sort of an index by table
Hi all
I have a button on a form to run reports,
There is a tabular block that has names of patients and a check box,
When a user check more than one box, baptisms of report,
When you close the first report, the second runs and so on.
the problem is that there is another element that maintains a number when you check in a patient,
If you check a patient, then the element holder is (1).
you check the second element holds (2),
but you can check the second record so that the point spacers (1), then check the first records in the block, so the first record holds (2),
When you click the button to run the reports,
(2) will be held the first (1), and that's what I don't want to happen, I want to sort them.
check who is the owner of one (1) works first, and who owns the tracks (2) second and so on.
so
I wrote this code in the button which runs reports, but is not what I want, it runs reports according to records not the numbers.
declare
V_PARM PARAMLIST ;
LST_REC NUMBER ;
REQUEST_NUM NUMBER:=1;
TYPE V_RECORD IS RECORD (V_VISIT_ID MR_PATIENT_VISITS.VISIT_ID%TYPE
,V_ORG_NO RC_PATIENT_EPISODES .ORGANIZATION_NO%TYPE
,V_NUM NUMBER);
TYPE PRD_TYPE IS TABLE OF V_RECORD INDEX BY BINARY_INTEGER;
PRD_TABLE PRD_TYPE;
BEGIN
GO_ITEM('ALL_ADMITTED_PATIENT.PATIENT_FILE_NO') ;
FIRST_RECORD ;
LOOP
IF :ALL_ADMITTED_PATIENT.CHECK_PAT = 'Y'
THEN
PRD_TABLE(:ALL_ADMITTED_PATIENT.NUM).V_VISIT_ID := :ALL_ADMITTED_PATIENT.VISIT_ID;
PRD_TABLE(:ALL_ADMITTED_PATIENT.NUM).V_ORG_NO := :ALL_ADMITTED_PATIENT.ORGANIZATION_NO;
PRD_TABLE(:ALL_ADMITTED_PATIENT.NUM).V_NUM := :ALL_ADMITTED_PATIENT.NUM;
V_PARM := GET_PARAMETER_LIST('REPDATA');
IF NOT ID_NULL(V_PARM) THEN
DESTROY_PARAMETER_LIST(V_PARM);
END IF;
V_PARM := CREATE_PARAMETER_LIST('REPDATA');
Add_Parameter(v_parm,'P_VISIT_ID' ,TEXT_PARAMETER, PRD_TABLE(:ALL_ADMITTED_PATIENT.NUM).V_VISIT_ID);
Add_Parameter(v_parm,'P_ORGANIZATION_NO' ,TEXT_PARAMETER,PRD_TABLE(:ALL_ADMITTED_PATIENT.NUM).V_ORG_NO);
REQUEST_NUM := REQUEST_NUM +1;
RUN_REPORT('MRSHTVIW',TO_NUMBER('1'),V_PARM ,'OCX_BLOCK.OCX');
EXIT WHEN :SYSTEM.LAST_RECORD = 'TRUE' ;
NEXT_RECORD ;
ELSE
EXIT WHEN :SYSTEM.LAST_RECORD = 'TRUE' ;
NEXT_RECORD ;
END IF ;
END LOOP ;
END;
-------------------
I want to sort the 'index by table' once he gets the data in it?
or any other solution
Many thanks to you all,.
Thank God I solved it, it comes to the latest version of my code that solved the problem:
DECLARE
V_PARM PARAMLIST ;
TYPE ADT_REC_TYPE IS RECORD (V_VISIT_ID VARCHAR2(90) ,
V_ORG_NO VARCHAR2(90)
) ;
ADT_REC ADT_REC_TYPE ;
TYPE ADT_TAB_TYPE IS TABLE OF ADT_REC_TYPE
INDEX BY BINARY_INTEGER ;
ADT_TAB ADT_TAB_TYPE ;
BEGIN
GO_BLOCK('ALL_ADMITTED_PATIENT') ;
FIRST_RECORD;
LOOP
IF :ALL_ADMITTED_PATIENT.CHECK_PAT = 'Y'
THEN
ADT_TAB(:ALL_ADMITTED_PATIENT.NUM).V_VISIT_ID := :ALL_ADMITTED_PATIENT.VISIT_ID ;
ADT_TAB(:ALL_ADMITTED_PATIENT.NUM).V_ORG_NO := :ALL_ADMITTED_PATIENT.ORGANIZATION_NO ;
END IF ;
EXIT WHEN :SYSTEM.LAST_RECORD = 'TRUE' ;
NEXT_RECORD ;
END LOOP ;
FOR I IN ADT_TAB.FIRST .. ADT_TAB.LAST LOOP
V_PARM := GET_PARAMETER_LIST('REPDATA');
IF NOT ID_NULL(V_PARM) THEN
DESTROY_PARAMETER_LIST(V_PARM);
END IF;
V_PARM := CREATE_PARAMETER_LIST('REPDATA');
Add_Parameter(v_parm,'P_VISIT_ID' ,TEXT_PARAMETER, ADT_TAB(I).V_VISIT_ID);
Add_Parameter(v_parm,'P_ORGANIZATION_NO' ,TEXT_PARAMETER,ADT_TAB(I).V_ORG_NO);
RUN_REPORT('MRSHTVIW',TO_NUMBER(:GLOBAL.LANGUAGE_ID),V_PARM ,'OCX_BLOCK.OCX');
END LOOP ;
END ;
Tags: Oracle Development
Similar Questions
-
How to view the columns (and the sequence and sort order) an index?
Suppose I have an INDEX for an existing TABLE.
How can I know the columns covered by this INDEX (and the sequence and sort order)?
Which table contains this information?
ALL_INDEXES does not work.
Peteruser559463 wrote:
Suppose I have an INDEX for an existing TABLE.How can I know the columns covered by this INDEX (and the sequence and sort order)?
Which table contains this information?
ALL_INDEXES does not work.
Peter
--
Select the table table_name, column_name, index_name, and position_colonne
of user_ind_columns
order by table_name, index_name, position_colonne; -
How to index a table on multiple sites?
Hello
How to index a table on multiple sites?
I searched this issue and was not able to find the answer. I understand that it can be done with loops, but I don't know how.
I use the detector of crete vi for frequency domain data collected a VNA (s2p) file. The products contain a table of amplitudes and a table of locations. The problem is that the locations refer to the index of table of amplitude, which is not the same as the frequency. My idea is that I can use this output of the places table to index the frequency to the detected peak frequencies table and then draw these, as well as some analysis data and manipulation on them. Currently, I can do this only by consulting table on the front panel.
The entrance to the peak detector is currently a table 1 d of the scale (what is the problem?).
I also looked at the supply frequency & estimate VI, but this VI seems only exit of scalar data for the largest peak, not exactly what I'm looking for.
Thanks for your help.
You have a second table for the tested frequency? If so, then you are right that you just need to index this table with the indexes by the Ridge detector. Use a loop for. Automatic index to the index, use index in array to get the value of the frequency and autoindex on frequencies.

-
What is the physical meaning of automatic indexing of table entry...
What is the physical interpretation of the automatic indexing. ?
You wire up a table on the edge of a loop, it sequentially will index the table for you as he travels the loops. A While loop will also do this, but it is much more common on loops For, therefore, loops For making automatically while the While loops must be 'right click' and said to the index in the array. Get it?
-
Partitioning or an index organized table. Suggestion required.
Hi gurus,
We decided to perfomance increase in customer table that has more than 100 million records
{code}
customer_id number,
cust_name varchar,
Date of Applied_date,
City varchar (100)
{code}
This is the structure of the customer table.
We decided to composite partition the table based on date (range) applied and customer_id (hash).
I am confused to go with table index (where tables and indexes are stored together) for better performance.
Please suggest what we I'm going? for best performance.
Please answer
Supersen
If the query predicate (WHERE clause) include the Partition key column, Oracle can make the size of Partition - that is to say identify the target Partition. Otherwise, he would have to do a full Table Scan because he doesn't know what Partition the target Row (s) is in.
For example, if you are partitioning by APPLIED_DATE but your request is on the table by CITY, Oracle cannot identify the target Partition and do a Scan of Table full - even if you subpartition by CUSTOMER_ID and integrate CUSTOMER_ID in your query, Oracle cannot identify the Subpartition because it cannot identify the Partition.
Hemant K Collette
-
Recovery of the records by using the Ref Cursor or indexes per Table (which is better)
Hi all
I am interested to know if there is a performance (or other) advantages to return a result set from an Oracle stored procedure for a client application (for example, in Java) by using a Ref Cursor or Index by Table, respectively. Most of the people I met who know Java seem to use a Ref Cursor but did not say why this method is preferable. I'm not too familiar with Java and do not have the opportunity to test the difference between either method, but I am very interested in the other user forum about this view, gauging
Kind regards
Kevin.KevinFitz wrote:
Hi zerathul,Thanks for the quick and helpful response. A REF CURSOR would be the best solution if the same set of results (content and number of records returned) should be dealt with by the application of the 'customer '. I'm guessing that maybe in this situation 'theoretical' that there might be less network traffic to return the set of results through an associative array,
Kind regards
Kevin.
Yes, it would always be the best solution, because an associative array would mean collecting all the data in memory of expensive PGA on the database server before they pass any return on the network, while a fair Ref cursor is to feed the data over the network (maybe a little extra load, but you were unlikely to notice). Also the client application would treat a ref as of rows returned cursor data recovery and could treat them upon their arrival, an associative array is a collection of data which will then be entirely spent before any treatment could be done and then the treatment should go through the entire table to do.
REF CURSOR will also provide other information such as the error codes etc regarding SQL if necessary. If you get an error when filling a table on the side of the database, it is not so easy to recover this error to the client.
REF CURSOR is designed for this purpose. Use them.
-
Delete Performance index organized Tables
Hello
We are experiencing some performance problems with one of our tables.
We have a table (test), which contains 9 columns:
A number (10) not null not pk,.
B number (10),
C number (10),
D number (10),
E number (10),
F varchar2 (30),
F varchar2 (2),
G varchar2 (2),
H varchar2 (250).
The table test is an ITO (Index Organized Table) in configuration of default ITO.
All columns are often necessary for we can not all overflows.
The table has currently 8 m records, which is roughly 1/2 years of a data value, so insignificant.
Inserts and updates are fine, but it takes 40 + seconds to delete a single line!
(remove test where a = 3043 ;))
If I convert this table in a standard table, deletes are only 0.5 of a second?
No idea why the delete statement takes an excessively long time on the IOT, or what I could do wrong?
Thank you
Victoria
Oracle Enterprise version 10.2.0.1.0
Oracle XE version 10.2.0.1.0It seems as if the PK on this table of ITO is referenced by a FK on a child table (big enough) but the FK does not have an associated index.
Deleting a line in this table, Oracle is required to perform a FTS on the child table to make sure that there is no matching FK.
Find out if you have indeed a FK that refers to this table, and if CF is indexed.
Just a guess, of course. A long track during the delete operation should be noted where Pio come just to be sure.
See you soon
Richard Foote
http://richardfoote.WordPress.com/ -
Is it possible to make multiple indexes and tables of contents?
I have InDesign CS2. I was wondering, is it possible to make several index? For example, an index of names, a separate index for places. Similarly, is it possible to make several Tables of contents? What I really want, it's a Table of contents, list of illustrations, a list of maps and a list of the cards. What is the best way to go about this? I know I can make a table of contents, copy the text and use it, then modify the toc settings to make a new. So my main concern is the index, but I'm curious to know if there is a better way for tables of contents.
Thank you
An InDesign document can have as many tables of contents you want, but you get only to create an index. One solution is to combine everything in a single index, and then copy and paste it into separate stories at the end. I'm a little fuzzy on the details of how get you this to sort (I never had the need, so far, to do), but it has been described here more than once. I think that a forum for several index search you would probably get the answer.
-
What is logical rowid in IOT? are they kept physically somwhere like physical rowId
What are secondary indexes?
what he meant by leaves block splits? When and how it happens?
and the primary key for a table in index constraint cannot be abandoned, delayed or off, is this true, if yes then Y
How overflow works? how the two clauses are implemented PCTTHRESHOLD and INCLUDING.how they work?
Published by: Juhi on October 22, 2008 13:09I'm sort of tempted to simply point you in the direction of the official documentation (concepts guide would be a start. See http://download.oracle.com/docs/cd/B28359_01/server.111/b28318/schema.htm#sthref759)
But I would say one or two other things.
First, physical ROWID not is not physically stored. I don't know why you would think they were. Certainly the ROWID data type can store a rowid if you choose to do, but if you do something like "select rowid from scott.emp", for example, you will see the ROWID that are generated on the fly. ROWID is a pseudo-column, not physically stored anywhere, but calculated each time as needed.
The difference between a physical rowid and logic used with IOT boils down to a bit of relational database theory. It is a rule in melting of relational databases that a line, once inserted into a table, must never move. In other words, the identifier that is assigned at the time of his first insertion, must be the rowid he "keeps" for ever and ever. If you ever want to change the assigned lines in an ordinary table ROWID, you must export them, truncate the table, and then reinsert them: Insert charges, fees rowid. (Oracle bend this rule for various purposes of maintenance and management, according to which 'allow the movement of line"allows lines without a table, but the general case is still valid for most).
This rule is obviously hopeless for the index structures. It was true, an index entry for "Bob" which is updated to "Robert" would find next to the entries for 'Adam' and 'Charlie', even though she now has a value of 'R '. Effectively, 'line' a 'b' in an index must be allowed to "move" a sort of 'r' of the block if it's the kind of update that takes place. (In practice, an update to an index entry consists of performing a delete followed by a re - insert, but the physicalities do not change the principle: 'lines' in an index must be allowed to move if their value is changed; rows of a table do not move, no matter what happens to their values)
An IOT is, at the end of the day, simply an index with columns much more in it that a 'normal' index would - he, too, has thus allow its entires (his 'rows', if you like) to move. Therefore, an IOT cannot use a standard ROWID, which is assigned only once and forever. Instead, one must use something that takes into account that its lines may wander. It's the logical rowid. It is not more 'physical' as a physical rowid - or are physically stored anywhere. But a 'physical' rowid is invariable; a logic is not. Logic, it is actually built in part of the primary key of the ITO - and this is the main reason why you can never get rid of the primary key on the IOT constraint. Be allowed to do would be to you to destroy an organizing principle for its content which has an IOT.
(See the section called "The virtual ROWID" and continued on this page: http://download.oracle.com/docs/cd/B28359_01/server.111/b28318/datatype.htm#CNCPT1845)
IOT so their data stored inside in the primary key order. But they only contain the primary key, but all the other columns in the definition of 'table' too. Therefore, just as with an ordinary table, you might sometimes find data on columns that are NOT part of the first key - and in this case, you might well these columns non-primary keys are indexed. Therefore, you create ordinary index on those columns - at this point, you create an index in an index, really, but it's a secondary question, too! These additional indices are called 'secondary index', simply because they are "subsidiary clues" in the main proceedings, which is the 'picture' himself laid out in the primary key order.
Finally, a split block of sheets is simply what happens when you have to make room for the new data in an index block which is already filled to overflowing with the existing data. Imagine an index block may not contain four entries, for example. Fill you with entries for Adam, Bob, Charlie, David. Now, you insert a new record of 'Brian '. If it's a table, you can take Brian to a new block you like: data from a table have no positional sense. But the entries of an index MUST have positional significance: you can't just throw MC Bean and Brian in the middle of a lot of Roberts, bristling. Brian DOIT pass between the existing entries for Bob and Charlie. Still you can not just put him in the middle of these two, because then you'd have five entries in a block, not four, which we imagined for the moment to be maximally allowed. So what to do? What you do is: get an empty block. Move Charlie and David entries in the new block. Now you have two blocks: Adam-Bob and Charlie David. Each has only two entries, so each has two 'spaces' to accept new entries. Now you have room to add in the entry for Brian... and if you end up with Adam-Bob-Brian and Charlie David.
The process of moving the index entries in a single block in a new one so that there is room to allow new entries to be inserted in the middle of existing ones is called a split of block. They occur for other reasons too, so it's just a brilliant of them treatment, but they give you the basic idea. It's because of splits of block that indexes (and thus IOT) see their 'lines' move: Charlie and David started in a single block and ended up in a completely different block due to a new (and completely foreign to them) Insert.
Very well, infinity is simply a means of segregation of data in a separate table segment that would not reasonably be stored in the main segment of the ITO himself. Suppose that you are creating an IOT containing four columns: one, a digital sequence number; two, a varchar2 (10); three, a varchar2 (15); and four, a BLOB. Column 1 is the primary key.
The first three columns are small and relatively compact. The fourth column is a blob of data type - so it could be stored whole, multi-gigabyte-size monsters DVD movies. Do you really want your index segment (because that's what an IOT really is) to ball to the huge dimensions, every time that you add a new line? Probably not. You probably want 1 to 3 columns, stored in the IOT, but column 4 can be struck off the coast to a segment on its own (the overflow segment, actually) and a link (in fact, a physical rowid pointer) can bind to the other. Left to himself, an IOT will cut each column after the a primary key when a record that threatens to consume more than 50% of a block is inserted. However, to keep the main IOT small and compact and yet still contain data of non-primary key, you can change these default settings. INCLUDE, for example, to specify what last non-primary key column should be the point where a record is split between "keep in IOT" and "out to overflow segment." You could say "INCLUDE COL3" in the previous example, so that COL1, COL2 and COL3 remain in the IOT and only COL4 overflows. And PCTTHRESHOLD can be set at, say, 5 or 10 so that you try to assure an IOT block always contains 10 to 20 saves - instead of the 2 you would end up with default if 50% of kicks.
-
At all indexes on tables of the same value in the structure of the event
Hello
I have a panel with the four bays and I use a structure of the event.
Now, I want that change of the index of array_1 also affects the index of 3 other tables at the same index.
But there is only a property "value Exchange" and no property 'index-change' in the properties of the table.
So I read the 'index' property and write in the other table.
But: It seems as if I have to do so within the period of waiting-section of the structure of the event.
Is there another way to do this?
Thanks for help
You can use the mouse event on each table to detec the event (of course, that will attract not only a change of index, but I don't think you care too) and then use the 'values of the indices' property on all the table to set.
See annex VI (LV2012), hope this helps
-
Hello and thanks for reading.
I have a problem that requires me to do a lot of manipulations with the berries, and I am doing this in a series of nested for loops. I'll cut straight to my question.
I initialize an array 0 in several user-defined columns. I run a loop for the number of times user, generating a random value to each iteration defined. If I activate the automatic indexing, I use the subset of table replace outside the loop and it works very well.
Here's my problem. If I turn off the automatic indexing, and son of the [i] block to the index on the subset of table replace, now all of a sudden all I get is a random value, and it is always in the last slot in the table.
I was pulling my hair out on this problem. I looked at the forums, I looked at the example problems, I don't know WHY it does this, but I have TO be able to use the loop counter to replace the elements in the array. I'll lay 3 loops, and I'm not quite (familiar) uncomfortable with the way the auto-indexation feature chooses value auto-index to be able to think through the problem.
I wrote the program in C in my head in about 10 minutes, but this automatic indexing thing is KILLING me and I have no idea how import C in LabView without writing a dll, which I don't know how do either.
Please let me know how I can get the loop For to browse a table without using automatic indexing. Yet once again, I have no idea why he is just posting a value in the last slot of the table.
Thanks a lot for all the replies.
I know what it is. I have no LV 2010 here at installed work, so I have to rely on my memory and see the code.
You use replace table subset. With lit autoindexing, you create a table 1 d of random numbers which is be the same length as your table due to the terminal N being associated with the length of the array. If you end up replacing the dimension table 1 d in its entirety in a single shot with the new data starting with element 0. (For smile, associate a smaller number to Terminal N and you will see that some of your table 1 d is replaced).
The way I showed you replace 1 data at a time, and the first iteration is item 0, the element following 1...
-
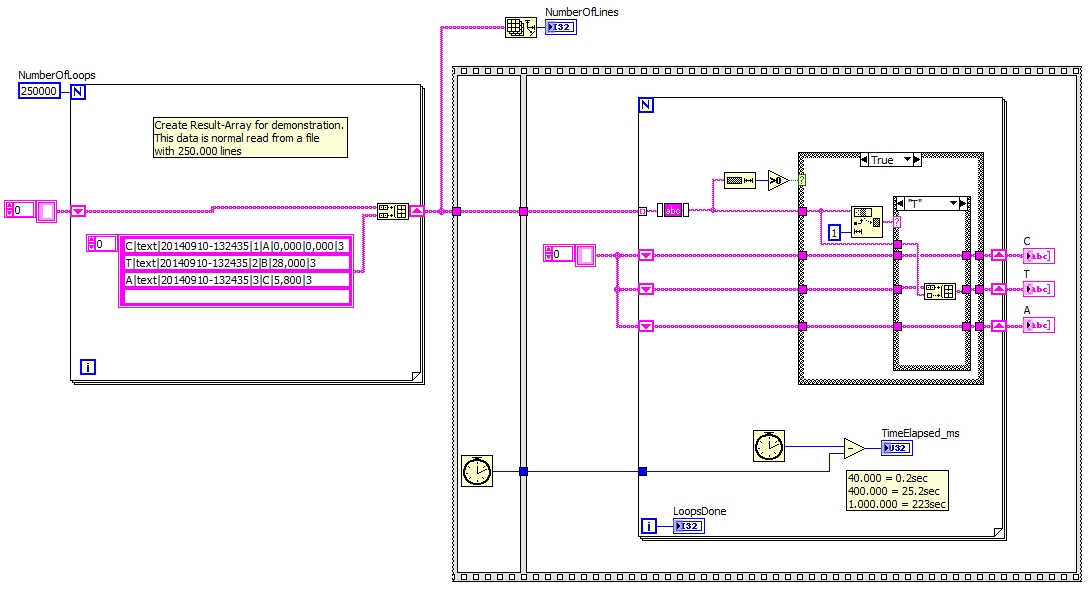
Sorting the rows in the table based on the first character - speed-problem
Hello
I have a text file with a lot of lines. The file is imported into LV, and must be sorted by the first character.
It works very well, but gets very slow lines if too.
If 40,000 lines then take 0. 2 s.
If 400,000 lines then the time rises with factor 100 in 25 years.
If 1,000,000 lines then the weather is dry 222 (~ 4 min)
Attached is the code which sorts a table to text.
The number of lines can be set with the meter of the loop (Loop-counter * 4 = NumberOfLines)
The elapsed time is displayed.
How to speed this up? (Or check the more linear time number of rows)
Thank you
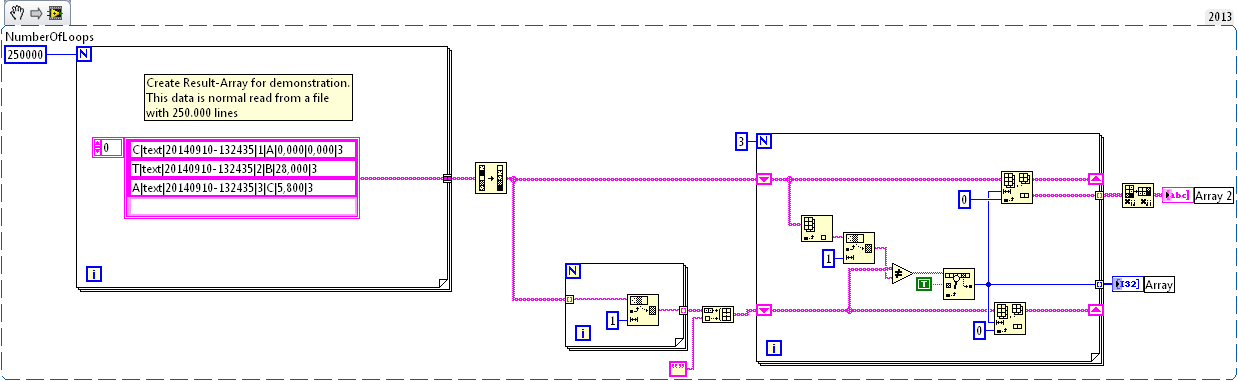
You can try something like that. If you treat a table line by line, you end up taking a lot of time.
Sorry I have a problem of fixing of the VI.
-
Sort by label name references table
I develop a DSC application with the alarming and shared variables and events with a quantity of hugh of variables. Each variable is displayed on the front panel in the tab controls. To reduce the time and effort during the expansion of variables, I want to organize my references from the front panel of the brand. I have attached some of the initialization of the façade. Here, I must manually unpack each variable in the variable shared library where the variable name must be in the same order as the definition of the cluster.
My approach was to build a digital type references and sort the references by name of the label. Because the shared variables have the same name that controls, they would be in the same order and I could also dislaim the cluster of references.
Maybe someone can give my a 'pipe '.
Kind regards
--
Joachim
Hello Joachim,.
use the standard approach "sort a table of cluster!
Put the label control and the reference (in that order!) in a cluster, make an array of these groupings and sort the table. It will sort by the label and you can ungroup the reference in the order...
-
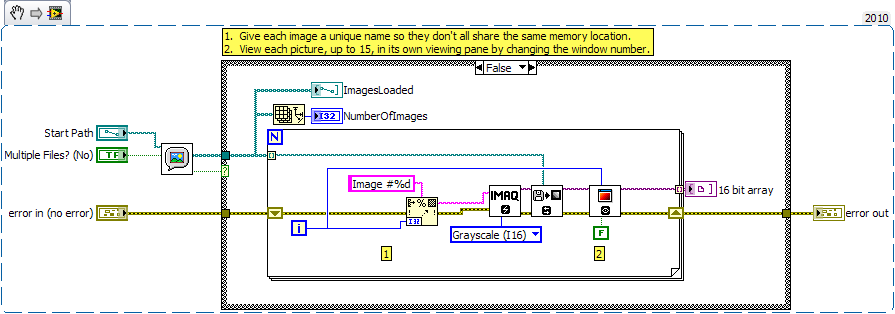
Impossible to index a table of images images!
Hi all
I encountered this problem lately. I am indexing a number of images in a table using a loop for. Then the array of images (16 bits) is used somewhere else in the program. It is indexed and the images are processed and displayed. The problem is; When you try to index the images of the sets using the table to index the result is the same regardless of the index!
Can someone explain that to me?
Thanks in advance
When you used the IMAQ create VI you specified each image to use the same name of 'image '. Each image must have a unique name. I edited your VI to give a unique name for each image and I could see three different images to three different display components.
-
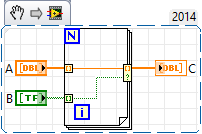
How to use a vector of Boolean indexing a table
I have a table A = [1 2 3 4 5 6 7 8 9 10].
I also have an array of Boolean B = [1 1 0 0 0 0 0 0 0 1].
I want to use the table of Boolean B spot the items, create a new matrix C = [1-2-10]. In MATLAB, I would just type C = a.b.
I'm scratching my head trying to figure how to do this. A solution would be to go through a loop for, query b.i and remove a (i) If b = 1. But that would change the size of A, while the second time I did it, my rating would be a mistake.
Anyone know of a way to do it?
BONUS: If I have an AA 2D, with multiple columns, it would be nice to use B to select several columns of AA (in MATLAB, it would be CC = AA(:,B).
This can be done with automatic indexing with conditional tunnels. The same approach could easily be applied to a 2D array, thus:
Maybe you are looking for
-
MacBook Pro retina 2015 (1 month)
Hello I can't work on my macbook pro when I am sitting on my couch! If I move my laptop, it goes to sleep, I see a black screen and I have to log back into my account. Do you have any suggestions? Thanks for your help. Luigi
-
How can I check an increasing rate
I want to check a frequency which increases. If it exceeds 2000 I want to capture immediately, but if it does not exceed 2000 for 12 seconds, I want to enter anything at that time here. Attached is a VI that accomplishes that, I wrote, but I used a l
-
Dear ppl. Need help to defame readings of voltage oscilloscope, torque, angular and contre-electromotrice of the attached circuit speed. The engine is a hand-driller of 550 watts. Mutual inductance A - F, the inertia of the shaft and friction are set
-
Upgrade Windows 7 (on-line) of Vista
If I upgrade to Windows 7 Vista online, Will Word, Powerpoint, Xcel and editor work as they do now? Will all of my files and emails in Hotmail and Outlook be o.k. Finally, I have other applications such as Contact Manager Maximizer, Hotspot shield,
-
Windows Vista Home Premiun 64 bit Sidebar stop working
My sidebar stop working and I can't find the answer to fix