pattern by using regular expressions match
I'm playing (and wrong) with regular expressions
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + > ') twice;
give < PSN > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.2 ') twice;
give < 231 > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.3 ') twice;
give < ABc > which confused me until I realized that < 3 25 > has not been matched, because it has a space inside
so I changed it to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ', 1.3) twice;
who gave a syntax error, so I changed it again to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ') twice;
that works, but gives < PSN > / # < 231 > # < 3 25 3 > / < ABc >
I guess because the. * corresponds to anyting that all but the last closure >
The question I have is how can I retrieve the text of mounting bracket included (even if it has multiple spaces)?
Hello
9c5dfde3-EAAE-45A7-80a1-bba8a71c826c wrote:
Thanks for that - is there a way to return all 4 surrounded by extracts of <> without resorting to PL/SQL?
Of course;
REGEXP_REPLACE (str
, '(^|>)[^<>
, '\1'
)
Returns a copy of str with all outside rafters removed, for example
<231><3 25="">
. It doesn't matter how many pairs of sharp hooks - there is.
Tags: Database
Similar Questions
-
Regular expression matching is not what matches Pattern
I read a lot of posts on how match model does not match what match regular expressions will be due some characters does not.
However, I found a problem with the other way. A simple Reg - Ex who works in the match pattern but not regular Expression match.
What I have here is just an example. I want to use regular Expression Match then I can specify some matches under.
The reg - ex's: one or more non-numeric characters, a space, one or more numeric characters. At the beginning of the string.
How can I get this to work in regular expression matching? I work in LabVIEW 2010f2 32 bit. Here is the code snippet and the results:
Rob
One of the subtle differences is the operator of negation for the character classes. In match pattern is ~, but for the Match RegEx is ^.
-
Using Regular Expressions in the Code of edge
Hello.
I am quite new to the Edge Code but find it quite interesting to use.
The find/replace feature is pretty but I got a little confused on how to use regular expression matching.
I tried to clean up the coordinates of a file Adobe Edge animate full of 120.17px (heavy and less accurate)
So basically you're looking \d+\.\d+px
First of all, she says "use /re/ for regex" even though I know the Code is made for developers who * courses * know that it took me a little time to understand I should just put my regex between slashes.
/\d+\.\d+PX/
then the time comes to replace them. ALT-cmd-F and it says "replace".
Puzzled again.
Will I type my full sentence there? Maybe a «...» "written up somewhere around would avoid this question because, there, of course, a second field to come.
And there, I got stuck.
I can not find how to get the replacement of the model.
tried to \1 $1 \1/ $1 / nothing seems to work... any hint of welcome.
Franck,
You are right that it does not work. I open a topic. Here is the link if you want to follow: https://github.com/adobe/brackets/issues/1861
FYI, I know exactly how you want to replace the search results, but here are a few tips:
You must set the text that you want to retrieve by using parentheses. Thus, for example, if you want the integer part of the number of the result, then your regexp would be: / (\d+)\.\d+px/
Then you must specify the first result using $1, so (when it's fixed), you can use something like: $1px
Thank you
Randy
-
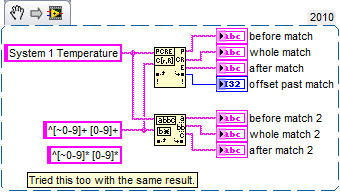
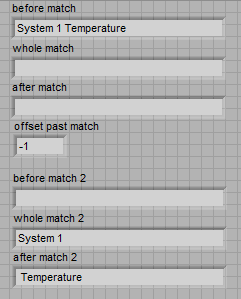
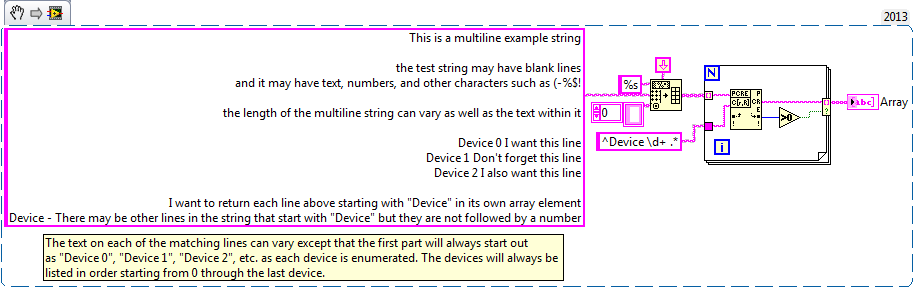
Multiline - Regular Expression Match string
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
aaronb wrote:
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
Corresponding regular expression works well for this.
Ben64
-
Analyze the Mac address with the regular expression matching
Hello world
I have a problem with the function of regular expression matching,
I try to analyse the response both a query arp - a 192.168.0.15 to retrieve the MAC address of the remote IP address, I used the following regular expression: ^ ([0-9a-fA-F]{2}[:-]){5}([0-9a-fA-F]{2})$
I wonder why should I do a subset of the first string to extract only the part of the MAC address. The regular Expression function is not able to recognize the regular expression directly in the middle of a string?
I only works when I extracted the subset of tring right as in the picture below.
Thanks for your replies.
Get rid of the "^" at the beginning of your regular expression. You are ordering him to find the model at the beginning of the string.
-
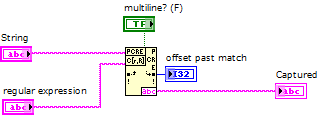
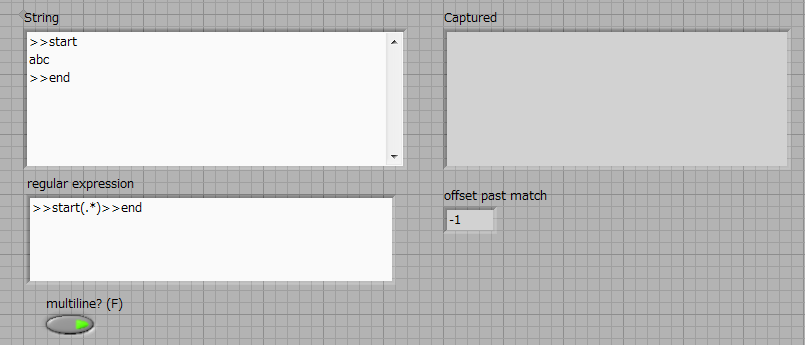
How to capture multiple line String using regular expressions?
Hello
I have a simple program like this:
What I want to accomplish is to capture everything between > start and > to end with a single regular expression matching node. It seems that the definition of multiples? true or False does not help.
I'm using LabVIEW 2012.
If it is impossible to capture using a single node, that's fine. But I want to assure you that I can make full use of this node without combining several others.
Thank you!
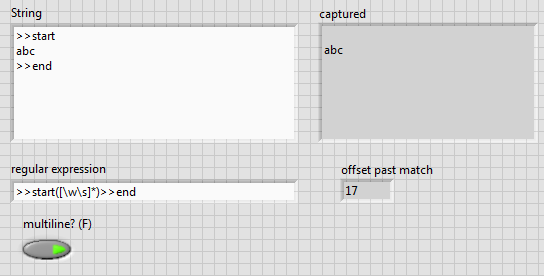
> start([\w\s]*) > end
A point matches any character except line break characters. You have two of them.
-
Find the words (wild cards) using regular expressions
I'm testing to see if the words are present for revision 1 of a drawing of the cartridge.
The script search the digit 1 followed by a date, a title, and 4 sets of initials.
The number 1 is static, (date, title and original are the cards that they are different for each design).
I use regular expressions to match the words.
The regular expression highlighted in blue is the number 1 and the date.
Him remains highlighted in orange does not match the title and initials.
If anyone can help with the regular expression that is most appreciated.
Once I got that work will add the form fields for the initials, noting only the console at this point for the tests.
numWords = this.getPageNumWords (0);
number of words on the page
loop through the words on the page
for (var j = 0; j < numWords-1; j ++)
{/ / get the pair of words to test}
ckWords = this.getPageNthWord (0, j) + ' ' + this.getPageNthWord (0, j + 1); test words
Check if 1 26.05.16 THE STRENGTHENING REVISED MM SB AE GM word string is present
If (ckWords.match(/ ^ 1\s [0-9] {1,2}.)) [0-9] {1,2}. [0-9] {2} \s\w+(\s+\w+){1,7}/))
{
Console.println (ckWords);
}
}
You can use something like this:
ckWords = this.getPageNthWord (0, j) + ' ' + this.getPageNthWord (j, 0, + 1) + ' ' + this.getPageNthWord (0, + 2 j) + ' ' + this.getPageNthWord (0, j + 3) + ' ' + this.getPageNthWord (0, j + 4) + ' ' + this.getPageNthWord (0, j + 5) + ' ' + this.getPageNthWord (0, j + 6);
If (! ckWords.match (/ ^ 1\s\d {1,2} \.\d {1,2} \.\d {2} \s\w+ (?:-s + \w +) {1.8} \s([A-Z]{2})\s([A-Z]{2})-s ([A - Z] {2}) \s([A-Z]{2})$ /)) ckWords + ckWords + "" + this.getPageNthWord (0, j + 7);
If (! ckWords.match (/ ^ 1\s\d {1,2} \.\d {1,2} \.\d {2} \s\w+ (?:-s + \w +) {1.8} \s([A-Z]{2})\s([A-Z]{2})-s ([A - Z] {2}) \s([A-Z]{2})$ /)) ckWords + ckWords + "" + this.getPageNthWord (0, j + 8);
If (ckWords.match (/ ^ 1\s\d {1,2} \.\d {1,2} {2} \s\w+ \.\d (?:-s + \w +) 1.8 ([A - Z] {2}) \s([A-Z]{2})\s([A-Z]{2})\s {} \s([A-Z]{2})$ /))
{
...
-
ADF Email of Validation using regular expressions
Hello
Wanted to add search Email Validation VO.
It works if I put
However, this requires identification of email to be entered in capital letters.<af:validateRegExp pattern="[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}" messageDetailNoMatch="The value {1} is not a valid email address:"/>
I tried with below the option does not work.
I got over information of<af:inputText value="#{bindings.xxEmail.inputValue}" label="Email" required="#{bindings.xxEmail.hints.mandatory}" columns="#{bindings.xxEmail.hints.displayWidth}" maximumLength="#{bindings.xxEmail.hints.precision}" shortDesc="#{bindings.xxEmail.hints.tooltip}" id="it5"> <f:validator binding="#{bindings.xxEmail.validator}"/> <f:validateLength minimum="6"/> <af:validateRegExp pattern="[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}" messageDetailNoMatch="The value {1} is not a valid email address:"/> </af:inputText>
ADF Email of Validation using regular expressions
The user enter email id without @.
Please suggest this model to reach.
Thank you
JIT
Published by: appsjit on January 25, 2013 19:08Hello.
My English is not very good.I use below format and it works
"^ [_A-Za-z0 - 9-] + (\.). [_A-Za-z0-9-]+)*@[A-Za-z0-9][A-Za-z0-9-]+ (-.)] ([A Za-z0-9] +) * (-.) [A-Za - z] {2,}) $»
messageDetailNoMatch = "the value {1} is not a valid email address" / >Habib
Published by: Habib Eslami on January 26, 2013 01:22
-
validate cfinput using regular expressions
Hello
can someone help me valditing a field of cfinput using regular expressions?
First digit must be a number or a 'R '.
Figure 2-15 can be anything without special characters. Figure 2-15 can also be empty.
I try this, but it does not work (sorry I'm a beginner using regex).
< cfinput type = "text" name = "field1" required = "yes" validate = 'regular_expression' pattern = "[0 - 9Rr] [0 - 9a - zA - Z]" * "maxlength ="15">"
Thank you for advice!
Claudia
^ [0 - 9Rr]([0-9a-zA-Z]{1,14})? $
-
Chips with 3 delimiter characters using regular expressions
Hello world
I have a function that is able to mark the input in a collection string using regular expressions.
In case the input string is a character such as the comma or semicolon delimiter,
We can just get the result we want like the example below.
SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production PL/SQL Release 11.2.0.1.0 - Production CORE 11.2.0.1.0 Production TNS for 64-bit Windows: Version 11.2.0.1.0 - Production NLSRTL Version 11.2.0.1.0 - Production
SQL> with tab1 as ( 2 select 'abc,dfg,h,,1234' as col1 from dual 3 ) 4 select regexp_substr(col1, '([^,]*)(,|$)', 1, level, 'i', 1) as result 5 from tab1 6 connect by level <= regexp_count(col1, ',')+1; RESULT --------------- abc dfg h 1234
But in the case where the channel of entry has 2 types of delimiter and each delimiter consists of 3 characters as below
I wonder if it is possible to get the result as below.
The input string: 01| ^ | ABCD| ^ | 111| * | 02| ^ | efgh| ^ | 222
Separators: | * | is divided into lines, | ^ | is divided into columns
Expected result:
col1 col2 col3
Row1 - > 01 abcd 111
row2-> efgh 02 222
Simply put, take a next
The input string: 01| ^ | ABCD |^| 111 |*| 02 |^| efgh |^| 222
Separator: | * |
Result:
01. ^ | ABCD | ^ | 111
02. ^ | efgh | ^ | 222
How can I achieve this using regular expressions?
Kind regards
Euntaek
You need to know the number of the column from the outset:
with tab1 as)
Select ' 01 | ^ | ABCD | ^ | 111. * | 02. ^ | efgh | ^ | 222' as double col1
)
Select rownum,
regexp_substr (regexp_substr (col1 '(.*?) ((\|\*\|)| $) ', 1, level, null, 1),'(.*?) ((\|\^\|)| $) ', 1, 1, null, 1) col1,.
regexp_substr (regexp_substr (col1 '(.*?) ((\|\*\|)| $) ', 1, level, null, 1),'(.*?) ((\|\^\|)| $) ', 1, 2, null, 1) col2.
regexp_substr (regexp_substr (col1 '(.*?) ((\|\*\|)| $) ', 1, level, null, 1),'(.*?) ((\|\^\|)| $) ', 1, 3, null, 1) col3
of tab1
connect by level<= regexp_count(col1,'\|\*\|')="" +="">
/
ROWNUM COL1 COL2 COL3
---------- ----- ----- -----
1 01 abcd 111
2 efgh 02 222
SQL >
SY.
-
How to extract the value of a tag XML using regular Expressions
We get a response XML from a WEB SERVICE.
I convert it to VARCHAR2.
Now, I want to get the real answer that is inside the tag of the response.
I tried this:
DECLARE
V_1 VARCHAR2 (30000): = ' < soap: Body > < ns:ProcessArgusFeedsResponse xmlns:ns = "urn: PegaRULES:SOAP:ArgusToPegaFeeds:Services" > ' |
'< response > good < / answer >< / ns:ProcessArgusFeedsResponse > < / soap: Body > ';
v_response VARCHAR2 (100);
BEGIN
DBMS_OUTPUT. PUT_LINE (V_1);
v_response: = REGEXP_SUBSTR (v_1, ' / < >(.+?) < \/Response > answer /');
dbms_output.put_line (v_response);
END;
It does not work.
Any help would be greatly appreicated.
Hello
user12240205 wrote:
We get a response XML from a WEB SERVICE.
I convert it to VARCHAR2.
Why? XML has its own native ways of analysis; Why not use them?
If you use regular expressions, then REGEXP_REPLACE, as shown above, is a good option in Oracle 10, but starting in Oracle 11.1, you can use REGEXP_SUBSTR like this:
REGEXP_SUBSTR (v_1
, '
(.+?) '1
1
NULL
1
)
The 6th argument is like a backreference; "He tells REGEXP_SUBSTR did not return to the entire organization, but only the part inside the 1st left '(' et correspondant à sa droite).
The '?' to make it non-greedy is necessary only if v_1 can contain more than one response.
Now, I want to get the real answer that is inside the tag of the response.
I tried this:
DECLARE
V_1 VARCHAR2 (30000): = "
'
Good v_response VARCHAR2 (100);
BEGIN
DBMS_OUTPUT. PUT_LINE (V_1);
v_response: = REGEXP_SUBSTR (v_1, ' /
(. +?)) <\ esponse="">/'); dbms_output.put_line (v_response);
END;
It does not work.
That's because it's looking for a slash ("/") before the '
' tag and another after the ' tag.The backslash ("\") is not necessary here, but it is not nothing wrong.
-
A special character validation using regular expressions in ADF
Hi guys,.
I want to put the validation of a special as character (,.') ((en) &, -) using regular expressions.
I asked the posting as [a-zA-Z0-9'(.),--/ &] but it does not work properly.
Special characters should be like:
Comma,
Hyfan-
Dot.
Open and close braces (and).
Ampercent &
Apastrophy '
Space ""
Please help if anyone has idea.
And I also tried to put under expression as...
[a-zA-Z] + (\\s* [0-9] * [a-zA-Z] *-* & * \\(*\\) *, *'*. *) * [a-zA-Z0-9] + but we need the validation if we put special characters between the charater as "ab," chain "& (bc).
his does not work if I put a special character at the beginning and the end of the string in the ADF
Thanks Timo...
its working fine...
-
String format using regular expressions
Input string output format... SELECT q'<select ab_c "ABC", efg "EFG" from dual>' str FROM DUAL Output: STR ------------------------------------- select ab_c "ABC", efg "EFG" from dual Required output format using regular expression... STR ------------------------------------- select 'ab_c' "ABC", 'efg' "EFG" from dualRegular expressions have many limitations as tools of analysis, and you specify the rules you want. This expression puts quotation marks around a non-empty string before a quoted string:
SELECT regexp_replace(q' -
One for the era: how to get this output using REGULAR EXPRESSIONS?
How to get the bottom of output using REGULAR EXPRESSIONS?
Published by: user12240205 on June 18, 2012 03:19SQL> ed Wrote file afiedt.buf 1* CREATE TABLE cus___addresses (full_address VARCHAR2(200 BYTE)) SQL> / Table created. SQL> PROMPT Address Format is: House #/Housename, street, City, Zip Code, COUNTRY House #/Housename, street, City, Zip Code, COUNTRY SQL> INSERT INTO cus___addresses VALUES('1, 3rd street, Lansing, MI 49001, USA'); 1 row created. SQL> INSERT INTO cus___addresses VALUES('3B, fifth street, Clinton, OK 74103, USA'); 1 row created. SQL> INSERT INTO cus___addresses VALUES('Rose Villa, Stanton Grove, Murray, TN 37183, USA'); 1 row created. SQL> SELECT * FROM cus___addresses; FULL_ADDRESS ---------------------------------------------------------------------------------------------------- 1, 3rd street, Lansing, MI 49001, USA 3B, fifth street, Clinton, OK 74103, USA Rose Villa, Stanton Grove, Murray, TN 37183, USA SQL> The REG EXP query shouLd output the ZIP codes: i.e. 49001, 74103, 37183 in 3 rows./* Formatted on 2012/06/18 17:25 (Formatter Plus v4.8.8) */ SELECT REGEXP_SUBSTR ((REGEXP_SUBSTR (full_address, '[^,]+', 1, 4)), '[[:digit:]]+') RESULT FROM cus___addresses -
Changeparticular the characters of a string using regular expressions...
Hi all
I'm writing a function using the function of expression regular oracles REGEXP_REPLACE but I could not succeed until now.
My problem is as follows, I have a text in a column say "Scott Sdfdfs Sdfd" I want to replace all the s and S with X characters and make the text looks like "XdfXdf XdfdfX Xdfd".
It is possible by using regular expressions in oracle?
Can you give me some clue?
Thank youselect regexp_replace('sdfsdf Sdfdfs Sdfd', 's|S', 'X') Replaced from dual;REPLACED ------------------ XdfXdf XdfdfX Xdfd
Maybe you are looking for
-
Thus, the battery of my iPhone (5 s) worked very well so I took it to be fixed and they could not get a new battery so they gave me a new phone! (if exellent customer service I dare say...) Anyway, the new phone works ios9, which is nice, but does no
-
Windows 7 - Error Codes: 66 a & dt000 (cannot install updates)
I tried to install the latest Windows security update, and I get this error message: "WindowsUpdate_0000066A" "WindowsUpdate_dt000" I'm doing something wrong? I thought that the updates will be automatic.
-
When I turn off the computer, it goes into the installation updates. It does this every time as apparently the installation was not completed successfully. I have several other problems. Y at - it someone who can take in charge my computer and diff
-
Hi, my laptop is dell inspiron 3537. I have recently updated the wireless driver in my laptop after that I have found no station hotspot in my laptop. How can I get it again... Greetings
-
I have a lot of files with the name "EULA" in the C drive.
Original title: a lot of files in C:\? Hello. I was watching my C drive today and I noticed that a lot of files in C:\. I want to know is what can delete and it will spoil my PC? I am running a Dell Optiplex 755 with Windows 7 Professional 32 bit. He