Missing data points
I have on some, but not all of my resources, a model where 4 datapoints are declared and then the 5th one is missing (grey appears in the table of availability). I suspect it's something like the agent is running out of time to collect or something like that, but there is no error in the agent.log messages that indicate this. Someone at - it ideas?What are the intervals of collection which collects this measure? Also, what is the date range in the scoreboard?
The default indicator charts show 60 slices of time even for the date range you have set. If you have the default value of 8 hours each time slice is within 8 minutes. If the metric you are looking at has a collection interval greater than what shows the slot, you will have gaps in the data points. Changing the resolution of the date range must show that the 5th data point is here.
Tags: VMware
Similar Questions
-
Point cloud with missing data and 3 sets of data
Hello
I'm doing a scatter diagram that has 3 sets of data in it (i.e. 3 plots on the same graph), except that 2 of my sets of data have a missing value while my third set has all the values. I end up getting 2 lines that are disconnected. I can't just remove the line containing the missing data for the 2 sets of data because since my category axis is time, my data points get shifted and no longer appear at the right time. This is the chart that I have.

Thank you.
Hi Gabrielle,.
If there is a diagram of dispersion, the x axis is a value axis. If you have auto selected for the min and max values on this axis, the scale may change when you remove the data point, 15, 85, but the rest remains in the same position relative to the values on each axis of ordinates. What change will be , however, is the curve on which 15 85 approached a local y maximum.
Scatterplots will always leave a gap in the line/curve of connection where there are a pair of missing data. There are two ways to close the gap.
If the chart is an essentially linear relationship, you can use a calculated value is pair up with the lack of value x. The downside of this is that the representation of this point will be indistinguishable on the map of the other data points, measured.
A better way would be to make two tables, one with the full data set, the other with the partial sets, but with the pair missing completely removed.
Adjust the cards the same size and have the same scales on each axis, then just remove one of the cards except the data points, the curves connecting the data points, the x axis of ordinates and the legend showing the color and the forms used to plot each series.
Give a graphic a transparent filling and place it in front of the other.
Kind regards
Barry
-
"All the data Points" option missing on totals
In a specific workbook (Discoverer Desktop 10.1.2.2), when I go to edit or create a total for one of the worksheets Table, 'All the data Points' option is not there. I can always create sums, counts, etc. on the individual columns. I forget something obvious? There are some sets of circumstances where "All the data Points" would not be an option?Hello
You will have only the option "All the data Points" when you create a new total if there is a data point in the report. Unlike a crosstab report where you can drag an item in the crosstab table to a data point, in the report of the table there is no way to tell Scout that a calculation is a data point.
Items (including the calculated items) in a folder can be changed to be a data point by changing the property to default to "Data point" position using the administrator of the Disco. If you add a data point in the report, then 'All the data Points' option will be available.
Also you can cheat discoverer by using a calculation as a data point using an aggregate function for example sum (case where student_grade like 'A%' then ends 1 0 otherwise), but discoverer will then use a group by in the query, and this can give you a different result.
Rod West
-
Is is possible to add a data Point to 'Stand hours?
Hello
I tried to add a data point to my hours of support in the application of health. I discovered, that 'stand hours' is the only category where the button "Add data Point" is missing. What is a possible way to add hours on another way?
I'm not allowed in the place where my watch at work, where I am standing approximately 11 hours. Caused by this, I am not able to reach my goals.
Hello
It is not currently possible to manually add the credit toward the daily goal of Stand to your Apple Watch.
If you want to suggest that Apple considers adding this as a new feature, you can do it here:
-
variable sharing, missing data, the timestamp even for two consecutively given
Hello
I have a problem with missing data when I read a published network shared variable.
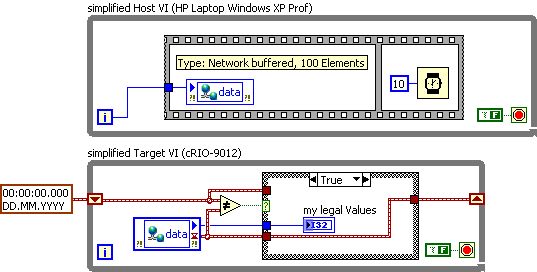
Host VI:
In a host of VI on my laptop (HP with Windows XP Prof.) I write data to the shared Variable 'data '. Between two consecutively write operations is a minimum milliseconds of wait time. I use it because I want to make sure that the time stamp of each new value of data is different then a preview (variables shared the resolution is 1 ms)
VI target:
the VI target cRIO-9012 bed only of new data in the way that it compares the timestamp of a new value with the time stamp of the last value on a device in real time.
Problem:
rarely, I'm missing a data point (sometimes everything works fine for several hours, transfer thousands of data correctly above all of a sudden failure occurs). With a workaround, I'm able to catch the missing data. I discovered that the missing data have the timestamp exactly the same, then the last point of data read, is so ignored in my data 'legal '.
To summarize, the missed value is written to the variable shared host, but ignores the target because its timestamp is wrong, respectively the same as the last value, despite the host waits for a minimum of 10 milliseconds each time before writing a new value.
Note:
The shared Variable is hosted on the laptop and configured using buffering.
The example is simple only to display the function of principle, in real time, I also use a handshake and I guarantee that there is no sub - positive and negative.
Simplified example:
Question:
Anyone has an idea why two consecutively data can have the same timestamp?
Where timestamping (evil) Finally comes (System?)?
What would be a possible solution (for the moment with shared Variables)?
-> I tried to work around the problem with the clusters where each data gets a unique ID. It works but it is slower that comparing the timestamps and I could get performance problems.
It would change anything when I animate the shared on the RT System Variable?
Thanks for your help
Concerning
Reto



This problem has been resolved in LabVIEW 2010. You can see other bugs corrections in theReadme of LabVIEW 2010.
-
Flags Data Points: copy - lack of flags?
I use DIAdem 2012 to extract a FFT points. Whenever I use the function ' copy of flags Data Points: "created channels are missing the last point data (flag). in other words channel contains n - 1 points.
For the moment, I add an additional indicator to make sure I have copy all the flags that I really need, but I got apprcieate all the tips, I can miss something obvious... I have attached a screenshot.
Thanks in advance!
Padraig
Hello
Thanks for posting. I confirm that you are able to put all the flags you need, but that all those flags don't get copied? If that's what you do, you then select flags more than necessary, then copying all the? You may need to browse to re - select indicators and copy them, then start again.
-
WITH T1 AS (SELECT 'A' ITEM, 'L' LOC, TO_DATE ('01-MAR-15', 'DD-MON-RR') EFF, TO_DATE ('08-Mar-15', 'DD-MON-RR') DISC FROM DUAL UNION ALL SELECT 'A' ITEM, 'L' LOC, TO_DATE ('15-MAR-15', 'DD-MON-RR') EFF, TO_DATE ('31-Mar-15', 'DD-MON-RR') DISC FROM DUAL UNION ALL SELECT 'A1' ITEM, 'L1' LOC, TO_DATE ('15-MAR-15', 'DD-MON-RR') EFF, TO_DATE ('04-APR-15', 'DD-MON-RR') DISC FROM DUAL UNION ALL SELECT 'A1' ITEM, 'L1' LOC, TO_DATE ('23-APR-15', 'DD-MON-RR') EFF, TO_DATE ('24-APR-15', 'DD-MON-RR') DISC FROM DUAL UNION ALL SELECT 'A1' ITEM, 'L1' LOC, TO_DATE ('05-MAY-15', 'DD-MON-RR') EFF, TO_DATE ('04-JUL-15', 'DD-MON-RR') DISC FROM DUAL) SELECT T1.* FROM T1;Current output:

For section A and L Loc-> I need missing dates between 01 and 08 March and 15 March 2015 and 31 March 2015 I need another line 07th March and 14 March 2015
Expected results
Header 1 Header 2 Header 3 Header 4 A L 01/03/2015 08/03/2015 A L 09/03/2015 14/03/2015 A L 15/03/2015 31/03/2015 A1 L1 15/03/2015 04/04/2015 A1 L1 05/04/2015 22/04/2015 A1 L1 23/04/2015 24/04/2015 A1 L1 25/04/2015 04/05/2015 A1 L1 05/05/2015 04/07/2015 I tried to use under request, but need to know how can I get new row.
WITH T1 AS (SELECT 'A' ITEM, 'L' LOC, TO_DATE ('01-MAR-15', 'DD-MON-RR') EFF, TO_DATE ('08-Mar-15', 'DD-MON-RR') DISC FROM DUAL UNION ALL SELECT 'A' ITEM, 'L' LOC, TO_DATE ('15-MAR-15', 'DD-MON-RR') EFF, TO_DATE ('31-Mar-15', 'DD-MON-RR') DISC FROM DUAL UNION ALL SELECT 'A1' ITEM, 'L1' LOC, TO_DATE ('15-MAR-15', 'DD-MON-RR') EFF, TO_DATE ('04-APR-15', 'DD-MON-RR') DISC FROM DUAL UNION ALL SELECT 'A1' ITEM, 'L1' LOC, TO_DATE ('23-APR-15', 'DD-MON-RR') EFF, TO_DATE ('24-APR-15', 'DD-MON-RR') DISC FROM DUAL UNION ALL SELECT 'A1' ITEM, 'L1' LOC, TO_DATE ('05-MAY-15', 'DD-MON-RR') EFF, TO_DATE ('04-JUL-15', 'DD-MON-RR') DISC FROM DUAL) SELECT T1.*, NVL ( LAG (DISC) OVER (PARTITION BY ITEM, LOC ORDER BY ITEM, LOC, EFF) - 1, EFF) NEW_EFF, NVL ( LAG (EFF) OVER (PARTITION BY ITEM, LOC ORDER BY ITEM, LOC, EFF) - 1, DISC) NEW_DISC FROM T1;Hello
You can use UNION to combine the new lines that you generate using LAG or LEAD to actually the rows in the table:
WITH new_rows AS
(
SELECT the point AS header1
loc AS tete2
Disc + 1 AS header3
, ADVANCE (FEP) OVER (PARTITION BY point, loc
ORDER BY eff
) - 1 AS header4
FROM t1
)
SELECT *.
OF new_rows
WHERE header3<>
UNION ALL
SELECT the element, loc, eff, disc
FROM t1
--
ORDER BY 1, 2, 3
;
In any analytical function, there is never any point of order by the same expression that DIVIDE you BY.
-
Line chart of several series with staggered data points
Hello
App of Hillary graphic sample includes an examples of charts and how to handle null values.
https://Apex.Oracle.com/pls/Apex/f?p=36648:55
I came across a scenario which goes a step further. If you have a series with a set of data points and another series that overlap, where a few data points are missing, for example:
create table graph_lines (series number, thedate date, thevalue number); insert into graph_lines select 1 series ,add_months(trunc(sysdate,'yy'),rownum-1) thedate ,log(2,rownum) thevalue from dual connect by level <= 12 union all select 2 ,add_months(trunc(sysdate,'yy'),rownum-1) ,case when mod(rownum,3) =0 or rownum =2 then log(3,rownum) end from dual connect by level <= 12;
I get the case where he's going to draw a line between the points that are next to each other, but the gaps it will display just the point

Https://apex.oracle.com/pls/apex/f?p=73000:35 image
I have no doubt a single this is the expected behavior, but I would like to know if anyone has any ideas on how to connect the dots.
I thought about a snazzy model clause generates middle in my data points might work, but this seems heavy handed and a little scary.
I thought that maybe there is a graphic solution?
APEX 4.2.x
Scott
The idea of 'Null' removal was not all that possible. After testing it out, I found apex will be always generated empty points. Explicitly define the XML to have only the data points with values does nothing either.
Because I thought it was a really interesting problem, I was wasting so much time on this :-). I was side on the reference guide and the user, modify the XML again and again and again.
I hoped that, by defining a second category axis and set regional and datetime parameters, change of the shaft in one type datetime and specifying a main grid with every month, the table would be plot my data on this axis. Unfortunately, it seems as if this is ignored - a very frustrating experience. Anychart would just keep trace points with its own calculated intervals.
Ultimately if I stumpled on a sort of difficulty, although I'm not sure how good it would be. There is a setting that you can set by using the custom XML part that ignores the missing data and the values of interpolation. It works well, but it always displays labels.
https://Apex.Oracle.com/pls/Apex/f?p=11031:4 apex_demo/demo
AnyChart | [AnyChart 6.x] How to connect mind lines...
node - reference XML - AnyChart.Com Flash Chart Component With all these nodes, is it easy to miss what you need... It's a bit weird, but who "ignore the missing" points, you must set the value to "false"? :-)
-
Lack of data Points in the chart Illustrator
Hello, I create a line chart in Illustrator (CC) on a Mac and after entering the data, one of the lines is lack of data points. When the line should be, it breaks everything. Here is a picture of what it looks like (see the purple line and the second column). I have not removed all the points or it separated. I tried to recreate it, and he did the same thing? Why the data points are missing? How can I fix this problem so that they appear?
(Note: I asked this via chat 0186206467 and it took so long to get an answer that cat quit on me.)

What happens if you enter the data without the comma? This missing data.
-
I use a 2D line chart to show the status of my weight loss I will give my doctor.

I want to select a group of data points, or individual data in the notes to table and place the points or the labels on them so I can identify things like water weight loss, the consumption of food and splurges, and so on.
Thank you, Eric
There is no such feature.
You can, however, add a column to the table where you enter the data and make this new column 'Notes' or 'Description '.
You can also use the arrows and other graphic elements in the menu "Shapes" to highlight specific items of interest.
-
Hi all
I would like to know where is the location of the mouse position to a point of data compared to the graph. basically, the opposite of this person's job action:
The point value of graphic display WPF overview
Instead of getting a data point, hold the position of the mouse. I am the superposition of the shapes on the chart and would like to know for a specific point in the graph in pixel coordinates.
Thank you.
Of after your question, I assume you have a data value you want to translate (as opposed to an event arguments of mouse, which already has a
GetPositionmethod).You can use the
DataToScreento get a position of the screen in the plot area, so useDesiredPlotAreaMarginto compensate for this position on-screen to reference external graphic control (i.e.point.X += margin.Left; point.Y += margin.Top).You can also use the
DataToRelativeto get a relative position of a data point, then place an object in theChildrencollection (a bit like aPointAnnotation):XAML
xmlns: or = "http://schemas.ni.com/controls/2009/xaml/presentation."
xmlns:niPrimitives = "http://schemas.ni.com/controls/2009/xaml/presentation/primitives".
...
Width = "10".
Height = "10".
STROKE = "Black".
StrokeThickness = "2".
niPrimitives:RelativePanel.RelativeHorizontalAlignment = "Center"
niPrimitives:RelativePanel.RelativeVerticalAlignment = "Center"
/>
Code
Parent = graphic point. DataToRelative (dataValue);
RelativePanel.SetRelativeHorizontalPosition (dataMarker, relative. (X);
RelativePanel.SetRelativeVerticalPosition (dataMarker, relative. Y);
-
How can, during the collection of data, start a new column in my table every 100 data points?
Hello! I have a problem with my data - I get in a wide range of 1 x 1000, but it's the repeated measures, each taking about 500 data points. I want to break this table for this data string start a new column in my table every 500 points given. I don't know how to do it-please help!
datacompiler100 wrote:
Hey thanks for the sponsor and the first off I must apologize for the State, I am attaching my VI. I put the part of the VI that I am working on (my team has access, so didn't post everything here) and also attached the data file (when just written in a spreadsheet file, not through the attached VI). I want to convert the long row of data and then start a new column every 50, 100, 5 points (user-defined).
Using the data from the file, you can reshape everything simply (as you already!), followed by transposition (since you want columns instead of rows). 2D arrays must always be rectangular, so the last column is filled with zeros if necessary. Is that what you want?

Of course if you try to add a new column in a file, that will not work. You can only add lines in an existing file because of the way the data is organized. To add columns, the entire file must be read, intertwined and all re-written new data in the file.
-
Sampling rate - too much data points
Hello community,
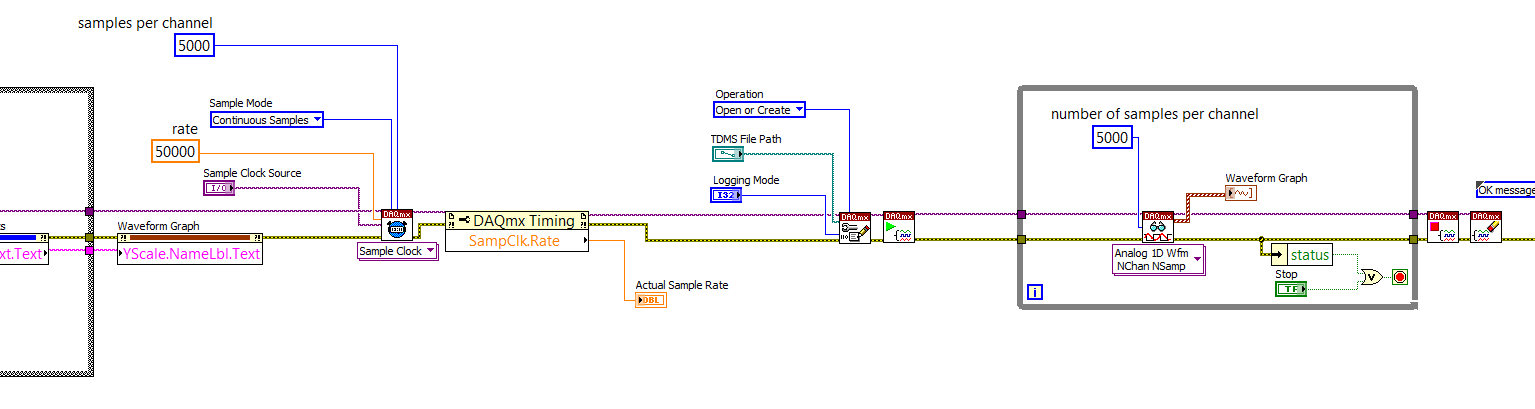
I use a sensor signal strength of pressure on DAQmx labview through 2014. My rate from the hardware synchronization function is 50 KHz. The samples per channel of timing and read screws are the same set to 5 Khz when the channels are a continuous sampling. The problem I'm having is that when I run labview for a few seconds, say 5 seconds, I'm half million points of data. I tried to run for 10 seconds and points were more than a million where it is difficult to analyze. I think that the vi generates too much data points and the buffer is large. Am I wrong? Can you please help me solve this problem?
Kind regards
Mike
You are now ready to learn a little of the power of LabVIEW and data flow programming. LabVIEW is an inherently parallel language - two loops can run independently and in parallel, allowing you to make time-sensitive (such as sampling data) and a lot of time (such as data logging and tracing) at the same time, using queues to pass data between the loops and ensure the buffering required.
If you open LabVIEW and click on the file menu in the toolbar, and then select new... (the points are important!), you will be able to create new ones (VI) from the model. Choose a Framework, Design Patterns, producer/consumer Design Pattern (data). It's what you want to do.
You basically set up a "pure DAQ Acquisition Loop" (without logging TDMS) as producer, creation of 5000-element arrays of data every tenth of a second (if you are sampling at 50 kHz). You create a queue of data outside the loop of producer whose elements are an array of 1 D of waveforms (the output of your Read DAQmx) and instead to send the data to a waveform graph, you put it in the queue.
You are under this loop, a parallel loop that gets the same queue and remove items. This loop will be sitting idle (no time taking CPU) until the data is queued. He then it takes away the poster and registers (logs) in a PDM file. Either way, you should open the TDMS file before entering this loop (consumer), write to the file inside the loop and close the file when the loop exits. Study the example of the VI, you create with the model and see how it works.
The beauty of this is that you can certainly 'keep up' with the writing of the data points in a TDMS file to 50 kHz. You might not be able to display all the points, but there is nothing to prevent you from data processing (by, say, decimating or "block average" it) to a more 'user-friendly' display (your eyes ' sees' a 50 KHz signal?) -you have a set of 100 msec prior to the next package arrives in the queue. Also note that the loop of producer probably takes very little time CPU - most of the time the material is waiting for its clock to 'tick', collection of points in a buffer, then transferring to the loop.
Now you can have your cake and the computer display, too.
Bob Schor
-
Hello. I am looking for a way to draw several XY cursors, then use a lasso (like paint or photoshop) tool to select a subset of the sliders.
Lasso would allow the user to outline to draw a region with the mouse to select cursors within the lassoed area.
Labview graphics can do this natively? Or maybe someone knows an elegant solution to achieve this?
Hi Marksyn,
No, that behavior is not native in LabVIEW.
First off, the selection can be rectangular, or should it be a "freeform"? The latter will be much more difficult to write, but it could look like this.
Build an event structure and case of mouse event down / mouse upwards (to keep track of when you press the button) and mouse move the XY graph. In the case of mouse move, LabVIEW returns the coordinates of the mouse control panel each time it moves. For the XY coordinates, use a node to invoke the graph with the method "Panel of XY coordinates." Make a list of all the XY coordinates until the mouse button is released. This table is your free form boundary. The tricky part now is to get a list of the "sliders" (or do you mean data points?) included in this limit. Let us know when you make it that far.
-
several data points Boolean indiacator
I run a program (which I'm still trying to work the kinks log data on) where I need to take several different channels and give me a warning if the temperature exceeds a certain limit. I'm 7 channels linking fieldpoint in a picture and sending it to a curve of waveform. I want each of these signals during playback to trigger a Boolean indiactor (LED) if the ambient temperature is more than 83. Ideally the temperature will be much higher later so I'll use it for fire tests (e.g. 1600) and it is very important that I get this down before we use the .vi in the fires of the test.
For some reason, when I write to spread sheet file, I get 1 column of the last data point are met. There is also no time stamp on the left most column. I need to ensure that data are collected on every second and is stored in this file.
I was also wondering if anyone knew how to change the names to write to destination of the spreadsheet (the gall that you create) file once instead of put the path in there. Finally, we will run several tests and we do not want to replace all the tests by accident. Please if someone could help with anything that would be great. Thank you!
Tanya
PS works with version 8.6
Well, we can discuss one thing at a time. First of all, it is a way, you could do the evaluation of Boolean values.
I think that I would split the data collection and processing of data in two loops. Have a loop that takes just the data and another that processes the data. This will also allow a state machine architecture. That would leave you do checks if a file exists before you leave and a few other things.






Maybe you are looking for
-
Satellite A60 Pro is not booting
Hello I hope someone here can help you. I know that this laptop is old ages, but it's the only one my aunt and she would that he repaired if possible. Basically, the question is this.You can start the laptop, all the normal lights light up and the sc
-
My computer broke down recently. I have the cd of windows XP Home Edition. When I try to put the cd in and "install windows" it tells me these things... -Setup cannot continue because the version of Windows on your computer is newer than the version
-
I bought Windows 7 via the webshop of Microsoft and I am not able to download. Please tell me what to do
-
I cannot read the file as a video and only as an audio Director. How to change the file in one only that the manufacturer can read?
-
arguments of a function addEventListener
public function getUser (): void{var i: Number;for (i = 0; i{red.addEventListener (MouseEvent.MOUSE_UP, addEntered (0));blue.addEventListener (MouseEvent.MOUSE_UP, addEntered (1));yellow.addEventListener (MouseEvent.MOUSE_UP, addEntered (2));green.ad