Sinlge select query in the diff for the same table (same Structure) diagrams
Scenario:Table XYZ is created in detail a.
After a year, the old data of the previous year could be moved to another schema. However in the other schema of the same table name would be used.
For example
A schema contains XYZ table with data from the year 2012
Schema B contains XYZ table with data for the year 2011
Table XYZ in the two schemas have an identical structure.
So we can draw a single select query to read the data from the tables in an effective way.
For example select * from XYZ so including date between October 15, 2011 to March 15, 2012.
However, the data resides in 2 different schema altogether.
Creating a view is an option.
But my problem, there are ORM (Hibernate or Eclipse Top Link) layer between the application and the database.
If the queries would be constituted by the ORM layer and are not generated by hand.
So I can't use the view.
So is there any option that would allow me to use only query on different scheme?
970773 wrote:
Scenario:Table XYZ is created in detail a.
After a year, the old data of the previous year could be moved to another schema. However in the other schema of the same table name would be used.For example
A schema contains XYZ table with data from the year 2012
Schema B contains XYZ table with data for the year 2011
Table XYZ in the two schemas have an identical structure.So we can draw a single select query to read the data from the tables in an effective way.
For example select * from XYZ so including date between October 15, 2011 to March 15, 2012.
However, the data resides in 2 different schema altogether.Creating a view is an option.
But my problem, there are ORM (Hibernate or Eclipse Top Link) layer between the application and the database.
If the queries would be constituted by the ORM layer and are not generated by hand.
So I can't use the view.
Why not make the ORM as below?
SELECT * FROM VIEW_BOTH;
-VIEW_BOTH is a real VIEW of Oracle
Tags: Database
Similar Questions
-
Restore the value of the selected line in the editable Table.
Hello, I use Jdeveloper 11.1.2.1.0.
My problem is:
1. Select a line in the editable table.
2. change the value inside elements of the af:inputText of columns.
3. tap on restore.
4. the values of the selected line remains the same.
If I select another line, before the restore, the restore will work as expected.
I want to when you press the button cancel the values of the selected row to be rollback-ed as well.Set the immediate on all the inputTextFields in the table and it worked.
Thank you.
-
limitation of the same structure add cases
Hello
Can I know any excretion have the same structure add event .bcase if I use more than 50 events in strucute even.
I posted on the forums about the recording of the change in value on multiple controls here and here.
There is no real problem having lots of event, but it takes a lot of time for each of them create then because I'm lazy, I'm trying to find ways to accelerate my LabVIEW programming - if you have a lot of events that do the same thing, so you can save time by having a single piece of code manage events.
-
compare files with the same structure of channel / rename channel(-groups)
Hello
I have several groups ch with many channels in the file of each measure.
Now, I need to display/compare Channels 2 or more files of measures in a chart. (channel 'speed1' to the file 'measurement1' vs 'speed1' to the file 'GCA2' channel)
So I import 2 files in the browser und have the same structure of string twice. To distinguish between the channels of the two files I want to rename the channels by script and add the file name of the channel-group name.
Is this a common way to compare measurement data in files with the same channel names and structures?
In the affirmative. How can I make a script?
Thank you very much in advance!
Ski
Hi Ski-Fahrer,
each channel has a name of the institution.
Data.Root.ChannelGroups ("Name" or Index). Channels (Index or "Name"). Name
You can assign a new name like this:... Name = "NouvNom".
I don't think it is necessary to rename the channels. If you do not forget the files. If you want to rename something I only rename the ChannelGroups by adding a date or a serial number.
Kind regards
Philipp K.
AE | NOR-Germany
-
Nested set tables in select query "in the clause of" take long time
create or replace type t_circuitids is table of the varchar2 (100);
-Under anonymous block continues to run away and never ends
DECLARE
v_circuitid t_circuitids;
number of v_count;
l_circuitids VARCHAR2 (4000)
: = "Value1, value2, value3, value4, Value5";
BEGIN
-Query below converts the output concatinated with commas to the list and stores it in the nested table collection v_circuitids
WITH an ACE
(SELECT ',' | l_circuitids |) ',' AS circuitid
THE DOUBLE)
SELECT DISTINCT TRIM (SUBSTR (circuitid,
INSTR (circuitid, "," 1, LEVEL) + 1.
INSTR (circuitid, "," 1, LEVEL + 1)
-INSTR (circuitid, "," 1, LEVEL)
-1
)
) cid
LOOSE COLLECTION v_circuitid
A
CONNECT BY LEVEL <
LENGTH (circuitid)
-LENGTH (REPLACE (circuitid, ','));SELECT COUNT (1)
IN v_count
TABLE
WHERE name IN (SELECT COLUMN_VALUE
TABLE (v_circuitid));
END;
/-I had the question, query "SELECT COLUMN_VALUE FROM TABLE (v_circuitid)" that is used in code above is responsible for this.
-Same code works fine in development and Test environments, but prod it continues to work on
-I solved this problem by creating a temporary table, loading of all values in the collection in the temporary table and using this temporary table "in the clause" "
-Can answer why his behavior like this when I use the collection where clause?
-I use Oracle 9i
Here is a summary of the question and the solution for this.
-Nested type to collect multiple values
CREATE or REPLACE the TYPE t_circuitid IS TABLE OF VARCHAR2 (100);
Below the code will simply on the run.
DECLARE
v_circuitid t_circuitid;
v_count NUMBER;
BEGIN
SELECT nal_name
LOOSE COLLECTION v_circuitid
OF fs_head
WHERE groupid = 10;SELECT COUNT (1)
IN v_count
OF fs_attrib
WHERE NAME IN (SELECT COLUMN_VALUE
TABLE (v_circuitid));Dbms_output.put_line (v_count);
END;
/Cause:-SELECT COLUMN_VALUE TABLE (v_circuitid)); -This request is causing problem
Why? : - Because the CBO does not know how many lines is present in the collection, by default it takes 8168 lines
Note:-always happens, it depends on the volume of data in the table, the path chosen by CBO. In my case, the table is huge on prod compared to DEV so he was causing a problem.
-The following modified code works very well
DECLARE
v_circuitid t_circuitid;
v_count NUMBER;
BEGIN
SELECT nal_name
LOOSE COLLECTION v_circuitid
OF fs_head
WHERE groupid = 10;SELECT COUNT (1)
IN v_count
OF fs_attrib
WHERE NAME IN (SELECT / * + cardinality (20 t) * /)
COLUMN_VALUE
TABLE (v_circuitid) t);Dbms_output.put_line (v_count);
END;
/Solution:-used as cardinality hint below.
SELECT / * + cardinality (20 t) * / t COLUMN_VALUE TABLE (v_circuitid);
Using cadinality I am saying CBO which dataset contains 20 lines or less.
If it is version of Oracle 10 g and more, we can use below code (CARD utility).
SELECT COLUMN_VALUE TABLE (CARD ((v_circuitid))
For more information reach me at [email protected]
Thank you best regards &,.
Amarnath a. Reddy.
-
How to store results of the select query in the tables.
I created a variable varray type and now want to assign some data of output of the select query in pl/SQL, as well as in reports 6i.You are in the wrong forum (this is for problems with the SQL Developer tool). You were the one where you have published first on the right, but not to reuse independent threads as you did.
Kind regards
K. -
Query on the organized Table (IOT) Index sorts unnecessarily data
I created hist3 to the table as follows:
create table hist3)
reference date,
palette varchar2 (6).
Artikel varchar2 (10),
Menge number (10),
status varchar2 (4).
VARCHAR2 (20) text.
VARCHAR2 (40) data.
primary key constraint hist3_pk (reference, palette, artikel)
)
index of the Organization;
The table being an IOT, I expect that the retrieval of rows in the same order as in the primary key must be very fast.
This is true for the following query:
SQL > select * from hist3 by reference;
-----------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | 1000K | 82 M | 3432 (1) | 00:00:42 |
| 1. INDEX SCAN FULL | HIST3_PK | 1000K | 82 M | 3432 (1) | 00:00:42 |
-----------------------------------------------------------------------------
But if I add the following column of the primary key as a criterion of the order, the query becomes very slow.
SQL > select * from hist3 by reference, palette;
------------------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | TempSpc | Cost (% CPU). Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | 1000K | 82 M | 22523 (1) | 00:04:31 |
| 1. SORT ORDER BY | 1000K | 82 M | 200 M | 22523 (1) | 00:04:31 |
| 2. FULL RESTRICTED INDEX SCAN FAST | HIST3_PK | 1000K | 82 M | 2524 (2) | 00:00:31 |
------------------------------------------------------------------------------------------
If I look at the execution plan, I don't understand why a SORT statement should be needed, as data already take the IOT in the order requested.
Any thoughts?
ThomasThere are various ways how Oracle sorts VARCHARs.
When you create an index on a VARCHAR column, sort order is binary.
Try ' alter session set nls_sort = "BINARY" "and run your query." -
Select Insert on the same partition: RELATIONAL() - REMOVE a GLOBAL INDEX
Hi all
I found on v$ sqlarea suite statament:
insert / * + / RELATIONAL PARALLEL ("TABLENAME") ("TABLENAME", 1) ADD NESTED_TABLE_SET_SETID NO_REF_CASCADE * /
in "SCHEMA." "" TABLENAME ' partition ('DAY20151015')
(
Select / * + RELATIONAL("TABLENAME") PARALLEL("TABLENAME", 1) * /.
*
a 'schema '. " TABLENAME' partition ("DAY20151015") ".
)
Remove the global index
This is a query that reads and writes the same data on the same partition!
I think that it is generated by Oracle, but I don't undestand what he does.
Can you give me some explanation or assistance on this query?
Thank you very much
This is a query that reads and writes the same data on the same partition!
Well not - enough is NOT that.
The RELATIONAL indicator causes unnest Oracle object data and insert the data from the attribute itself rather than the object.
The indicators used are usable only by Oracle-c ' is why they are undocumented. You can find songs on the web, but practically everything you find is "best estimate".
-
Select values from the db1 table and insert into the DB2 table
Hello
I have three databases oracle running in three different machines. their ip address is different. among the DB can access databases. (means am able to select values and insert values into tables individually.)
I need to extract data from the DB1 table (ip say DB1 is 10.10.10.10 and the user is DB1user and the table is DB1user_table) and insert the values into DB2 table (say ip DB2 is 11.11.11.11 and the user is DB2user and table DB2user_table) of DB3 that is to have access to the two IPs DB.
How do I do this
Edited by: Aemunathan on February 10, 2010 23:12Depending on the amount of data must be moved between DB1 and DB2, and the frequency at which this should happen, you might consider the SQL * COPY more control. I think it's very useful for one-off tasks little, so I can live within its limits of the data type. More http://download.oracle.com/docs/cd/E11882_01/server.112/e10823/apb.htm#i641251.
Change some parameter of sqlplus session are almost mandatory in order to get decent transfer rates. Tuning ARRAYSIZE and COPYCOMMIT can make a huge difference in flow. LONG change may be necessary, too, depending on your data. The documentation offers these notes on use:
To activate the copy of data between Oracle and databases non-Oracle, NUMBER of columns is replaced by DECIMAL columns in the destination table. Therefore, if you are copying between Oracle databases, a NUMBER column with no precision will become a DECIMAL column (38). When copying between Oracle databases, you must use SQL commands (CREATE TABLE AS and INSERTION), or you must make sure that your columns have a specified precision.
SQL * the VALUE LONGER variable limits the length of the LONG column you are copying. If all LONG columns contain data exceeds the value of LONG, COPY truncates the data.
SQL * Plus performs a validation at the end of each successful COPY. If you set the SQL * variable more COPYCOMMIT DEFINED to a value positive n, SQL * Plus performs a validation after copying all lots n of records. The SQL * Plus ARRAYSIZE variable SET determines the size of a batch.
Some operating environments require that the service names be placed between double quotes.
From a SQL * Plus term on DB3, can resemble the command to move all content from my_table in DB1 to the same table in DB2
COPY from user1/pass1@DB1 to user2/pass2@DB2 - INSERT INTO my_table - USING select * from my_tableNote the SQL code * more line-continuation character ' - '. It is used to escape the newline character in a SQL * Plus command if you do not have to type all on one line. I use it all the time with this command, but I can't locate the documentation on that right now. Maybe someone else can put their finger on it.
There are other ways to accomplish what the command copy and it is not without its quirks and limitations, but I find that there is usefulness in an Oracle Toolbox.
-
Creating tables with the same Structure and with the remote control FOR the parts database
Hello
I have a remote DB connection and a local DB connection in my system
I want to create the same Table and data from my DB remote to Local Connection DB connection.
Please tell me how to do this?CREATE TABLE LOCAL_TABLE AS SELECT * FROM REMOTE_TABLE@TNS_ALIAS;
-
How to select data using the same remote database column name 3
Hello
Can anyone help me on how to get the data with the same remote database column names 3 and a unique nickname.
E.g.
SELECT *.
B.SID, b.status, SUM (b.qty) qantity MAX (b.) date_as_of
Of
* ((table1@remotedatabase1, table1@remotedatabase2, table1@remotedatabase3) has, *)
(* (table1@remotedatabase1, table1@remotedatabase2, table1@remotedatabase3) b). *
WHERE b.dept = 'finance '.
AND a.position = "admin".
AND a.latest = 'Y' AND (b.status <>"MLT") AND b.qty > 0;
B.SID GROUP, b.status;
NOTE: the instructions "BOLD" is just an example of what I want to do but I always get an error beacause of ambiguous column.
Thanks to advnce. :)
Published by: user12994685 on 4 January 2011 21:42user12994685 wrote:
Can anyone help me on how to get the data with the same remote database column names 3 and a unique nickname.
Not valid. This makes no sense and breaks all the rules of scope-resolution. And if it is in a single database, or uses tables in databases, is not relevant.
Each object must be particularly well identified. If you cannot do this:
select * from (table1@remotedatabase1, table1@remotedatabase2, table1@remotedatabase3) a3 objects cannot share the same alias. Example:
SQL> select * from (dual, dual) d; select * from (dual, dual) d * ERROR at line 1: ORA-00907: missing right parenthesisYou need to combine objects - by using a join union or similar. He will have to be done as follows:
SQL> select * from (select * from dual d1, dual d2) d; select * from (select * from dual d1, dual d2) d * ERROR at line 1: ORA-00918: column ambiguously definedHowever, we need to have unique column in a projection of SQL names - so the join of the need to project a unique set of columns. So:
SQL> select * from (select d1.dummy as dummy1, d2.dummy as dummy2 from dual d1, dual d2) d; DUM DUM --- --- X X SQL>I suggest that you look carefully at what opportunities are and how it applies in SQL - and ignore if the referenced objects are local or remote, because it has no effect on the basic principles of scope-resolution.
-
Help with a query on the HRMS tables
I need assistance with a request that I'm running. Here are two tables that I'm trying to join:
PER_ALL_POSITIONS
PER_ALL_PEOPLE_F
What I'm trying to accomplish is to get the first name, last name by PREPtable ALL_PEOPLE_F and then join the PER_ALL_POSITIONS table to get a unique list of positions. However what I need help for is to determine how to join the two tables. I know that the primary key on PER_ALL_PEOPLE_F is Person_ID but this value does not appear in the table PER_ALL_POSITIONS. Could someone give me any advice would be greatly appreciated. :)you need go to per_all_assignments_f, then to per_all_positions per_all_people_f.
-
Generate select 2 in the same statement consecutive sequence numbers
Hello
Could someone please tell me how to generate 2 consecutive sequence numbers in the same select statement.
See you soonCREATE SEQUENCE my_seq INCREMENT BY 2 / select nxt_value , nxt_value + 1 from ( select my_seq.nextval nxt_value from dual ) /Anton
-
Dear all.
I have 2 progrlams application in the same schema. the intention is to use the 2 different when excuting programs for different applications, and each have to stop and start button, of course, I'll have to stop master. But when I run the program, it works as a program in time, it's the 1st block which I make active only, when I tried to activate the second block, that won't work, works only when I stopped the1st one. So, he wants your help, how can I solve my problem. Here I am attaching some of my programs.
Kind regards!
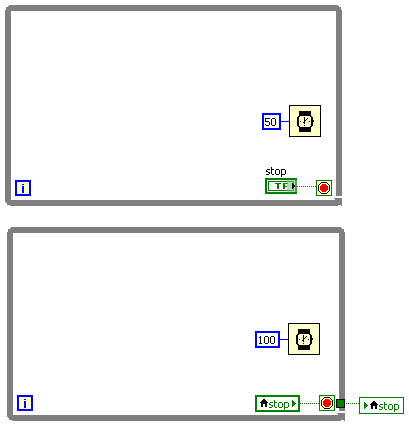
Furthermore, if you want two loops to run at the same time, just this.
-
How to run several programs simultaneously on the same block diagram
Hi all
I want to run three instruments simultaneously on the same schema. One is a control position for linear drives, other is an optical micrometer and the third is a digitizer card. When using tabs of the controls, the linear actuator Vi is the only thing that seems to work (confirmation on the front panel) but the optical micrometer show no indication on the front panel, but runs in background. I used a tab control to consume less space on the front panel. Someone can help me solve this problem where I can carry several bolts on a single diagram and could even see on the front panel. I enclose my VI.
Thanks for the help!
I can't open your VI, but in general; Either you use a loop with all the instruments in the same loop, or separate loops each with no wires between them that forces the execution order. You have none of this?
Tab control is purely visual, and has nothing to do with the execution.
/Y
Maybe you are looking for
-
I want to make a photo of a 2D of the 8 data bits unsigned integer matrix. I can do successfully using the function to "draw no flattened pixmap. However, it requires a color card. If you don't wire the card color, it uses the default mapping of colo
-
Which connection to Windows 8.1 the eye symbol and the symbol of the arrow to the right were posted up to that (I think so) after an automatic update of Windows. As I was intending to migrate to Windows 10 I na not invest a lot of research on this pr
-
Im having Aproblem install programs, I think it is somewthink to do whit windows installer
Im having a problem installing programs, I think it could be the windows installer
-
Activity report of PC showing use 24 hours a day
I'm administrator of my son with Windows 7 PC. I set parental control for hours limited to 4 per day, between 4-8 pm. However, his report shows 24 hours some days, which is impossible because the computer is unplugged and in full view as limited. Wha
-
GIMP works do not correctly under Windows 7 (GUI problem)
I think it could be a problem in GTK +. I have problems selecting an item with the click of the mouse. I can go over it with the pointer, it became blue, but I can't click on it, i like is stuck. He accepted instead of the 'Space' key as a confirmati