sum when separate
Hello
I have table
ID | cost
1. 100
2. 200
2. 200
3. 500
4. 500
5. 800
6. 100
6. 100
6. 100
and I need sum (cost) where id is distinct, NO GROUP!
I need to get
all costs
2200
(1 id) 100 + (id 2) 200 + (id 3)500 + (id 4)500+ (id 5)800+ (id 6) 100= 100 + 200 + 500 + 500 + 800 + 100 = 2200
Thanks for help
Select
Sum (Max (cost)) cost
from your_table
Group by id
Tags: Database
Similar Questions
-
Question about trade SUM () and SEPARATE - Oracle 10 g
Hi all
I have a table (customer) with 7 million rows and columns around 20. I want to retrieve all the account numbers. and the corresponding summarized balance sheets (only 2 of the 20 columns) into a new table which I will use as a snapshot, to compare with the data of payment processed at a later stage.
In the current table, there are several lines for an account no. with entries 0 or others in the balance column. I don't know how to to consolidate the info as I have just one line per account and the sum remains in a new table, say temp
Thanks in advance.
Rgds
noviceWhat:
Create table my_temp as select account,sum(balance1) as balance1,sum(balance2) as balance2 from customer group by account; -
Helps with the instruction WHEN SUM
I have the following code which works without a problem. However, I need to add an extra parameter. I need to SUM when the name of the month is > 0 and less than 37. How can I add the > option 0?
Thank you!
, sum (case when month_name < 37 then qty_used 0 otherwise end) M_0Hello
847497 wrote:
I have the following code which works without a problem. However, I need to add an extra parameter. I need to SUM when the name of the month is > 0 and less than 37. How can I add the > option 0?Thank you!
sum (case when month_name< 37="" then="" qty_used="" else="" 0="" end)="">
Conditions in a CASE expression can be compound conditions, linked by AND or or, as the conditions in a WHERE clause.
SUM ( CASE WHEN month_name > 0 AND month_name < 37 THEN qty_used ELSE 0 END ) AS m_0 -
Separate issue of County 10 G OBIEE
Hello
I am really new to OBI now runs into this problem.
I did, and three tables of dimensions as follows:
fact:
1. turnover:
sold_vlaue (sum)
transactions (count distinct receipt_id)
branch_id (foreign key)
daykey (foreign key)
receipt_id (foreign key)
product_key (foreign key)
Dimensions
1. General management
branch_id (key)
2. the time
daykey (key)
3 product
product_key (key)
These tables are attached as above keys star schema. Sales.sold_value is aggregated by 'sum', operations (separate County receipt_id) is. I don't have a receipt_id dimension since it is only for the calculation of the transaction.
So, how can I implement to do operations correct (County receipt_id distinct)?
I tried to put transactions as a separate County in order of default aggregation. But the result is false (1)
All right. I thought about it.
The fact table must be modeled as:
1. turnover:
physical layer:
sold_vlaue
branch_id (foreign key)
daykey (foreign key)
receipt_id (foreign key)
product_key (foreign key)
The underlying query is:
Select
branch_id daykey, receipt_id, product_key
sum (sold_value)
table
Group
branch_id daykey, receipt_id, product_key
Layer MDB:
sold_value (sum)
transactions (count distinct receipt_id)
branch_id (foreign key)
daykey (foreign key)
receipt_id (foreign key) (deleted)
product_key (foreign key)
-
Articles of Sum in tabularform
Good afternoon
my name is maribel and I need help
I want that 2 items in my sub form of sum when I press "TAB".
For example, I have "Code""Cant", 'Unit of V', 'TOTAL', I put 2 in "Cant" "TAB" and I put 10.05 in 'V unit' then when I put 'TAB' automatically 'TOTAL' have 20.10
I hope you can understand me because I do not speak English
Thank you
Published by: 997648 on 02-Apr-2013 15:49
Published by: 997648 on 02-Apr-2013 15:59Hello
Thanks for your reply.
I understand so so, but I mix this post with others and I fix my problem :DThank you
-
Hi all I'm new to sql.
I run a long query:
SELECT T1. OrderNo SDDOCO. "
T1. "" OrderLineNo SDLNID. "
T1. "' SDDCTO ' OrderType.
T1. "" OrderCompany SDKCOO. "
T1. "' SDIVD ' InvoiceDate,.
NVL (LTRIM (RTRIM (T1." SDLITM')), 'None') ProductCode.
NVL (T1." (SDSHAN', 0) CustomerCode,.
NVL (LTRIM (RTRIM (T1." SDMCU')), 'None') DepotCode,.
T1. "" InvoiceDocNo SDDOC. "
decode (T1." SDDCT","RI","Invoice","Palette invoice") DocType.
NVL (LTRIM (RTRIM (T1." (SDCARS")), 0) TransporterCode,
NVL (LTRIM (RTRIM (T1." (SDMOT')), ' 0') ModeOfTransport,.
NVL (LTRIM (RTRIM (T1." SDPRP1')), 'None') unit of MEASURE.
NVL (T1." (SDAEXP', 0) / 100 InvoiceAmount,.
(CASE WHEN T1. SDIVD BETWEEN 105182 AND 105215 THEN
(((NVL (T1." ((SDAEXP', 0) / 100) * NVL ((SELECT NVL("ALFVTR",0)/10000 OF))
'PRODDTA '. "' F4074 ' WHERE ' ALDOCO '= T1.'" SDDOCO' AND
'ALDCTO' = T1. "" SDDCTO "AND"ALKCOO"= T1. "" SDKCOO "AND"ALLNID "=.
T1. ((((' ' SDLNID ' AND 'ADERNIERES' = 'REBACCR' AND ALASN = 'CEMENT'), 0) / 100) * - 1).
ANOTHER (((NVL (T1." ((SDUORG', 0) / 100) * NVL ((SELECT NVL("ALUPRC",0)/10000 OF))
'PRODDTA '. "' F4074 ' WHERE ' ALDOCO '= T1.'" SDDOCO' AND
'ALDCTO' = T1. "" SDDCTO "AND"ALKCOO"= T1. "" SDKCOO "AND"ALLNID "=.
T1. ((((' ' SDLNID ' AND 'ADERNIERES' = 'REBACCR' AND ALASN = 'CEMENT'), 0) / 100) * - 1).
END) AS RebateAccr,
(CASE WHEN T1. SDIVD BETWEEN 105182 AND 105215 THEN
(((NVL (T1." ((SDAEXP', 0) / 100) * NVL ((SELECT NVL("ALFVTR",0)/10000 OF))
'PRODDTA '. "' F4074 ' WHERE ' ALDOCO '= T1.'" SDDOCO' AND
'ALDCTO' = T1. "" SDDCTO "AND"ALKCOO"= T1. "" SDKCOO "AND"ALLNID "=.
T1. ((((' ' SDLNID ' AND 'ADERNIERES' = 'REBWGHT' AND ALASN = 'CEMENT'), 0) / 100) * - 1).
ANOTHER (((NVL (T1." ((SDUORG', 0) / 100) * NVL ((SELECT NVL("ALUPRC",0)/10000 OF))
'PRODDTA '. "' F4074 ' WHERE ' ALDOCO '= T1.'" SDDOCO' AND
'ALDCTO' = T1. "" SDDCTO "AND"ALKCOO"= T1. "" SDKCOO "AND"ALLNID "=.
T1. ((((' ' SDLNID ' AND 'ADERNIERES' = 'REBWGHT' AND ALASN = 'CEMENT'), 0) / 100) * - 1).
END) as RebateWght,
(CASE WHEN T1. SDIVD BETWEEN 105182 AND 105215 THEN
(((NVL (T1." ((SDAEXP', 0) / 100) * NVL ((SELECT NVL("ALFVTR",0)/10000 OF))
'PRODDTA '. "' F4074 ' WHERE ' ALDOCO '= T1.'" SDDOCO' AND
'ALDCTO' = T1. "" SDDCTO "AND"ALKCOO"= T1. "" SDKCOO "AND"ALLNID "=.
T1. ((((' ' SDLNID ' AND 'ADERNIERES' = 'REBTON' AND ALASN = 'CEMENT'), 0) / 100) *-1) ELSE
(((NVL (T1." ((SDUORG', 0) / 100) * NVL ((SELECT NVL("ALUPRC",0)/10000 OF))
'PRODDTA '. "' F4074 ' WHERE ' ALDOCO '= T1.'" SDDOCO' AND
'ALDCTO' = T1. "" SDDCTO "AND"ALKCOO"= T1. "" SDKCOO "AND"ALLNID "=.
T1. (((((' ' SDLNID ' AND 'ADERNIERES' = 'REBTON' AND ALASN = 'CEMENT'), 0) / 100) *-1) END)
as RebateTon,
NVL (T1." (SDECST', 0) / 100 ProdCosts.
DECODE (T1." SDDCT","PR", 0, NVL)
SELECT MAX (T5. "FHNAMT"(/100) * ((T1.' " SDUORG "(/100) WHEEL (T5." " FHRTDQ "(/100)) OF"
'PRODDTA '. "" F4981 T5 ","PRODDTA ". "F4942"T4 ".
where T5. "" FHSHPN "= T4. "' ISSHPN ' AND T1. "" SDDOCO "=.
T4. "' ISDOCO ' AND T1. "" SDDCTO "= T4. "" ISDCTO "AND T5. ((("' FHOVFH ' <>' 1'), 0))
CustTransport,
T1. "SDUORG" / 10000 NoOfBags, "
T1. SDUORG/10000 *-1 * NVL ((SELECT SUM (NVL (BOX WHEN SEPARATE
(T1. "" SDIVD "> = 107001 AND T1. "" SDIVD "< = 107181
AND ADERNIERES = 'SETTLE15' AND a. ("' ALUPRC ' IS NOT NULL) THEN
NVL (a." (ALUPRC', 0) / 10000
WHEN (T1. "" SDIVD "> = 107001 AND T1. "" SDIVD "< = 107181
AND a.ALAST = 'SETTLE07' AND one. ("' ALUPRC ' <>0) THEN
NVL (a." (ALUPRC', 0) / 10000
WHEN (T1. "" SDIVD "> = 107001 AND T1. "" SDIVD "< = 107181
AND a.ALAST = 'SETTLE07' AND one. ("" ALUPRC "= 0) THEN
0
WHEN (T1. "" SDIVD "< 107001 OR T1. "" SDIVD "> 107181 AND a.ALAST =
"SETTLE07") THEN
NVL (a." (((ALUPRC', 0) / 10000 END, 0)) ALUPRC
OF 'PRODDTA '. "' F4074 ' a
where a. "" ALDOCO "= T1. "" SDDOCO ".
AND one. "" ALLNID "= T1. "" SDLNID ".
AND one. "" ALDCTO "= T1. "" SDDCTO ".
AND (a.ALAST = "SETTLE07"
OR a.ALAST = "SETTLE15")
(), 0) SettlementDiscount,
NVL (LTRIM (RTRIM (T1." SDFRTH')), 'None') FreightHandlingCode,.
NVL ((SELECT "DRDL01"TO "PRODCTL"." F0005"WHERE 'DRSY' = '00' AND
"MOVING" IS "DT" AND LTRIM (RTRIM("DRKY")) = T1. "" ""SDDCTO"), 'None').
OrderTypeDescription,
NVL (T1." (SDLNTY', ' no) line type
of 'PRODDTA '. "' F42119 ' T1
WHERE T1. "" SDDCT "("RI","PR")
and T1. "" SDIVD "> 108365
and T1. "" SDKCOO "="00007 '
AND T1. ' SDDCTO ' IN ('IF', 'SY', 'IF').
and T1. "' SDLNTY ' <>'TB '.
It immediately gives me:
SQL > @script
84
and then just wait.
He gets a lot of data, but what is the 84?I've created a script with the content
select * from dualtry to start it wil show me the next number in the line:
SQL> @script 3 / D - X SQL>entered a slash / and there we go...
-
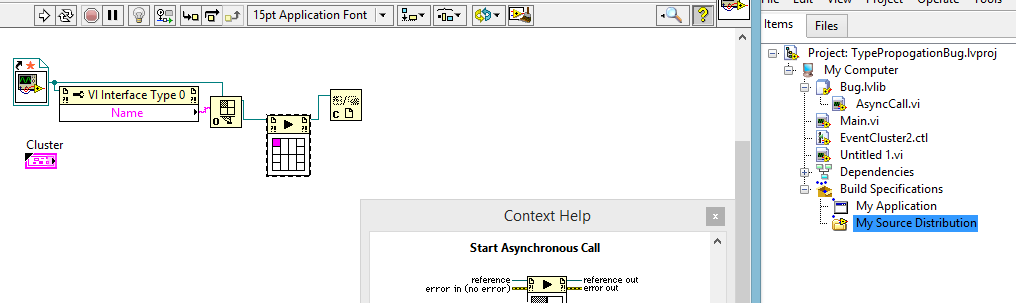
Start the asynchronous call brutal Typedef Bug
There is a nasty bug which I think is the cause of many anomalies weird I see with the events of the user, like where some get fired and if I probe the refnum of the event on a VI that was launched using the asynchronous call node start I get some weird value for reference as 8450 or 5500 instead of some great typical integer. It is not also match the value that I get when I initialize the reference. This happens only intermittently, but I can reproduce the bug that I see on a smaller scale to a certain extent. This is not exactly the same as what I see in my current project, but I guarantee you both are related. Also, I'm pretty confident that this has to do with the help of LVlibs as well.
So... to reproduce some questions:
Unzip the attached code and open the project
Open Main.vi. It is hard to see because it's pink, but notice the point of constraint on the node to call asynchronous start. This is provided at this point because I have a cluster of non-typedef in the connector pane, but a TD cluster plugged into it.
Now open AsyncCall.vi
Drag the eventcluster.ctl of the project on the façade of the asynccall.vi
CTRL + x on the typedef cluster that has placed you on the front panel
Select the non-typedef cluster by clicking it
CTRL + v to replace the TD not cluster with the cluster of TD and save
Return to main.vi, you will notice that the point of constraint does not go far.
Open context-sensitive help and notice that the ctrl types match, but it's as if LV does not recognize it on the beginning of the node of the asynchronous call.
Remove the node from asynchronous start call, then replace it. The cluster to the top wire. Voila, no point of constraint.
Second question - same result but different method to get there.
Now that you have components of connector typedef stress points and no more because you've taken the first steps of this 'exercise', remove the EventCluster.ctl from the library and record.
WOAH, look the points of back strain, because node call asynchronous start still referencing the typedef cluster that he thinks that should be in the library. This can be seen by removing the cluster on main.vi and then right-click on the node to call asynchronous start on the side of the connector and creating a new constant of cluster
It is creates a greyed out of control! Why? Well, we will reopen the context-sensitive help. Whadda you know, it's always looking for the control in Bug.lvlib that no longer exists.
Now, the question that I'll have in my complete project that I can't post and can not reproduce on a smaller scale updates the typedef causes the dot of coercion. Otherwise I can't update my typedef cluster that contains all my events without going and replacing EVERY SINGLE launch async call node EVERY time I have add a new event.
Major problem.
Please let me know if these steps to reproduce were not clear or you have difficulties to reproduce the problem. I use LV2013 SP1. I opened the project in 2014 to see if it has been fixed in a later version, but I saw the same thing.
I can repro with measurements of @GregFreeman and also confirm that I saw this same issue at least since the LV2012, but they have not reported it having not been able to provide a minimum test (thanks, @GregFreeman!) scenario
For the record, it seems that the bug here, it is the spread of type sometimes makes an incorrect assumption / optimization as to if the conpane of the start the asynchronous call node must be updated when the source changes.
A more obvious change - say, add/remove an entry, reverse order, or change data types altogether - always seems to spread properly.
Incorrect optimization seems to be a terminal retains the same type of database, but transforms the type definitions - or, if the type definition is re-related or related outside a library owner.
@GregFreeman watch the bug goes from non-typedef typedef, but it's actually worse in the other direction - when a link to a missing file is maintained.
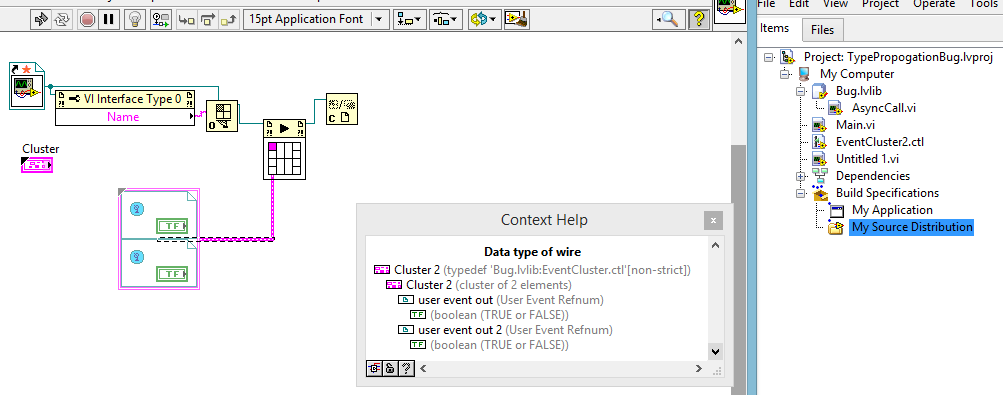
Call the asynchronous starting node seems to maintain a list of links that is distinct from that of the VI, and this list of links separated, this is what seems to not be properly invalidated. For example, in the screenshot, I illustrated example of Greg that the node generates no error in the compiler even after parenthood and rename the Typedef...
... even when we "Create Constant" on this terminal incriminated with list obsolete links, we get a compilation error. Since then, the grayed out type highlighted in the contextual help cannot be found, because 'Bug.lvlib:EventCluster.ctl' no longer exists, but the list of links separated from this node was not notified:
It is worth noting that "Bug.lvlib:EventCluster.ctl" does not appear in the list of links of the VI at this stage.
Often, no compiler error is generated after this failure occurs and as Greg reports, you could end up with undefined behavior (e.g. suspicious Refnums and events that seem to not fire not) (and I'll add it to this list a hearty portion of DAborts with diversion total number of messages).
In addition, you * could * receive errors of cryptic linker for generations, but maybe not (the above screenshot, you'll notice I added two builds, neither of which seems to have a problem of building). (It seems that the broken link is travel with the distribution of the source, even if 'Disconnect the definitions of Type' is selected during the build process. That is why I believe anecdotally that node maintains a list of link separately the list of VI, and it's maybe part of the problem).
It is noted that during this refactor (de-parent and rename) all screws and control remained open and in memory and all files have been saved. No funny business where LabVIEW would be unable to update links in a file that was not in memory.
Another note - in the original example, all source files have been unifiles, and I can add anecdotal report this bug is much more insidious when separate compiled Code is active on the source files. In this case, the source may appear to be perfect - no point of constraint, no link expired - but the code that is currently running can be broken. In other words, what you see is not what you get, which makes debugging impossible. (This bug in particular is one of the few who makes "Cache of compiled clear objects" become a normal procedure controlled throughout the application development)
Anyway, I wanted to draw attention to this issue, given that this thread is not yet associated with a CAR and it's a serious bug that generates a behavior undefined performance caused by a fairly normal refactor now has a well-characterized small repro case.
-
Problem with button 'Load' and Boolean reset
Hello...
I've built a simple VI to load a file ascii with 100 values, split the file into 4 segments (overlap of 50%) and perform the calculation of the SUM of the segments. Each segment is represented by a graph and has a LED that, when is ON means that the segment will be used for the calculation of the SUM, when the LED is OFF this segment will not be used for the calculation.
I have two problems:
First: I inserted a button load and I need when I push the button, a window open and allowed me to select the ascii file to load, after that I analyzed segments and take note of the AMOUNT, I want to again press the Load button and load another file to analyze. The problem is that the works of load button only once, on the second file that I try to load, button freezes pushed and nothing happens and I need to stop the VI and run it again.
Second: by default, I need that after I push the Load button to load another file ascii state that all the LEDS change STATE. In other words, by default all 4 LEDS should be lit when a new file is loaded.
Thanks in advance
Daniel
-
Merging databases and memory settings
I have two separate long-term database server (11r2 on RHEL 5). We seek to combine them into a single server in order to reduce the costs and delays of the admin. On both servers, I can run...
select * from v$sga_target_advice order by sga_size;
.. .and get plenty of data on each box. I can check the current sizes for parameters static EAMA does not dynamically as well.
Question: if I'm their fusion, the initial memory parameters (sga_target, etc.) must simply be the sizes from two servers added?
Aka, if SGA_TARGET is 4 GB on db1 and 5 GB on db2, the combined server is 9 GB?
Thank you
You should study hugepages.
Sybrand is correct. In a dynamic system with many variables, the merger of the two systems is not additive. You go through an iterative process of adjustment. Even the advisers are only a starting point, they tend to want to, just to keep memory more. Find the paper to think clearly on Cary Millsap's performance and consider there are probably things that are fine when separate them, but you cut above the knees when combined. Unless, of course, the two systems are currently passing too provisioned.
You should be able to anticipate some things by taking the CWA (if authorized, statspack if not) reports to see what is normal. Keep just a few looks at the pga and sga statistics. Redo the calibration is probably something that is additive.
-
Analytical function - COUNT issue
Hi all
DB Oracle 11 g running on 64-bit Linux x 86 platform...
I'm curious to know why the underside of two sets of queries produce different results.
Q 1
------
WITH TEMP AS
(
SELECT 'A' VAL BY DOUBLE UNION ALL 5
SELECT 'A' VAL BY 7 OF DOUBLE UNION ALL
SELECT 'FIVE' VAL BY 17 DOUBLE UNION ALL
SELECT 'FOUR' VAL BY 0 FROM DUAL UNION ALL
SELECT 'THREE' VAL BY 78 OF DOUBLE UNION ALL
SELECT 'THREE' VAL BY 34 FROM DUAL UNION ALL
SELECT 'THREE' VAL, PAR 4 FROM DUAL UNION ALL
SELECT 'TWO' VAL BY 6 IN DOUBLE UNION ALL
SELECT "TWO" VAL, 12 BY DOUBLE
)
SELECT SUM (BY) OVER SEPARATE (PARTITION OF VAL), VAL NTC TEMP.
Q2
----
WITH TEMP AS
(
SELECT 'A' VAL BY DOUBLE UNION ALL 5
SELECT 'A' VAL BY 7 OF DOUBLE UNION ALL
SELECT 'FIVE' VAL BY 17 DOUBLE UNION ALL
SELECT 'FOUR' VAL BY 0 FROM DUAL UNION ALL
SELECT 'THREE' VAL BY 78 OF DOUBLE UNION ALL
SELECT 'THREE' VAL BY 34 FROM DUAL UNION ALL
SELECT 'THREE' VAL, PAR 4 FROM DUAL UNION ALL
SELECT 'TWO' VAL BY 6 IN DOUBLE UNION ALL
SELECT "TWO" VAL, 12 BY DOUBLE
)
SELECT SUM (BY) SEPARATE DURING THE CNT (PARTITION BY ORDER OF VAL BY IRON), VAL TEMP;
The only difference between the 2 queries is that Q2 has the additional "ORDER BY".
For the 2nd quarter, I am assuming that the partitions are classified by the RAILWAY and the SUM is applied on the partition. Obviously, the results prove that my assumption is wrong.
So, Q2 is as good as select * TEMP;
Hello
You're right about 'ORDER BY per'; This means that the SUM will be the lowest nominal value up to and including the current line.
I think you're ignoring "PARTITION BY val", which means that each distinct value of val will be a world in itself, not affected by all the lines with a different value of val. Val is different on each row, it means that the indicated SUM will always be the SUM of just 1 point, so SUM (RAP) will be the same only by.
Try it without the PARTITION BY clause.
-
I'm looking for a script powercli and I guess someone already wrote that.
I would like to a total of our ability to store data, a total of all the space provided to the VMs and a total of what virtual machines are actually using on the data store.
I am a noob to powershell and this is currently beyond my skills.
Natasha
Hello, LeaV97-
You're right, there are a few scripts out there that datastore info like you asked for it. I took the opportunity to write a new one, with speed in mind:
## get the sums of the given properties for all datastores$arrSums = Get-View -ViewType Datastore -Property Summary | %{$_.Summary} | Measure-Object -Property Capacity, FreeSpace, Uncommitted -Sum## separate out the sums to separate variables for calculations later$fltCapacityGB = ($arrSums | ?{$_.Property -eq "Capacity"}).Sum / 1GB$fltFreeGB = ($arrSums | ?{$_.Property -eq "FreeSpace"}).Sum / 1GB$fltUncommittedGB = ($arrSums | ?{$_.Property -eq "Uncommitted"}).Sum / 1GB New-Object -TypeName PSObject -Property @{ ## the total capacity of the datastores CapacityGB = [Math]::round($fltCapacityGB, 1) ## the amount of space used by VMs UsedGB = [Math]::round(($fltCapacityGB - $fltFreeGB), 1) ## the amount of space provisioned to VMs ProvisionedGB = [Math]::round(($fltCapacityGB - $fltFreeGB + $fltUncommittedGB), 1)} ## end new-objectIt uses the Get-View and Measure-Object cmdlets for the info and returns an object with the three parts of the info you requested.
-
Problem with the computation of the processing lines
Hi all
We use Jdeveloper 11.1.1.4.0 JHS 11.1.1.4.26.
I am trying to calculate the Salary table Employees field and then put the result in the footer of the table as follows:
1 - a feature on the Employees table construction
2-go to salary attributes field-> control tips and then put the following values:
-Type format = number
-Format = #, # 0.00
3 - construction of a new page of JHS and put the following value on the Salary field:
-View the summary in the table = Type sum
When executing the application, it will throw an exception:
"java.lang.NumberFormatException: for input string:"
When you debug the code, we see that the JHS calls a TableBean.java method called sumRow.
Inside this method, the input value cannot be converted from a string to a number
Any suggestions will be appreciated.
Thank you
Ali.Ali,
It is indeed a bug. To fix it, you should create a subclass of the table bean Jheadstart and override the getSumRow method to return your own map
public getSumRow() map
{
Return sumRowFixed;
}And the private map class looks like this:
private map sumRowFixed = new HashMap()
{
public Object get (Object key)
{
Total = new Number (0);
int rowsWithValue = 0;
int rowCount = getTable ()! = null? getTable () .getRowCount (): 0;
for (int i = 0; i)< rowcount;="">
{
Map rowData = getTable () .getRowData (i) (card);
If (rowData! = null)
{
Object objectValue = rowData.get (key);
If (objectValue is nothing)
{
continue;
}
Number of value = null;
If (objectValue instanceof number)
{
value = (number) objectValue;
}
ElseIf (rowData instanceof JUCtrlHierNodeBinding)
{
JUCtrlHierNodeBinding node = rowData (JUCtrlHierNodeBinding);
objectValue = node.getRow () .getAttribute (key.toString ());
If (objectValue instanceof number)
{
value = (number) objectValue;
}
}
If (value! = null)
{
Total = total.add (value);
rowsWithValue ++;
}
}
}
return to the total;
}
};Then change the tableBean.vm template to use your subclass.
We'll include the fix in the next version.
Steven Davelaar,
Jheadstart team. -
Group items with a changing diapers
I want to group some items, move it then it separated again. After dissociation, however, all the elements are on a single layer.
It is possible to group elements move it and then he disassociate with keeps them in the same layer as they were before I grouped them?
Thanks for any help.
I don't think it's possible. It would be possible to do it with a script.
Maybe check out the Forum script that if there is a way to group a set of items with a script - then when separate you with a script it releases their return to their original positions of layer?
-
SUM and CASES on SEPARATE column
1 query 1:
SELECT IN_SRC_SYSTEM, COUNT (1)
(SELECT
(IN THE CASE WHERE THE VALUE LIKE '% LO %' THEN 'LO'
WHAT VALUE LIKE ' % THE % ' THEN 'THE
WHAT VALUE LIKE '% SAP %' THEN 'SAP '.
WHAT VALUE AS 'SPA %' THEN 'SPA' OTHER 'OTHER '.
IN_SRC_SYSTEM END)
OF LOGTD
WHEN TRUNC (DATE_AGS) = TRUNC (SYSDATE)-1
AND LOG_STATUS = 'P '.
AND VALUE IS NOT NULL)
IN_SRC_SYSTEM GROUP
ORDER BY 1;
output:
IN_SRC_SYSTEM count (*)
THE 62140
LO 59611
SAP 2685
SPA 95
I changed above query returns the results online wise.
Question:-how to add a total of column below sql. (I can reach to above sql by cumulative Group)
SELECT
SUM (CASE WHERE THE VALUE LIKE '% LO %' THEN 1 0) OTHERWISE END "LO."
SUM (CASE WHERE THE VALUE AS THE ' %') THEN 1 OTHER END 0 'LA',)
SUM (CASE WHERE THE VALUE AS "SAP %') THEN 1 OTHER 0 END 'SAP',)
SUM (CASE WHERE THE VALUE LIKE ' % SPA %') THEN 1 ANOTHER END 'SPA' 0)
OF LOGTD
WHEN TRUNC (DATE_AGS) = TRUNC (SYSDATE)-1
AND LOG_STATUS = 'P '.
AND VALUE IS NOT NULL
output
THE SAP LO SPA
62140 59611 2685 95
2.
SELECT ERR_SRC_SYSTEM, COUNT (VALUE)
(SELECT DISTINCT VALUE,
(IN THE CASE WHERE THE VALUE LIKE '% LO %' THEN 'LO'
WHAT VALUE LIKE ' % THE % ' THEN 'THE
WHAT VALUE LIKE '% SAP %' THEN 'SAP '.
WHAT VALUE AS 'SPA %' THEN 'SPA' OTHER 'OTHER '.
ERR_SRC_SYSTEM END)
OF LOGTD
WHEN TRUNC (DATEAGS) = TRUNC (SYSDATE)-1
AND LOG_STATUS = 'E '.
AND VALUE IS NOT NULL)
ERR_SRC_SYSTEM GROUP
ORDER BY 1;
ERR_SRC_SYSTEM, COUNT (VALUE)
THE 174
LO 3
63 SPA
Question:-how to display columns for bottom case distinct values and the State (I can reach to above sql by cumulative Group)
Expected:
THE SPA SAP LO
174-3-63-0
I tried something below, but it didn't work because it lead to a distinct value for the column name
SELECT
SUM (SEPARATE CASE WHEN TRANSACTION_SID LIKE '% LO %' THEN 1 0) OTHERWISE END "LO."
SUM (DISTINCT CASES WHERE TRANSACTION_SID LIKE ' % THE %') THEN 1 OTHER END 0 'LA',)
SUM (DISTINCT CASES WHERE TRANSACTION_SID LIKE ' % SAP %') THEN 1 OTHER 0 END 'SAP',)
SUM (separate BOX WHEN TRANSACTION_SID LIKE '% SPA %' THEN 1 ELSE 0 END) "SPA".
OF OD_LG_TRANSACTION_LOG
WHEN TRUNC (CREATED_DATE) = TRUNC (SYSDATE)-1
AND LOG_STATUS = 'E '.
AND TRANSACTION_SID IS NOT NULL
Kind regards
Veera
It's a shame that we didn't give examples of input data to go with your question. Therefore, it is difficult to answer. Saying that, here are my attempts to answer your questions:
(1) to add columns, you do: col1 and col2 +... + colN. This applies, even if those columns are functions - for example. (Col1) FN + fn (col2) +... + fn (colN).
(2) maybe you're after something like ' count (distinct cases where trasnaction_sid ' % THE %' as the end value)?
For example I think you're after, based on a small sample of the dataset:
with sample_data as (select 1 col1, 'abc' col2 from dual union all select 2 col1, 'bcd' col2 from dual union all select 3 col1, 'abc' col2 from dual union all select 4 col1, 'efg' col2 from dual union all select 5 col1, 'abc' col2 from dual union all select 6 col1, 'hij' col2 from dual union all select 7 col1, 'bcd' col2 from dual union all select 8 col1, 'dfg' col2 from dual union all select 9 col1, 'cde' col2 from dual) select count(distinct case when col2 like '%b%' then col2 end) b, count(distinct case when col2 like '%d%' then col2 end) d, count(distinct case when col2 like '%l%' then col2 end) l from sample_data; B D L ---------- ---------- ---------- 2 3 0 -
When count sum ID number total < 300
Afternoon Folks,
I was wondering if someone could help me with a query of code?
I'm counting the number of Packs of Service where the total payment of the amount for each separate sp_id is less than 300 pounds and also more than 300 pounds.
This is the code I have so far:
Select the specialty
count (distinct sp_id) "Service Packs",
Sum (payment_total) "Total paid £»,
round (sum (payment_total) / count (distinct sp_id), 0) 'average spend by MS.
of a3_fact_sms_service_inv
where specialized ("podiatry", "Podiatry")
and service_date between '01 Jan 11' and 31 Dec 11'
Specialty group
This is the table that I want it to look
SPECIALTY Service Packs Total paid £ average spend by SP * < 300 * > 300 *.
Podiatry 129 25682,26 199 * 107 * 22 *.
Podiatry 622 206651,08 332 * 403 * 219 *.
I'm currently running application 10 g
Concerning
Farming :)First of all, ' 01 Jan 11' is not a date, but rather a string. Use literals date (or at least to_date):
with t as ( select specialty, sp_id, sum(payment_total) sp_id_total from a3_fact_sms_service_inv where specialty in ('Chiropody','Podiatry') and service_date between date '2011-01-01' and date '2011-12-31' group by specialty, sp_id ) select specialty, count(sp_id) "Service Packs", sum(sp_id_total) "Total Paid £", round(sum(sp_id_total) / count(sp_id)) "Average Spend per SP", count(case when sp_id_total < 300 then 1 end) "Service Packs Less £300", count(case when sp_id_total = 300 then 1 end) "Service Packs Equal £300", count(case when sp_id_total > 300 then 1 end) "Service Packs Greater £300" from t group by specialty /SY.
Maybe you are looking for
-
cannot drag and drop into the chat
I had used for a long time a very old version of Skype (3.8) without problem. Recently I have updated to the latest version, and now, I can't drag and drop files in a chat window. I still can select Conversation-Send-file, select a file and send it,
-
Read all about UMI-7774 inhibit in Labview
I use a UMI-7774 with a PXI 7340 controller. How can I check the inhibition throughout Labview? I tried to read the output enable for axis I use, but it does not change when I trigger inhibition all, even if the disabled LED lights and the motor stop
-
There is a configuration option that allows the parallel execution of sub vi?
I'm trying to run a vi in teststand has two parallel execution paths. A path under vi implements the trigger and wait for data from a module scope, while in the other lane, I'm starting a power supply. The power waits until the scope is armed and run
-
Recent update of Windows Defender KB915597
As you probably know, these updates are small KB, but lately they have been 10 MB + and my computer is acting strange. I am trying to remove Windows Defender with a virus (!), but I wonder now, because these updates are relatively large. I searched
-
How to properly install a Station Iogear GUWIP204 Wireless USB sharing in Windows 8?
I can't seem to install - repeatedly said control Setup program is not completed