Normal reboot a server DB is a good practice?
Hi all
Recently, I hit a bug "Bug 10194190 - Solaris: spin process and/or ASM and DB crash if RAC instance > 248 days ( Doc ID 10194190.8 )" "
One solution is to restart the Server DB regularly.
I would like to know if control restart a server DB is a good practice in a normal case without hitting the bug.
In my experience, Unix platform is more stable than the Windows platform in
end of time. Truth without papers we need to restart Windows
Server for the services included in some cases.
I heard not to restart a database regularly in the Unix platform.
To my knowledge, a 7 x 24 reviews should have as more long availability possible.
However, I share that a database must be restarted in some cases as
patching and some other maintenance.
In our case, I agree that we must take this workaround solution, restart regularly the DB server, to
the problem at this point. However, I want to know, as a good practice, if a DB server must be restarted on a regular basis in the
normal case without hitting the bug.
Maybe a need to define "regular". To my knowledge, the bounce is not good because it has continuous setting on in the background, which is reset every rebound in memory. I am referring to the tuning that is associated with the presence of the SPFILE.
I don't know how long it takes before this system is on the right track, it's an interesting question.
But rebounding is good, because ultimately you will need a few days. Nothing like a test procedure and bounce a database is one procedure like the others.
Obviously, 24/7 databases are a reality, which makes this exercise very difficult/impossible.
Not many problems will be solved with bounce data well. But if a problem appears as it does, it is not impossible. I saw only once (on a Unix system). In the end, no one was able to explain the cause, and bounce was unsalted solution. The dirty fix was: kill the production process. And the problem disappeared with the upgrade (11g). Just a fact.
Tags: Database
Similar Questions
-
When the Active Server is shut down normally, the passive server does not start the service
Hi friends,
I have a question for the vCenter heartbeat,
When the Active Server is shut down normally, the passive server does not start the service.
Is this normal?
Thank you.
He starts the services on the passive server because the correct judgment still leaves the server active as being the "main".
Stop all services of it properly. And after it comes back online replication starts as before, so that no service must be started on both servers. (in this case that you will have questions)
Please note that on a server computer, you have 2 possibilities to "stopping down": the BONE and the option of status and control of the server Vcenter Heartbeat
See you soon!
-
Good practices of FIFO: updated old cluster or create new
Hello world
My question is more on "good practices" that really solve a problem.
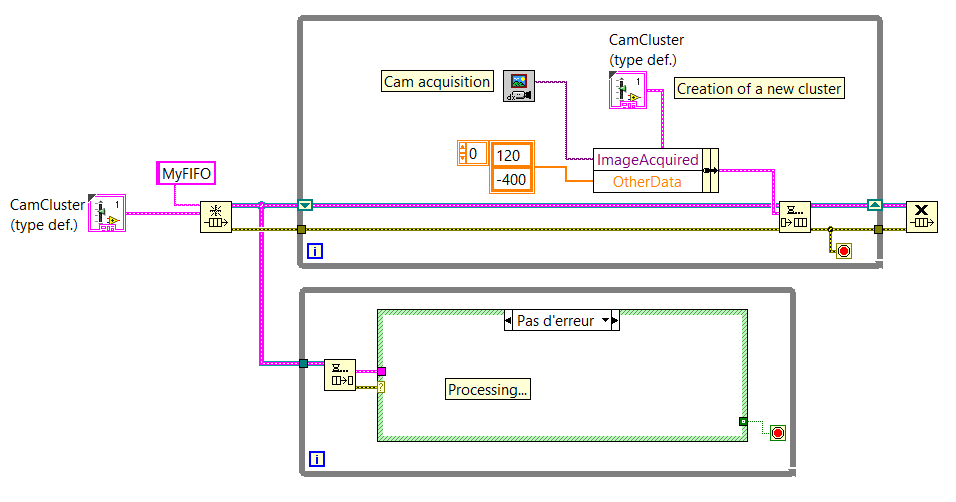
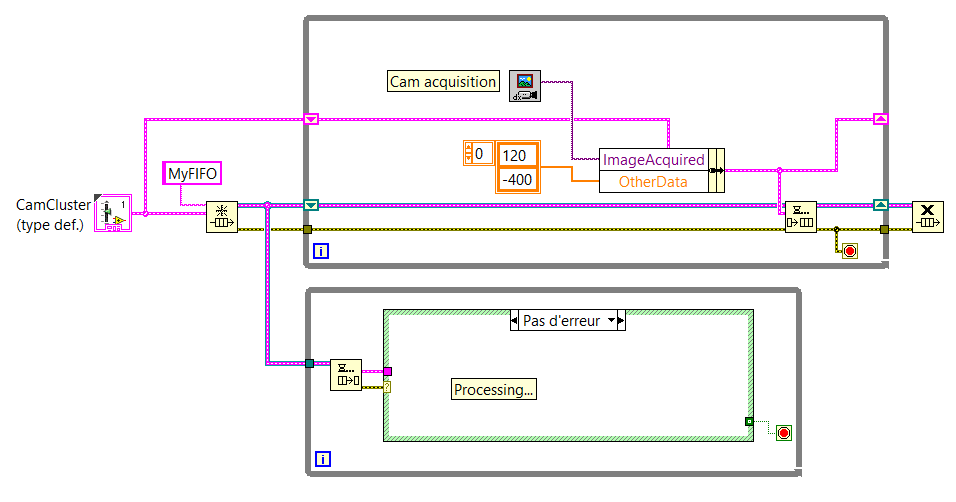
I use FIFO to send images and other data from a producer to a consumer.
I created a cluster which includes all the data that must be sent through the FIFO.
My question is: can I create a new cluster to each loop of the producer and put this cluster in the FIFO or should I set a shift and then register and update the data of this fallen registry change by sending in the FIFO?
Below you will find two screenshots that sums up the idea (NB: these aren't the real VI.) We come here to show the general idea).
If there is a difference (in the way that the computer uses memory for example, or something else...) between these two methods of programming, you will give me some details so that I can understand why to use one over the other, please?
Thank you very much.
Best regards.
Luke
I think that there is very little difference in terms of performance (perhaps the registry approach change is slower than sliiightly - but probably not noticeable in most cases).
The main reason you want to use the shift register approach is that if you update only certain values before sending the data in the queue, those that would be lost if you created a new cluster each time. For example, if 'Directories' was constant, you could just power/updating that once the value to the registry to shift and just update the part "ImageAcquired" of the cluster before you send it in the queue. This also means that if you update your cluster to have more elements (using a type-def, of course), you can be less worried about having to update the individual elements.
I think it is less a problem of performance (both are valid and effective) and more a matter of maintainability and flexibility.
-
What is a good practice to manage LOV in jdev apps?
Hi, experts,
In jdev 11.1.2.3,.
In our projects, there are numerous LOVs whose value are stored in a common dictionary table, for example in the refcode table:
refcode (id, low_value, high_value, sense, domain_no),
Different LOVs can extract value peers (low_value, meaning), or (high_value, sense) refcode table by using domain_no as the filter criteria.
In the user interface of the user, the values of field/code number should be displayed by a sense of refcode password
To achieve this, I'll create many links between the different tables with refcode,
and create your entity refcode consider the secondary entity views.
I feel some odd (because so many associations with the same table refcode),
What is a good practice to manage LOV in this way?
Thank you.The merger for Oracle Application Development Framework Developer's Guide
10.3 defining an object of basic display for use with Lookup Tables
(http://docs.oracle.com/cd/E37975_01/web.111240/e16182/bclookups.htm#BABIBHIJ)
10.3.3 How to set the WHERE Clause of the view of search criteria to display objectThere is valuable information and suggestions on the search features to implement, in particular using view criteria
(see criteria and display accessor is one of the important and a great idea in ADF)I think that, by using the view criteria, attribute derived to display information of fk can be implemented without definition of associations FK convinent way.
-
Is this a good practice if oracle home is installed under / opt directory?
Is this a good practice if oracle home is installed under / opt directory?
Appreciate any suggestions.
S.PL post OS and database versions. You can install in any directory you choose - recommendations are documented - http://docs.oracle.com/cd/E11882_01/install.112/e24321/appendix_ofa.htm
HTH
Srini -
What is good practice to update fields of VO on the user action
Hi all
version: Jdeveloper: 11.1.2.1.0
I have an obligation to update some fields in VO (such as status, date of approval) to the "Approve" button is clicked, I want to know what the good practice of VO update in this case because I see two options for me here.
1 1 manipuler handle in a managed bean, get the iterator VO and to update the VO and invoke the validation operation.
2. write a method in AM and get the VO, update the attributes of the vo and call commit transaction db.
Can anyone suggest what is good practice in this case?
Kind regards
Delighted Nuka.How about a combination of the two?
The requirement is a requirement of the company, the method must be implemented in the model. Use a method in the vo or am for her. This method you expose on the customer interface and then call through the layer, just like you call create method error. After you call the method commit the bean or no later than the point in your workflow.
You should not call commit inside the method as method then can be part of a larger transaction.Timo
-
CRS does not come after reboot the server in Oracle11g r2 11.2.0.1.0
Dear Oracle gurus
Our platform:
ORACLE11G r2 RAC/GRID 11.2.0.1.0
ReadHat Enterprise Linux5.3 64-bit
RAC - 2 NŒUD
[root@xyz-ch-aaadb-02 evmd] # /u01/app/11.2.0/grid/bin/crsctl check crs
CRS-4638: Oracle high availability Services is online
CRS-4535: cannot communicate with Cluster Ready Services
CRS-4530: communication failure communicating with Cluster Synchronization Services daemon
CRS-4534: can not communicate with the event Manager
RAC - 1 NŒUD
[root@xyx-ch-aaadb-01 crsd] # /u01/app/11.2.0/grid/bin/crsctl check crs
CRS-4638: Oracle high availability Services is online
CRS-4535: cannot communicate with Cluster Ready Services
CRS-4530: communication failure communicating with Cluster Synchronization Services daemon
CRS-4533: Event Manager is online
RAC - 1 NŒUD
crsd.log
2011-08-21 00:35:27.913: [CSSCLNT] [3047883232] clssscConnect: gipc request failed with 29 (0x16)
2011-08-21 00:35:27.913: clsssInitNative [CSSCLNT] [3047883232]: connection failed, rc 29
2011-08-21 00:35:27.914: [CRSRTI] [3047883232] CSS isn't ready. Status received 3 of CSS. Waiting for a status of good...
2011-08-21 00:35:28.915: [CSSCLNT] [3047883232] clssscConnect: gipc request failed with 29 (0x16)
2011-08-21 00:35:28.915: clsssInitNative [CSSCLNT] [3047883232]: connection failed, rc 29
2011-08-21 00:35:28.916: [CRSRTI] [3047883232] CSS isn't ready. Status received 3 of CSS. Waiting for a status of good...
RAC - 2 NŒUD
crsd.log
2011-08-21 00:38:52.225: [CSSCLNT] [3198087648] clssscConnect: gipc request failed with 29 (0x16)
2011-08-21 00:38:52.225: clsssInitNative [CSSCLNT] [3198087648]: connection failed, rc 29
2011-08-21 00:38:52.225: [CRSRTI] [3198087648] CSS isn't ready. Status received 3 of CSS. Waiting for a status of good...
2011-08-21 00:38:53.228: [CSSCLNT] [3198087648] clssscConnect: gipc request failed with 29 (0x16)
2011-08-21 00:38:53.228: clsssInitNative [CSSCLNT] [3198087648]: connection failed, rc 29
2011-08-21 00:38:53.228: [CRSRTI] [3198087648] CSS isn't ready. Status received 3 of CSS. Waiting for a status of good...
Please help solve the problem.
Let me know if you required information.
Concerning
Hitesh Gondaliahitgon wrote:
We correctly the required permissions and ownership changes before we install the RAC.
But after restarting the server.Please find the required papers.
[root@xyz-ch-aaadb-01 ~] # ls-l/dev/sd *.
BRW - r - 1 root disk 8, 0 21 August 00:20 / dev/sda
BRW - r - 1 root disk 8, 1 Aug 21 0020: / dev/sda1
BRW - r - disc 1 root 8, 2 21 August 00:20 / dev/sda2
BRW - r - 1 root disk 8, 3-21 August 00:20 / dev/sda3
BRW - r - 1 root disk 8, 4 August 21, 00:20 / dev/sda4
BRW - r - 1 root disk 8, 5 August 21, 00:20 / dev/sda5
BRW - r - 1 root disk 8, 6 August 21, 00:20 / dev/sda6
BRW - r - 1 root disk 8, 16, 21 Aug 00:20 / dev/sdb
BRW - r - 1 root disk 8, 32 21 August 00:20 / dev/sdc
BRW - r - 1 root disk 8, 48 21 August 00:20 / dev/sdd
BRW - r - 1 root disk 8, 49-21 August 00:20 / dev/sdd1
BRW - r - 1 root disk 8, 64 21 August 00:20 / dev/sde
BRW - r - 1 root disk 8, 65 21 August 00:20 / dev/sde1
BRW - r - 1 root disk 8, 80 21 August 00:20 / dev/sdf
BRW - r - 1 root disk 8, 81 21 August 00:20 / dev/sdf1
BRW - r - 1 root disk 8, 96 21 August 00:20 / dev/sdg
BRW - r - 1 root disk 8, 97-21 August 00:20 / dev/sdg1
BRW - r - 1 root disk 8, 112 21 August 00:20 / dev/sdh
BRW - r - 1 root disk 8, 113 21 August 00:20 / dev/sdh1[root@xyz-ch-aaadb-02 ~] # ls-l/dev/sd *.
BRW - r - 1 root disk 8, 0 21 August 00:20 / dev/sda
BRW - r - 1 root disk 8, 1 Aug 21 0020: / dev/sda1
BRW - r - disc 1 root 8, 2 21 August 00:20 / dev/sda2
BRW - r - 1 root disk 8, 3-21 August 00:20 / dev/sda3
BRW - r - 1 root disk 8, 4 August 21, 00:20 / dev/sda4
BRW - r - 1 root disk 8, 5 August 21, 00:20 / dev/sda5
BRW - r - 1 root disk 8, 16, 21 Aug 00:20 / dev/sdb
BRW - r - 1 root disk 8, 32 21 August 00:20 / dev/sdc
BRW - r - 1 root disk 8, 48 21 August 00:20 / dev/sdd
BRW - r - 1 root disk 8, 49-21 August 00:20 / dev/sdd1
BRW - r - 1 root disk 8, 64 21 August 00:20 / dev/sde
BRW - r - 1 root disk 8, 65 21 August 00:20 / dev/sde1
BRW - r - 1 root disk 8, 80 21 August 00:20 / dev/sdf
BRW - r - 1 root disk 8, 81 21 August 00:20 / dev/sdf1
BRW - r - 1 root disk 8, 96 21 August 00:20 / dev/sdg
BRW - r - 1 root disk 8, 97-21 August 00:20 / dev/sdg1
BRW - r - 1 root disk 8, 112 21 August 00:20 / dev/sdh
BRW - r - 1 root disk 8, 113 21 August 00:20 / dev/sdh1Concerning
Hitesh GondaliaHello
Permission vote drive and the drive to vote changed after the reboot. sustain the permissions and ownership of roc and drive to vote even after reboot. check out this storage admin, they should be able to do.
After this test restart again and see the resultHope this helps
See you soon
-
Failed to install Vista Service Pack 2 (32-bit): do not normally reboot system...
When update SP2 introduced a few days ago, I tried to install it next to other updates. He installed the files, asked me to restart to make the facilities to be effective, and again started installation of the service pack in 3 steps (of course he has shown not to turn off the ot system to disconnect it). When he began to install while closing, the first step has been successful at 100%, and when it was 98% done in step 2 THE SYSTEM of COMPLETTELY STOP ALL of a SUDDEN WITHOUT ANY WARNING. When I rebooted the system, it recommended to launch startup repair and asked me if I want to restore the system and when I accepted, it AUTOMATICALLY restored to a previous point and windows started normally (before you start to install SP2, it has shown to do a restore point)...
Now, when I checked in the history of the update, all other updates of internet explorer, windows etc defender have been installed except SP2. What is more worrying is that my laptop is not STARTING NORMALLY since then. Always asking me 'Launch system repair' at the beginning - to go to system restore... and then only from the windows... even if just RESTART instead shutdown and startup, the same thing happens... So, I started to keep mode "sleep" when not in use (I was doing important work in small sessions and did not dare to stop)
I tried to install SP2 twice since then and each time the SAME THING REPEATED.
Now when I rebooted my system that's repeatedly went to 'Launch Startup Repair' but not to the point where he asks me if I want to RESTORE... instead, it's just SHUTTING DOWN...
I am running Vista Home premium on my laptop HP Pavilion DV2000 series with processor 2.1 GHz intel core 2 duo, 2 GB RAM, 160 GB HD, NVIDIA graphics 512 MB, lightscribe DVD burner...
No idea what can do now? Any suggestions would be much appreciated...
Cissokho
Hi Patricia,
For assistance, contact Microsoft.
Free unlimited installation and compatibility support is available for Windows Vista, but only for Service Pack 2 (SP2). This support for Windows Vista Service Pack 2 (SP2) is valid until November 26, 2009.
Availability of support chat or messaging differs depending on your location. For customers in North America, chat and e-mail support is available.
Go to http://support.microsoft.com/oas/default.aspx?prid=13014&gprid=582034 and select the appropriate category (e.g., Installation).Hope this helps, Vincenzo Di Russo - Microsoft MVP Windows Internet Explorer, Windows Desktop experience & Security - since 2003. ~ ~ ~ My MVP profile: https://mvp.support.microsoft.com/profile/Vincenzo
-
SWFVerification without restart/reboot the server
I was now two occurrences of SWFVerification is not activating when the values are added to the application.xml for a client application.
We allowed him with an empty dir, and any player will always through.
I tried to add a "is not not-really-the - player.swf" to confirm that he will reject all other connections, and they always get through.
I tried to reload the Application, and which also had no effect.
In a previous proceeding, only after the virtual server is restarted, SWFVerification will start to work.
This question quite important for us - as we host 100 s other connections of client application on several boxes that make SWFverification is not just simple 'reboot' these boxes.
Any suggestion on how to get SWFVerification to work without having to restart the virtual server or FMS itself?
Thank you.
-Va
Figured it out.
From what I saw. the Admin "unloadApp" command is not an effect the SWFVerification. However, "reloadApp" seems to indulge the SWFVerification on a modified application.
-Va
-
Services Exchange do not start automatically when rebooting the server (SBS 2011/07)
Both services must be started manually after the server is restarted namely:
Authentication based on the form of MS Exchange
The MS Exchange RPC Client AccessTry asking in the Windows Server forum:
http://social.technet.Microsoft.com/forums/en-us/category/WindowsServer -
How to reboot the server Oracle Rac?
Kind of beginner to the CARS, just started?
I know that the order to stop it.
Instances of database 1 stop
2 stop the Services on the node database
3. stop the node level apps
4 stop the Listener
Can someone let me know the order to restart?
Thank you
Hello
Instances of database 1 stop
2 stop the Services on the node database
3. stop the node level apps
4 stop the Listener
1. If you stop instances of database - community services which if accessed by client customers that it will get the problem (they would say that they are unable to connect to your databases). The Central battery will go into an abnormal state - compared to your normal startup and shutdown procedure (reason for that since your listener are always up and try to provide services (services database).) Maybe they cannot provide the service because the database is out of service. If you need to stop your stack of middle ware initially.
2. after the middleware stack you must work on the stop of the listeners and services (which is logically the scoop of cluster and data bases - right at the bottom) with other dependencies.
3. then, you can stop the database followed by the applications node.
4. Finally cluster ware
-Pavan Kumar N
-
HTML refresh after reboot the server
Hello all
Compliments of the season
I recently edited some of the HTML files in our 11.7 OBIEE environment. (toc.htm, biee0088.htm and a few others)
After that the server restarted al content of the files changed to its original state, thus eliminating all of my changes that I made.
Is there a temp directory where these files can be stored?
Concerning
Benoit
Can be analytics.war
check the Console Home > summary of deployments >
-
should we reboot BI Server for each change in the RPD or answers?
Hi guys,.
When creating new user (or a change a little) in the RPD or the answers, why we must resume the BI server each time?
This process could be problematic or expensive to restart the server in the production environment?
What do you think
Thanks for the help,
HoussemYou do not have to restart the BI Services if you have opened the RPD in online mode and make the changes...
When you work offline her need of restart the RPD -
Pragma EXCEPTION_INIT or RAISE_APPLICATION_ERROR - that is good practice
Hello
I have came across a point where I need suggestion and views on error handling. However I use above all error handler.
But in case the base unit (inside) / program that calls that one would be preferable to use the PRAGMA EXCEPTION_INIT or directly use RAISE_APPLICATION_ERROR.Here's the example I've tried
SQL> DECLARE 2 L_CNT NUMBER; 3 NO_DATA_FND EXCEPTION; 4 PRAGMA EXCEPTION_INIT(NO_DATA_FND,100); 5 BEGIN 6 SELECT 1 INTO L_CNT 7 FROM DUAL WHERE 1=2; 8 EXCEPTION 9 WHEN NO_DATA_FND THEN 10 raise NO_DATA_FND ; 11 End; 12 / DECLARE * ERROR at line 1: ORA-01403: no data found ORA-06512: at line 10 ORA-01403: no data found
Or is better
SQL> DECLARE 2 L_CNT NUMBER; 3 BEGIN 4 SELECT 1 INTO L_CNT 5 FROM DUAL WHERE 1=2; 6 EXCEPTION 7 WHEN NO_DATA_FOUND THEN 8 RAISE_APPLICATION_ERROR(-20001,'OR is this good way of handling'); 9 End; 10 / DECLARE * ERROR at line 1: ORA-20001: OR is this good way of handling ORA-06512: at line 8
No, it's not the same.
Let's say you had a PL/SQL code you want to process the cases where you get an error ORA-01234 (for example), and you want to write an exception handler for it. You could use exception_init for card ORA-01234 an exception called MY_EXCEPTION and then use "when MY_EXCEPTION" in your exception handler. It has NOTHING to do with the throwing of an exception. You can also use this name to throw the exception directly
raise_application_error throws an exception with a specific number and text associated with it. The error number must be within a specified range (-20000 29999 if memory serves).
-
vCenter Server with vSphere Essentials best practices for small business
I hesitated to post this thread for fear of redundancy, but I wasn't able to find an answer in previous discussions.
I read the installation documentation for vSphere Essentials vCenter Server installation.
Is it a good idea to install vCenter on my ESXi host as a virtual machine? I don't understand how the server can be installed as a virtual machine if she must always be on. What happens when I do the updates of the hypervisor, ESXi (4.0 to 4.1)? This would not cause the vCenter Server to disconnect?Because I have Essentials, I don't have a HA and cannot migrate the server vCenter Server to another host as shown in the installation documentation.
Thank you
It should not be a problem - if you manually perform the update using either the esxupdate or vcenter command vihostupdate does not at all in the game - if you use VUM he actually intitiates the vihostupdate order - when restarting the host to be reconnecting to vcenter once it is running.
Maybe you are looking for
-
Reference design DAQ missing DAQ.lvclass
When loading the Data Acquisition Reference Design.lvproj of daq_ref_app_v10.zip in 9 LabVIEW, LabVIEW to find the class file DAQ.lvclass. There is no file in my system. There is no file in daq_ref_app_v10.zip or in the directories he created. Where
-
I want to transfer all the files / documents, information on Windows XP or 7 or 8.
I have some important files in the windows 95 operating system. I want to transfer all the files / documents, information on Windows XP or 7 or 8. How to do this. OT: Mr. Shekar Iyer
-
drivers for Pavilion 15-n003sq win 7 32-bit
Hello I can't find drivers for my hp Pavilion 15-n003sq with a win 7 32-bit operating system. Help, please! Below are the IDS of material for the non working devices: Network controller - hardware id:PCI\VEN_8086 & DEV_08B1 & SUBSYS_40628086 & REV_63
-
I will install another antenna in my T430 for LAN wireless for my ultimate Intel wireless card. I probably should have just ordered the thinkpad with it originally, but too late for that. My question is, will all work fine WLAN antenna or do I need a
-
I reinstall windows xp & he said that if I continue, I'm not able to connect to windows. I accidentally hit continue and now I can't log on. Help, please. What should I do now? Lynn B. original title: Reinstalling windows xp