Questioning REGEXP_SUBSTR, regular expressions
With the expression below, I expect to come back the first 4 words and do not understand why it is not doing.
db > select regexp_substr('This is a sample text string', '([[:alpha:]]+){3,4}') from dual;
REGE
----
This
This works as expected.
db > select regexp_substr('This is a sample text string', '([[:alpha:]]+ ){3,4}') from dual;
REGEXP_SUBSTR('TH
-----------------
This is a sample
Hello
Solomon Yakobson says:
Frank Kulash wrote:
If you are looking for 3 or 4 instances of 1 or more letters, without anything in addition to the letters between them. Any group of 3 or more consecutive letters matches. For example,.
- "Th" as the 1st appearance of 1 or more letters,
- 'i' as the 2nd appearance of 1 or more letters, and
- of ' as the 3rd appearance of 1 or more letters
is a substring that matches the pattern you described.
In fact T is the 1st appearance of 1 or several letters, h is the second, I ranked third and s are defined. Otherwise:
SQL > select regexp_substr ('the following is an example of text string', ' ([[: alpha:]] +) {3,4}') of the double
2.REG
---
TheSQL >
returns no rows.
Not that it is important for the OP's question, but I think the way I presented it is more precise.
How can tell us if 'This' match of the 4 occurrences (all 1 character) or 3 occurrences (1 with 2 characters and 2 with 1 character each)?
In more general terms, when we say something like
(expr +) {x, y}
is '+' more greedy than "{x, y}.
It seems to me that '+' is dishonest in this case. Consider this query:
WITH sample_data AS
(
SELECT "This is an example of text string" dual UNION ALL STR
SELECT 'the following is an example of text string' FROM dual UNION ALL
SELECT 'Fubar' double UNION ALL
SELECT 'chat' FROM dual
)
SELECT str
REGEXP_REPLACE (str
, ' ([[: alpha:]] {1,2})([[:alpha:]]+) ([[: alpha:]] +)([[:alpha:]]+)?'
, "\1=1;\2=2;\3=3;\4=4".
) And matches
OF sample_data
;
which produces this output:
STR MATCHES
------------------------------------- ------------------------------
This is an example of text string Th = 1; i = 2; s = 3; = 4 is a samp = 1; l =
2; e = 3; 4 = = you 1; x = 2; t = 3; = 4 = stri
1; n = 2; g = 3; = 4
The following is an example of text string T = 1; h = 2; e = 3; = 4 followi = 1; n = 2; g
= 3 ; = 4 is a samp = 1; l = 2; e = 3; = 4 t
e = 1; x = 2; t = 3; = stri 4 = 1; n = 2; g = 3;
= 4
Fubar Fub = 1; a = 2; r = 3; = 4
cat c=1;a=2;t=3;=4
In this case, '+' appears to be labels as "{3.4}.
I don't have not seen this documented anywhere, but it seems it's because + gets to go first in the model. In other words, there is nothing to inherently rapacity on ' + '. If we change the first '+' above "{1,9}", like this
WITH sample_data AS
(
SELECT "This is an example of text string" dual UNION ALL STR
SELECT 'the following is an example of text string' FROM dual UNION ALL
SELECT 'Fubar' double UNION ALL
SELECT 'chat' FROM dual
)
SELECT str
REGEXP_REPLACE (str
, ' ([[: alpha:]]{1,9}) ([[: alpha:]] +) ([[: alpha:]] +)([[:alpha:]]+)?'
, "\1=1;\2=2;\3=3;\4=4".
) And matches
OF sample_data
;
the result remains the same.
Of course, is using the first query I posted above
(expr) (expr) (expr) (expr)?
It is possible that
(expr) {3,4}
which is what OP posted, is handled differently.
Tags: Database
Similar Questions
-
Another question about regular expressions with String.matches
don't match String.matches () method expressions when a substring of the string matches, or must match the whole string? So if I have the string '123ABC', and I ask match "1 or more letters" will be it fail because there are other that the letters in the string, but then spend if I add "1 or more letters AND numbers 1 or more? Thus, in the second case each character in the string is recorded in the research, as opposed to the first. Is that correct, or are there ways to JUST matching a substring in the string instead of all this? I'll do some examples too... but that makes sense?It must match the entire string. Use Matcher.find () to match on just a sub-string)
-
REGULAR EXPRESSION - names of Split.
Hello guys,.
I have a question about regular expressions. Here are some names:
WITH T AS ( SELECT 'Bill CLINTON' as name FROM dual UNION ALL SELECT 'Christiano RONALDO' FROM dual UNION ALL SELECT 'Barack Hussein OBAMA' FROM dual UNION ALL SELECT 'JUAN JOSE Miguel Ange' FROM dual UNION ALL SELECT 'Miguel Ange JUAN JOSE' FROM dual UNION ALL SELECT 'RONALDO Christiano' FROM dual ) SELECT name FROM t;
I want to break this chain. I want something like that
RESULT: Bill CLINTON Christiano RONALDO Barack Hussein OBAMA Miguel Ange JUAN JOSE Miguel Ange JUAN JOSE Christiano RONALDO
Is this possible? Any idea?
Thank you guys
This works with your data, but as Frank said, much more unusually still exists:
SQL> WITH T AS 2 ( 3 SELECT 'Bill CLINTON' as name FROM dual UNION ALL 4 SELECT 'Christiano RONALDO' FROM dual UNION ALL 5 SELECT 'Barack Hussein OBAMA' FROM dual UNION ALL 6 SELECT 'JUAN JOSE Miguel Ange' FROM dual UNION ALL 7 SELECT 'Miguel Ange JUAN JOSE' FROM dual UNION ALL 8 SELECT 'RONALDO Christiano' FROM dual UNION ALL 9 -- 10 SELECT 'M''BONGO Jesus' FROM dual UNION ALL 11 SELECT 'Jesus M''BONGO' FROM dual UNION ALL 12 SELECT 'Jean-Baptiste POQUELIN MOLIERE MANY OTHER NAMES' FROM dual UNION ALL 13 SELECT 'Jean Michel JARRE' FROM dual UNION ALL 14 SELECT 'JARRE HEAD Jean Michel' FROM dual 15 ) 16 SELECT rtrim(regexp_substr(name, '([[:upper:]'']{2,}[ -]*)+')) as last_name 17 , rtrim(regexp_substr(name, '([[:upper:]][[:lower:]]+[ -]*)+')) as first_name 18 FROM t; LAST_NAME FIRST_NAME -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- CLINTON Bill RONALDO Christiano OBAMA Barack Hussein JUAN JOSE Miguel Ange JUAN JOSE Miguel Ange RONALDO Christiano M'BONGO Jesus M'BONGO Jesus POQUELIN MOLIERE MANY OTHER NAMES Jean-Baptiste JARRE Jean Michel JARRE HEAD Jean Michel 11 rows selected. -
regexp_substr: a regular expression for the separate comma operator of witn of string literals IN
The following regular expression separates simple values separated by commas (SELECT regexp_substr (: pCsv,'[^,] +', 1, level) FROM DUAL CONNECT BY regexp_substr (: pCsv, ' [^,] +', 1, level) IS NOT NULL); Exampple: 300100033146068, 300100033146071, 300100033146079 returns 300100033146068 300100033146071 300100033146079
This works very well if we use the regex with SQL IN operator select * from mytable where t.mycolumn IN (SELECT regexp_substr (: pCsv,'[^,] +', 1, level) FROM DUAL CONNECT BY regexp_substr (: pCsv, ' [^,] +', 1, level) IS NOT NULL);
But this query does not work if the comma-separated value is a single literal string 'one', 'two', 'three '.
Thanks for your reply. my request was mainly on regexp_substr. Need to request was simple: any table with a column of varchar type can be used. Next time I'll give you an example.
All ways working answer for my question is is SELECT regexp_substr (: pCsv,'[^, "] +', 1, level) FROM DUAL CONNECT BY regexp_substr (: pCsv, ' [^,"] +', 1, level) IS NOT NULL
-
Regular Expression search and replace question - please help!
I was wondering if someone could help me I have a lot of paper with notes like this: [1], but I need them to look like in this [1].
I don't know what to put in the section find [[\d]*] , but I need help with what to put in the field replace to make < sup > numbers]
In fact, your regular expression is false. What you need is the following:
(\[\d+\])
The field replace must contain this:
$1
-
I have a large body of text that I am breaking into individual words (as part of an experimental project of indexing).
I can break the text into a list in a paragraph break for each word space (a simple find and replace).
But I want proper nouns to stay intact.
So I'll try to write a script of the regular expression that finds all occurrences of two contiguous words that begin in a capital letter, then replace the space between the two words with an underscore.
Sigmund Freud becomes Sigmund_Freud.
Does anyone know how I would write this script?
Thank you!!!
You don't need a script, you can do it in the interface:
Search: (\u[-\w]+)\x{20}(?=\u[-\w]+)
Change: $1_
\u[-\w]+ is the abbreviation of "letter followed capital one or more of the characters dash/word"; This is the first name.
\x{20} refers to the space.
followed by an another \u[-\w]+, the family name. This one is in an advanced search, so the whole expression paraphrases that "find a word that begins with a capital letter followed by a space if it is followed by another word beginning with a letter from the uc.
Peter
-
Regular Expressions of Drivng me crazy!
Oracle Version 11 GR 2
Scripts of test data
CREATE TABLE REGEX_TEST
(ID NUMBER 4,
VARCHAR2 (50) COMMENTS
);
Insert into REGEX_TEST (ID, COMMENTS) values (1, "< Little Red Riding Hood > #title");
Insert into REGEX_TEST (ID, COMMENTS) values (2, "#title < Little Red Riding Hood > #publisher < Penguin >");
Insert into REGEX_TEST (ID, COMMENTS) values (3, ' #title < Little Red Riding Hood > #publisher < Penguin > #pages < 30 > ");
Congratulations to Frank Kulash to provide the following SQL to clean the field of comments only properly marked the text in the field
Properly tagged text is defined as
Start by #.
then nameOfHashTag
then < valueOfHashTag >
The number or name of hashtags is variable and is not known at design time
The Frank provided SQL is (with a slight mod)
Original, SELECT comments
REGEXP_REPLACE (comments
, '(^|>)[^#.*<]*'
"\1") that cleaned
of REGEX_TEST;
Source language CLEANED #title < little Red Riding Hood > #title < little Red Riding Hood > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > FIRST QUESTION: I understand the [^ #. * <] * component - search for zero or more occurrences of anything that is not a # tracking of zero or more characters, then a < and I understand the () sets a capturing group, but I don't understand how it works - 1 is probably a reference to the Group?
Now, I add a few more - lines to see how he treats badly marked text that is
void <>
text that is not marked
text is not enclosed by sharp hooks
Insert into REGEX_TEST (ID, COMMENTS) values ('4, #title <>");
Insert into REGEX_TEST (ID, COMMENTS) values (5, "#title <>#publisher < Penguin >");
Insert into REGEX_TEST (ID, COMMENTS) values (6, "#title < Little Red Riding Hood > text that isn't marked < Penguin > #publisher");
Insert into REGEX_TEST (ID, COMMENTS) values (7, "#title oops I forgot #publisher < Penguin > rafters").
Original, SELECT comments
REGEXP_REPLACE (comments
, '(^|>)[^#.*<]*'
"\1") that cleaned
of REGEX_TEST;
Source language CLEANED #title < little Red Riding Hood > #title < little Red Riding Hood > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > #title <> #title <> #title <>#publisher < penguin > #title <>#publisher < penguin > #title < little Red Riding Hood > text that is not signposted #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #title oops I forgot the #publisher < Penguin > rafters #title oops I forgot the #publisher < Penguin > rafters SECOND QUESTION: Is there any way I can specify that the <>cannot be empty - I played a bit with the +? but impossible to get what I want. Similarly, the latter (without text no sharp hooks)-I guess this would be impossible because you don't know if it was wong, until you have met the # next date you would be somehow to follow back and ignore the whole group.
I learned two things in this
1. regular expressions are extremely powerful
2. but they will drive you crazy?
Once again thanks a lot for the help
BTW - I managed to do what I had to do it using a lot of PL/SQL code, but not very fast!
Hello
So, you want only the substrings that are well-formed attribute/value pairs (attribute or value may be missing). You want to ignore anything in the comments that is not part of a well-formed pair.
It is not very difficult to get a single well-formed pair. The problem is that there is no good way to say 'everything that is not part of a well-formed pair '. One solution is to extract from each pair trained well on a separate line and then re - combine them into a single string by id, like this:
WITH split_data AS
(
SELECT id
comments
REGEXP_SUBSTR (comments,
, '#' || -sign #.
'[^<]+' || ="" --="" 1="" or="" more="" of="" any="" characters="" except="">
'<' || ="" --=""><>
'[^>]+' || -1 or several characters any except >
'>' -- > sign
1
LEVEL
) AS well_formed_pair
LEVEL AS pair_num
OF regex_test
([LEVEL CONNECTION <= regexp_count="" (comments,=""> <> <[^>] + > ')
AND PRIOR id = id
AND PRIOR SYS_GUID () IS NOT NULL
)
SELECT id
commented THAT the original
LISTAGG (well_formed_pair) WITHIN GROUP (ORDER BY pair_num)
THAT cleaned
OF split_data
GROUP BY id, comments
ORDER BY id
;
The 2nd argument of REGEXP_SUBSTR above is actually the same as the 2nd argument of REGEXP_COUNT. I wrote one of them in a more detailed form, hoping to make it clear what happens if has been done. You can write an expression so be it.
The result is just what you asked:
ID CLEANED ORIGINAL
--- ---------------------------------------- ---------------------------------
1 #title#title 2 #title
#publisher #title #pu
blisher 3 #title
#publisher #title #pu
#pages<30> blisher #pages<30> 4 #title<>
5 #title<>#publisher
#publisher 6 #title
#title #pu text
is not marked #publisherblisher 7 #title oops I forgot that the rafters whoops # #title forgotten angle br
Editorackets #publisher -
pattern by using regular expressions match
I'm playing (and wrong) with regular expressions
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + > ') twice;
give < PSN > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.2 ') twice;
give < 231 > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.3 ') twice;
give < ABc > which confused me until I realized that < 3 25 > has not been matched, because it has a space inside
so I changed it to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ', 1.3) twice;
who gave a syntax error, so I changed it again to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ') twice;
that works, but gives < PSN > / # < 231 > # < 3 25 3 > / < ABc >
I guess because the. * corresponds to anyting that all but the last closure >
The question I have is how can I retrieve the text of mounting bracket included (even if it has multiple spaces)?
Hello
9c5dfde3-EAAE-45A7-80a1-bba8a71c826c wrote:
Thanks for that - is there a way to return all 4 surrounded by extracts of <> without resorting to PL/SQL?
Of course;
REGEXP_REPLACE (str
, '(^|>)[^<>
, '\1'
)
Returns a copy of str with all outside rafters removed, for example
<231><3 25=""> . It doesn't matter how many pairs of sharp hooks - there is.
-
The regular expression Dilimit
How can I delimit the regular expression with the number sign (#) and then use an apostrophe in the expression.
Can someone give some explamples.
As regular expressions are placed in quotation marks, and I have an apostrophe in a string also how would I be able to specify the regular expression with a sign by dilimiting #.
Thank you
Published by: LostWorld Sep 15, 2010 05:40Hello
Not sure I understand the question you are faced with, but I think using q citing might help:
SQL> with t as ( 2 select 'abcd ''1234''' str from dual) 3 -- end of sample data 4 select str, regexp_substr(str, q'#'1234'#') str from t; STR STR ----------- ----------- abcd '1234' '1234'The symbol # now includes the string in the example above.
You can view the documentation for more information in the link below:
http://download.Oracle.com/docs/CD/E11882_01/server.112/e17118/sql_elements003.htm -
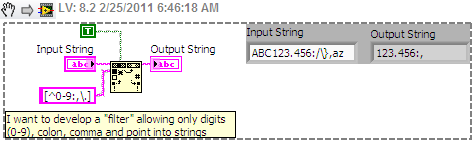
Allow specific characters - Regular Expression
Hello everyone
I am new to the regular expression and I have a very simple question. I use the function "read from the text file" to load a file delimited by tabs with 3 columns in my VI. Then, the string is converted to table and I use the values.
Nevertheless, I would like to develop a "filter" that allows only digits (0-9), colon, comma , and point to strings.
Using the function "matches regular expression", I tried a regular expression like this:
[^ 0-9] | [^\]. [|^:]| [^,]
But it does not work.
Could someone help me with this problem?
Thank you
Dan07
Use search and replace with regular Expression String selected.
-
Can I do regular expressions or Boolean logic in the search?
Can I do regular expressions or Boolean logic in the search? (Windows + F) Suppose I want to search pdf files or text files. I can go * .txt | * .pdf?
I searched for about an hour for a simple answer to this and this is the closest, I came, but it still not answering the question.
Can I use expressions simple boolian in instant search and if yes what are.
I think that AND and WOULDN'T cover 90% of what I want.
I want to search for emails for things such as [Minutes AND project x]
Currently, this property returns all the messeges with minutes and all messages with project x.
Since I have minutes of many projects, and many emails with project x not the minutes that returns are many. I would use a simple AND to get the intersection.If and expression exist, I have found no reference to it.
According to me, the back had these expressions in the search function.
Thank you
-
regular expression for the xml tags
Dear smart people of the labview world.
I have a question about how to match the names of xml text elements.
The image that I have some xml, for example:
Peter 13 and I want to match all of the names of elements, that is to say: no, son, grandson, age, regardless of any attribute have these items. There is a regular expression, I can loop, that can do this? (Something like "\<.+\> ". "") It is no good because it matches the entire xml string.) I'd really only two different expressions, one for the match start elements, e.g.
and one for the correspondence of the elements, for example. Thanks for your help in advance!
Paul.
The site Of regular Expressions will be very convenient.
They have some good tutorials on regexp with a demo of the XML tags:
Here is a small excerpt:
The regular expression <\i\c*\s*>matches an opening of the XML without the attributes tag corresponds to a closing tag. <\i\c*(\s+\i\c*\s*=\s*("[^"]*"|'[^']*'))*\s*>corresponds to an opening with a number any attributes. Put all together, <(\i\c*(\s+\i\c*\s*=\s*("[^"]*"|'[^']*'))*| i\c*)\s*="">corresponds to an opening with attributes or a closing tag. (source)
If you want advanced XML analysis I suggest JKI XML toolkit.
Tone
-
Regular Expressions do not work
With the help of sensors 4.X, VMS2.2
It seems that the normal regualar expressions are not accepted as valid by CiscoWorks. Example:
If I wanted to match for "Red Duck", but the number of spaces between each letter had to be 0-5 I would use spaces:
[R] {0-5} e [] {0-5} [d] {0-5} D {0-5} [] u] {0-5} [c] {0-5} k [] {0-5}
That the expression would be: R e d D uc k, Red D u c k and similar.
Why they are not allowed in String.TCP?
SO the question is, WHERE can find a list of regular expressions ACCEPTED, that works with sensors 4.X. I found a list that works with 3.X sensors... it did not work at all. Here, any help would be great.
Eric
Duck of red in google returns as red + duck in Google. Space will be replaced by a plus (+) sign or % 20 as it goes over HTTP (the browser for this).
The regular expression must be (including breaks):
[Rr] [+] * [Ee] [+] * [JJ] [+] * [JJ] [+] * [Uu] [+] * [Cc] [+] * [Kk]
You can't repeat a pattern of three characters like [%] 20.
-
Chips with 3 delimiter characters using regular expressions
Hello world
I have a function that is able to mark the input in a collection string using regular expressions.
In case the input string is a character such as the comma or semicolon delimiter,
We can just get the result we want like the example below.
SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production PL/SQL Release 11.2.0.1.0 - Production CORE 11.2.0.1.0 Production TNS for 64-bit Windows: Version 11.2.0.1.0 - Production NLSRTL Version 11.2.0.1.0 - Production
SQL> with tab1 as ( 2 select 'abc,dfg,h,,1234' as col1 from dual 3 ) 4 select regexp_substr(col1, '([^,]*)(,|$)', 1, level, 'i', 1) as result 5 from tab1 6 connect by level <= regexp_count(col1, ',')+1; RESULT --------------- abc dfg h 1234
But in the case where the channel of entry has 2 types of delimiter and each delimiter consists of 3 characters as below
I wonder if it is possible to get the result as below.
The input string: 01| ^ | ABCD| ^ | 111| * | 02| ^ | efgh| ^ | 222
Separators: | * | is divided into lines, | ^ | is divided into columns
Expected result:
col1 col2 col3
Row1 - > 01 abcd 111
row2-> efgh 02 222
Simply put, take a next
The input string: 01| ^ | ABCD |^| 111 |*| 02 |^| efgh |^| 222
Separator: | * |
Result:
01. ^ | ABCD | ^ | 111
02. ^ | efgh | ^ | 222
How can I achieve this using regular expressions?
Kind regards
Euntaek
You need to know the number of the column from the outset:
with tab1 as)
Select ' 01 | ^ | ABCD | ^ | 111. * | 02. ^ | efgh | ^ | 222' as double col1
)
Select rownum,
regexp_substr (regexp_substr (col1 '(.*?) ((\|\*\|)| $) ', 1, level, null, 1),'(.*?) ((\|\^\|)| $) ', 1, 1, null, 1) col1,.
regexp_substr (regexp_substr (col1 '(.*?) ((\|\*\|)| $) ', 1, level, null, 1),'(.*?) ((\|\^\|)| $) ', 1, 2, null, 1) col2.
regexp_substr (regexp_substr (col1 '(.*?) ((\|\*\|)| $) ', 1, level, null, 1),'(.*?) ((\|\^\|)| $) ', 1, 3, null, 1) col3
of tab1
connect by level<= regexp_count(col1,'\|\*\|')="" +="">
/
ROWNUM COL1 COL2 COL3
---------- ----- ----- -----
1 01 abcd 111
2 efgh 02 222
SQL >
SY.
-
Oracle regular expressions - splits the string into words for
Hello
Nice day!
My requirement is to split the string into words.
So I need to identify the new line character and the semicolon (;), comma and space like terminator for string entry.
Please note that I am currently embedded blank and the comma as separator, as shown below.
Select regexp_substr('test)
TO
string in words, "([^, [: blanc:]] +) (', 1, 1) double;"How to integrate the semicolons and line break characters in regular expression Oracle?
Please notify.
Thanks and greetings
Sree
This has nothing to do with REGEXP. Is SQL * more parser does not not a semicolon at the end of the line:
SQL > select ' testto, mm\;
ERROR:
ORA-01756: city not properly finished chainSQL >
Just break the chain:
SQL > select regexp_substr ('testto, mm\;' |) '
2 string into words
3 \w+',1,level ',') of double
4. connect by level<= regexp_count('testto,mm\;'="" ||="">
5 string in words
6 ','\w+')
7.REGEXP_SUBSTR ('TESTTO, MM\;' |') STRINGIN
--------------------------------------
Testto
mm
string
in
WordsSQL >
Or modify SQL * more the character of endpoints:
SQL > set sqlterm.
SQL > select regexp_substr ('testto, mm\;)
2 string into words
3 \w+',1,level ',') of double
4. connect by level<=>
5 string in words
6 ','\w+')
7.REGEXP_SUBSTR ('TESTTO, MM\;) STRINGINTOWO
--------------------------------------
Testto
mm
string
in
WordsSQL >
SY.
Maybe you are looking for
-
Format a new external hard drive
I have a new external HD to format for OS X. http://www.wdc.com/en/products/products.aspx?ID=1490 I'll use for the backup of photos (in addition to other backups I have). 1. do I need to do a Partitions (TLE say to choose a single Partition and perha
-
All the network cables are plugged in, all lights are on the rise, what's the problem?
-
Notebook HP Presario CQ40 - 304TU WinXP Vista Downgrade
Hello I want to downgrade my laptop HP from Vista to XP. Could someone please locate the drivers? Shiraz.
-
Applications Android blackBerry Z10
How can I get android applications on my Z10
-
vSphere 4, win2008r2 and alignment sql2008r2
Hello group,I wanted to check what I read.We create a new virtual machine to host a sql server server and I wanted to make sure that I understand what I read. Is it true that I don't have to do anything about alignment? The use of vsphere when the