Interpolation: Executives vs seconds
I talked to a few other Flash developers, who use a little interpolation and find that they use seconds (true) when you write tweens, where I was always told to use frames (false). I'm sure I learned that when you use seconds (true) your pre-teen has relied on the computer of users at the moment and if the computer has been "blowing" then the animation would not smooth because of the lag in time from him, and when you use frames (false) that he was on the film itself, which, at the time where you see , it has been fully charged and that you shouldn't have any problems. Here is an example of a tween using seconds installation:new Tween (instance_name, ' FLF", Back.easeInOut, instance_name._y, 800, 10, true");
I could be completely off on this, but I'm sure I learned this when I started to develop and since I usually don't use too much actionscript I just need some clarification.
Thank you!!!
You are welcome :D
Tags: Adobe Animate
Similar Questions
-
Hi all
I have two functional screw a loop a set of read and write tasks with device 1 (NI USB-6008). The second loop a set of writing with device 2 (another NI USB-6008) tasks. 2 VI has a massively slower than VI 1 time scale, which means that it must run in a separate loop. Otherwise, VI 2 was created by copying and modifying 1 VI and variable names actions with him (though not, for example, global variables). The two screws are meant to run at the same time on the same PC.
However, if VI 1 is running at the same time as VI 2, any read operations or in writing to 1 VI 1 device are executed - but the VISA read and write operations to a serial device work. When VI 2, all VI 1 functions work fine.
Although I configured channels for tasks using the GUI DAQmx, I execute tasks using reading DAQmx write commands and have correctly defined the task 'create' and 'stop the task' live out the beginning and the end of my loop, respectively.
Does anyone have suggestions for what could be the cause? My thoughts so far:
a. maybe it's some conflicts in the names of variables in memory between the two screws?
b. LabVIEW for some reason any cannot read and write two devices on two separate screws?
should c. I avoid to use DAQmx to configure these tasks (a sort of memory)?
I know I can make it work if I have all together in a single massive VI, but for my application, it is much easier and better to do them in two separate screws.
Thank you in advance for your help!
In case anyone wondered, I found the solution:
When I copied the original code for a new VI, it turns out that the structures of loop timed in the new VI had the same object name in the delivery structure of LabVIEW as timed in the original VI loop structures. This prevents effectively regardless of the VI was executed the second execution of the timed loop. (The serial number read/write suite to work because he was in a different timed loop.)
I found this error when I ran the VI in execution of highlight mode and noticed that the output of 'error' on the timed loop flashed. When I plugged it on my error stream, I found error-808, which explains the above problem.
I have it set by right-clicking on the timed loop, change to a while loop, then change to a timed loop and plug the broken wires. LabVIEW gave the new timed loop object a new name, and all was well in the universe.
-
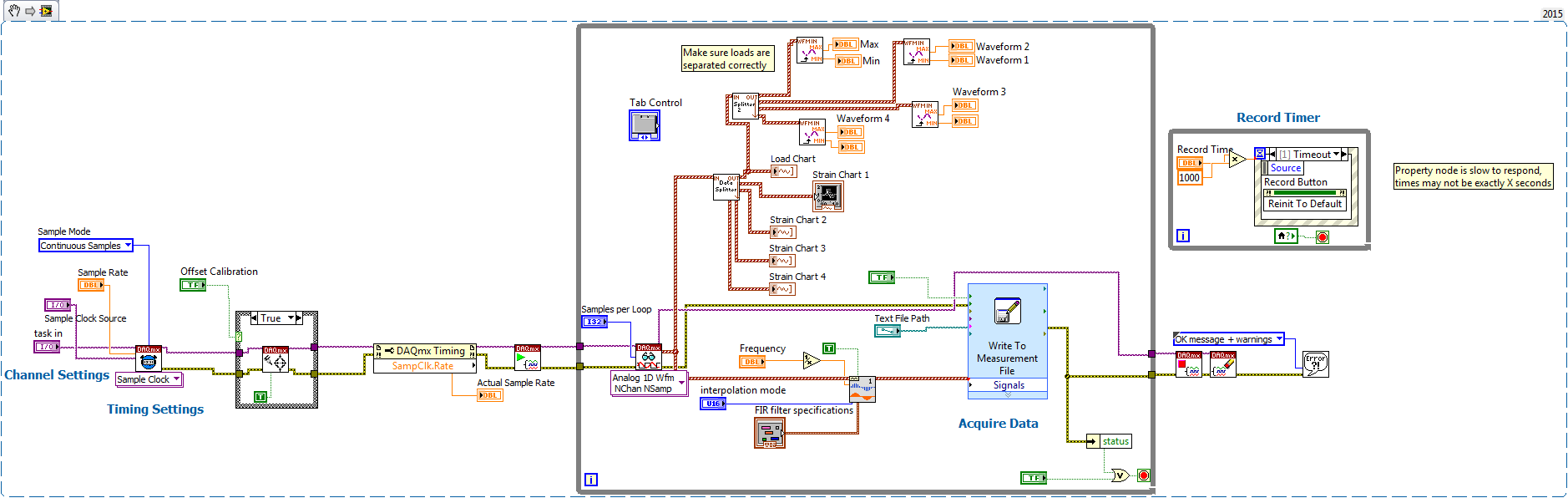
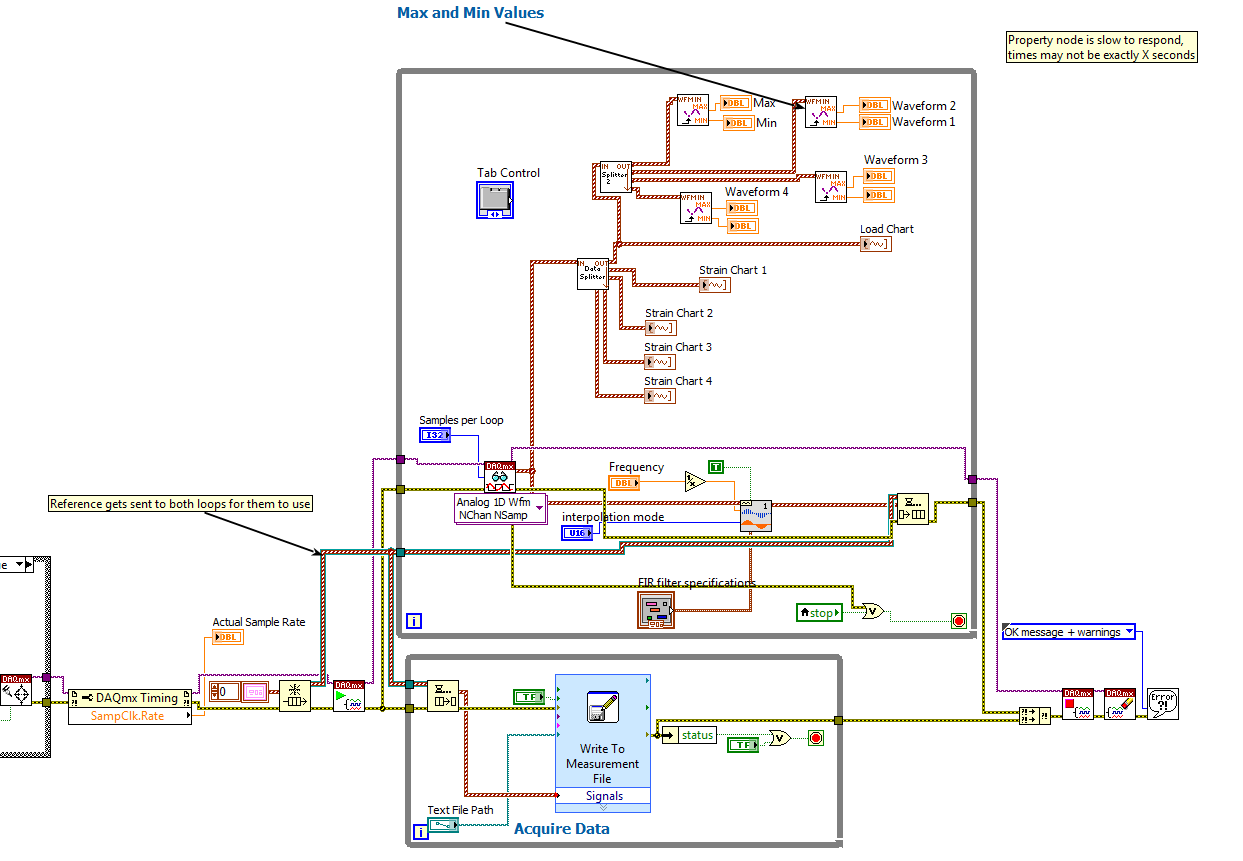
data collection ignores every 0.5 seconds
Hello
I use a NI9205 to collect four different load values outputs plus a NI9236 for several values of deformation using the attached VI. For some reason, during check-in for several more seconds, I noticed that the charges on the 9205 jump a single data point every 0.5 seconds. I have a frequency of 100 or 200 points per second recording, but the question is when I try to plot these data. The following values are moving in where gaps should be, so the end of 3 executed same second, the values of load and strain are off by 6 hundredths of a second. When I export the data to an excel file, load values cascade not upward, but variances are always a problem, because they are visible on the drawn line graphs. I know that's not a problem with data acquisition, because I ran a similar program in DasyLab who had no problem jumping of data, but it only happens with the 9205 (not the 9236), so I'm confused here.
Any help would be appreciated!
Save the sass, we're all just here to help

hhart, your loop of consumers is directly dependent on your loop producer via the reference queue and cluster of error. In other words, that they will not work in parallel, since the consumer loop will wait for the loop of producer to stop before handling the queue.
Here's how the producer/consumer with a queue should look like:
Programming LabVIEW is based entirely on the data flow and parallelism. It is incredibly powerful and has led to its success over the years (coupled with graphical programming), but is usually one of the first things the new developers stumble on. This is a simple resource to familiarize themselves with its functioning. The function to highlight execution is a great way to watch how your application uses data streams.
-
How to stop / clear current interpolation?
Hello
I have a clip that I travel with interpolations. When the user clicks on a button, it creates a new Tween and clip moves. However, I have another button that sets the position of the same clip. The problem comes when this button is clicked if interpolation is underway. Interpolation continues and my content moves out of sight. Is there a way to stop or remove interpolation when the second button is clicked?
Here's an example simplified of the relevant such as:
button1.onRelease = function(){ new Tween(movieClip, "_y", Strong.easeOut, movieClip._y, movieClip._y + 200, 1, true); } button2.onRelease = function(){ // code here to stop the above tween if it is in progress? movieClip._y = 0; }I use AS2 in CS3
Any help would be appreciated.
Assign the interpolation as a variable and use the stop() for her method...
var tw:Tween;
Button1.onRelease = function() {}
TW = new Tween (movieClip, ' FLF", Strong.easeOut, movieClip._y, movieClip._y + 200, 1, true");
}Button2.onRelease = function() {}
TW. Stop();
} -
Why the distribution is less capacity?
Seems that I am upset by this * (& ^ * #& ^ % $ box everytime I try to do something...)
I have a NAS 6 Pro that I bought with the readers of 6x1TB. I wanted to update capabilities by installing the disks 6x3TB. A technical support call suggested the best way was to do a "factory reset", of course, that's what I fact/tried to do the following:
1. from Frontview, I selected the 'Factory Default' button. When the process started, I was asked to do a few entries to configure the unit.
2 prior to entry and restart, I removed and replaced all 6 discs 1 TB with red WD 3 TB drives.
3. in Frontview, I have selected X-RAID2 with fault tolerant disk 2 and press the go button
4. the process has begun, but that I view Frontview volume settings, it seems that I have will wind upward with a fraction of the available capacity as only 927 GB on each disc is 'allocated' (see screenshot)
What happens here? Why I don't get the whole of 2 794 each allocated disk GB?
Thank you!
I executed a second 'factory reset' Frontview and the problem fixed itself. I see (almost) the entire capacity GB 2 794 in the distribution column. It of now the synchronization itself and is expected to be completed in a little more than 12 hours.
-
Well, as evidenced by my increase in the issue positions (vs answer my other posts), I get down to the wire trying to get a new operating system. I'm controlling a Hitachi L300P inverter (motor controller), via its RS485 link. I have, at the end of the computer, a usb to RS485 adapter, and the race to the L300P made by a short, twisted pair (60 feet max) runs (the controller is configured for "Half duplex, two sons"). When I send a message to the unit I get no response, the purpose, or a message ACK or NAK. I tested my port by connecting a second and "talking to myself", performed the L300P self back loop, which is to unplug the external connection and do manual things through its programming before Panel and have, while the cable was disconnected tested its continuity. This morning I intend on executing the second long twisted of the location of the computer for controllers and make one end to end test to confirm I can talk down the wires. I'm sure that my chain of command is correct, but do think the device is supposed to send an ACK or NAK if it "sees" something coming.
If there is anyone who has had experience with these discs, either through LabVIEW or not, I would be grateful hearing on their part. Also all other paths to solve this are appreciated. I'm more tired, mentally and physically, and another set of "eyes" looking at the problem will probably help.
Well, to help anyone with similar problems, I'll say what I found. As mentioned in previous posts, I had ran 150' cable out to the fine disc and connected to the other end of the cable comm existing on the disc, the near end of another adapter USB-RS485 (Easysync ES-U-3001-M). When it worked, I thought it turned out that the problem is not hardware but whatever my software (doubtful, the sent string implementation match the example in the manual) or a problem of disk configuration. While I was talking to 'Sam' to Hitachi, I found that once I sent the order message I received a returned "ACK" message. Hmmm! ?? Well, the USB adapter, I, designed to be used as RE232, 422 or 485, has a number of configuration inside bars, which allow the addition of 750 ohms pullups and pulldowns and 120 ohm termination resistors to some signals. I activated the and "Bam!" the reader begins to see and responding to my messages. Apparently, the cards have a more sensitive front end that are matched to the car, or at least (reasonable) to communicate successfully more than ~ 300 feet of twisted out of the box configuration, pair but the necessary drive configuration changes. Still have a big headache (a real one) and I now talk to other Hitachi drive, which uses Modbus rather than the simple protocol of this player.
Thanks again for the support, it can feel pretty lonely here with you people!
-
I have a hp pavillion a6314 which stops automatically - if the machine is started it works during 5 minutes to an hour then fails - when the machine has been executed the second restart will last only seconds with the error CPU fan has failed... The fan is normally quiet, but when it accelerates upward and in 30 seconds it stops the machine. The fan looks like it is free of dust/dirt and moves freely. I presume that the circuit on the motherboard detects something to trigger the stop. I have looked at the news of the event under the control panel but can't find any error that says heat caused it or another error. There are critical events in the list, but do not have any problem with the fan. So I am wary that replacing the fan would do nothing to solve the problem. What do you think?
Keith
Once the cpu stops, there is a light on the power supply dc. I guess I was looking for confirmation that it is time for a new computer... Thanks for your help.
Keith
-
Print spooler does not restart
I can't get my print spooler to restart. Sometimes I can restart my computer and it will start (there are usually several attempts), however, it did not work today and restart my computer is getting old. When I try to start from the services window, I get a 1053 error message that says: it does not. I ran all the malware scans and I'm not coming with a problem with a corrupted file. How can I solve this problem?
A "HP ProBook" is a computer. We need the brand and model of your printer. You should also tell us which version of Windows (Windows 7 Home Premium 32-bit, Windows 7 Pro 64 bit, etc.) and service pack (no, 1) is installed. If you are unsure, do a click right my computer and select properties for this information.
In general, the print spooler problems are caused by a corrupt print job or a damaged printer driver. For Windows 7, run this Microsoft Fix It routine--> http://go.microsoft.com/?linkid=9829710
If that does not solve the problem, and then run this Microsoft Fix It routine--> http://go.microsoft.com/?linkid=9829711
Note that if you execute the second difficulty, you need to restart after you run it and then reinstall all your printers. To reinstall your printer, go to the web site of the manufacturer of the printer (not the manufacturer of your computer) and download the correct driver for your system. For more help with this, please identify your printer and your version of Windows, especially if it's 32-bit or 64-bit.
-
Select for update doesn't work for me
I have a table that stores a set of numbers. These numbers, when used, should not be used again within 365 days. In addition, different process requesting a number should be split different numbers. Basically, a number must be used only once.
Here's the code I used to allocate 100 numbers. It is supposed to select a line, try to lock it using 'UPDATES'. If he is able to select, I guess that it is available and update the LASTMODTM. It's impossible to choose, this means another process has locked, and I will try the next number.
I've run 2 process running the code below together, expects that each process will get 2 unique series of numbers, but I'm left with exactly the same list of numbers for the two methods. I believe that SELECT for UPDATE is not working, that's why the two processes are able to choose the same line. Any advice for me?
DECLARE
v_nbr NUMBER_POOL. NBR % TYPE: = null;
CNT INTEGER: = 0;
v_nbrlist VARCHAR2 (32676): = ";
BEGIN
FOR x IN)
SELECT THE ROWID RID
OF NUMBER_POOL
WHERE
AND SYSDATE - LASTMODTM > 365
ORDER OF LASTMODTM, NBR
)
LOOP
BEGIN
-To lock the line so that it be referred to the other application
SELECT MAWB
IN v_nbr
OF NUMBER_POOL
WHERE ROWID = x.RID
FOR UPDATE NOWAIT.
EXCEPTION
-Impossible to line lock, this means that this number is locked by another process at the same time. Try the next nbr
WHILE OTHERS THEN
CONTINUE;
END;
UPDATE NUMBER_POOL
SET LASTMODTM = SYSTIMESTAMP
WHERE ROWID = x.RID;
CNT: = cnt + 1;
v_nbrlist: = v_nbrlist | ',' || v_nbr;
IF cnt = 100 THEN
DBMS_OUTPUT. Put_line (SUBSTR (v_nbrlist, 2));
EXIT;
END IF;
END LOOP;
END;
TKS all for your advice. I solved my problem
Sorry - but that does NOT solve your problem. It may "seem" to simple tests you run, but he does not take into account how locking and consistency reading actually works in Oracle.
It turns out that the 2 process has no conflict each othe at all, because the select sql loop took 0.2 sec, while 100 loops completed almost instantly. So the 2 process select almost at the same time, when first completed the process select, he received 100 numbers in a very short period of time, until the 2nd process is to select always. When the arrival of select 2nd process, the first process had already finished and committed the change. That is why the 2nd process does not meet lock exception.
Yes--but it's NOT the caue in the root of your problem. The problem is you are using TWO separate queries. The first request is to determine which rows to select, but it IS NOT lockingk these lines. This means that any other user can also select or even lock the rows that were selected only by the first user and the first query.
To fix this, I simply added "AND SYSDATE - LASTMODTM > 365" for numbers used will not be selected. The select for update query will be raise exception and then continue the loop to try the next number.
No - that will NOT fix the problem if you always use a separate SELECT statement for the first query.
A query, even a SELECT query, establishes sthe YVERT point-in-time for the data. This query second "select for update" is still being used by lines that were selected only, but not locked, the first query. This means that an another session/user may have selected some of these same rows in their first query, and then run the second query before and even during your attempt to execute your second query.
Tom Kyte shows, in the link I gave
In addition, there are some "read consistency problems" here.
The min (job_id) select where status = 0, which runs... It returns the number 100 (for example).
Update us this line - but have not committed yet.
Someone calls it, gets them min (job_id) select... you guessed it, 100. But they block on the update.
Now commit you and you have 100. They have now released and - well - update the SAME row...
for example: your logic does not work. You EF the same record N process sometimes.
The solution is to LOCK the lines with the first query so that no other session can perform DML on these lines. SKIP LOCKED clause in 11g is what you use.
See the example of Tom Kytes in its first reply in this thread;
https://asktom.Oracle.com/pls/asktom/f?p=100:11:0:P11_QUESTION_ID:2060739900346201280
Can you show how I can avoid using the QA and use SKIP LOCKED to elements of process simultaneously unpretentious? ...
Suppose you want to get the first line of a table that is not currently locked and corresponds to a unique key - or otherwise (single would not make sense, he would have one - and this would be trivial to determine whether it is locked or not, without the 'skip locked', you would use just nowait).
so the case of unique key is not remotely interesting, should not jump - needed ever - locked, just a nowait.
You come to question and search, for example:
OPS$ % ORA11GR2 tkyte > select empno
scott.emp 2
3 where job = 'CLERK '.
4.EMPNO
----------
7369
7876
7900
7934OPS$ % ORA11GR2 tkyte >
OPS$ % ORA11GR2 tkyte > declare
l_rec 2 scott.emp%rowtype;
slider 3 c is select * from scott.emp job where = 'CLERK' for update skip locked;
4 start
5. open c;
6 retrieve c in l_rec;
7. close c;
8 dbms_output.put_line (' I got empno = ' | l_rec.empno);
9 end;
10.
I myself empno = 7369See the 'for UPDATE SKIP LOCKED' in the definition of the cursor? Which LOCKS the lines that are needed AND causes code pass all lines which can already be locked instead of throwing an exception as NOWAIT would.
Allows you to get some lines unlocked are available that meet your query and prevents the contention with other users.
NOTE: there is only ONE query.
Summary - This is your SELECT FIRST query that does NOT lock the lines are selected. It IS THE CAUSE of your problem. Your 'two query' solution ' will NOT work. Use the solution presented by Tom.
-
Welcome and export as screen screen does not show entirely
I don't think I've seen that never happen in any of my prior Adobe apps, but when I just upgraded to Photoshop CC 2015, the Welcome screen is not fully displayed on my Macbook Pro 13 "when executing a second Cinema Display. Same thing happens when I tried in the file - export. The pop up appears incomplete, there is no way I see to move where I can view the whole component. A way to fix this? Here is a screenshot of my Macbook Pro.

OK, here's a suggestion. Organize the largest display to the right of the smaller screen and move the menu bar to the larger screen, just like mine.
Note that my laptop wallpaper is on low level of the larger screen.
Another note must close Photoshop before you connect or disconnect your monitor.
I think that your problems will go away with this arrangement.
What it does is make the large display of the main screen when connected. To get to Photoshop to use up the full display area, click the Green Resize button and it will fill the screen.
If you open the export dialog box, it should be where mine is in my example.
-
Extract the workload statistics
Is there a way to easily extract the stats of the workload of all guests, that is, in the example mail server, we would like a report on actual metrics data. We run a series of experiments and here to see how him detailed measures. I looked at the file tilescore.pl, where it actually gets the data, but runs to change it there at - it an easier way?
Moussa
Hi Moussa,.
Yes, I think that what you are looking for is in .wrf each workload (workload results file). These are the output of workload files which tilescore.pl the process to create Score_N_Tile_Test.out. You can find all the .wrf of executing files in the folder results of the race, C:\VMmark2\results\Results_
time the race finished. For example, in MailserverN.wrf, where N is the number of tile of the workload, you can see per minute on average metric for the workload of mail server. These measures are extremely specific and include the throughput and the latency of the types of operations among other things. As a measure of overall throughput, I often refer to '\\VMMARK2VCLIENTN\Exchange load motor of the generator (_total) \Tasks Completed/s", which would normally fall around a bit more than 30 tasks executed per second. You can view this file .wrf either under Perfmon a .csv.
Each .wrf file format is specific to its workload.
-
My Creative Cloud Desktop application said that apps that are not installed.
Important thing to note: I system restored yesterday, that deleted programs I had installed the day before.
After my previous discussion received no response, I looked for solutions more and found one of only two weeks now has suggested that the OOBE folder I have rename was not correct. I should go in Program Files/Common Files/Adobe and rename the OOBE folder it OOBE_old. While I'm looking for what I am on the phone with a customer service representative I annoyingly do not remember the name that is asking for the remote control of my computer, I am reluctant to give it, of course. So I tell him that I am running this solution, that he says is very well. So I run the solution, and finally, the creative cloud desktop application does not start with a blank screen! In fact, he asked my username and password! I enter and access the normal page in the list of installed applications, etc. Except, there is no trace of the apps installed on my computer, in fact, the creative Cloud Files folder is empty. They are not in my list of installed programs. Because, of course, they were removed yesterday by restoring the system. But, he now doesn't give me the option to reinstall. I tell the customer Rep this service. Then, the customer service representative hangs up on me. Hangs up on me.
I still don't have a solution, and the man who could have given me one clearly did not bother to do. It is representative of your customer service?
I care more about this issue, to be perfectly honest.
For the benefit of any person who has the same problems as me, that's what I did to solve it:
I run the Adobe CleanerTool to wipe the creative cloud. Then I executed a second time to erase any trace of cloud creative apps. Now! It works! No thanks to the customer service.
-
Stop the dynamics of Action True Actions if ApplyMRU fails
Hello everyone and happy new year!
I have an APEX 4.2 question
How can I stop dynamic Action - Action real treatment, if the first action fails.
The first real action is the submission form, which calls the process of default ApplyMRU.
The second true action sets a value in the form... (but I don't want the value to set if the send form fails for some reason any example space full table...)
Kind regards
MairaSorry for giving it to the fact that your first DA submits the page.
When the first dynamic action runs, he submits the page and executes the following dynamic action (in order). Present it called the ApplyMRU process. I don't know if there is a direct way to wait for successful execution of the ApplyMRU process before you trigger the second dynamic action.Is there a specific need to execute the second action as a dynamic action? Is it possible to replace the same with a sur-soumettre of pl/sql processes (called after the ApplyMRU)? In this way, the second process of will not be called if the ApplyMRU did not.
-
Problem of memory on 3.7.1.3 coherence
Hello
Currently, we are migrating on request Ch 3.5.3 to 3.7.1.3. We found that for one of our EntryProcessor process, we reach OOM due 3.7 using more memory. The process I have the following:
We have 3 caches in 2 different services:
Elements of 120 M Cache1 DistributedCache service
Cache2 120 M service DistributedCache elements
Cache3 empty in DistributedCacheIndexing service
elements of 120M each and a cache is empty. 90 storage enabled nodes with 4 GB each.
The process task is to load the third cache, which acts as a distributed inverted index, then for each item in one of the 120 M cache of items we carry:
cache1_with_120M.invokeAll (AlwaysFilter.INSTANCE, entryprocessor);
the entryprocessor in the processAll of the method traverses all passed through consistency and extract a single field of each object and executes a second entryprocessor (do group by partition, paging, etc.) to the cache3. This call for an another entryprocessor of an entryprocesor is very well since the second goes to another service, and we do not run any other process that might be a dead end.
While this process, it is when the OOM happens only on 3.7.
Using VisualVM allowed us to find that the following objects appear only in 3.7 consume a lot of memory:
PartitionedCache$ storage$ EntryStatus 1.3 M items 126 MB of memory
BMEventFabric$ EventQueue 1.3 M 76 MB of memory objects
java.util.concurrent.locks.ReentrantLock$ NonfairSync 1.3 M objs 55MB memory
java.util.concurrent.ConcurrentHashMap$ HashEntry 1.3 M objs 55MB memory
java.util.concurrent.ConcurrentHashMap$ HashEntry [of] 4.2 k objs 34 MB memory
CompositeKey 1.3 M objs 40 MB memory
RecyclingLinkedList$ Node [15.8 k 31 MB of memory
java.util.concurrent.locks.ReentrantLock 1.3 M 30 MB memory
Total: 447 MB of memory
(Screenshot of VisualVM difference: https://docs.google.com/open?id=0B7BNexVqvbaqejFFZ1ZWemxqc2s)
What he changed from 3.7 to consume more memory? Is there a way to avoid the extra consumption?
Thanks in advance,
Mikel.
Cache configuration:
<? XML version = "1.0"? >
< cache-config xmlns: xsi = "http://www.w3.org/2001/XMLSchema-instance".
xmlns = "http://xmlns.oracle.com/coherence/coherence-cache-config."
xsi: schemaLocation = "http://xmlns.oracle.com/coherence/coherence-cache-config coherence-cache - config.xsd" >
< cache-system-mapping >
<>cache-mapping
< name-cache > CoherenceCachesMetaData < / cache-name >
< scheme name > caches-meta-info < / system-name >
< / cache-mapping >
<>cache-mapping
< name of cache - > * < / cache-name >
< scheme name > distributed plan < / system-name >
< / cache-mapping >
<>cache-mapping
< name-cache > CoherenceCachesIndexes * < / cache-name >
< name of the schema - > indexing scheme < / system-name >
< / cache-mapping >
< / cache-system-mapping >
<>- cached patterns
< replicated system >
< scheme name > caches-meta-info < / system-name >
< support-map-plan >
< local plan >
<>plan-Ref distributed-support-map < / plan-ref >
< / local plan >
< / support-map-plan >
< / replicated system >
< distributed plan >
< name of the schema - > indexing scheme < / system-name >
< service name > DistributedCacheIndexing < / service-name >
< number of threads > 5 < / thread count >
< number of partition > 3137 < / partition-County >
> number of backup < 1 < / backup-County >
<>partition-listener
> class name < service.data.manager.coherence.PartitionLostListener < / class name >
< / listener of partition >
< support-map-plan >
< partitioned > true < / partitioned >
< local plan >
<>plan-Ref distributed-support-card-indexing < / plan-ref >
< / local plan >
< / support-map-plan >
< autostart > true < / autostart >
< / distributed plan >
< distributed plan >
< scheme name > distributed plan < / system-name >
< service name > DistributedCache < / service-name >
< number of threads > 5 < / thread count >
< number of partition > 4721 < / partition-County >
> number of backup < 1 < / backup-County >
<>partition-listener
> class name < service.data.manager.coherence.PartitionLostListener < / class name >
< / listener of partition >
< support-map-plan >
< partitioned > true < / partitioned >
< local plan >
<>plan-Ref distributed-support-map < / plan-ref >
< / local plan >
< / support-map-plan >
< autostart > true < / autostart >
< / distributed plan >
< local plan >
< scheme name > distributed-support-map < / system-name >
<>earpiece
schema < class >
> class name < service.data.manager.coherence.impl.DelegateMapListener < / class name >
< init-params >
< init-param >
java.lang.String < param-type > < / param-type >
< param-value >
service.data.manager.coherence.impl.index.IndexMapListener,
service.data.manager.coherence.impl.util.CoherenceBackingMapListener,
service.data.manager.coherence.impl.MetadataCacheDelegateBackingMapListener
< / param-value >
< / init-param >
< init-param >
com.tangosol.net.BackingMapManagerContext < param-type > < / param-type >
{Manager-context} < param-value > < / param-value >
< / init-param >
< init-param >
java.lang.String < param-type > < / param-type >
{cache name} < param-value > < / param-value >
< / init-param >
< / init-params >
< / class-system >
< / earphone >
< / local plan >
< local plan >
< scheme name > distributed-support-card-indexing < / system-name >
< / local plan >
< invocation-plan >
< service name > InvocationService < / service-name >
< number of threads > 5 < / thread count >
< autostart > true < / autostart >
< / invocation-plan >
< / cache-plans >
< / cache-config >
file substitution of consistency:
<? XML version = "1.0"? >
< consistency xmlns: xsi = "http://www.w3.org/2001/XMLSchema-instance".
xmlns = "http://xmlns.oracle.com/coherence/coherence-operational-config."
xsi: schemaLocation = "operational consistency http://xmlns.oracle.com/coherence/coherence-operational-config - config.xsd" >
<>cluster-config
< member-identity >
< cluster name > pat1UPTOpat12 < / cluster-name >
< site name > qa < / name-site >
pat1 < computer name > - < / computer name >
DataGrid > role name < < / role name >
< priority > 5 < / priority >
< / member-identity >
< multicast listener >
< address > 224.0.55.0 < / address >
< port > 35716 < / port >
< time-to-live > 3 < / time-to-live >
<!-< package-buffer >->
<!-< maximum-packages > 64 < / maximum-package >->
<!-< / package-buffer >->
< priority > 8 < / priority >
< join-timeout-milliseconds > 30000 < / join-timeout-milliseconds >
< %-threshold-multicast > 25 < / multicast-threshold-% >
< / multicast listener >
< package-editor >
< package-delivery >
< timeout-milliseconds > 300000 < / timeout-milliseconds >
< / package-delivery >
< / package-editor >
< / cluster-config >
< / coherence >
Published by: Mikel_Alcon on May 9, 2012 05:32
Published by: Mikel_Alcon on May 9, 2012 05:37Hi Mikel,
Increase the JVM heap size can also be a solution (although I don't know how much you need) unless you have other reasons to avoid it.
It is not necessary to run a single at the time partition. You can pack several partitions (for example 10 partitions for each active storage method ~ 10% of your data in a query). Key point does not materialize all key available on particular member set.
Also recursive entry processor running is not good to be, some eligible items from the GC are kept in the heap while the second entry processor is running.
Kind regards
Alexey -
PLS-00103: encountered the symbol "ALTER".
I receive he following error when I run this script
DECLARE
vcount NUMBER (1);
BEGIN
SELECT count (*) IN the all_col_comments vcount
WHERE owner = 'myUser' and Table_Name = 'table1' and column_name = 'col1 ';
IF vcount = 0 THEN
ALTER TABLE myUser.table1
ADD (col1 varchar2 (1) DEFAULT ' is NOT NULL);
END IF
END;
Error report:
ORA-06550: line 7, column 4:
PLS-00103: encountered the symbol "ALTER" when expecting one of the following conditions:
(begin case declare exit for goto if loop mod null pragma
raise return select update while < ID >
< between double quote delimited identifiers of > < a variable binding > < <
continue the narrow current delete fetch locking insert open rollback
savepoint sql set run commit forall fusion pipe purge
The symbol 'lock has been inserted before "ALTER" to continue.
ORA-06550: line 8, column 11:
PLS-00103: encountered the symbol "(" quand attend une deles de valeurs suivantes:) "
, in
ORA-06550: line 8, column 47:
PLS-00103: encountered the symbol "NULL" when expected in the following way:
as like2 like4 likec between Member submultiset
06550 00000 - "line %s, column % s:\n%s".
* Cause: Usually a PL/SQL compilation error.There is no need to pack the column names in the TOP, the names of the objects are stored by default at the top of case. Isn't that quoted strings must be upper case, but yes, your last block is basically my second block and will correctly find the column already exists when it is executed a second time. Your original, with tiny strings cited would never return a line fomr the query on the column, so would attempt to add the column each time.
SQL> select table_name, column_name 2 from all_tab_columns 3 where owner = 'ops$oracle' and 4 table_name = 'table1' and 5 column_name = 'col1'; no rows selected SQL> select table_name, column_name 2 from all_tab_columns 3 where owner = 'OPS$ORACLE' and 4 table_name = 'TABLE1' and 5 column_name = 'COL1'; TABLE_NAME COLUMN_NAME ------------------------------ ------------------------------ TABLE1 COL1See the difference?
(I only did the drop table so that I can redo the pl/sql block from scratch to show that was) the first time he ran he added the column and b) for subsequent executions, he did not attempt to add the column because it exists, unlike your first display.
However, scripts that add columns to tables should, in general, not be something that is executed repeatedly. More often by adding a column to a table would be part of a process of controlled upgrade, and most of the time, the fact that a 'new' column already exists in the database before the upgrade seems to indicate a problem with the upgrade process, and probably not something to be ignored in silent mode.
John


Maybe you are looking for
-
Toshiba change help buttons for readers of music on a Satellite A100-467
HelloI don't like windows media player and I want to listen to music by other aplications.I'm tempted to change the buttons play/pause, next and prev to another application such as iTunes or winamp, but I couldn't change it. I have Toshiba Satellite
-
Control of VISA resource name: to refresh the list of COM ports programmatically
When the application runs, and you first click this control, it takes 2 to 5 seconds to respond and complete the list for the first time. I would like to auto fill in the first time that the application is busy. Can I do this?
-
Z420: E5-2630 v2 and compatibility z420
Hello The question is very simple: I have a V2 E5-2630, is compatible with the z420? If not, how to fix? Thank you to.
-
Windows Live continues to receive emails (passage in thousands), then back to error. Talked to Dell (bought the laptop from them), they say it's a software problem. They want to pay for their help. I need help. I can generally follow directions.
-
I have problems with my screen freezing. If I try to restore to an earlier point, I get the above error message with a blue screen. I can shut down and restart the computer, and the system performs ok. I always have problems with the screen freezi