773' | Chr (9) | "5467' | Chr (9) | ' 169407' | Chr (9) | ' GBP'. Chr (9) | "February 8, 2016'. Chr (9) | "February 8, 2016'. Chr (9) | "Bill regularization UK' | Chr (9) | "Accumulation of UK - import '. Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ' RDWHMP.03.00025.IND' | Chr (9): "| Chr (9) | ' 300'. Chr (9) | ' 15' | Chr (9) | ' Each ' | Chr (9) | ' ZZOU ' | Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | "PL imported invoices | Chr (9) | ' 119' | Chr (9) | ' 229'. Chr (9) | ' 340' | Chr (9) | "450 | Chr (9) | ' 560' | Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | "Franchise of the WORKINGS. Chr (9) | ' 12'. Chr (9) | ' 13'. Chr (9) | ' 14'. Chr (9) | ' 15' | Chr (9) | » Y'|| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ' 10'. Chr (9) | » 0' || Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (10) | '2'|| Chr (9) | "5467' | Chr (9) | "41773' | Chr (9) | "5467' | Chr (9) | ' 169407' | Chr (9) | ' GBP'. Chr (9) | "February 8, 2016'. Chr (9) | "February 8, 2016'. Chr (9) | "Bill regularization UK' | Chr (9) | "Accumulation of UK - import '. Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ' RDWHMP.03.00025.IND' | Chr (9): "| Chr (9) | ' 10'. Chr (9) | ' 15' | Chr (9) | ' Each ' | Chr (9) | ' ZZOU ' | Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | "PL imported invoices | Chr (9) | ' 120'. Chr (9) | ' 230'. Chr (9) | ' 341'. Chr (9) | ' 451' | Chr (9) | "561' | Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | "Franchise of the WORKINGS. Chr (9) | ' 12'. Chr (9) | ' 13'. Chr (9) | ' 14'. Chr (9) | ' 15' | Chr (9) | » Y'|| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ' 10'. Chr (9) | » 0' || Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ") the_clob
of the double
)
Select x.lne
of xx_test1 t.
XMLTable ('/ a/b ')
from xmltype ('' |) Replace (t.the_clob, Chr (10),''): '')
path of ESA varchar2 columns (4000) '.'
) x
ESA 1 5467 41773 5467 169407 GBP 8 February 2016 8 February 2016 regularization invoice accounting UK UK - import RDWHMP.03.00025.IND 15 300 each ZZU PL Imported bills 119 229 340 450 560 Franchise COGS 12 13 14 15 Y 10 0 2 5467 41773 5467 169407 GBP 8 February 2016 8 February 2016 regularization invoice accounting UK UK - import RDWHMP.03.00025.IND 10 15 imported bills each PL ZZU 120 230 341 451 561 Franchise COGS 12 13 14 15 Y 10 0 It seems that you know how to do the rest
Concerning
Etbin
-
Sqlplus recognize any type of DBMS_OUTPUT newline character?
I am creating a complex chain inside a procedure and the display with dbms_output.put_line. It works fine with SQL Developer, but when I use it in SQL Plus it comes out goofy. It was narrowed down to me using Chr (10) where I want the line breaks. Is it possible to display a 'formatted' in SQL varchar2, as I expect them? I've even tried using .put with no luck.
With the help of:
Oracle 10.2.0.4.0
SQL Plus 10.2.0.1 / 9.2.something
Here is a little example:
Right now I use a work around, but want to use a character (or a combination of characters) that SQL more will play with beautiful... If there is.set serverout on set linesize 10 declare lv_string varchar2(32767); begin for x in 1..5 loop lv_string := lv_string || 'I AM LINE ' || to_char(x) || chr(10); end loop; dbms_output.put_line(lv_string); end; / Expected Output (What I'm getting in SQL Developer): I AM LINE 1 I AM LINE 2 I AM LINE 3 I AM LINE 4 I AM LINE 5 Actual Output (SQL Plus): I AM LINE 1 I AM LINE 2 I AM LINE 3 I AM LINE 4 I AM LINE 5
declare lv_string varchar2(32767); lv_start pls_integer; lv_end pls_integer := 0; c_newl constant varchar2(1) := chr(10); begin for x in 1..200 loop lv_string := lv_string || 'I AM LINE ' || to_char(x) || c_newl; end loop; loop lv_start := lv_end + 1; lv_end := instr(lv_string, c_newl, lv_start); exit when lv_end <= lv_start; dbms_output.put_line(substr(lv_string, lv_start, lv_end- lv_start)); end loop; end; /Hello
Try increasing your linesize:
set linesize 180
-
I'm trying to understand how to use a line break within text in header for a dataGridColumn. This is what I have at the moment, it simply shows the title as "approved" & \n extension. ".
Thank you!Use:
Approved
Extension of timeTracy
-
ADF: how to insert the character of new line in the column of VO?
Hello world
IM using Jdev 11 G.
I have a VO with 5 columns appear on the page of the ADF. (VO a total 8 columns)
column 1 is the combination of 3 columns. I concatenated 3 columns and add the new line character after each column Chr (13).
VO query works very well as a toad. the columnn displays each column value concatenated after a newline character, but the same query does not work in the ADF.
The column that is the concatenation of the 3 columns and should display with the new line character does not display the new line character its just concatenation of the 3 values and display on the page.
Wat could be the solution for this in the ADF?
Thank you.Column does not have the property to escape. It is part of the output text.
Something like
Arun-
-
How to remove a character from new line in a column
Hi all...
I have a column in a table in which some data contains a newline character to their last.
I need to remove the line break characters.
for example... are data
"abcd
'
(Notice the end of the quote)... I need to get data under... "abcd".
PLSS help me...
Thanks in advance...Hello:
select replace(column_name,CHR(13),'') from table_name;If it does not work, try Chr (10) instead of Chr (13).
Saad,
-
delete the last character of line break
How can I remove the newline character from the end of a string? (Note: there are several line break characters in the string). Thank you!This may or may not work, but it is worth it.
If (right (Votrechaine, 1) is 10)
Votrechaine = left (Votrechaine, 1, len (yourstring)-1); -
Connect to a device using TELNET
Hi all
I'm again using LabVIEW afairly... I have only the subset of basic skills so far. So I would respectfully when you reply to a catchall as possible please. In fact, a sample project with a lot of explanation would be absolutely fantastic.
Essentially, I have a Kollmorgan AKD motor controller device (more precisely the model AKD - 00306-x) which controls a servo controller. It uses the TELNET Protocol, among other things, to communicate with him. So far, I was able to use the TELNET of MS and Kollmorgans workbench service to communicate with the device with great success. Although the workshop of Kollmorgan is a good program, I am looking for more precise control.
Here's the question:
What is the best method of sending the commands mulitple like that of the TELNET Protocol (to where I can enter a command, have the Kollmorgan run, enter another command, run,... multiple iterations this... with out disconnecting)? In other words, I want to be able to enter a few commands, one at a time, and the Kollmorgan executes each command after each time that the key has been affected (with them having to restart the application... because of the disconnection). So far, I've implemented a while loop (without success) and one for the loops (with no success).
With the involvement of a loop, I can send a command and carry out very well... the connection becomes just disturbed/disconnected. My working model of the program, out of the loop is attached. You will find that it does what an execution (using the "run once"). If you use the button "Continuous run", the buffer is literally invaded (which probably you know).
Thanks in advance.
You have 2 problems:
- Do not connect a value to the N of a loop terminal for and auto-index at the same time. One or the other. In your case, you're automatic indexing. Remove the 9 constant.
- Your strings are not correct. If you want to enter special characters such as newline and carriage returns, your string must be in '-' display mode. Otherwise get them interpreted exactly as you enter them. You send your channel, then the character "-" and the character "n". This is not the same thing as the newline character. Right-click on the string element, and then select this mode on the shortcut menu. You will see there are two characters "\" before the "n" and the characters 'r '. Change all the double-backslashes to those unique.
-
RN104 - problem of "Delete inactive volumes to use the disc." #27199519
I have what seems to be similar to many other questions.
I have a RN104 with two 2 TB drives using X-RAID RAID 1 (mirror). I also activated the encryption. A couple of days, we had a power outage and the ReadyNAS close.
I plugged the USB with the encryption key and he started upward but am now getting the error "delete inactive volumes to use the disk. Drive #1,2 '. And we can access is no longer the actions that have been setup on the NAS.
All the suggestions/help? We are out of the period of our support.
Just to close the loop and maybe help someone else who is having a problem, here is what he has done for me.
I end up paying for support, however ultimately my problem was that when I copied/pasted the encryption key from our secure and saved on the USB password manager, the key had a newline character hidden line the end of it (an artifact of the copy/paste from the password manager) which was originally not to be able to decrypt the volume. I had to use a hex editor to view and delete the character that is hidden at the end of the key, then my volume was fine. So, if you have the above error AND you use an encrypted volume AND you have copied/pasted your encryption key from another source to a USB key, check the key for you ensure that no character hidden inside.
I had a problem of tracking where we couldn't access or connect to one of the actions. Support has fixed this issue for me, the samba configuration file was empty, for some reason, support it repaired and we are back in business.
-
Titles or subtitles of the file name?
Is it possible to automatically generate the titles or subtitles of the file name? I have a video made up of several small files and you need to insert their names under the name of a chapter, or at least as a subtitle. FCPX only supports to support the generation of TC.
The short answer (obtuse) is not. Not in FCPX alone.
I seriously doubt you will be interested in this procedure, but someone might be.
You need movement (this is the only expense here), TextWrangler and a droplet of Automator (see below).
First, gather all your files of clips in a folder.
Drop the file on the files in the folder (the automator app/drop) that will create a text file with the names of all files in the folder. When you are prompted to save the file, you can name it and save it wherever you want.
Gout Gets the names of files from the Finder, and they are complete paths, such as:
/ Users/fx/Desktop/txtLicenses/Aardvark Cafe readme.txt
[You can download a copy of the 'Files in the folder' drop HERE ]
Open a window in TextWrangler, and then drag the text file to a blank page (very cool - TextWrangler automatically opens the file with drag and drop.) [TextWrangler is FREE of Barebones.com (http://www.barebones.com/products/textwrangler/) software, everyone should have a copy! The most recent version is 5.0.2 in date 25/12/2015]
Type the command + F to open the Find/Replace dialog box. Make sure that Grep is checked.
To find them, use this regex:
.*\/(.+)\.. +
[translated: find everything up to and including the last ' / ' character, can find everything up to the last period and save it as a game (the parenthesis) and then find everything at the end of the line]
As an alternative, use:
\1\n
[Translated: prints the substring and adds a newline character - it will be double space lines of text]
In the drop-down menu with the label of 'g', save... (model - something like Remove Path and FileType) so you can find it again easily.
The text from the above example will become:
Aardvark Cafe readme
[and will follow an empty line]
[I recommend you do all your spelling at this point.] Make sure that all text is as you want it to appear in FCPX. Repair later gets a bit dicey. and generally it is a good idea to start over if you need to make changes to the text file.]
Save the file with another file in TXT format.
On the move:
Create a project generator. It can be almost any length, so accept the default value of 10 seconds. You will be stretching out in FCPX in any case.
Add: Generators > text > file
[You can use the Inspector to Format to choose the font, size, etc. and the inspector looks for color and 3D options].
In the Inspector of the generator, find the section, load your text file
Set the speed to Custom
Reset the Custom speed setting
Publish the speed of Custom setting slider
Save in FCPX (and create a category called subtitles)
When you save the generator in FCPX, the file being used is hard-copied in the media for access folder. You cannot publish the setting browse generator, so all files subtitles prepared in this way are projects of "One Shot". You can throw away them once your project is completed because their utility essentially died with the FCPX project.
In FCPX, apply the generator to the plot and develop it to adapt to the length.
Keyframe of the lines of text to match the timing of your video. This is where double spacing will be useful because it is a real pain in simple lines of keyframe and you will need a bit of space for a step-by-step. You can, of course, import the audio portion of your story in motion, create a project for quite a long time for the entire length and key image subtitles in movement. You can export as, eventually, the subtitle project as ProRes (if you do not use 4444, then you can apply the Composite blend mode add to the layer that you use in FCPX as the background should be black.)
If all of your clips are the same length of time, then using the subtitle generator is a snap. Set a keyframe at 0 for the appearance of the first line and in the end, the last line should appear, simply drag the speed until the last line shows control (should be at or close to 100%). The generator systematically displays a single line both throughout the progression of his 'read'
I found that the faster is to import the audio in motion and create a Motion project, the length of the audio used for subtitles + a little extra at the end. Listen to the audio, and for each line that you display, add a keyframe... little whatever it is. When there is a keyframe for each line, listen again and adjust keyframe values to display the line. This will leave you with linear transitions from one image to another key (and overlapping in some cases, or the appearance of lines before image real key because of "Rounding errors") - is NOT a problem! Just select 1 keyframe, type command + A to select all the keyframes, and then right-click on a keyframe and select constant on the menu drop down. This will create a step-by-step through each value and you give the * discreet * timing you have need for the text to appear at the right time. Remove the audio track and save the project as a generator of FCPX... it is faster and easier to export a track video overlay.
You need movement 5.1.x or better (there are serious problems with 5.0 versions and file generator.)
I know it doesn't look like it, but this method of captioning is much easier than ANY other software of captioning I've tried in the past... NO timecode or the special formatting is required... other recommended spacing to double.
HTH
-
Communication series with visa, need help
IM G-codes(which is a string in this case) sending to my Board of Directors, Im using the structure of the event choose sent a code that, when sending as string constants program runs without problems, but when Im getting the format string to string program dosnt sent the code in this case, but its present when events change (so in other cases it works too previous)
problem can be seen in the performance of climax too
I will ask once again: do you need to send a character of endpoint with your order?
Your 4 character button events 'home' have all orders ending in the line. Other events are not. My guess is that the unit does not recoginize newline character he received a valid full command until he got the line.
PS: Those who touch terminals that belong in their boxes of the discipline concerned.
-
LV lose bytes (once?) in the process of loop
Hey dear community NOR!
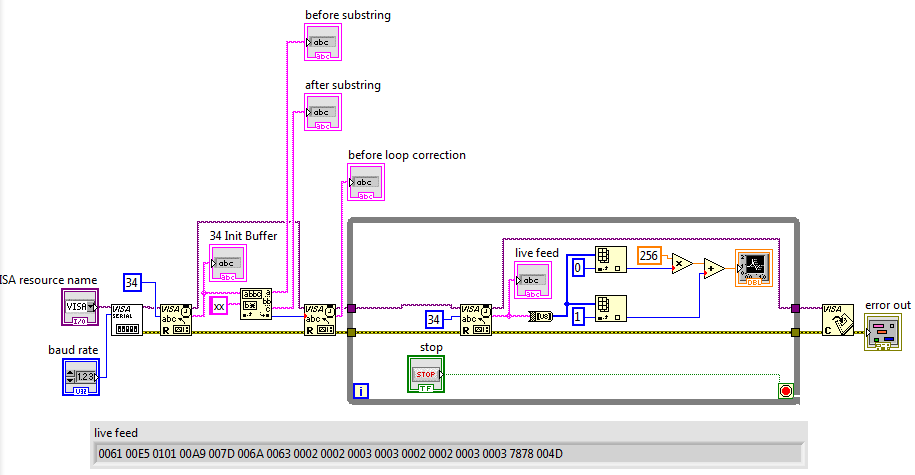
I lose bytes... and I guess, I do it during the first loop of my program.
The .vi is attached below. Here is a screenshot of the block diagram and the 'live feed' monitor the missing bytes (after explanation):
Here's how the program works:
My Arduino Mega2560 sends the data of 16 pins + chain marker 'xx' in a continuous cycle. Now, I want to follow those pins.
1-34 (= 16pins * 2 [bytes] + 2 ['xx']) bytes are read and checked for the sequence "xx".
2. the index of the first character after "xx" determines how much more bytes are to be read before our loop begins. (The purpose behind this is to have the 34-byte-strings during each loop begins with 32 followed data bytes the bytes of the 'xx' marker.)
3. the loop takes 34 bytes and evaluates the first two bytes for the value of the first pin.
The 'before the correction of the loop' shows that the used string ends with 'xx' just before the beginning of the loop. Measure the loop bytes with 'live feed' displays however data, where 'xx' is not in the end, makes the assessment of my impossible. (Note: 'xx' in hexadecimal display '7878', then the string of bytes in the above image is disabled by a single byte.) Also, note that once the program is started, the false '7878' position remains the same, as if the byte loses occurce once.
Any ideas?
Kind regards
Froebel, Friedrich G.
PS: The Arduino Mega2560 is running at 38400 baud. Higher values are not accepted. Do you know why or how I could solve this problem?
Friedrich,
The default value for VISA configure Serial Port is to terminate readings with a stop = 0a = newline character. Any time a 0a occurs in all of your data, the reading will be terminated without expectation of 34 characters. Solution: wire a False entrance to stop character constant allow the upper part of Setup.
Or you can change the stop character to be your character of marker (such as discussed in your other thread).
Lynn
-
Some parts of the chain has lost communication with the Arduino.
Everything by contacting arduino, the chain that I receive from the arduino is buffered, but it is not completely read by LabVIEW
and change the data to trace some information is lost. Someone knows how to fix this?
Information may be useful:
Arduino mega
Baud rate: 19200
Delay in the Arduino loop: 10 ms
The string is composed of 3 integers values concatenated like this:
gh123ab123cd123ef
I m attaching the Vi.
Thx a lot!
Paulo
Is your waiting time in fact 0 milliseconds? It is not very long wait for a message to come.
Each message ends with a line as a termination character newline character? You have the default stop character. If Yes, then you're better to read a large number of bytes and let the end of termination character read, rather than using "bytes to the Port. So now that you read, not all bytes have arrived yet, then you're bytes to the port will be less that you really want and you'll have the wind reading an incomplete message.
-
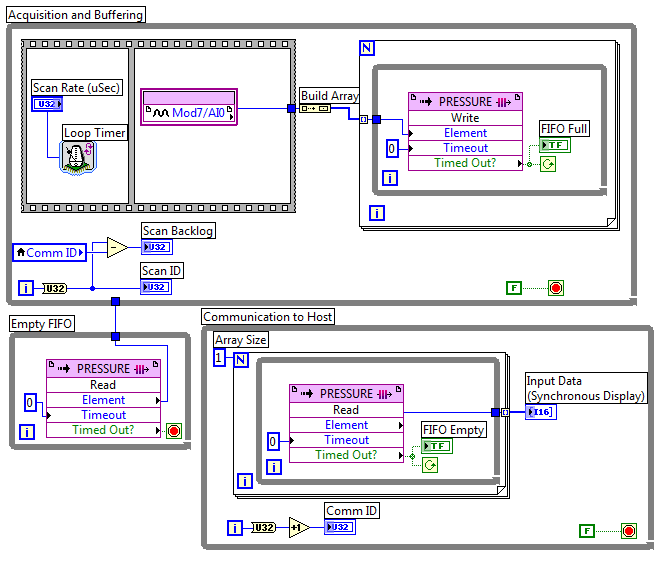
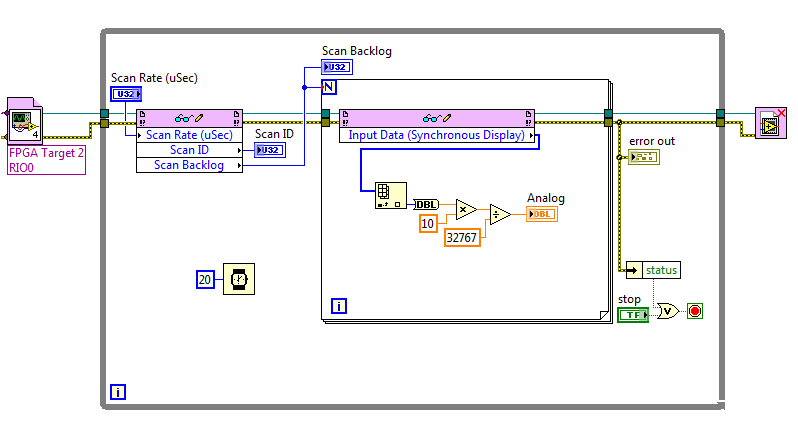
FPGA FIFO real-time error-61206
I used this white paper as a base for my code. My FPGA look like:
And my time real-time (RT):
I am using a cRIO-9022 and now just trying to get the foundations buried for my project. The problem is that the side FPGA works well but environmental RT takes maybe 2 or 3 seconds and close with this error:
Code:-61206
Source: Read/write in FIFO_pressure_RT.vi control
I have not dealt with the FIFOs in LabView before I have no idea what is the cause. Any ideas?
Thank you
Logan
What version of LabVIEW are you using? In LabVIEW 2011, if orders or the lights on the front of the FPGA had a jump of line or transport back in the label, the question would be filling in the read/write control node, but you would see this error. It seems that Input Data (synchronous display) probably has a newline character that could cause this. That the problem has been solved in LabVIEW 2011 SP1, but what happens if you remove the line break and recompile the FPGA VI?
Maybe you are looking for
-
Still can not update to iOS10 and get annoyed.
Thus, it was like what, 4 days since iOS10 came out and for four whole days now apparently my iPhone software is up-to-date with 9.3.5. I'm really tired of it now, I'd love to update but are not own a computer and I'm not going to sit for another 90
-
HP COLOR LASER JET CM1312 MFP: Print cartridge problems
I loaded two cartridges with success, but with the third (CB541A - Cyan) I get the 'delete the shipping in the Cyan cartridge latch '. It IS deleted. I put the old cartridge and no problems, I tried again with the new and the same message appears. I
-
Elevation of privileges UCS CLI CSCuz91263
I am able to Cisco bug reports and don't know how to interpret section "concerned admits communicated." The bug listed in the title has 2.2 (1A) A and 2.2 (6th) A listed under the above section. I am not clear as to whether this means that these rele
-
Hello I have HP ENVY Sleekbook 6-1080exand I just install win 7 64 bitand when I install driver amd it did not recognize the card or the card intelso pleas help me with this
-
Why my photoshop and lightroom updates to 2015?
My lightroom and photoshop does not update to 2015.How to correct this?