Report of Script delete the first line
Hello all-I have the following report script:
< INSTALLATION < SYM < SUPSHARE < sparse
{NoIndentGen} {SupPageHeading} {SUPFEED} {SupZeroRows} {SUPEMPTYROWS}
{SupBrackets} {ROWREPEAT} {TABDELIMIT} {decimal 0} {SUPMISSINGROWS}
< END
Members page
< PAGE ("Emp", "HP", "Curr', 'Version', 'DType', 'HSP_Rates')
"Emp".
"HP".
"USD".
Final
"UnAlloc.
'HSP_InputValue '.
Members of the column
< SYM
* < COLUMN ('accounts', 'Periods'). *
* "Indirect labor *" "teacher tax."
Rules of selection and output options for dimension: periods of time
< link ((< LEV ("", "Lev0, périodes")) AND (< IDESC ("YearTotal")))
{CALCULATION COLUMN "P1" = 3 + 4}
{CALCULATION COLUMN "P2" = 5 + 6}
{CALCULATION COLUMN "P3" = 7 + 8}
{CALCULATION COLUMN "P4" = 9 + 10}
{CALCULATION COLUMN "P5" = 11 + 12}
{CALCULATION COLUMN 'P6' = 13 + 14}
{CALCULATION OF COLUMN "P7" = 15 + 16}
{CALCULATION COLUMN 'P8' = 17 + 18}
{CALCULATION COLUMN "P9" = 19 + 20}
{CALCULATION COLUMN "P10" = 21 + 22}
{CALCULATION COLUMN "P11" = 23 + 24}
{CALCULATION COLUMN "P12" = 25 + 26}
{CALCULATE THE COLUMN "P13" = 27 + 28}
{ORDER 0,1,2,29,30,31,32,33,34,35,36,37,38,39,40,41 FIXCOLUMNS 16}
Line members
< ROW ('entities', 'Scenario', "Years")
Rules of selection and output options for dimension: entities
< link ((< LEV ("", "Lev0, entités")) AND (< IDESC ("Entities")))
"Forecasting".
FY10
!
End of report
The report works fine but the text file created by this script still introduced a starting line that contains the name of the account. I regret that the line is not empty it has the header for the accounts, but I want to delete it. Is this possible? I have
don't want to use the title of column delete I like P1, P2... P13 as my column heading.
Please notify
To get rid of it, you'd have to suppre topics, but who's going to get rid of the desired topics. As a work around, you could add the repression and create a file that has the desired header. If you run this from a command script, the last step would be to add the header file and report all file in a final file. You can do this using the command copy. Something like
Copy headefile.txt + reportfile.rpt Finalfile.txt
Tags: Business Intelligence
Similar Questions
-
delete the first line of operation alwaysdeletes
Hi all
I'm new to jdeveloper and I have some problems with the delete operation. I have a standard jsp page with data child parent. The child table has emplid and seqno in the form of key fields. When you try to delete the third (or any other line) row in the child table it somehow always deletes the line first. I tried using standard deletion operation and also have tried to use the code to remove the data below. Can someone please help me understand what could be the problem?
I use jdeveloper 11.1.2.2
Thanks in advance.
{} public void deleterow (ActionEvent actionEvent)
DCBindingContainer links =
(DCBindingContainer) BindingContext.getCurrent () .getCurrentBindingsEntry ();
DCIteratorBinding dcItteratorBindings = bindings.findIteratorBinding("EMPL_PROVW1Iterator");
System.out.println ("HI" + dcItteratorBindings.GetCurrentRow ());
dcItteratorBindings.removeCurrentRow ();This is the reason why...
can u paste your table code so that I can help you...
chk this
http://docs.Oracle.com/CD/E21043_01/Web.1111/b31974/web_tables_forms.htm#CJAGIGAB -
Delete in af:table always remove the first line when using ExecuteWithParams
Hello world
I got a page with master form and af:table two details related to the master. When I'm trying to remove a line in an af:table of detail, it always removes the first line, any line, I selected before. The table has a single = rowSelection and the line is properly visually selected. I remove the line using a "delete hyperlink" on each line, but I first have to select the line. Delete called a bond (or a method at the bean by removing the current line of the iterator, I tried both, none of them work)
Links page has an ExecuteWithParams defining the correct ID to edit on the master of iterator and an InvokeExecuteWithParams the renderModel value. If I put the refresh condition zero and I hard-code an ID in the binding variable in the model, I am able to delete the selected line.
In addition, I don't know if this information is useful, but if I set the iterator to PPR ChangeEventPolicy, when I select a line, there always select the first line.
Any ideas what I could do wrong? Is this a bug?
I use JDev 11.1.1.7
Thank you
Guillaume
You can try creating a method in ApplicationModule for filter master records instead of executeWithParams?
Ashish
-
I can only access buttons of menu on the first line when I use mode full-screen, why?
Many Web sites I visit have on the first line of the web page in a series of menu options that do not respond when I move the mouse to select options. If I use the mode full screen these buttons work correctly. These buttons work correctly when I use IE or Chrome. I am running Windows 7 and this has happened in the last two weeks.
Recently, the extension of the Yahoo! toolbar and the extension of Babylon have been reported to cause a problem like that. Disable or uninstall the modules.
* https://support.mozilla.com/kb/Troubleshooting+extensions+and+themes
-
Delete the first 4 characters in a cell... (IND CS4)
I need to delete the first 4 characters if the text of the cells begins by "< Cs.
Is it possible without using "find/replace"?
My script is something like that...
var doc=app.documents[0]; var allTablesArray=doc.stories.everyItem().tables.everyItem().getElements(); /************************************************************************/ var TbCount = allTablesArray.length; for(var Tb=0; Tb<TbCount; Tb++) { var Tab = allTablesArray[Tb]; var numRows = Tab.rows.length - 1; for(var R=numRows; R>=0; R--) { var numCells = Tab.rows[R].cells.length - 1; for(var Td=numCells; Td>=0; Td--) { var xCell = Tab.rows[R].cells[Td]; var Content_3 = xCell.contents.slice(0,3); if (Content_3 == "<Cs") { //Remove the first 4 characters in the cell } if (Content_3 == "<Rs") { //Remove the first 4 characters in the cell } } } } //*****************Hello
Try this...
var doc=app.documents[0]; var allTablesArray=doc.stories.everyItem().tables.everyItem().getElements(); /************************************************************************/ var TbCount = allTablesArray.length; for(var Tb=0; Tb
-
The first line of packaging is not around a framework anchored
Hello everyone,
In InDesign CS6, I use anchored frames to insert images running on the side of paragraphs. That's what I want to do:

Executives have a positioning custom, placed to the right of the text frame. Text wrapping is allowed for the surrounding text block. However, when I insert the anchor frame at the beginning or at the end of this paragraph of text, the first line of the paragraph continues to straddle the frame of inking. The rest of the paragraph is very good and it wraps correctly:

I reported this problem before Adobe, but never heard of them or seen this problem solved, so I would like to ask you if you have an idea about what goes wrong.
Thank you
Paolo
Text wrap differently entrenched works FRO objects does it differently for inline and anchors and floating custom.
Inlines skin affects the text that follows the anchor point. Custom anchors placed only the text in the lines that follow the anchor are affected. It is design to prevent the composition endless loop when wrap would move the position of the anchor on the page.
-
Remove the first line xml generated xml to VO
I am combining multiple xml files to generate the report using BIPublisher. I generated xml based on a VO by using VO.writeXML. How can I remove first row (<? xml version = "1.0"? >) in the xml file?Use the transformer and setOutputProperty to omit the first line.
Transformer transformer = TransformerFactory.newInstance () .newTransformer ();
transformer.setOutputProperty (OutputKeys.OMIT_XML_DECLARATION, 'yes');Edited by: Puthanampatti Dec. 6 2012 18:42
-
Pulling on the first line with a value of repetition
Hello
We use the Oracle 11.1.
We have a table of postal codes.
We have several lines for each zip code because we have different areas that use the same zip code.
We want to reduce the lines of a line by zip code. But they said use they want to keep the fields that differ (neighborhood of the exodus).
Then they said "Just take the first value of each."
This code reduces the postcodes of a line by postal code, but as you can see I replaced the field with the name of the field values.
How should I take either one record per postal code with the first value in these fields orSELECT distinct ZIPCODE, CITY, STATE, COUNTY, AREACODE, 'CITYTYPE', CITYALIASABBREVIATION, 'CITYALIASNAME', LATITUDE, LONGITUDE, TIMEZONE, ELEVATION, COUNTYFIPS, DAYLIGHTSAVING, PREFERREDLASTLINEKEY, CLASSIFICATIONCODE, MULTICOUNTY, STATEFIPS, 'CITYSTATEKEY', 'CITYALIASCODE', 'PRIMARYRECORD', CITYMIXEDCASE, 'CITYALIASMIXEDCASE', STATEANSI, COUNTYANSI FROM zip_code GROUP BY ZIPCODE, CITY, STATE, COUNTY, AREACODE, CITYTYPE, CITYALIASABBREVIATION, LATITUDE, LONGITUDE, TIMEZONE, ELEVATION, COUNTYFIPS, DAYLIGHTSAVING, PREFERREDLASTLINEKEY, CLASSIFICATIONCODE, MULTICOUNTY, STATEFIPS, CITYALIASCODE, PRIMARYRECORD, CITYMIXEDCASE, STATEANSI, COUNTYANSI order by zipcode;
How should I take the first record for each zip code?
either way works for me.
Thank youHello
This is called a Query Top - N , and this is a way to do it:
WITH got_r_num AS ( SELECT z.* , ROW_NUMBER () OVER ( PARTITION BY zipcode ORDER BY city , ... -- add tie-breakers here ) AS r_num FROM zip_code ) SELECT * -- or list all columns except r_num FROM got_r_num WHERE r_num = 1 ;You can simply use MIN or MAX on the columns, as the line with the name of the minimum city do not lowest have area code or the longitude. The above method preserves the first line of each zip code intact, where the 'first': the first in order of aphabetic by the name of the city. If it is not unique, then you may want breakage to the analytical ORDER BY clause.
If you are deleting rows, you can use this in a NOT IN subquery. If you copy lines to a new table, you can use the query above in an INSERT statement.
Published by: Frank Kulash, March 18, 2011 12:40
I just see Polywog response:
Pollywog wrote:
You can use the rank or rownumber function...If I understand the problem, you don't want to use RANK in this particular case. When there is equality, GRADE will assign 1 to all the contenders. I think the whole point of this thread is that you exactly want a #1 in each zip code, which is what ROW_NUMBER, but not RANK, guarantees.
-
How do to "BOLD" in the first line of text on a number of sections of text at a time
CS5 using (but we have CS5
.5 available) we will create a business directory. Each page has columns of type
business listings with the company name on top, under this address under this phone, etc. Each ad is separated
by a single line. There are thousands of ads, and we need to "BOLD" in the top line of each. How can do us
without making them individually?
Each line a paragraph, or each list a paragraph with soft returns (forced line breaks)?
It's very simple and basic in both cases an operation. It is especially easy if each ad has the same number of lines, so we will focus first with this case.
Each line should be a separate paragraph. If you have 4 lines, as your example, you might want to mention their name, street, city, and phone. You can and should, all the styles that will be similar in appearance on the same basic model and change only the atrributes that are different, so, for example, if all lines use the same font, many use the same size and weight and only the top line is different and only by being "BOLD" and or larger size start by defining the street, then city and phone based Street and you don't need to define something more than the next Style, I'll get to in a second.
For topics, set name based as well on the street, but change the font characters. Now all the features of the basic fonts can be changed in one place, the definition of the style Stree.
Since you have the same number of lines in each list, you can set up a loop "next style". For name, style next street is, the street is the city, for the city it is the phone and is name for the phone. You will also need to toe after the add space in the name, or space on the phone to book spaces registration and you probably also consider to assign everything except phone keep with the next line to prevent a list from breaking across a page or column break. If currently you have blank lines as separators (empty paragraphs), get rid of them. There are change queries find already registered in ID that will do that.
Once the text is in place and the styles are defined, you can select all, then right click on the style name in the paragraph Styles Panel and choose apply following Style and name. Reformatted your entire list. IT IS CRITICAL in this method that the structure of each list is identical, and if there are no empty lines between the lists.
If each line is a paragraph, but there is line different counts, you will probably reach with just two styles, one for the headings oand one for everything else, but the beat of following style will not work. If there is something unique that appears in all the headings you can use find/replace to make search and reformat in shape, but I suspect that this will not be the case on in the real world, there will be a manual work involved.
Where a lisitn is a single paragraph, line break forced (which is better suited to the case of an uneven lines by registration number) you can define a character style nested to be applied by means of a line break forced to make the first line "BOLD", red or any other thing you want.
At this point, you are probbly, noting that a bit before planningn is a good idea when you do a directory so that your ads have some sort of coherent structure that allows for automation. I have no idea whre that your text is coming from or how it is done in the code. If it can be established as a .csv or a tab-delimited text file, you can use data merge to fill a file based on a model of merge (i.e., how to build directories for my clients who need). You can set styles in the model to each field or paragraph that contains several fields, and merge data will remove empty lines if all row fields are null and there is no punctuation or whitespace on the line.
A multiple records per page fusion will give you individual blocks of text for each record, and you can, if you wish, thread them using the script text point of Rorohiko.com.
-
Pleazzz... help me put my record of the opening on the first line
I use this query inside my builder6 (oracle10g) report, but it is untimely return of output.
only when I give the start date of the report (: m_frm_date) as the opening date (op_date), the balance
the report that is stored in the table op_bal, happens correctly, with the first line, the opening balance.
later, when I try to run the same report giving other start dates, opening balance
line was traded to the second row. Please refer to the screenshot of my reports, for the best idea.
http://S640.Photobucket.com/albums/uu123/fairoozxp/?action=view & Current = EXPRPT.jpgselect op_date, TNO,OP_CODE,EI,withdrawal,deposit, sum(NVL(DEPOSIT,0)-NVL(WITHDRAWAL,0)) over (order by op_date,TNO) bal from ( select op_date, NULL TNO,null OP_CODE,NULL EI,withdrawal,deposit from ( select :M_FRM_DATE op_date, sum(withdrawal) withdrawal, sum(deposit) deposit from ( select :M_FRM_DATE op_date,sum(DECODE(EXPN_EI,'E',EXN_AMOUNT)) WITHDRAWAL, sum(DECODE(EXPN_EI,'I',EXN_AMOUNT)) DEPOSIT from EXPENSES_TXN, expense_master where exn_acnt_code = expn_code and exn_date < to_CHAR(:M_FRM_DATE,'dd/mm/yyyy') union all select op_date, null withdrawal, op_amount deposit from op_bal)) union all SELECT EXN_DATE, EXN_NO, EXN_ACNT_CODE, EXPN_EI, DECODE(EXPN_EI,'E',EXN_AMOUNT) WITHDRAWAL, DECODE(EXPN_EI,'I',EXN_AMOUNT) DEPOSIT FROM EXPENSES_TXN, EXPENSE_MASTER WHERE EXN_ACNT_CODE = EXPN_CODE and EXN_DATE between to_CHAR(:M_FRM_DATE,'dd/mm/yyyy') and to_CHAR(:M_UPTO_DATE,'dd/mm/yyyy')) order by op_DATE,tno / this is the actual for which report has to come; SQL> select * from op_bal; OP_COD OP_NAME OP_DATE OP_AMOUNT ------ ------------------ --------- ------------- OP0000 NATIONAL BANK 01-JAN-09 5000.000 *Date No.2* SQL> SELECT 2 EXN_DATE, 3 EXN_NO, 4 EXN_ACNT_CODE, 5 EXPN_EI, 6 DECODE(EXPN_EI,'E',EXN_AMOUNT) WITHDRAWAL, 7 DECODE(EXPN_EI,'I',EXN_AMOUNT) DEPOSIT 8 FROM EXPENSES_TXN, EXPENSE_MASTER 9 WHERE EXN_ACNT_CODE = EXPN_CODE 10 order by 1; EXN_DATE EXN_NO EXN_AC E WITHDRAWAL DEPOSIT --------- ------------- ------ - ------------- ------------- 01-MAR-09 2.000 AC0002 E 2000.000 10-MAR-09 7.000 AC0012 I 500.000 15-MAR-09 5.000 AC0007 E 15.000 20-MAR-09 8.000 AC0012 I 700.000 31-MAR-09 6.000 AC0008 E 30.000 01-APR-09 9.000 AC0013 I 250.000 07-APR-09 1.000 AC0001 E 200.000 09-APR-09 4.000 AC0011 E 35.000 09-APR-09 3.000 AC0003 E 50.000 9 rows selected.
http://S640.Photobucket.com/albums/uu123/fairoozxp/?action=view & Current = EXPRPT1.jpg
http://S640.Photobucket.com/albums/uu123/fairoozxp/?action=view & Current = EXPRPT2.jpg
much appreciated, tyvm.Hello
Is the problem that, when it is be a rank with exn_date =: m_frm_date, the line which represents the total front: m_frm_date sometimes appears after him?
If Yes, then you must add something to the ORDEER TO ensure that the total line comes first.
If NWT is NULL rfor only the total row, and then, as said to put, simply add 'NULLS FIRST' to "ORDER BY tno". Don't forget to do this as well in the analytical AGENDA BY:OVER (ORDER BY op_date, tno NULLS FIRST) AS baltowards the beginning of your query and the result ORDER BY value at the end:
ORDER BY op_date, tno NULLS FIRST;If reallly NWT can be null, you can create a new column (I'll call her sort_key) ust to distinguish the total line on the lines later. SELECT a literal 1 sort_key of ACE in the part of the UNION that created the total line, and then '2 AS sort_key' in the part of the UNION, who gets lines and after: m_frm_date:
SELECT op_date, tno, op_code, ei, withdrawal, deposit, SUM ( NVL (deposit, 0) - NVL (withdrawal, 0) ) OVER (ORDER BY op_date, sort_key, tno) AS bal FROM ( SELECT TO_DATE (:m_frm_date, 'dd/mm/yyyy') AS op_date, NULL AS tno, NULL AS op_code, NULL AS ei, withdrawal, deposit, 1 AS sort_key FROM ( -- Begin sub-query for expenses before :m_frm_date SELECT TO_DATE (:m_frm_date, 'dd/mm/yyyy') AS op_date, SELECT SUM (withdrawal) AS withdrawal, SUM (deposit) AS deposit FROM ( SELECT SUM (DECODE (expn_ei, 'E', exn_amount)) AS withdrawal, SUM (DECODE (expn_ei, 'I', exn_amount)) AS deposit FROM expenses_txn, expense_master WHERE exn_acnt_code = expn_code AND exn_date < TO_DATE (:m_frm_date, 'dd/mm/yyyy') UNION ALL SELECT NULL AS withdrawal, op_amount AS deposit FROM op_bal ) ) -- End sub-query for expenses before :m_frm_date UNION ALL SELECT exn_date, exn_no, exn_acnt_code, expn_ei, DECODE (expn_ei, 'E', exn_amount) AS withdrawal, DECODE (expn_ei, 'I', exn_amount) AS deposit, 2 AS sort_key FROM expenses_txn, expense_master WHERE exn_acnt_code = expn_code AND exn_date BETWEEN TO_DATE (:m_frm_date, 'dd/mm/yyyy') AND TO_DATE (:m_upto_date,'dd/mm/yyyy') ) ORDER BY op_date, sort_key, tno;Be sure to use strings to represent DATEs. If: m_frm_date is a string, it must always be used with TO_DATE and TO_CHAR ever.
Never, send or even write, unformatted code.
During the validation of code on this site, type the 6 characters
{code}
(small letters only, inside curly braces) before and after the code for formatting, to keep the spacing. -
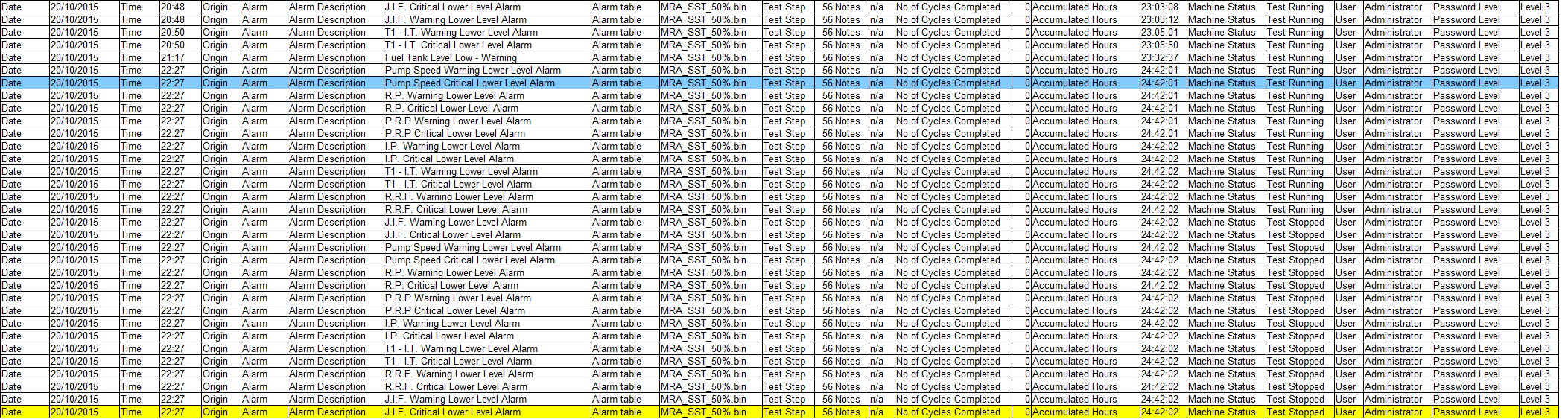
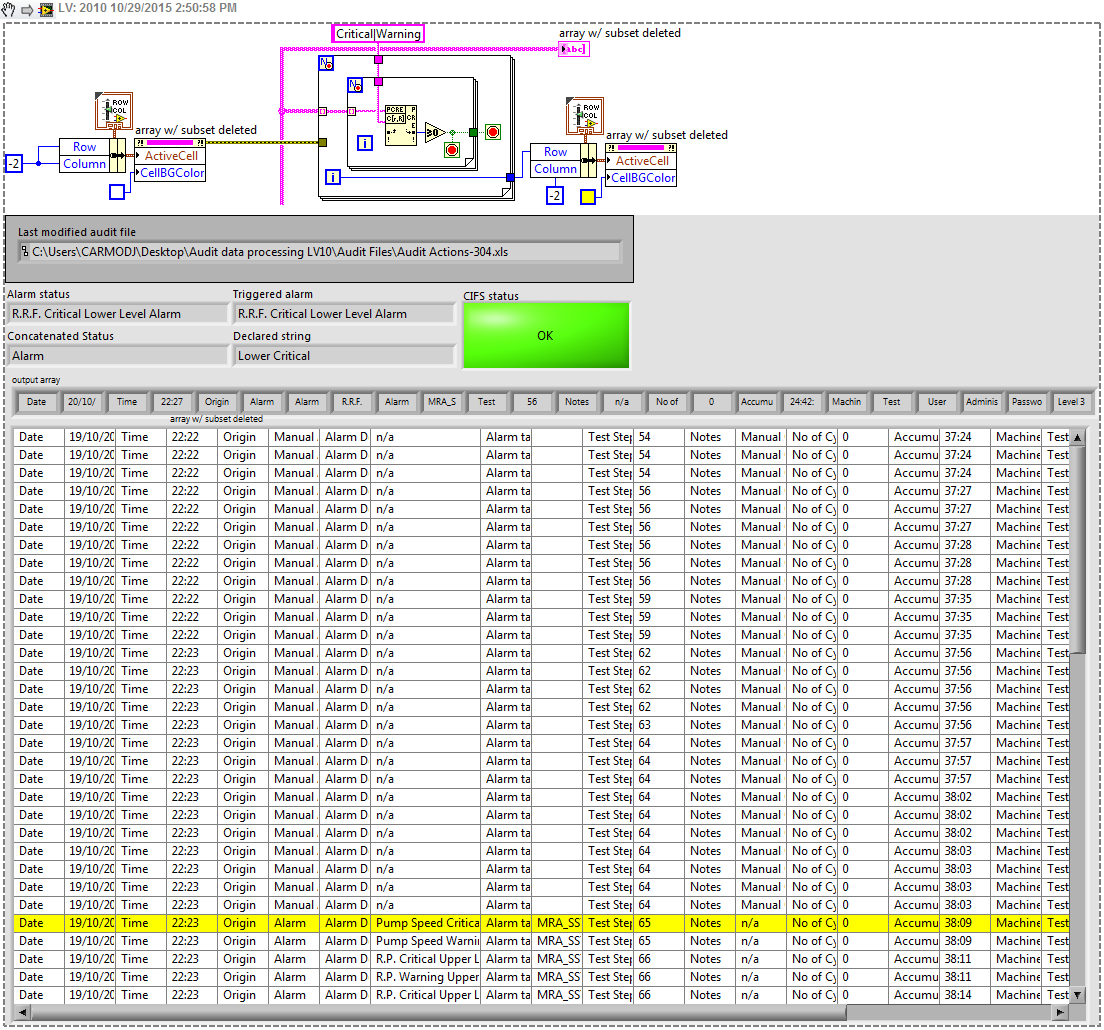
Extract the first line containing "critical" or "E-Stop" of the last avalanche of line
Hi all
I'm watching some test systems by analyzing their audit files.
In this case, the platform generates several line 100 files in a specific folder. The code below is to find the last file and extract the contents of the last line of the last file.

Unfortunately, when an error occurs, the main software generates not only one entry, but an avalanche of lines [not a specific quantity of them, depending on how much the alarms are resolved] and I'm now ideas of how I could identify and the contents of the first line containing "Criticism" or "E-Stop" to exit from this avalanche [line avalanche started 22.27].
As an example, the above program is extract the yellow line, while I need information from the blue line.
Any idea on how I can do this?
See you soon,.
You can add this snippet to the top of your existing code. I changed the indicator table to a table so I could highlight the line.
-
First character left in file by reading the first line in text file
When you use the function of reading text from a file file, I noticed that the 1st character is left in the file. I read the line correctly.
When adding a 2nd line this character is in the file.
Part vi code is attached.
Any ideas?
Thank you.
Elik
Can you attach a file of real data and tell us what you mean by "first character". The number of characters per line do you have?
Can you tell us what you see in the modified file and what you expect to see.
Everything seems good.
- Read you the first line and so the file pointer is just after the first line
- You set the size of the file at the end (seems unnecessary, because it does nothing). The file pointer is always right after the first line.
- You write the first line you read concatenated with a second line. It will be written on the current file pointer, i.e. after the existing line
- The first line is in the file twice, as planned.
Setting the file size to the 'end' on an existing file does not have something useful. If you want to set the position of the file instead?
Try to set the file position from and new data will be written at the beginning of the file.
-
my printer has stopped printing. The issuance of documents in Quebec and he says the first line is printing, but it is not.
Hello
1. what version of Windows is installed on the computer?
2. What is the brand and model of the printer?
I suggest you to follow these steps and check if that helps:
Method 1:
Try to run the printer Troubleshooter and check that if it helps, here is the link:
http://Windows.Microsoft.com/en-us/Windows7/open-the-printer-TroubleshooterMethod 2:
Try to run the below fixit and check if this may help:
http://Windows.Microsoft.com/en-us/Windows7/why-cant-I-printIt will be useful.
-
Scan of a file only works on the first line
Hello
I'm new to Labview (see 8.6) and I'm running on this problem.
I use the Scan of a file to get a certain amount of information for the installation of test.txt. The data of the file looks like this:
AAA 1
BBB 2
REC 3
I noticed that the Scan of the file works for only the first line. Trying to get data that are not in the first line results in an error 85.
Any ideas? Thank you

It's all in what the scan of the file reads, and what is the next cgaracter in the file.
Your first analysis of the file reads up to but NOT including the first newline in the file.
The second read readings where the first reading was arrested and is expected to see 'B' as the next character, but sees the new line instead, and if the analysis fails. You must specify second reading formatted to await the return line.
You can do this by making the FIRST character of the format string space, that will tell it to expect a number any of charaters 'white space '.
Yo can indeed put a space at the beginning of the format string in your first analysis of the file and it will match with zero white space characters before you see the AAA. By doing this he also tolerate to see the spaces and tabs before your AAA or BBB identifiers.
Rod.
-
typed a letter and drafts in hotmail, whent sent to retrieve to send and only got the first line of text back.
Hotmail forums:
http://www.windowslivehelp.com/forums.aspx?ProductID=1
They will help you when repost you your question in the Forums above for Hotmail.
See you soon
Mick Murphy - Microsoft partner


Maybe you are looking for
-
Vista and Tecra S1 - need new Display Driver
Hi all I hope you can help me.I installed Vista Ultimate on my Toshiba Tecra S1 (of control), but I have no correct video driver. Only for Windows XP Home display-ts1-xp-614106476 driver is not accepted by Vista and my Tecra with Videodriver standard
-
I signed up for Netflix and when I try to play a movie all the getting is a black page...
Remember - this is a public forum so never post private information such as numbers of mail or telephone! Ideas: You have problems with programs Error messages Recent changes to your computer What you have already tried to solve the problem
-
I'm unable to send/receive emails.
Send/receive blocked I'm unable to send/receive e-mails due to an attempt to send and receive photos that appear to have hung my send/receive function. Whenever I try to send/receive, it results in an error message. How can I overcome this? Unfortuna
-
How to install printer HP Officejet Pro 8600 software more? Windows 7
How do we install printing to my HP Officejet Pro 8600 software more? I had trouble with the wireless connection, but that is fixed. The printer now shows the menu, but I can't find how and when to install the software. Thank you
-
Utility HP always chooses the wrong printer
I have two HP printers that I use a MacBook and travel with her. An I keep at home (a Photosmart C4180) and another (a Photosmart Premium C309g-m). For some reason any, whenever I Plug one of them in my computer, the HP utility think I the other is p