RAC replication environment in a disaster recovery Site
Hi all, in my environment I must reproduce the main site on a recovery site disaster. I use the network at high speed between the two sites and the data on file systems shared on two of SEM (one on the primary) and one on the site of the disaster related synchronously.My environment's RAC ORACLE 11 g 2, with AIX 6.1 and clusters of twins between the primary recovery and disaster sites.
Recovery site servers have IP addresses and different IP names and names of main site.
I mean, I installed my first ORACLE RAC, but I don't know how to install ORACLE RAC in the Dr site after a disaster.
I have a few questions:
(1) how should install ORACLE RAC in the recovering site, based on SAN storage that is constantly in overrided by replication of the primary storage to the storage of physical recovery? of course, the recovering site, ORACLE RAC is usually kept off-line, but I don't know how to organize the alignment between the two (primary and recovery) ORACLE environments and how to make the process of taking control.
Please, can you tell me?
Thank you
Marco
Hi Marco,.
I think you should be able to start.
Have you implemented this or being implemented?
I don't know about the behavior of replication SAN disk OCR/vote. But we use it for the database unique instance and it works fine.
I also suggest you open SR with oracle support on this subject.
Concerning
Rajesh
Tags: Database
Similar Questions
-
SAN only for VM Disaster Recovery replication
I am part of the talks for a recovery site that will not be replicated SAN data warehouses. So, we have an essentially empty ESXi environment with LUNS replicated data store. In the case of a DR, the plan would be to start the import of virtual machines in the DR ESX environment. I've never seen replication strict SAN has offered as a solution of Dr. ignore the logistics around IP, naming, etc. I want to focus on the consistency of the VMs who grew up and which have been replicated like that.
- My hypothesis is that the system VMs would probably upward in a consistent state of failure. Is that correct or could I do not affirm the VM would be healthy at all.
- If the virtual machine is running, I guess that the integrity of any application or DB data on these virtual machines would be suspect.
As I said, I never considered this scenerio. Most of the solutions I've seen using an application layer to maintain compatibility in different time intervals. Just curious if anyone has had experience with this kind of recovery.
vmproteau wrote:
Just curious if anyone has had experience with this kind of recovery.
Hi vmproteau,
This works perfectly. I made thousands of these movements of the virtual machine in a uniform way down with a success rate of 100%. The portability that we all talk about is real. He works for me very well since 2005 when I started with EMC SRDF. I also had great success with SnapMirror of NetApp. If you have any kind of enterprise storage, you should be fine. In addition, modern guest operating systems are extremely resistant to crash-compatible power (i.e. 2008 R2 is a dream come true). In addition, I have never had a problem with NT 4.0, 2000 or 2003 in my data center migrations or exercises of DR.
Nowadays, most DBAs use something like SQL LiteSpeed and Idera to create local backups on of additional vmdk attached to the virtual machine. If a recovery of a painting is necessary for example, they can obtain this granular coverage using these products. Yet once again, I never had a problem with SQL put online following a crash-consistent (i.e. test DR, moving to DC or power event HA). Of course, YMMV and you must test for your specific environment.
With respect to the RPO, it is to you to determine how often the table performs the replication. More often = more money, of course. You can also get more granular on the SQL backup points. For many, a backup per day is fine. Others take Idera SQL backups every 15 minutes for example (a slight exaggeration!).
On OTN... The biggest risk for your RTO is the lack of organization and preparation (update document and books run scripts!). In addition, having good PMs to manage the application mapping and interdependencies is essential. You'd be surprised to know how many tests application fails due to host files, order DNS or boot of VMS (i.e. Ideally you should show AD/DNS, then SQL, then App, then Web). Practice makes perfect. PowerCLI is your friend here.
Unless the plan is to re - ip, this place DR must be built as totally isolated with dedicated physical Firewall (or many sessions of sniffer and excellent ACL). If you choose SRM (as it should!), a large part of this risk is avoided since you can test in the bubble. Many companies bit on correct insulation and end up hurting prod during the test. Don't, don't. Physical Citrix is particularly vulnerable to this and is often required for DR since many apps is published exclusively via Citrix. Often, the Citrix server will eventually be multihomed (so the company doesn't have to pay for additional SQL and Citrix license servers, etc.) and will be riding the Prod and isolated environments. The default behavior is that the Citrix user will get the same routing as the underlying Citrix server so the risk is that they can connect by mistake for prod. You must study it well.
Not to mention that Citrix, other considerations ensure good VPN and other mechanisms on the DR site (which will be used for actual testing of isolated app and DR). Have several new hubs according to the needs and requirements of the network. This, along with time, often being saved at the end, but are important to your success and should be reviewed as soon as possible. In addition, to maintain the volumes that you both own (i.e. no laggard vmdk who are orphans, etc.). Use scripts to check RVTools or Vsante to remain vigilant on this. What get is replicated on the other side should be clean. Only what you need. Each vmx that is there should be one that gets recorded.
Anyway, with the replication table, this project should be a slam dunk. Don't worry so much the market crash-compliant of your guests. It works.
-
Disaster recovery with replication for VSphere
Am just test VSphere 5 of replication. with a couple of test VMs
The replication process works very well
What I want to know is the process to recover a VM replicated to new hardware in the case of the complete failure of the original host and/or data store
In essence, disaster recovery.
Are there other parts (software), that I need to take the replica VMDK and files related to re - create a new virtual machine on a new host
Steve
Yes, because it will be all your hard and .vmx files.
-
vCloud Air Disaster Recovery - vSphere replication of specific records
In the most recent documentation for vSphere replication, the ability to select specific disks when you replicate a single workload is described:
Documentation Centre of vSphere 5.5
However, in the videos of vCloud Air DR, this option is not currently available. Is - this specific to Air DR vCloud or some videos of previous versions?
vCloud Air Disaster Recovery: configuration of the Virtual Machine replication - YouTube
Answer: No.
-
With vSphere test/recovery replication all while keeping the main site online.
Hi guys. niot sure if I'm missing something really obvious.
From what I can understand tha base "recovery process" in vSphere Replication5.1 implies the following workflow
However, our profession demands that we test the ability to recover the VMs selected the site of DR then than DO NOT impact main site.
Is this possible without SRM / table to database replication / replication of VEEAM?
Our installation program
VCenter PROD (dedicated VLAN x)
VR PROD device (including VLAN, dedicated)
PROD-HA and DRS Cluster
Guest PROD networking (VLAN z)
DR VCenter (dedicated Vlan X)
VR PROD device (including VLAN, dedicated)
PROD-HA and DRS Cluster
PROD comments Networking (VLAN, isolated, cannot drive to the main site)
No RS and no possibility to use the replication table according to preverred, no Budget for VEEAM replciation.
MUST BE DONE, while the primary site remains fully alive >
Basic procedure to test recovery to DR and come back if I understand correctly >
1 tasks replication setup (fact)
2 access to the web in VCENTER DR > Pause/Stop replication on the virtual machines, we want to retrieve.
3 web access in VCENTER DR > retrieve DR virtual machines using 'recover with the latest changes' (Show stop as primary/Source VM needs to go down)
3 assuming that it is a path last step 3, we intend to move guests picked up at DR VLAN, one port groups and reconfigure the Ips using Powershell process mass
4 active Directory and DNS will be changed to Dr. TEST Site to make usable salvaged customers.
test to DR on revovered VMs in DR VLan 5 users, so this should be route back or affect the site of PROD.
6 not recovered VMs to the main site. This required once more primal VMs being to low or EVEN be removed from the inventory!
Procedure here
Looks like so there is no way to use vSphere replication to TEST the abilty to toggle, unless you can share the secrets with me.
If you are using vSphere replication without SRM above it, recovery Test is not available. The process, you can follow in case you do not want your main Web site:
(1) perform a recovery using the second option (retrieve by using the latest available data). In this way you will not have to power off of the VMs source and your main site will be online.
(2) when the recovery is complete, stop the replications (which will be in a State of recovery)
(3) power off VMs recovered, unsubscribe them inventory of VC, but keep the files of disk intact.
(4) manually configure all repetitions using disks that have been left in the form of initial seeds. This will cause the changes to synchronize.
In step 4 of ease, you can use the multi-vm replication configuration wizard vSphere. Just make sure that the data store target each disk that will be used as initial copy is put in the folder with the name of the virtual computer. Then, you could try to configure all virtual machines at once, performing the search of seeds and confirming to use.
-
How to get the ID of externsión SRM in an environment shared recovery sites
I am setting up a new site and I want to get this protected site and point to the existing shared recovery site.
I have no idea what is the ID extension SRM used the previous seller
Is anyway to extract the extension of MRS. ID?
Connect to the SRM at-> Solutions and Applications, go to the Sites-> Summary tab and you will see the ID of SRM as in this picture:

-
Physical server VM disaster recovery
Hello
Today, I meet some customers who would ask the site of recovery after a disaster. They would like to use all physical servers to the recovering site.
Here's the scenario. In the production site, they will have 3 host to ESXi 4.1, with BL460G6 (the Server Blade HP), 2 Proc Intel X 5600 series, 48 GB RAM. Storage use is NetApp with iSCSI (NETAPP FAS2040) options.
All their (converted from physical) virtual computers will consume about 4.2 TB, for most of the Linux server, multiple windows, according to. The growth of data every day is 1.6 GB. They will invest the same storage (FAS2040) on the site of DRC. Will of replication occurs every 15 minutes. They had a very good bandwidth
Now they're using the standard replication method, they transfer file to the DRC to their server (Linux, replication, automated with script-based) and until now its works very well.
Because they will migrate to Virtual Server, after all migration, they all want their server used in the DRC Site. My point is to know how to do it. Pouvez VMware replicated on the physical server? They will not invest more than license VMware or upgrading their equipment. They want to use the server as is.
I thought to use RDM, create a LUN, attached to the virtual machine with the physical/virtual compatibility, then use the NetApp replication method to replicate the DRC site. Then, in the DRC, all the physical server mapped to the same LUN. Restoration, then, just reverse the replication. But then, the implementation will be difficult, because each server has a specific LUN (it had more 20 + server).
A guy had an idea?
Thanks for your help.
From what I understand so far, they virtualized or not their systems and virtual machine files are stored on NetApp storage synced to the DRS!
In this case, with the environment of virtualization (VMware Essentials) in place at the DRS, they would have only to add the virtual machine to inventory and them lights disaster on the production side. This doesn't mean no reconfiguration of drivers (for the merger to the physical hardware), up to date systems (synchronizes every 15 min.) and very little time to have the environment running on the DRS.
The advantage of the Essentials package on the free version is management, which equals the production site and the possibility of use for example, backup software, which usually requires a licensed version.
André
-
OBIEE Disaster Recovery can be configured without CARS and shared storage?
Hi people,
As say the topic, I'm looking for advice on disaster recovery. What I find in the docs pointing me to the high availability configuration, or maybe I'm simply not find the docs I'm looking for. And it always points to the RAC, etc. of shared storage. My database is already configured to Dataguard and I want to do things this way, with a recovery site which isn't always upwards and a part of a cluster (although it's very well as long as the CAR is not involved), I'm looking for some feedback on how people do things. I have 11.1 now, but will be upgrading to 12.2 soon. Just a straight stitch to the documentation would be useful if I'm missing just that.
Thank you
-Adam
Since you have already configured Dataguard and in a DR situation, you will be switching/switch on your course in standby mode and it will active db. All this is fine. You can do the same with instances of weblogic OBIEE. You can clone your binaries installed using tools provided by Oracle cloning, or build binaries from weblogic with the accurate determination of drive on your Dr. use the pack of weblogic server and then unzip tool to archive your entire weblogic domain and it Unarchive in your prepared DR server.
Now, you have to just challenge the hostname (s) of your domain to point to your database JDBC data sources and weblogic.
To facilitate the task, you can change the host name used by weblogic to host alias that can be remapped in DNS during DR. Similarly, you can change the JDBC connection string so that it can automatically select the active database as long as you use a database instead of a SID service name in the connection string.
You will need to regularly make a pack on your weblogic domain in order to maintain an up-to-date backup of your domain proximity. Similarly, if you have reports that are stored on the file system, they must also be backed up regularly so that they can be restored.
-
Can we create a Vlan without SRM for disaster recovery testing
We are working on plans for our recovery after disaster in our VMWare environment. We have a recovery Site which has a NETAPP file server we reproduce our VM data warehouse and SQL data. We have no RS, but must be able to test if possible disaster recovery with Production upwards. Is it possible to configure a VLAN and do a test isolated Dr. without SRM? Thank you
Welcome to the VMware communities forum.
You can create a VLAN without SRM. You will need to properly set up your network hardware, and then you add new virtual machine port groups to your ESXi hosts. You can then save the virtual machines by giving them a different name and starts in isolation. When you attempt to save the virtual machines they will always have a reference for the port VM production group so you'll want to make sure you update you turn on.
-
Disater recovery site main VPN, OSPF
I am trying to find a solution for our site recovery. We have 13 websites with VPN tunnles back to the main site with OSPF and GRE tunnels for routing. I need to make a site separate from the main site mirror (ip addresses, VIRTUAL LANs, etc.). How can I switch the VPN sites on the site automatically using the GRE and OSPF network disaster recovery using the same model of IP address?
The stateless failover is used when primary network edge platform fails, IPsec sessions can failover and reconnect to the edge network backup platform, thereby reducing downtime of connection.
-
Recovery site - redundant VPN peers
Hello all, thank you in advance for your expertise.
We put in place a recovery site disaster that will host the redundant copies of our servers and critical data in Kansas City. When disaster strikes, our headquarters site would be totally gone.
We currently have 7 locations that communicate to our HQ via VPN tunnels (whether on a circuit of the Internet or on a circuit of Cox Communications Ethernet WAN). Branch sites each can an ISR of Cisco 2821 router. At Headquarters and on the DR site, we use a Cisco ASA 5510 to terminate VPN tunnels and do everything that our column spinal routing. Routing on the ASA and branch routers is all static, using a routing protocol would be a nice update in the future... any ideas? We use IPSEC VPN lan lan tunnels 2, no GRE/VPN is used because it is not terminated by the ASA.
What is the best way to configure my routers for branch to automatically or manually failover to connect to one ASA different site of DR?
In addition, if my seat is still in place, but either my Internet or Cox headquarters ethernet circuit breaks down. How can I re - route all traffic in a loop to the seat on the right remains a circuit?
Is there a better way to do what I want to accomplish? BGP is not an option at this point due to its complexity.
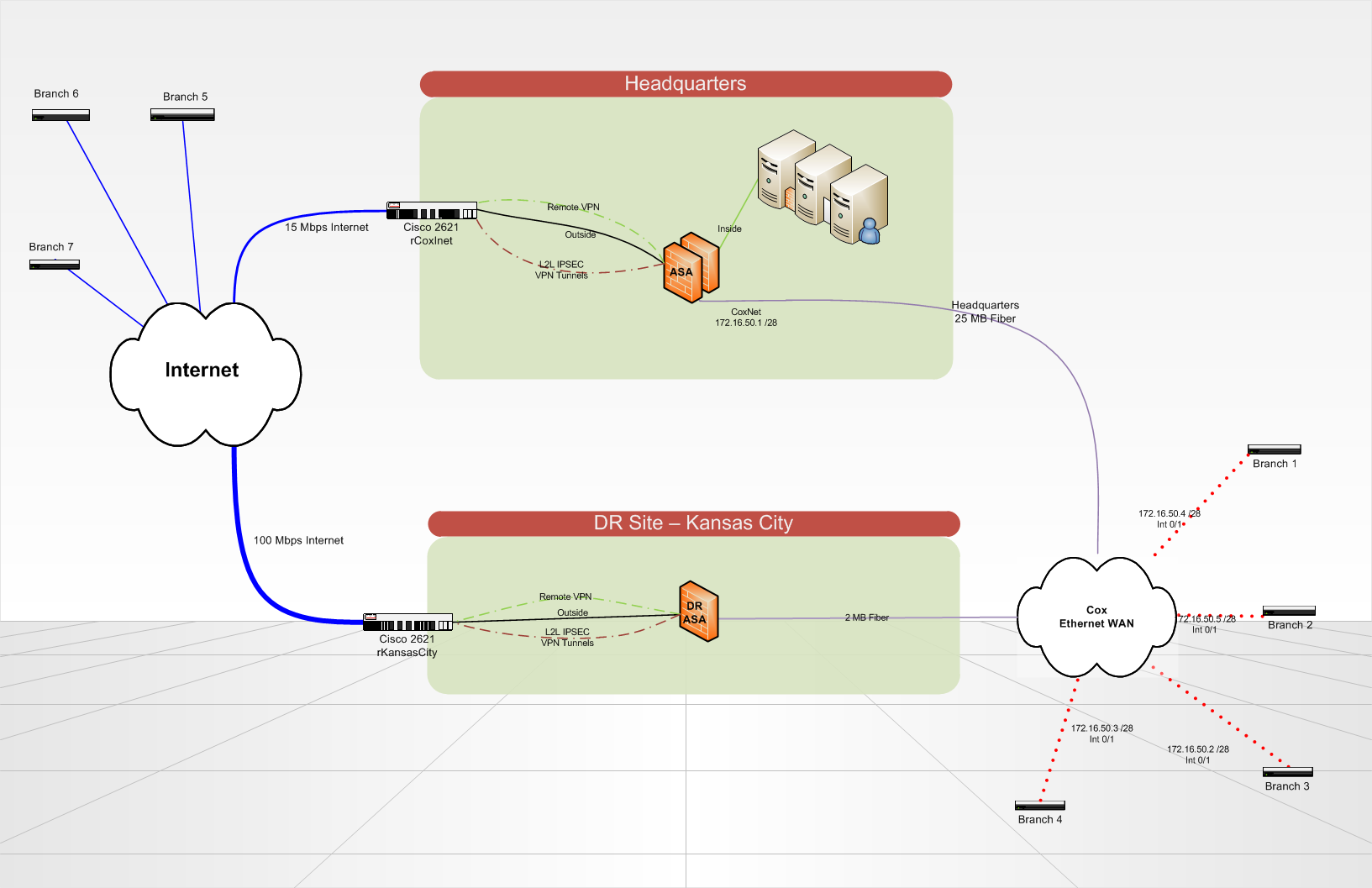
Lucas,
To circumvent the two point separately.
The best way to provide active / standby time of reundancy is preferred peer in cryptographic cards (on the ISR routers).
You can choose to establish VPN to HQ and only if HQ is not aid you to DR, when HQ is you will EVENTUALLY return to it.
The answer to share of your questions may also be the preferred option by peers (and several counterparts in a crypto map entry).
This being said, you can try to send OSPF traffic to IPsec tunnel (and using the neighbor command to avoid the manipulation of mcast in pure IPsec).
Docs:
HTH,
Marcin
P. S.
If you want my personal opion, chaning ASAs in HQ and DR sites and put you in routers could make DMVPN or DVTI-ASIT scenario which gives you a lot more features ;-)
-
IPSec VPN between ASAs with same subnet for disaster recovery
Hello
I need some clarification from you guys.
To do disaster EasyVPN tunnels for the Cisco ASA 5505 firewall recovery site. Now, there is only one main site and 3 remote sites.
Dr., must use the same subnet that it is on the main site because virtual machines Vmware will be replicated to DR.
For the DR we use Double-Take software.
What is the best solution for this? I think we could use NAT of Destination on ASAs. Other sites (HQ and remote control) will be directed to only address NAT of the
DR and not real which is the same as on the main site.
So guys, will this work? We are using IPSec VPN? In packet - trace on ASA, I see that the package is the first using a NAT, and then encrypted, so it should work, Yes?
I hope someone can confirm this.
I can confirm that this will work certainly,
for prior type natting see 8.3:
http://www.Cisco.com/en/us/products/ps6120/products_configuration_example09186a0080b37d0b.shtml#diag
for 8.3 and later it is also achievable.
-
vCloud Air - Disaster Recovery - Europe - UK
Please can someone advise where Europe - UK datacentres are based, whereas the vCloud service Air Disaster Recovery.
All links related to security and compliance would be welcome.
The service is available for re - sale by any partner VMware or only those with a certain specialization / accreditation.
Thank you
Hi Ben,
Answers to your questions:
-You can see the vCloud updated map to know where on the Web site: vCloud locations - VMware vCloud Air Air
If you need a more specific location (for put in a private line, MPLS/VPLS), you can see them here: Direct Connect - VMware vCloud Air
-Info security & compliance is here: reports of Certifications of compliance - VMware vCloud Air the AT101 full compliance are available under NDA - you will need to contact your VMware representative for this.
-Partners VMware must reach their hybrid Cloud competence to transact
Hope that helps!
Jenny
-
replication of vSphere to several target sites?
Hello
Is it possible replication a VM to target multiple sites with vSphere replication (say in two places in recovery)?
Thank you
Greg
Hi Greg,.
VR allows only a single site target replication.
Kind regards
-Martin
-
Need recommendation for installation recovery site
Hi all
1. What are the basic things that we must analyze it before we recommend the company to go to oracle Dataguard for DR configuration?
2. do you know any technology that will replicate the schema of a data center [data one] to another data center [secondary database or replication]?
3. What are the different option to configure the disaster recovery plan at the schema level?
Thank youHello again;
I use Oracle Streams, but it is certainly an option:
http://www.Oracle.com/technetwork/database/information-management/streams-FOV-11g-134280.PDF
It also has its own forum (you probably know that)
Oracle Streams comes with more than 7000 data dictionary views, and DBMS built-ins so my main concern is the complexity and moving parts. Flow also includes guard data items, for example to capture downstream. If I had to choose between streams
and Data Guard, I'd go with Data Guard, as his most popular (view) and thus better supported.The last time I checked GoldenGate needed a license. If you need money. I also believe that the options for the host operating systems are less than the other two options.
My understanding is that you have to learn a new language with a boatload of new keywords. That said, Yes, it could be an option. It has a forum here somewhere. But I don't use it either.
In any case, it looks like you ask all the right questions. Good luck with your project.
Best regards
mseberg

Maybe you are looking for
-
How many keywords can be asigned to a photo.
I'm scanning "analog" photos, shot on negative and positive film. It will take a few months before the end, and in order to check them I want to assign keywords if I can easily find specific information. How many keywords will accept Photos, and they
-
Unload the modules work / wish
When you select the "Unlod" modules in the module, you have no result message: the user cannot know whether or not the modules were really low. You can see the situation with a sequence that load a. Extension DLL is open and was executed: If you want
-
Windows mail 0x800CCC78 error code
Just started not to be able to send e-mail, can receive very well. I get this message and the error code: The message could not be sent. The authentication setting are may not be wrong for your e-mail [SMTP] Server outgoing. To resolve this issue, go
-
Windows 7 problem with the Dell XPS 15 laptop (L502x)
Dear friends, Greetings! I need your assistance related to a problem, I was confronted with my Dell XPS laptop computer L502x purchased in the United Kingdom a couple of years back. In fact, I tried to update my system for windows-10 de-windows 7 Hom
-
In case of failure. Return code: 4
After a problem with my computer, a Dell 9200 Dimensio, I got an error on one of my 2 hard drives. I ran Drive Diagnostics hard and here is the result: Drive 0 WDC WD2500JS-75NCB3 Fail. Return code: 4 Disc 1 WDC WD2500JS-75NCB3 Pass My computer is ve