SEPARATE returns an error on column with TO_NUMBER
Oracle Database 10g Enterprise Edition Release 10.2.0.5.0 - 64biPL/SQL Release 10.2.0.5.0 - Production
CORE Production 10.2.0.5.0
AMT for 64-bit Windows: Version 10.2.0.5.0 - Production
NLSRTL Version 10.2.0.5.0 - Production
Hello
I have a question like this that works very well and returns x amount of records;
select to_number(col_3) plot_number
from user_recovery_external;select distinct to_number(col_3) plot_number
from user_recovery_external;
Error starting at line 15 in command:
select distinct to_number(col_3) plot_number
from user_recovery_external
Error report:
SQL Error: ORA-29913: error in executing ODCIEXTTABLEFETCH callout
ORA-01722: invalid number
ORA-06512: at "SYS.ORACLE_LOADER", line 52
29913. 00000 - "error in executing %s callout"
*Cause: The execution of the specified callout caused an error.
*Action: Examine the error messages take appropriate action.Ben
There are some invalid numbers in your file.
Your first query reads only first few records of the file, where there is no 'invalid numbers "(in the first few records)
When you use DISTINCT, the query will read the entire file to find unique records.
Tags: Database
Similar Questions
-
plugin VMware update manager returns with "the remote server returned an error: (404) not found."
Hello
We have recently updated our virtual Center Server to version 4 and now when I try to download and install from the page manager plugin vmware update manager plugin is back with "the remote server returned an error: (404) not found"
Has anyone had this problem before and eventually worked out how to fix this?
Gregg Robertson, VCP, MCSE, MCSA, MCTS, MCITP
You are welcome!!
-
Design:
2 vCenter VMs version 5.5 on new W2k12. x. related and the same use facilities key SSO (default installation)
2 x fresh install of the SRM VMs version 5.5
20 + hosts vSphere 5.5 with DR/HA configured and working. Two dvSwitches (one per site) configured with the groups of port / VLAN work
Question:
Installation goes well until I needed to activate the Plugin SRM in vCenter. Plugin called "Plug-ins available" and I click on the link 'download and install '.
I had two separate fouls on both servers vCenter, both with same errors if it is compatible.
Errors:
(attached file viclient-3 - 000.log)
The request has been aborted: could not create SSL/TLS secure channel.
(attached file viclient-3 - 000.log)
The remote server returned an error: (503) server unavailable
I guess that the two are linked and probably something with SSO. Post installation on each server vCenter vCenter, at the level of the vCenter, I added the "Domain Admins" AD Group with all permissions and then properly connected and built the group with this set of credentials.
I need help to debug this further.
Thank you
************
< < Updated > >
Seems the features and functions are NOT present so you don't not sign in as '[email protected]' (SSO account by default for this "basic" configuration)
But even with this connection, I have noticed that there is NO option in the webclient service, to perform the installation of a vCenter plug-in. It does not appear in the vSphere Client (see images).
I also found it weird that the web client to vCenter illustrates SRM roles but the traditional client does not work.
Maybe it's a clue to the root cause of...
Post edited by: ArrowSIVAC 2013-10-07 to provide more details and attachments
Post edited by: ArrowSIVAC, this is related to the case of support for vmware 13384832210 This problem is solved. Several pieces here. (1) vCenters were installed secretly with local account as own databases, and this is how I usually do things (2) MRS. servers were built as separate virtual machines, VMWare vs guides guess and documents in anticipation of your SRM installation on the same server as vCenter Documentation / Installer is not clarified that you MUST use domain for MRS accounts in the multiplayer linked site facilities and if you do not, the installation is completed without error, but resources will not work. Errors have for client plugin does not work. It was the symptom, the reason was that the SRM service did not work. The service would not start and only an error in the Windows event log is 'vmware-dr stopped service' is because the connectivity issue of MRS to vCenter hosted the new SQL instance database SRM. The SRM database has been installed on the instance of vCenter server as vCenter database. And just like the installation of default vCenter I chose localhost\administrator for database owner. The database was filled with tables, but SRM has connectivity problems. The fix for this was to add "domain\user" (called mine SRMAdmin and added as a member of domain admin), add this user in SQL in the list of database users and then promoted as the owner of SRM database and define the rights on DBO. This fixed the first issue. Second issue was that SRM installation set the DSN system identification information, but does not specify that they must also be domain based accounts. The installation program is not not clear here and should only allow user domain\username when installing. After several attempts because of the root and installation methods different tried, how to get the installation complete and properly configure was to log on to the system AS the example domain account: domain\srmadmin = > Configuration System DSN by selecting "How should SQL Server verify the authenticity of the login ID?" "with integrated Windows authentication', and then the installation of SRM to the"Enter Database user credentials"value"domain\srmadmin ". Then and communication services to the vCenter SRM hosted DB database will work correctly. < See images attached benchmarks >
attached files
-
How to avoid duplicates on a column with condition
Hi all
I need some advice here. At work, we have an Oracle APEX application that allow the user to add new records with the decision of the increment automatic number based on the year and the group name.
Said that if they add the first record, group name AA, for 2012, they get the decision number AA 1 2013 as their record casein displayed page of the report.
The second record of AA in 2013 will be AA 2 2013.
If we add about 20 records, it will be AA 20 2013.
The first record for 2014 will be AA 1 2014.
However, recently, we get a claim of the user on two files of the same name of group have the same number of the decision.
When I looked in the history table and find that the time gap between 2 record is about 0.1 seconds.
In addition, we have the correspondence table which allows the user admin update the sequence number start with the restraint that it must be greater than the maximum number of the current name of the current year.
This boot sequence number and the name of the group is stored together in a table.
And in some other case, the user can add a decision duplicate for related record number. (this is a new feature)
The current logic of the procedure to add the new record on the application are
_Get max record table with selected group name (decision_number) and the current year.
_INSERT in the folder table the new record came with the decision to number + 1
_ update sequence number of the number of the decision just added.
So instead of utitlising the process of editing the built-in automatic table of the APEX, I write a procedure that combine all three processes.
I have run some loop for continually perform this procedure, and it seems that it can generate autotically new decision unique number with time about 0.1 second difference.
However, when I increase the number of entry to 200 and let two users run 100 each.
If the time gap is about 0.01 second, double decision numbers are displayed.
What can I do to prevent duplicate?
I can't just apply a unique constraint here for three columns with condition because it can be duplicated in some special conditions. I don't know much about the use of lock and its impact.
This is the content of my procedure
create or replace
PROCEDURE add_new_case)
-ID just use the trigger
p_case_title IN varchar2,
p_year IN varchar2,
p_group_name IN VARCHAR2,
-decisionnumber here
p_case_file_number IN VARCHAR2,
-active
p_user in VARCHAR2
)
AS
NUMBER default_value;
caseCount NUMBER;
seqNumber NUMBER;
previousDecisionNumber NUMBER;
BEGIN
-execution immediate q '[alter session set nls_date_format = "dd/mm/yyyy"]';
SELECT count (*)
IN caseCount
OF CASE_RECORD
WHERE GROUP_ABBR = p_group_name
AND to_number (to_char (create_date, "yyyy")) = to_number (to_char (date_utils.get_current_date, "yyyy"));
SELECT max (decision_number)
IN previousDecisionNumber
OF CASE_RECORD
WHERE GROUP_ABBR = p_group_name
AND to_number (to_char (create_date, "yyyy")) = to_number (to_char (date_utils.get_current_date, "yyyy"));
IF p_group_name IS NULL
THEN seqNumber: = 0;
ON THE OTHER
SELECT Seq_number INTO seqNumber FROM GROUP_LOOKUP WHERE ABBREVIATION = p_group_name;
END IF;
IF caseCount > 0 THEN
default_value: largest = (seqNumber, previousdecisionnumber) + 1;
ON THE OTHER
default_value: = 1;
END IF;
INSERT INTO CASE_RECORD (case_title, decision_year, GROUP_ABBR, decision_number, case_file_number, active_yn, created_by, create_date)
VALUES (p_case_title, p_year, p_group_name, default_value, p_case_file_number, 'Y', p_user, sysdate);
-Need to update the sequence here also
UPDATE GROUP_LOOKUP
SET SEQ_NUMBER = default_value
WHERE the ABBREVIATION = p_group_name;
COMMIT;
EXCEPTION
WHILE OTHERS THEN
Logger.Error (p_message_text = > SQLERRM)
, p_message_code = > SQLCODE
, p_stack_trace = > dbms_utility.format_error_backtrace
);
LIFT;
END;
Many thanks in advance,
Ann
It's easier to solve for the case, while p_group_name is not null. In this case, you update a GROUP_LOOKUP line, so that you can select to update this line at the beginning, to prevent cases of two for the same group added at the same time. To do this, change the selection of GROUP_LOOKUP to:
SELECT Seq_number INTO seqNumber FROM GROUP_LOOKUP WHERE ABBREVIATION = p_group_name for an updated VERSION OF the SEQ_NUMBER;
and move this to be the first thing that did the procedure - before it has CASE_RECORD lines.
In the case when p_group_name is set to null, you have some object to be locked. I think the best you can do is to lock the entire table GROUP_LOOKUP:
the table lock in exclusive mode GROUP_LOOKUP wait 100;
The '100 expectation' means that he will wait until 100 seconds before giving up and trigger an error. in practice, that is expected to only wait a moment.
Exclusive mode allows others to read, but not to update the table.
UPDATES and the LOCK of the TABLE will be updates of other sessions wait for this transaction to validate. Queries from other sessions are not affected.
The locks are released when you commit or roll back.
-
The research of a column with comma separated values with ora-text
I use the Oracle 11 g 2 XE and Oracle Text to a web search engine.
I've now created and text indexed a CLOB keywords column that contains words separated by spaces. This allowed me to expand the search, as Oracle Text returns the rows that have one or more keywords that are stored in this column. The contents of the column are visible to the user and serves to 'expand' the search. This does not work as expected.
But now I need support several words or even sentences. With the current configuration, Oracle Text will only search for each keyword. How should I store the phrases and configure Oracle text so that it will search entire sentences (exact match is better, but the partial match is fine too)?
Example of content column of two lines (values separated semicolon):
"Hello, Hello; y at - it anyone out there? Nope; »
"the just; basic facts; »
I found a similar question: looking for a column with values separated by commas, except that I need a solution for Oracle 11 g with it's freetext search.
Possible solutions:
1st solution: I thought to redraw the DB as follows. I would like to make a new array of keywords (pkID NUMBER, nonUniqueID NUMBER, singlePhrase VARCHAR2 (100 BYTE)). And I want to change the column previous keyword to KeywordNonUniqueID, holding the ID (instead of a list of values). At the time of the research I had INNER JOIN with the new keyword table. The problem with this solution is that I will get several lines containing the same data except for the sentence. I guess this will destroy the ranking?
2nd solution: is it possible to store sentences as an XML in the column key of origin and somehow say Oracle text to search for in the XML?
3rd solution: separate individual phrases with spaces, but replace the spaces in sentences with the underscore or something (making a single word). If a phrase "why Hello there, Johnny!" is saved as "Why_hello_there, _Johnny!
4th solution?:
Note that, generally, there is a lot of sentences (less than 100), nor that they will be long (one sentence will be up to 5 words).
Also note that I am currently using CONTAINS, and needs some of its operators, to my full-text searches.When you talk about "phrase", do you mean "a list of words separated by a comma other sentences?
Isn't that the definition of "sentence" used by Oracle Text, where it simply means "a list of words in the order defined."
If I understand your requirement, you want to have data such as:
"aa bb cc dd".
"aa ee dd ff.and give priority to the first on the second if someone looking for "dd".
First, to conduct research in the comma separated list, you should look for in a section. You can either explicitly define sections of field such as
AA bb cc dd
Or you can use the PHRASE special section and set the sentence delimiters correctly. This is done with the attribute BASIC_LEXER punctuationThen you have the number you want to find only words where they are the only words in the section. That's the same problem, I address in the last post of this forum entry:
Contains: match exactlyOur solution will be substantially the same, some surrounding text with special markers, and then prioritize a phrase search with these special markers each side of the word.
We need to do a treatment some additional, although, as we need to surround each "sentence" (in your terminology) with special markers. I did it by surrounding the text with "XX1"... Condition2"then by replacing every comma with"Condition2, XX1"as part of a MULTI_COLUMN_DATASTORE:drop table names; create table names (id number primary key, text varchar2(50)); insert into names values( 1, 'just and kind, kind and loving' ); insert into names values( 2, 'just, kind' ); exec ctx_ddl.drop_preference ( 'mylex' ) exec ctx_ddl.create_preference( 'mylex', 'BASIC_LEXER' ) exec ctx_ddl.set_attribute ( 'mylex', 'PUNCTUATIONS', ',' ) exec ctx_ddl.drop_preference ( 'mcds' ) exec ctx_ddl.create_preference( 'mcds', 'MULTI_COLUMN_DATASTORE' ) exec ctx_ddl.set_attribute ( 'mcds', 'COLUMNS', '''XX1 ''||replace(text, '','',''XX2, XX1'')||'' XX2''' ) exec ctx_ddl.drop_preference ( 'mywl' ) exec ctx_ddl.create_preference( 'mywl', 'BASIC_WORDLIST' ) exec ctx_ddl.set_attribute ( 'mywl', 'SUBSTRING_INDEX', 'YES' ) create index namesindex on names(text) indextype is ctxsys.context parameters( 'datastore mcds wordlist mywl' ) / select score(1),id,text from names where contains( text, 'XX1 kind XX2 kind Output of this is:
SCORE(1) ID TEXT ---------- ---------- -------------------------------------------------- 52 2 just, kind 2 1 just and kind, kind and loving -
Indexes on columns with only "Y" and "n".
Our transaction table has about 100 mn lines. Of these latter on 60 minutes the lines are not actively used.
We have composite index on multiple columns, including dates, and these are used to regular queries.
Will be adding a status = 'y' or ' don't column and the creation of an index on this column is useful to increase the performance of the query?
For example, will add a condition like
OÙ......... AND ACTIVE_FLAG = 'Y '.
help increase the performance of queries?
Creating such a column and adding a help index?
What type of clue do you recommend?
The alternative advocated by some members of the staff is the archiving of INACTIVE lines in a separate table. This will have a big impact on business processes. But we might be able to pull it off.
Is there another solution.
I am a beginner full performance although I am familiar with PL/SQL and queries.
I'm on the constraints of very tight timetable for the first level of back. I'll have more time as soon as I know the direction in which to go.
Forgive me if I broke a tag forum. I'm new on the forum too.Thanks for providing this information. This gives a much clearer picture of what you are facing.
I will try to give you my answer your questions afterwards.
You have indicated your data volumes have steadily increased and performance made that decline.
Even if you do not say (I forgot to ask) but it may be that the number of users increases as and.
so typical, many users use the system of the time.For me it's indicative of a systemic problem. In other words, the problem is not due to a
a thing or a part of the system.There are two main components of a server: the instance and the database. This link sums up the difference
between the two - http://www.adp-gmbh.ch/ora/misc/database_vs_instance.html and here is a link to recent forum
for reference Re: difference between Oracle Instance and Database.To paraphrase, an instance includes background processes and structures of memory (SGA, PGA, etc.)
Oracle uses.The symptoms you describe could mean that your instance is more configured size not set correctly
for your current workload are originally strain throughout the system. Maybe the memory is too limited.
Maybe your sorts are growing with addional data.I suggest that you start the new thread to ask for help in the evaluation and optimization of your instance. Use this
as a starting point:
>
Question/title - how to evaluate the State of health / instance and tuneOur facility has a problem of increasing return.
How can we collect and provide assessment of workload and configuration information, so you can help determine
possible solutions such as: memory sizing, temp and segment again sizing, sort the issue.Statement of the problem
1 oracle Version is? ?. ?. ?2. gradually return was degrading with more and more data. The UI response suffers and
batch processing is also in hours. We expect volumes to only continue to grow.3. the volumes have continued to increase over the years and gradually performance issues
accumulate over the past 2 years. Data volumes began to increase faster
last year 1 due to changes in the company.4. the data in OLTP system is a combination of assets of 40% and 60% relatively inactive (financial history).
5. a complete system near-live replecation on several sites. In my opinion, using streams.
6. notice of the tech team is a few tables have too many lines. We know that our demands can be suboptimal.
>
Now to your question:
>
1. I do not know the index on the existing columns are not fully exploited. In the meantime can but, we still get some benefits from adding
a 'Y' and the null column? What will be improved?
>It is unlikely the benefits you need. It's putting the cart before the horse. The first step is to identify a specific problem.
Only then can examine you and evaluate solutions. for example by adding a new column or index.There are several reasons, this isn't the right solution; certainly not at the moment
A. any new column and index, BY DEFINITION, maybe even this does not use except if one or more current
queries are changed. This is obvious since no existing query could possibly refer to a column that does not exist.(B) to try to obtain the Oracle to use the new index column / single lease request must be changed.
C. in my opinion, you should never modify a query of production without knowing which allows to obtain the amendment
a well-defined objective. You must evaluate the current execution plan to identify what changes, IF ANY,
can improve performance.D. it can be and given your systemic problem is likely to be, some ripe fruit on the performance. That
is that there may be ways to tune the query to use existing indexes or add a new index on an existing column
improve things.E. assuming that none of the above does the work adding a new column and an index to identify
a 40/60 split (40% of assets) is unlikely to be used by Oracle (see response of Centinui).>
2. notes that this calculation 'Y' is not negligible. I can easily reproduce this with a WHERE condition on the existing columns. We can have
to run a batch on the weekend to check row groups and mark them as 'Y '. So it is not only the advantage of indexing on 'Y', but also some benefits of prior calculation.
Given this info doing now more logic to have a 'Y' and the null column?
>
My answer is no – there is no sense to have a Y/N Y/NULL column.A. certainly not for reasons of performance - as noted above above it is unlikely help
Certainly not for commercial reasons.
The calculation of your "non-trivial" is to demonstrate a business rule: identify groups of lines that have earned.
If you perform this calculation, the result must be saved significantly. One way is to create a new
column called 'DATE_NETTED_OUT '. This column name have meanings, and can be used as a boolean DATE/NULL type. This
It would be much better that Y/NULL which is not really enter the business sense of the value.>
3 partitioning speed up queries on the minutes 40 active and slow queries on the full 100 minutes?
>
Probably not to have one influence on the other. Allocation decisions are usually made to ensure easier data management and often
have little, if any, a performance impact. All existing applications are unlikely to accomplish the any
differently just because the table is partitioned. There are exceptions of course. If you partition on DATE
and an existing query has a DATE filter, but there is no index on the DATE column, it will do a full table scan
of the whole picture. If the table is partitioned on this DATE column that oracle would probably make a partition full
Scan just the 40% or 60% of the table according to the value DATE. It would be so much faster.But if there is already an index on the column DATE I do not expect the performance to change much. It comes
just speculation since it is based on data, the factor of grouping the data, and the existing queries.>
1. I still need to a particular column of partion, I do not?
>
Yes, you do. Unless you use HASH Partitioning that don't really benefit your use case. You too
says that "...". staff advocate is the archiving of INACTIVE lines in a separate table "."
Partitioning can be used as part of this strategy. Partition by MONTH or by QUARTER on your
new column "DATE_NETTED_OUT." Keep 1 or 2 years of data online as you do now and when a partition
becomes more than 2 years you can 'transport' it to your archiving system. This is part of the partition
management, which I mentioned earlier. You can simply disconnect the oldest partition and copy it to archive.
This will not affect your applications other than the data not being is not available.>
2. "adds a column' or ' cut-and - paste lines of table created by copy" the worst idea?
>
I don't know what that means.SUMMARY
It is premature to consider alternatives until you know what the problems are. Only then you can try to
determine the applicable solutions.I do it in this order:
1. upgrading to a newer version of Oracle you are on an older (you said 9i which is not
longer supported)2 assess the health and configuration of your instance. You may be able to significantly improve things
by adjusting the parameters of configuration and instance. Post a new question, as previously mentioned. I don't
have the expertise to advise you in details on that and the gurus tuning of the Forum the Forum can
not to notice this thread (indexes on columns with only 'Y' and 'n') than even know you need help.3. identify the ripe fruits for performance problems. Is this one of your batch process? An individual
request? You mentioned UI soon - that could be a problem of front end, middle tier or application
not a database one.4. don't it make changes architecture (add columns) until you have tried everything first.
-
am getting error error when am with funcation wm_concat.
Hi all
am getting error error when am with funcation wm_concat.
Thanks to all in advanceSQL> DECLARE 2 ex VARCHAR2(200); 3 BEGIN 4 SELECT wm_concat(ename) INTO EX FROM EMP WHERE deptno=30; 5 DBMS_OUTPUT.PUT_LINE(EX); 6 END; 7 8 . SQL> SQL> / DECLARE * ERROR at line 1: ORA-06550: line 4, column 10: PL/SQL: ORA-00904: "WM_CONCAT": invalid identifier ORA-06550: line 4, column 3: PL/SQL: SQL Statement ignored
Published by: Maldini on 9 January 2012 22:02Cool wrote:
HelloPlease check the version of database you are using.
wm_concat is available from 11 g Release 2.
Incorrect answer.
wm_concat is undocumented and should not be used.
Even Tom Kyte tell you... Re: SEPARATE does not not with wmsys.wm_concat
11 GR 2, there is a documented feature called LISTAGG...
http://docs.Oracle.com/CD/E11882_01/server.112/e26088/functions089.htm
-
[8i & 10g XE] How to compare a column with the text of a column with numbers
This is probably a simple question, but I can't seem to find the answer. I tried variations on use to_number to_char and interpreters, all nothing will do.
The real problem is that I have a table with a column of numbers in a database 8i (datatype = NUMBER (3)) and a column with the text (datatype = CHAR (3)), and I need to compare two values.
This table has thousands of lines, but here's an example of the data in these two columns:
What I want to do is select the lines where the TXT and CHR VALUES do not match, then it would be (given my example):TXT CHR ----------- 001 1 001 2 002 2 XXX 1 003 3
But, I'm having difficulties in comparing two columns, because they are not the same type of data.TXT CHR ----------- 001 2 XXX 1
I tried to work on a simplified version of the problem in the 8i database both my 10g XE database:
But this also returns any line, and it isn't even the "XXX" in the text column to treat in this example.SELECT * FROM ( SELECT 1.000 AS nbr , TO_CHAR(1.000,'000') AS txt , CAST('001' AS CHAR(3)) AS chr FROM dual ) WHERE txt = chr ;
Can someone help me understand what it is that I'm missing?
Thank you!Hello
user11033437 wrote:
This is probably a simple question...Simple if you know the secret; maddening if you do not have.
... I tried to work on a simplified version of the problem in the 8i database both my 10g XE database:
SELECT * FROM ( SELECT 1.000 AS nbr , TO_CHAR(1.000,'000') AS txt , CAST('001' AS CHAR(3)) AS chr FROM dual ) WHERE txt = chr ;Try:
TO_CHAR (1.000, 'FM000')By default, TO_CHAR leaves place the beginning of the string to a sign less, in which case he should ever one, TO_CHAR (1,000, '000') returns makes 4 characters, not 3. "FM" in the format said TO_CHAR do not add a space.
If it does not, after the release of DUMP (txt) for the few lines that you can't match, so that we can see exactly what is in them.
-
Error using filter with Expression SQL
Hey all -
New to Oracle BI and have a problem with filters that use the SQL Expressions.
The column I'm filtering is a 4-digit year, expressed as a VARCHAR2(4 byte) in the physical database. My SQL Expression in the filter is:
Column: CAL 4-DIGIT YEAR
Operator: is in
SQL expression: TO_CHAR (ADD_MONTHS (SYSDATE,-24), "YYYY"))
When I click on the "Results" tab, I get the following error message:
Error codes: YQCO4T56:OPR4ONWY:U9IM8TAC:OI2DL65P
ODBC driver returned an error (SQLExecDirectW).
State: HY000. Code: 10058. [NQODBC] [SQL_STATE: HY000] [nQSError: 10058] A general error occurred. [nQSError: 27002] Near <>(): syntax error [nQSError: 26012]. (HY000)
I've isolated the problem to the above expression. If I put a literal value and provide a year to four digits as below, it works:
Column: CAL 4-DIGIT YEAR
Operator: is in
SQL expression: * 2008. *
Any ideas on what is causing my problem?
Thank you!
MacYep, this should work, although sometimes you need an extra cast to CHAR.
It works fine:
SELECT "D0 time." "" Saw_0 T05 by name of the year ","recipes of F1. " "" Recipes 1-01 (all in all) ' saw_1 'Sample Sales' WHERE 'Time D0. "" T05 by name year ' = CAST (YEAR (TIMESTAMPADD (SQL_TSI_MONTH-24, CURRENT_DATE)) as CHAR) ORDER BY saw_0concerning
John
http://www.obiee101.blogspot.com/ -
Error: No function with name to_date does exist in this scope
Hai All
insert into dail_att(empcode,barcode,intime,attend_date)
(select r1.barcode, to_date (to_char (r1.bardate, 'ddmmyyyy'): min (r1.bartime), 'ddmmyyyy hh24mi'),)
R1.bardate of the r1.barcode temp_attendance group, r1.bardat);
It is my statement to insert
Here I insert data Dail_att the table Temp_attendance and here R1 is the folder that I stated.
It works very well. More I need to add a column in the Insert EMPCODE IE and I need to
take Empl_barcode.
Table of Empl_barcode consist of fields
Empcode tank
Barcode varchar
Etc.
So I need to include empcode in this statement when I use this in my insert statement
insert into dail_att(empcode,barcode,intime,attend_date)
(selecte.emplcode, r1.barcode, to_date (to_char (r1.bardate, 'ddmmyyyy'): min (r1.bartime), 'ddmmyyyy hh24mi'),)
Temp_attendance R1.bardate, e empl_barcode, where e.barcode = r1.barcode group by
R1. Barcode, R1.bardate, e.emplcode);
I got an error
No function with name to_date does exist in the scope
Any help is highly appericatable
Thanks and greetings
Srikkanth.M
Published by: Srikkanth.M on April 24, 2010 09:26Dear Srikkanth,
First of all, in the table / column you provided and that the corresponding query names there are a large number of spelling errors or incompatibilities. It is very important that you make sure that your question is consistent.We have 'trying to figure out' if Bar_code is anme name or a table column, whence the emplcode column etc.
Take the time to write the question and format, please.
Frame queries and code in a pair of tags {code} without spaces.That said...
update dail_att set empcode=(select emplcode from empl_barcode ,dail_att where bar_Code= barcode); And i have an error ORA-01427: single-row subquery returns more than one rowLet us think about this...
The subquery in your update statement (which is the main request) is(select emplcode from empl_barcode ,dail_att where bar_Code= barcode)In this query, you want to join empl_barcode table and dail_att on * bar_code = barcode) condition.
Why must you table dial_att in the subquery? You do not have.
Remove dail_att the subquery table.VR
Sudhakar B. -
How to take a column of duplicate names and fill a different column with the same names, excluding duplicates?
I find easier to use this copy separate Automator Service (download Dropbox).
To install in your numbers > Services, double-click menu just the package downloaded .workflow and if necessary give permissions in system preferences > security & privacy.
To use, just:
- Select the cells in the column with duplicate names.
- Choose separate copy in numbers > Services menu.
- Click once in the upper cell where you want the deduplicated values appear.
- Command-v to paste.
SG
-
An internal tool or the library returned an error.
I had a very slight modification of a source today and update the source file. When I tried to build the distribution, however, failed to build with the following messages: "Error Part developer configuration options", then "an internal tool or the library returned an error." No other information was provided as to the source of possible error. It is a project that has been maintained for several years. I tried to build in 2015 of the BCI and in 2013 with the same results. I was able to build another project without error.
I've attached a screenshot of the error window. I was able to build the distribution after you have created a new file .cds. The other file must be corrupted in some unknown way.
-
Error updating databases with more than 255 characters of text
Rocking LV2012 with a database MS Access 2000 was created and the installer in a different environment. Try to access and manipulate the data using a LV because GUI sucks one, they built for us.
Some columns are of type "Memo" and LV indicates column information for these columns with a size of 1073741823. The problem is that if I try to update the data in these columns with the Data.vi to update the DB tools and the string is > 255 or so characters I get:
ERROR-2147217887
Possible reasons:
ADO error: 0x80040E21
Exception occurred in the Microsoft OLE DB provider for ODBC drivers: value invalid precision [Microsoft] [ODBC Microsoft Access driver] to create a NI_Database_API.lvlib:Rec - Command.vi-> NI_Database_API.lvlib:Cmd Execute.vi-> NI_Database_API.lvlib Data.vi B Tools Update-> update DB.vi-> GTS.vi
Data.vi B Tools Update-> update DB.vi-> GTS.viI realize that 255 is the limit for certain applications. Is there some settings that I have to do to have the limit defined by the data source, and not by any supplier is to limit the length of the data?
It should work. Looks like you are using the database connectivity kit. This could also be a problem. Click here for other drivers.
http://www.notatamelion.com/2015/01/05/managing-data-the-easy-way/
Mike...
-
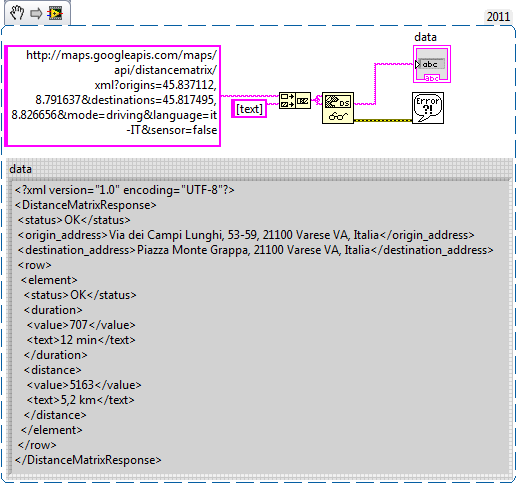
Why the HTTP become function returns the error code 63?
I tried to use the get HTTP function to get the XML file is returned by the api Google MAPS distance-matrix. I got the right answer if I insert the url directly in the browser, but using the get HTTP function, it returns the error 63, why?
This is my code (the VI is developed on LV2011).
I guess, the VI GET for use with LabVIEW Web Service, only not to get of the Internet pages.
Using the simplest way:
Andrey.
-
I am running Windows 7 and noticed that Windows updates did not work. The parameters are defined for the update every day. When I went to update manually returned an error WindowsUpdate_80070017. MSFT site was no help. Any recommendations?
Since neither updates Jan - 10 have installed, I'm going to hand you Support MS in the hope that they can resolve the problem. See below.
That being said, is an interpretation of the 80070017 - cyclic redundancy check error "a device attached to the system does not work," which suggests that a hardware problem might be the cause of the error (although I must say that it is a very low possibility in this case).
Good luck!
=======================
Visit the Microsoft Solution Center and antivirus security for resources and tools to keep your PC safe and healthy. If you have problems with the installation of the update itself, visit the Microsoft Update Support for resources and tools to keep your PC updated with the latest updates.
~ Robear Dyer (PA Bear) ~ MS MVP (that is to say, mail, security, Windows & Update Services) since 2002 ~ WARNING: MS MVPs represent or work for Microsoft
Maybe you are looking for
-
Satellite C70 - A - get BT cannot work
Hello I just installed bluetooth suite driver thread of suggestion, but I can't manage to see in Device Manager... I have model controller C70 - A win 8.1 Atheros ethernet Realtek Wireless LAN
-
my ipod is disabled. I will lose all the photos when I erase
my ipod is disabled. I understand that I need for recovery, but I lost all my photos?
-
I use the E bike since the last 2 weeks. The front of the phone, it is the screen worsens when, after 10-15 minutes of gameplay or any such intensive use, & if I keep going it continues to become more heated. This is my IMEI number - [edited for your
-
Problem with drivers when downgraded from windows 8 for windows 7
Product Nam: laptop HP Pavilion G6-2360EJ I can't find a driver that works with my windows 7 home premium... and when I find that some of them does not work I searched hp website for my product and it gives me just the drivers of windows 8 Please hel
-
Help me with lack drivers basic system for Parvillion dv4-1413xt Entertainment Notebook PC
Dear company, I currently have 3 drivers system missing or not installed Base and 1 unknown driver missing or not installed this com. My laptop is a HP Parvillion dv4-1413xt Entertainment Notebook PC with an Intel Centrino 2 processor / 4 GB RAM / 32