Put the data store in the Cluster data store (StoragePod)
Hello
Try to a data store in a data cluster store, but the attribute VcDatastore.parent is ready, what is the best way to do this?
Thanks in advance.
Try stoargeCluster.moveIntoFolder_Task (arrayOfDatastoresToAdd);
Tags: VMware
Similar Questions
-
After putting the Cluster and ASM is in place, I'm not able to start the ins RDBMS.
I'm not able to bring up the database.
Cluster and ASM is running.
ORA-01078: failure in the treatment of system settings
LRM-00109: could not open the parameter file ' / oracle/app/oracle/product/11.1.0/db_1/dbs/initTMISC11G.ora'It seems that it is a spfile to-spfile = +DATA_TIER/dintw10g/parameterfile/spfile_dintw10g.ora
Now you must create a binding O_H/dbs/spfile .ora
pointing to +DATA_TIER/dintw10g/parameterfile/spfile_dintw10g.ora and try to start the database.
-
remove the Cluster data store data store
I have an infrastructure with vCenter and ESXi 4 5.5 I have a data cluster store in SAN with 8 Mon, I need to remove 3 Lun (to be used for other purposes) what is the appropriate procedure
to remove the Lun (end then to destroy)? Thank you
Do you want the LUN to use for purpose of non-vSphere? If so, you can just storage vMotion virtual machines since associated LUN data warehouses that you want to decommission (or simply putting the data store in maintenance mode, in this way, that the virtual machines will automatically be migrated). Cleaning after the data store, move the data store from the cluster data store, and then delete the VMware environment data store as described here: best practices: how to properly remove a unit number logic of a host ESX - VMware vSphere Blog - VMware Blogs
-
How to select the cluster/resourcepool data store?
Hello
as you know others my son, I'm working on a workflow to create several identical virtual machines on a VC-cluster.
At this time a virtual computer is created like this:
task = vmFolder.createVM_Task( configSpec, vmCluster.resourcePool);
Context is being filled with the configuration of the virtual machine. vmCluster is a workflow input parameter and contains the cluster.
It works well, but I still have to specify the data store to store files on a different input parameter, because the cluster has several shared storage units.
Note also that our clusters have only a single pool of resources, the default.
Let the user select a data store is not a very nice solution because of possible errors and mistakes (the user can select the local drive of the VMHost, lack of space on the storage selected etc..). But I, as a developer, also can not predefine the storage to use (several storage units, unit of different names etc.).
Now, what I've been thinking about (and trying to implement) was to get the vmCluster data warehouses or the resourcePool, check if they are put in place for the virtual machine files and if they have enough space for the virtual machine.
I know how to check the size and which storage are to be used for virtual machines, but I don't know how to get out them of the cluster/resourcepool.
Can someone help me with this?
Thank you and
Concerning
Andreas
PS: Is it just me or I really make things complicated with orchestrator here?
Hi Andreas,
One way to get the value of storage of data is to use VcSdkConnection.getAllDatastores
For more information, see here: http://www.vmware.com/support/orchestrator/doc/vco_vsphere41_api/html/VcSdkConnection.html#getAllDatastores
Personally, I have not played with it, but it seems very powerful.
There is discussion on the use of xpath in such a case in this topic (to get the value of VMs): http://communities.vmware.com/message/1673575
Other than that you could:
-use VcSdkConnection.getAllClusterComputeResource (gets all clusters) or VcSdk.getAllResourcePools
-in case you work with clusters - each cluster's data store property that returns an array of data for this cluster warehouses
-in case you use pools of resources, you must check that is the parent of each resource pool and get its data warehouses.
Kind regards
-Martin
-
Issue of SDRS to vCloud Director after you add the new data store to the Cluster of DTS
Hi people,
We use vCloud Director 5.5 in a vSphere full 5.5 environment.
We have several DTS Cluster in vSphere and connected to vCloud Director.
Following problem.
When I add a data store to a Cluster of DTS and connect this to the corresponding storage profile data store, the storage profile is not available to vCloud Director more.
After removing the new store data in the cluster of DTS, the profile becomes available again.
Any ideas?
Concerning
Jean
How did you the storage profile associated with the data store? via c# client or vSphere web client?
If you did the wrong way (c#) there no storage class label appropriate against it.
A data cluster store has the storage class who would have all preparations of data contained inside.
I think that you should check the service class is associated properly in vSphere web client (before adding to the DS Cluster). Once it displays correctly, and then add the data store to the cluster.
-
Use the case of the Cluster data without DRS storage store?
Can someone tell me please the use case of the Cluster data without DRS storage store?
Virtually no,.
The only one that is useful is the aggregation of resources of data warehouses in a cluster data store. But it is aggregation of resources in its crudest form. When you create a virtual machine and the use of a cluster as the destination data store, you must always select the data store that will store the virtual machine.
Storage DRS off =
No calculation of initial investment
No space load balancing
No I/O load balancing
No rule affinity VMDK
No maintenance mode
For this purpose a group of data without active DRS storage store is a kind of a data store folder.
-
Add the host Cluster in the Cluster data store
How can I add host/HostCluster in the Cluster data store after the cluster data store is created. I know that we can add at this time, when you create the cluster data store, but how can we add it as soon as it is created?
I think that as long as the new host has access to all the LUNS that comprise data warehouses in the cluster data store, then no further action is necessary.
Make sure just that if using CF then zoning is configured correctly and the LUNS are not hidden from the new host.
Also, make sure you restart the analysis for new data warehouses on your new host so that it can detect data warehouses
-
HA will only work if I share NFS data store in the cluster
Hi all
Please help me with my question below?
HA work if I share NFS data store in the cluster? Even if if works is it advisable?
Thank you
Lucette
Yes, but a VM restarts on a host within the same cluster VMware only.
-
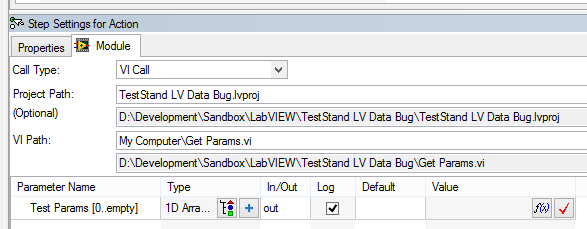
[BUG] TestStand 2013 receives corrupt data to LabVIEW adapter if the cluster contains waveform array
Hi all
I am having trouble with the corruption of the data. My minimal test case is below.
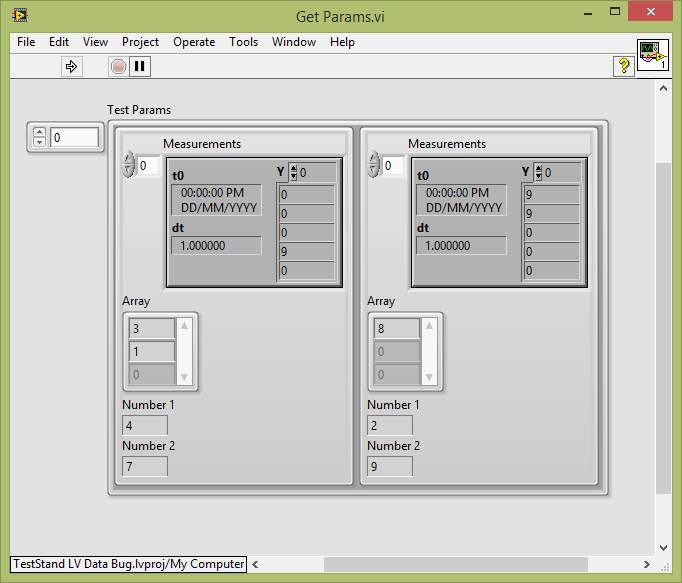
I have a VI that returns an array of clusters. My TestStand sequence simply call this VI and connects to its output:
When I run the (with my open VI) .seq file, I can see the update of the Panel before LabVIEW with expected values:
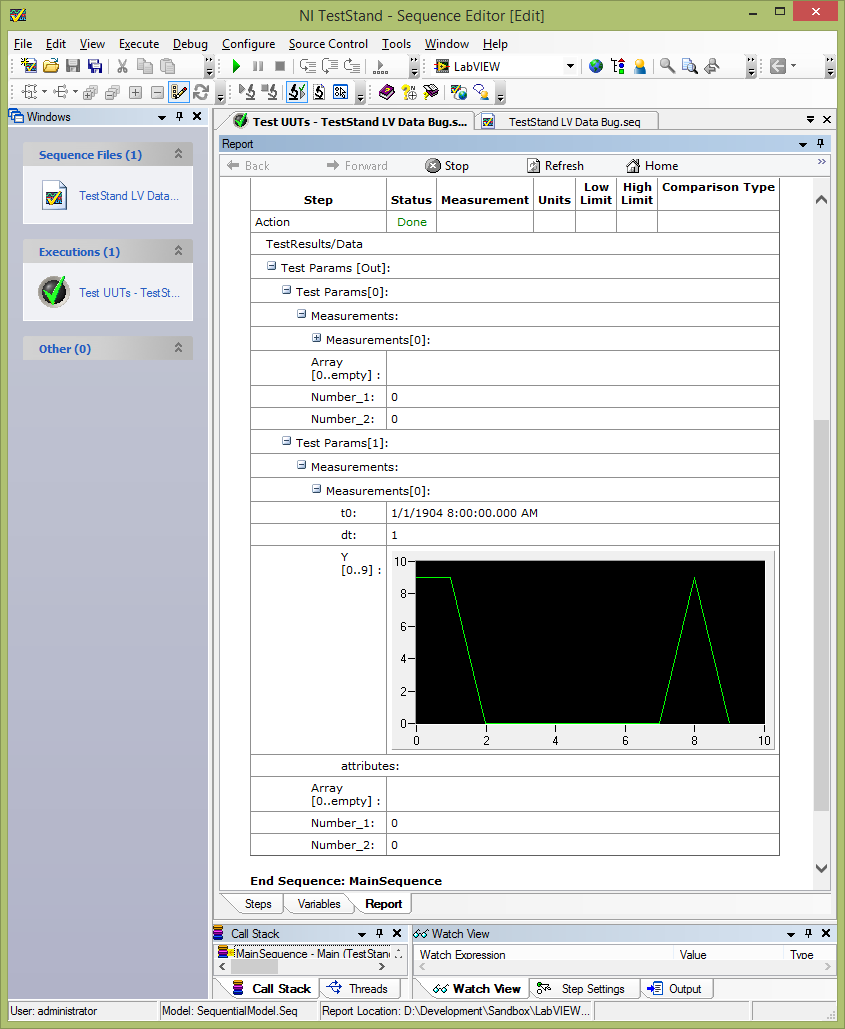
However, TestStand receives all these values. Waveform bays have the correct values, but everything else is empty / null:
If I delete my typedef waveform table, all elements of the cluster are correctly registered by TestStand.
I've attached an example of test (2013 TestStand, LabVIEW 2013) case.
Any ideas on how to make it work?
Hey JKSH,
Thanks for the detailed on this report. I looked into it a little bit last week.
I think that it is closely related to the 206892 of CAR, which describes a problem where data will not appear on the report unless a property or variable is specified for the output waveform parameter. However, this does not completely cover your case, because you see incorrect digital data in the row with the waveform of your cluster. I filed 462209 CAR for that matter, and we will investigate it more thoroughly.
This problem only affects data that appears "below" the waveform in the cluster. In the case of the sample, if you put the waveform as the last element of the bunch, I think that it works correctly. I know that your real data could be more complex than this example, but this workaround solution would help in the meantime? You could also consider separating the waveform of the rest of the data, that would probably work too.
As I said, please let us know, and it is classified in our system now for a developer to investigate the matter. Please let me know if solutions are not appropriate for your application, we would be happy to know a little more about your overall use case order to work around the problem.
-
Convert a table 1 d of the Cluster (time + data) in 2D-table time and data. How?
Hello
is there a simple way to convert a large table 1 d of the Cluster (containing a timestamp and a given) in a table 2D with time stamp and data?
I could index the table in a while loop, separate each item and put the timestamps and the data in a new table.
The format of the new table could be an array of double (then the timestamp must be converted to a double) or an array of strings.
Could I do this without a loop?
Johannes
LabVIEW 7.1 (!)
Hi Johannes,
If it is possible to manage your time as dbl-floats stamps, I suggest using a simple loop and the cluster to function array (Cluster_to_Array_Mod1.vi).
If you want to stay with time stamp data type, even once use a loop for a cluster unbundle and build the function array (cluster_to_array_Mod2.vi).
Kind regards
Thomas
-
Hello
I wanted to collect script inventory VM VM name with location, name of the Cluster and data store total size and free space left in Datastore.I have script but his mistake of shows during its execution. Any help on this will be apreciated.
Thank you
VMG
Error: -.
Get-view: could not validate the argument on the parameter "VIObject". The argument is null or empty. Provide an argument that is not null or empty, and then try
the command again.
E:\script\VM-DS-cluster.ps1:7 tank: 20
+ $esx = get-view < < < < $vm. Runtime.Host - name of the Parent property
+ CategoryInfo: InvalidData: (:)) [Get-view], ParameterBindingValidationException)
+ FullyQualifiedErrorId: ParameterArgumentValidationError, VMware.VimAutomation.ViCore.Cmdlets.Commands.DotNetInterop.GetVIViewGet-view: could not validate the argument on the parameter "VIObject". The argument is null or empty. Provide an argument that is not null or empty, and then try
the command again.
E:\script\VM-DS-cluster.ps1:8 tank: 24
+ $cluster = get-view < < < < $esx. Parent - the name of the property
+ CategoryInfo: InvalidData: (:)) [Get-view], ParameterBindingValidationException)
+ FullyQualifiedErrorId: ParameterArgumentValidationError, VMware.VimAutomation.ViCore.Cmdlets.Commands.DotNetInterop.GetVIViewGet-view: could not validate the argument on the parameter "VIObject". The argument is null or empty. Provide an argument that is not null or empty, and then try
the command again.
E:\script\VM-DS-cluster.ps1:9 tank: 24
+ += get-view $report < < < < $vm. Store data-name of the property, summary |
+ CategoryInfo: InvalidData: (:)) [Get-view], ParameterBindingValidationException)
+ FullyQualifiedErrorId: ParameterArgumentValidationError, VMware.VimAutomation.ViCore.Cmdlets.Commands.DotNetInterop.GetVIViewIt seems that your copy/paste lost some
. I have attached the script
-
I put my date of January 1, 1970 and as soon as I rebooted my iPod (6th generation) he never returned to my home screen, but instead, he stayed on the apple logo. I tried to drain the battery, but he always did. I even connected it to my computer and put it in DFU mode to reset, but it froze at a very small percentage of loading and no progress has been made.
Given that the DFU mode does not work, then
If you have this problem,contact Apple technical support.
-
Is it possible to recover the cluster labels in the data of the class?
Is it possible to recover the cluster labels in the data of the class?
I'm looking to use the labels of the cluster in the class data to build an insert sql on a mysql database. I am currently doing this way by using a cluster control, but it becomes big enough and I want to reorganize.
Thank you
Zac
-
Initialize the cluster with data types different (lots of data)
Hello
I have data, which are composed of different data types. First of all, I have initialize cluster with these types of data and then "print" to light (photo). In case of photo data carries 8 characters than ja 4 floats. It was easy to initialize, but here's the question: How can I do this even if I have data that look like this (interpreter):
floating point number
name char [32]
Short value [16]
What I create loooong cluster which have a fleet of 32 characters, 16 short films? Or I can create these 'paintings' in a different way?
THX once again

-Aa-
I suggest using the table-cluster and configuration of the cluster size to match the size of your berries, then package these groups together. In terms of storage of LabVIEW, there is no difference between a group of
floating point number
Name1 tank
name2 tank
...
short value1
short value2
...
and a bunch of
floating point number
-> cluster shipped from
Name1 tank
name2 tank
...
-> cluster shipped from
short value1
short value2
So you can use the cluster table to get the right sizes rather than individually create all these values in a single giant cluster.
-
Default password Machine virtual XP Mode
I've set up the virtual machine in win 7 Ultimate and put some data. Now when I try to connect it asks password and does not accept any password. Please giveme the default passwordIf you're talking about XP Mode the default password is XPMUser. In general you can not use Windows without a password in Windows Virtual PC that you can with Virtual PC 2007 and before. XPMUser is used only with the XP Mode virtual machine. All other virtual machines requires a user created password. If you have changed the password in XP Mode and forgotten, then you have to start over.
Windows Virtual PC is based on virtual server rather than VPC and all virtual machines need a password. If necessary, uninstall the integration features, start the virtual machine and create a password for the admin user. Restart the virtual machine, and then reinstall the integration features. You will not be able to access a virtual machine created by the user that has no password, while the integration features are installed. Once you have everything right, that a virtual machine will not be asked a password if you are the admin user in Windows 7.
@george1009,.
Everything got? :)
-
The problem of the distribution of the data in the cluster of NoSQL Oracle databases
Hello
I write (about 10 G) data in an Oracle Databae NoSQL cluster (which consists of three nodes: ud1, Node2, node3). It has only one table in the DB and I create an index on a field.
The amount of data in each node is about 16G.
Then I write the same data (about 10G) in an Oracle NoSQL Database (Only one node) and I create an index on the same lot.
But the amount of data is about 46G.
So I assumed that each node holds no data complete. Then if the failure of a node, the cluster can still work but some data cannot be queried. Am I wrong?
There is an intersection in the form of database on each node?
You should take a look at the documentation. For example:
http://docs.Oracle.com/CD/NoSQL/HTML/AdminGuide/introduction.html
-mark
Maybe you are looking for
-
When I click on edit and then click on find that nothing happens
I use firefox 25 in windows 7. Recently, perhaps since the last update, when I click on 'Edit' and then click 'Search', nothing happens, or does it work ctrl + 'f '...
-
Firefox 3.6 - realplayer streaming capture is not available
I can capture is no longer streaming with realplayer videos. This has happened Don't know how many times Is today (25 June 2010)
-
I need to remove windows sign in assistant so I can reinstall windows live
I already posted a problem with movie maker with a problem I can not remember the error code as I deleted it, but what happened was when I open movie maker a box pops up with a code 0x00 and said that I had to restart but when I closed this filmmaker
-
Possible to use labview with daq system not of NOR?
Hello I have a daq system and the software from another company that NEITHER. But I want some changes in the software. If the opportunity was to make a new program with Labview. Is it possible to use the old system of data acquisition? Is this compat
-
Someone else then reading pages have normals of the gaze and then some will be super great with a weird format. Difficult to read.