Profile - Cluster HV 2012r2 of service
Hi all
I wanted to get feedback on a model of service profile that we try to put into production for our new cluster HV. Notice that we use SMB storage managed by SOFA W2012R2 server.
|
NIC
|
General description
|
RSS FEED
|
UM2
|
RCI/RDMA
|
General note
|
Failover
|
|
MGT
|
Used for the management of hosts
|
NO.
|
NO.
|
NO.
|
Windows generic adapter policy
|
A FI + tipping
|
|
Heartbeat
|
Heartbeat
|
NO.
|
NO.
|
NO.
|
Windows generic adapter policy
|
FI B + failover
|
|
LiveMigration
|
LiveMigration
|
Yes
|
NO.
|
Yes
|
Used for the live VM migration
|
A FI + tipping
|
|
SMB-1
|
Used for SMEs in the host
|
Yes
|
NO.
|
NO.
|
Custom adapter strategy
|
FI - no tipping
|
|
SMB-2
|
Used for SMEs in the host
|
Yes
|
NO.
|
NO.
|
Custom adapter strategy
|
FI B - no tipping
|
|
SMB-3
|
Used to present part in VM is hosted on the cluster of SOFA |
Any thoughts? Should I reduce A - VM and VM - B and let UCS manage the LB and HA?
Thank you
Hello
There are generic problem, irrelevant if failover hardware or software HA. If you communicate in a veth vlan (network l2) source in fabric A and fabric B veth destination, you leave domain UCS to the switch to the North and back again. Even if nothing is initially is on A fabric, due to the failure, the part could failover to the B fabric...
Tags: Cisco DataCenter
Similar Questions
-
When you try to access the user profile, get the error message "the service user profile Service has no logon. User profile cannot be loaded. "The new profile tried to go through the steps of profile user fix damaged by ms, but trying to create a new user profile to copy the files from the damaged user profile does not display on my C: drive the users folder (as it should). Anyway to fix the corrupted if user profile profile are available?
Hello
References to Vista also apply to Windows 7.
You can try to fix it with Safe Mode - repeatedly press F8 as you bootup. The ADMIN account in trunk
Mode has no default password (unless someone has changed the password so it should be available).Some programs such as the updated Google (if you added the toolbar Google, Chrome or Google Earth)
has been known to cause this problem.Error message when you log on a Windows Vista-based or Windows 7 using computer a
Temporary profile: "the user profile Service has no logon. Unable to load the user profile.
http://support.Microsoft.com/kb/947215How to fix error "the user profile Service has no logon. User profile cannot be loaded. »
http://www.Vistax64.com/tutorials/130095-user-profile-service-failed-logon-user-profile-cannot-loaded.htmlHow to fix error "your user profile was not loaded correctly! You have been connected with a
temporary profile. "in Vista
http://www.Vistax64.com/tutorials/135858-user-profile-error-logged-temporary-profile.htmlBE VERY CAREFUL IF YOU USE THIS ONE:
DO NOT USE THE ACCOUNT HIDDEN ON A DAILY BASIS! If it corrupts you are TOAST.
How to enable or disable the built-in Windows 7 Administrator account
http://www.SevenForums.com/tutorials/507-built-administrator-account-enable-disable.htmlUse the hidden administrator account to lower your user account APPLY / OK and then lift it to ADMIN.
This allows clear of corruption. Do the same for other accounts if necessary after following the above message.You can use the hidden - administrator account to make another account as ADMINISTRATOR with password even
(or two with the same password) use a test or fix the other.You can run the Admin account hidden from the prompt by if necessary.
How Boot for Windows 7 System Recovery Options or use a Windows 7 boot disk.
http://www.SevenForums.com/tutorials/668-system-recovery-options.htmlWhat are the system recovery options in Windows 7?
http://Windows.Microsoft.com/en-us/Windows7/what-are-the-system-recovery-options-in-Windows-7How to create a Windows 7 system repair disc
http://www.SevenForums.com/tutorials/2083-system-repair-disc-create.htmlIf you cannot access your old account, you can still use an Admin to migrate to another (don't forget
always leave to an Admin who is not used except for testing and difficulty account).Difficulty of a corrupted user profile
http://windowshelp.Microsoft.com/Windows/en-AU/help/769495bf-035C-4764-A538-c9b05c22001e1033.mspxI hope this helps.
-
How to find vCenter virtual cluster large when the services are not running?
Does anyone have advice for locating vCenter in a cluster, when his services are not running?
For example, I have to restart vCenter and its network is having issues. I need to go to the host ESX (i) is on and open the console to get to the virtual machine. But to find that host is on can sometimes take a long time, because I have to log in to each HOST and see if it is the host where vCenter.
Does anyone have any advice or suggestions to make this process easier? It is not so important, but just curious to know what others might suggest.
Thank you.
I used PowerCLI and
to connect-viserver esx1, esx2, esx3
connect to all the ESX(I) hosts and then run
Get - vm vCenterServerName | Select the name, the host
-
Dependent Service in UCSM material of blade profiles?
Is that we can assign the same service to a B200M2 profile, B230 M2 and a blade of B200M3?
An example: if my B200 M2 goes down because of a hardware failure, I replaced the same slot with a B200 M3 Blade.Then is possible that I have separate Service of B200M2 profile and associate the same Service profile with B200M3?
Hi Deepak,
It is certainly possible.
If there is no problem, because of incompatibilities, it triggers a failed configuration error, the service profile is related to the new blade.
I hope this helps.
Thank you
Michael
-
I have a UCS chassis with 8 blades B200 M3 (run 2.0.5a). Each blade contains a 1240 VIC and a 1280 of VIC. The blades have a service profile that is already associated with them and everything works fine. I bought cards cache for these EMC xtreme blades so I need stop each blade, remove the VIC 1280 and insert the new card cache xtreme. My question: will I be able to re - associate the original service profile for blades once I inserted cards cache xtreme or do I have to create a new service profile template and create new service profiles?
I know that I get an error when I try to associate a profile of invalid service for a blade, but I have trying to figure out if this will work before I do actually.
Thank you in advance.
Hello Ernes,
About the association of profile service, you can use the same profile after making changes on the hardware and the creation of new service profiles is not necessary.
I guess you refer to LSI 400GO SLC warpdrive adapter when you are referring to the memory card cover xterme EMC.
http://www.Cisco.com/en/us/prod/collateral/ps10265/ps10280/data_sheet_c78-727854.html
Padma
-
I have another computer. I turned it on and when I typed my windows password, I received the following message: the user profile service service has no logon. User profile cannot be loaded. Service user profile Service has no logon. User profile cannot be loaded. I use Windows 7 Professional. I don't have a password reset disk. How can I get?
Hello
You can try to fix it with Safe Mode - repeatedly press F8 as you bootup. The ADMIN account in trunk
Mode has no default password (unless someone has changed the password so it should be available).Some programs such as the updated Google (if you added the toolbar Google, Chrome or Google Earth)
has been known to cause this problem.Error message when you log on a Windows Vista-based or Windows 7 using computer a
Temporary profile: "the user profile Service has no logon. Unable to load the user profile.
http://support.Microsoft.com/kb/947215How to fix error "the user profile Service has no logon. User profile cannot be loaded. »
http://www.Vistax64.com/tutorials/130095-user-profile-service-failed-logon-user-profile-cannot-loaded.htmlHow to fix error "your user profile was not loaded correctly! You have been connected with a
temporary profile. "in Vista
http://www.Vistax64.com/tutorials/135858-user-profile-error-logged-temporary-profile.htmlBE VERY CAREFUL IF YOU USE THIS ONE:
DO NOT USE THE ACCOUNT HIDDEN ON A DAILY BASIS! If it corrupts you are TOAST.
How to enable or disable the built-in Windows 7 Administrator account
http://www.SevenForums.com/tutorials/507-built-administrator-account-enable-disable.htmlUse the hidden administrator account to lower your user account APPLY / OK and then lift it to ADMIN.
This allows clear of corruption. Do the same for other accounts if necessary after following the above message.You can use the hidden - administrator account to make another account as ADMINISTRATOR with password even
(or two with the same password) use a test or fix the other.You can run the Admin account hidden from the prompt by if necessary.
How Boot for Windows 7 System Recovery Options or use a Windows 7 boot disk.
http://www.SevenForums.com/tutorials/668-system-recovery-options.htmlWhat are the system recovery options in Windows 7?
http://Windows.Microsoft.com/en-us/Windows7/what-are-the-system-recovery-options-in-Windows-7How to create a Windows 7 system repair disc
http://www.SevenForums.com/tutorials/2083-system-repair-disc-create.htmlIf you cannot access your old account, you can still use an Admin to migrate to another (don't forget
always leave to an Admin who is not used except for testing and difficulty account).Difficulty of a corrupted user profile
http://windowshelp.Microsoft.com/Windows/en-AU/help/769495bf-035C-4764-A538-c9b05c22001e1033.mspxI hope this helps.
Rob Brown - MS MVP - Windows Desktop Experience: Bike - Mark Twain said it right.
-
How to change the power state in a Service profile template
I would like to change the "Power status" in a model of Service profile. While I can change almost all other aspects of the model, I don't find it in the UCS Manager GUI. Is it an unchangeable decision while creating the model? I can change it via the CLI?
Hi Joernclausen,
What version of the firmware of your UCS?
In the CLI, try the steps below and let me know if it works.
Go into the FI CLI and perform the steps below, ensure to enter your own template_name and select appropriate type of template followed by setting the power up or down sj-ucs-r13-mon-A# scope org sj-ucs-r13-mon-A /org # enter service-profile template_name initial-template sj-ucs-r13-mon-A /org/service-profile # power up sj-ucs-r13-mon-A /org/service-profile* # commit-buffer sj-ucs-r13-mon-A /org/service-profile # power down sj-ucs-r13-mon-A /org/service-profile* # commit-buffer
You may also be able to change the power state of the individual service profiles
Go to the service profile and use "Change Initial Power State" button for modifying the desired-power value.
See attached screenshot
-
MapListener is not survive after the cluster service is restarted
According to this article, MapListener will survive restart of the service, however, is not what we have seen in our environment.
We use 3.3.1/389.
We have an application running as disabled storage node which acts also as a MapListener on a cache.
This application performs certain actions when entry inserted/updated to day occur.
However, we have observed that when there is network problem, the cluster service will be shutdown. And
This application will not join the cluster after that the network problem go away. Here is what we
light at the end of the journal.
*****************************************************************************************************
2008-09-02 11:57:21.645 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 7): timeout while offering a package; asking the confirmation of departure for members (Id = 3, Timestamp = 2008-09-02 11:57:21.645, address = 172.31.1.51:8088, MachineId = 45619, Location=process:4016@CHEN_DESKTOP, role = OpCacheProxy)
by the member set (size = 1, BitSetCount = 1
Member (Id = 2, Timestamp = 2008-09-02 11:36:50.756, address = 172.31.1.51:8089, MachineId = 45619, Location=process:2636@CHEN_DESKTOP, role = OpCacheNode)
)
2008-09-02 11:57:22.646 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 7): timeout while offering a package; asking the confirmation of departure for members (Id = 4, Timestamp = 2008-09-02 11:57:22.646, address = 172.31.1.51:8091, MachineId = 45619, Location=process:2604@CHEN_DESKTOP)
by the member set (size = 1, BitSetCount = 1
Member (Id = 2, Timestamp = 2008-09-02 11:36:50.756, address = 172.31.1.51:8089, MachineId = 45619, Location=process:2636@CHEN_DESKTOP, role = OpCacheNode)
)
2008-09-02 11:57:23.638 Oracle coherence GE 3.3.1/389 < error > (thread = PacketPublisher, Member = 7): this node appears to be disconnected from the rest of the cluster containing 3 nodes. All requests for confirmation of departure are unanswered.
Stop the cluster service.
2008-09-02 11:57:23.638 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = 7): Service de Cluster in the cluster on the left
2008-09-02 11:57:23.758 Oracle coherence GE 3.3.1/389 < D5 > (thread = ReplicatedCache, Member = 7): Service ReplicatedCache left in the cluster
*****************************************************************************************************
We recalled the previous discussion on the forum that consistency will not restart the cluster service until
One needs. Fine, so we add a monitor who will call routely CacheFactory.ensureCluster () each
minute since the original application only will using cluster service when it receives events from MapListener.
Well, after we put in this thread to monitor. We saw the cluster service restart and this request will be
join the cluster when network problem solved. However, not even any of the insert/update. The MapListener
is not after the cluster service is restarted. Here is the log after that we put in the monitor to call ensureCluster().
******************************************************************************************************
2008-09-02 13:30:05.816 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 5): timeout while offering a package; asking the confirmation of departure for members (Id = 2, Timestamp = 2008-09-02 13:30:05.816, address = 172.31.1.51:8089, MachineId = 45619, Location=process:2636@CHEN_DESKTOP, role = OpCacheNode)
by the member set (size = 1, BitSetCount = 1
Member (Id = 1, Timestamp is 2008-09-02 12:23:06.84 address = 172.31.1.51:8092, MachineId = 45619, Location=process:4200@CHEN_DESKTOP, Role = OpCacheNode.82461540040000250)
)
2008-09-02 13:30:06.827 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 5): timeout while offering a package; asking the confirmation of departure for members (Id = 3, Timestamp = 2008-09-02 13:30:06.827, address = 172.31.1.51:8088, MachineId = 45619, Location=process:4016@CHEN_DESKTOP, role = OpCacheProxy)
by the member set (size = 1, BitSetCount = 1
Member (Id = 1, Timestamp is 2008-09-02 12:23:06.84 address = 172.31.1.51:8092, MachineId = 45619, Location=process:4200@CHEN_DESKTOP, Role = OpCacheNode.82461540040000250)
)
2008-09-02 13:30:07.829 Oracle coherence GE 3.3.1/389 < WARNING > (thread = PacketPublisher, Member = 5): timeout while offering a package; asking the confirmation of departure for members (Id = 4, Timestamp = 2008-09-02 13:30:07.829, address = 172.31.1.51:8091, MachineId = 45619, Location=process:2604@CHEN_DESKTOP)
by the member set (size = 1, BitSetCount = 1
Member (Id = 1, Timestamp is 2008-09-02 12:23:06.84 address = 172.31.1.51:8092, MachineId = 45619, Location=process:4200@CHEN_DESKTOP, Role = OpCacheNode.82461540040000250)
)
2008-09-02 13:30:08.830 Oracle coherence GE 3.3.1/389 < error > (thread = PacketPublisher, Member = 5): this node appears to be disconnected from the rest of the cluster containing 4 nodes. All requests for confirmation of departure are unanswered.
Stop the cluster service.
2008-09-02 13:30:08.830 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = 5): Service de Cluster in the cluster on the left
2008-09-02 13:30:08.960 Oracle coherence GE 3.3.1/389 < D5 > (thread = ReplicatedCache, Member = 5): Service ReplicatedCache left in the cluster
2008-09-02 13:30:17.973 Oracle coherence GE 3.3.1/389 < Info > (thread = main Member, = n/a): restart cluster
2008-09-02 13:30:18.284 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service de Cluster has joined the cluster with the senior members of the service s/o
2008-09-02 13:30:21.508 Oracle coherence GE 3.3.1/389 < Info > (thread = Cluster, Member = n/a): creates a new cluster "EVODENTRTYY" with Member(Id=1, Timestamp=2008-09-02 13:30:17.993, Address=172.31.1.55:8088, MachineId=45623, Location=process:4404@cchen01, Edition=Grid Edition, Mode=Development, CpuCount=1, SocketCount=1) UID = 0xAC1F01370000011C241D6409B2371F98
2008-09-02 13:30:30.401 Oracle coherence GE 3.3.1/389 < error > (thread = Cluster, Member = 1): senior member (Id = 1, Timestamp = 2008-09-02 13:30:17.993, address = 172.31.1.55:8088, MachineId = 45623, Location=process:4404@cchen01) seems to have been disconnected from another senior member (Id = 3, Timestamp = 2008-09-02 11:02:24.055, address = 172.31.1.51:8088, MachineId = 45619, Location=process:4016@CHEN_DESKTOP, role = OpCacheProxy); stop the cluster service.
2008-09-02 13:30:30.401 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = 1): Service de Cluster in the cluster on the left
2008-09-02 13:30:31.513 Oracle coherence GE 3.3.1/389 < Info > (thread = main Member, = n/a): restart cluster
2008-09-02 13:30:31.783 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service de Cluster has joined the cluster with the senior members of the service s/o
2008-09-02 13:30:31.984 Oracle coherence GE 3.3.1/389 < Info > (thread = Cluster, Member = n/a): this Member(Id=6, Timestamp=2008-09-02 13:30:54.24, Address=172.31.1.55:8088, MachineId=45623, Location=process:4404@cchen01, Edition=Grid Edition, Mode=Development, CpuCount=1, SocketCount=1) has joined the cluster "EVODENTRTYY" with the upper limbs (Id = 3, Timestamp = 2008-09-02 11:02:24.055, address = 172.31.1.51:8088, MachineId = 45619, Location=process:4016@CHEN_DESKTOP role = OpCacheProxy = Grid Edition Edition, Mode = development, CpuCount = 2, SocketCount = 1)
2008-09-02 13:30:31.994 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Member (Id = 1, Timestamp is 2008-09-02 12:23:06.84 address = 172.31.1.51:8092, MachineId = 45619, Location=process:4200@CHEN_DESKTOP, Role = OpCacheNode.82461540040000250) joined the Cluster with veteran 3
2008-09-02 13:30:31.994 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Member (Id = 2, Timestamp = 2008-09-02 11:36:50.756, address = 172.31.1.51:8089, MachineId = 45619, Location=process:2636@CHEN_DESKTOP, role = OpCacheNode) joined the Cluster with veteran 3
2008-09-02 13:30:31.994 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Member (Id = 4, Timestamp = 2008-09-02 11:40:09.661, address = 172.31.1.51:8091, MachineId = 45619, Location=process:2604@CHEN_DESKTOP) joined the Cluster with veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): 3 members joined Service Management with veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): 3 members joined Service DistributedCache with veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ReplicatedCache is 3 associate member veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service InvocationService is 3 associate member veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ExtendTcpProxyService is 3 associate member veteran 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): 1 member is associated with Service Management senior member 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service DistributedCache is 1 associate member senior member 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ReplicatedCache is 1 associate member senior member 3
2008-09-02 13:30:32.004 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service InvocationService is 1 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): service management is 2 3 senior member associate member
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service DistributedCache is 2 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ReplicatedCache is 2 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service InvocationService is 2 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): 4 members joined Service Management with veteran 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service DistributedCache is 4 associate member senior member 3
2008-09-02 13:30:32.014 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = n/a): Service ReplicatedCache is 4 associate member senior member 3
2008-09-02 13:30:32.184 Oracle coherence GE 3.3.1/389 < D5 > (thread = Cluster, Member = 6): TcpRing: connection to the 2 using TcpSocket {State = STATE_OPEN, Socket=Socket[addr=/172.31.1.51,port=8089,localport=3984]} Member
2008-09-02 13:30:33.416 Oracle coherence GE 3.3.1/389 < D5 > (thread = TcpRingListener, = 6 member): TcpRing: connection to members 3 using TcpSocket {State = STATE_OPEN, Socket=Socket[addr=/172.31.1.51,port=2199,localport=8088]}
2008-09-02 13:30:33.416 Oracle coherence GE 3.3.1/389 < D5 > (thread = TcpRingListener, = 6 member): TcpRing: connection to the Member 4 using TcpSocket {State = STATE_OPEN, Socket=Socket[addr=/172.31.1.51,port=2200,localport=8088]}
2008-09-02 13:30:33.606 Oracle coherence GE 3.3.1/389 < D5 > (thread = TcpRingListener, = 6 member): TcpRing: connection to members 1 using TcpSocket {State = STATE_OPEN, Socket=Socket[addr=/172.31.1.51,port=2201,localport=8088]}
*********************************************************************************************************
According to this article, this problem could be solved using MemberLister.
If we implement the MemberLister, and we get MemberLeft event when the cluster service has obtained the judgment.
However, we receive no MoreRejoignez event at all when this application join the cluster.
The MemberListener has been added to the CacheService belong to the cache, we added the MapListener. It seems
the MemberListener don't survive that restart CacheService in this case, so no cases of MoreRejoignez received.
Now the question arises. What can we do to ensure that MapListener can survive restarting the cluster service
in our case? Or is there a way for us to detect that the MapListener is not valid more so one reattach necessary?
Kind regards
ChenHi Chen,
In the thread of your monitor, instead of CacheFactory.ensureCluster () you can call cache.size () (on a cache that you added another to.)
Kind regards
Dimitri -
vSphere 5.5: "the storage service is not initialized.
Hello
When I go to the views of storage for any object (vm or cluster or host...), I have this popup "the storage service is not initialized. And windows is empty...
I am 5.5 (1891313). When I go to the State of the Service, the VMware vCenter vCenter, monitoring of Storage Service is on alert warning and show 'Service initializing... '. »
I try a lot of KB VMware, but nothing works to solve my problem. I can't find any KB explaining MY problem. The sms.log is not updated since the beginning of the problem and the sps.log show an error to the VMware vSphere Profile-Driven Storage Service service starts:
2014-07-29 13:15:39, 281 [WrapperSimpleAppMain] INFO opId = com.vmware.sps.util.impl.SpsQsConnectorImpl - connected to the query Service
2014-07-29 13:15:39, 281 [WrapperSimpleAppMain] INFO = com.vmware.sps.SpsLocalService - SPS opId subscribing to the query Service
2014-07-29 13:15:39, 281 [WrapperSimpleAppMain] DEBUG opId = com.vmware.sps.qs.SpsQsProvider - registerSpsProvider
2014-07-29 13:15:39, 284 [WrapperSimpleAppMain] WARN opId = com.vmware.vim.vmomi.client.http.impl.HttpProtocolBindingImpl - run asynchronously requested but no executor configured. The request will be executed as a synchronous.
2014-07-29 13:15:39, 293 opId [WrapperSimpleAppMain] DEBUG = com.vmware.vim.storage.common.util.UUIDFactory - server GUID in the config file - a056401d-1138-4509-931d-5d81fdaeda36
2014-07-29 13:15:39, 293 [WrapperSimpleAppMain] opId = com.vmware.sps.qs.SpsQsProvider - SPS INFO has already been registered in QS by uuid: a056401d-1138-4509-931 d-5d81fdaeda36
2014-07-29 13:15:39, 293 [WrapperSimpleAppMain] opId = com.vmware.sps.qs.SpsQsProvider ERROR - cannot save the SPS in QS:com.vmware.vim.binding.dataservice.fault.AlreadyExistsFault:
inherited from com.vmware.vim.binding.dataservice.fault.AlreadyExistsFault
2014-07-29 13:15:39, 293 [WrapperSimpleAppMain] INFO = com.vmware.sps.qs.SpsQsProvider - SPS opId was saved in the query with the GUID of the provider service: a056401d-1138-4509-931d-5d81fdaeda36
2014-07-29 13:15:39, 314 [WrapperSimpleAppMain] INFO opId = org.dozer.config.GlobalSettings - trying to find the bulldozer configuration file: dozer.properties
2014-07-29 13:15:39, 315 [WrapperSimpleAppMain] INFO opId = org.dozer.config.GlobalSettings - bulldozer configuration file not found: dozer.properties. Using default values for all of the global properties of bulldozer.
I solved the problem with VMware technical service.
I have 2 Wrapper files in "C:\Program Files\VMware\Infrastructure\Profile-Driven" of storage. Wrapper and Wrapper1.
There is a problem because some files must be in both folders. To solve the problem and use a single Wrapper file as a clean install, just uninstall VMware Vcenter Server, delete the folder "C:\Program Files\VMware\Infrastructure\Profile - Driven Storage" and reinstall. Change the connection of service "VMware vSphere based storage Service profile" to set the same service "VMware VirtualCenter Server. You must have initialized service and directory of a wrapper.
-
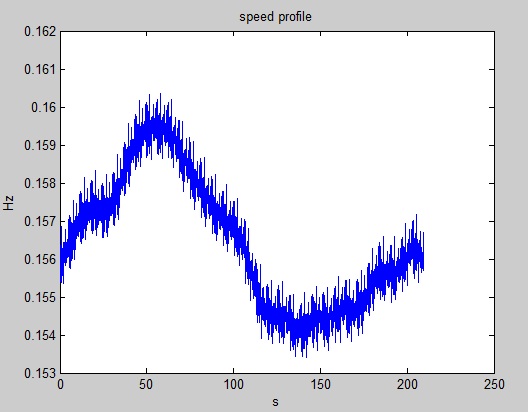
Analysis of the order - the speed profile of the data measured in Hz
Hello
When I want an analysis of order in LV, I need to have the tacho signal. I understand that I need a certain signal "TTL" where there's one pulse per turn. ___ |-| ___ |-| ___ |-| _ The period depends on the rotation speed. This signal is transformed into BT on the corner same signal and the output is signal of speed profile that will at OA blok.
However I my case I don't have the TTL of tacho signal but turn signal speed in Hz and corresponding to time values.
I know that speed is about 0.1-0.2 Hz I have 200 seconds the signal with 4000 samples of rot. Speed in Hz and corresponding to time values. I want to do the speed profile cluster that contains the time table and table RPM. My idea is to just take the time and decay values. Speed in Hz multiplied by 60 to get the RPM.
However, I am not sure about this. OSTEOARTHRITIS results seems not to be correct. Some does something like that?
Try the attached VI. There are two matrices of equal size, speed in rpm and the timestamp of the control system. It produces a continuous-time waveform that can be used with analog tachometer VI of analytical tools of enforcement.
-
How to extract a report to list all the s VM that are turned off in a cluster.
I tried to do this by adding my cluster in a new service and then, by running a report on this group, but did not.
I have to add the VM; s as well as in the service to pick up this report.
Please advise.
What version of the SOUL are you running? You need not create any service.
There is an out of the box report that you can run:


-
What priority should I put in the QOS to work with IP voice service
I have a new router Cisco RV180W and don't know which priority should I put in the high, medium, low possibility of QOS
in order to work properly with the Ip voice device.
The default values are 61, 31 y 10 but in a net with 12 PCs
I think that this configuration 61 voice Ip and only 31 to the rest of the net
is a value that is too low. This is definition 2 VLANs.
How I can well criteria to configure these values of priorities?
In the previous (a WR210 of Cisco router), the only thing that was
set up which was the Ip voice connected in Lan 2 Port number with a high priority.
I'm stuck with this matter and it should resolve quickly
Thank you very much
Daniel Di Matteo
Hi Daniel, the claim of LAN should not affect the performance of the internet. All that is on the local interconnection, make queries on the local network will not use an internet connection. So as long as your servers/computers/cameras, etc. are using Cat6 cable and are all active GigE products, it will not be a large part of the review.
But for your connection internet, you may be correct. 4/1 connection is not much.
I need you to understand however, the WAN QoS for download speed only. Is not for download speed.
You can make the profile works in 2 ways. You can keep the amount of download speed to a device or you can ensure that a device does not take more than he should.
To set up a WAN profile correctly-
QoS-> WAN QoS profiles
Choose the maximum flow
Specify your bandwidth
Save
Back to WAN QoS profiles, at the bottom there is a WAN QoS profile table, click Add. In the drop-down list, select the priority. Set the minimum and maximum bandwidth, and then click Save.
Then you have to bound the profiles for the traffic selector. Go to QoS-> binding profile
There is a service drop down choose which desired protocol
Then choose the QOS profile you had a precedent set
The last part, choose the IP address you want to assign.
You can do this individually or in sequence. If you choose to be forbidden to use a device too download so that the beginning and the IP is the same. Conversely, if you have a range of devices, you can use their IP ranges if they are consecutive.
Apply the profile, restart the router.
I hope that I wrote this clearly for you.
-Tom
Please mark replied messages useful -
I received an email on the new Microsoft service contracts, changes that will take place on 19 Oct. I did not open the link. Is it a scam?
Hello
Be VERY careful as there are a the TWO legitimate versions and the versions of MALICIOUS software
who are being sent. Best thing to do is to DELETE the email, then go to the
Microsoft sites to read information.Check this thread:
and this one:
--------------------------------------------------------------------------------------------------------
Here are the legitimate links to information in the email.
http://Windows.Microsoft.com/en-us/Windows-Live/Microsoft-services-agreement
http://www.microsoft.com/en-us/default.aspx
http://privacy.Microsoft.com/en-us/default.mspx
I hope this helps.
Rob Brown - Microsoft MVP<- profile="" -="" windows="" expert="" -="" consumer="" :="" bicycle=""><- mark="" twain="" said="" it="">
-
RAC services with server pools
Env: DB 12.1.0.2. | 4 node RAC cluster | OEL 6.x
All-
I'm working on a successful political VINE of the test databases. I think that is what Oracle recommends to go forward.
One of our enviornment product runs on 4 node RAC cluster (11g) and we use partitioning/Application Isolation.
1 to 3 knots: are used for the OLTP workload by using services
Node 4: is used for batch jobs/reports
We request for Isolation/segregation has helped to stabilize the RAC environment and we could avoid the famous CARS/Cluster waiting for questions.
While gong through documentation, I understand that we have only 2 options when configuring services with Pool. It can be UNIFORM or SINGLETON. I understand the server pools help a lot and make life easy for DBA (and that's why we have initiative to test)
but I couldn't know if the partitioning Application can be reached.
With Singleton services - we are not sure on which service instance will run. We cannot set specific settings for instance, which promotes the batch jobs/Heavy Reporting (great PGA may be increased multi block / County, if it is automatic and there could be several parameters).
And we cannot define same service that suppose to run on a subset of the Cluster, for example:-OLTP service that runs on 3 nodes.
Please help me clarify my doubts.
Thank you very much!
I do not understand your question, it looks pretty we would apply.
For example, if you want your service to run at three knots, OLTP problem: create a pool OLTP, place the four inside servers and specify min = 1 max = 3. Then create a second pool called lot, new place all four inside servers and specify min = 1 max = 1. Assign the database for two pools, and the services of a pool each, as uniform.
I have been using political management databases for many years and considered flexible enough. I never understood reluctance of others to use it.
-
Status of the services: "EXISTS".
I'm trying to set up vRA 6.2 distributed. When I open the configuration of device on the port 5480 page it shows some services such as "EXISTS". I am not able to understand the real meaning of this message.
Anyone had seen this kind of behavior?
Screenshot below comes from the vRA primary device.

After some tests, I got to the root of this problem. I used postgres cluster and both nodes are active in load balancing. When I removed the node passive cluster postgres and restarted services, all services properly registered.



Maybe you are looking for
-
Cursor my laptop Vaio jumps. Does anyone have a solution?
Anyon has had problems with the cursor jumps while typing?
-
Question about video drivers Satellite P100-257
Hello.Question about video driver. Version 14.25... Works (tells... 945 GM chipset); 14.27--works but with ocassional problems (tells... 945GM/GU); version 14,29... (said 945GM/GU) - does not work at all - black screen, but you can hear sounds which
-
HP G61 - 110SA Notebook PC: Bluetooth disappeared
Hello & help! Re: HP G61-110SA laptop PC I just bought a wireless headphones (Philips headset stereo Bluetooth SHB4000) but I am unable to get them to connect to my laptop (they connect fine on my phone if this isn't a problem with the headphones). I
-
How to get rid of the small shield on my shortcut icons?
Hi all.There was a small picture of shield on my icons.I know that they are to remind me that the programs need administrator privileges to run.But, is there a way to get rid of it? I don't want that appear on my beautiful icons.I tried to disable UA
-
I do not want my files engraved in alphabetical order
I'm burning files to a cd, & he keeps putting it in alphabetical order. How can I keep them in the order I want