In oracle's regular expression to match what is in parentheses
I want a regular expression that matches anything in brackets.
for ex: if I run REGEXP_SUBSTR ("select * from emp where empno in (22,1,444,6) order by sal', regular_expression");
Then, the function should return 22,1,444,6 as a substring.
So, what can come instead of 'regular_expression '.
You can get this in a substr... Try the below... Substr is more effective than regexp. So if you can get the result using substr easily using substr... Otherwise, you can go with regexp
SELECT SUBSTR (val1, INSTR (val1, '(()) + 1, INSTR(val1,')') - INSTR (val1,'(()) - 1) new_val)
FROM (SELECT ' select * from emp where empno in (22,1,444,6) order by sal' val1 FROM DUAL ");
OUTPUT:-
-------
NEW_VAL
----------
22,1,444,6
Tags: Database
Similar Questions
-
Search for a string using "Game Plan" or "Regular Expression to Match."
Hello
I would use the 'game plan' or the vi "Expression regular game" simply because the products that provide these vi. The result that interests me is the substring 'after '. I want to be able to specify a "substring" and get everything after the substring of the input string. However, I'm getting all confused and/or watered upward when it comes to "regular expressions". Is there a way to create a "regular expression" which acts as a 'substring' to find within the input string?
The substring is a path of partial directory that contains a colon, backslashes, etc. which are part of a directory path. If some how the "regular expression" entry must ingnore all special characters and simply to understand if the substring in the string entry and give me 'all things' after the substring in the output of 'after the string.
Use Regular Expression Match instead of match pattern; It's better.
-
Matches regular expression in the collection
Hello
I need to do the following:
I have a long string with repeated similar data. I would like, by using a regular expression, to excerpts from all matches in a collection. Is there a way to perform this task?
I look through the owa_pattern package, but as far as I saw, I can extract only a single match. Here's an exact quote:
"" If the regular expression can match several strings that overlap, this function is the longest game."- http://download.oracle.com/docs/cd/B28359_01/appdev.111/b28419/w_patt.htm
So what can I do if I want to get all the games?
Thank you in advance. Any help would be appreciated.
Best regards
beroetzMaybe this will help:
SELECT REGEXP_SUBSTR ('{A1:5} {BB:10}
{CC:5}', ' (<.*?>) |) () {. *?})', 1, LEVEL) token
OF THE DOUBLE
CONNECT REGEXP_INSTR ('{A1:5} {BB:10}{CC:5}', ' (<.*?>) |) () {. *?})', 1, LEVEL) > 0
ORDER BY CSA LEVEL;If you want to eliminate the unwanted characters <> {} then use REGEXP_REPLACE in addition:
SELECT REGEXP_REPLACE (REGEXP_SUBSTR ('{A1:5} {BB:10}
{CC:5}', ' (<.*?>) |)) () {. *?})', 1, LEVEL), "[<>{}]') token.
OF THE DOUBLE
CONNECT REGEXP_INSTR ('{A1:5} {BB:10}{CC:5}', ' (<.*?>) |) () {. *?})', 1, LEVEL) > 0
ORDER BY CSA LEVEL;See you soon
Edited by: Nuerni the 17.10.2008 at 11:02
-
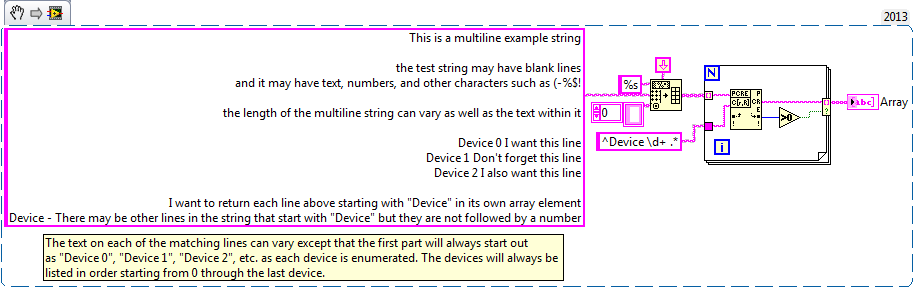
Multiline - Regular Expression Match string
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
aaronb wrote:
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
Corresponding regular expression works well for this.
Ben64
-
Looking for the character "$" in a regular expression
I try to use the vi "Regular Expression to Match", but what I'm trying to find is a dollar sign followed by a space.
Using the slash codes allows me to specify a whitespace character (\s) but I can't find how to specify the $.
I tried \x24 and \36 try hex and decimal ASCII representations, but no luck, I tried to put the $ hooks - but which doesn't work either.
Everything I try, the $ is interpreted as a command rather than the search term.
I used to use model game (legacy code) and the search term "$\s*$ ' worked - now need to use regex that I need to feed in some other matches this regex only can do - except for the dollar (if only I worked in the good old UK £!)
Any ideas out there?
Thank you
I think that we must work...
\\$\s[\n\r]
seems to do the trick
-
Hello all, I need to learn the normal Oracle database expression. Peut
anyones tell me where to find information - good sites that give the secrets ;)
I already look but like some tips. LydieJames wrote:
Hello all, I need to learn the normal Oracle database expression. Peut
anyones tell me where to find information - good sites that give the secrets ;)
I already look but like some tips. LydieHey James,.
I've been watching this recently myself and I have a little
my favorite sites. Appreciate the subtleties of the Regex - with any
luck, you won't even have to learn any PL/SQL ;)Good introdution http://www.zytrax.com/tech/web/regex.htm Simple summary of Oracle's regular expressions http://www.regular-expressions.info/oracle.html Not forgetting the Wiki (contains table with vi equivalents - for those of us who use a real editor ;) http://en.wikipedia.org/wiki/Regular_expression This site should be one of your main ports of call for any Oracle issues. Good forums also - better software than Oracle themselves. http://www.orafaq.com/node/2404 Morgan's Library - used to be psoug.org - don't know what happened - anyone? Daniel posts here from time to time http://www.morganslibrary.org/reference/regexp.html And,not forgetting the Oracle docco. http://docs.oracle.com/cd/B19306_01/appdev.102/b14251/adfns_regexp.htm http://docs.oracle.com/cd/B12037_01/appdev.101/b10795/adfns_re.htm Also look on OTN for a .pdf for introduction.HTH,
Paul...
-
Find the words (wild cards) using regular expressions
I'm testing to see if the words are present for revision 1 of a drawing of the cartridge.
The script search the digit 1 followed by a date, a title, and 4 sets of initials.
The number 1 is static, (date, title and original are the cards that they are different for each design).
I use regular expressions to match the words.
The regular expression highlighted in blue is the number 1 and the date.
Him remains highlighted in orange does not match the title and initials.
If anyone can help with the regular expression that is most appreciated.
Once I got that work will add the form fields for the initials, noting only the console at this point for the tests.
numWords = this.getPageNumWords (0);
number of words on the page
loop through the words on the page
for (var j = 0; j < numWords-1; j ++)
{/ / get the pair of words to test}
ckWords = this.getPageNthWord (0, j) + ' ' + this.getPageNthWord (0, j + 1); test words
Check if 1 26.05.16 THE STRENGTHENING REVISED MM SB AE GM word string is present
If (ckWords.match(/ ^ 1\s [0-9] {1,2}.)) [0-9] {1,2}. [0-9] {2} \s\w+(\s+\w+){1,7}/))
{
Console.println (ckWords);
}
}
You can use something like this:
ckWords = this.getPageNthWord (0, j) + ' ' + this.getPageNthWord (j, 0, + 1) + ' ' + this.getPageNthWord (0, + 2 j) + ' ' + this.getPageNthWord (0, j + 3) + ' ' + this.getPageNthWord (0, j + 4) + ' ' + this.getPageNthWord (0, j + 5) + ' ' + this.getPageNthWord (0, j + 6);
If (! ckWords.match (/ ^ 1\s\d {1,2} \.\d {1,2} \.\d {2} \s\w+ (?:-s + \w +) {1.8} \s([A-Z]{2})\s([A-Z]{2})-s ([A - Z] {2}) \s([A-Z]{2})$ /)) ckWords + ckWords + "" + this.getPageNthWord (0, j + 7);
If (! ckWords.match (/ ^ 1\s\d {1,2} \.\d {1,2} \.\d {2} \s\w+ (?:-s + \w +) {1.8} \s([A-Z]{2})\s([A-Z]{2})-s ([A - Z] {2}) \s([A-Z]{2})$ /)) ckWords + ckWords + "" + this.getPageNthWord (0, j + 8);
If (ckWords.match (/ ^ 1\s\d {1,2} \.\d {1,2} {2} \s\w+ \.\d (?:-s + \w +) 1.8 ([A - Z] {2}) \s([A-Z]{2})\s([A-Z]{2})\s {} \s([A-Z]{2})$ /))
{
...
-
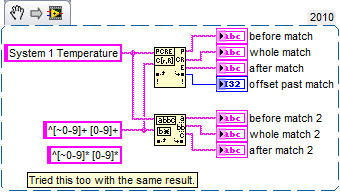
Regular expression matching is not what matches Pattern
I read a lot of posts on how match model does not match what match regular expressions will be due some characters does not.
However, I found a problem with the other way. A simple Reg - Ex who works in the match pattern but not regular Expression match.
What I have here is just an example. I want to use regular Expression Match then I can specify some matches under.
The reg - ex's: one or more non-numeric characters, a space, one or more numeric characters. At the beginning of the string.
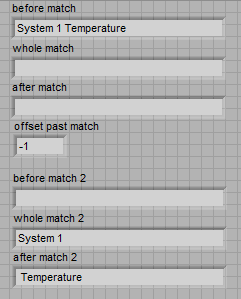
How can I get this to work in regular expression matching? I work in LabVIEW 2010f2 32 bit. Here is the code snippet and the results:
Rob
One of the subtle differences is the operator of negation for the character classes. In match pattern is ~, but for the Match RegEx is ^.
-
"Matches regular Expression" and "Model match" vi behaves differently
Hello
I need a simple matching chain and experimenting that found the "Regular Expression Match' and 'Correspondence model' vi behave a little differently. I guess that the entries of the regular expression on the two the same behavior. It's a difference that I discovered that the "|" character ("vertical" character, commonly used as an operator 'or') is recognized as such in the regex to Match vi, but not in the match vi model (where it is taken to the letter). Furthermore, I can't find any document using (online or in LabVIEW) on the ' | ' usage in regular expressions of character. Is - this documented anywhere?
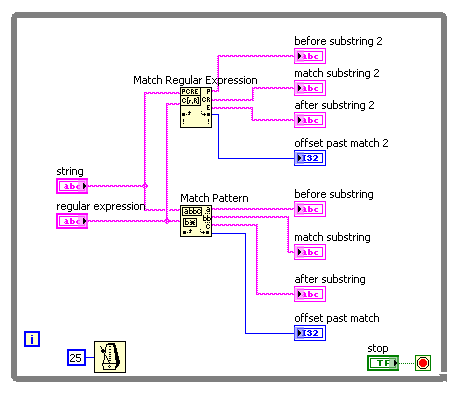
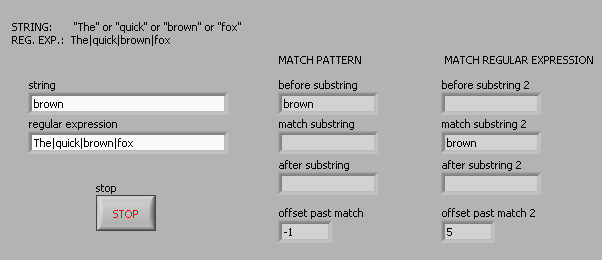
For example, suppose I want corresponding to one of the following 4 words: 'The' or 'fast' or 'brown' or 'fox '. The regular expression ' the | fast | Brown | Fox' (without the quotes) works for the vi Regular Expression Match but not the match pattern vi. Here is a photo of the block diagram and the results of the façade:
The Help explains that the vi Regular Expression Match performs a little more slowly the match vi pattern, so I started with the latter. But since he does not work for me, I'll use the old. But does anyone have an idea of the speed difference? I guess that's negligible in a simple example.
Thank you!

Thank you, Jeff. That's what I was looking for. BUT my version of LabVIEW 8.5, does NOT say "functionfor example, the Match model does not support the parenthesis or vertical bars (|) characters.«» !
See: http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_pattern/
and http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_regular_expression/
It is not mentioned in the help of special characters used for the match pattern : http://zone.ni.com/reference/en-XX/help/371361D-01/lvhowto/specialcharformatchpatt/
The only place | has 'talked', it is in the sentence: "some regular expressions that use alternating (such as (. |))". \s)*) require significant resources to deal with when it is applied to the large input strings. "But I'm not processing a large chain.
It seems that NEITHER fixed this omission. What version is your help?
Ed
-
Validation using regular expressions or oracle fn
Hello
I want to apply validation to a column. I'm trying to see if I can use the regexp_replace function to find a boss and see if I can replace it to a better format. Can someone help me with these rules?
1. only the characters a - z, A - Z, 0-9, ', - is allowed. If there are no other characters, then these characters must be removed.
2. name should not begin with a symbol.
3. If there is any symbol permitted in the name, (for example the hyphen) then the hyphen should be preceded and followed by a space.
I would like to know if the above can be obtained by regular expressions or any other function will be useful to achieve the same.
Thank you very muchCherkaoui
HI, Charan,
Whenever you have a problem, please post a small example data (CREATE TABLE and only relevant columns, INSERT statements) of all the tables involved, so that people who want to help you can recreate the problem and test their ideas.
Also post the exact results you want from this data, as well as an explanation of how you get these results from these data, with specific examples. Post in this case, maybe 5 or 10 strings, and what you would like to see (a string corrected, or a 'yes' / 'No' flag saying if this string follows rules.)
Always say what version of Oracle you are using (for example, 11.2.0.2.0).
See the FAQ forum: Re: 2. How can I ask a question on the forums?
2784427 wrote:
Hello
I want to apply validation to a column. I'm trying to see if I can use the regexp_replace function to find a boss and see if I can replace it to a better format. Can someone help me with these rules?
1. only the characters a - z, A - Z, 0-9, ', - is allowed. If there are no other characters, then these characters must be removed.
2. name should not begin with a symbol.
3. If there is any symbol permitted in the name, (for example the hyphen) then the hyphen should be preceded and followed by a space.
I would like to know if the above can be obtained by regular expressions or any other function will be useful to achieve the same.
Thank you very much
Cherkaoui
Sorry, we don't know what you want to do.
1 seems to mean you want to change the given string so that it follows the rules. (What exactly are special characters? Are there only 2 special characters: single quotation mark and hyphen?)
2 seems to tell us that you want to check if it meets the rules
3. can be a
I'll assume that you want to modify the string so that the returned value corresponds to rules. This means that if the given string violates, 2 symbols will be removed from the beginning of the string, and if it violates 3, then spaces will be added.
I don't think that there is a way to do this with a regular expression.
You can make each with a separate REGEXP_REPLACE corrections, and make all in the same query by one nesting inside each other, like this:
SELECT REGEXP_REPLACE (REGEXP_REPLACE (REGEXP_REPLACE (: str)))
, "[^ a-zA-Z0-9 cm-]"
)
, '^[''-]+'
)
, ' *([''-]) *'
, ' \1 '
) AS new_str
OF the double
;
of course, I can't test it, until post you some sample data and the exact results you want from these data.
Here, the inner REGEXP_REPLACE rule 1 applies. It deletes all characters except a to z small letters, capital letters A to Z, numbers, spaces, single quotes and hyphens.
Rule 2 applies the REGEXP_REPLACE middle. It removes the single quotes and hyphens that appear at the beginning of the string.
The external REGEXP_REPLACE rule 3. It guarantees that each single quotation mark or a hyphen is preceded and followed by a space. If there is already a space (or several spaces) before and/or after the special symbol, they are replaced by a single space. If this isn't what you want, it can be fixed, but it will make the expression even messier.
You might consider to write a user-defined function to normalize strings. In a function procedure, you can apply the rules one after the other. you need not nesting complicated like that. Of course, a user-defined function will be slower, but maybe it's not a problem.
Still, the above query converts the string so that the production rules.
If you just want to check whether a string conforms to the rules, you can compare the original string to the output of the above expression. If they are identical, then the string is in accordance with the rules.
-
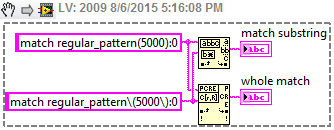
Use matching of regular expressions to search for parentheses
Hi all
I am currently looking for a particular pattern in a string, I can't display the exact string, but say its something like that. corresponds to regular_pattern (5000): 0
I'm also looking for the a different model at the same time, so I have to use the corresponding regular expression and the | function. I can't understand how to match this model because the regular expression function allows parentheses unless I put them in the legs, and that does not help me for this.
Any advice?
Thank you
Matt
Have you tried to escape the bracket?
-
Regular expression matching receives only two digit in brackets
Hello
I use the regular expression of the correspondence with the following expression. It is only able to get all the numbers that are not mere numbers. I want to retrieve all the values which lie between >< in="" the="" string="" and="" create="" an="">
Then
182 2 would be output
182
2
Any help would be appreciated. I've attached what I have so far. Right now I still have the >< and="" it="" can="" only="" grab="" numbers="" that="" are="" not="" single="">
Use (>.) [ ^(<>)]*)< *="" instead="" of="">
-
Analyze the Mac address with the regular expression matching
Hello world
I have a problem with the function of regular expression matching,
I try to analyse the response both a query arp - a 192.168.0.15 to retrieve the MAC address of the remote IP address, I used the following regular expression: ^ ([0-9a-fA-F]{2}[:-]){5}([0-9a-fA-F]{2})$
I wonder why should I do a subset of the first string to extract only the part of the MAC address. The regular Expression function is not able to recognize the regular expression directly in the middle of a string?
I only works when I extracted the subset of tring right as in the picture below.
Thanks for your replies.
Get rid of the "^" at the beginning of your regular expression. You are ordering him to find the model at the beginning of the string.
-
Oracle regular expressions - splits the string into words for
Hello
Nice day!
My requirement is to split the string into words.
So I need to identify the new line character and the semicolon (;), comma and space like terminator for string entry.
Please note that I am currently embedded blank and the comma as separator, as shown below.
Select regexp_substr('test)
TO
string in words, "([^, [: blanc:]] +) (', 1, 1) double;"How to integrate the semicolons and line break characters in regular expression Oracle?
Please notify.
Thanks and greetings
Sree
This has nothing to do with REGEXP. Is SQL * more parser does not not a semicolon at the end of the line:
SQL > select ' testto, mm\;
ERROR:
ORA-01756: city not properly finished chainSQL >
Just break the chain:
SQL > select regexp_substr ('testto, mm\;' |) '
2 string into words
3 \w+',1,level ',') of double
4. connect by level<= regexp_count('testto,mm\;'="" ||="">
5 string in words
6 ','\w+')
7.REGEXP_SUBSTR ('TESTTO, MM\;' |') STRINGIN
--------------------------------------
Testto
mm
string
in
WordsSQL >
Or modify SQL * more the character of endpoints:
SQL > set sqlterm.
SQL > select regexp_substr ('testto, mm\;)
2 string into words
3 \w+',1,level ',') of double
4. connect by level<=>
5 string in words
6 ','\w+')
7.REGEXP_SUBSTR ('TESTTO, MM\;) STRINGINTOWO
--------------------------------------
Testto
mm
string
in
WordsSQL >
SY.
-
pattern by using regular expressions match
I'm playing (and wrong) with regular expressions
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + > ') twice;
give < PSN > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.2 ') twice;
give < 231 > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.3 ') twice;
give < ABc > which confused me until I realized that < 3 25 > has not been matched, because it has a space inside
so I changed it to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ', 1.3) twice;
who gave a syntax error, so I changed it again to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ') twice;
that works, but gives < PSN > / # < 231 > # < 3 25 3 > / < ABc >
I guess because the. * corresponds to anyting that all but the last closure >
The question I have is how can I retrieve the text of mounting bracket included (even if it has multiple spaces)?
Hello
9c5dfde3-EAAE-45A7-80a1-bba8a71c826c wrote:
Thanks for that - is there a way to return all 4 surrounded by extracts of <> without resorting to PL/SQL?
Of course;
REGEXP_REPLACE (str
, '(^|>)[^<>
, '\1'
)
Returns a copy of str with all outside rafters removed, for example
<231><3 25=""> . It doesn't matter how many pairs of sharp hooks - there is.

Maybe you are looking for
-
I have a VI that creates. CSV files by taking measures so that I can analyze the data in other software. I recently added a camera to my system which also creates one. AVI file I want to analyze together with the. Data in the CSV file. I would write
-
Cyber link DVD Suite is end of life. Where to get replacement software
A ran Secunia PSI and end of life software discovered Cyber link DVD Suite for HP pavilion dv6-1245dx laptop. Windows Vista 64-bit... Went to their site and there is a DVD software to purchase, but amazing is a free replacement is just as good and c
-
Photosmart HP 7510 - cannot stop the laptop to his research when it is off
I just purchased the Photosmart 7510 and am very satisfied with its performance so far, however, in these times of conscious energy, I only turn on the printer when I want to use it, but it means that my laptop constantly looking for him all 20 or so
-
Windows 8, Windows 8.1, Windows Store
It's the ultimate Catch 22. My laptop is running Windows 8. As also (maybe), he ceased to access Windows Store. There are many discussions on this subject, which none seems not to be a solution - I've tried all those that I'm not really afraid, wit