Organize my library - best practices
I'm getting used to the way iTunes works to organize things and I would like to get your thoughts and ideas on what I came with. I would like to have the option checked in the preferences to keep my music organized folder (although this caused a problem with the audio books I ripped CD). Please check if the following is correct:
- For simple of artists and Albums, each song file must have the artist name under name of artist and artist of the Album. Then the name of the Album should be the same in each file. This will display in this hierarchy in the interface of iTunes and the music files
- When it comes to albums with more than one artist, I saw (in the iTunes interface) iTunes put them under Compilations, Soundtrack and various artists. But it always corresponds to the underlying files. So that's what I did:
- If it's really a soundtrack, I often find the artist of the Album to be "Soundtrack" and the "Compilation" checked. This places the album under Soundtrack in iTunes and in the case of Compilations in the music folder. In these cases, I just remove the check mark.
- If it is a compilation which is not a soundtrack, I do the artist of the Album "Compilations" and check the box. This creates a record of Compilations in the iTunes interface and stores the files in the folder of Compilations.
- So far I don't see the need for a 'various artists folder - this seems redundant.
Is that all that I'm missing? For example, there is an album of an artist, where all the songs, but a list of this artist. However this song lists the artist as well as another. In the past, iTunes share this one song on another. Can I keep the artist Album is identical for all the songs so that they are all in the same place but this other artist as a "artist contributing ' to the list?
So that's how I do it now. Any thoughts, all that I'm missing? Care to share how to do this if it is different? (my concern is that this can work very well for music, but once I start to add podcasts or audio books, that the system may fail). Thank you.
For simple of artists and Albums, each song file must have the artist name under name of artist and artist of the Album. Then the name of the Album should be the same in each file. This will display in this hierarchy in the interface of iTunes and the music files
For these cases, it is not necessary fill The Album artist as an artist, although he won't be a problem to do so.
When it comes to albums with more than one artist, I saw (in the iTunes interface) iTunes put them under Compilations, Soundtrack and various artists. But it always corresponds to the underlying files. So that's what I did:
- If it's really a soundtrack, I often find the artist of the Album to be "Soundtrack" and the "Compilation" checked. This places the album under Soundtrack in iTunes and in the case of Compilations in the music folder. In these cases, I just remove the check mark.
The flag of "the Album is a compilation... "is redundant functionality with the setting of a common value of the Album artist , because both will include albums with titles related to different artists. However, the use of the flag "the Album is a compilation...". ' is required if you have an iPod Classic or other model older iPod that does not support the Album artist tag. As you have noted, the indicator "Album is a compilation...". "affects where iTunes stores media files:
- If the flag is set, the files will be stored in iTunes\iTunes Media\Music\Compilations\album_title
- If the flag is not set, the files will be stored in iTunes\iTunes Media\Music\album_artist\album_title
If it is a compilation which is not a soundtrack, I do the artist of the Album "Compilations" and check the box. This creates a record of Compilations in the iTunes interface and stores the files in the folder of Compilations.
With this value in The Album artist albums will be placed in iTunes\iTunes Media\Music\Compilations\album_title if the flag is set or not (although its actually the indicator that determines the consumption of this issue, since in this case any value in Album artist is ignored in the determination of folder names).
So far I don't see the need for a 'various artists folder - this seems redundant.
Files of the form iTunes\iTunes Media\Music\Compilations\album_title will be created and used for albums where:
- The flag of "the Album is a compilation... ' is not defined, and
- the value of the Album artist is set to "Various Artists"
-This isn't a 'standard' as the Compilations one iTunes folder.
For example, there is an album of an artist, where all the songs, but a list of this artist. However this song lists the artist as well as another. In the past, iTunes share this one song on another. Can I keep the artist Album is identical for all the songs so that they are all in the same place but this other artist as a "artist contributing ' to the list?
In this case, I put the value of The Album artist to that of the 'main' artist and add all the names of "guest artist" in the field of the artist on individual tracks. Note, however, that it is common practice in digital downloads and (in some cases) the database GraceNote used to search for names of tracks on CD, to add the value "guest artist" in the name of the song... which for me is not good, so I've always updated metadata for this move in the artist field.
So that's how I do it now. Any thoughts, all that I'm missing? Care to share how to do this if it is different? (my concern is that this can work very well for music, but once I start to add podcasts or audio books, that the system may fail). Thank you.
You approach seems fine - as long as you get the results there no way to 'straight' or 'bad '. My standard approach is:
- complete The Album artist only when securities have different values of artist
- to all compilations, set the value of the Album artist to "Various Artists"
- never set the flag of "the Album is a compilation... »
- I treat soundtracks differently, but if I did I would probably put the Genre tag "Soundtrack" and create a smart playlist to collect together, given that many BO have a single artist or composer (for example, I have the various soundtracks of 'Star Wars' with the artist, the value John Williams).
These are then combined with a consistent method to set the tags of the kind the artist and Album comes out :

more an approach somewhat esoteric set up the tag of The Album fate on a combination of the most important of the four listed above, tags more release of album in the yyyymmdd format - date to ensure that records are classified by chronological order when an artist has even several films a year (see How can I sort the albums of the same year in iTunes music? for an example).
I don't know how it would affect the podcasts, but generally the same principles should apply to audiobooks in iTunes - note, however, that there is a big difference in the way that different iDevices manage audiobooks - especially for those who use a format of audio book dedicated such as .m4b files in the iTunes Store or .aa from Audible files.
Tags: iTunes
Similar Questions
-
What is the best practice to move an image from one library to another library
What is the best practice to move an image from a photo library to another library of Photos ?
Right now, I just export an image on the desktop, then remove the image from Photos. Then, I open the other library and import these images from the office in Photos.
Is there a better way?
Yes -PowerPhotos is a better way to move images
LN
-
Best practices of VCO - combination of workflow
I took a modular approach to a task, I am trying to accomplish in VCO. I want to take action against the network to ANY NAT routed ORG in a specified org. Here is where I am now. Would like to comment on what is possible or recommended before you start down the wrong path. I have two separate workflows individually do what I need to do and now I need to combine them. Two of these workflows work well separately and I am now ready to combine both in a single workflow.

(1) with the help on this forum of Joerg, I was able to return all ORG networks in a particular ORG, then filters according to the fenced mode return array ONLY NAT network routed ORG. Name of the workflow is «Routed BACK ORG nets» The input parameter is an organization, and the output parameter is an array of NAT routed networks ORG.

2) there is an existing workflow (comes with the VCD 1.5 plugin) that configures a routed NAT ORG network. The input parameter is a routed Org network of NAT. name of the workflow is 'Routed SECURE ORG Net' and I would like to use this (slightly modified) workflow as it is perfect for a task I need to fill.

I think there are two options.
(1) to include javascript code and the logic of the 'SECURE Ext ORG' which has several elements in the workflow in the workflow for "Nets of ORG routed BACK" Net inside the loop of the search RETURN flow.
(2) the second option is to add the 'SECURE routed ORG Net' as part of workflow for existing workflow "Nets of ORG routed RETURN" as part of workflow. I like this approach better because it allows me to keep them separate and reuse elements of the workflow or individually.
Issues related to the:
What is recommended?
Y thre restrictions on what I can pass as an INPUT to the second workflow (embedded) parameter? Can I pass only the JavaScript object references or can I get through an array of '.name' routed networks NAT ORG property in the table?
I assume that the input parameters for the second workflow can be invited in the first and passed as OUTPUT to the second workflow (embedded) where they will be mapped as INPUT?
I read through the developer's guide, but I wanted to get your comments here also.
Hello!
A good principle (from software engineering) is DRY: don't repeat yourself!
So call to a workflow library indeed seems to be the best approach for the majority of use cases. (So you don't have to worry about maintaining the logic, if something changes in the next version,...) That's exactly what the workflow library is for.
To move objects to a workflow item, you can use all the inventory items, basic (such as boolean, string, number) and generic data types ones (all, properties). Each of them can also be an array.
However, the type must adapt to the input of the called Workflow parameter (or be "ANY").
So in your case, I guess that the COURSE called...-Workflow is waiting for just a single network (perhaps by his name, probably also OrgNetwork).
You must create the logic of loop to go through all the networks you want to reconfigure manually (in your "external" workflow).
For an example: see http://www.vcoteam.info/learn-vco/creating-workflow-loops.html
And as Tip: the developer's Guide is unfortunately not really useful for this "methodology" - related issues. See the examples on http://www.vcoteam.info , the beautiful videos on youtube ( http://www.vcoportal.de/2011/11/getting-started-with-workflow-development/ ) and watch the recording of our session at VMworld: http://www.vcoportal.de/2011/10/workflow-development-best-practices/ (audio recording is in the post in mp3 format)
See you soon,.
Joerg
-
Code/sequence TestStand sharing best practices?
I am the architect for a project that uses TestStand, Switch Executive and LabVIEW code modules to control automated on a certain number of USE that we do.
It's my first time using TestStand and I want to adopt the best practices of software allowing sharing between my other software engineers who each will be responsible to create scripts of TestStand for one of the DUT single a lot of code. I've identified some 'functions' which will be common across all UUT like connecting two points on our switching matrix and then take a measure of tension with our EMS to check if it meets the limits.
The gist of my question is which is the version of TestStand to a LabVIEW library for sequence calls?
Right now what I did is to create these sequences Commons/generic settings and placed in their own sequence called "Functions.seq" common file as a pseduo library. This "Common Functions.seq" file is never intended to be run as a script itself, rather the sequences inside are put in by another top-level sequence that is unique to one of our DUT.
Is this a good practice or is there a better way to compartmentalize the calls of common sequence?
It seems that you are doing it correctly. I always remove MainSequence out there too, it will trigger an error if they try to run it with a model. You can also access the properties of file sequence and disassociate from any model.
I always equate a sequence on a vi and a sequence for a lvlib file. In this case, a step is a node in the diagram and local variables are son.
They just need to include this library of sequence files in their construction (and all of its dependencies).
Hope this helps,
-
best practices to increase the speed of image processing
Are there best practices for effective image processing so that will improve the overall speed of the performance? I have a need to do near real-time image processing real (threshold, filtering, analysis of the particle/cleaning and measures) at 10 frames per second. So far I am not satisfied with the length of my cycle so I wonder if he has documented ways to speed up performance.
Hello
IMAQdx is only the pilot, it is not directly related to the image processing IMAQ is the library of the vision. This function allows you to use multi-hearts on IMAQ function, to decrease the time of treatment, Arce image processing is the longest task for your computer.
Concerning
-
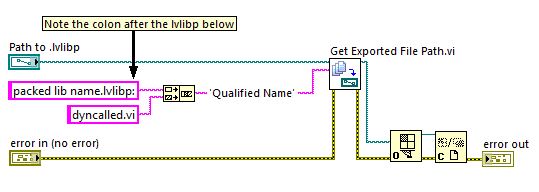
Best practices - dynamic distribution of VI with LV2011
I'm the code distribution which consists of a main program that calls existing (and future) vi dynamically, but one at a time. Dynamics called vi have no input or output terminals. They run one at a time, in a subgroup of experts in the main program. The main program must maintain a reference to the vi loaded dynamically, so it can be sure that the dyn. responsible VI has stopped completely before unloading the call a replacement vi. These vi do not use shared or global variables, but may have a few vi together with the main program (it would be OK to duplicate these in the version of vi).
In this context, what are best practices these days to release dynamically load of vi (and their dependants)?
If I use a library of project (.lvlib), it seems that I have to first build an .exe that contains the top-level VI (that dynamically load), so that a separate .lvlib can be generated which includes their dependencies. The content of this .lvlib and a .lvlib containing the top-level VI can be merged to create a single .lvlib, and then a packed library can be generated for distribution with the main .exe.
This seems much too involved (but necessary)?
My goal is to have a .exe for the main program and another structure containing the VI called dynamically and their dependents. It seemed so straighforward when an .exe was really a .llb a few years ago

Thanks in advance for your comments.
Continue the conversation with me
here is the solution:Runs like a champ. All dependencies are contained in the packed library and the dynamic call works fine.
-
Best practices for color use in Adobe CC?
Hi all
Is there an article that describes the best practices for use of color in Adobe CC?
I produce a mixture of viewing online (PDF, for the most part) and real world print projects - often with the obligation for both. I recently updated my PANTONE + bridge books for the first time in ages and I am suddenly confused by the use of Lab colors in the Adobe Suite (Illustrator and InDesign).
Everything I found online, looks like Lab color mode preferred to use because it is device independent. And perceptual (on screen), it looks much closer to the color, it is trying to represent. But when I mark a Spot color Illustrator rectangle using laboratory coordinates, to the sides of a rectangle using PANTONE + bridge CP and then export it to PDF, the version of CP to mix CMYK color corresponds exactly to my Pantone book - while the version of laboratory (after converted to CMYK using the ink Manager) is far away.
I have this fantasy to manage only a single Illustrator or InDesign file for both worlds (PDF) printed and online. Is not possible in practice?
Any info describing the basic definitions of the color modes - or even a book tracing more than use them in the real world - would be much appreciated!
Thank you
Bob
Here are a few best practices you can already do.
1 make sure that your color settings are synchronized on all applications.
2. use a CMYK profile appropriate for your print output. Lab spot colors convert to CMYK values based on the CMYK icc profile.
3. include icc profiles when save or export pdf files
In theory, your imagination is possible today. It requires color management and the use of icc profiles. You can place RGB images in InDesign and use Pantone colors in your objects. The problem lies in the printers. If a printer uses a RIP with built in Pantone library, the colors will match when printing. Unfortunately, this kind of CUT is more expensive and not enough printers use them. Most of them is always manually approximate CMYK values composition given Pantone colors.
-
We have companies everything changed at some point in our lives. And we all go through the process in the first weeks, where you feel new and are just trying to figure out how not to get lost on your way in the mornings.
On top of that, trying to familiarize yourself with your new company Eloqua instance can be a daunting task, especially if it's a large organization.
What are the best practices for new employees to learn as efficiently and effectively as possible?
I am in this situation right now. Moved to a much larger organization. It is a huge task trying to understand all the ins and outs not only society, but also of the eloqua instance, especially when she is complex with many points of integration. I find that most of the learning happens when I really go do the work. I spent a ton of time going through the programs, documentation, integrations, etc., but after awhile, it's all just words on a page and not absorbed.
The biggest thing that I recommend is to learn how and why things are made the way they are currently, ask lots of questions, don't assume not that things work the same as they did with your previous employer.
Download some base in place level benchmarks to demonstrate additional improvement.
Make a list of tasks in the long term. As a new pair of eyes, make a list of things you'd like to improve.
-
Best practices for building an infrastructure of APEX for 12 c
Hi all
Have we not the docs on best practices for building an infrastructure of APEX?
Which means, for the production, it is acceptable to use Embedded PL as the listener, or we stick with the Listenr tested on Weblogic?
Thank you
Hi JCGO,.
JCGO wrote:
Hi all
Have we not the docs on best practices for building an infrastructure of APEX?
Which means, for the production, it is acceptable to use Embedded PL as the listener, or we stick with the Listenr tested on Weblogic?
Thank you
I agree with Scott's response '' it depends. '' It starts with the appropriate choice of a web listening port.
You should discourage use EPG facility based in Production environments in accordance with the recommendation of the Oracle.
Reference: See security considerations when you use the Embedded PL/SQL Gateway section.
ADR (APEX Listener) + Oracle Weblogic Server sounds good, if you already have tried and have appropriate expertise to manage it.
Also, you might consider what other facilities ADR based ADR + Apache Tomcat with Apache HTTP Server reverse proxy as described here:
But it depends on Apache skills, you have within your organization.
I hope this helps!
Kind regards
Kiran
-
Design by using NetApp's best practices
I am preparing for my VCP5 and I read the new book by Scott Lowe. the book describes how the traffic should be isolated. your vMotion, vmkernal, etc., but in many organizations, I see the NetApp with some of data warehouses and a few LUNS to CIFS share LUNS. I guess you can have your vmMotion on a VLAN separated, but would not safer just configure a windows VM file server to host your files? In freenas and openfiler forums, they stress is not to run their software in virtual machines in a production environment. Physical separation would be better then just a VLAN? I was inking and correct me if I'm wrong. I think the CIFS shares in a virtual hosting machine would SAN, vMotion, vmkernal, most reliable if you have redundant switches on both sides VMware hosts. So if your kernel switches drop your vmware environment will not drop.
> traffic must be isolated.
Yes, the network traffic must be split on networks separated for various reasons, including performance and safety.
> NetApps with MON a few for data warehouses and a few LUNS to CIFS share.
Yes, if you have a NetApp file server you can block-level storage server as FCP or iSCSI, CIFS or NFS file-level storage.
> I guess you can have your vmMotion on a VLAN separated, but would not safer just configure a windows VM file server to host your files?
OK, you lost me. Yes, you must separate the vMotion traffic to enhance the performance and because the vMotion traffic is not encrypted.
I don't see where you're going for vMotion to a Windows file server?
However, if you are referring to, why don't you your NetApp instead of Windows CIFS Server:
You don't need to patch and reboot the NetApp at least once a month.
Performance is better
You don't need to buy a Windows license and then maintain Windows
Snapshots. NetApp has the best shots in the business. When your Windows I/O high, or just typing box because it of Tuesday and removes all of your VSS snapshots you really wish you had a NetApp.
> In the forums of freenas and openfiler, they stress is not to run their software in virtual machines in a production environment.
Note that there are a ton of storage there equipment running as VMs and server NFS for shared storage, including left and they have been stable for years.
> Physical separation would be better then just a VLAN?
Yes, if you have the infrastructure. When it comes to the first time I've seen reference you VLAN? Are you talking about now the NetApp as the series 2020 with two network cards where you need to carry all traffic (managent, CIFS and iSCSI) through them via VLAN?
Like this: http://sostechblog.com/2012/01/08/netapp-fas2xxx-fas3xxx-2-nic-ethernet-scheme/
> I was inking and correct me if I'm wrong. I think the CIFS shares in a virtual hosting machine would SAN, vMotion, vmkernal, most reliable
CIFS is nothting to do with SAN, vMotion or VMkernel. CIFS (SMB) is the protocol used mainly by Windows file sharing
> If you have redundant switches on both sides of the VMware hosts. So if your kernel switches drop your vmware environment will not drop.
You always want to redundant switches. No single point of failure is the best practice.
-
Big 2 TB + vm - what is the best practice?
Hello
Our file server currently uses the measure with a total area of 4 to DS. The virtual machine contains 11 vDisks with sizes ranging from 50 GB to 1.35 to totaling 3.8 TB of data. each vDisk belongs to a division within the company. We are running out of space on the DS, and we need to make changes.
I did read something positive on the use of measurement other than for a short fix.
Question: What are the best practices to go forward get rid us of the widespread use, it has been suggested, we look at DFS or perhaps a new virtual machine intended only for the major divisions.
If we add a new disk and that it points to an another DS on it's own logic unit number, we run into the trouble of storage vMotion, try to group the disc under a store.
I'm sure that there are large organizations out there running in this situation, any guidance is appreciated!
See you soon
Brendan
If you need a file server, that SFR might be a solution.
You can use vmdk as well on the same VM, or more file servers.
For other purposes, you can use the junction to mount a drive in a folder.
André
-
Roles, permissions - DataCenter, file, Cluster, host Layout - best Practices\How-to
Have a little problem with permissions and roles. I'm sure it will be an easy one for those of you with more experience of working with roles. I hope that my layout organization made with quote boxes is readable.
The Organization has just spun a new host ESXi 4 for developers and added in vCenter. Developers want to use the vSphere Client\VIC to manage the ESX Server. They need rights to create virtual machines, remove VMs, clone VMs, VMs potential power. However, we don't want them to be able to reach production.
According to the diagram below, the new host of development, labeled as "HostC (autonomous DEVELOPMENT host)", is located under "Data Center-City-2", who also owns the production ESX clusters. " And obviously I don't want developers having rights on production groups.
Lets say I have create a role called 'HostC Dev Sandbox Rights', add users and assign directly to "HostC" below. This role contains the VM 'create' right, however when I run the wizard Creation of VM of HostC as a member of the role the vSphere Client tells me this task requires rights create VM on the level of data center! But given these developers to create VMS access on the data center would give them rights to create virtual machines in the poles of Production! Which is obviously a problem.
I can't believe that our need to give these rights to ONLY one host in a DataCenter is rare. I don't know that there is a misunderstanding on my part of how to configure VMware roles for best practices.
Anyone with more expirence on VMware roles ready to help me on this one? Thanks in advance!
Organization representative Schema using quote boxes:
vSphere (vCenter Server)
City of DataCenter-1
Many cases, clusters, hosts
City of DataCenter-2
FolderA (Division A)
ClusterA (A Cluster of Production)
HostA1 (Production host in Group A)
HostA2 (Production host in Group A)
%Windir%$NTUninstallKB941568_DX8$\Spuninstb (division B)
Focus (Production Cluster B)
HostB1 (Production host in Group B)
HostB2 (Production host in Group B)
HostC (autonomous DEVELOPMENT host) - under %windir%$NTUninstallKB941568_DX8$\Spuninstb but not in the cluster
City Center-3
Many cases, clusters, hosts
You can apply permissions directly to the data store. I didn't need to go further than the clusters in our environment, but what really works for you is to place data warehouses in folders for storage. Have the records be the names of your groups hosts and clusters. Then place the warehouses of data for each cluster in the corresponding folder. Then, just apply permissions for the data on the record instead of warehouses in each individual data store. Off topic a little, but a records of something in the store of data discovered lack is the function of "views of storage" and I put a future application.
Yes, if you set permissision to the view of the data store the user can turn opinion and see. Extensive your permissions framework tests is guaranteed before pushing users. Looks like you are already doing.
-
Best practices for automation of ghettoVCBg2 starting from cron
Hello world!
I set up an instance of vma for scheduling backups with ghettoVCBg2 in a SIN store. Everything works like a charm from the command line, I use vi fastpass for authentication, backups complete very well.
However, I would like to invade the cron script and got stuck. Since vifp is designed to run only command line and as I read not supposed to work from a script, it seems that the only possibility would be to create a backup user dedicated with administrator privileges and store the user and pass in the shell script. I'm not happy to do so. I searched through the forums but couldn't ' find any simple solution.
any IDE for best practices?
Thank you
eliott100
In fact, incorrect. The script relies on the fact that the host ESX or ESXi are led by vi-fastpass... but when you run the script, it does not use vifpinit command to connect. It access credentials via the modules of vi-fastpass which don't vifpinit library but as you have noticed, you cannot run this utility in off-line mode. Therefore, it can be scheduled via cron, basically, but you must run the script interactively, just set up in your crontab. Please take a look at the documentation for more information
=========================================================================
William Lam
VMware vExpert 2009
Scripts for VMware ESX/ESXi and resources at: http://engineering.ucsb.edu/~duonglt/vmware/
Introduction to the vMA (tips/tricks)
Getting started with vSphere SDK for Perl
VMware Code Central - Scripts/code samples for developers and administrators
If you find this information useful, please give points to "correct" or "useful".
-
More file size small .swf - best practices?
I make the flash banner for a website of the College and the CBS guidelines require that all size of the file is less than 40 k. How the hell can you do something with it?
(A) unused library items don't effect the .swf file size?
(B) I use a lower res .jpg for a background that is about 10 k, and each line of text that I use to only 40 images looks like 20 k! (3 sets of text = 60 k) Why plain text is so great?
Interpolations and clips video creation C) really seems to influence the size of the file, which is essentially correct?
(D) all considered, is the main thing that affects the final size .swf, the size of each file used on the timeline? Is there a best practice for converting graphics graphics clips, clips video, symbols, etc. ?
Answers to one of them would be much appreciated, this is driving me crazy. 40 k is so small!
Thank you
Damon
(A) No, it does not affect the SWF file
(B) create textfields and load image execution of external source
(C) It will have an impact on the size to the minimum level, you can also use the tween class to animate
(D) load bitmap from an external source
Consider at least a level of Kbs.
-
Best practices: collaborate between Mac and PC
Department of development for the Web of my not-for-profit organization is expanding - me on a PC using Dreamweaver and ColdFusion, me / PC more a co-worker in Dreamweaver on Mac.
I'm looking for some advice from someone who did the development with a Mac and PC. Basically, I'm looking for "best practices" on how we work together, without spoiling each and other work. It will focus on aspects of the design of the projects: CSS, for example. I work primarily on ColdFusion coding that allows to make information in our databases .cfm pages.
I am just afraid to get into a situation where he has made changes to a single version of a file and I have make changes to another - disaster! Otherwise, I'm worried (as he's a new guy... I've known him for about two weeks!) that his work could "ruin" pages that worked very well until he got his hands on them.
Advice would be really appreciated. Because him and me have these complementary skills, this could be a great collaboration. I want to just make sure we do it as straight as possible from the get-go. -diane> I'm looking for some advice from someone who did the development with a Mac
> and
> PC. Basically, I'm looking for "best practices" on how we should
> collaborate, without spoiling each and other work. It will primarily focus
> on
> aspects of the design of the projects: CSS, for example. I work mainly on
> the
> ColdFusion coding that allows us to extract information in .cfm pages
> of
> our databases.Consider using check-in/check-out option in DW.
-Darrel



Maybe you are looking for
-
Watch connect to a dead iphone?
I lost my iphone 4 days ago. My watch says it is connected when I'm at home, but disconnects when I'm not. He is the head I think my phone is at home. But when I call my phone it goes to voicemail, and I can't hear when I ping. If I was gone for a w
-
When I select a tab, the history displayed automatically for this tab, how to disable?
I don't want to have the little show of white history box every time I move a tab or click on one. It make me DESACT somewhere, I find it very unproductive.
-
I'm looking for documentation on the Firefox command line arguments.
I'm looking for documentation on the Firefox command line arguments. I use Ubuntu.
-
iPhoto went after I updated my OS to El Capitan
Before upgrading my Macbook Pro, I had iPhoto and he had pictures in it. After that I upgraded to OS X El Capitan iPhoto is gone, also when I get on the app store its not available. If I re install, I find my photos in there? (I don't think right the
-
We have an iMac and MacBook 2 backup on a capsule 3 TB. It now says not enough space. Should it not be automatically delete older backups to free up space. I have to start over and do a back up of all three computers?