Operating on 5772-01 data
Hello
For my application, I need to integrate the analog 5772-01 entry over time, so I need to extend the 5772 32-bit input before joining. My attempts to implement the sum is clearly incorrect, and I think it's because I do not properly understand the 5772 data format.
Page 19 States Manual 5772digital data resolution is 12 bits, signed, binary, accessible data using a left-justified data I16 type.
Page 32 of the ADC12D800RF data sheetshows the code for output from the analog input voltage:
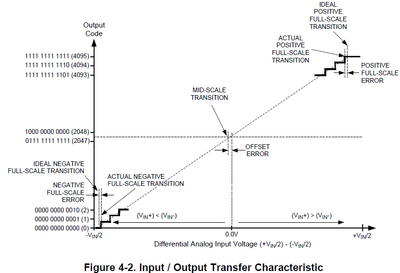
They are not lining up in my mind, I guess because the CLIP between the two? Can someone help me understand how to extend the entry 5772-01 to 32-bit and run on it? What the I16 convert voltage? Thanks in advance for any help.
-Steve K
Tags: NI Products
Similar Questions
-
As an operator with the long data type
Oracle 10g.
Hi gurus
I want to apply as an operator on the long data type, but I get the error message, can you please help me why is that I use as an operator with the long data type. I did some research and but unable to find a solution, see query for more details below...
Query
SELECT trigger_body FROM user_triggers
WHERE trigger_body LIKE '% UPDA % CASE % ';
Error
ORA-00932: inconsistent data types: expected NUMBER got LONG
00932 00000 - ' incompatible data types: wait %s %s got. "
* Cause:
* Action:
Error on line: column 2: 7
Concerning
Muzz
Adrian Billington wrote to the top of your options.
-
How to install components of the operations on files in Data Integrator
Hello short Forum,
I am interested in the use of the components of operations on files in Data Integrator, but get and install them are amazingly obscure.
I want to talk...
http://doc.cloveretl.com/documentation/Userguide/index.jsp?topic=/com.cloveretl.GUI.docs/docs/file-operations.html
The States of documentation (http://doc.cloveretl.com/documentation/UserGuide/index.jsp?topic=/com.cloveretl.gui.docs/docs/components.html) clover...
"+ Note if you do not see this component category, go to window → Preferences → CloverETL → components in the Palette and tick the two boxes next to file operations.
However, when I go to window-> Preferences-> CloverETL-> components in the Palette, I can't even file operations. It tells me that the version of clover packed with OEID is not installed components.
Going to help-> check for updates also give nothing that resembled components file operations.
I hope that someone here are familiar with the steps necessary to get these installed components...
Thank you
JeromeHi Jerome,
CloverETL documentation that you are talking about is their latest version: CloverETL 3.3.0. If you go to the first page of the documentation, you will see the following note:
"This Guide refers to the version 3.3.x CloverETL Designer."The integrator in EID 2.3.0 does not rely on CloverETL 3.3.x, it is based on CloverETL 3.2.x. Please use the documentation on this page for the Integrator:
http://docs.Oracle.com/CD/E29805_01/index.htmBest,
Laureline. -
My C drive (disk solid state drive), which held my operating system and data from the app crashed. I had it replaced, updated Win 7 to win 10 and have downloaded Firefox. I was able to restore my profile from a Mozy backup data and copied in the Firefox folder. But Firefox resolutely refuses to recognize. I tried using the recovery data from an old profile, but no advantage help page. Tried to use the Manager profile, but without success. When I go to Troubleshooting Information and click on file/Show profile, it comes up with a list of files (files starting with bookmarkbackups, which however is empty, down for webapps, which has the file inside webapps.json), then the files from addons.json down through xulstore.json and the file places.sqlite is 10 240 KB Although there is something in there, but Firefox resolutely refuses to acknowledge my profile, bookmarks, etc..
I'm out of options and ripping my hair out trying to get all my favorites, in which I have a lot of information such as the authentication of data for many favorite sites. It is frustrating that all the information seems to be there, but Firefox ignore all.
Can anyone help?
Such a backup is perhaps a ZIP archive containing all the files into it if it is not a real file, but only one file.
Note is that you replace the file places.sqlite with a copy of the backup that you have to make sure to remove existing places.sqlite - shm and temporary files to SQLite places.sqlite - wal.
Ditto for the other SQLite files that you are restoring.Have you checked the application.ini file in the backup?
-
between operator to group by date in the Apex of the interactive reports
Hello
In the filter of interactive reports, I could not find the "between" for the date field (got a "group by date" in my (source) sql query.) I wonder, is - this in view of the group by clause date?. Is there a way to show the operator "between" in the interactive reports filter.
Thank youI just opened an existing style IR report, went to the actions, filter, selected a date column and found at the bottom of the list of values... Are you sure of the date that you want to filter on is a real date column?
Thank you
Tony Miller
Webster, TXWhat happens if you were really stalking a paranoid schizophrenic... They would know?
If you answer this question, please mark the thread as closed and give points where won...
-
operator case where clause date comparison
Hi can please help for query teas comparsion date based on requirements is
I could use decode in the application to manage the two scenarios (decode orig enrl
to date, if < = 12/01/15 then use 1/12/15 + 25 as the date for comparison, otherwise use
date enrl orig + 25
can u help for these
tried to decode also
/ * AND
To_date (get_attr_usage_val (7599,docr.org_prog_cam_recipient_id),'MM/DD/YYYY') < =)
Decode (to_date('01/12/2015','MM/DD/YYYY'),
TO_DATE (JANUARY 12, 2015 "," MM/DD/YYYY "") + 25,.
To_date (get_attr_usage_val (7599,docr.org_prog_cam_recipient_id),'MM/DD/YYYY'))
*/
Sorry for the delay to ask, thank you very much for the reply
in above query
It's feature column used to join date: (trunc (sysdate) - TO_DATE (get_attr_usage_val (7599,docr.org_prog_cam_recipient_id),'MM/DD/YYYY')))
AND if (trunc (sysdate) - TO_DATE (get_attr_usage_val (7599,docr.org_prog_cam_recipient_id),'MM/DD/YYYY')))<= to_date('01/12/2015','mm/dd/yyyy')="">
TO_DATE (JANUARY 12, 2015 "," MM/DD/YYYY "") + 25
another (trunc (sysdate) - TO_DATE (get_attr_usage_val (7599,docr.org_prog_cam_recipient_id),'MM/DD/YYYY'))+25
end if
for example: 1) the enrollmentdate value function
(1) If a patient registered on 01/04/2015 then wait 25 days from 12/01/2015 which 06/02/2015 before creating the event would provide that all other conditions are met.
(2) If a registered on 13/01/2015 patient can expect 25 days from the date of registration which would be 07/02/2015 before creating the event provided that all other conditions are met
AND ((TO_DATE (get_attr_usage (7599,docr.org_prog_cam),'MM/DD/YYYY'))))<=TO_DATE('01>
AND
To_date (get_attr_usage (7599,docr.org_prog_cam),'MM/DD/YYYY'))<=>
)
or
(TO_DATE (get_attr_usage (7599,docr.org_prog_cam),'MM/DD/YYYY')>TO_DATE('01/12/15','MM/DD/YYYY')))
AND
To_date (get_attr_usage (7599,docr.org_prog_cam),'MM/DD/YYYY')+25 > trunc (sysdate)))
) )
Thank you
-
VMDK of 1 or 2 for operating system drives and data
What do most people with data disks and OS? In other words, you use 1 vmdk for vmdk OS and a 2nd for data readers? This would create 2 connections to the data store or just 1?
We use a separate for any drive. If you ever want to enlarge a partition makes it so much easier. As long as you keep all your .vmdks of the guest (s) in question, on the same LUN there will be only one connection.
-
Audio/video/bbm BBM works not because the new operating system up-to-date
When I updated my phone yesterday and I try to resonate on bbm voice or video, nothing happens. If someone rings me on BBM it doesn't let me answer--says something about the network connection lost, unable to connect call.
Hello! I would like to know if the following article helps

KB36633 impossible to place a voice call or video BBM after upgrade to BlackBerry 10 OS version 10.3.1
http://www.BlackBerry.com/BTSC/KB36633Thank you!
-
* URGENT * please help me! -DATA
My IPhone is stuck on just restart the Apple Logo and I have a lot of valubable very inforumation and median for me there, and I need a top backup immediately. The only thing I can access this topic is DFU mode and recovery mode.
Sure that no backup will be possible now. Recovery and DFU mode can get you operational, but without your data back.
Before a planned or unforeseen events is at this time to make a backup.
-
RND4000 - change the hard disks, will that erases data on older players
I took out the old records and set it asside.
Then put in some different readers. Different drives are from a NAS RNDX4000 and they initialize automatically.
I wasn't expecting that.
Now, if I take on different disks and put the old disks in will I lose all the data?
I need to still get the data on the old disks. They worked very well.
I don't want them to be initalized.
The reason is that the RNDX4000 was struck by lightning. Really wanted to get information out of thoes readers. Now, I don't want to lose the information I had in RND4000 work.
OS 4.x ReadyNAS all begin with the formatting of disks when they are hot-inserted and in many cases even when they are not hot-inserted.
But if you turn off, insert the old disks in their original locations, and then powered on, then the system should simply repeat the operation without loss of data or reformatting.
-
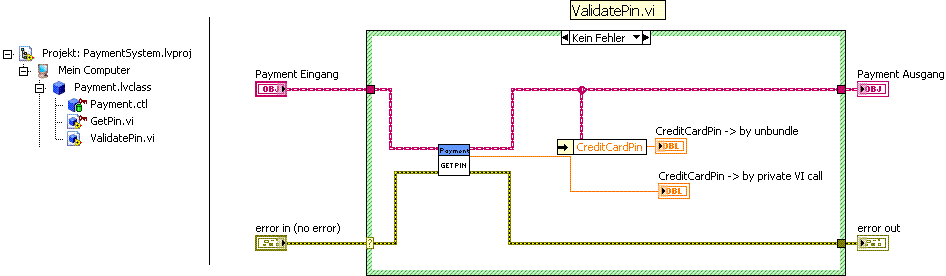
LV OOP using accessor (subVIs) or operation bundle/unbundle methods?
Hello
When should I use the (private) (subVIs) accessor methods and when the bundle/unbundle the operation to access the data of the class? What is the reason that the operation bundle/unbundle is introduced in LabVIEW OOP? I need some rules for a codification of the directive.
Thank you
Thanks for your advice. I wanted to understand the differences between a private access vi and unbundle operation as in the picture.
I found a few more explanations on the website: http://www.ni.com/white-paper/3574/en
-> ' Methods 'Read' and 'write' for each data value in a class is a recognized process as being bulky. " LabVIEW 8.5 introduced the ability to create the screw accessor in a dialog Wizard and LV2009 added to other options in this dialog box.
We were concerned about the performance overhead to a Subvi call instead of unbundling just data. We found that our general fees current compiler for the Subvi call is insignificant (measured between 6 and 10 microseconds on average PC). A bundle/unbundle directly on the appellant VI compared to a Subvi is almost the same amount of time. We have a problem with copies of data for unbundled components because a large part of the LabVIEW inplaceness algorithm does not work beyond the limits of the Subvi. To work around the problem, you can also choose to avoid the accessor methods for methods that perform work in the Subvi to avoid returning the Subvi elements, thus avoiding copies of data. This choice is often better OO design anyway, because it avoids exposing the implementation private to a class as part of its public API. In future versions, I bet that this feature of subVIs will become possible, which will eliminate the overhead entirely.
We feel in the long run it is better to improve the experience of the editor and the efficiency of the compiler for these screws rather than introduce data public/protected/community. »
-
Applications for registration of data is not juggling
I have an application that is reading data of a ring memory reflective and then written to a RAID (NI 826 x) in a PXI chassis. The application must read and write 5 separate data streams, 3-1at 20 Hz and 1 to 10 Hz 100 Hz. LV 8.61 using on a regular PXI chassis. Currently, the application has a separate loop for each stream of data to be read from reflective memory and a separate loop for each stream of data to write to the disk. The app works very well but from time to time (3 to 4 times in a two hour period), the loops that read stall reflective memory momentarily and as a result, data are lost. The rings of memory are such that for flows of 100 Hz, the memory must be read at least once every second (100 elements of the ring). An approximation of the time loop is usually a little more than a second. When the reference of the elements in the ring has been set at 50, the time of the 'fail' loop was a little more than 500 ms (do not understand this). I use a file regular write to write to the disk. In a system not real time is this normal? Can it be prevented?
Any input appreciated.
Thank you
Craig
It has been many years, but I remember a problem with a RAID controller and "written" in an industrial PC.
I was running under Windows XP operating system, by using the provider-specific triggers. I ended up adding the 'File Flush' function. I don't remember if I called him every time, or if it were every n-th iteration of the loop of Scripture (quotient and remainder function).
http://zone.NI.com/reference/en-XX/help/371361E-01/Glang/flush_file/
"This function forces the operating system to write data from the buffer to the file."
-
Hello
I have a dynamic function DLL acting as a data source within a LabVIEW application (see attachment) - I use DSNewHandle to dynamically allocate an array 2D handle storage via the Manager memory LV for arrays of arbitrary in application size data. I had assumed that these blocks of memory would be willing (Magic) when appropriate by the LabVIEW built in blocks that are sitting downstream, however, is not the case for treatment and the system LabVIEW memory usage continues to increase until you quit LabVIEW environment (not just if the offending application is stopped or closed).
So my question is how and where to mop up the table used for buffers in the treatment of the application of the chain and how do I know when the buffers are really exhausted and not be re-used downstream (for instance two 2D paintings are first grouped into a 2D complex table by the re + im at the operator complex labview - is data memory out of this totally different stage of entries or is - a) modified version of the entry tables - if they are totally different and 2D to entry tables are not wired in all other blocks why the operator not have input data banks?)
Maybe Im going to this topic in the wrong direction have the DLL data source dynamically allocates space data tables? Any advice would be welcome
Concerning
Steve
So instead of doing:
DLLEXPORT int32_t DataGetFloatDll(... , Array2DFloat ***p_samples_2d_i, ...) { ... if ( p_samples_2d_i ) { // *p_samples_2d_i can be non NULL, because of performance optimization where LabVIEW will pass in the same handle // that you returned in a previous call from this function, unless some other LabVIEW diagram took ownership of the handle. // Your C code can't really take ownership of the handle, it owns the handle for the duration of the function call and either // has to pass it back or deallocate it (and if you deallocate it you better NULL out the handle before returning from the // function or return a different newly allocated handle. A NULL handle for an array is valid and treated as empty array. *p_samples_2d_i = (Array2DFloat **) DSNewHandle( ( sizeof(int32_t) * 2 ) + ( sizeof(float) * channel_count * sample_count ) ); // Generally you should first try to insert the data into the array before adjusting the size // the most safe would be to adjust the size after filling in the data if the array gets bigger in respect to the passed in array // and do the opposite if the adjusted handle happened to get smaller. This is only really important though if your C code can // bail out of the code path because of error conditions between adjusting the handle size and adjusting the array sizes. // You should definitely avoid to return from this function with the array dimensions indicating a bigger size than what the // handle really is allocated for, which can happen if the array was resized to a smaller size and you then return because of errors // before adjusting the dimension sizes in the array. ........ (**p_samples_2d_i)->Rows = channel_count; (**p_samples_2d_i)->Columns = sample_count; } ...}You should do:
DLLEXPORT int32_t DataGetFloatDll(... , Array2DFloat ***p_samples_2d_i, ...) { ... MgErr err = NumericArrayResize(fS /* array of singles */, 2 /* number of dims */, (UHandle*)p_samples_2d_i, channel_count * sample_count); if (!err) { // Fill in the data somehow ..... // Adjust the dimension sizes (**p_samples_2d_i)->Rows = channel_count; (**p_samples_2d_i)->Columns = sample_count; } ...} -
The most effective way to log data and read simultaneously (DAQmx, PDM) high data rates
Hello
I want to acquire the data of several Modules cDAQ using several chassis to
high data rates (100 k samples per second if possible). Let's say the measurement time is 10 minutes and we got a large number of channels (40 for example). The measured data is written to a PDM file. I guess, the memory or the HARD disk speed is the limits. For the user, there must be a possibility to view the selection of channels in a graph during the measurement.My question: what is the best and most effective way to save and read data at the same time?
First of all, I use an architecture of producer-consumer and I don't want to write and display the data in the same loop. I expect two possibilities:
[1] to use the 'DAQmx configure logging.vi' with the operation 'journal and read' to write the data to a PDM file. To display the data in a second loop, I would create a DVR samples documented and 'sent' the DVR for the second loop, where the data will be displayed in a graph (data value reference). This method has the disadvantage that the data of all channels is copied into memory. Correct me if I'm wrong.
[2] use 'DAQmx configure logging.vi', but only with the "journal" operation to write the data to a PDM file. To view the selected data, I had read a number of samples of the TDMS file in the second loop (I'm currently writing the TDMS file). In this case, I have only one copy data from the selected channels (not), but there will be more HARD drive accesses necessary.
What is the most effective and efficient solution in this case?
Are there ways to connect and read data with high frequencies of sampling?
Thank you for your help.
You say that the measurement time is 10 minutes. If you have 40 channels and you enjoy all CHs at 100 kHz, it is quite a number of values.
In this case, I always try to approach under the conditions of use. If a measure is only 10 minutes, I just connect all PDM data and create a graphic module that could be in the same loop of consumers where connect you the data. You can always work on the raw data files big offline afterwards, the extraction of all the information you need (have a look at the product called NI DIAdem: http://www.ni.com/diadem/)
The main issue is that the user needs to see in the graph (or perhaps a chart can be useful too). Lets say that the graph is 1024 pixels wide. It makes no sense to show multiple data to 1024 points, Yes? Every second will produce you 100 data points k per channel. What is the useful information, which should see your username? It depends on the application. In similar cases, I usually use some kind of data reduction method: I use a moving average (Point by point Mean.VI for example) with a size of the interval of 100. This way you get 100 data points of 1000 per channel every second. If you feed your graph every second with these average values, it will be able to data points in 1024 of the store (as a default) by channel (curve), which is a little more than 10 minutes, so that the user will see the entire measurement.
So it depends on the frequency at which you send data to the consumer. For example, collect you values 1024 by iteration of the producer and send it to the consumer. Here you can make a normal means calc or a bearing (according to your needs) and he draw a graphic. This way your chart will display only the values of the last 10 seconds...
Once I programmed some kind of module where I use a chart and not a graph, and the user can specify the interval of the absolute timestamp that is traced. If the data size is larger than the size of the chart in pixels, the module performs an average calculation in order to reduce the number of data points. Of course, if you need to see the raw data, you can specify an interval that is small. It all depends on how you program zoom functions, etc... In my case I hade a rate of 1 Hz, so I just kept all data in RAM limiting the berries to keep 24 hours of data, so that technicians could monitor the system. In your case, given the enormous amount of data, only a file read/write approach can work, if you really need access to all of the RAW data on the fly. But I hope that the values of working capital means will be enough?
-
The embedded controller (EC) data returned when none was requested. (T420s)
Everyone sees this warring newspaper system running Windows 8 or Windows Server 2012?
: The embedded controller (EC) data returned when none was requested. The BIOS may try to access the European Community without synchronization with the operating system. These data will be ignored. No further action is necessary; However, you should check with the manufacturer of your computer for an updated BIOS.
Should I just ignore it?
Concerning
Anders Jensen
This message normally appears permanently, if TPFanControl or PFControl is installed and the start-programs-TPFanControl-optional-acpiecnl was not used to disable logging these events...
Maybe you are looking for
-
The printer CP6015 stop printing when the fuser unit reaches its end of life suggested 100,000 copies or wil the machine continues to run with the message "change the fuser unit?
-
Satellite Pro P300-1CH and drivers for Vista64
Hello. Where can I find the drivers for my new P300-1CH for Vista x 64? I searched for them on this web page, but I've only had the 32-bit drivers. Is it possible that Toshiba does not supply these drivers even if they exist? I can, for example, down
-
Hi all I was wondering if it is possible to create an executable file, so that I don't have to actually install on another computer, but just being able to run it via CD, DVD or any external drive. Concerning
-
T61p drivers on Windows 7 (64-bit)
Hello I want to upgrade my laptop to Windows 7 (64-bit) Windows XP I use (instead of slow Vista) is old enough (and only 32-bit). I found there is no drivers for a lot of thing (tried the system update, but it downloaded only a few drivers). Finally
-
Wireless does radio not fuctioning help
any help please