Problem incrementing in a worksheet
I recently discovered a new problem while trying to increment per line in a worksheet. The problem is when I try to rank 9 to 10 (single two-digit) increment, it increments to ': ' there is no! Similarly, when I try to go from rank 10 to 11 it increments to '2 '!
I have two example VI attached that have been written differently to increment line but the same problem exists in both!
Any help here would be much appreicated!
Thank you!
Barry
Hey Barry,
I think you might have better luck using the 'string of decimal number' and 'Number in comma String' live I have attached an example. I checked, and it increments the 9 and 10 properly.
Andrew
Tags: NI Software
Similar Questions
-
Double digital precision control using the D:H:M format has problem increment/decrement
I have a VI that allows users to define the range of dates in a control, and it does not work as it should. Specifically, the control is the standard digital control of the modern palette, this is the data type is Double, and it is in the format % <%D:%H:%M> t. The problem is that when I have the cursor in the hours (two digits highlighted), when I use the keyboard keys arrow up and down or buttons increase/decrease control, instead of the increment or decrement, the minutes. When I have the cursor over the days, the inc/dec intervenes on the hours. Has no way to increase/decrease the days in the control either. In addition, if the cursor the cursor in the line rather than a selection, changing values are the values to the right of the cursor on the line - even the opposite of the features of LabVIEW with other digital formats.
In addition, the left-right arrow keys won't move the selection / cursor in the control, except to spend hours to days - no other movement is possible.
Is this a known issue? I'm the see in 2010 SP1 and LV LV 2012
I have attached a VI composed solely of misconduct control.
In addition, I tried digital controls system palettes, classic and Express and they do the same thing (or worse).
I guess at this point, I'll need to use separate controls for each field, the event handlers for the arrows, etc., but the complexity which adds is almost painful. If anyone has another idea, I'm all ears.
Thank you,
Erik
took an hour and built a work around for the problem. No was not as bad as I thought originally that are curious differences between the Terminal command, local variables and value - namely, the Value property is the value after the event, while others have the value of pre-event for the control. This always works for my application.
This version is in LV 2010 SP1, which is as far as I can go.
-
Problem of deletion copy worksheet
When you copy an excel spreadsheet, why the deletions of the copy will also delete the original? I tried to rename the copy, but both documents are still changing.
If it is a matter of Microsoft Excel, you should ask in the forums of Microsoft Excel for a better response:
-
Results in Discoverer Desktop screen is different in DiscViewer and more
Hi all
I built a discoverer of crosstab. In the Office of the oracle, the results are ok for example.
1119999 1111888 11117777
OCT-08 533 432 123.45
NOV-08 111 222 333
However, when I open the screen with the viewer or more results are the following:
1119999 1111888 11117777
NULL NULL NULL OCT-08
NULL NULL NULL NOV-08
I worked for two years with the discoverer of the oracle and last year, I have another problem with a binder of table and I found that I need to change the value of two variables in the registry.
[Request]
AggregationBehavior = 1
AllowAggregationOverRepeatedValues = 1
I want to know if the current problem is the same, or if I do another action to resolve the issue. If it's the same problem, how can I change the value in unix environment?
Thanks for your help,
Cordially Mariano. -.If you want that the method of aggregation to change only for this workbook, you
can do this by changing the aggregation behavior of in the most in the spreadsheet properties.
Open the properties for spreadsheet and go to the tab 'aggregation '.
Try to change the aggregation method and check the results.
Maybe this will solve your problem for this specific worksheet to you, and it will return you the data that you expect as in the edition of office.
When you save the workbook, it will save the method of aggregation for each worksheet.on values:
If you open the pref.txt file, you'll see explanations on all the preferences...AggregationBehavior = default # 0 - / 1 - linear aggregate values that may be locally
aggregated (except analytics and calculations with repeated
No values) no effect if the EDA is enabled.
AllowAggregationOverRepeatedValues = default # 0 - / 1 - allow aggregation on repeated values -
chart of increment with the new data to the worksheet
I'm having a little trouble and could use some help if someone has a moment. My vi is streaming at 2 Hz data acquisition and adding data in a worksheet open. I would like to be able to view the data from the worksheet in graphic form, but I don't want to redraw all the data points whenever the worksheet is in graphic form. I have attached the section from vi which is dealing with this issue. I have included an incrementer in my loop (+ 0.5 each implimentation) to allow time (for (i = 0) that each data point is collected, so my spreadsheet has essentially 2 columns, one for the time (0, 0.5, 1.0, 1.5, etc.) and a second column of data point recorded. It all works very well. It's just the graphical representation that gives me. Assume that the broken wires are not broken in total vi. Any ideas on that?
For anyone interested, we solved this problem by attaching a waveform chart to the table converted out of my acquisition of data and define the history of this table to include the necessary length. It seems that a waveform graph is not enough, and each parcel will not appear unless the table is horizontally (columns instead of rows for each data point). Thanks to Jeff at home OR for the help on this one.
Matt
-
Problem reading the worksheet after you use a DLL to write on the worksheet
Hello
I have a few problems reading a sheet DLL created in LabVIEW. The DLL is written in C++.
I'll dexcribe what do the VI in the screenshots:
For DLL_INIT = the first false steps the VI (LabVIEW) values and exports in a DLL initialization.
DLL takes these values and not some und calculation, then wrote the measured values and the new calculated values in a csv file called 'filtered_values' and a file 'filtered_values_complete '.
so, I have two files like this after initialization:1.0000000000; 1.0000000000; 18.8991610737; -3.2940000000; 0.0060000000; 0.9000000000; 6.5806287097; -3.2940000000; 1.0000000000; 0.0000000000; 1.0000000000; 0.0000000000;
So now on DLL_INIT = true.
For the calculation, the next step i read the "filtered_values" - file (LabVIEW), calculate the new values and write in filtered_values (DLL)
And in the "filtered_values_complete" - file I will allways read the DLL entry first, so that I can check later, if the DLL has obtained the values to the right of the front step and then add the calculated values.For i > 0 initialization has been made:
-the VI bed sheet "filtered_values" calculation and rotted the table 1 d in its unique values
-The last seven values in the worksheet have been exported in the dll as well as five new measured values.
-This DLL is still a few calculation
- then it replaces the "filtered_values" - file and adds a new line to the 'filtered_values_complete '.This migth be a bit of confusion, so a small example, afer five steps it loooks like this:
filtered_values:
5.0625000000; 1.0000000000; 18.9300200447; -3.2870000000; 9.7320000000; 0.8997597592; 5.9159054233; -2.6533532901; 1.0000000400; 0.0000000000; 0.8078703403; 0.0000000000;filtered_values_complete:
1.0000000000; 1.0000000000; 18.8991610737; -3.2940000000; 0.0060000000; 0.9000000000; 6.5806287097; -3.2940000000; 1.0000000000; 0.0000000000; 1.0000000000; 0.0000000000;
2.0625000000; 1.0000000000; 18.8330081064; -3.2940000000; 9.7270000000; 0.9000000000; 6.5806287097; -3.2940000000; 1.0000000000; 0.0000000000; 1.0000000000; 0.0000000000;
2.0625000000; 1.0000000000; 18.8330081064; -3.2940000000; 9.7270000000; 0.8999399568; 6.4077416273; -3.1451829134; 1.0000000100; 0.0000000000; 0.9480589053; 0.0000000000;
3.0625000000; 1.0000000000; 18.7932988441; -3.2870000000; 9.7280000000; 0.8999399568; 6.4077416273; -3.1451829134; 1.0000000100; 0.0000000000; 0.9480589053; 0.0000000000;
3.0625000000; 1.0000000000; 18.7932988441; -3.2870000000; 9.7280000000; 0.8998799074; 6.2394046705; -2.9768465052; 1.0000000200; 0.0000000000; 0.8988158138; 0.0000000000;
4.0625000000; 1.0000000000; 19.0445703499; -3.2870000000; 9.7320000000; 0.8998799074; 6.2394046705; -2.9768465052; 1.0000000200; 0.0000000000; 0.8988158138; 0.0000000000;
4.0625000000; 1.0000000000; 19.0445703499; -3.2870000000; 9.7320000000; 0.8998198333; 6.0754981785; -2.8129479844; 1.0000000300; 0.0000000000; 0.8521305805; 0.0000000000;5.0625000000; 1.0000000000; 18.9300200447; -3.2870000000; 9.7320000000; 0.8998198333; 6.0754981785; -2.8129479844; 1.0000000300; 0.0000000000; 0.8521305805; 0.0000000000;
5.0625000000; 1.0000000000; 18.9300200447; -3.2870000000; 9.7320000000; 0.8997597592; 5.9159054233; -2.6533532901; 1.0000000400; 0.0000000000; 0.8078703403; 0.0000000000;So it's good enough that the VI and it works fine until some point when the just VI reads more calculation and x = sheet! There? becomes true.
Most of the time it happens when the csv file is about 1200 lines
Someone knows why this happens?
Best regards
Stefan
Hello
understood, that the error occurs somewhere completely else. the thread may be closed
BR
Stefan
-
Problems with multiple worksheets XY plotting (program generates repeated data)
Hello
I want to make a small program that will reduce the amount of time to go forward with the measurement data. I get data into .dat format, where all the files consist of frequency measurement with an X and a Y column. The problem is that I made 4 experiments (X column is the same for each experience) with 15 measures file each and more than 500 points of measurement in each file. I would like to make a simple manipulation and this copy that information to a file with same X column and multi-column, later I could use these data with Excel or origin (do it manually, it's frustrating and time consuming).
At the beginning my program reads the background information with X and Y (b), and after I open the worksheet to insert the X and data of Y (n). (make a simple manipulation, like dividing Y (n) /Y (b), program show a graph of the current data and another graph multiple data, which are stored and must be exported in .txt, .dat or directly to Excel (which is more preferable)). I'm OK with the opening of several files of data, but which are not okay with copy/paste file and handle all that data manually, but that's my motivation for this program.
The attached example can do all this (except for the entry in the file). He draws multiple charts on a XY chart using cluster and travel records. It is even possible to extract data in Excel, all that graphic, but the real problems comes with data are always added because of the loop. This gives a lot of empty and repeated data later. I'm jonesing to get rid of this. I have also attached several files of measure: 1 background and 3 measures.
P.S. I tried to save time thanks to this program, but now, I spent more time than if I did it manually

Your program absolutely no sense. What is the purpose of the structure of sequence? It just sits there, operating both in parallel to the while loop. Probably that you read from the local variables before other parts of the program had a chance to write valid data for them.
In the while loop, you have a case of timeout that adds the same data over and over again, every 50ms. Why?
Your mechanical actions "switch release" are misguided. Use actions to latch and remove structures deal as part of the event.
Try to rethink the problem once the mode, and then solve the problem with 20% of your current code. See how far you get.
-
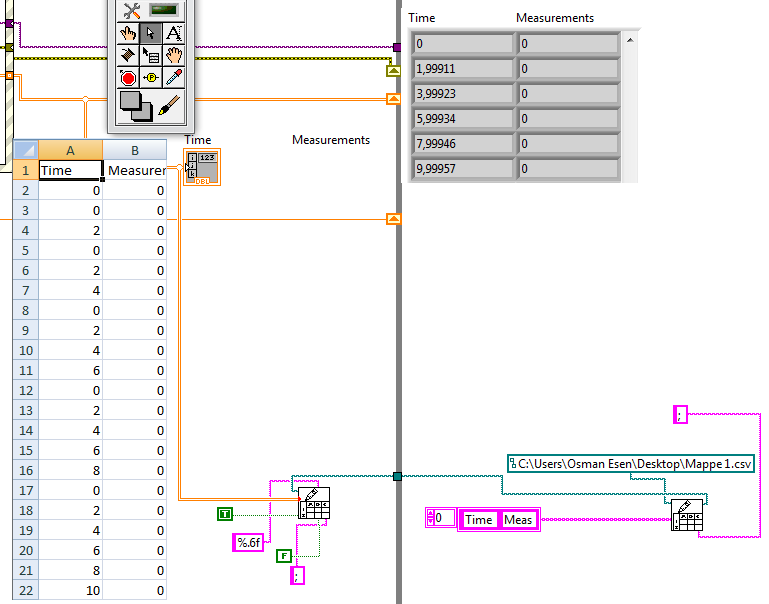
Write on the worksheet while loop problem
Hello dear Labviewers. I have a 'writing on spreadsheet"with a table 2D DBL connected on it, but the problem occurs inside the while loop. I want exactly those time six values in my excel document, but it restarts after every "two seconds" and I cannot get rid of this problem. I want exactly the same numbers in the Excel document as it is in the table.
I tried to move the two "write to the spreadsheet' boxes outside the while loop, but the Excel document does not display a single value in the table, when I do this. It shows that the two headers
My second problem is rounded off on the numbers. Even if I wrote "%.6f" in the part of the format, it gives me a single decimal value.
Thanks in advance
Orlando
Orlando says:
Thanks for the help Ravensfan
But the "worksheet to write" not a not an output port, then how can I do this?
I downloaded my VI
I never said anything about writing about a spreadsheet file with an output port.
See the attached VI for changes. It's only the new data of this iteration of the loop that will write it on the spreadsheet file VI, not made all of the table from all iterations. There is an entry of table 1 d to the spreadsheet file.
-
Problems printing my worksheets in Excel
Hello. I have a strange problem with my print Excel. I put all options correctly page Setup and printer properties. (A4) paper size, landscape, to the scale (100%), quality (600 dpi), Margines, print and there is no specific area chosen as the print area. And all the corresponding options in the printer properties are correct.
But I always get a bad my printer output. The table is cultivated most small to the right.
It applies also to say that all my printer drivers are correctly installed. Because the printer works well with all other software. The printer is HP Laser Jet P1505.
I thank you a fortune I help me with this problem.So I'm a little outside my area expertise (printers, etc.), but I checked on the HP site and they have released a new driver for this printer a few weeks ago, so I strongly recommend to download the latest driver from their site and then try. Driver update tend to often fix weird problems, isolated like this one... sometimes they derive by using different fonts, and they will update the drivers to adjust to this.
I doubt that there is a framework, that would be something you would remember changing and usually don't vary according to the print job.
In fact, out of curiosity, if the updated driver does not resolve the problem, you could try change fonts on the worksheet and see if you get a change in behavior (standard use something like Helvetica, Times New Roman, Arial, etc.) -
Incremental synchronization AUSST problem
Hello
I took the responsibility inherited from maintain server update adobe internal to the company and currently facing some problems.
2 questions:
1. when I run the incremental update via schedule task, it begins and ends in 1 min with event id 201. the account used to run with the highest privileges and I removed the duration max which can do the task to make sure that it is not out of time, but it still doesn't work. I spent very little of my time to research on this but no luck. Hoping that you guys will have comments.
2. when I run the same command on CMD, his chosen Syn incremental deadlock and nothing happens. It worked 3 weeks when I ran it manually, and to my knowledge, nothing has changed on the firewall.
I'm hesitant to do a sync fees as I am not aware the time it will take.
Any help is appreciated.
Here is the log of the DLM.
05/08/16 09:19:11:369 | [INFO] | | | | | | | 4228 | start of download *.
05/08/16 09:19:11:369 | [INFO] | | | | | | | 4228 | Version of WDM is 9.0.0.4 (BuildVersion: 6.0;) Brand: Wednesday, March 4, 2015 21:34:10)
05/08/16 09:19:11:540 | [INFO] | | | | | | | 4228 | *******************End****************
05/08/16 09:19:52:619 | [INFO] | | | | | | | 3172. start of download *.
05/08/16 09:19:52:619 | [INFO] | | | | | | | 3172. Version of WDM is 9.0.0.4 (BuildVersion: 6.0;) Brand: Wednesday, March 4, 2015 21:34:10)
05/08/16 09:19:52:760 | [INFO] | | | | | | | 3172. *******************End****************
05/08/16 09:20:02:572 | [INFO] | | | | | | | 5924. start of download *.
05/08/16 09:20:02:572 | [INFO] | | | | | | | 5924. Version of WDM is 9.0.0.4 (BuildVersion: 6.0;) Brand: Wednesday, March 4, 2015 21:34:10)
05/08/16 09:20:02:713 | [INFO] | | | | | | | 5924. *******************End****************
05/08/16 09:20:24:822 | [INFO] | | | | | | | 4720 | start of download *.
05/08/16 09:20:24:822 | [INFO] | | | | | | | 4720 | Version of WDM is 9.0.0.4 (BuildVersion: 6.0;) Brand: Wednesday, March 4, 2015 21:34:10)
05/08/16 09:20:24:994 | [INFO] | | | | | | | 4720 | *******************End****************
05/08/16 09:20:30:791 | [INFO] | | | | | | | 2864. start of download *.
05/08/16 09:20:30:791 | [INFO] | | | | | | | 2864. Version of WDM is 9.0.0.4 (BuildVersion: 6.0;) Brand: Wednesday, March 4, 2015 21:34:10)
05/08/16 09:22:24:839 | [INFO] | | | | | | | 2864. *******************End****************
05/08/16 09:22:37:198 | [INFO] | | | | | | | 520 | start of download *.
05/08/16 09:22:37:198 | [INFO] | | | | | | | 520 | Version of WDM is 9.0.0.4 (BuildVersion: 6.0;) Brand: Wednesday, March 4, 2015 21:34:10)
05/08/16 09:22:37:292 | [ERROR] | | | | | | | 520 | Is the windows error code - 12180
05/08/16 09:22:37:292 | [ERROR] | | | | | | | 520 | Could not get the user proxy settings. The error is 12180. Ignoring the proxy setting in this case.
05/08/16 09:22:37:292 | [ERROR] | | | | | | | 520 | Impossible to adjust the setting on the proxy computer
05/08/16 09:22:37:292 | [INFO] | | | | | | | 520 | The file to download is https://swupmf.adobe.com/webfeed/oobe/aam10/win/updaterfeed.xml
05/08/16 09:22:37:292 | [INFO] | | | | | | | 520 | Going to download the file to C:\inetpub\wwwroot\adobeupdates\webfeed\oobe\aam10\win\/updaterfeed.xml.tmp
Hey Andy_nag,
I don't know how many people in the forums to download, installation and commissioning have the expertise to address this issue. I could be wrong, and a little-known genius waiting in the wings with a perfect solution. In the meantime, however, you can ask your question in Cloud creative team, Enterprise, deployment & CS. There are some members of the staff who specialize in issues of volume license watching this space. You can also get help via the site Web of Adobe License | Serial numbers, orders and accounts, or by contacting customer service.
-
Problems with the retention policy that removes a Cumulative incremental backup
Hello
I have following two scripts:
1 RMAN script runs the weekend and made a full backup of level 0.
2 RMAN script works on a daily basis and a level 1 Cumulative backup.
at the end of each script I delete noprompt obsolete redundancy 1; (I don't need a single copy of local disk)
My problem is that it seems that remove obsolete handles only level 0 (full) backups.
for example, my goal is:
Saturday = > level 0 + delete obsolete (level 0 + all the incremental)
Sunday = > obsolete level 1 cumulative + delete
Monday = > level 1 cumulative + Delete obsolete (backup Sunday)
etc...
What happens in reality is rather that remove obsolete Monday, completely ignores Sunday 1 cumulative level.
and he keeps all the up to the next level 0 backup
its actually covered in the Oracle Documentation:
http://docs.Oracle.com/CD/E11882_01/backup.112/e10642/rcmconfb.htm#BRADV8400
but it's just not make sense.
in order to have redundancy of 1 copy I only need to level 0 + unique Level 1 cumulative backup.
I don't have level 0 + all level 1 cumulative backups between full backups.
so my question is there a way to make the retention policy to keep only the last level 1 cumulative?
It's true window of 1 day recovery ignores several backups of cumulativ made the same day as being obsolete. Regular retention strategies rman probably cannot provide what you want. You can manually identify the backupset and delete them or change of cumulativ backups to incremental backups.
That would save the space of several cumulative backups and and would work even for several backups on the same day. Of course with the disadvantage that you need all of the incremental backups and your recovery time may be longer
-
MERGE statement is increment the sequence. It problem?
Hi allI use a merge statement to update thousands of data in a table. If the criteria does not match (WHEN NOT MATCHED) I wrote an insert statement that contains a reference to the sequence. And it works very well.
My question is, will this increment also sequence even though it won't insert the statement in the script of fusion. I think it will be. Right?
Say, I update 20K record will be the sequence also increment by 20 times k. If his past all work around.
Thanks in advance.
Here is a less effective solution to your problem that creates a function to get the value of the following sequence, but I agree with Justin cave that because of the cache you must lose the values.
SQL > CREATE SEQUENCE s_emp;
Order of creation.
SQL > CREATE or REPLACE FUNCTION s_emp_nextval
2 RETURN NUMBER
3 AS
4 v_nextval NUMBER;
5 BEGIN
6. SELECT s_emp.nextval
7 INTO v_nextval
8 DOUBLE;
9 v_nextval of RETURN;
10 END;
11.
The function is created.
SQL > MERGE IN emp t (USING)
2. SELECT empno, ename
3 FROM emp) s
4. WE (t.empno = s.empno)
5. WHEN MATCHED THEN
UPDATE 6
7 SET t.ename = s.ename
8 WHEN NOT MATCHED THEN
9 INSERT (empno, ename)
10 VALUES (s_emp_nextval, 'SMITH');
14 lines merged.
SQL > SELECT s_emp. NEXTVAL
2 FROM dual;
NEXTVAL
----------
1
-
Problem of incremental update in the treatment of updates
Hi all
I use ODI 11.1.1 and IKM Oracle incremental update. I have the following problem:
My target table contains the following keys: NAME EVENT_ID, location_id and following columns, VALUE
And assume that my source table that contains the same columns and a TIME column.
If the source table is as follows:
EVENT_ID LOCATION_ID NAME TIME VALUE
1 1 T 1 1
1 1 T 2 2
If these two lines are loaded into the staging table I$ at the same time and the target table does not contain already the (1,1) combination for event_id, location_id 2 new lines will be inserted into the fact table. I would not have only one line with the most recent value. The problem is that step 'make update' will never report the second row as 'U' because there is no such thing as the combined update key in the fact table.
How can I get the desired behavior?
Hello
There are several ways to do so. It depends mainly on your cardinality.
APPROACH 1 (VERY BAD): filter
- Place a filter with this text
- EVENT_ID | LOCATION_ID | TIME IN (SELECT EVENT_ID |) LOCATION_ID | MAX (TIME) FROM TABLE GROUP BY EVENT_ID, LOCATION_ID)
APPROACH 2: make a subselect interface
- create a temporary with interface
- EVENT_ID = EVENT_ID
- LOCATION_ID = LOCATION_ID
- TIME = MAX (TIME)
- then put this interface (yellow) in your source and mark as subselect
- make an inner join
METHOD 3: VIEW
- give an opinion on your db
- create view MYVIEW AS SELECT EVENT_ID, location_id, MAX (TIME) FROM TABLE GROUP BY EVENT_ID location_id
- reversing the trend
- inner join
APPROACH 4: FUNCTION ANALYTICS (good)
Use an analytic function. See for example Re: 2nd Max Sal. But what will little customization.
However, a variable is not a solution.
Let us know
- Place a filter with this text
-
Problem with triggers - sequential incrementing
I have a table called student and I need to add the trigger for this table. This trigger needs to update increment_id for each line, each time that the new row is inserted or updated the existing line. If a new row inserted without specified increment_id that it should automatically assign the next value of sequence for this line.
First of all, I added new column to the table of students.
change the student table add (increment_id COMP (21.6);)
Then, a sequence is created for that table.
CREATE SEQUENCE seq_students
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;
Finally, I created the trigger as follows.
CREATE OR REPLACE TRIGGER trg_students_seqid
BEFORE the INSERT OR UPDATE ON students
FOR EACH LINE
BEGIN
insertion and: new.increment_id is null then
Select seq_students.nextval in: double new.increment_id;
elsif UPDATE then
Select seq_students.nextval in: double new.increment_id;
end if;
END;
Everything works fine and the increment_id is updated / inserted whenever I have add/edit new line. But the problem is sometimes when I change/add line and commit changes, I noticed that the assigned ID of increment is not continuous.
Example: Let say increment_id maximum current for this table is 50. If I update the row with student_id = 100 and commit the changes I found the increment_id so that the rank is 120 instead of 101. This happens sometimes when I insert a new line as well.
Can someone please help me with this and tell me where I have done wrong.
Thank you.Sequences will be not free of gap.
When the sequence is aging out of the shared pool, for example, the cached values will be eliminated. Given that your cache is set to 20, which explains why the values will increase from 101 to 121 (101-120 were, no doubt, put in cache, and when the years sequence, the cached values have been cancelled). You can reduce the chances that you will get a deviation of the NOCACHE but sequence that will negatively affect performance. It won't completely prevent also the gaps - you'll see always gaps in transactions do backward when the triggers are redone for consistency of Scripture, etc.. If you can tolerate some gaps, you should be able to tolerate deviations resulting sequence cache aging on.
Justin
-
Problem of moving objects by small increments
Hey everyone, I've seen this similar question before but none of the solutions seem to help my problem. I'm trying to move an object in a fairly small increase, I have the box Increments preferences keyboard set to its lowest number, but I still need to move my object 1/3 as long. I also tried to manually move the object to the correct point with my mouse and it takes just return to the area where he was sitting, which was as close as I could get it with the help of the arrow keys. I disabled to line up on the grid and snap to point, no change in my result. Basically, I am trying to align a smaller triangle on a part of a larger triangle to act as an area of shading. All solutions? Thanks in advance.
mblaney,
It looks like the attribute Align to pixel grid ghost haunting you, as SRiegel suggested.
Or maybe snap to grid.
Are both unchecked (the former when the black triangle is selected)?
Maybe you are looking for
-
When you perform a restore to original factory it fails during the "HP Software is installed. After several reboots, I get the following error: The attempt to retrieve filed. Please select one of the following buttons: (details and try again is displ
-
One of my clients wants to buy a computer at the end of the lease that had the deleted o/s. They want to know if they can use the product keys from sticker COST units to re - install the o/s legally. Since it is a COA OEM license moves with the PC
-
Run DHCP on the router with DSL internet
I currently have internet DSL with Bell (Canada) with my wrt160n router connected to the modem. I've been reading around and it seems that my router should use PPPoE rather that DHCP is currently using it. I guess that of maybe the reason why I have
-
nybody know of any free software to help speed up my laptop?
Original title: FREE SPEED UP! Anyone know of any free software to help speed up my laptop - its time for a new just need this to carry me for another 6 months at the plus-juste slow down don't want to spend money! l will buy a very quickly soon enou
-
Help available for download Photoshop elements 11?
HelloI bought Photoshop elements 11 about two years ago, the downloadable version. It worked perfectly on my PC.Now, I bought a new HP laptop running Windows 10. I have the serial number Element´s and my Adobe IDCan I download Photoshop elements 11 f